目录
3.SPPF(Spatial Pyramid Pooling - Fast)

系列文章
【目标检测】英雄联盟能用YOLOv5实时目标检测了 支持onnx推理
一、简介
YOLOv5是在YOLOv3和YOLOv4基础上进行的升级,没有颠覆性的改变,增加的tricks也要看实际情况使用。
YOLOv5主要是给出了一个目标检测框架的落地方案,方便工作落地。
YOLOv5原版代码中给出的网络文件是yaml格式,非常不直观,这里我们直接使用pytorch改写的版本介绍。
这篇文章主要介绍原理,使用方式请跳转另一篇文章:【目标检测】英雄联盟能用YOLOv5实时目标检测了 支持onnx推理
项目链接: https://github.com/oaifaye/dcmyolo
二、模型结构
1.整体结构图
YOLOv5按大小一共有5个版本,Yolov5n、Yolov5s、Yolov5m、Yolov5l、Yolov5x,这5个版本模型只有中间层的通道数和深度不同,模型大致结构其实是一样的,5个版本的模型结构参数如下:
| 模型 | 通道数系数 | 深度系数 | 通道数[bc] | 深度[Depth] |
|---|---|---|---|---|
| Yolov5n | 0.25 | 0.33 | 16 | 1 |
| Yolov5s | 0.50 | 0.33 | 32 | 1 |
| Yolov5m | 0.75 | 0.67 | 48 | 2 |
| Yolov5l | 1.00 | 1.00 | 64 | 3 |
| Yolov5x | 1.25 | 1.33 | 80 | 4 |
表格中的通道数是基础通道数=64乘以前面的通道数系数的结果,深度是基础深度=3乘以深度系数的结果,下面我们以Yolov5l为例([bc]=64,[Depth]=3),给出模型图,进行介绍。
图1中每个块下面灰色的部分是输出,图中用到的参数如下:
batch_size=1
input_size=640x640
[bc]通道数=64
[Depth]CSP中Bottleneck的深度=3
[cls]分类数=3
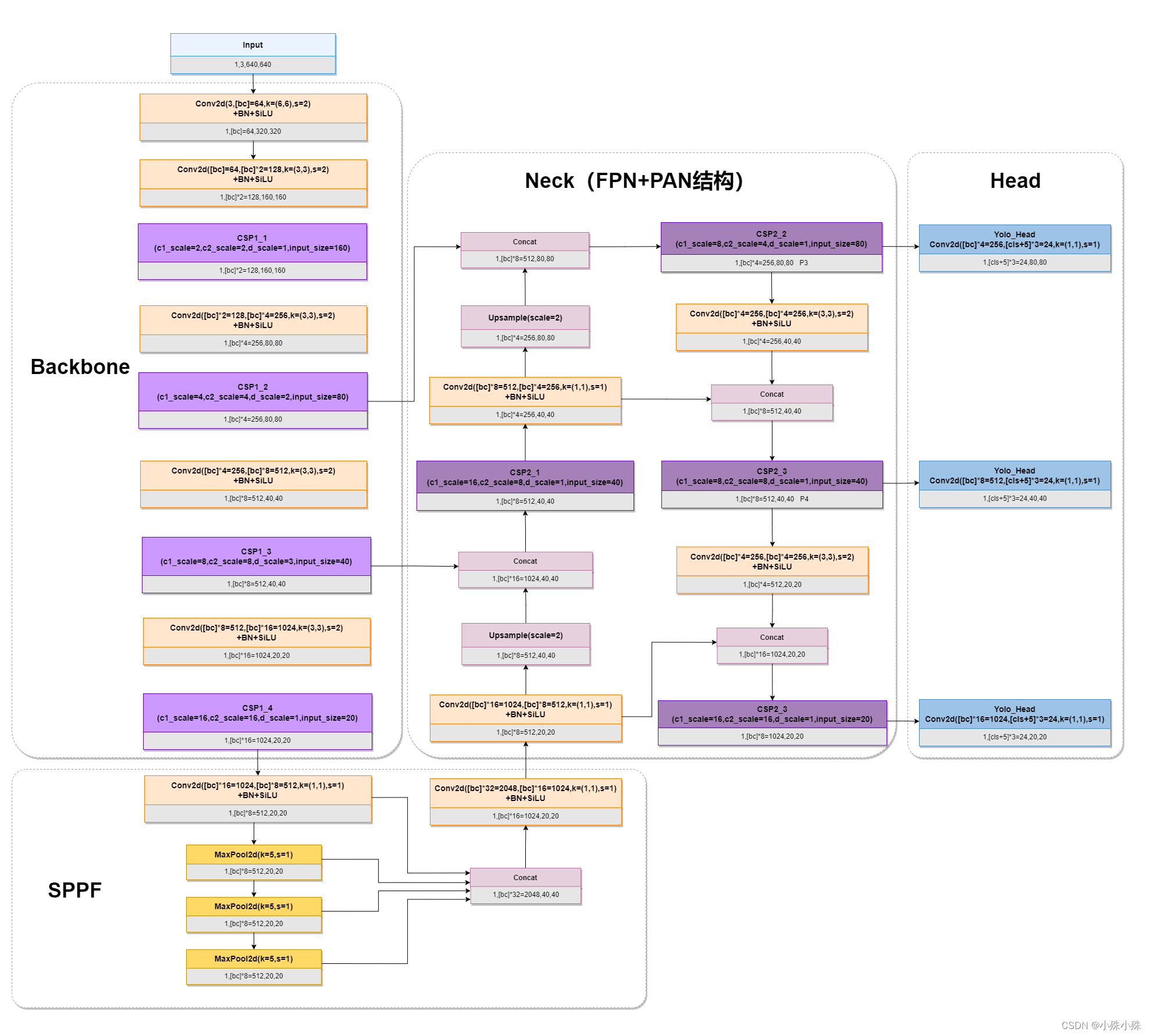
图1
2.Backbone(CSPDarknet)
Backbone我们使用4个CSP块的堆叠,分别提取后三个CSP块的输出作为下一步骤的输入。
Darknet是很经典的一个深层网络,在残差块中先使用1x1卷积增加通道数,再使用3x3同时stride=2的卷积做下采样,将通道数的改变和特征图大小的改变分开,这样做的好处是减少参数同时提升可解释性,同时使用stride=2的卷积做下采样减少计算开销。
CSPDarknet在Darknet的基础上增加了CSP结构。进一步减少计算量并且增强梯度的表现。主要做法是在输入block之前,将输入分为两个部分,其中一部分通过block进行计算,另一部分直接通过一个shortcut进行concat,当然两个分支都会先使用一个1x1的卷积层将通道数减半,这样能保证concat之后通道数不变。
YOLOv5的backbone使用了两种CSPDarknet,两种CSPDarknet差别并不大,只有一个残差的区别。
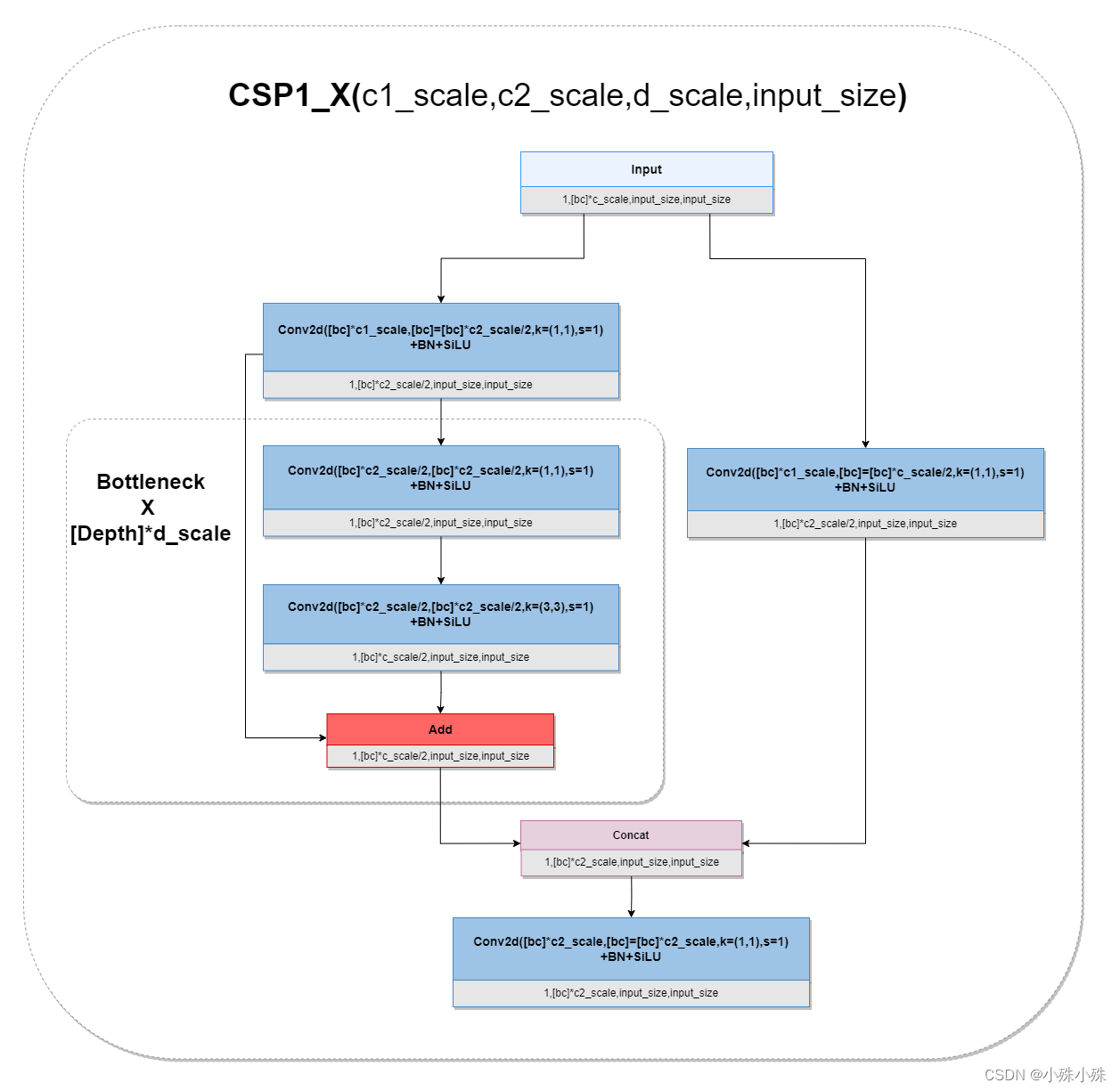
图2
如上图,CSP1_X应用于backbone主干网络部分,输入输出的特征图shape不变;backbone是较深的网络,增加残差结构可以增加层与层之间反向传播的梯度值,避免因为加深而带来的梯度消失,从而可以提取到更细粒度的特征并且不用担心网络退化。
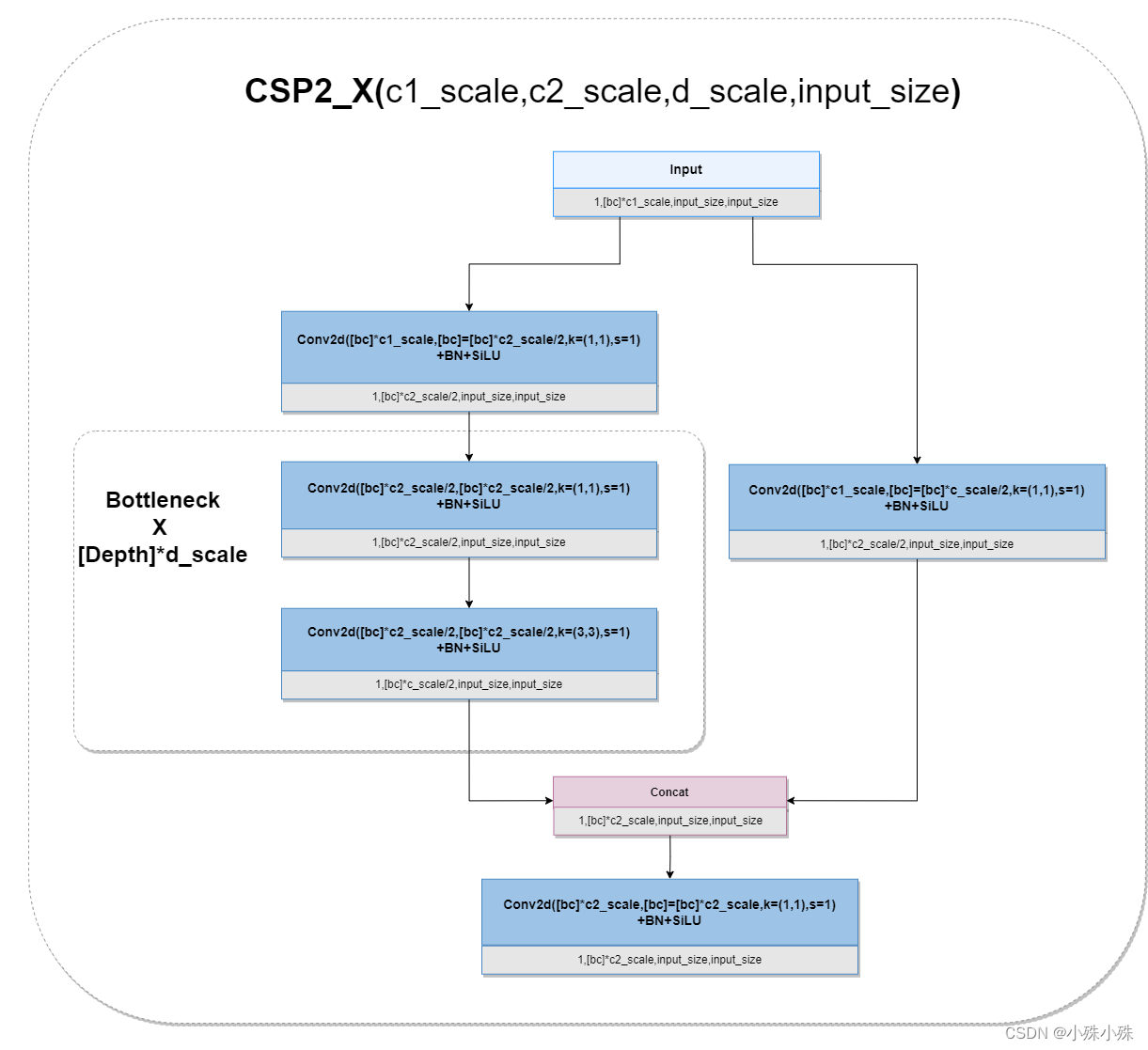
图3
CSP2_X主要应用在Neck部分,因为网络没那么深,去掉残差可以减少计算量。
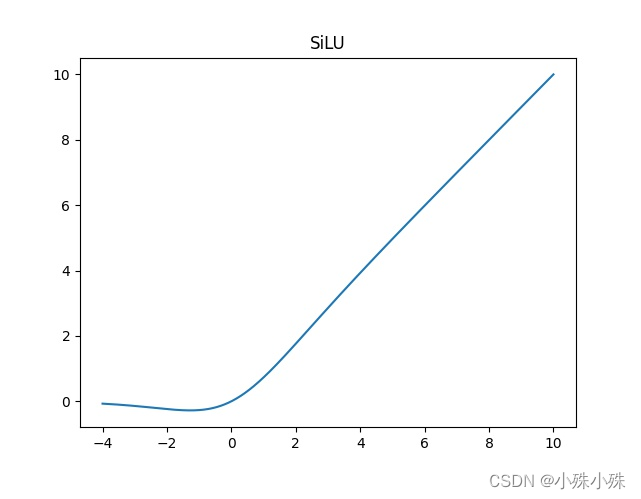
最原始的CSPDarknet激活函数是LeakyReLU,后期改为SiLU。SiLU是Sigmoid和LeakyReLU的改进版。SiLU具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于 LeakyReLU。可以看做是平滑的ReLU激活函数。
SiLU公式:
CSP块代码位置:dcmyolo/model/backbone/CSPdarknet.py
CSP块代码实现:
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat(
(
self.m(self.cv1(x)),
self.cv2(x)
)
, dim=1))3.SPPF(Spatial Pyramid Pooling - Fast)
YOLOv4和原始版本的YOLOv5使用了SPP结构,SPP通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。
这里我们使用SPPF代替SPP结构,SPPF将三个并联的MaxPool2d改成串联,然后concat,好处是比SPP快很多,SPPF已经在图1中画完整,结构如下:
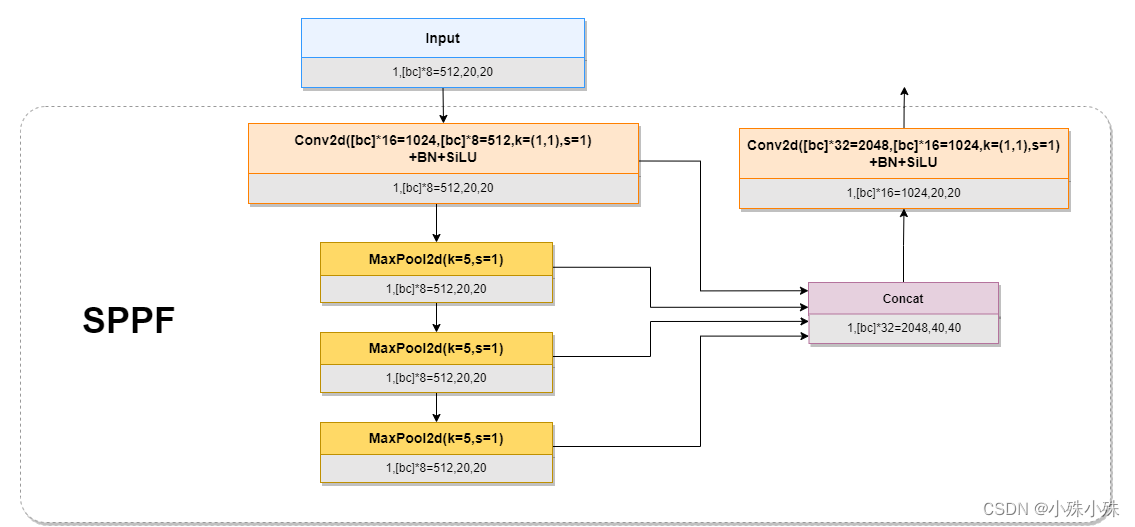
图4
代码位置:dcmyolo/model/backbone/CSPdarknet.py
代码实现:
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))4.Neck(FPN+PAN)
YOLOv5的Neck是一个FPN+PAN结构。
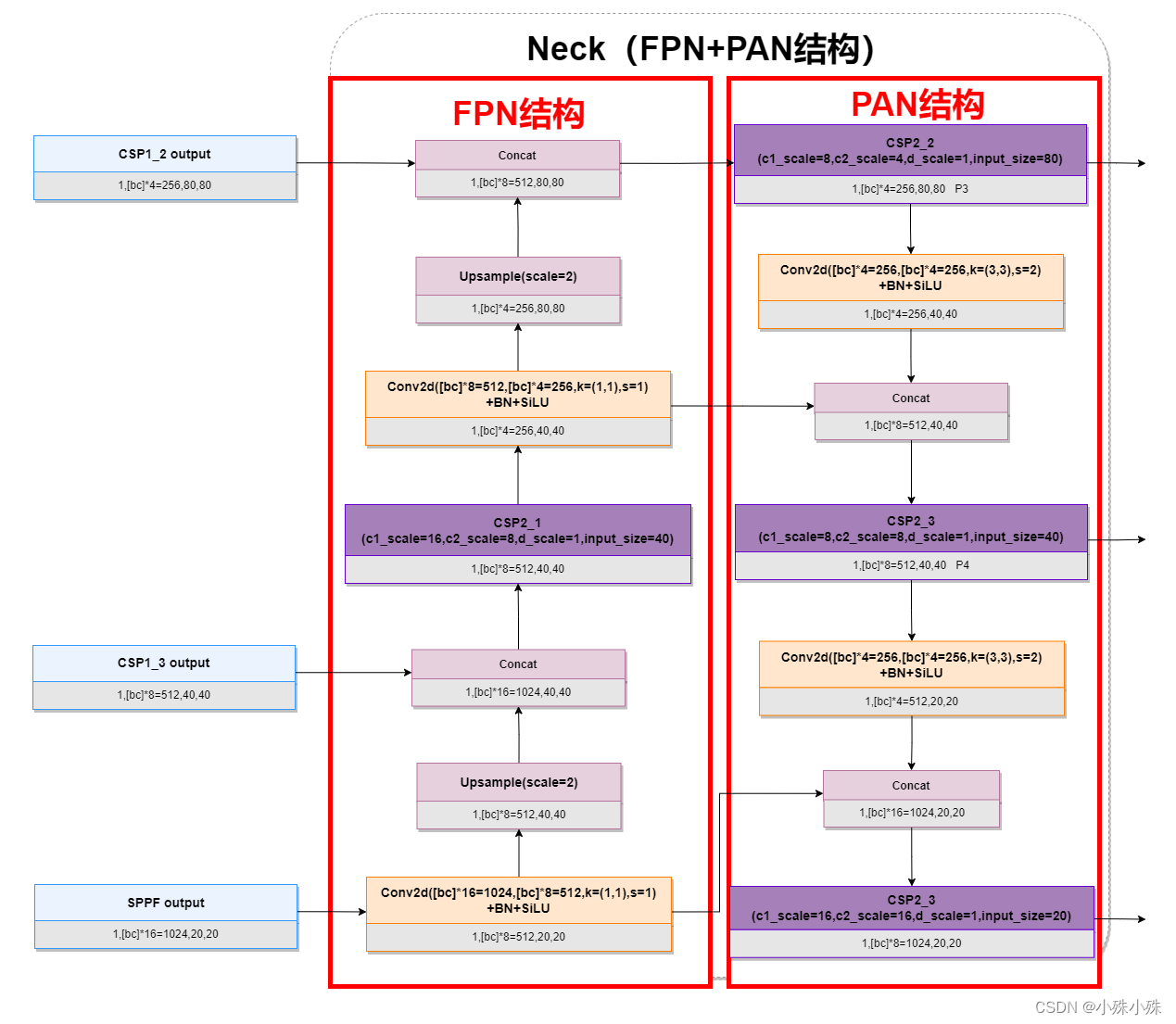
图5
FPN将不同尺度特征图上的特征进行融合,在融合之后得到的特征图上再进行预测。实现能在增加极小的计算量的情况下,处理好物体检测中的多尺度变化问题。
PAN结构是在FPN的基础上引入了 Bottom-up path augmentation 结构,不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。
FPN主要是通过融合高低层特征提升目标检测的效果,尤其可以提高小尺寸目标的检测效果。Bottom-up path augmentation结构可以充分利用网络浅特征进行分割,网络浅层特征信息对于目标检测非常重要,因为目标检测是像素级别的分类浅层特征多是边缘形状等特征。PAN 在 FPN 的基础上加了一个自底向上方向的增强,使得顶层 feature map 也可以享受到底层带来的丰富的位置信息,从而提升了大物体的检测效果。
FPN层自顶向下传达强语义特征,而PAN则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,这样的操作确实很皮。
Neck还有一个改进改进的是在每次concat之后增加了没有残差的CSP块:
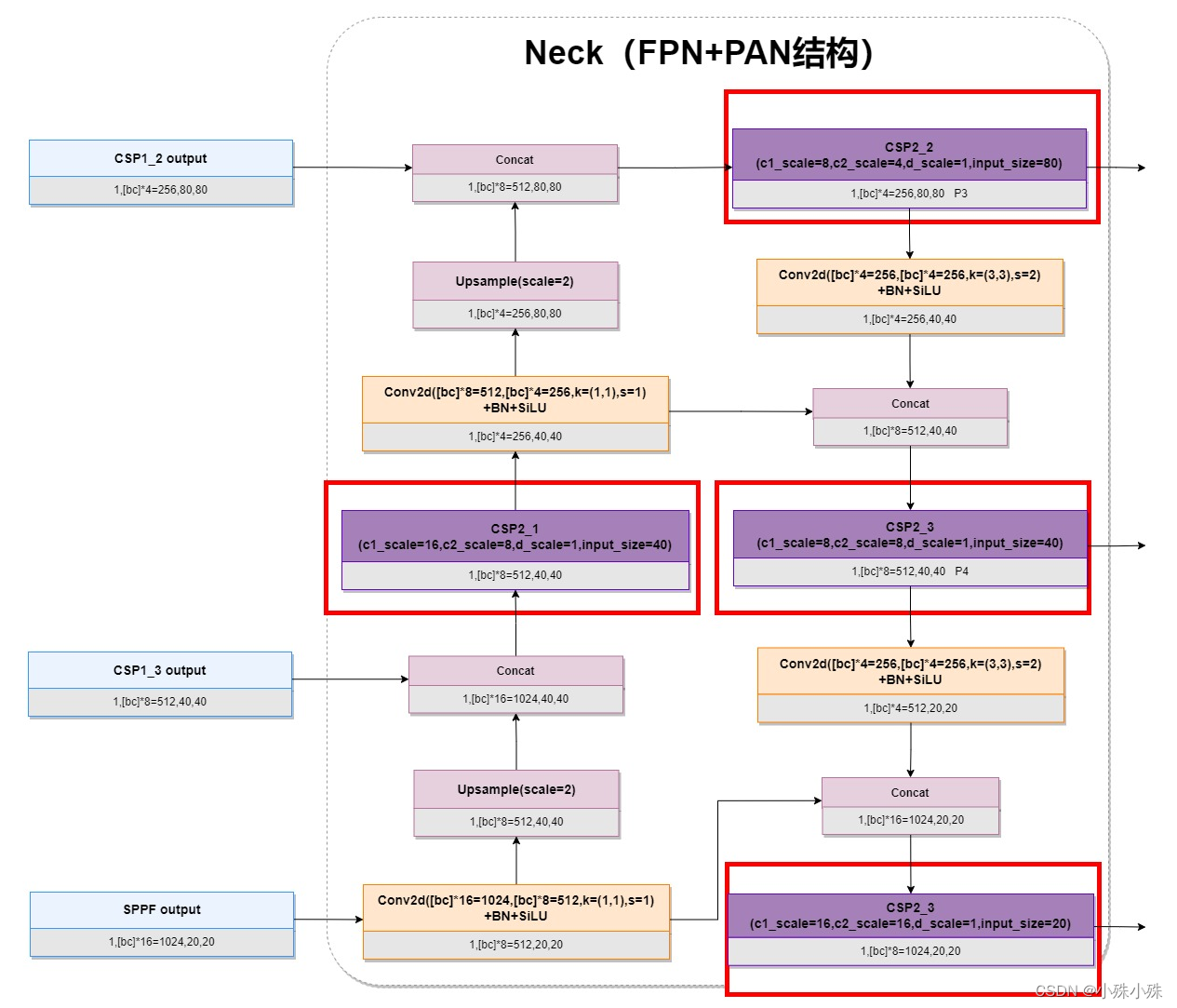
5.Head
Head没有太大变化,还是比较传统的YoloHead(用YOLOvX的话是耦合头:Couped Head)。
我们使用的是英雄联盟的数据集,有3个类别,在图1中三个Head从下往上输出分别为(24,20,20),(24,40,40),(24,80,80)。
其中20、40、80为固定值(input_size=640x640的情况下),用于不同尺度的anchor编解码。
24 = (4+1+3)*3,前4个参数用于判断每一个特征点的回归参数,分别对应着先验框中心坐标在xy方向的偏移和预测框高宽;第5个参数预测否包含物体;最后3个参数预测每个类别的概率;*3是因为9个预设anchors分3组,每组有3个先验框。
如果使用VOC数据集,有20个分类,Head输出为:(75,20,20),(75,40,40),(75,80,80)。
如果使用COCO数据集,有80个分类,Head输出为:(255,20,20),(255,40,40),(255,80,80)。
Neck+Head代码如下:
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, phi, anchors=None, input_shape=None, backbone_model_dir='', need_detect_box=False):
super(YoloBody, self).__init__()
depth_dict = {'n': 0.33, 's': 0.33, 'm': 0.67, 'l': 1.00, 'x': 1.33}
width_dict = {'n': 0.25, 's': 0.50, 'm': 0.75, 'l': 1.00, 'x': 1.25}
dep_mul, wid_mul = depth_dict[phi], width_dict[phi]
base_channels = int(wid_mul * 64) # 64
base_depth = max(round(dep_mul * 3), 1) # 3
#-----------------------------------------------#
# 输入图片是3, 640, 640
# 初始的基本通道是64
#-----------------------------------------------#
self.backbone = self._get_backbone(base_channels, base_depth, phi, backbone_model_dir)
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
self.conv_for_feat3 = Conv(base_channels * 16, base_channels * 8, 1, 1)
self.conv3_for_upsample1 = C3(base_channels * 16, base_channels * 8, base_depth, shortcut=False)
self.conv_for_feat2 = Conv(base_channels * 8, base_channels * 4, 1, 1)
self.conv3_for_upsample2 = C3(base_channels * 8, base_channels * 4, base_depth, shortcut=False)
self.down_sample1 = Conv(base_channels * 4, base_channels * 4, 3, 2)
self.conv3_for_downsample1 = C3(base_channels * 8, base_channels * 8, base_depth, shortcut=False)
self.down_sample2 = Conv(base_channels * 8, base_channels * 8, 3, 2)
self.conv3_for_downsample2 = C3(base_channels * 16, base_channels * 16, base_depth, shortcut=False)
# 256, 80, 80 => 3 * (5 + num_classes), 80, 80
self.yolo_head_P3 = nn.Conv2d(base_channels * 4, len(anchors_mask[2]) * (5 + num_classes), 1)
# 512, 40, 40 => 3 * (5 + num_classes), 40, 40
self.yolo_head_P4 = nn.Conv2d(base_channels * 8, len(anchors_mask[1]) * (5 + num_classes), 1)
# 1024, 20, 20, => 3 * (5 + num_classes), 20, 20
self.yolo_head_P5 = nn.Conv2d(base_channels * 16, len(anchors_mask[0]) * (5 + num_classes), 1)
self.need_detect_box = need_detect_box
if need_detect_box:
self.detectBox = DetectBox(anchors, num_classes, input_shape)
def _get_backbone(self, channels, depth, phi, backbone_model_dir):
"""
初始化backbone
Returns
-------
"""
backbone_model_path = os.path.join(backbone_model_dir, 'cspdarknet_'+phi+'_backbone.pth')
return CSPDarknet(channels, depth, backbone_model_path)
def forward(self, x):
# backbone
feat1, feat2, feat3 = self.backbone(x)
# 1024, 20, 20 -> 512, 20, 20
P5 = self.conv_for_feat3(feat3)
# 512, 20, 20 -> 512, 40, 40
P5_upsample = self.upsample(P5)
# 512, 40, 40 -> 1024, 40, 40
P4 = torch.cat([P5_upsample, feat2], 1)
# 1024, 40, 40 -> 512, 40, 40
P4 = self.conv3_for_upsample1(P4)
# 512, 40, 40 -> 256, 40, 40
P4 = self.conv_for_feat2(P4)
# 256, 40, 40 -> 256, 80, 80
P4_upsample = self.upsample(P4)
# 256, 80, 80 concat 256, 80, 80 -> 512, 80, 80
P3 = torch.cat([P4_upsample, feat1], 1)
# 512, 80, 80 -> 256, 80, 80
P3 = self.conv3_for_upsample2(P3)
# 256, 80, 80 -> 256, 40, 40
P3_downsample = self.down_sample1(P3)
# 256, 40, 40 concat 256, 40, 40 -> 512, 40, 40
P4 = torch.cat([P3_downsample, P4], 1)
# 512, 40, 40 -> 512, 40, 40
P4 = self.conv3_for_downsample1(P4)
# 512, 40, 40 -> 512, 20, 20
P4_downsample = self.down_sample2(P4)
# 512, 20, 20 cat 512, 20, 20 -> 1024, 20, 20
P5 = torch.cat([P4_downsample, P5], 1)
# 1024, 20, 20 -> 1024, 20, 20
P5 = self.conv3_for_downsample2(P5)
#---------------------------------------------------#
# 第三个特征层
# y3=(batch_size,24,80,80)
#---------------------------------------------------#
out2 = self.yolo_head_P3(P3)
#---------------------------------------------------#
# 第二个特征层
# y2=(batch_size,24,40,40)
#---------------------------------------------------#
out1 = self.yolo_head_P4(P4)
#---------------------------------------------------#
# 第一个特征层
# y1=(batch_size,24,20,20)
#---------------------------------------------------#
out0 = self.yolo_head_P5(P5)
if self.need_detect_box:
return self.detectBox([out0, out1, out2])
return out0, out1, out2三、anchor编解码
YOLOv5的anchor有9个,根据数据集会有不同,我们以COCO的anchor为例:
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326anchor分成3组,每组3对,每对表示anchor的宽高。3组分别对应模型的输出,分别是:
(1,24,80,80)对应第一组10,13, 16,30, 33,23
(1,24,40,40)对应第二组30,61, 62,45, 59,119
(1,24,20,20)对应第三组116,90, 156,198, 373,326
可以看到输出的尺度越小,对应的anchor越大,因为输出可以看做将图片平均分成了80x80、40x40、20x20,尺度划分的越细,越有利于预测小物体,划分的越组越有利于预测大物体,所以小尺度对应大anchor是有道理的。
下面我们以20x20的尺度为例,进行介绍。图像被划分成20x20,意味着stride=640/20=32。
1.anchor编码
编码的功能是在训练阶段,将gt的左上右下坐标表示方式与anchor结合转换成与模型输出一样的格式,方便对预测值进行比较计算损失。
步骤如下:
(1)将gt的坐标除以图片的宽高进行归一化;将box左上右下的表示方式转换成xywh:
#---------------------------------------------------#
# 对真实框进行归一化,调整到0-1之间
#---------------------------------------------------#
box[:, [0, 2]] = box[:, [0, 2]] / self.input_shape[1]
box[:, [1, 3]] = box[:, [1, 3]] / self.input_shape[0]
#---------------------------------------------------#
# 序号为0、1的部分,为真实框的中心
# 序号为2、3的部分,为真实框的宽高
# 序号为4的部分,为真实框的种类
#---------------------------------------------------#
box[:, 2:4] = box[:, 2:4] - box[:, 0:2]
box[:, 0:2] = box[:, 0:2] + box[:, 2:4] / 2(2)多正样本匹配,判断gt落在哪个尺度的格中,就由哪个格负责预测,这里每个gt选择三个框,如下图:
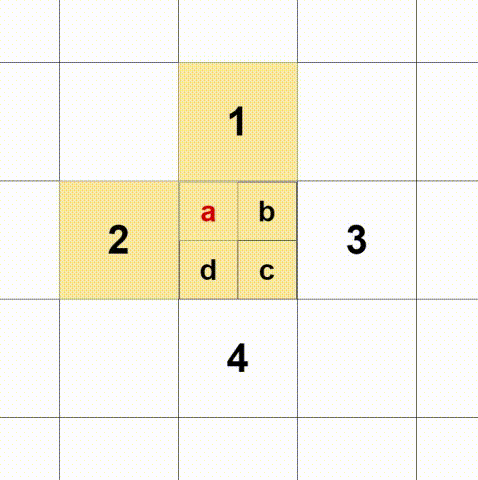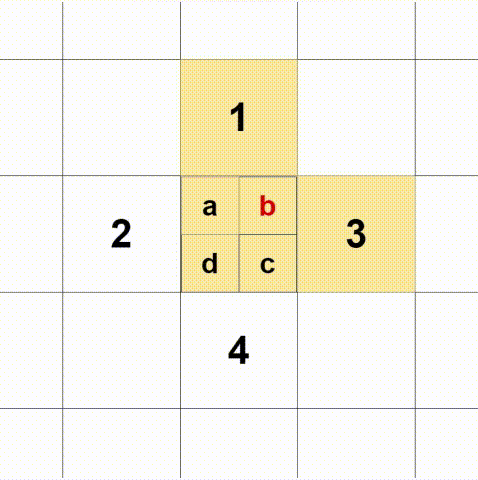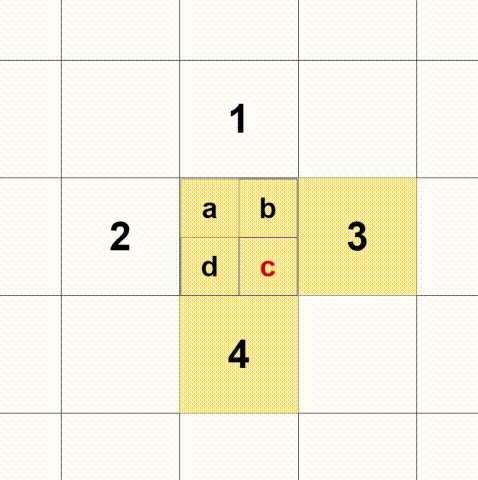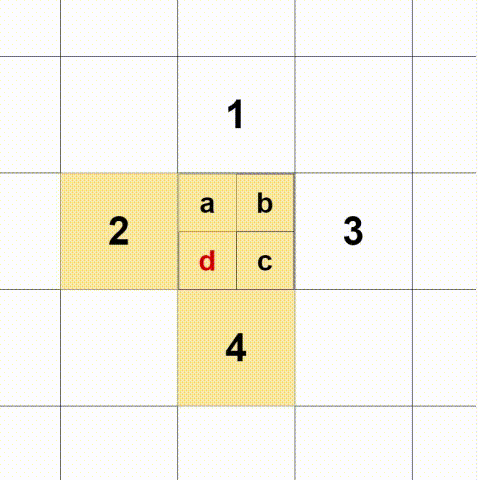
如果gt的中点落在a,除了选择a所在的格还选择1、2,三个格同时参与预测。同理b+1+3、c+3+4、d+2+4。
def get_near_points(self, x, y, i, j):
sub_x = x - i
sub_y = y - j
if sub_x > 0.5 and sub_y > 0.5:
return [[0, 0], [1, 0], [0, 1]]
elif sub_x < 0.5 and sub_y > 0.5:
return [[0, 0], [-1, 0], [0, 1]]
elif sub_x < 0.5 and sub_y < 0.5:
return [[0, 0], [-1, 0], [0, -1]]
else:
return [[0, 0], [1, 0], [0, -1]]找到中心后,就要计算中心的距离的偏移,归一化的中心点乘以20即可。
#-------------------------------------------------------#
# 计算出正样本在特征层上的中心点
#-------------------------------------------------------#
batch_target[:, [0,2]] = targets[:, [0,2]] * in_w
batch_target[:, [1,3]] = targets[:, [1,3]] * in_h(3)中点找到之后,接下来计算宽高,这就用到anchor,这里要算的事gt宽高相对于anchor的比值。
anchor除以stride得到anchor在当前尺度的表示。
计算wh与anchor的比值,去掉比值超过4的,至于为什么是4,取决于解码中的公式,下面我们会提到。
# wh : num_true_box, 2
# np.expand_dims(wh, 1) : num_true_box, 1, 2
# anchors : 9, 2
# np.expand_dims(anchors, 0) : 1, 9, 2
#
# ratios_of_gt_anchors代表每一个真实框和每一个先验框的宽高的比值
# ratios_of_gt_anchors : num_true_box, 9, 2
# ratios_of_anchors_gt代表每一个先验框和每一个真实框的宽高的比值
# ratios_of_anchors_gt : num_true_box, 9, 2
#
# ratios : num_true_box, 9, 4
# max_ratios代表每一个真实框和每一个先验框的宽高的比值的最大值
# max_ratios : num_true_box, 9
#-------------------------------------------------------#
ratios_of_gt_anchors = np.expand_dims(batch_target[:, 2:4], 1) / np.expand_dims(anchors, 0)
ratios_of_anchors_gt = np.expand_dims(anchors, 0) / np.expand_dims(batch_target[:, 2:4], 1)
ratios = np.concatenate([ratios_of_gt_anchors, ratios_of_anchors_gt], axis = -1)
max_ratios = np.max(ratios, axis = -1)
for t, ratio in enumerate(max_ratios):
# -------------------------------------------------------#
# 和gt相比 去掉宽高相差太大的anchors
# 这里阈值=4
# 因为tw = (sigmoid(gtw) * 2) ** 2 th = (sigmoid(gth) * 2) ** 2
# tw和th的取值是(0, 4)
# -------------------------------------------------------#
over_threshold = ratio < self.threshold
over_threshold[np.argmin(ratio)] = True
for k, mask in enumerate(self.anchors_mask[l]):
if not over_threshold[mask]:
continue
#----------------------------------------#
# 获得真实框属于哪个网格点
# x 1.25 => 1
# y 3.75 => 3
#----------------------------------------#
i = int(np.floor(batch_target[t, 0]))
j = int(np.floor(batch_target[t, 1]))
offsets = self.get_near_points(batch_target[t, 0], batch_target[t, 1], i, j)
for offset in offsets:
local_i = i + offset[0]
local_j = j + offset[1]
if local_i >= in_w or local_i < 0 or local_j >= in_h or local_j < 0:
continue
if box_best_ratio[l][k, local_j, local_i] != 0:
if box_best_ratio[l][k, local_j, local_i] > ratio[mask]:
y_true[l][k, local_j, local_i, :] = 0
else:
continue
#----------------------------------------#
# 取出真实框的种类
#----------------------------------------#
c = int(batch_target[t, 4])
#----------------------------------------#
# tx、ty代表中心调整参数的真实值
#----------------------------------------#
y_true[l][k, local_j, local_i, 0] = batch_target[t, 0]
y_true[l][k, local_j, local_i, 1] = batch_target[t, 1]
y_true[l][k, local_j, local_i, 2] = batch_target[t, 2]
y_true[l][k, local_j, local_i, 3] = batch_target[t, 3]
y_true[l][k, local_j, local_i, 4] = 1
y_true[l][k, local_j, local_i, c + 5] = 1
#----------------------------------------#
# 获得当前先验框最好的比例
#----------------------------------------#
box_best_ratio[l][k, local_j, local_i] = ratio[mask]经过上面三步,gt的原始坐标就转换成了预测坐标信息,shape为(1,3,20,20,4)接下来看解码。
2.anchor解码
解码针对模型输出进行操作,将模型的输出变成xywh形式
中点偏移的范围由原来的(0, 1)调整到了( −0.5, 1.5),公式如下:
目标宽高的计算公式调整为,其中范围(0,1)、
和
范围(0,1)所以
和
范围(0,4):
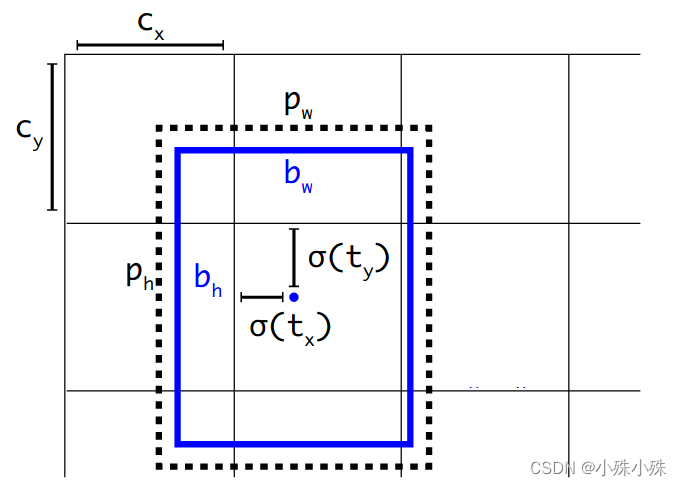
参数解释:
:预测的坐标信息
: 最终预测坐标信息
:表示sigmoid,将坐标归一化到0~1
: 中心点所在的网格的左上角坐标
: anchor框的大小
经过解码的输出shape为(1,3,20,20,4),可以和上面的编码结果计算损失了。
四、损失函数
YoloV5的损失函数分为三个部分:
Location loss:定位损失,采用GIoU loss(CIoU的具体介绍可以参考https://blog.csdn.net/xian0710830114/article/details/128177705),只计算正样本的定位损失,利用前4个值计算损失。
Objectness loss:obj置信度损失,采用BCE loss,计算的是否有物体的obj损失。利用第5个值计算损失。
Classes loss:分类损失,采用BCE loss,只计算正样本的分类损失。利用第5个值后面的所有值计算损失。
总的损失函数是一个Multi-task Loss:
三段损失的代码实现:
def box_giou(self, b1, b2):
"""
输入为:
----------
b1: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
b2: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
返回为:
-------
giou: tensor, shape=(batch, feat_w, feat_h, anchor_num, 1)
"""
# ----------------------------------------------------#
# 求出预测框左上角右下角
# ----------------------------------------------------#
print("max:", torch.max(b1), torch.max(b2))
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh / 2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
# ----------------------------------------------------#
# 求出真实框左上角右下角
# ----------------------------------------------------#
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh / 2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
# ----------------------------------------------------#
# 求真实框和预测框所有的iou
# ----------------------------------------------------#
intersect_mins = torch.max(b1_mins, b2_mins)
intersect_maxes = torch.min(b1_maxes, b2_maxes)
intersect_wh = torch.max(intersect_maxes - intersect_mins, torch.zeros_like(intersect_maxes))
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
union_area = b1_area + b2_area - intersect_area
iou = intersect_area / union_area
# ----------------------------------------------------#
# 找到包裹两个框的最小框的左上角和右下角
# ----------------------------------------------------#
enclose_mins = torch.min(b1_mins, b2_mins)
enclose_maxes = torch.max(b1_maxes, b2_maxes)
enclose_wh = torch.max(enclose_maxes - enclose_mins, torch.zeros_like(intersect_maxes))
# ----------------------------------------------------#
# 计算对角线距离
# ----------------------------------------------------#
enclose_area = enclose_wh[..., 0] * enclose_wh[..., 1]
giou = iou - (enclose_area - union_area) / enclose_area
return giou
def BCELoss(self, pred, target):
epsilon = 1e-7
pred = self.clip_by_tensor(pred, epsilon, 1.0 - epsilon)
output = - target * torch.log(pred) - (1.0 - target) * torch.log(1.0 - pred)
return output
def MSELoss(self, pred, target):
return torch.pow(pred - target, 2)五、总结
YOLOv5在算法上有创新,但不多,工作中使用还是挺方便的,主要创新如下:
(1) 通过灵活的配置参数,可以得到不同复杂度的模型,Yolov5n、Yolov5s、Yolov5m、Yolov5l、Yolov5x。
(2) Mosaic数据增强、Mosaic利用了四张图片进行拼接实现数据中增强,优点是丰富检测物体的背景,且在计算时一下子会计算四张图片的数据。
(3) 使用SiLU激活函数。
(4) 多正样本匹配:在之前的Yolo系列里面,在训练时每一个真实框对应一个正样本,即在训练时,每一个真实框仅由一个先验框负责预测。YoloV5中为了加快模型的训练效率,增加了正样本的数量,在训练时,每一个真实框可以由多个先验框负责预测。
YOLOv5还有很多很多细节,比如数据增强、NMS等等,这篇文章只说了最重要的,其它细节会慢慢说。