
如果你遇到以下问题,很适合阅读本篇文章
- 数据集太小太零散,找不到合适数据?
- 数据集不知道从哪里获得,很容易得到的都是外国的
- 数据集不均匀训练的模型不准确、不收敛、很偏见
- 在犹豫优化模型还是继续找数据集
- 是否花钱购买数据
- 还在发愁找不到数据集训练你的模型?
如果用一个句子总结学习数据科学的本质,那就是: 学习数据科学的最佳方法就是应用数据科学。 如果你是一个初学者,你每完成一个新项目后自身能力都会有极大的提高,如果你是一个有经验的数据科学专家,你已经知道这里所蕴含的价值。
首先,在选择数据集时要记住几个重要标准:
- 数据集不能过于混乱,过于混乱的数据会导致模型难以收敛,加大了训练难度。
- 与训练目标相一致的数据集才能更高效的完成识别任务
- 数据集量级是否符合模型规模,复杂的深度网络需要更多的数据才能发挥能力。
数据至关重要
数据质量决定着模型的准确率,技巧模型比重很小。好的数据是成功的90%,数据采集,数据标注,数据清洗,数据预处理,有着至关重要的作用。如果你是学生,下面文章提供几个下载数据集的网站及标注工具,方便快速跑起来你的代码。把精力都用在模型学习和优化上而非枯燥的数据处理。如果你是从业者,更多的数据才是制胜的法宝,可以采用下面列出的工具例如Aidiscovery快速收集尽可能多的数据。利用Labelme图像分割标注
数据集划分
训练集、验证集、测试集,这三个集合不能有交集,常见的比例是8:1:1。
数据准备之数据采集标注软件
【Labelme】 图像分割标注推荐


简单介绍:LabelMe的目标是提供一个在线注释工具,以建立用于计算机视觉研究的图像数据库。如果未完全标记图像,则用户可以使用鼠标在图像中绘制一个包含对象的多边形。LabelMe项目提供了一组工具,用于使用Matlab中的LabelMe数据集。
功能:
- 对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注(可用于目标检测,图像分割,等任务)。
- 对图像进行进行 flag 形式的标注(可用于图像分类 和 清理 任务)。
- 视频标注
- 生成 VOC 格式的数据集(for semantic / instance segmentation)
- 生成 COCO 格式的数据集(for instance segmentation)
地址:http://labelme.csail.mit.edu/Release3.0/browserTools/php/dataset.php
点击下载
【Aidiscovery】数据采集自动分类推荐


简单介绍:无需登陆注册,即可免费下载。人脸数据自动收集,界面友好、操作简单、其中包含的数据采集是其他软件不具备的,包括数据增强自动分类,解决标注头疼问题。除此之外,对数据集的采集来源、数据采集量、数据分布等进行统计分析,以可视化图表的形式展现,辅助评判数据集可用性。
功能:
- 数据采集,从视频和屏幕采集数据,实时标注
- 数据增强,提供数据增强详细的参数选择及预览,有单一数据增强和组合数据增强
- 数据处理,对于采集结果进行自动处理,再对不正确的手动处理
- 统计分析,对于采集资源的优劣进行统计
常用数据集下载网站
一、【Kaggle】 地址:https://www.kaggle.com/datasets

介绍:一个竞赛网站,上面有很多有价值的数据集和题目。每个比赛都是独立的。无需确定自己的项目范围并收集数据,可以腾出时间专注于其他技能。实践就是实践。
二、【ImageNet】 地址:http://image-net.org/

介绍:ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库。超过1400万的图像URL被ImageNet手动注释,以指示图片中的对象;在至少一百万个图像中,还提供了边界框。ImageNet包含2万多个类别
四、【MS COCO】 地址 :https://cocodataset.org/#download
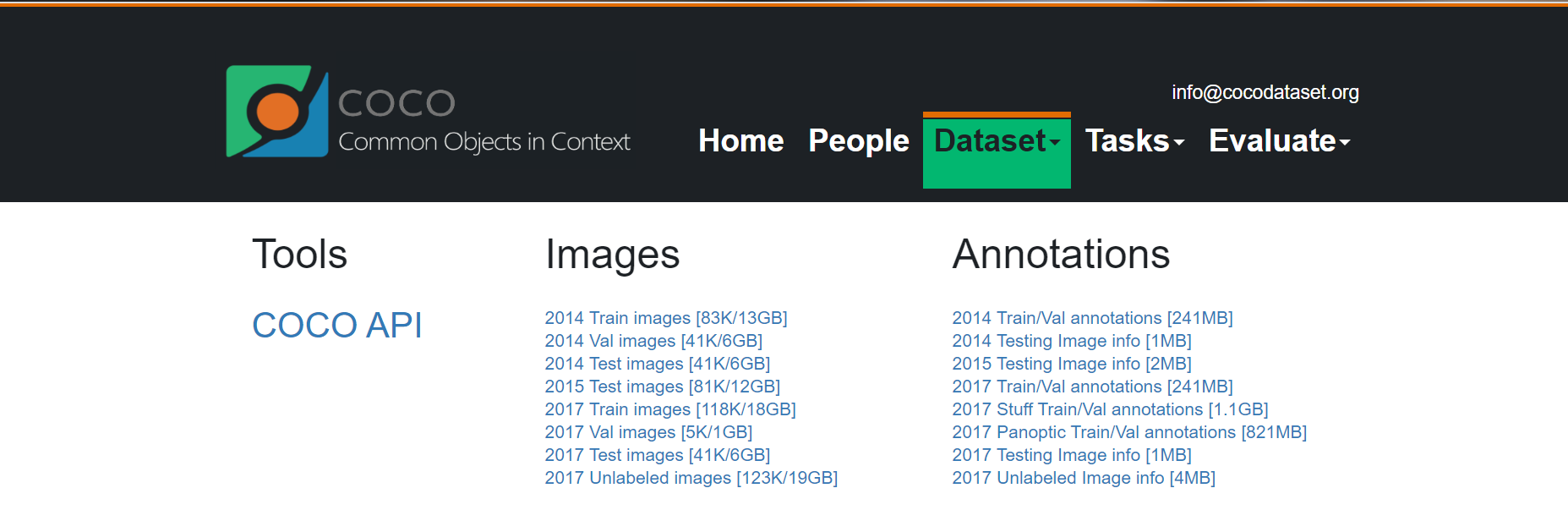
介绍 :COCO是大规模的对象检测,分割和字幕数据集。COCO具有以下功能:对象分割、上下文识别、超像素东西分割、330K图像(已标记> 200K)、150万个对象实例、80个对象类别、91个东西类别、每个图像5个字幕、有关键点的250,000人
五、【COIL100】 地址:http://www1.cs.columbia.edu/CAVE/software/softlib/coil-100.php

介绍:100 个不同的物体在 360°旋转中以每个角度成像
六、【Visual Genome】地址:http://visualgenome.org/

介绍:非常详细的视觉知识库,配有约 100K 个图像的注释。
七、【Labelled Faces in the Wild】地址:http://vis-www.cs.umass.edu/lfw/

介绍:13000 张贴有标签的人脸图像,用于作为人脸识别测试集。
八、【Stanford Dogs Dataset】地址:http://vision.stanford.edu/aditya86/ImageNetDogs/
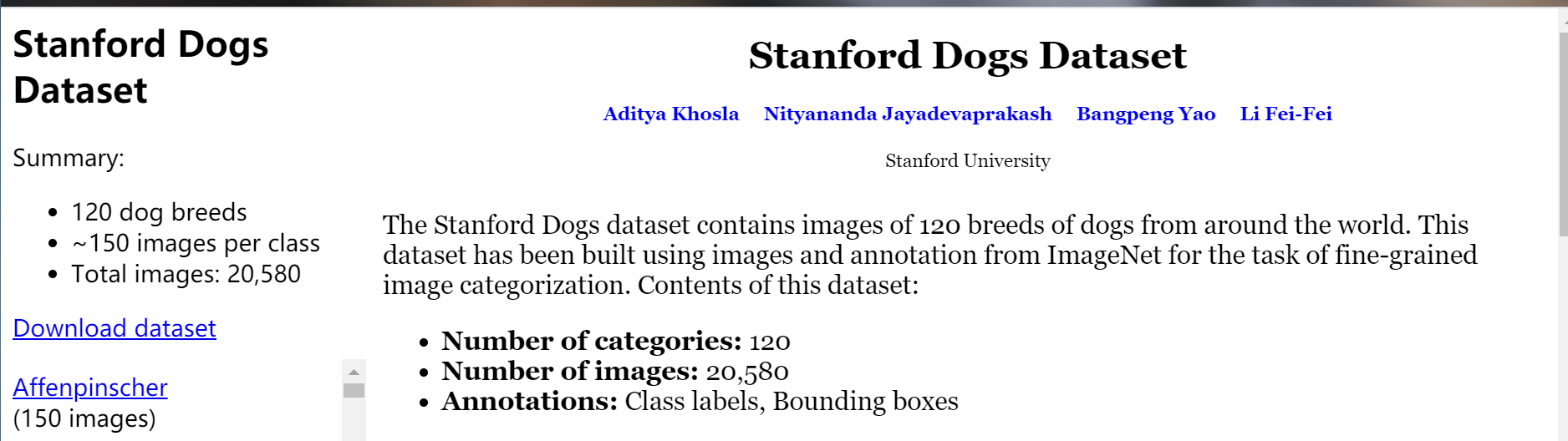
介绍:包含 20580 个图像和 120 个不同品种的狗类别。注释:类别标签,边界框
九、【Indoor Scene Recognition】地址:http://web.mit.edu/torralba/www/indoor.html

介绍:该数据库包含67个室内类别,共15620张图像。图像的数量因类别而异,但每个类别至少有100张图像。所有图像均为jpg格式。此处提供的图像仅用于研究目的。
十、【vggface】地址:http://www.shujujishi.com/dataset/f66a2818-dd92-4c6e-bb83-a32f59f86170.html
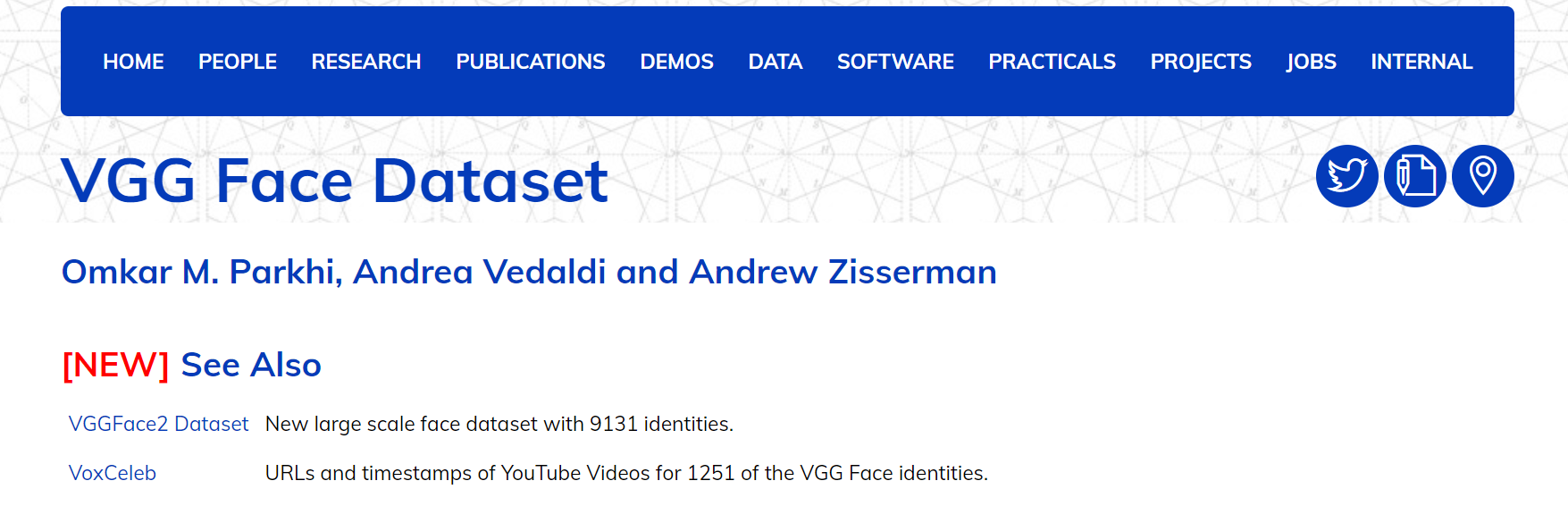
介绍:VGG-Face中的身份分布数据集可能无法代表全球人口。在训练或部署根据此数据训练的模型时,根据场景使用,避免学习结果有偏见
VGGFace2数据集 具有9131个身份的新的大规模面部数据集。 VoxCeleb 1251个VGG Face身份的YouTube视频的URL和时间戳。
十一、【MS-Celeb-1M】地址:http://academictorrents.com/details/9e67eb7cc23c9417f39778a8e06cca5e26196a97
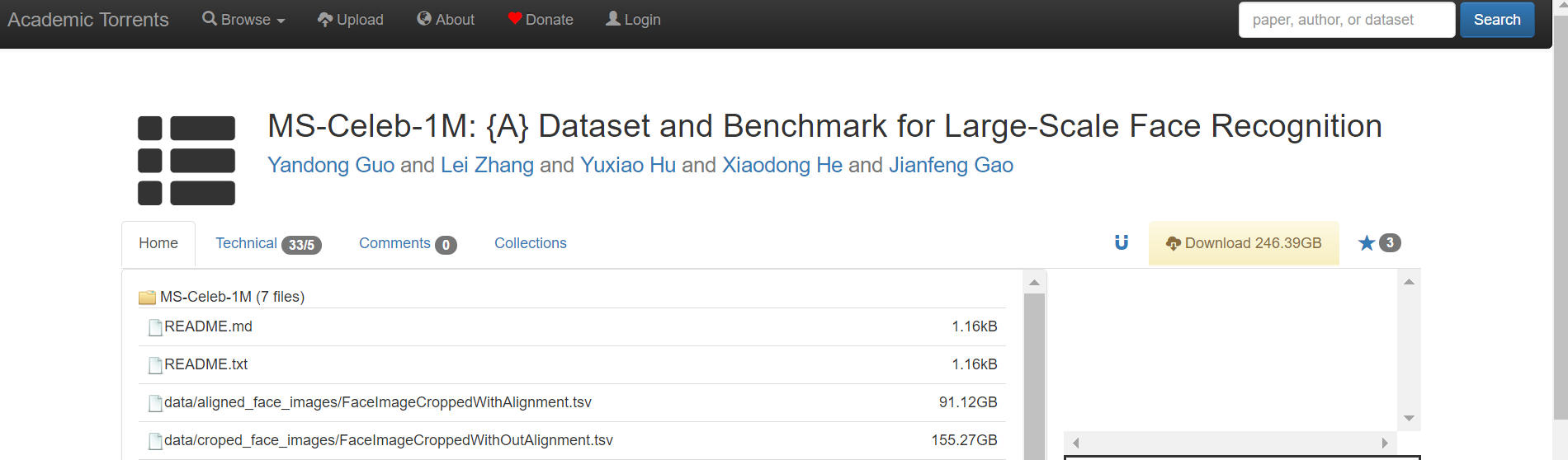
介绍:用于识别人脸图像的相关数据集,一百万名人。知识库提供的丰富信息有助于进行消歧和提高识别精度,并有助于各种现实应用,如图像字幕和新闻视频分析。是世界上最大的公开数据集,在版本1中包含1000万幅图像。
十二、【PubFig: Public Figures Face Database】地址:https://www.cs.columbia.edu/CAVE/databases/pubfig/
介绍:PubFig数据库是一个大型的真实人脸数据集,58797张图像200人。与大多数其他现有的人脸数据集不同,这些图像是在完全不受控制的情况下拍摄的,对象不合作。因此,在姿势、照明、表情、场景、相机、成像条件和参数等方面有很大的变化。
十三、【megaface】地址:http://megaface.cs.washington.edu/dataset/download_training.html
介绍:megaface训练数据集是最大的(在身份数量上)可公开获得的面部识别数据集,具有470万张脸、672个身份和它们各自的边界框。
十四、【Yale Face Database 】http://vision.ucsd.edu/~leekc/ExtYaleDatabase/ExtYaleB.html

介绍:耶鲁人脸数据库包含28个人在9种姿势和64种光照条件下的16128幅图像
其他
- Datahub – a community-managed home for open data sets
- Data.gov – the U.S. Government's open data
- data.world
- GCMD – the Global Change Master Directory containing over 20,000 descriptions of Earth science and environmental science data sets and services
- Humanitarian Data Exchange(HDX) – The Humanitarian Data Exchange (HDX) is an open humanitarian data sharing platform managed by the United Nations Office for the Coordination of Humanitarian Affairs.
- NYC Open Data – free public data published by New York City agencies and other partners.
- Relational data set repository
- Research Pipeline – a wiki/website with links to data sets on many different topics
- StatLib–JASA Data Archive
- UCI – a machine learning repository
- UK Government Public Data
- World Bank Open Data – Free and open access to global development data by World Bank