Integrating distributional lexical contrast into word embeddings for antonym synonym
文章目录
1 论文出处
会议/期刊:ACL(Annual Meeting of the Association for Computational Linguistics )
级别:CCF-A
时间:2016
2 背景
2.1 背景介绍
近义词与反义词是一中非常重要的语义关系,在nlp中应用广泛,由于它们在文本中可以互相替换着出现,所以区分它们颇具挑战。目前的方法认为具有相似分布的词汇有着相关的含义,于是倾向于构建词向量的方式来区分近义词与反义词。
2.2 针对问题
如何较好地利用分布语义空间中的词汇对比信息和词汇嵌入进行反义词和同义词区分。
2.3 创新点
- 将词汇对比纳入分布向量,并加强那些对确定单词相似性最显著的单词特征。
- 提出了一种新的具有负抽样的skip-gram的扩展,该模型将词汇对比信息集成到目标函数中。
3 主要设计思路
3.1 改进特征向量的权重

-
使用同义词与目标词相似度的均值和反义词与目标词的均值,计算这两个均值的差,使用这个差值更新weight 分数。使用consine计算向量的相似度即sim()。
-
如果目标词在现有的词表中没有同义词或反义词,或没有特征与目标词共现,则weight=0
-
词的最强特征倾向于代表其同义词的强特征,同时对反义词较弱。
-
通常反义词比同义词少很多,为丰富反义词,可使用反义词的同义词扩展;例如:good只有两个反义词在WordNet数据集中(bad和evil),而有31个同义词,此时可使用bad和evil的同义词作为good的反义词。
3.2 将分布的词汇对比度整合到一个skip-gram模型中
使用负采样的skip-gram模型的目标函数:
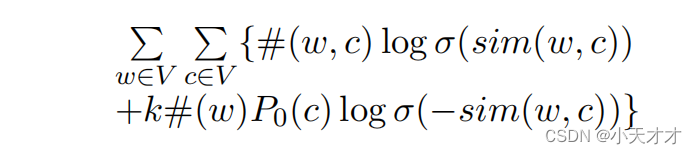
4 实验设计
本文使用EN-COW14A数据集,原始的向量表示和词向量模型的窗口大小为 5;词向量维度为500,负样本k为15;排除数据集中少于100到的词汇;使用SGD反向传播更新参数;学习率为0.025;使用WordNet和Wordnik收集反义词和同义词,共363309同义词和38423反义词对。


5 个人总结
- 本文提出了新式的向量表示,提高预测词汇的相似度,对传统的分布式语义模型和词向量模型都有效。此方法通过使用词汇对比信息提高了权重特征的质量以区分同义词和反义词;结合词汇对比信息和skip-gram 模型预测相似、确定反义词。
- 提高了权重特征的质量以区分同义词和反义词;结合词汇对比信息和skip-gram 模型预测相似、确定反义词。
- 对于一个没有近义词与反义词与其相关的单词,直接将权重赋值为0可能会丧失其语义。