01 闭包
闭包


简单的闭包

演示
"""
演示Python的闭包特性
"""
# 简单闭包
def outer(logo):
"""
简单闭包函数
:param logo: 接收一个任意字符
:return: 返回内部函数inner
"""
def inner(msg):
print(f"<{logo}>{msg}<{logo}>")
return inner # 返回内部的函数
fn1 = outer("黑马程序员")
fn1("大家好呀") # 注意现在的fn1就是一个内部函数 - inner
fn1("学Python就来")
print("--------------------------")
fn2 = outer("传智教育")
fn2("IT教育培训")
fn2("学Python就来")
# 使用nonlocal关键字修改外部函数的值
# 使用闭包实现ATM小案例

修改外部函数变量的值

演示
# 使用nonlocal关键字修改外部函数的值
def outer(num1):
def inner(num2):
nonlocal num1
num1 += num2
print(num1)
return inner
fn = outer(10)
fn(10) # 20
fn(10) # 30
fn(10) # 40
fn(10) # 50
现在可以尝试实现以下atm取钱的闭包实现了

演示
# 使用闭包实现ATM小案例
def account_create(initial_amoumt = 0):
def atm(num,deposit = True):
nonlocal initial_amoumt
if deposit:
initial_amoumt += num
print(f"存款:+{num},账户余额:{initial_amoumt}")
else:
initial_amoumt -= num
print(f"取款:-{num},账户余额:{initial_amoumt}")
return atm
fn =account_create()
fn(50) # 存款
fn(25,False) # 取款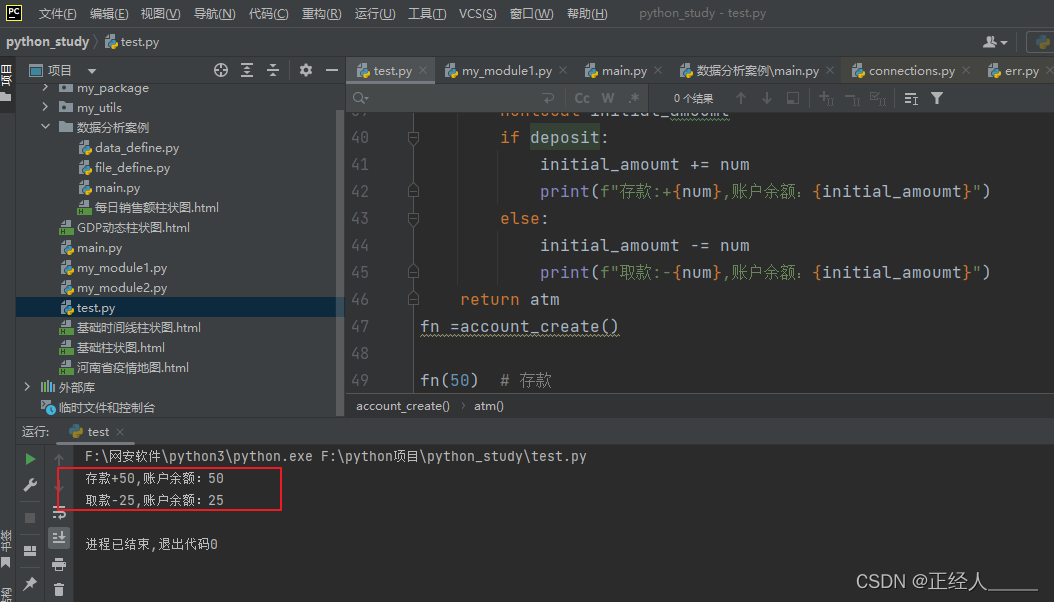
闭包注意事项

总结

02 装饰器
装饰器

装饰器的一般写法(闭包写法)

"""
演示装饰器的写法
"""
# 装饰器的一般写法(闭包)
def outer(func):
def inner():
print("我睡觉了")
func()
print("我起床了")
return inner
def sleep():
import random
import time
print("睡眠中......")
time.sleep(random.randint(1,5)) # time.sleep() 暂停执行 random.randint(1,5)生成1-5的随机数
# 这样实现也可以就是显得不太高级
# print("我睡觉了")
# sleep()
# print("我起床了")
# 使用装饰器
fn = outer(sleep)
fn()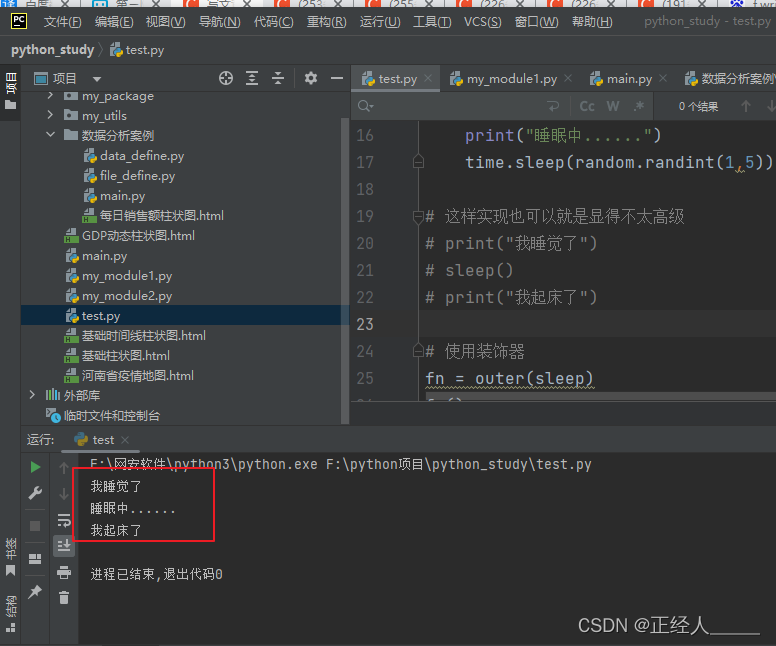
装饰器的语法糖写法

演示
"""
演示装饰器的写法
"""
# 装饰器的一般写法(闭包)
def outer(func):
def inner():
print("我睡觉了")
func()
print("我起床了")
return inner
@outer # 使用语法糖
def sleep():
import random
import time
print("睡眠中......")
time.sleep(random.randint(1,5)) # time.sleep() 暂停执行 random.randint(1,5)生成1-5的随机数
sleep()
总结

03 设计模式

单例模式


演示
创建一个str_tools_py.py文件
class StrTools:
pass
str_tool = StrTools()在创建一个:单例模式.py的文件
"""
演示单例模式的效果
"""
class StrTools:
pass
s1 = StrTools()
s2 = StrTools()
print(id(s1),s1)
print(id(s2),s2)
# 改一种写法
from str_tools_py import str_tool
s1 = str_tool
s2 = str_tool
print(id(s1),s1)
print(id(s2),s2)
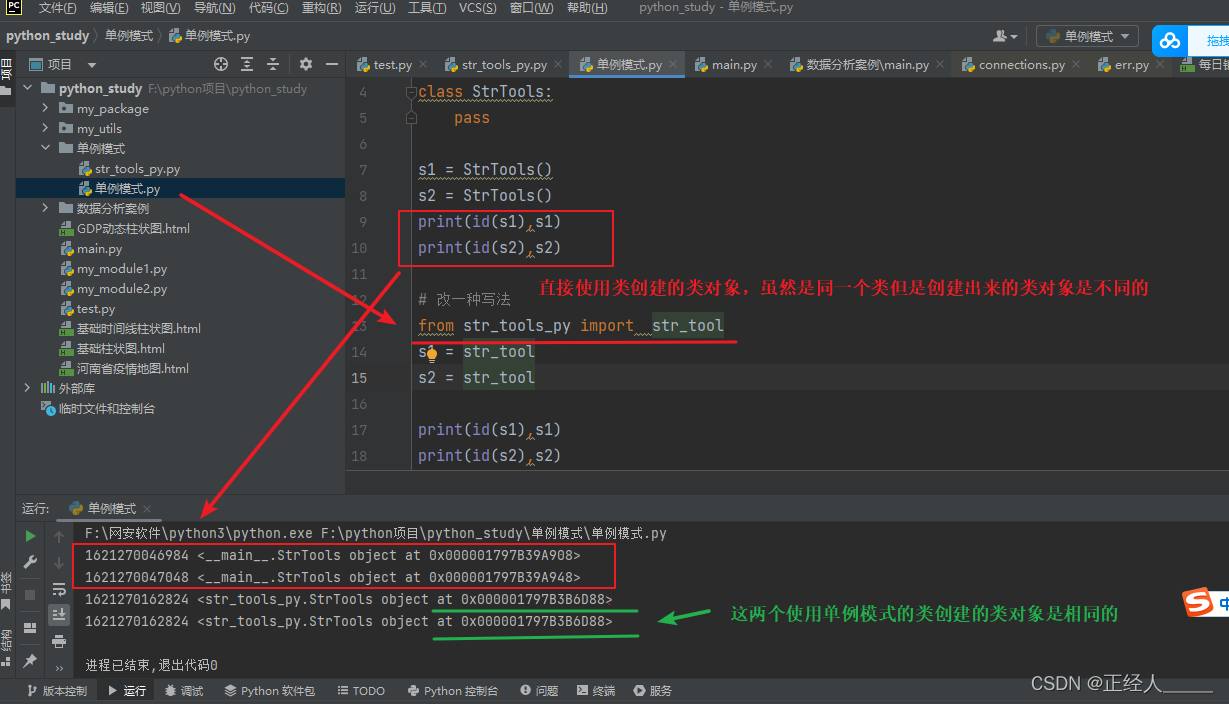
总结

工厂模式


演示
"""
演示设计模式之工厂模式
"""
class Person:
pass
class Worker(Person):
pass
class Student(Person):
pass
class Teacher(Person):
pass
class PersonFactory:
def get_person(self,p_type):
if p_type == 'w':
return Worker()
elif p_type == 's':
return Student()
else:
return Teacher()
pf = PersonFactory()
worker = pf.get_person('w')
stu = pf.get_person('s')
teacher = pf.get_person('t')
# 使用工厂模式的优点:如果以后类发生改变,我们只需改工厂类中的代码而不需要做太多的改动
总结

04 多线程
进程、线程和并行执行
进程、线程
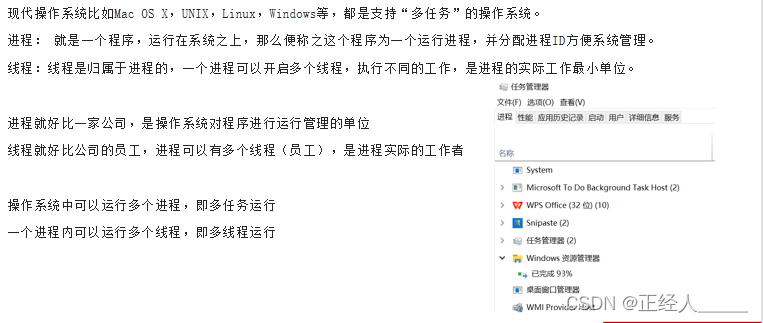
注意点:
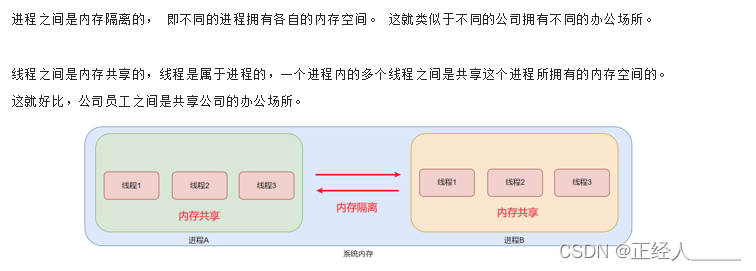
并行执行

总结

多线程编程
threading模块

多线程编程


演示
"""
演示多线程的使用
"""
import time
import threading
def sing(msg):
while True:
print(msg)
time.sleep(1)
def dance(msg):
while True:
print(msg)
time.sleep(1)
if __name__ == '__main__':
# 没有使用多线程的情况
# sing("我在唱歌..")
# dance("我在跳舞...")
# 使用多线程 target 指定要执行的任务名称 args 以元组的形式给执行任务传参 kwargs 以字典的方式传参
sing_thread = threading.Thread(target=sing, args=("我在唱歌...",)) # 创建一个唱歌的线程
dance_thread = threading.Thread(target=dance, kwargs={"msg":"我在跳舞..."}) # 创建一个唱歌的线程
# 启动线程
sing_thread.start()
dance_thread.start()
总结

05 网络编程
服务端开发
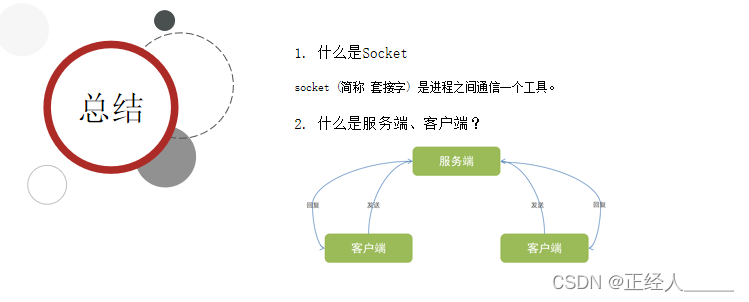
Socket

客户端和服务端
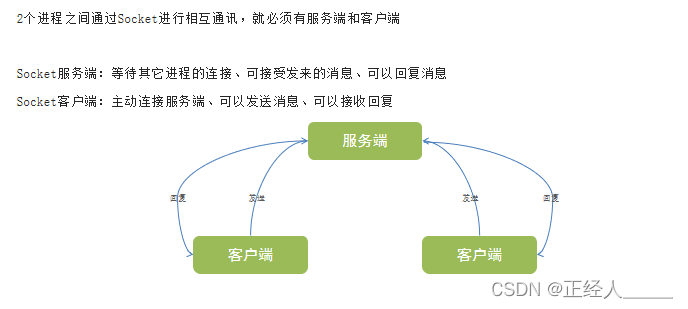
Socket服务端编程


实现服务端并结合客户端进行测试
Releases · nicedayzhu/netAssist · GitHub工具下载: Releases · nicedayzhu/netAssist · GitHub

演示
先把上面的工具下载了,然后运行下面的代码
"""
演示Socket服务端开发
"""
import socket
# 创建Socket对象
socket_server =socket.socket()
# 绑定ip地址和端口
socket_server.bind(("localhost",8888))
# 监听端口
socket_server.listen(1)
# listen方法内接受一个整数传参数,表示接受的链接数量
# result:tuple = socket_server.accept()
# conn = result[0] # 客户端和服务端的链接对象
# address = result[1] # 客户端的地址信息
conn,address = socket_server.accept() # 简化
# accept()方法放回的值,二元元组(链接对象,客户端的地址信息)
# 可以通过 变量1,变量2 = socket_server.accept() 的形式,直接接收二元元组的两个元素
# accept() 放个,是阻塞方法,等待客户端的链接,如果没有链接就在这一行不向下执行了
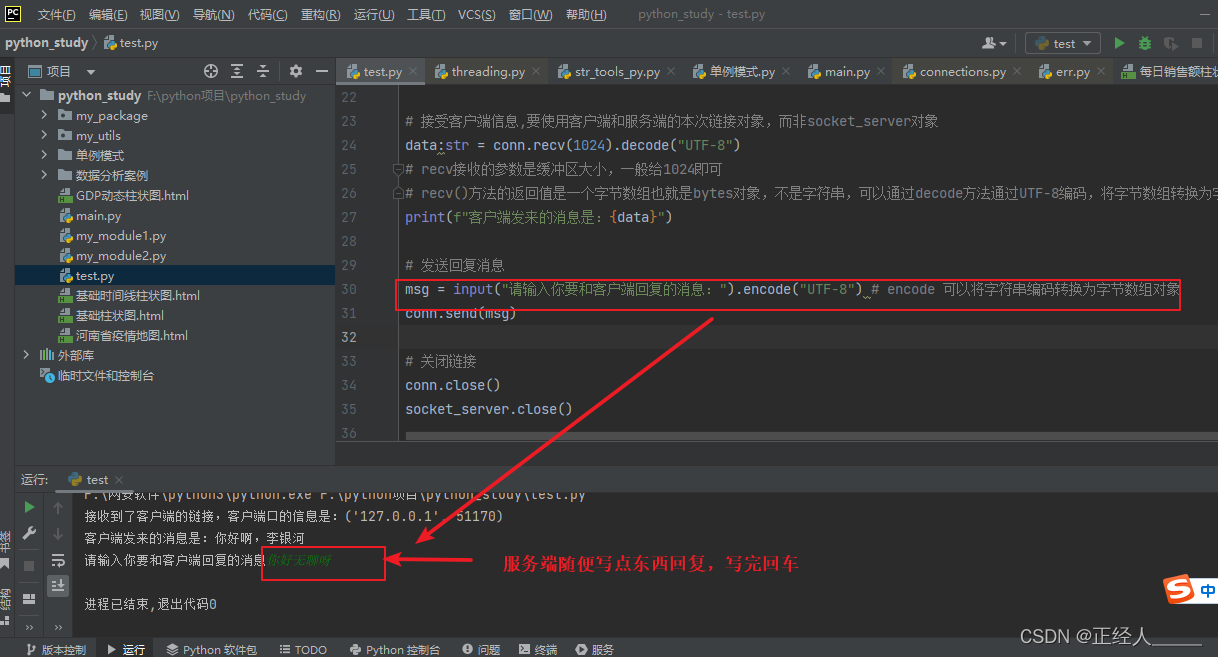
print(f"接收到了客户端的链接,客户端口的信息是:{address}")
# 接受客户端信息,要使用客户端和服务端的本次链接对象,而非socket_server对象
data:str = conn.recv(1024).decode("UTF-8")
# recv接收的参数是缓冲区大小,一般给1024即可
# recv()方法的返回值是一个字节数组也就是bytes对象,不是字符串,可以通过decode方法通过UTF-8编码,将字节数组转换为字符串对象
print(f"客户端发来的消息是:{data}")
# 发送回复消息
msg = input("请输入你要和客户端回复的消息:").encode("UTF-8") # encode 可以将字符串编码转换为字节数组对象
conn.send(msg)
# 关闭链接
conn.close()
socket_server.close()


回到编译器查看

去连接工具中发条消息

编译器查看
服务端回复消息

如果你需要一直聊天,需要退出时在断开连接那就改一下代码
"""
演示Socket服务端开发
"""
import socket
# 创建Socket对象
socket_server =socket.socket()
# 绑定ip地址和端口
socket_server.bind(("localhost",8888))
# 监听端口
socket_server.listen(1)
# listen方法内接受一个整数传参数,表示接受的链接数量
# result:tuple = socket_server.accept()
# conn = result[0] # 客户端和服务端的链接对象
# address = result[1] # 客户端的地址信息
conn,address = socket_server.accept() # 简化
# accept()方法放回的值,二元元组(链接对象,客户端的地址信息)
# 可以通过 变量1,变量2 = socket_server.accept() 的形式,直接接收二元元组的两个元素
# accept() 放个,是阻塞方法,等待客户端的链接,如果没有链接就在这一行不向下执行了
print(f"接收到了客户端的链接,客户端口的信息是:{address}")
# 接受客户端信息,要使用客户端和服务端的本次链接对象,而非socket_server对象
while True: # 设置一个无限循环
data:str = conn.recv(1024).decode("UTF-8")
# recv接收的参数是缓冲区大小,一般给1024即可
# recv()方法的返回值是一个字节数组也就是bytes对象,不是字符串,可以通过decode方法通过UTF-8编码,将字节数组转换为字符串对象
print(f"客户端发来的消息是:{data}")
# 发送回复消息
msg = input("请输入你要和客户端回复的消息:")
if msg == 'exit': # 设置当用户输入exit就退出循环
break
conn.send(msg.encode("UTF-8") ) #.encode("UTF-8") # encode 可以将字符串编码转换为字节数组对象
# 关闭链接
conn.close()
socket_server.close()



总结
客户端开发
Socket客户端编程


演示
"""
演示Socket客户端开发
"""
import socket
# 创建socket对象
socket_cliant = socket.socket()
# 连接到服务端
socket_cliant.connect(("localhost",8888))
while True:
# 发送消息
msg = input("请输入要发送个服务端的消息:")
if msg == 'exit':
break
socket_cliant.send(msg.encode("UTF-8")) # ncode 可以将字符串编码转换为字节数组对象
# 接收返回消息
recv_data = socket_cliant.recv(1024) # recv()方法可以暂停代码的执行知道接收到了返回消息
# recv接收的参数是缓冲区大小,一般给1024即可
# recv()方法的返回值是一个字节数组也就是bytes对象,不是字符串,可以通过decode方法通过UTF-8编码,将字节数组转换为字符串对象
print(f"服务端回复的消息是:{recv_data.decode('UTF-8')}")
# 关闭链接
socket_cliant.close()服务端客户端相互通讯

演示:
创建一个文件夹如:Socket编程,里面有两个文件 :Socket客服端.py Socket服务端.py
然后把客户端的代码与服务端的代码分别粘贴进去,先运行服务端后运行客户端连接
效果

06 正则表达式
基础匹配
正则表达式

正则的三个基础方法
match 从头匹配

search 搜索匹配

findall 搜索全部匹配
演示
"""
演示Python正则表达式re模块的3个基础匹配方法
"""
import re
s = "python itheima python"
s1 = "1python itheima python"
# match 从头匹配
result = re.match("python",s)
result1 = re.match("python",s1)
print(result)
print(result.span()) # span() 返回匹配到的字符的开始与结束下标,不包括结束下标 (0, 6)
print(result.group()) # group() 返回匹配到的字符 python
print(result1) # None match 只能匹配开头的字符,匹配不上就返回None
print("---------------search 搜索匹配---------------")
# search 搜索匹配 (找到第一个就停止不会往后,找不到返回None)
result2 = re.search("python",s1)
result3 = re.search("python1",s1)
print(result2)
print(result2.span()) # (1, 7)
print(result2.group()) # pytho
print(result3) # 找不到返回Node
print("---------------findall 搜索匹配---------------")
# findall 搜索全部匹配
result4 = re.findall("python",s1)
result5 = re.findall("python1",s1)
print(result4) # ['python', 'python'] 把匹配上的全部返回
print(result5) # [] 找不到返回空列表

总结

元字符匹配
在刚刚我们只是进行了基础的字符串匹配,正则最强大的功能在于元字符匹配规则。
单字符匹配:

演示
"""
演示Python正则表达式使用元字符进行匹配
"""
import re
s = "itheima @@python2 !!666 ##itccast3"
# 找出数字 \d 匹配数字,即:0-9
result = re.findall(r'\d',s) # 字符串前面加r的标记,表示字符串中的转义字符\无效,就是普通字符的意思
print(result)
# 找出特殊字符 \W 匹配非单词字符
result1 = re.findall(r'\W',s)
print(result1)
# 找出全部英文字母
result1 = re.findall('[a-zA-Z]',s)
print(result1)

数量匹配:

边界匹配:

分组匹配:

案例

演示 (这个建议参考我的写一 遍,辅助理解)
"""
演示Python正则表达式使用元字符进行匹配
"""
import re
# s = "itheima @@python2 !!666 ##itccast3"
#
# # 找出数字 \d 匹配数字,即:0-9
# result = re.findall(r'\d',s) # 字符串前面加r的标记,表示字符串中的转义字符\无效,就是普通字符的意思
# print(result)
#
# # 找出特殊字符 \W 匹配非单词字符
# result1 = re.findall(r'\W',s)
# print(result1)
# 找出全部英文字母
# result1 = re.findall('[a-zA-Z]',s)
# print(result1)
# 匹配账号,只能有字母或数字组成,长度限制6到10位
r ='^[0-9a-zA-Z]{6,10}$' # ^ 匹配开头 $ 匹配结尾 {6,10} 匹配6-10位 ,总的来说就是匹配:0-9、a-z、A-Z、6-10位字符、从开头匹配到结尾
s = "12345678912345"
print(re.findall(r,s)) # [] r 这个正则要求的字符是 6 -10 我们写的s变量的字符明显长度超出了
s1 = "12345678"
print(re.findall(r,s1)) # ['12345678']
print('--------------匹配QQ号,要求纯数字,长度5-11,第一位不为0--------------')
# 匹配QQ号,要求纯数字,长度5-11,第一位不为0
r1 ='[1-9][0-9]{4,10}' # [1-9] 第一位数字是1-9 ,[0-9]{4,10}后面的数字是0-9并且是4-10位数字,为啥是4-10?因为前面已经占了一位数字
s2 = "012345678"
print(re.findall(r1,s2)) # ['12345678'] 他自动把我们的0给去掉了,这不是我们想要的要么就匹配上要么就匹配不上
# 出现上面的原因是我们没有加 ^ $ 让正则从开头匹配到结尾
r2 ='^[1-9][0-9]{4,10}$'
s3 = "12345678"
print(re.findall(r2,s2)) # []
print(re.findall(r2,s3)) # ['12345678']
print("-----------匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址-----------")
# 匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址
"""
首先一般的邮箱格式:[email protected] [email protected]
解析:
^ $ 匹配从开头到结束
[\w-]+ 匹配中括号中的字符 \w 匹配单词字符,即:a-z、A-Z、0-9、 _ - 就是表示可以匹配 - + 表示这个规则可以匹配1次到无数次
(\.[\w-]+)* \. 在正则中就是表示点本身 * 表示这个规程可以匹配0次到无数次 因为有些邮箱可能是 asd.asad.qq.com
(qq|163|gmail) | 匹配左右任意一个表达式
(\.[\w-]+)+ 最后这个+的含义是1或无数次,最少出现一次(邮箱的结尾.com或其他的必须出现一次)
字符串前面加r的标记,表示字符串中的转义字符\无效,就是普通字符的意思
"""
r3 = r'(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)'
s4 = '[email protected]'
s5 = '[email protected]'
print(re.findall(r3,s4))
print(re.match(r3,s4))
print(re.match(r3,s5)) # None
总结

07 递归

递归找文件

演示
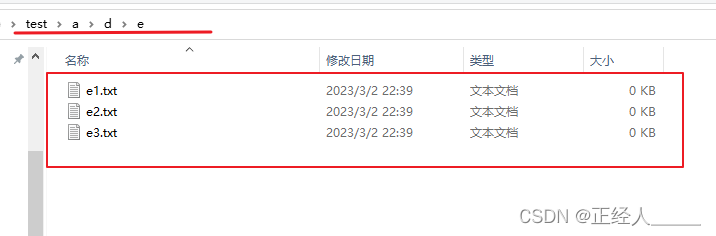
创建一个文件用来做实验
test

test/a

test/a/d

test/a/d/e
test/b
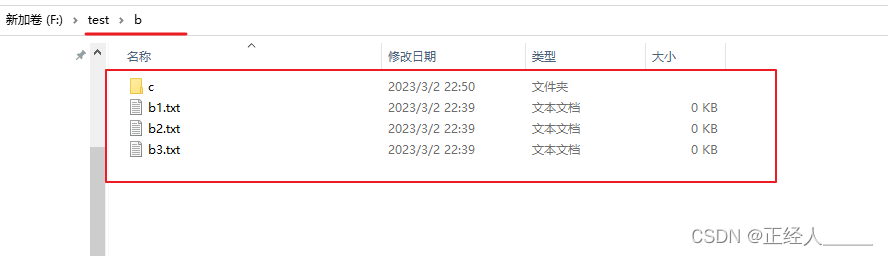
test/b/c
代码
"""
演示Python递归操作
需求:通过递归,找出一个指定文件夹内的全部文件
思路:写一个函数,列出文件夹内容的全部内容,如果是文件就收集到list
如果是文件夹,就递归调用自己,再次判断。
"""
import os
def test_os():
"""演示os模块的3个基础方法"""
print(os.listdir("F:/test")) # 列出文件路径的内容
# print(os.isdir("F:/test/a")) # 判断指定文件是不是文件夹
# print(os.exists("F:/test")) # 判断指定路径是否存在
def get_files_recursion_from_dir(path):
"""
从指定的文件夹中使用递归的方式,获取全部的文件列表
:param path: path 被判断的文件夹
:return: list 包含全部的文件,如果目录不存在或者无文件就返回一个空lisr
"""
print(f"当前判断的文件路径是:{path}")
file_list =[] # 定义一个变量存储文件路径
if os.path.exists(path): # exists() 判断指定路径是否存在
for f in os.listdir(path): # listdir() 列出文件路径的内容
new_path = path + "/" + f # 拼接补全一下文件的路径
if os.path.isdir(new_path): # isdir 判断文件是否是文件夹
# 进入到这里,表明这里目录是文件夹而不是文件
file_list += get_files_recursion_from_dir(new_path) # 调用函数自身,继续重复执行上面的代码
"""
file_list += 存储函数递归后的返回值即get_files_recursion_from_dir函数的
返回值也就是上一次代码执行完成后的返回文件路径列表file_list,这里就是把当前的
返回值与上一次的返回值组合一下
"""
else:
file_list.append(new_path) # 不是文件夹那就是文件,那我们就把文件路径追加给file_list量收集起来
else:
print(f"指定的目录{path},不存在")
return {}
return file_list # 返回全部的文件路径
if __name__ == '__main__':
test_os()
print(get_files_recursion_from_dir("F:/test"))
总结
