< Linux> Linux 项目自动化构建工具—make/makefile的使用

文章目录
一、make/makefile的背景
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力。make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
总结:make是一条命令,makefile是一个文件,二者搭配使用,实现项目自动化构建。
二、如何编写 makefile
1.依赖关系和依赖方法
makefire存在的意义,是为了构建项目的,当我们创建好了makefile文件,需要在里面添加依赖关系和依赖方法,下面详谈:
- 依赖关系好比如你向父母借钱,开口第一句你就说我是你们的儿子,这就表明了依赖关系,因为依赖关系的存在(因为我是你儿子),所以你要给我打钱,而这就是依赖方法。此时就能达到你要钱的目的。
依赖关系和依赖方法是对应的,不能颠倒。比如我现在有一个源文件mycode.c,而我的目的是为了形成可执行程序,基于我的目的,我就有了依赖关系和依赖方法。
-
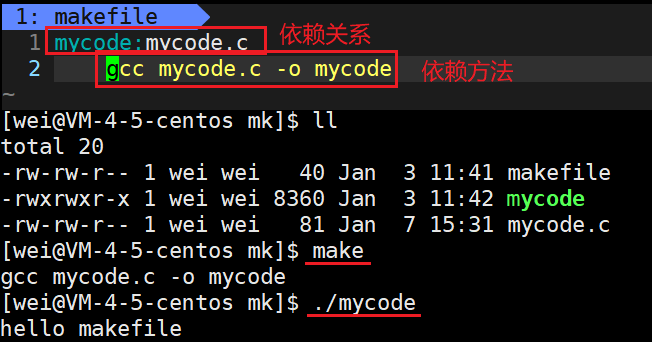
依赖关系:形成的可执行程序(mycode)依赖于源文件mycode.c
-
依赖方法:使用gcc编译:gcc mycode.c -o mycode
-
下面在我们创建好的Makefile文件里演示添需要依赖关系和依赖方法。比如一要做一件事,找你爸要钱,你打电话给你爸,说:“爸,我是你儿子”。表明了依赖关系(我是你儿子)和依赖方法(你得给我打钱)。
我们结合代码分析一下:
创建mycode.c利用vim编写一个简单的程序,再创建文件makefile/Makefile 编写依赖关系和依赖方法,最后通过make完成编译,生成mycode。
makefile内部包含:依赖关系和依赖方法
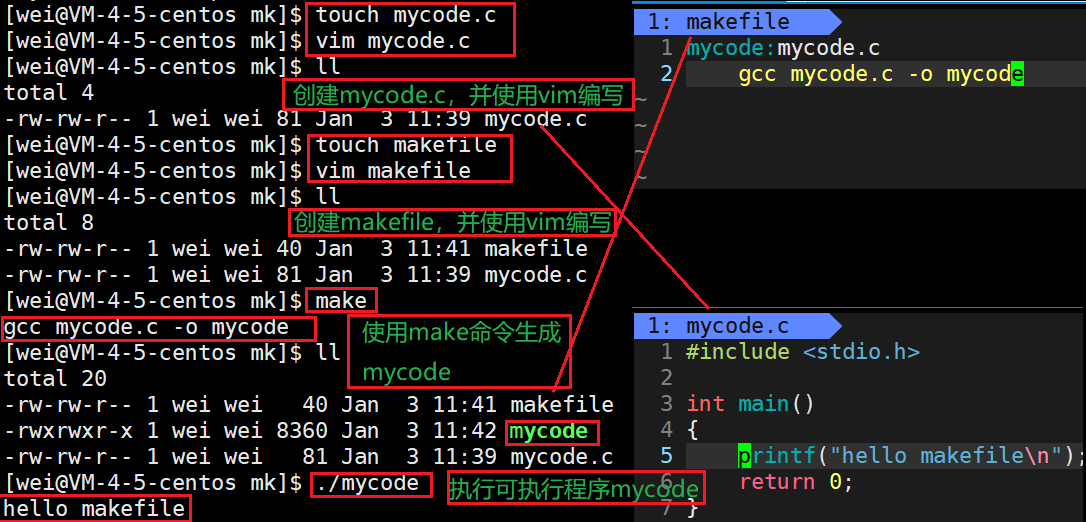
2.makefile的使用
makefile的作用,是为了构建项目。上述makefile中,mycode的形成依赖于mycode.c,所以需要对mycode.c进行编译形成mycode。
我们现在实现一个简单的makefile。第一步,建立依赖关系,谁依赖于谁,比如mycode依赖于mycode.c。mycode.c是我们自身创建出来的,而mycode是通过其编译出来的。第二步,建立依赖方法,另起一行,必须以tab键开头(这很重要,不能是4个空格),然后编写依赖方法 gcc mycode.c -o mycode。
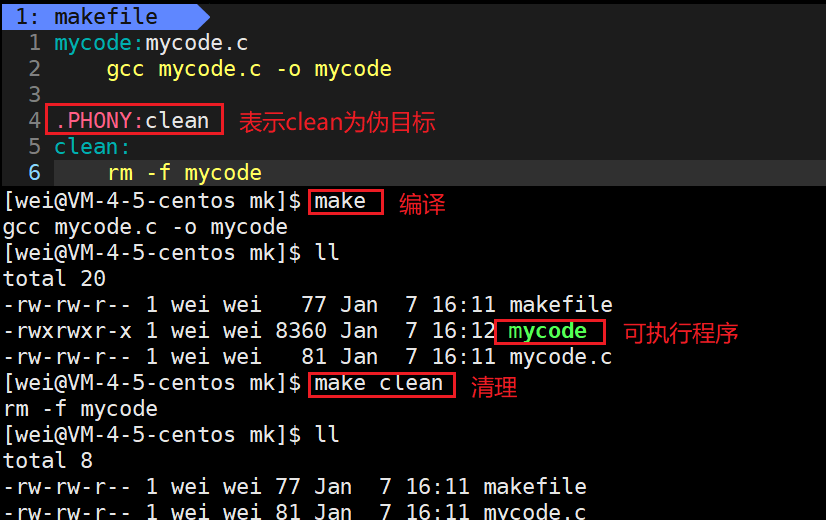
3.clean的使用
既然我们能构建项目,也就能删除项目。在我们每次重新生成可执行程序前,都应该将上一次生成可执行程序时生成的一系列文件进行清理,但是如果我们每次都手动执行一系列指令进行清理工作的话,未免有些麻烦,因为每次清理时执行的都是相同的清理指令,这时我们可以将项目清理的指令也加入到Makefile文件当中。这里我们也可以使用clean清理文件/临时数据。这里clean没有依赖关系,只有依赖方法。
特性总结:
-
工程是需要被清理的。
-
像clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过,我们可以显示要make执行。即命令——“make clean”,以此来清除所有的目标文件,以便重编译。
-
但是一般我们这种clean的目标文件,我们将它设置为伪目标,用 .PHONY 修饰,伪目标的特性是:总是被执行的(无论目标文件是否新旧,直接忽略了对比时间,照样直接执行依赖关系)。
-
makefile根据对比源文件和可执行程序的最近修改时间,评估要不要重新生成,以此识别我的exe / bin是新的还是旧的。
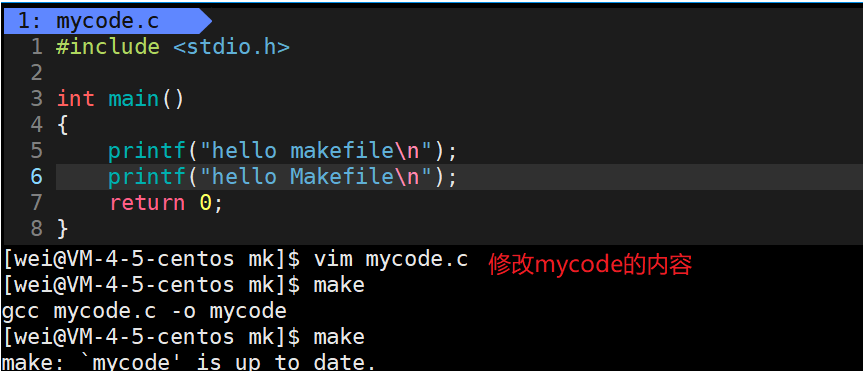
这里有一个问题,我们知道代码编译形成可执行程序后,就不需要再次编译去覆盖旧程序,因为本质他们两个是一样的。所以下图中我们一直make,但是没有用。因为代码没有修改,不需要要再次编译,如果有修改,就可以再次make。
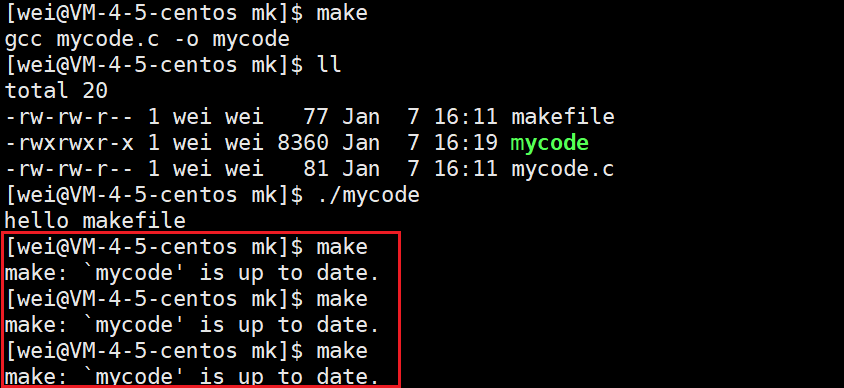
下面我们修改一下mycode.c的内容,观察是否能够再次make。结果是可以的。
4.多文件编译
多文件编译
当你的工程当中有多个源文件的时候,应该如何进行编译生成可执行程序呢?

首先,我们可以直接使用gcc指令对多个源文件进行编译,进而生成可执行程序。
但进行多文件编译的时候一般不使用源文件直接生成可执行程序,而是先用每个源文件各自生成自己的二进制文件,然后再将这些二进制文件通过链接生成可执行程序。
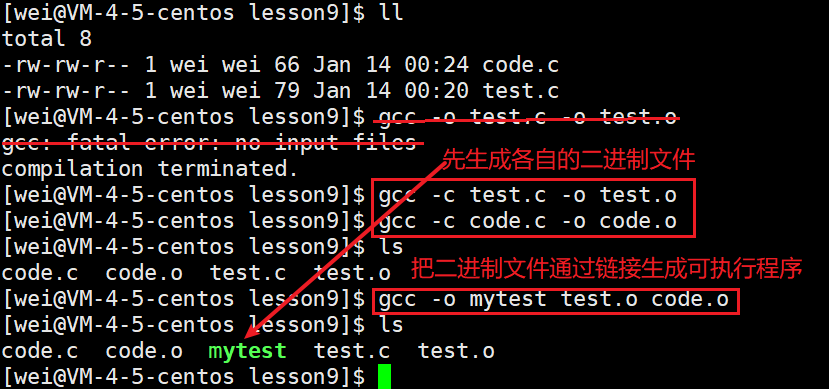
原因:
-
若是直接使用源文件生成可执行程序,那么其中一个源文件进行了修改,再生成可执行程序的时候就需要将所以的源文件重新进行编译链接。
-
而若是先用每个源文件各自生成自己的二进制文件,那么其中一个源文件进行了修改,就只需重新编译生成该源文件的二进制文件,然后再将这些二进制文件通过链接生成可执行程序即可。
注意:
-
编译链接的时候不需要加上头文件,因为编译器通过源文件的内容可以知道所需的头文件名字,而通过头文件的包含方式(“尖括号”包含和“双引号”包含),编译器可以知道应该从何处去寻找所需头文件。
-
但是随着源文件个数的增加,我们每次重新生成可执行程序时,所需输入的gcc指令的长度与个数也会随之增加。这时我们就需要使用make和Makefile了,这将大大减少我们的工作量。
5.伪目标 .PHONY
我们在上述清除文件/数据中有一个.PHONY:,它表示被该关键字修饰的对象是一个伪目标。但是如果我们一直make clean会发生奇怪的事情,如下:
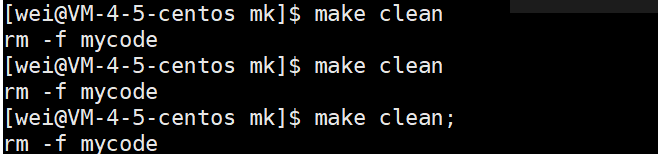
我们发现,make clean可以一直执行,而不受约束。这就是伪目标的作用。伪目标表示该目标总是被执行的
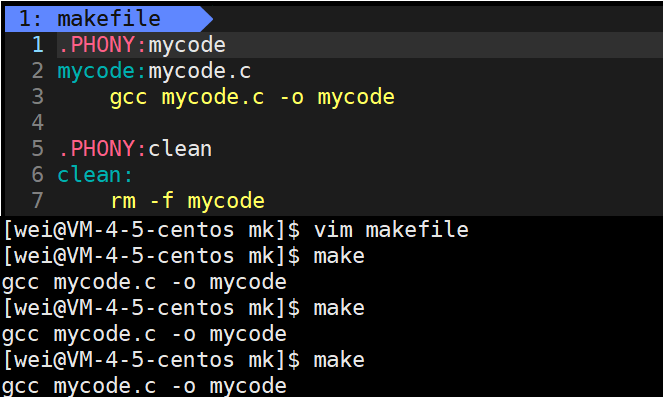
这里还有一个小问题需要注意一下,make 默认从上到下执行,第一个被找到的直接用make执行,总是调用第一个,后面不再执行,而调用其他的需要手动指明。如果需要同时调用,需要用;分隔。
6.三个时间
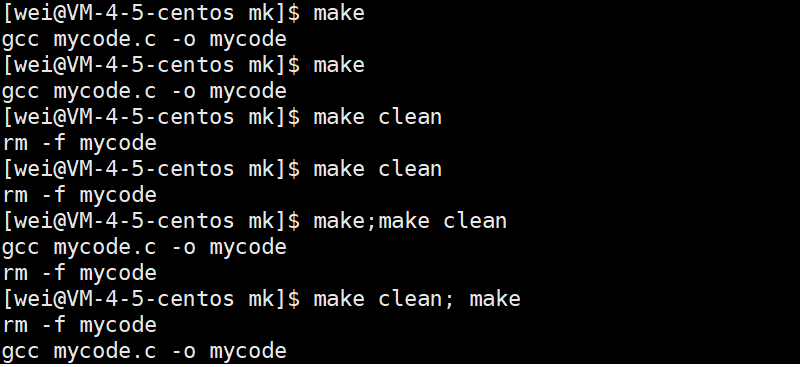
这里我们再插入一个问题,gcc是如何得知我不需要再编译了呢(在没有加上伪目标的情况下,直接显示…is up to data.)(比较时间)
-
Access:文件内容被访问的时间
-
Modify:文件内容被修改的时间
-
Change:文件属性被修改的时间
这里有一个问题,我们在文件操作的时候,是修改文件次数多,还是访问文件次数多?
那一定是访问文件次数多,因为你修改文件一定会访问文件,但是你访问文件不一定会修改文件。所以access时间被更改的频率太多了。
你只要访问文件,它的access时间就会被更改,access时间等于属性,你大量访问文件,它就会不断更改属性,它也会不断的进行IO,这对操作系统来说是一种负担。因为一般人关注的是 Modify 和 Change 的时间,不太关注 Access 的时间。所以操作系统的新内核对其进行修改,根据一段时间内访问频率去更新。
在第一次编译的时候一定先有源文件,再有可执行程序,所以第一次的mycode.c的modify时间要比mycode的modify时间要更早,如果后来mycode没修改,而把mycode.c修改了,导致mycode.c的时间更新。所以识别要不要重新编译就看mycode.c时间是不是比mycode的时间更新,如果更新,就重新编译。
注意:用.PHONY修饰的就不需要根据时间做对比,因为它每次都需要编译。并且 touch 已存在文件名 表示的是改变该文件的创建时间。
7.推导过程
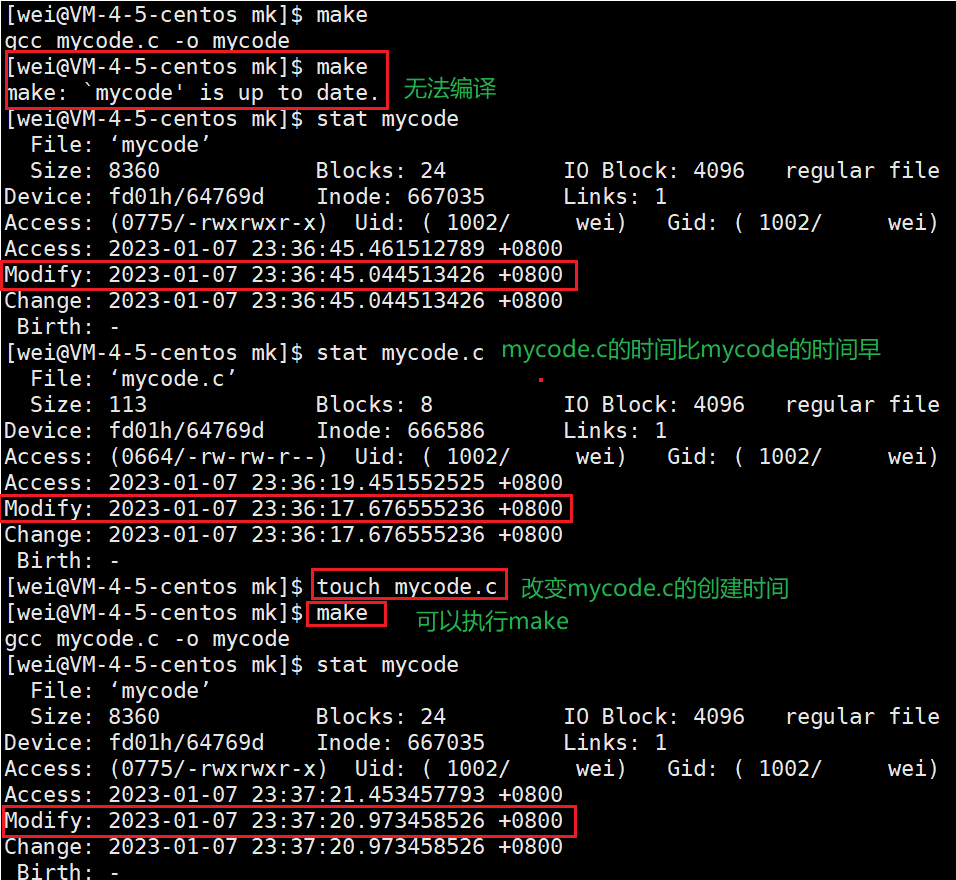
我先前的演示编译的四大过程,每一步都要进行gcc太过于麻烦,我们直接在Makefile文件里面利用依赖关系和依赖方法来解决:
- 上面的文件 mycode,它依赖 mycode.o
- mycode.o,它依赖 mycode.s
- mycode.s,它依赖 mycode.i
- mycode.i,它依赖 mycode.c
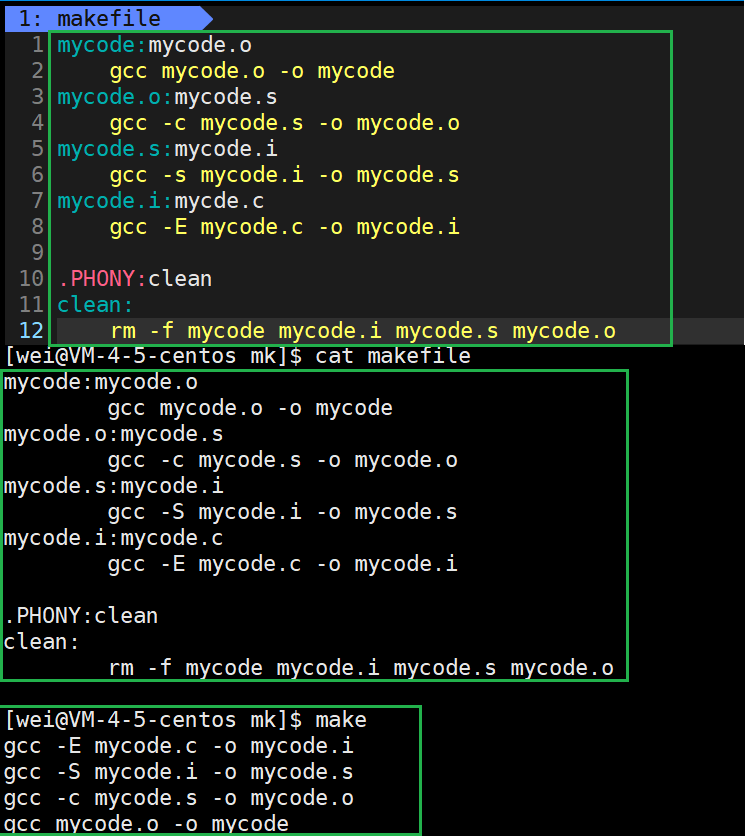
我们可以看出,make执行的时候预处理操作是逆着来的。在make推导的时候会根据依赖关系推导,从上到下,当依赖文件列表不存在就会继续根据依赖文件列表所对应的项而继续向下寻找。比如mycode依赖于mycode.o,这时并未发现mycode.o,继续向下寻找,发现mycode.o依赖于mycode.s以此类推。不过平时一步到位即可。
8.make的工作原理
make是如何工作的,在默认的方式下,也就是我们只输入make命令。那么,
-
make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
-
如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“hello”这个文件,并把这个文件作为最终的目标文件。
-
如果hello文件不存在,或是hello所依赖的后面的hello.o文件的文件修改时间要比hello这个文件新(可以用 touch 测试),那么,他就会执行后面所定义的命令来生成hello这个文件。
-
如果hello所依赖的hello.o文件不存在,那么make会在当前文件中找目标为hello.o文件的依赖性,如果找到则再根据那一个规则生成hello.o文件。(这有点像一个堆栈的过程)
-
当然,你的C文件和H文件是存在的,于是make会生成 hello.o 文件,然后再用 hello.o 文件声明make的终极任务,也就是执行文件hello了。
-
这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
-
在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
-
make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么对不起,我就不工作了。