前言
一直以来,在目标检测中,边界框是处理的基本元素:在图像中先定位目标的边界框,再从边界框中提取特征,最后基于边界框里提取的特征进行目标的识别和推理。
但是,基于边界框的目标表示也有一些缺点,它们只提供一个粗略的目标定位,并不完全拟合目标的形状和姿态。此外,从边界框的规则网格中提取的特征可能会受到背景或包含少量语义信息的前景区域的严重影响。这些都会使提取的特征质量变低,从而降低了目标检测的分类性能。
本文提出了一种新的目标表示方式,称为RepPoints,它能提供更细粒度的分类和更方便的定位,如下图所示:

RepPoints能自适应地分布在目标重要的局部语义区域,并能表征目标的几何外延,从而提供了一个对目标更加细致的几何描述,同时这些点也能用于提取对识别有帮助的图像特征。
RepPoints的学习由两项监督信息驱动,分别是目标定位与目标识别,因此RepPoints与gt box紧密相关,并引导检测器实现正确的目标分类。RepPoints可以被连贯地用于目标检测器的不同阶段,并且不需要anchor。
现有的非矩形表示目标的检测器,它们都是以自底向上的方式构建的,它们的表示依然像边界框那样是轴对齐的,或者需要gt作为额外的监督。而RepPoints是以自顶向下的方式从输入图像/特征中学习的,允许端到端的训练,并且不需要额外监督就能实现细粒度的目标定位。
边界框表示
边界框是对目标的空间位置的4-d表示,
,其中
表示中心点,
分别表示宽和高。在多阶段目标检测器中,目标定位是逐步细化的。目标表示的过程如下:

在first stage,对于一个anchor,位于其中心处的图像特征被采用为目标特征,然后根据这个目标特征产生一个置信度分数,表示这个anchor中是否包含一个目标,还要通过边界框回归产生refined bbox。如上式,refined bbox被记为"bbox proposal(S1)".
在second stage,refined feature通过RoI-pooling或者RoI-Align从refined bbox中提取出来。对于一个two-stage的检测器来说,这个refined feature会通过边界框回归产生最终的bbox;对于multi-stage检测器来说,refined feature会通过边界框回归生成中间的refined bbox proposal(S2),如上式所示。
在边界框回归中,用一个4-d的回归向量
将当前的bbox
映射到一个refined bbox
:
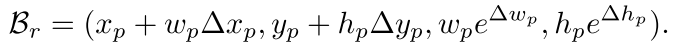
给定gt box
,边界框回归的目标就是让
和
靠的尽可能近。具体来说,在训练检测器时,将predicted回归向量和expected回归向量之间的距离作为学习目标,用smooth L1 loss:
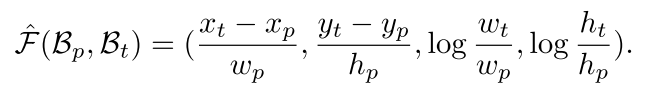
当这个距离很大的时候,边界框回归的性能会变得很差。
RepPoints
边界框表示只考虑目标的矩形空间范围,并不考虑目标的形状、姿态和重要的局部语义区域,而这些可用于更精细的定位和更好的特征提取。
为了克服边界框表示的局限,RepPoints基于点集来替代边界框的目标表示,对一组自适应样本点进行建模:
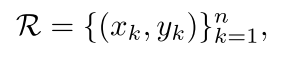
其中
是用于表示的样本点的数量,实验中
默认设置为9。
1. RepPoints的细化
细化bbox的位置和特征提取对于multi-stage目标检测器的成功是非常重要的。对于RepPoints,这种细化可以被表示为:
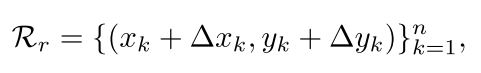
其中
是新的样本点相对于旧样本点之间的offset。作者注意到,这个细化并没有处理不同尺度的bbox回归的参数问题,因为在细化过程中offset的尺度都是一样的。
2. 将RepPoints转换为bbox
通过一个预定义的转换方程来将RepPoints转换为bbox:
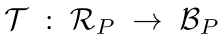
其中
表示目标
的RepPoints,
表示一个pseudo box
在这个转换过程中有以下3个转换方程:
- :Min-max function。在RepPoints上,对两个轴线执行min-max操作以确定 , 相当于采样点上的bbox;
- :Partial min-max function。在两个轴线上,对采样点的子集进行min-max操作,以获得矩形框 ;
- :Moment-based function。用RepPoints的均值和标准差计算矩形框 中心点和尺度,其中尺度要与全局共享的可学习乘数 和 相乘。
这些方程都是可微的,保证了端到端的训练。
3. RepPoints的学习
RepPoints的学习是由目标定位损失与目标识别损失共同驱动的。为了计算目标定位损失,首先通过转换方程将
将RepPoints转换为pseudo box,然后计算pseudo box和gt box之间的差异。在网络中,用左上角和右下角之间的smooth
距离表示定位损失。这个smooth
距离不需要调整不同损失所占的权重。下图说明当训练由这两种损失驱动时,目标的极点和语义关键点会自动学习。

RPDet
本文基于RepPoints设计了一个anchor-free的目标检测器,称为RepPoints Detector(REDet),它采用FPN作为主干网络。它的目标表示过程如下:
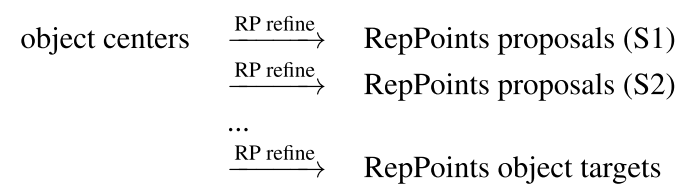
RPDet包括两个基于deformable conv的识别阶段,deformable conv和RepPoints很好地结合在一起,因为其卷积是在不规则分布的采样点集合上计算的,反之,其识别反馈可以指导训练这些点的位置。
1. 基于中心点的初始目标表示
本文像YOLO和DenseBox那样使用中心点作为初始的目标表示。使用中心点表示的一个很重要的好处是,与anchor-based方法相比,它的假设空间更紧密。
但是,基于中心点的表示方法也会遇到模糊识别的问题,比如两个不同目标的中心点在特征图中的位置可能是一样的。在RPDet中,这个问题可以通过FPN解决,原因如下:
- 不同尺度的目标被分配到不同层级的特征图中,这不仅解决了多尺度目标的问题,也大大降低了不同尺度目标的中心点在同一位置的可能性;
- FPN使用高分辨率的特征图来处理小目标,由于高分辨率的特征图的细节信息更详细,这也能降低两个不同的目标的中心点在同一位置的可能性。
在实验中,在采用FPN之后,COCO数据集中只有1.1%的目标的中心点会位于特征图中的同一位置。
2. 如何利用RepPoints

如上图所示,RepPoints在整个网络中作为基础的目标表示方法。从中心点开始,将一个3x3的卷积应用于这个点的图像特征上,回归出多个目标点和中心源点的偏移值,这些目标点共同构成RepPoints点集。RepPoints的学习由两项监督信息驱动:
- pseudo box与gt box之间左上角和右下角的距离损失;
- 后面阶段的目标识别损失。
通过下式将RepPoints进行细化,得到的第二组RepPoints用来表示最终的目标定位。这组RepPoints的学习只由距离损失驱动,学习更精细的目标定位。也就是说在RPDet中,定位分为两个阶段,每个阶段都有一组RepPoints,其中第二组RepPoints是由第一组经过细化后得到的。
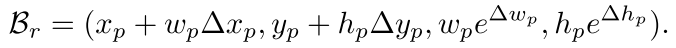
3. 与deformable RoI pooling的关系
在目标检测中,deformable RoI pooling与RepPoints的作用是不同的。RepPoints是对目标的几何表示,反映了具有更重要的语义信息的位置。而deformable RoI pooling更适合学习目标的更强大的外观特征。事实上,deformable RoI pooling无法学习能够表示目标精确位置的采样点。作者注意到,deformable RoI pooling与RepPoints之间是互补的关系。如下表所示,在采用deformable RoI pooling后,使用RepPoints的检测器的性能得到了增强。

4. backbone and head architectures
FPN主干网络生成了
到
五层特征图的特征金字塔,这些特征图然后被输入到detection head中。head architecture如下图所示,可以看到head包括两个子网,它们之间不共享参数。一个用于定位(生成RepPoints),一个用于分类。

定位子网首先采用3个256-d 3 × 3 conv层,后接两个连续的conv计算两组RepPoints的offset。分类子网也采用了3个256-d 3 × 3 conv层,后接一个256-d 3 × 3 deformable conv层,它的输入的offet域和定位子网中第一个deformable conv的输入offset是共享的,如图中两个绿色的方块是deformable conv,它们输入的offset是相同的。在每个子网中的前三个256-d 3 × 3 conv层之后,接一个group normalization层。
即使RPDet中,目标定位包含两个阶段,但依然比one-stage的目标检测器如RetinaNet更有效率。由于层之间的共享,额外的定位阶段引入的开销是很小的。
5. 定位与分类
定位分为两个阶段:
- 通过对目标中心点(feature map bin)进行细化得到第一组RepPoints;
- 通过对第一组RepPoints进行细化得到第二组RepPoints。
在每个阶段,训练时只对正样本进行定位。对于第一个阶段,一个中心点是正样本需要满足以下条件:
- 这个中心点所处的特征金字塔的层级,需要与gt box大小的log值相等:
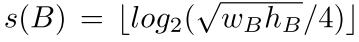
- gt的中心点与该目标中心点位于一个feature map bin之内。
对于第二个阶段,如果RepPoint的pseudo box与gt之间的IoU大于0.5,这个RepPoint就是正样本。
分类只在第一组RepPoints上进行。 只有当RepPoints的pseudo box与gt之间的IoU大于0.5(正样本)或小于0.4(背景),才对这些RepPoints进行分类,不考虑其他的RepPoints。用focal loss来训练分类器。
