学习目标:
reppoints网络模型学习以及源码解析
RepPoints是一项比较好的工作,使用点集的方式来预测目标的位置,本人对RepPoints学习过很长一段时间但是一直没能理解其具体的工作原理,最近又重新学习一遍这个网络模型终于对其内部结构有了更为详细的理解。
RepPoints是采用点集的方式来预测目标,属于anchor-free目标检测器的一种,实质和DCN类似,也可以称为DCNV3版本,下面让我们具体学习模型的网络结构。
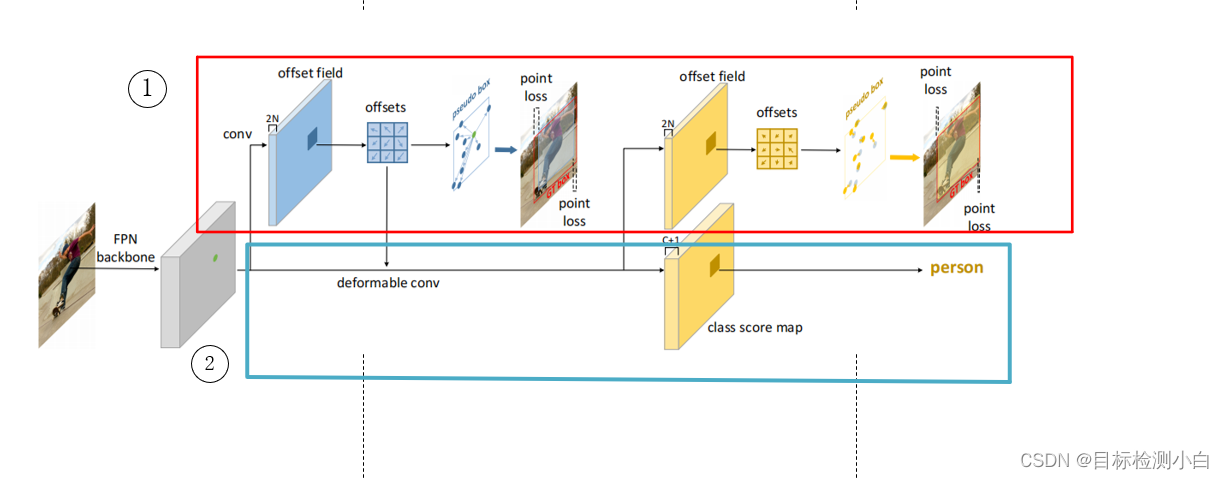
模型的结构主要分为两部分,上半部分为回归分支,下半部分为分类分支,回归分支分为两个阶段
(1)产生offsets并回归
(2)根据上一阶段回归结果调整偏移量进行更加精细化回归。
分类分支根据回归分支第一阶段产生的结果直接进行分类预测
接下来讲解代码的具体执行方式。
class RepPointsHead(AnchorFreeHead):
"""RepPoint head.
Args:
point_feat_channels (int): Number of channels of points features.
gradient_mul (float): The multiplier to gradients from
points refinement and recognition.
point_strides (Iterable): points strides.
point_base_scale (int): bbox scale for assigning labels.
loss_cls (dict): Config of classification loss.
loss_bbox_init (dict): Config of initial points loss.
loss_bbox_refine (dict): Config of points loss in refinement.
use_grid_points (bool): If we use bounding box representation, the
reppoints is represented as grid points on the bounding box.
center_init (bool): Whether to use center point assignment.
transform_method (str): The methods to transform RepPoints to bbox.
""" # noqa: W605
def __init__(self,
num_classes,
in_channels,
point_feat_channels=256,
num_points=9,
gradient_mul=0.1,
point_strides=[8, 16, 32, 64, 128],
point_base_scale=4,
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox_init=dict(
type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=0.5),
loss_bbox_refine=dict(
type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0),
use_grid_points=False,
center_init=True,
transform_method='moment',
moment_mul=0.01,
**kwargs):
self.num_points = num_points
self.point_feat_channels = point_feat_channels
self.use_grid_points = use_grid_points
self.center_init = center_init
# we use deform conv to extract points features
self.dcn_kernel = int(np.sqrt(num_points))
self.dcn_pad = int((self.dcn_kernel - 1) / 2)
assert self.dcn_kernel * self.dcn_kernel == num_points, \
'The points number should be a square number.'
assert self.dcn_kernel % 2 == 1, \
'The points number should be an odd square number.'
dcn_base = np.arange(-self.dcn_pad,
self.dcn_pad + 1).astype(np.float64)
dcn_base_y = np.repeat(dcn_base, self.dcn_kernel)
dcn_base_x = np.tile(dcn_base, self.dcn_kernel)
dcn_base_offset = np.stack([dcn_base_y, dcn_base_x], axis=1).reshape(
(-1))
self.dcn_base_offset = torch.tensor(dcn_base_offset).view(1, -1, 1, 1)
super().__init__(num_classes, in_channels, loss_cls=loss_cls, **kwargs)
self.gradient_mul = gradient_mul
self.point_base_scale = point_base_scale
self.point_strides = point_strides
self.point_generators = [PointGenerator() for _ in self.point_strides]
self.sampling = loss_cls['type'] not in ['FocalLoss']
if self.train_cfg:
self.init_assigner = build_assigner(self.train_cfg.init.assigner)
self.refine_assigner = build_assigner(
self.train_cfg.refine.assigner)
# use PseudoSampler when sampling is False
if self.sampling and hasattr(self.train_cfg, 'sampler'):
sampler_cfg = self.train_cfg.sampler
else:
sampler_cfg = dict(type='PseudoSampler')
self.sampler = build_sampler(sampler_cfg, context=self)
self.transform_method = transform_method
if self.transform_method == 'moment':
self.moment_transfer = nn.Parameter(
data=torch.zeros(2), requires_grad=True)
self.moment_mul = moment_mul
self.use_sigmoid_cls = loss_cls.get('use_sigmoid', False)
if self.use_sigmoid_cls:
self.cls_out_channels = self.num_classes
else:
self.cls_out_channels = self.num_classes + 1
self.loss_bbox_init = build_loss(loss_bbox_init)
self.loss_bbox_refine = build_loss(loss_bbox_refine)
def _init_layers(self):
"""Initialize layers of the head."""
self.relu = nn.ReLU(inplace=True)
self.cls_convs = nn.ModuleList()
self.reg_convs = nn.ModuleList()
# 常规4层卷积堆叠
for i in range(self.stacked_convs):
chn = self.in_channels if i == 0 else self.feat_channels
self.cls_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg))
self.reg_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg))
# self.num_points表示9个语义点
# 如果use_grid_points,则表示学习delta xywh模式
pts_out_dim = 4 if self.use_grid_points else 2 * self.num_points
# 分类分支的dcn
self.reppoints_cls_conv = DeformConv2d(self.feat_channels,
self.point_feat_channels,
self.dcn_kernel, 1,
self.dcn_pad)
# 分类分支输出
self.reppoints_cls_out = nn.Conv2d(self.point_feat_channels,
self.cls_out_channels, 1, 1, 0)
# 第一次回归
self.reppoints_pts_init_conv = nn.Conv2d(self.feat_channels,
self.point_feat_channels, 3,
1, 1)
# 第一次回归的点位置输出,每个位置都要输出pts_out_dim
self.reppoints_pts_init_out = nn.Conv2d(self.point_feat_channels,
pts_out_dim, 1, 1, 0)
# 点回归分支的dcn
self.reppoints_pts_refine_conv = DeformConv2d(self.feat_channels,
self.point_feat_channels,
self.dcn_kernel, 1,
self.dcn_pad)
# 最终回归点输出
self.reppoints_pts_refine_out = nn.Conv2d(self.point_feat_channels,
pts_out_dim, 1, 1, 0)
def init_weights(self):
"""Initialize weights of the head."""
for m in self.cls_convs:
normal_init(m.conv, std=0.01)
for m in self.reg_convs:
normal_init(m.conv, std=0.01)
bias_cls = bias_init_with_prob(0.01)
normal_init(self.reppoints_cls_conv, std=0.01)
normal_init(self.reppoints_cls_out, std=0.01, bias=bias_cls)
normal_init(self.reppoints_pts_init_conv, std=0.01)
normal_init(self.reppoints_pts_init_out, std=0.01)
normal_init(self.reppoints_pts_refine_conv, std=0.01)
normal_init(self.reppoints_pts_refine_out, std=0.01)
def points2bbox(self, pts, y_first=True):
"""Converting the points set into bounding box.
:param pts: the input points sets (fields), each points
set (fields) is represented as 2n scalar.
:param y_first: if y_fisrt=True, the point set is represented as
[y1, x1, y2, x2 ... yn, xn], otherwise the point set is
represented as [x1, y1, x2, y2 ... xn, yn].
:return: each points set is converting to a bbox [x1, y1, x2, y2].
"""
pts_reshape = pts.view(pts.shape[0], -1, 2, *pts.shape[2:])
pts_y = pts_reshape[:, :, 0, ...] if y_first else pts_reshape[:, :, 1,
...]
pts_x = pts_reshape[:, :, 1, ...] if y_first else pts_reshape[:, :, 0,
...]
if self.transform_method == 'minmax':
bbox_left = pts_x.min(dim=1, keepdim=True)[0]
bbox_right = pts_x.max(dim=1, keepdim=True)[0]
bbox_up = pts_y.min(dim=1, keepdim=True)[0]
bbox_bottom = pts_y.max(dim=1, keepdim=True)[0]
bbox = torch.cat([bbox_left, bbox_up, bbox_right, bbox_bottom],
dim=1)
elif self.transform_method == 'partial_minmax':
pts_y = pts_y[:, :4, ...]
pts_x = pts_x[:, :4, ...]
bbox_left = pts_x.min(dim=1, keepdim=True)[0]
bbox_right = pts_x.max(dim=1, keepdim=True)[0]
bbox_up = pts_y.min(dim=1, keepdim=True)[0]
bbox_bottom = pts_y.max(dim=1, keepdim=True)[0]
bbox = torch.cat([bbox_left, bbox_up, bbox_right, bbox_bottom],
dim=1)
elif self.transform_method == 'moment': # 中心矩
# 均值和方差就是gt bbox的中心点
pts_y_mean = pts_y.mean(dim=1, keepdim=True)
pts_x_mean = pts_x.mean(dim=1, keepdim=True)
pts_y_std = torch.std(pts_y - pts_y_mean, dim=1, keepdim=True)
pts_x_std = torch.std(pts_x - pts_x_mean, dim=1, keepdim=True)
# self.moment_transfer也进行梯度增强操作
moment_transfer = (self.moment_transfer * self.moment_mul) + (
self.moment_transfer.detach() * (1 - self.moment_mul))
moment_width_transfer = moment_transfer[0]
moment_height_transfer = moment_transfer[1]
# 解码代码
half_width = pts_x_std * torch.exp(moment_width_transfer)
half_height = pts_y_std * torch.exp(moment_height_transfer)
bbox = torch.cat([
pts_x_mean - half_width, pts_y_mean - half_height,
pts_x_mean + half_width, pts_y_mean + half_height
],
dim=1)
else:
raise NotImplementedError
return bbox
def gen_grid_from_reg(self, reg, previous_boxes):
"""Base on the previous bboxes and regression values, we compute the
regressed bboxes and generate the grids on the bboxes.
:param reg: the regression value to previous bboxes.
:param previous_boxes: previous bboxes.
:return: generate grids on the regressed bboxes.
"""
# reg 预测的offset值(4个数),previous_boxes是预设bbox
b, _, h, w = reg.shape
bxy = (previous_boxes[:, :2, ...] + previous_boxes[:, 2:, ...]) / 2.
bwh = (previous_boxes[:, 2:, ...] -
previous_boxes[:, :2, ...]).clamp(min=1e-6)
# 回归输出的offset(4个数,表示xywh预测相对值)含义是相对预设bbox(2个点坐标)的偏移值
# 也就是预测的两个点其实和faster rcnn里面的bbox编码规则一样
grid_topleft = bxy + bwh * reg[:, :2, ...] - 0.5 * bwh * torch.exp(
reg[:, 2:, ...])
grid_wh = bwh * torch.exp(reg[:, 2:, ...])
grid_left = grid_topleft[:, [0], ...]
grid_top = grid_topleft[:, [1], ...]
grid_width = grid_wh[:, [0], ...]
grid_height = grid_wh[:, [1], ...]
# 网格模式输出grid_yx
# 因为reg预测的offset值是4个数,不是9个语义点,故需要转化为9个语义点,后面才可以继续算
# 故做法是得到bbox的左上右下坐标后,在该bbox内部,均匀采样9个点,就当做9个语义点即可
intervel = torch.linspace(0., 1., self.dcn_kernel).view(
1, self.dcn_kernel, 1, 1).type_as(reg)
grid_x = grid_left + grid_width * intervel
grid_x = grid_x.unsqueeze(1).repeat(1, self.dcn_kernel, 1, 1, 1)
grid_x = grid_x.view(b, -1, h, w) # b,9,h,w
grid_y = grid_top + grid_height * intervel
grid_y = grid_y.unsqueeze(2).repeat(1, 1, self.dcn_kernel, 1, 1)
grid_y = grid_y.view(b, -1, h, w)
grid_yx = torch.stack([grid_y, grid_x], dim=2)
grid_yx = grid_yx.view(b, -1, h, w)
# 变成xyxy格式
regressed_bbox = torch.cat([
grid_left, grid_top, grid_left + grid_width, grid_top + grid_height
], 1)
return grid_yx, regressed_bbox
def forward(self, feats):
return multi_apply(self.forward_single, feats)
def forward_single(self, x):
"""Forward feature map of a single FPN level."""
dcn_base_offset = self.dcn_base_offset.type_as(x)
# If we use center_init, the initial reppoints is from center points.
# If we use bounding bbox representation, the initial reppoints is
# from regular grid placed on a pre-defined bbox.
if self.use_grid_points or not self.center_init:
scale = self.point_base_scale / 2
# bbox预测模式
points_init = dcn_base_offset / dcn_base_offset.max() * scale
# 初始bbox
bbox_init = x.new_tensor([-scale, -scale, scale,
scale]).view(1, 4, 1, 1)
else:
points_init = 0
cls_feat = x
pts_feat = x
for cls_conv in self.cls_convs:
cls_feat = cls_conv(cls_feat)
for reg_conv in self.reg_convs:
pts_feat = reg_conv(pts_feat)
# 初始化预测每个点的offset
pts_out_init = self.reppoints_pts_init_out(
self.relu(self.reppoints_pts_init_conv(pts_feat)))
if self.use_grid_points:
# bbox模式,输出通道是4表示相当于anchor的bbox_init的wywh预测,可以还原得到bbox,然后利用用网格做法将其转化为9个语义点
pts_out_init, bbox_out_init = self.gen_grid_from_reg(
pts_out_init, bbox_init.detach())
else:
# 本身通道就是9个语义点offset,无须操作
pts_out_init = pts_out_init + points_init
# refine and classify reppoints
# 预测值不变,但是梯度乘上了self.gradient_mul
pts_out_init_grad_mul = (1 - self.gradient_mul) * pts_out_init.detach(
) + self.gradient_mul * pts_out_init
# 很容易就可以得到dcn的offset新坐标
dcn_offset = pts_out_init_grad_mul - dcn_base_offset
# 分类输出
cls_out = self.reppoints_cls_out(
self.relu(self.reppoints_cls_conv(cls_feat, dcn_offset)))
# 点offset输出refine
pts_out_refine = self.reppoints_pts_refine_out(
self.relu(self.reppoints_pts_refine_conv(pts_feat, dcn_offset)))
if self.use_grid_points:
pts_out_refine, bbox_out_refine = self.gen_grid_from_reg(
pts_out_refine, bbox_out_init.detach())
else:
# 直接相加就可以得到最终offset
pts_out_refine = pts_out_refine + pts_out_init.detach()
return cls_out, pts_out_init, pts_out_refine
def get_points(self, featmap_sizes, img_metas, device):
"""Get points according to feature map sizes.
Args:
featmap_sizes (list[tuple]): Multi-level feature map sizes.
img_metas (list[dict]): Image meta info.
Returns:
tuple: points of each image, valid flags of each image
"""
num_imgs = len(img_metas)
num_levels = len(featmap_sizes)
# since feature map sizes of all images are the same, we only compute
# points center for one time
multi_level_points = []
for i in range(num_levels):
# 为特征图的每个点生成相对原图左上角坐标(没有偏移0.5),额外stack上stride
# points shape=(wxh,3),3表示原图x,y坐标,stride
points = self.point_generators[i].grid_points(
featmap_sizes[i], self.point_strides[i], device)
multi_level_points.append(points)
# 每张图片都clone一遍,方便后面运算
points_list = [[point.clone() for point in multi_level_points]
for _ in range(num_imgs)]
# for each image, we compute valid flags of multi level grids
valid_flag_list = []
for img_id, img_meta in enumerate(img_metas):
multi_level_flags = []
for i in range(num_levels):
point_stride = self.point_strides[i]
feat_h, feat_w = featmap_sizes[i]
h, w = img_meta['pad_shape'][:2]
valid_feat_h = min(int(np.ceil(h / point_stride)), feat_h)
valid_feat_w = min(int(np.ceil(w / point_stride)), feat_w)
flags = self.point_generators[i].valid_flags(
(feat_h, feat_w), (valid_feat_h, valid_feat_w), device)
multi_level_flags.append(flags)
valid_flag_list.append(multi_level_flags)
return points_list, valid_flag_list
def centers_to_bboxes(self, point_list):
"""Get bboxes according to center points.
Only used in :class:`MaxIoUAssigner`.
"""
bbox_list = []
for i_img, point in enumerate(point_list):
bbox = []
for i_lvl in range(len(self.point_strides)):
scale = self.point_base_scale * self.point_strides[i_lvl] * 0.5
bbox_shift = torch.Tensor([-scale, -scale, scale,
scale]).view(1, 4).type_as(point[0])
bbox_center = torch.cat(
[point[i_lvl][:, :2], point[i_lvl][:, :2]], dim=1)
bbox.append(bbox_center + bbox_shift)
bbox_list.append(bbox)
return bbox_list
def offset_to_pts(self, center_list, pred_list):
"""Change from point offset to point coordinate."""
pts_list = []
for i_lvl in range(len(self.point_strides)):
pts_lvl = []
for i_img in range(len(center_list)):
# :2是特征图点对应的原图尺度左上角xy坐标值
pts_center = center_list[i_img][i_lvl][:, :2].repeat(
1, self.num_points)
pts_shift = pred_list[i_lvl][i_img]
yx_pts_shift = pts_shift.permute(1, 2, 0).view(
-1, 2 * self.num_points)
y_pts_shift = yx_pts_shift[..., 0::2]
x_pts_shift = yx_pts_shift[..., 1::2]
xy_pts_shift = torch.stack([x_pts_shift, y_pts_shift], -1)
xy_pts_shift = xy_pts_shift.view(*yx_pts_shift.shape[:-1], -1)
# 还原到原图坐标=预测offset乘上stride+原图左上角坐标值
# 可以看出预测的offset值是在特别图尺度,且实际上是相对于原图左上角偏移
pts = xy_pts_shift * self.point_strides[i_lvl] + pts_center
pts_lvl.append(pts)
pts_lvl = torch.stack(pts_lvl, 0)
pts_list.append(pts_lvl)
return pts_list
def _point_target_single(self,
flat_proposals,
valid_flags,
gt_bboxes,
gt_bboxes_ignore,
gt_labels,
label_channels=1,
stage='init',
unmap_outputs=True):
inside_flags = valid_flags
if not inside_flags.any():
return (None,) * 7
# assign gt and sample proposals
proposals = flat_proposals[inside_flags, :]
if stage == 'init': # 初始训练
assigner = self.init_assigner
pos_weight = self.train_cfg.init.pos_weight
else: # refine训练
assigner = self.refine_assigner
pos_weight = self.train_cfg.refine.pos_weight
# proposals实际上是point坐标,不是anchor坐标
# 得到特征图上面每个点应该负责哪个gt bbox
assign_result = assigner.assign(proposals, gt_bboxes, gt_bboxes_ignore,
None if self.sampling else gt_labels)
# 伪随机
sampling_result = self.sampler.sample(assign_result, proposals,
gt_bboxes)
num_valid_proposals = proposals.shape[0]
bbox_gt = proposals.new_zeros([num_valid_proposals, 4])
pos_proposals = torch.zeros_like(proposals)
proposals_weights = proposals.new_zeros([num_valid_proposals, 4])
labels = proposals.new_full((num_valid_proposals,),
self.num_classes,
dtype=torch.long)
label_weights = proposals.new_zeros(
num_valid_proposals, dtype=torch.float)
pos_inds = sampling_result.pos_inds
neg_inds = sampling_result.neg_inds
if len(pos_inds) > 0:
pos_gt_bboxes = sampling_result.pos_gt_bboxes
bbox_gt[pos_inds, :] = pos_gt_bboxes
pos_proposals[pos_inds, :] = proposals[pos_inds, :]
proposals_weights[pos_inds, :] = 1.0
if gt_labels is None:
# Only rpn gives gt_labels as None
# Foreground is the first class
labels[pos_inds] = 0
else:
labels[pos_inds] = gt_labels[
sampling_result.pos_assigned_gt_inds]
if pos_weight <= 0:
label_weights[pos_inds] = 1.0
else:
label_weights[pos_inds] = pos_weight
if len(neg_inds) > 0:
label_weights[neg_inds] = 1.0
# map up to original set of proposals
if unmap_outputs:
num_total_proposals = flat_proposals.size(0)
labels = unmap(labels, num_total_proposals, inside_flags)
label_weights = unmap(label_weights, num_total_proposals,
inside_flags)
bbox_gt = unmap(bbox_gt, num_total_proposals, inside_flags)
pos_proposals = unmap(pos_proposals, num_total_proposals,
inside_flags)
proposals_weights = unmap(proposals_weights, num_total_proposals,
inside_flags)
return (labels, label_weights, bbox_gt, pos_proposals,
proposals_weights, pos_inds, neg_inds)
def get_targets(self,
proposals_list,
valid_flag_list,
gt_bboxes_list,
img_metas,
gt_bboxes_ignore_list=None,
gt_labels_list=None,
stage='init',
label_channels=1,
unmap_outputs=True):
"""Compute corresponding GT box and classification targets for
proposals.
Args:
proposals_list (list[list]): Multi level points/bboxes of each
image.
valid_flag_list (list[list]): Multi level valid flags of each
image.
gt_bboxes_list (list[Tensor]): Ground truth bboxes of each image.
img_metas (list[dict]): Meta info of each image.
gt_bboxes_ignore_list (list[Tensor]): Ground truth bboxes to be
ignored.
gt_bboxes_list (list[Tensor]): Ground truth labels of each box.
stage (str): `init` or `refine`. Generate target for init stage or
refine stage
label_channels (int): Channel of label.
unmap_outputs (bool): Whether to map outputs back to the original
set of anchors.
Returns:
tuple:
- labels_list (list[Tensor]): Labels of each level.
- label_weights_list (list[Tensor]): Label weights of each level. # noqa: E501
- bbox_gt_list (list[Tensor]): Ground truth bbox of each level.
- proposal_list (list[Tensor]): Proposals(points/bboxes) of each level. # noqa: E501
- proposal_weights_list (list[Tensor]): Proposal weights of each level. # noqa: E501
- num_total_pos (int): Number of positive samples in all images. # noqa: E501
- num_total_neg (int): Number of negative samples in all images. # noqa: E501
"""
assert stage in ['init', 'refine']
num_imgs = len(img_metas)
assert len(proposals_list) == len(valid_flag_list) == num_imgs
# points number of multi levels
num_level_proposals = [points.size(0) for points in proposals_list[0]]
# concat all level points and flags to a single tensor
for i in range(num_imgs):
assert len(proposals_list[i]) == len(valid_flag_list[i])
proposals_list[i] = torch.cat(proposals_list[i])
valid_flag_list[i] = torch.cat(valid_flag_list[i])
# compute targets for each image
if gt_bboxes_ignore_list is None:
gt_bboxes_ignore_list = [None for _ in range(num_imgs)]
if gt_labels_list is None:
gt_labels_list = [None for _ in range(num_imgs)]
(all_labels, all_label_weights, all_bbox_gt, all_proposals,
all_proposal_weights, pos_inds_list, neg_inds_list) = multi_apply(
self._point_target_single,
proposals_list,
valid_flag_list,
gt_bboxes_list,
gt_bboxes_ignore_list,
gt_labels_list,
stage=stage,
label_channels=label_channels,
unmap_outputs=unmap_outputs)
# no valid points
if any([labels is None for labels in all_labels]):
return None
# sampled points of all images
num_total_pos = sum([max(inds.numel(), 1) for inds in pos_inds_list])
num_total_neg = sum([max(inds.numel(), 1) for inds in neg_inds_list])
labels_list = images_to_levels(all_labels, num_level_proposals)
label_weights_list = images_to_levels(all_label_weights,
num_level_proposals)
bbox_gt_list = images_to_levels(all_bbox_gt, num_level_proposals)
proposals_list = images_to_levels(all_proposals, num_level_proposals)
proposal_weights_list = images_to_levels(all_proposal_weights,
num_level_proposals)
return (labels_list, label_weights_list, bbox_gt_list, proposals_list,
proposal_weights_list, num_total_pos, num_total_neg)
def loss_single(self, cls_score, pts_pred_init, pts_pred_refine, labels,
label_weights, bbox_gt_init, bbox_weights_init,
bbox_gt_refine, bbox_weights_refine, stride,
num_total_samples_init, num_total_samples_refine):
# classification loss
labels = labels.reshape(-1)
label_weights = label_weights.reshape(-1)
cls_score = cls_score.permute(0, 2, 3,
1).reshape(-1, self.cls_out_channels)
cls_score = cls_score.contiguous()
loss_cls = self.loss_cls(
cls_score,
labels,
label_weights,
avg_factor=num_total_samples_refine)
# points loss
bbox_gt_init = bbox_gt_init.reshape(-1, 4)
bbox_weights_init = bbox_weights_init.reshape(-1, 4)
# 需要转化为bbox才能计算loss
bbox_pred_init = self.points2bbox(
pts_pred_init.reshape(-1, 2 * self.num_points), y_first=False)
bbox_gt_refine = bbox_gt_refine.reshape(-1, 4)
bbox_weights_refine = bbox_weights_refine.reshape(-1, 4)
bbox_pred_refine = self.points2bbox(
pts_pred_refine.reshape(-1, 2 * self.num_points), y_first=False)
normalize_term = self.point_base_scale * stride
loss_pts_init = self.loss_bbox_init(
bbox_pred_init / normalize_term,
bbox_gt_init / normalize_term,
bbox_weights_init,
avg_factor=num_total_samples_init)
loss_pts_refine = self.loss_bbox_refine(
bbox_pred_refine / normalize_term,
bbox_gt_refine / normalize_term,
bbox_weights_refine,
avg_factor=num_total_samples_refine)
return loss_cls, loss_pts_init, loss_pts_refine