前言
在实际工作中,如果已经定位到某些具体的sql需要进行explain分析进而优化,可以直接使用explain+sql来分析其执行计划;如果还不能确定是哪些具体的sql语句需要进行explain分析进而优化,那么我们可以首先要定位哪些sql查询慢,性能低,消耗高;
定位低效sql
- 慢查询日志,可以通过开启慢查询日志来定位低效sql,它是通过设置慢查询时间阈值(默认是10s)或者设置查询没有走索引的sql记录到慢查询日志中;mysql性能优化之慢查询
- show processlist :慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题的时候查询慢查询日志并不能定位问题,可以使用
show processlist命令查看当前MySQL在进行的线程,包括线程的状态、是否锁表等,可以实时地查看 SQL的执行情况,同时对一些锁表操作进行优化。
explain介绍
使用explain分析执行计划实际上是:模拟优化器执行SQL语句;分析你的查询语句或是结构的性能瓶颈,使用方式
explain 需要分析的查询sql,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息, 而不是执行这条SQL 注意:如果 from 中包含子查询,仍会执行该子查询,将结果放入临时表中。
在mysql官网中与explain相关的文章也有很多,首推去官网阅读学习
了解查询执行计划
我们能通过explain + sql知道些什么了?
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询 …
话不多说,直接拿一条sql使用explain来分析一下,并对它的一些参数进行解读;
为了测试,有2张表emp和dept;

explain select * from dept;

+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 498343 | 100 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
1 row in set
字段解读
| 字段 | 含义 |
|---|---|
| id | select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。 |
| select_type | 表示 SELECT 的类型,常见的取值有:1.SIMPLE(简单表,即不使用表连接或者子查询)、2.PRIMARY(主查询,即外层的查询)、3.UNION(UNION 中的第二个或者后面的查询语句)、4.SUBQUERY(子查询中的第一个 SELECT)等 |
| table | 输出结果集的表 |
| type | 表示表的连接类型,性能由好到差的连接类型为( system —> const -----> eq_ref ------> ref-------> ref_or_null----> index_merge —> index_subquery -----> range -----> index ------>all ) |
| possible_keys | 表示查询时,可能使用的索引 |
| key | 表示实际使用的索引 |
| key_len | 索引字段的长度 |
| rows | 扫描行的数量 |
| extra | 执行情况的说明和描述 |
id
id 字段是 select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。id 情况有三种:
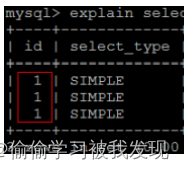
- id 相同,表示加载表的顺序是从上到下。
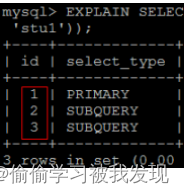
- id 不同,id值越大,优先级越高,越先被执行。
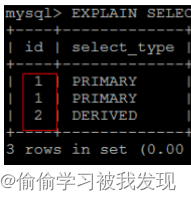
- id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行。
select_type
数据读取操作的操作类型,查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
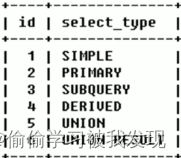
| select_type | 含义 |
|---|---|
| SIMPLE | 简单的select查询,查询中不包含子查询或者UNION |
| PRIMARY | 查询中若包含任何复杂的子查询,最外层查询标记为该标识 |
| SUBQUERY | 在SELECT 或 WHERE 列表中包含了子查询 |
| DERIVED | 在FROM 列表中包含的子查询,被标记为 DERIVED(衍生) MYSQL会递归执行这些子查询,把结果放在临时表中 |
| UNION | 若第二个SELECT出现在UNION之后,则标记为UNION ; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为 : DERIVED |
| UNION RESULT | 从UNION表获取结果的SELECT |
table
显示执行的表名,这一列表示 explain 的一行正在访问哪个表。
当 from 子句中有子查询时,表示当前查询依赖 id=N 的查询,于是先执行 id=N 的查询。 当有 union 时,UNION RESULT 的 table 列的值为<union id1,id2>,id1和id2表示参与 union 的 select 行id。
type
type 显示的是访问类型。
结果值从最好到最坏依次是:
null> system > const > eq_ref > ref > range > index > all
在实际工作中,我认为:查询sql至少达到 range 级别。
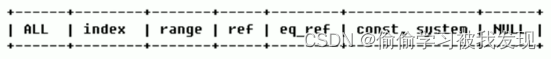
| type | 含义 |
|---|---|
| null | MySQL不访问任何表,索引,直接返回结果 |
| system | 表只有一行记录(等于系统表),这是const类型的特例,一般不会出现 |
| const | 表示通过索引一次就找到了,const 用于比较primary key 或者 unique 索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL 就能将该查询转换为一个常量。const于将"主键" 或 “唯一” 索引的所有部分与常量值进行比较 |
| eq_ref | 类似ref,区别在于使用的是唯一索引,使用主键的关联查询,关联查询出的记录只有一条。常见于主键或唯一索引扫描 |
| ref | 表之间的引用,显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,返回所有匹配某个单独值的所有行(多个) |
| range | 只检索给定返回的行,使用一个索引来选择行。 where 之后出现 between , < , > , in 等操作。 |
| index | index 与 ALL的区别为 index 类型只是遍历了索引树, 通常比ALL 快, ALL 是遍历数据文件。 |
| all | 将遍历全表以找到匹配的行 |
key
| key | 含义 |
|---|---|
| possible_keys | 哪些索引可以使用,显示可能应用在这张表的索引, 一个或多个 |
| key | 哪些索引被实际使用,实际使用的索引, 如果为NULL,则没有使用索引 |
| key_len | 消耗的字节数,表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前 提下,长度越短越好 |
rows
每张表有多少行被优化器查询,根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数(越小越好)。
extra
其他的额外的执行计划信息,在该列展示 。
| extra | 含义 |
|---|---|
| using filesort | 需要优化,说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取, 称为“文件排序”, 效率低。 |
| using temporary | 需要优化,使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于 order by 和group by; 效率低 |
| using index | 表示相应的select操作使用了覆盖索引, 避免访问表的数据行, 效率不错。 |