【小样本实体识别】Few-NERD——基于N-way K-shot的实体识别数据集和方法介绍
前记:
实体识别是信息抽取领域中比较重要的任务,其在学术界和工业界都是有很广泛的应用前景。但是当前实体识别任务强依赖于大量精细标注的数据,导致很难适应于快速迭代与实际业务快速发展的脚步。为了能够快速地在某个新的领域知识内,使用非常少的标注数据来达到更好效果,尤其是在学术界成为当前比较热门的话题。总的来说,我们引入新的研究课题——小样本实体识别(Few-shot Named Entity Recognition)。
本文介绍一个近期的有关few-shot NER的benchmark工作,引出基于元学习的NER数据集及baseline。
核心要点:
- 提出一种新的Few-shot NER数据集和benchmark,在语料数量、实体数量、实体类型数量上比现有数据集更有优势;
- 针对实体类型,划分了粗粒度和细粒度,并提出 N N N-way K K K~ 2 K 2K 2K-shot 的Few-shot NER划分方案;
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 数据集名称 | Few-NERD |
| 2 | 发表位置 | ACL2021 |
| 3 | 所属领域 | 自然语言处理、信息抽取 |
| 4 | 研究内容 | 基于小样本学习的实体识别 |
| 5 | 核心内容 | Few-shot Learning,NER,Prototypical Learning,Metric Learning |
| 6 | GitHub源码 | https://ningding97.github.io/fewnerd/ |
| 7 | 论文PDF | https://aclanthology.org/2021.acl-long.248.pdf |
一、动机
- 深度学习模型(传统的神经网络、预训练语言模型等)在标注数据充足的情况下可以在full-supervised NER上达到较好效果;
- 但是我们认为few-shot NER更切合实际场景,即unseen entity type只有少量样本;目前市面上缺乏这种专门为few-shot NER设计的数据集;
- 先前的一些数据集(例如OntoNotes、CoNLL’03、WNUT’17等)粗粒度的实体类型数量过少,而且真实场景下unseen entity均为细粒度的;
二、任务定义
对于传统的分类任务,基本上是基于句子进行分类,因此定义小样本则可以使用基于episode的 N N N-way K K K-shot规则。即一个小样本学习过程(episode)只有 N N N个类别,每个类别下只有 K K K 个句子。
我们回顾一下传统的episode训练过程,我们以Prototype Network(原型网络)为例:
- 首先随机采样一个episode data。 每个episode data包含 support set(支持集)和query set (查询集)。对于support set而言,其包含 N N N个类别,每个类别下只有 K K K 个句子,即每个support set只有 N × K N\times K N×K 个样本。而对于query set则比较随意,可以只有1个句子,也可以有多个句子,也可以遵循 N N N-way K K K-shot 规则;
- 对于每个episode data,在support set上获得原型向量。对于每个类的 K K K 个句子,获得其句子表征后,对所有句子进行平均后即可得到当前类的原型向量(prototype)。因此support set可以得到 N N N 个prototype。
- 对于query set里的每一个样本,根据其标注的类别,计算分类损失。因为在训练时,每个query example是有标签的,所以获得query句子的表征向量后,与 N N N 个prototype计算距离作为预测的logit,并使用交叉信息熵作为目标函数。
在测试阶段,此时我们只有有标注的support set和无标注的query set,此时执行模型推理,先获得support set的prototype,再对每个query计算其与各个prototype的距离,并取最近的作为预测结果。
但是不同于分类,NER是基于token的分类,其旨在对每个token进行序列标注,因此无法直接使用传统的 N N N-way K K K-shot 规则。因此本文重新定义了episode规则。Few-shot NER定义
挑战:
- NER是在token-level级别的分类,而不是sentence-level的分类,而且每个句子可能包含很多类型的实体。但是在划分时必须是以sentence为主,因为不同句子的语义会影响实体的类型
However, in the sequence labeling problem like NER, a sentence may contain multiple entities from different classes. And it is imperative(至关重要) to sample examples in sentence-level since contextual information is crucial for sequence labeling problems, especially for NER. Thus the sampling is more difficult than conventional classification tasks like relation extraction.
- 例如5-way 5-shot,则必须确保这5个样本中只能包含5个类型的实体,这是很难采样这么精准的,换句话说,无法确保随机采样得到的一个episode data包含5个不同类别,且每个类别正好5个实体。
For example, when it comes to a 5-way 5-shot setting, if the support set already had 4 classes with 5 exam ples and 1 class with 4 examples, the next sampled sentence must only contain the specific one entity to strictly meet the requirement of 5 way 5 shot
- 因此,本文提出 N N N-way K K K~ 2 K 2K 2K-shot 规则,即给定的 N N N 个entity type class,只要确保采样的样本数量在 K K K~ 2 K 2K 2K 之间即可,相当于放宽了对每个类别对应实体数量的强行约束。
例如,N=5时,K=5,则每个类的样本数量可以是8,9,5,7,5。且所有样本涉及到的所有实体只能是这5个类。
为了满足这个规则,我们实现了采样算法,如下图所示:

三、Few-NERD——大规模多粒度小样本实体识别评测基准
基于Few-shot NER的任务定义,我们进行人工打标+机器处理的过程获得了新的数据集Few-NERD。具体体现在如下三点:
- 参考FIGER,粗粒度实体类型有8个。细粒度有66个
- 语料来自于Wikipedia English dumps,对于每个细粒度实体类,随机挑选1000个paragraph进行人工标注,每个paragraph平均包含61.3个tokens
- 邀请70个标注者和10位专家进行标注和检查;
Few-NERD数据分布情况如下:
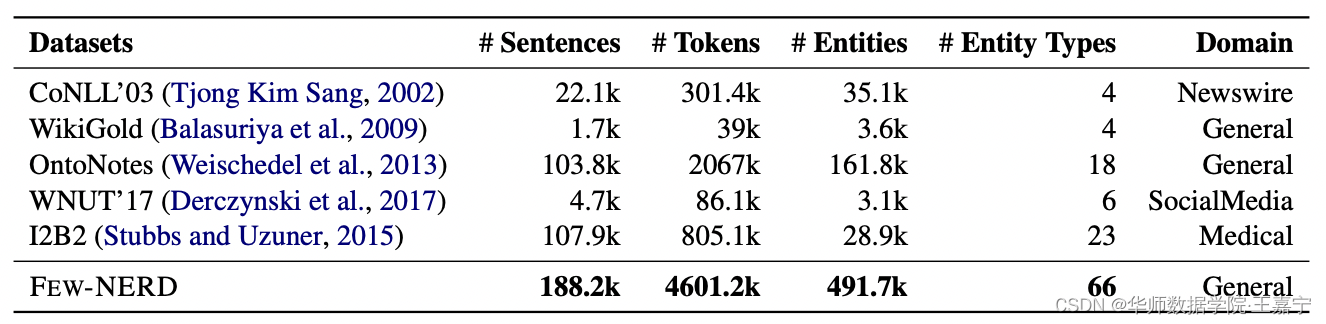
数据集中包含了18万余句子460万余token(分词),近50万个实体,类别数量则有66个。而现有的其他数据集本质并非是小样本场景,因此Few-NERD是首个为few-shot量身定制的数据集。
为了验证构建的数据集是有效的,进行了一些简单的实验,如下图所示:
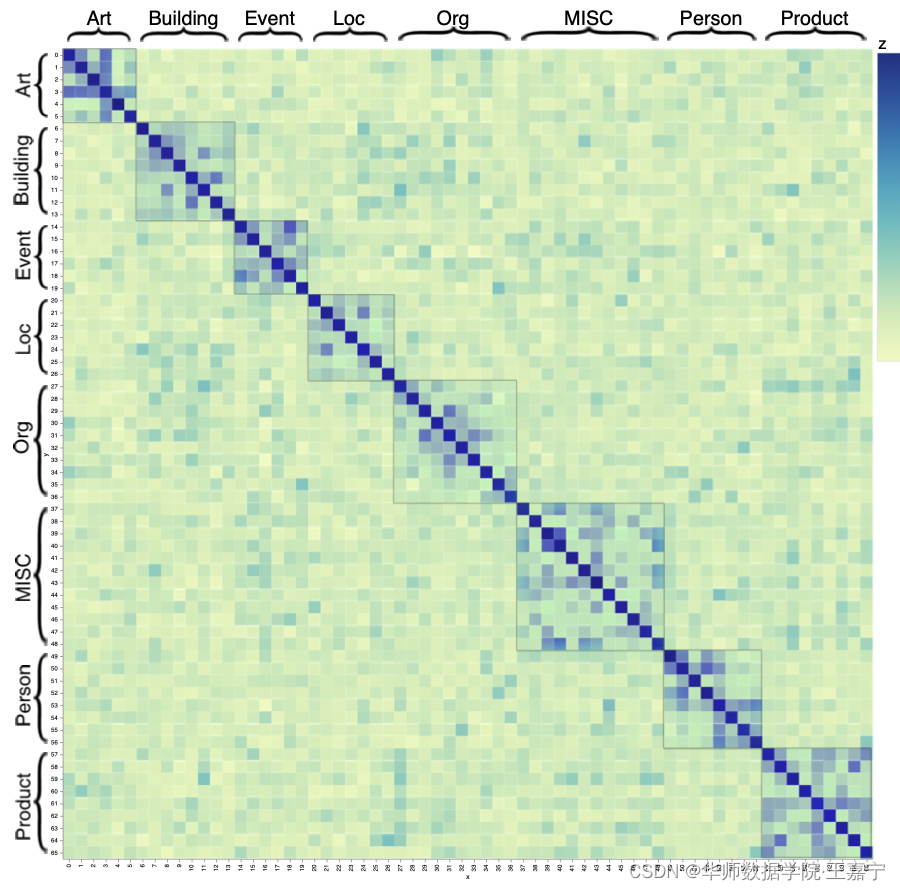
对66个细粒度实体类进行两两相似度的计算,发现同属于一个粗粒度实体类的所有细粒度实体类更加相似,具备transfer能力,而不同粗粒度实体之间差异较大。
基于构建好的数据集,我们提出三种基准,分别是监督模式、Intra模式和Inter模式:
- Few-NERD(SUP):标准的监督学习模式,随机对所有语料进行采样。70%作为训练集,10%作为验证集,20%作为测试集,三个集合均都包含66个细粒度实体类;
- Few-shot NER:根据实体类型划分训练集、验证集和测试集,确保每个数据集中只包含部分实体类,且各个数据集的实体类之间不存在交叉;具体的包括:
(1)Few-NERD(INTRA):按照粗粒度的实体进行分类。例如训练集:People, MISC, Art, Product,验证集:Event, Building,测试集:ORG, LOC;由于不同粗粒度之间相关性很低,所以该任务具有挑战性;
(2) Few-NERD(INTER):按照细粒度进行划分。每个粗粒度类中,均随机挑选60%的细粒度实体类作为训练集,同理,每个粗粒度类中随机挑选20%、20%作为验证集和测试集。该设定下,每个数据集都涉及到所有粗粒度实体类,而需要考察细粒度实体类之间的泛化性能。
作者提供了预处理好的三种基准数据集,对应的数据分布情况如图所示:
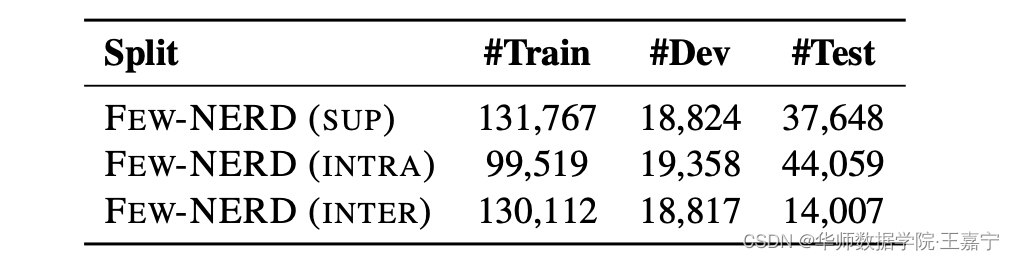
其中,一个episode data的数据格式如下所示:
{
"support": {
"word": [
["averostra", ",", "or", "``", "bird", "snouts", "''", ",", "is", "a", "clade", "that", "includes", "most", "theropod", "dinosaurs", "that", "have", "a", "promaxillary", "fenestra", "(", "``", "fenestra", "promaxillaris", "``", ")", ",", "an", "extra", "opening", "in", "the", "front", "outer", "side", "of", "the", "maxilla", ",", "the", "bone", "that", "makes", "up", "the", "upper", "jaw", "."],
["since", "that", "time", ",", "the", "squadron", "made", "several", "extended", "indian", "ocean", ",", "mediterranean", "sea", ",", "and", "north", "atlantic", "deployments", "as", "part", "of", "cvw-1", "/", "cv-66", ",", "until", "the", "decommissioning", "of", "uss", "``", "america", "''", "in", "1996", "."],
...
],
"label": [
["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "other-biologything", "other-biologything", "O", "O", "other-biologything", "other-biologything", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "other-biologything", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"],
["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "product-ship", "O", "product-ship", "O", "O", "O", "O", "O", "product-ship", "product-ship", "product-ship", "product-ship", "O", "O", "O"],
...
]
},
"query": {
"word": [["the", "final", "significant", "change", "in", "the", "life", "of", "the", "coco", "2", "(", "models", "26-3134b", ",", "26-3136b", ",", "and", "26-3127b", ";", "16", "kb", "standard", ",", "16", "kb", "extended", ",", "and", "64", "kb", "extended", "respectively", ")", "was", "to", "use", "the", "enhanced", "vdg", ",", "the", "mc6847t1", ",", "allowing", "lowercase", "characters", "and", "changing", "the", "text", "screen", "border", "color", "."],
...
],
"label": [["O", "O", "O", "O", "O", "O", "O", "O", "O", "product-software", "product-software", "O", "O", "product-software", "O", "product-software", "O", "O", "product-software", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "product-software", "O", "O", "product-software", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"],
...
]
},
"types": ["other-biologything", "building-airport", "location-island", "product-ship", "product-software"]
}
四、baseline及其代码
我们暂时只关注Few-shot场景,因为最终依然遵循类似 N N N-way K K K-shot 的规则,因此可以使用度量学习的方法,例如Prototypical Learning。具体细节如下:
- 采样获得一个episode数据,其包含support set和query set,均遵循 N N N-way K K K~ 2 K 2K 2K-shot 的规则;
- 对于support set,句子的数量是不确定的,但是我们依然将所有句子喂入encoder里(例如BERT)获得每个句子每个token的表示向量;
- 由于已经知道每个句子的各个token的标签(BIO规则) ,因此根据标签,将各个类别的token向量汇总起来,并计算prototype;
- 对于query set的每个句子的每个token,计算其与各个prototype的距离,并使用交叉信息熵计算损失。
作者开源了数据集以及代码框架,详见https://ningding97.github.io/fewnerd/。我们对核心代码进行了分析:
(1)train_demo.py:运行的主文件
(2)data_loader.py:数据处理与加载
默认情况下,读取原始的数据集后,根据采样算法,随机采样符合 N N N-way K K K~ 2 K 2K 2K-shot 规则的episode data。采样代码如下所示:
class FewShotNERDatasetWithRandomSampling(data.Dataset):
"""
Fewshot NER Dataset
"""
def __init__(self, filepath, tokenizer, N, K, Q, max_length, ignore_label_id=-1):
if not os.path.exists(filepath):
print("[ERROR] Data file does not exist!")
assert(0)
self.class2sampleid = {
} # 每个entity type class涉及到的样本标号
self.N = N
self.K = K
self.Q = Q
self.tokenizer = tokenizer
self.samples, self.classes = self.__load_data_from_file__(filepath) # 获取当前数据集所有样本和类
self.max_length = max_length
self.sampler = FewshotSampler(N, K, Q, self.samples, classes=self.classes) # 用于采样出一个episode任务
self.ignore_label_id = ignore_label_id
def __insert_sample__(self, index, sample_classes):
for item in sample_classes:
if item in self.class2sampleid:
self.class2sampleid[item].append(index)
else:
self.class2sampleid[item] = [index]
def __load_data_from_file__(self, filepath):
# 从本地加载数据集
samples = [] # 所有样本
classes = [] # 所有涉及的entity type class
with open(filepath, 'r', encoding='utf-8')as f:
lines = f.readlines()
samplelines = []
index = 0 # 当前样本编号
for line in lines:
line = line.strip()
if line:
samplelines.append(line)
else:
sample = Sample(samplelines)
samples.append(sample)
sample_classes = sample.get_tag_class() # 获得该样本中所有的entity type class
self.__insert_sample__(index, sample_classes)
classes += sample_classes
samplelines = []
index += 1
if samplelines: # 处理文件最后一个样本
sample = Sample(samplelines)
samples.append(sample)
sample_classes = sample.get_tag_class()
self.__insert_sample__(index, sample_classes)
classes += sample_classes
samplelines = []
index += 1
classes = list(set(classes))
return samples, classes
def __get_token_label_list__(self, sample):
tokens = []
labels = []
for word, tag in zip(sample.words, sample.normalized_tags):
word_tokens = self.tokenizer.tokenize(word)
if word_tokens:
tokens.extend(word_tokens)
# Use the real label id for the first token of the word, and padding ids for the remaining tokens
word_labels = [self.tag2label[tag]] + [self.ignore_label_id] * (len(word_tokens) - 1)
labels.extend(word_labels)
return tokens, labels
def __getraw__(self, tokens, labels):
# 分词、获得input_id,attention mask和segment id
# get tokenized word list, attention mask, text mask (mask [CLS], [SEP] as well), tags
# split into chunks of length (max_length-2)
# 2 is for special tokens [CLS] and [SEP]
tokens_list = []
labels_list = []
while len(tokens) > self.max_length - 2:
tokens_list.append(tokens[:self.max_length-2])
tokens = tokens[self.max_length-2:]
labels_list.append(labels[:self.max_length-2])
labels = labels[self.max_length-2:]
if tokens:
tokens_list.append(tokens)
labels_list.append(labels)
# add special tokens and get masks
indexed_tokens_list = []
mask_list = []
text_mask_list = []
for i, tokens in enumerate(tokens_list):
# token -> ids
tokens = ['[CLS]'] + tokens + ['[SEP]']
indexed_tokens = self.tokenizer.convert_tokens_to_ids(tokens)
# padding
while len(indexed_tokens) < self.max_length:
indexed_tokens.append(0)
indexed_tokens_list.append(indexed_tokens)
# mask
mask = np.zeros((self.max_length), dtype=np.int32)
mask[:len(tokens)] = 1
mask_list.append(mask)
# text mask, also mask [CLS] and [SEP]
text_mask = np.zeros((self.max_length), dtype=np.int32)
text_mask[1:len(tokens)-1] = 1
text_mask_list.append(text_mask)
assert len(labels_list[i]) == len(tokens) - 2, print(labels_list[i], tokens)
return indexed_tokens_list, mask_list, text_mask_list, labels_list
def __additem__(self, index, d, word, mask, text_mask, label):
d['index'].append(index)
d['word'] += word
d['mask'] += mask
d['label'] += label
d['text_mask'] += text_mask
def __populate__(self, idx_list, savelabeldic=False):
'''
populate samples into data dict
set savelabeldic=True if you want to save label2tag dict
'index': sample_index
'word': tokenized word ids
'mask': attention mask in BERT
'label': NER labels
'sentence_num': number of sentences in this set (a batch contains multiple sets)
'text_mask': 0 for special tokens and paddings, 1 for real text
'''
dataset = {
'index': [], 'word': [], 'mask': [], 'label': [], 'sentence_num': [], 'text_mask': []}
for idx in idx_list:
tokens, labels = self.__get_token_label_list__(self.samples[idx])
word, mask, text_mask, label = self.__getraw__(tokens, labels) # BERT分词、生成input_ids,attention_mask...
word = torch.tensor(word).long()
mask = torch.tensor(np.array(mask)).long()
text_mask = torch.tensor(np.array(text_mask)).long()
self.__additem__(idx, dataset, word, mask, text_mask, label)
dataset['sentence_num'] = [len(dataset['word'])]
if savelabeldic:
dataset['label2tag'] = [self.label2tag]
return dataset
def __getitem__(self, index):
# 每次获得一个新数据。一个item表示一个episode任务数据
target_classes, support_idx, query_idx = self.sampler.__next__() # Sampler采样一组episode任务数据
# add 'O' and make sure 'O' is labeled 0
distinct_tags = ['O'] + target_classes
self.tag2label = {
tag: idx for idx, tag in enumerate(distinct_tags)}
self.label2tag = {
idx: tag for idx, tag in enumerate(distinct_tags)}
# support_set (类似input features):{'index': [], 'word': [], 'mask': [], 'label': [], 'sentence_num': [], 'text_mask': []}
support_set = self.__populate__(support_idx) # 根据采样得到的样本编号,生成数据(input_id, attention_mask等)
query_set = self.__populate__(query_idx, savelabeldic=True)
return support_set, query_set
def __len__(self):
return 100000
由于每次采样的结果是不一样的,为了公平地对比baseline,作者也提供了已经预处理好的episode data,该数据在后续的research中被用于公平对比。直接读取预处理好的episode data代码如下:
class FewShotNERDataset(FewShotNERDatasetWithRandomSampling):
def __init__(self, filepath, tokenizer, max_length, ignore_label_id=-1):
if not os.path.exists(filepath):
print("[ERROR] Data file does not exist!")
assert(0)
self.class2sampleid = {
}
self.tokenizer = tokenizer
self.samples = self.__load_data_from_file__(filepath)
self.max_length = max_length
self.ignore_label_id = ignore_label_id
def __load_data_from_file__(self, filepath):
with open(filepath)as f:
lines = f.readlines()
for i in range(len(lines)):
lines[i] = json.loads(lines[i].strip())
return lines
def __additem__(self, d, word, mask, text_mask, label):
d['word'] += word
d['mask'] += mask
d['label'] += label
d['text_mask'] += text_mask
def __get_token_label_list__(self, words, tags):
tokens = []
labels = []
for word, tag in zip(words, tags):
word_tokens = self.tokenizer.tokenize(word)
if word_tokens:
tokens.extend(word_tokens)
# Use the real label id for the first token of the word, and padding ids for the remaining tokens
word_labels = [self.tag2label[tag]] + [self.ignore_label_id] * (len(word_tokens) - 1)
labels.extend(word_labels)
return tokens, labels
def __populate__(self, data, savelabeldic=False):
'''
populate samples into data dict
set savelabeldic=True if you want to save label2tag dict
'word': tokenized word ids
'mask': attention mask in BERT
'label': NER labels
'sentence_num': number of sentences in this set (a batch contains multiple sets)
'text_mask': 0 for special tokens and paddings, 1 for real text
'''
dataset = {
'word': [], 'mask': [], 'label':[], 'sentence_num':[], 'text_mask':[] }
for i in range(len(data['word'])):
tokens, labels = self.__get_token_label_list__(data['word'][i], data['label'][i])
word, mask, text_mask, label = self.__getraw__(tokens, labels)
word = torch.tensor(word).long()
mask = torch.tensor(mask).long()
text_mask = torch.tensor(text_mask).long()
self.__additem__(dataset, word, mask, text_mask, label)
dataset['sentence_num'] = [len(dataset['word'])]
if savelabeldic:
dataset['label2tag'] = [self.label2tag]
return dataset
def __getitem__(self, index):
sample = self.samples[index]
target_classes = sample['types']
support = sample['support']
query = sample['query']
# add 'O' and make sure 'O' is labeled 0
distinct_tags = ['O'] + target_classes
self.tag2label = {
tag: idx for idx, tag in enumerate(distinct_tags)}
self.label2tag = {
idx: tag for idx, tag in enumerate(distinct_tags)}
support_set = self.__populate__(support)
query_set = self.__populate__(query, savelabeldic=True)
return support_set, query_set
def __len__(self):
return len(self.samples)
(3)Collator:数据装载回调函数
其主要将读取的数据转换为模型的输入,例如我们非常常见的字典翻转(详见下面代码注释)。
def collate_fn(data):
'''
dataloader会生成一个batch,对一个batch内的数据进行处理
一个batch内原始数据按照list({'word': [..], ..}, ...)存储
因此需要转换为{'word': [[..]. ..], ..}
e.g [{'word': [1, 2, 3]}, {'word': [4, 5, 6]}]
->
{'word': [[1, 2, 3], [4, 5, 6]]}
'''
batch_support = {
'word': [], 'mask': [], 'label': [], 'sentence_num':[], 'text_mask':[]}
batch_query = {
'word': [], 'mask': [], 'label': [], 'sentence_num':[], 'label2tag':[], 'text_mask':[]}
support_sets, query_sets = zip(*data)
for i in range(len(support_sets)):
for k in batch_support:
batch_support[k] += support_sets[i][k]
for k in batch_query:
batch_query[k] += query_sets[i][k]
for k in batch_support:
if k != 'label' and k != 'sentence_num':
batch_support[k] = torch.stack(batch_support[k], 0)
for k in batch_query:
if k !='label' and k != 'sentence_num' and k!= 'label2tag':
batch_query[k] = torch.stack(batch_query[k], 0)
batch_support['label'] = [torch.tensor(tag_list).long() for tag_list in batch_support['label']]
batch_query['label'] = [torch.tensor(tag_list).long() for tag_list in batch_query['label']]
return batch_support, batch_query
这里需要强调一点,对于 N N N-way K K K-shot 训练模式下的batch size,不再是传统的句子数量,而是episode data数量,因此这里需要额外添加一个变量用于定位episode的位置,即sentence_num。具体细节描述如下:
- 模型的输入部分,我们拆分为两个集合,分别是support和query,每个集合对应若干个句子,是直接将一个batch内所有episode data的support/query句子直接堆叠起来。
- 为了知道哪些句子是一个episode,
sentence_num变量则记录着第 i i i 个episode的句子数量,在后期可逐个检索到相应的episode。
例如对于support,输入2个batch,句子数量分别为5和7。那么support[word]包含12个句子,support[sentence_num]包含两个元素,分别为5和7。在后续计算prototype的时候,需要单独提取出每个episode对应的句子。
(4)Encoder
Few-NERD以及后续对比的方法,均采用BERT-base-uncased模型,下载地址为https://huggingface.co/bert-base-uncased。代码如下所示:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import numpy as np
import os
from torch import optim
from transformers import BertTokenizer, BertModel, BertForMaskedLM, BertForSequenceClassification, RobertaModel, RobertaTokenizer, RobertaForSequenceClassification
class BERTWordEncoder(nn.Module):
def __init__(self, pretrain_path):
nn.Module.__init__(self)
self.bert = BertModel.from_pretrained(pretrain_path)
def forward(self, words, masks):
outputs = self.bert(words, attention_mask=masks, output_hidden_states=True, return_dict=True)
#outputs = self.bert(inputs['word'], attention_mask=inputs['mask'], output_hidden_states=True, return_dict=True)
# use the sum of the last 4 layers
last_four_hidden_states = torch.cat([hidden_state.unsqueeze(0) for hidden_state in outputs['hidden_states'][-4:]], 0)
del outputs
word_embeddings = torch.sum(last_four_hidden_states, 0) # [num_sent, number_of_tokens, 768]
return word_embeddings
(5)模型主体结构
以Prototype Network为例,代码如下所示,可参考详细的代码注释理解。
import sys
sys.path.append('..')
import util
import torch
from torch import autograd, optim, nn
from torch.autograd import Variable
from torch.nn import functional as F
class Proto(util.framework.FewShotNERModel):
def __init__(self, word_encoder, dot=False, ignore_index=-1):
util.framework.FewShotNERModel.__init__(self, word_encoder, ignore_index=ignore_index)
self.drop = nn.Dropout()
self.dot = dot
def __dist__(self, x, y, dim):
if self.dot:
return (x * y).sum(dim)
else:
return -(torch.pow(x - y, 2)).sum(dim)
def __batch_dist__(self, S, Q, q_mask):
# S [class, embed_dim], Q [num_of_sent, num_of_tokens, embed_dim]
assert Q.size()[:2] == q_mask.size()
Q = Q[q_mask==1].view(-1, Q.size(-1)) # [num_of_all_text_tokens, embed_dim]
return self.__dist__(S.unsqueeze(0), Q.unsqueeze(1), 2)
def __get_proto__(self, embedding, tag, mask):
proto = []
embedding = embedding[mask==1].view(-1, embedding.size(-1))
tag = torch.cat(tag, 0)
assert tag.size(0) == embedding.size(0)
for label in range(torch.max(tag)+1):
proto.append(torch.mean(embedding[tag==label], 0))
proto = torch.stack(proto)
return proto, embedding
def forward(self, support, query):
'''
support: Inputs of the support set.
query: Inputs of the query set.
N: Num of classes
K: Num of instances for each class in the support set
Q: Num of instances in the query set
support/query = {'index': [], 'word': [], 'mask': [], 'label': [], 'sentence_num': [], 'text_mask': []}
'''
# support set和query set分别喂入BERT中获得各个样本的表示
support_emb = self.word_encoder(support['word'], support['mask']) # [num_sent, number_of_tokens, 768]
query_emb = self.word_encoder(query['word'], query['mask']) # [num_sent, number_of_tokens, 768]
support_emb = self.drop(support_emb)
query_emb = self.drop(query_emb)
# Prototypical Networks
logits = []
current_support_num = 0
current_query_num = 0
assert support_emb.size()[:2] == support['mask'].size()
assert query_emb.size()[:2] == query['mask'].size()
for i, sent_support_num in enumerate(support['sentence_num']): # 遍历每个采样得到的N-way K-shot任务数据
sent_query_num = query['sentence_num'][i]
# Calculate prototype for each class
# 因为一个batch里对应多个episode,因此 current_support_num:current_support_num+sent_support_num
# 用来表示当前输入的张量中,哪个范围内的句子属于当前N-way K-shot采样数据
support_proto, embedding = self.__get_proto__(
support_emb[current_support_num:current_support_num+sent_support_num],
support['label'][current_support_num:current_support_num+sent_support_num],
support['text_mask'][current_support_num: current_support_num+sent_support_num])
# calculate distance to each prototype
logits.append(self.__batch_dist__(
support_proto,
query_emb[current_query_num:current_query_num+sent_query_num],
query['text_mask'][current_query_num: current_query_num+sent_query_num])) # [num_of_query_tokens, class_num]
current_query_num += sent_query_num
current_support_num += sent_support_num
logits = torch.cat(logits, 0) # 每个query的从属于support set对应各个类的概率
_, pred = torch.max(logits, 1) # 挑选最大概率对应的proto类作为预测结果
return logits, pred, embedding
作者还实现了NN-Shot和Struct-Shot,可具体参考原文与GitHub。
五、目前实验对比
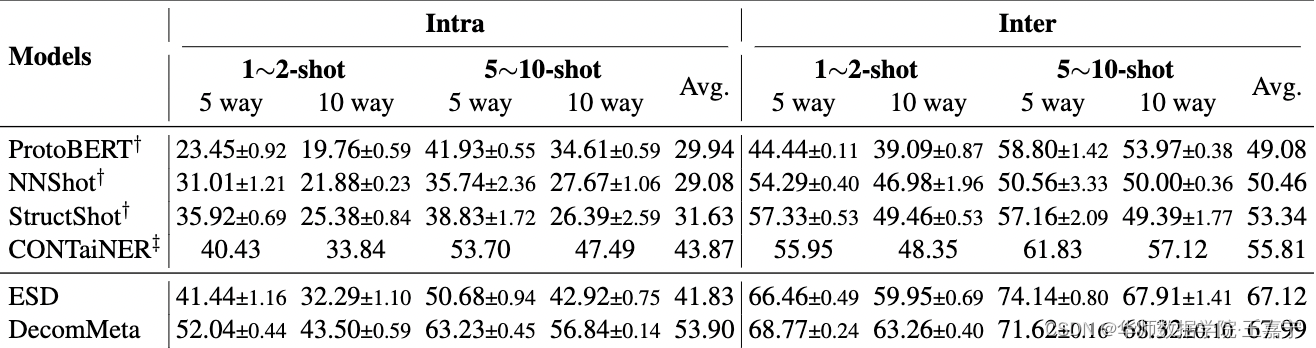
截止目前(2022年6月28日),已有多篇工作在EMNLP2021、AAAI、ACL2022上开始使用该数据集进行评测,目前的实验对比情况可详情:paperwithcode-INTRA和paperwithcode-INTER。目前的对比情况如图所示:
六、总结
Few-NERD是比较新的评测任务,在其被提出之前,Few-shot NER基本是从几个热门的监督数据上采样构造成few-shot数据,不同人采用不同的构建方法使得模型之间的对比并不公平,而Few-NERD则提供了较为公平的评测基准,同时引出了few-shot在NER上的采样规则。
不过现有的这些评测方法和提出的模型依然存在一些问题:
- “O”标签问题:因为Few-NERD依然是基于序列标注的数据,每个token给予“BIO”标签,因此对于一个句子,依然存在大量的“O”标签,这会对模型产生干扰。目前有相关工作解决该类问题;
- token之间的label依赖:因为序列标注需要考虑到输出部分的依赖关系,例如B必须在实体的第一个位置。因此需要额外引入类似维特比算法。但是因为每个episode的类别不一样,无法直接使用CRF来预测。目前有一些工作尝试解决few-shot场景下的标签依赖问题。