目录
22. 读取CSV、TSV、TXT中的数据
22.1 知识点
CSV、TSV、TXT 都叫纯文本文件,除了文本,没有任何的修饰。
csv value又叫由逗号分隔看的值,用记事本打开如下所示:都默认以逗号分开
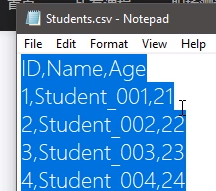
TSV
是数据以TAB分开
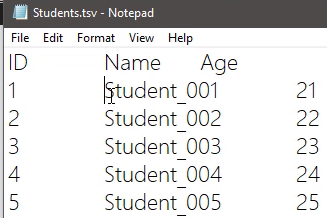
如果既不是用逗号,又不是用TAB分开的数据,建议用 txt 保存。
22.2 Excel操作–导入数据
22.5.1 导入CSV中的数据
从文本文件中导入数据 from text:
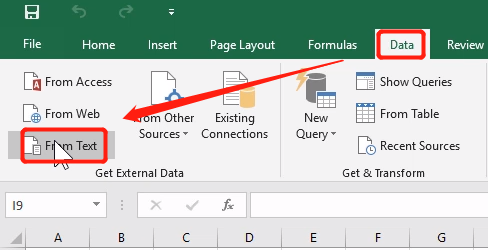







22.5.2 导入TXT 中的数据



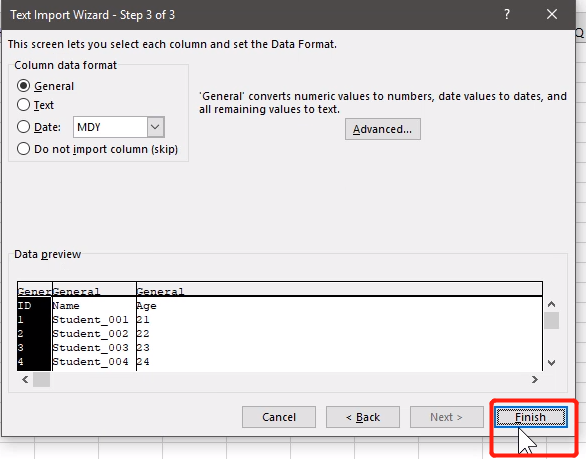

导入成功:

22.5.3 导入TSV 中的数据


导入成功:

22.3 Python–导入数据
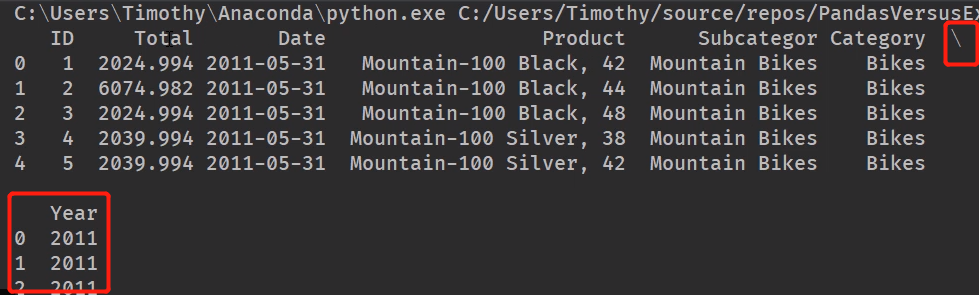
读取 CSV、TXT、TSV,都是用 pd.read_csv()方法。
读csv
import pandas as pd
students1 = pd.read_csv('C:/Temp/Data/Students.csv')
print(students1)
输出:索引是自动生成的

指定 Index
import pandas as pd
students1 = pd.read_csv('C:/Temp/Data/Students.csv', index_col='ID')
print(students1)

读取 TSV,ep='\t’表示用制表符(TAB)进行分割
students2 = pd.read_csv('C:/Temp/Data/Students.tsv', sep='\t', index_col='ID') # sep='\t'表示用制表符进行分割
print(students2)
读取 TXT,ep=‘|’,本例所用数据使用 | 进行分割的,
students2 = pd.read_csv('C:/Temp/Data/Students.txt', sep='|', index_col='ID')
print(students2)

22.3 Python–导入数据
22. 分类&汇总 【透视表、分组、聚合】
22.1 pandas实现数据透视表
一家公司的销售数据
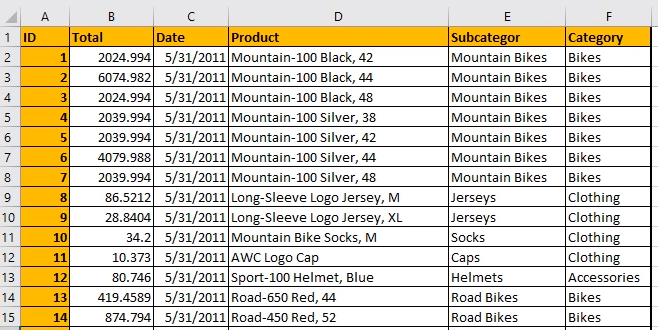

pandas实现同样的功能
import pandas as pd
pd.options.display.max_columns = 999 # 为了把所有列都显示出来
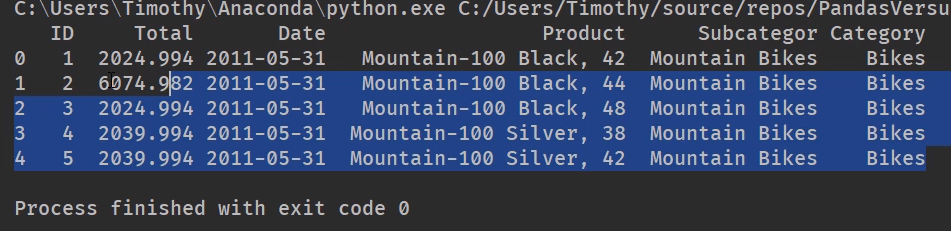
orders = pd.read_excel('C:/Temp/Orders.xlsx')
print(orders.head())
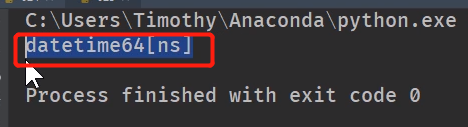
print(orders.Date.dytpe) # 日期类型
自动生成年份列
import pandas as pd
pd.options.display.max_columns = 999 # 为了把所有列都显示出来
orders = pd.read_excel('C:/Temp/Orders.xlsx')
orders['Year'] = pd.DatetimeIndex(orders['Date']).year
print(orders.head())
新增了一列:接下来按 Year 进行 groupby()
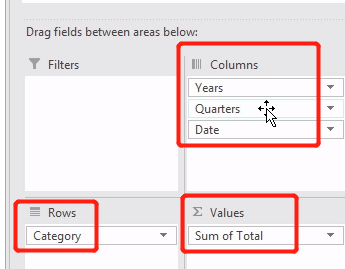
方法1:pivot_table
import numpy as np
import pandas as pd
pd.options.display.max_columns = 999 # 为了把所有列都显示出来
orders = pd.read_excel('C:/Temp/Orders.xlsx')
orders['Year'] = pd.DatetimeIndex(orders['Date']).year
pt1 = orders.pivot_table(index='Category', columns='Years', values='Total', aggfunc=np.sum) # 均参考上面透视图
print(pt1)
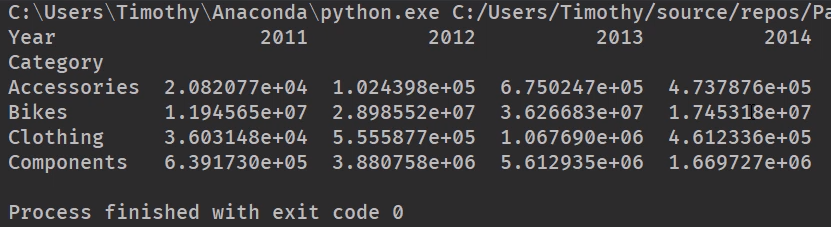
方法2: groupby()
import numpy as np
import pandas as pd
pd.options.display.max_columns = 999 # 为了把所有列都显示出来
orders = pd.read_excel('C:/Temp/Orders.xlsx')
orders['Year'] = pd.DatetimeIndex(orders['Date']).year
groups = orders.groupby(['Category', 'Year']) # 均参考上面透视图
s = groups['Total'].sum() # 销售总额
c = groups['ID'].count() # 卖了多少件
pt2 = pd.DataFrame({
'Sum':s, 'Count':c})
print(pt2)
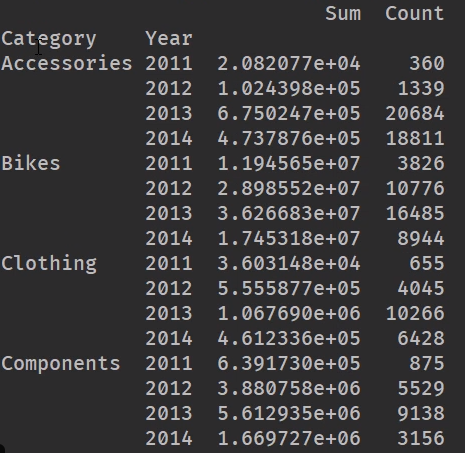
23. 线性回归&数据预测
23.1 数据预测 Excel操作
用excel实现

上图为收入的走势,选中任何一个数据点,右击选择 --> 添加趋势线

也可以这么操作

选择【线性方程】,勾选【Display Equation on chart】,把方程也显示出来.如图 y=2.4688x-0.1142,利用该方程进行预测即可。

23.2 数据预测 pandas 操作
import pandas as pd
import matplotlib.pyplot as plt
# 'Month'的值是2017.01,2017.02的浮点值,用dtype将其表示为 字符串 str(强制)
sales = pd.read_excel('C:/Temp/Sales.xlsx', dtype={
'Month': str})
print(sales)
plt.bar(sales.index, sales.Revenue) # 柱状图显示销售额,
plt.title('Sales')
plt.xticks(sales.index, sales.Month, rotation=90) # x 轴用index(自动生成),
plt.tight_layout()
plt.show()
除了分析数据,还要展示数据:

画出趋势线
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import linregress
# 'Month'的值是2017.01,2017.02的浮点值,用dtype将其表示为 字符串 str(强制)
sales = pd.read_excel('C:/Temp/Sales.xlsx', dtype={
'Month': str})
print(sales)
# 斜率、截距
slope, intercept, r, p, std_err = linregress(sales.index, sales.Revenue)
exp = sales.index * slope + intercept # 期望值
plt.scatter(sales.index, sales.Revenue) # 柱状图显示销售额,
plt.plot(sales.index, exp, color='orange')
plt.title('Sales')
plt.xticks(sales.index, sales.Month, rotation=90) # x 轴用index(自动生成),
plt.tight_layout()
plt.show()
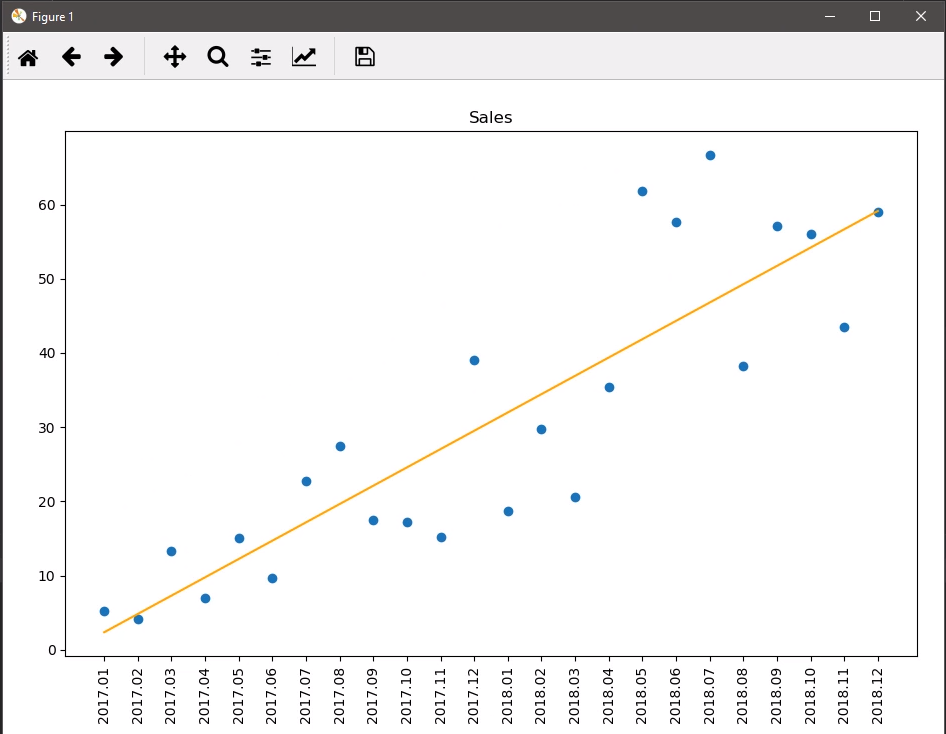
看一下回归方程里面的值是什么样子:
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import linregress
# 'Month'的值是2017.01,2017.02的浮点值,用dtype将其表示为 字符串 str(强制)
sales = pd.read_excel('C:/Temp/Sales.xlsx', dtype={
'Month': str})
print(sales)
# 斜率、截距
slope, intercept, r, p, std_err = linregress(sales.index, sales.Revenue)
exp = sales.index * slope + intercept # 期望值
plt.scatter(sales.index, sales.Revenue) # 柱状图显示销售额,
plt.plot(sales.index, exp, color='orange')
plt.title(f'y={
slope}*x+{
intercept}')
plt.xticks(sales.index, sales.Month, rotation=90) # x 轴用index(自动生成),
plt.tight_layout()
plt.show()

然后,用方程预测未来的值,预测2019年的值:
print(slope * 35 + intercept) # index为35的那个值

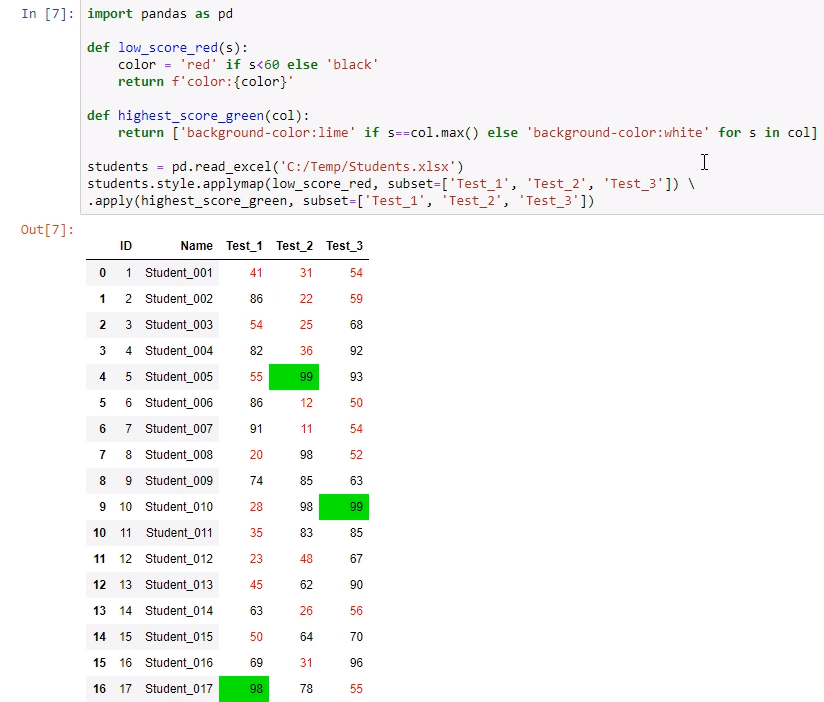
25. 条件格式化1
25.1 excel 操作
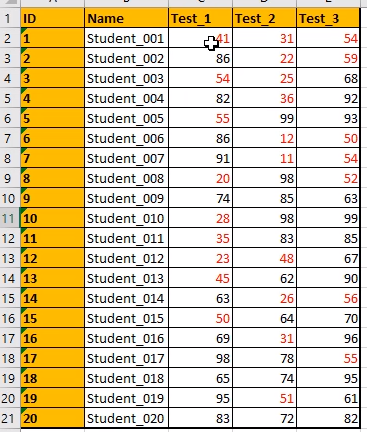
学生 3 次考试的成绩单:

看一下大家学习成绩,看一下谁考的好,以及不好,针对数据区域的单元格,施加条件格式:
选中数据区域,让不及格的变成红色: 最高分、不及格分
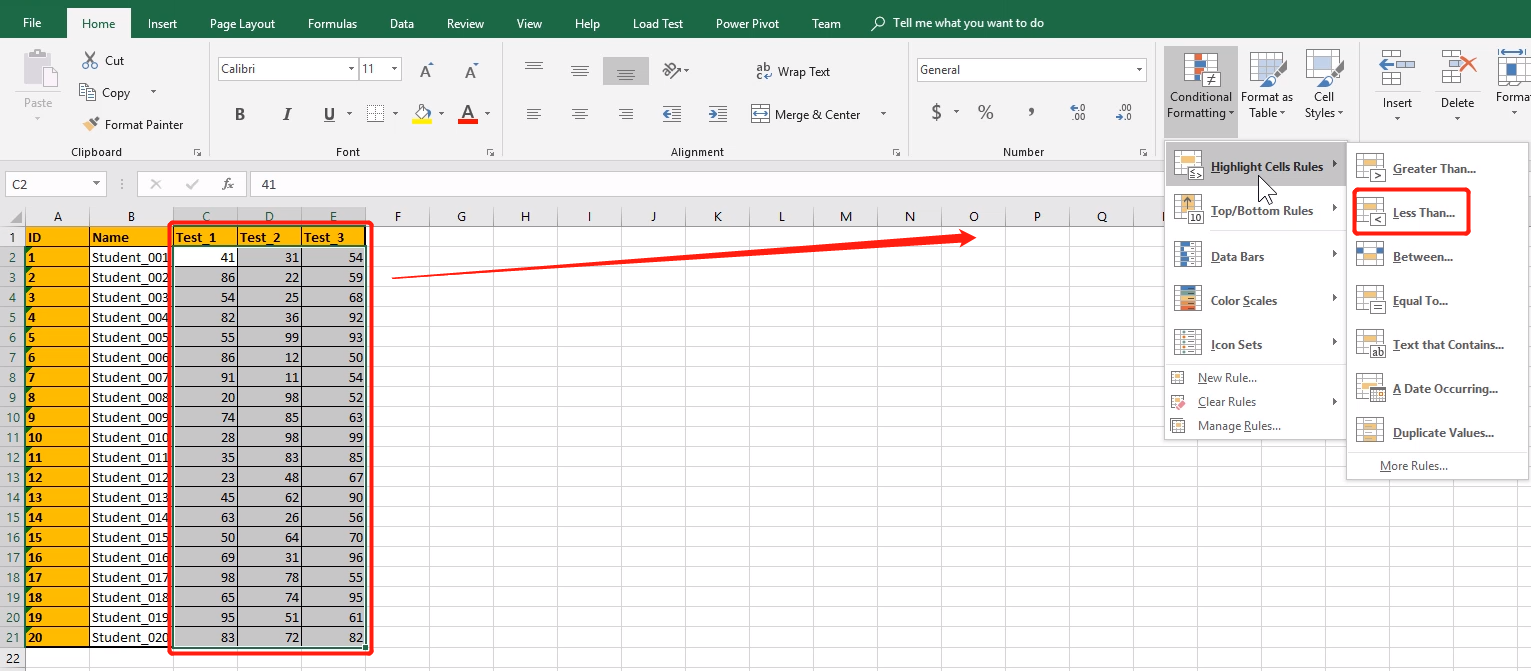
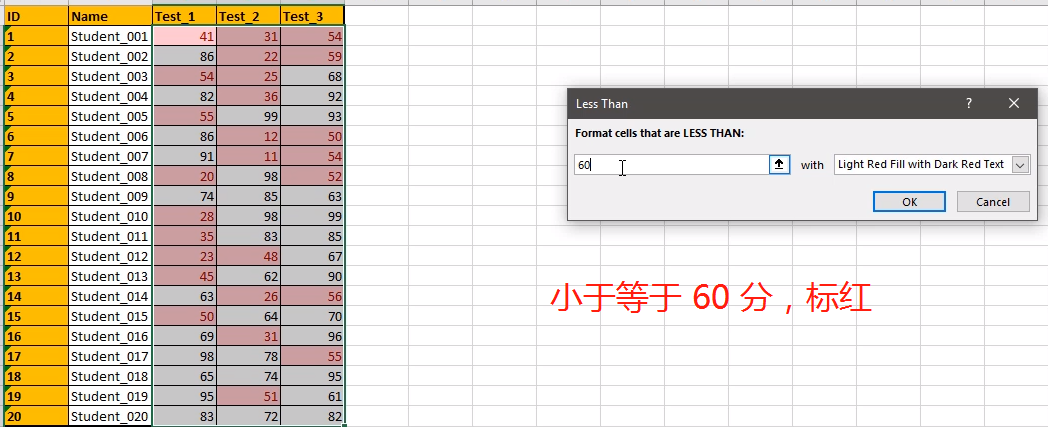
修改格式,让底色还是白色,仅将字体变为红色即可:选择 Custom Format 自定义
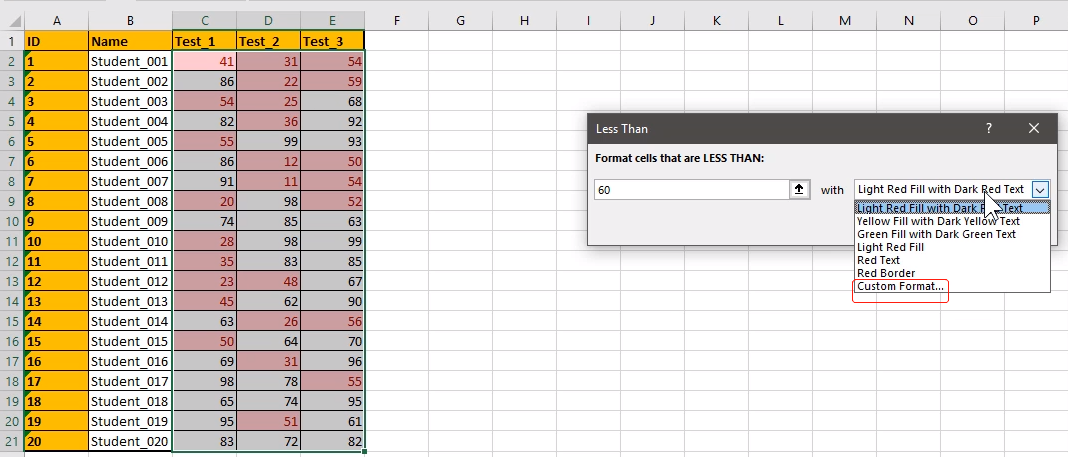
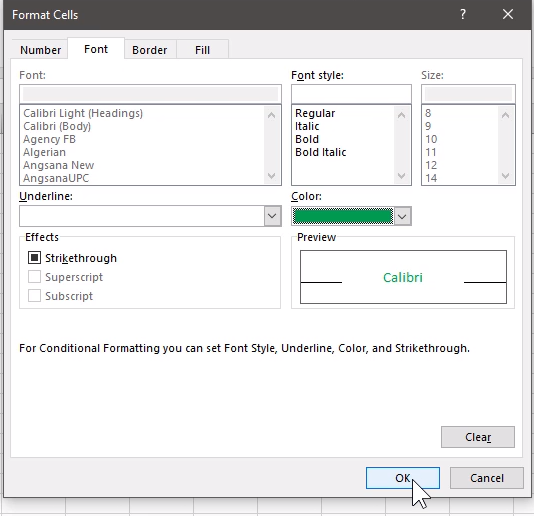
修改字体颜色
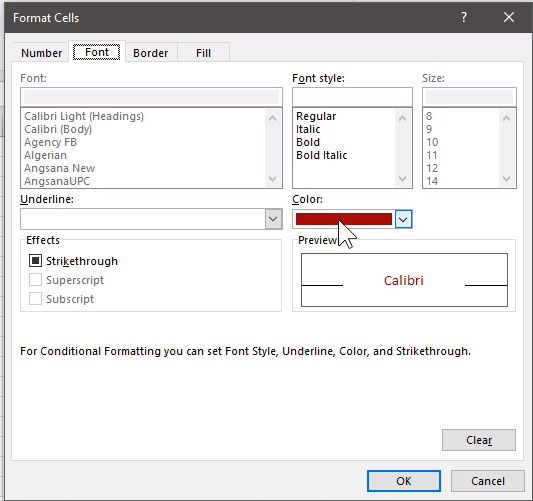
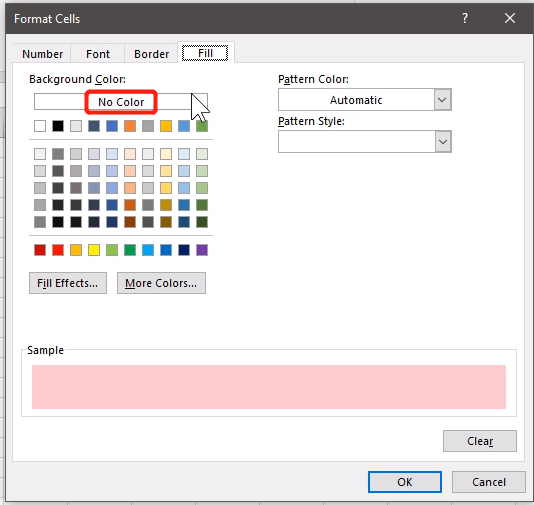
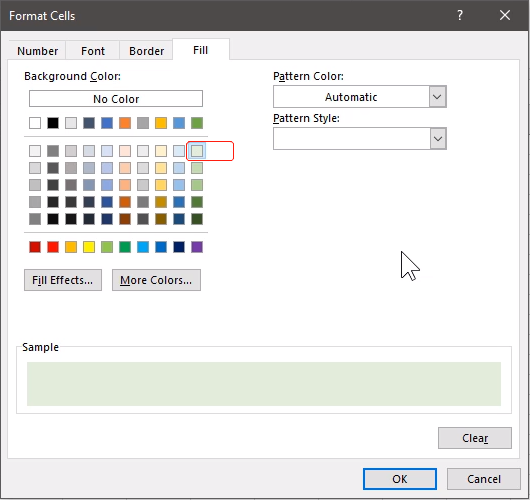
从Fill修改填充颜色:
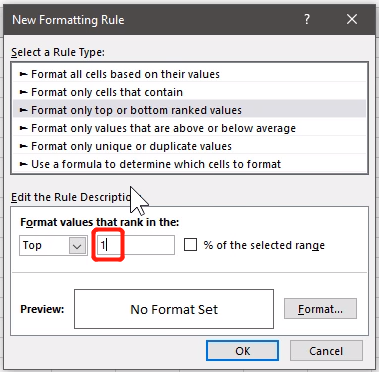
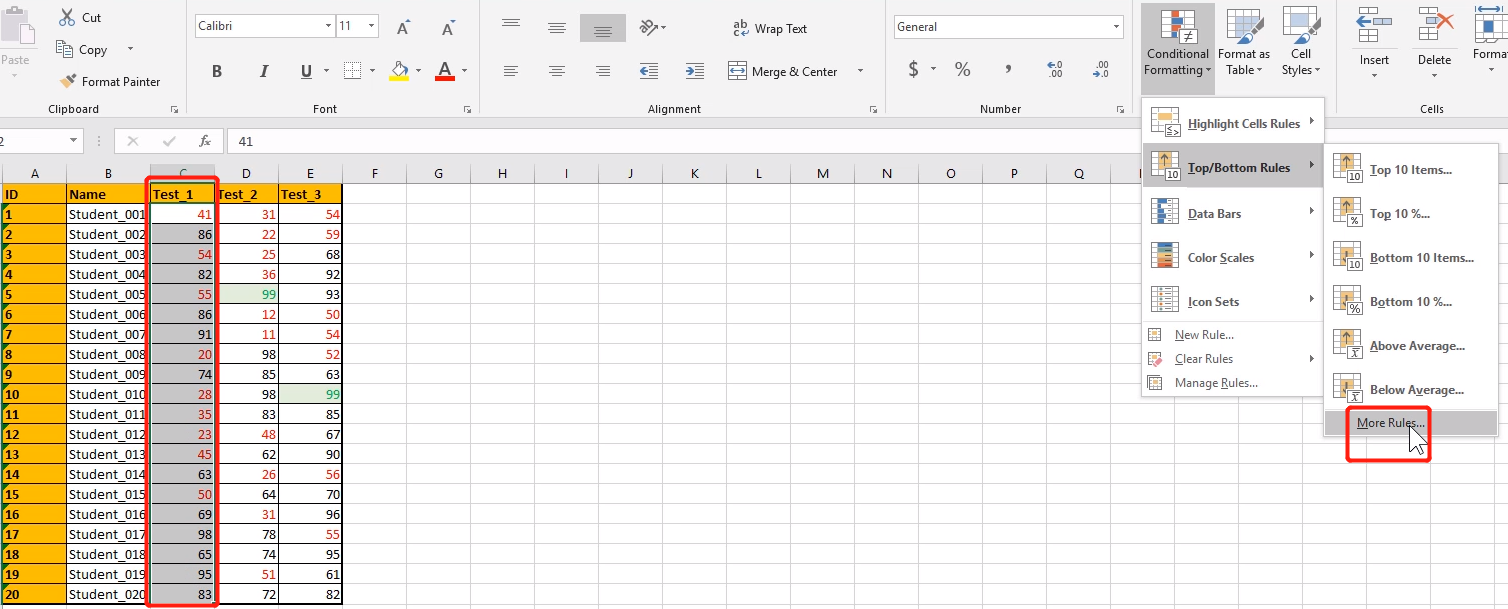
找到每次考试的第一名,给予奖励,条件格式要是加在每次考试上,而不是全部考试上。也就是施加在每一列上,
Top/Bottom Rules 从上到下来施加条件格式
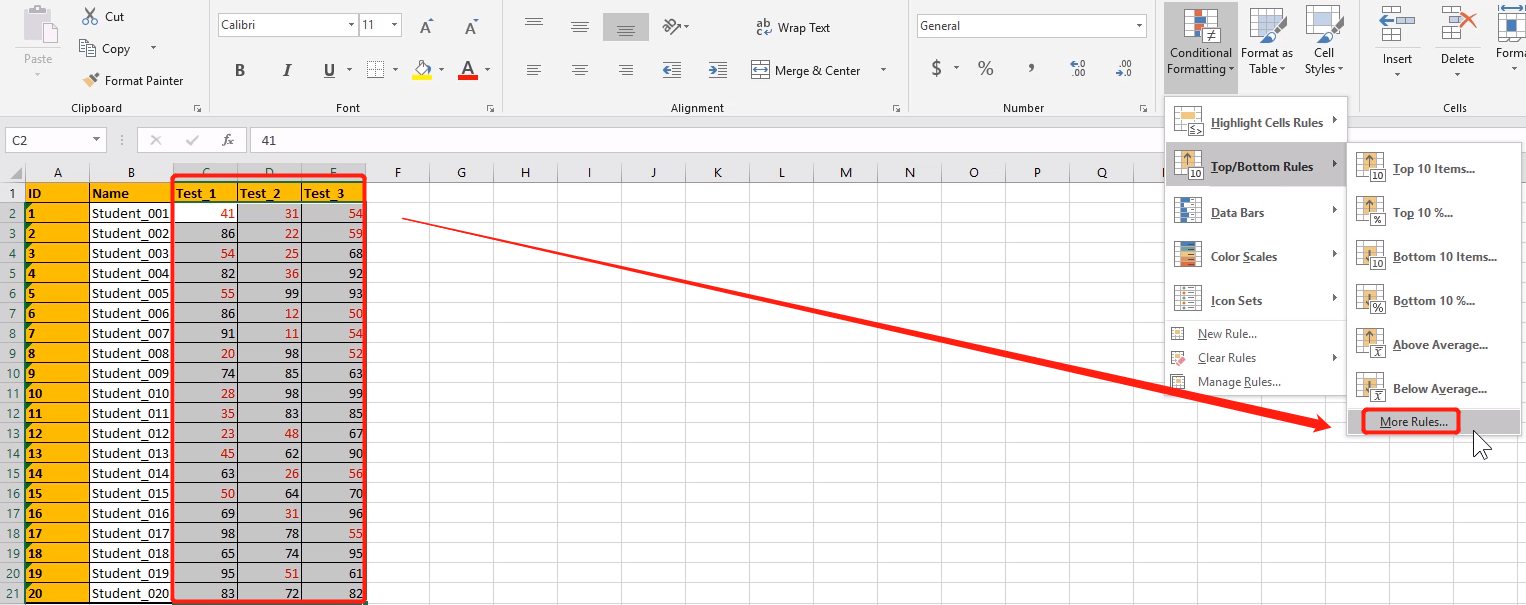
默认给出了前十名,
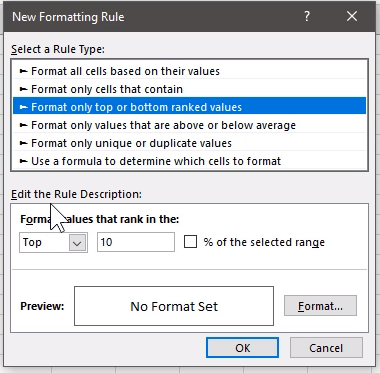
而我们要第一名,然后点击右侧Format,
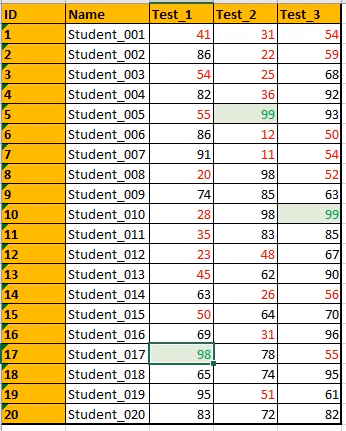
背景调为淡绿色:
将颜色调为绿色:
只认出来后两列的最高分,第一列的最高分没有认出来。
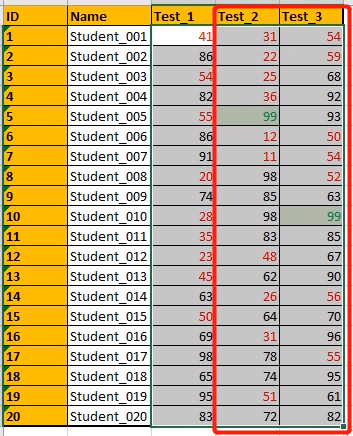
选中第一列,再来一遍
25.2 pandas 操作
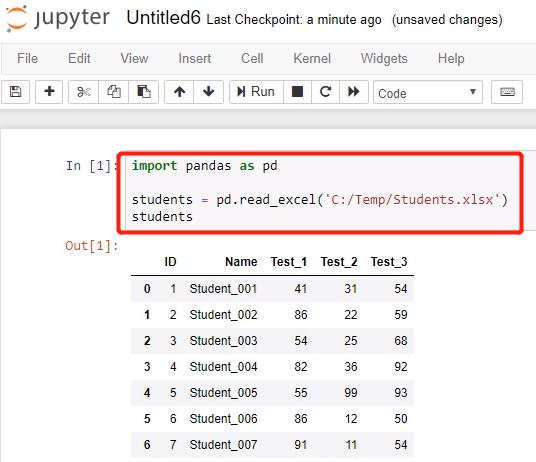
PyCharm目前无法显示带有条件格式的数据表,Jupyter Notebook是可以显示的。
·applymap()我要把你给我的格式,无差别的显示在选中的区域,而apply()是操作每列:
运行程序,不及格成绩变红
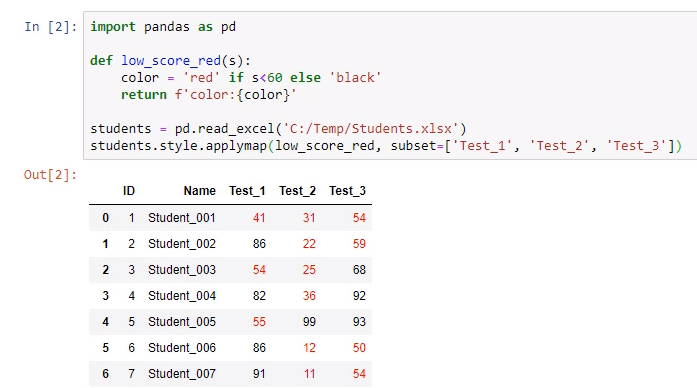
把每次考试的第一名变为绿色:0 列 1 行(apply的axis)