文章目录
七、TIME_WAIT 与 四次挥手
现象:如果 server 端间歇性不可用,可能是 TIME_WAIT 造成的:
- server 的每个 tcp 连接会占一个 port,在高并发情况下,若 TIME_WAIT 状态的连接太多,多到把本机可用的 ports 耗尽,server 端就会表现为不可用。而当过一段时间,TIME_WAIT 的连接被系统回收后,释放出 port,即表现为对外可用。如此周而复始即表现为间歇性不可用的现象。
7.1 原因
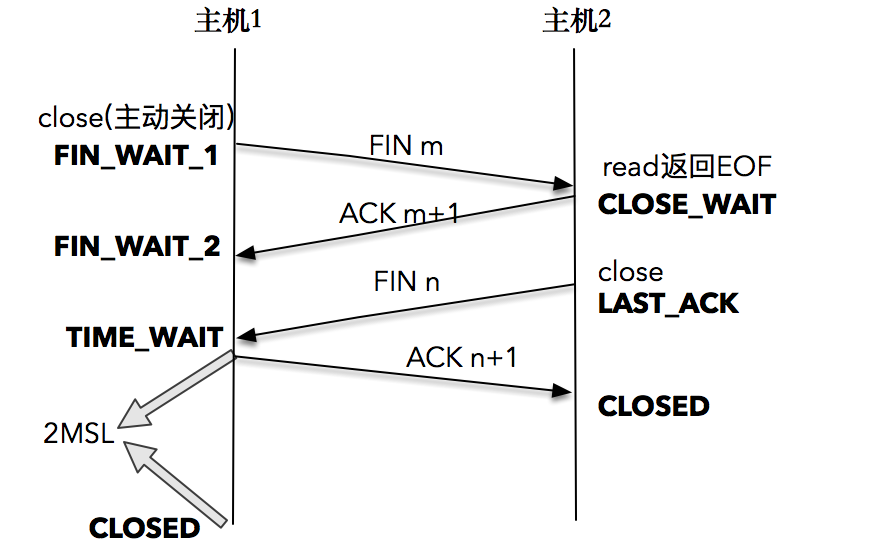
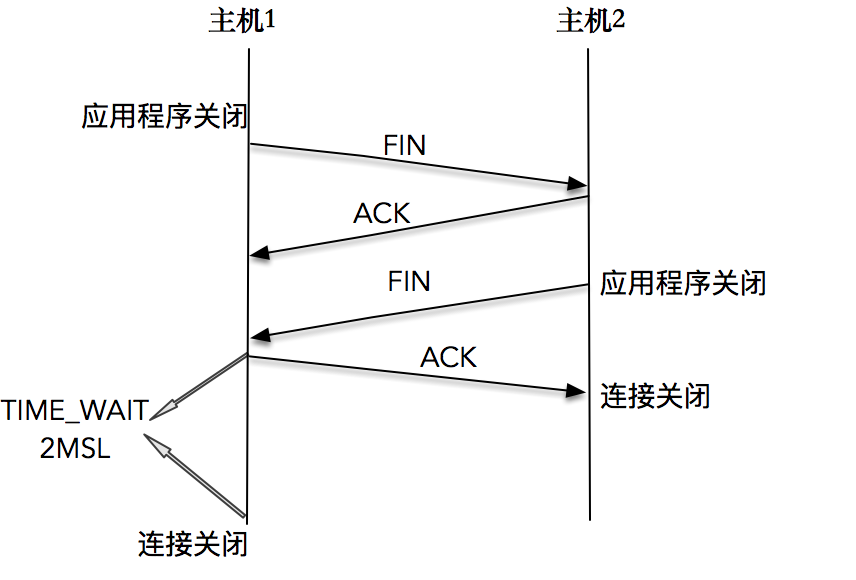
TCP 连接终止时,主机 1 先发送 FIN 报文,主机 2 进入 CLOSE_WAIT 状态,并发送一个 ACK 应答,同时,主机 2 通过 read 调用获得 EOF,并将此结果通知应用程序进行主动关闭操作,发送 FIN 报文。主机 1 在接收到 FIN 报文后发送 ACK 应答,此时主机 1 进入 TIME_WAIT 状态。
主机 1 在 TIME_WAIT 停留持续时间是固定的,是最长分节生命期 MSL(maximum segment lifetime)的两倍,一般称之为 2MSL。和大多数 BSD 派生的系统一样,Linux 系统里有一个硬编码的字段,名称为TCP_TIMEWAIT_LEN,其值为 60 秒。也就是说,Linux 系统停留在 TIME_WAIT 的时间为固定的 60 秒。
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT state, about 60 seconds */
过了这个时间之后,主机 1 就进入 CLOSED 状态。即只有发起连接终止的一方会进入 TIME_WAIT 状态。
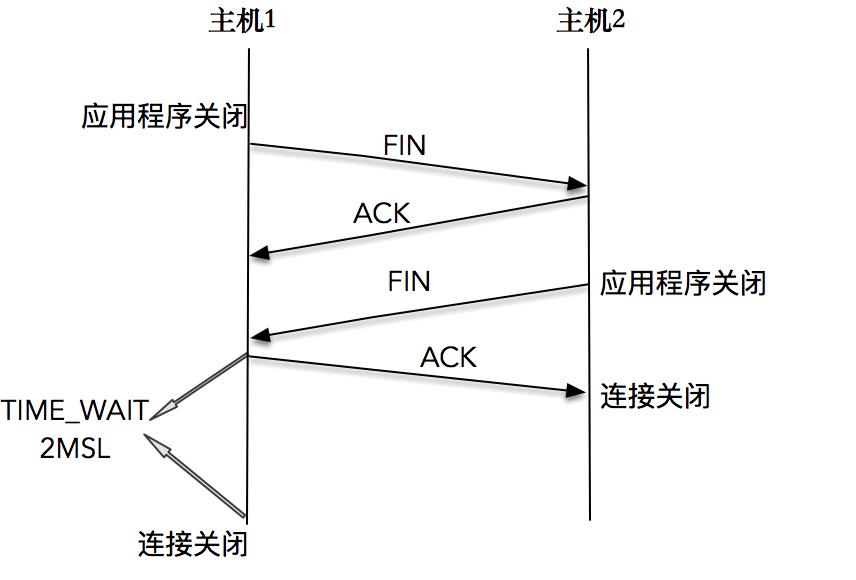
首先,一方应用程序调用 close,我们称该方为主动关闭方,该端的 TCP 发送一个 FIN 包,表示需要关闭连接。之后主动关闭方进入 FIN_WAIT_1 状态。
接着,接收到这个 FIN 包的对端执行被动关闭。这个 FIN 由 TCP 协议栈处理,我们知道,TCP 协议栈为 FIN 包插入一个文件结束符 EOF 到接收缓冲区中,应用程序可以通过 read 调用来感知这个 FIN 包。一定要注意,这个 EOF 会被放在已排队等候的其他已接收的数据之后,这就意味着接收端应用程序需要处理这种异常情况,因为 EOF 表示在该连接上再无额外数据到达。此时,被动关闭方进入 CLOSE_WAIT 状态。
接下来,被动关闭方将读到这个 EOF,于是,应用程序也调用 close 关闭它的套接字,这导致它的 TCP 也发送一个 FIN 包。这样,被动关闭方将进入 LAST_ACK 状态。
最终,主动关闭方接收到对方的 FIN 包,并确认这个 FIN 包。主动关闭方进入 TIME_WAIT 状态,而接收到 ACK 的被动关闭方则进入 CLOSED 状态。进过 2MSL 时间之后,主动关闭方也进入 CLOSED 状态。
你可以看到,每个方向都需要一个 FIN 和一个 ACK,因此通常被称为四次挥手。
当然,这中间使用 shutdown,执行一端到另一端的半关闭也是可以的。
当然,这中间使用 shutdown,执行一端到另一端的半关闭也是可以的。
当套接字被关闭时,TCP 为其所在端发送一个 FIN 包。在大多数情况下,这是由应用进程调用 close 而发生的,值得注意的是,一个进程无论是正常退出(exit 或者 main 函数返回),还是非正常退出(比如,收到 SIGKILL 信号关闭,就是我们常常干的 kill -9),所有该进程打开的描述符都会被系统关闭,这也导致 TCP 描述符对应的连接上发出一个 FIN 包。
无论是客户端还是服务器,任何一端都可以发起主动关闭。大多数真实情况是客户端执行主动关闭,你可能不会想到的是,HTTP/1.0 却是由服务器发起主动关闭的。
7.2 作用
为什么不直接进入 CLOSED 状态,而要停留在 TIME_WAIT 这个状态?
-
TCP 在设计的时候,做了充分的容错性设计,比如,TCP 假设报文会出错,需要重传。在这里,如果图中主机 1 的 ACK 报文没有传输成功,那么主机 2 就会重新发送 FIN 报文。
如果主机 1 没有维护 TIME_WAIT 状态,而直接进入 CLOSED 状态,它就失去了当前状态的上下文,只能回复一个 RST 操作,从而导致被动关闭方出现错误。
现在主机 1 知道自己处于 TIME_WAIT 的状态,就可以在接收到 FIN 报文之后,重新发出一个 ACK 报文,使得主机 2 可以进入正常的 CLOSED 状态。
-
第二个理由和连接“化身”和报文迷走有关系,为了让旧连接的重复分节在网络中自然消失。
我们知道,在网络中,经常会发生报文经过一段时间才能到达目的地的情况,产生的原因是多种多样的,如路由器重启,链路突然出现故障等。如果迷走报文到达时,发现 TCP 连接四元组(源 IP,源端口,目的 IP,目的端口)所代表的连接不复存在,那么很简单,这个报文自然丢弃。
我们考虑这样一个场景,在原连接中断后,又重新创建了一个原连接的“化身”,说是化身其实是因为这个连接和原先的连接四元组完全相同,如果迷失报文经过一段时间也到达,那么这个报文会被误认为是连接“化身”的一个 TCP 分节,这样就会对 TCP 通信产生影响。
所以,TCP 就设计出了这么一个机制,经过 2MSL 这个时间,足以让两个方向上的分组都被丢弃,使得原来连接的分组在网络中都自然消失,再出现的分组一定都是新化身所产生的。
划重点,2MSL 的时间是从主机 1 接收到 FIN 后发送 ACK 开始计时的;如果在 TIME_WAIT 时间内,因为主机 1 的 ACK 没有传输到主机 2,主机 1 又接收到了主机 2 重发的 FIN 报文,那么 2MSL 时间将
重新计时。道理很简单,因为 2MSL 的时间,目的是为了让旧连接的所有报文都能自然消亡,现在主机 1 重新发送了 ACK 报文,自然需要重新计时,以便防止这个 ACK 报文对新可能的连接化身造成干扰。
MSL 是任何 IP 数据报能够在因特网中存活的最长时间。其实它的实现不是靠计时器来完成的,在每个数据报里都包含有一个被称为 TTL(time to live)的 8 位字段,它的最大值为 255。TTL 可译为“生存时间”,这个生存时间由源主机设置初始值,它表示的是一个 IP 数据报可以经过的最大跳跃数,每经过一个路由器,就相当于经过了一跳,它的值就减 1,当此值减为 0 时,则所在的路由器会将其丢弃,同时发送 ICMP 报文通知源主机。RFC793 中规定 MSL 的时间为 2 分钟,Linux 实际设置为 30 秒。
7.3 危害
- 第一是内存资源占用,这个目前看来不是太严重,基本可以忽略。
- 第二是对端口资源的占用,一个 TCP 连接至少消耗一个本地 port。要知道,port 资源也是有限的,一般可以开启的 port 为 32768~61000 ,也可以通过
net.ipv4.ip_local_port_range指定,如果 TIME_WAIT 状态过多,会导致无法创建新连接。
7.4 优化方案
在高并发的情况下,如果我们想对 TIME_WAIT 做一些优化,来解决我们一开始提到的例子,该如何办呢?
-
net.ipv4.tcp_max_tw_buckets
一个暴力的方法是通过 sysctl 命令,将系统值调小。这个值默认为 18000,当系统中处于 TIME_WAIT 的连接一旦超过这个值时,系统就会将所有的 TIME_WAIT 连接状态重置,并且只打印出警告信息。这个方法过于暴力,而且治标不治本,带来的问题远比解决的问题多,不推荐使用。 -
调低 TCP_TIMEWAIT_LEN,重新编译系统
这个方法是一个不错的方法,缺点是需要“一点”内核方面的知识,能够重新编译内核。我想这个不是大多数人能接受的方式。 -
SO_LINGER 的设置(不推荐)
英文单词“linger”的意思为停留,我们可以通过setsockopt(),来设置调用 close() 或者 shutdown() 关闭连接时的行为。设置 linger 参数有几种可能:
- 如果
l_onoff为 0,那么关闭本选项。l_linger 的值被忽略,这对应了默认行为,close 或 shutdown 立即返回。如果在套接字发送缓冲区中有数据残留,系统会将试着把这些数据发送出去。 - 如果
l_onoff为非 0, 而l_linger值为 0,那么调用 close 后,会立刻发送一个RST标志给对端,该 TCP 连接将跳过四次挥手,也就跳过了 TIME_WAIT 状态,直接关闭。这种关闭的方式称为“强行关闭”。- 在这种情况下,排队数据不会被发送,
- 被动关闭方也不知道对端已经彻底断开。只有当被动关闭方正
阻塞在 recv()调用上时,接受到 RST 时,会立刻得到一个“connet reset by peer”的异常。
- 如果
l_onoff为非 0, 且l_linger的值也非 0,那么调用 close 后,调用 close 的线程就将阻塞,直到数据被发送出去,或者设置的 l_linger 计时时间到。 - 第二种可能为跨越 TIME_WAIT 状态提供了一个可能,不过是一个非常危险的行为,不值得提倡。
- 如果
// 接口
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
struct linger {
int l_onoff; // 0=off, nonzero=on
int l_linger; // linger time, POSIX specifies units as seconds
}
// 使用
struct linger so_linger;
so_linger.l_onoff = 1;
so_linger.l_linger = 0;
setsockopt(s,SOL_SOCKET,SO_LINGER, &so_linger,sizeof(so_linger));
net.ipv4.tcp_tw_reuse:更安全的设置
即从协议角度理解如果是安全可控的,可以复用处于 TIME_WAIT 的套接字为新的连接所用。什么是协议角度理解的安全可控呢?主要有两点:- 只适用于连接发起方(C/S 模型中的 client );
- 对应的 TIME_WAIT 状态的连接创建时间超过 1 秒才可以被复用。
使用这个选项,前提是需要打开对 TCP 时间戳的支持,即net.ipv4.tcp_timestamps=1(默认即为 1)。
// net.ipv4.tcp_tw_reuse:
Allow to reuse TIME-WAIT sockets for new connections when it is safe from protocol viewpoint. Default value is 0.
It should not be changed without advice/request of technical experts.
要知道,TCP 协议也在与时俱进,RFC 1323 中实现了 TCP 拓展规范,以便保证 TCP 的高可用,并引入了新的 TCP 选项,两个 4 字节的时间戳字段,用于记录 TCP 发送方的当前时间戳和从对端接收到的最新时间戳。由于引入了时间戳,我们在前面提到的 2MSL 问题就不复存在了,因为重复的数据包会因为时间戳过期被自然丢弃。
八、server 优雅关闭
client 主动发起连接的中断,将自己到 server 的数据流方向关闭,此时, client 不再往 server 写入数据, server 读完 client 数据后就不会再有新的报文到达。但这并不意味着,TCP 连接已经完全关闭,很有可能的是, server 正在对 client 的最后报文进行处理,比如去访问数据库,存入一些数据;或者是计算出某个 client 需要的值,当完成这些操作之后, server 把结果通过套接字写给 client ,我们说这个套接字的状态此时是“半关闭”的。最后, server 才有条不紊地关闭剩下的半个连接,结束这一段 TCP 连接的使命。
当然,我这里描述的,是 server “优雅”地关闭了连接。如果 server 处理不好,就会导致最后的关闭过程是“粗暴”的,达不到我们上面描述的“优雅”关闭的目标,形成的后果,很可能是 server 处理完的信息没办法正常传送给 client ,破坏了用户侧的使用场景。
8.1 close()
int close(int sockfd)
这个函数会对套接字引用计数减一,一旦发现套接字引用计数到 0,就会对套接字进行彻底释放,并且会关闭TCP 两个方向的数据流。
套接字引用计数是什么意思呢?因为套接字可以被多个进程共享,你可以理解为我们给每个套接字都设置了一个积分,如果我们通过 fork 的方式产生子进程,套接字就会积分 +1, 如果我们调用一次 close 函数,套接字积分就会 -1。这就是套接字引用计数的含义。
close 函数具体是如何关闭两个方向的数据流呢?
在输入方向,系统内核会将该套接字设置为不可读,任何读操作都会返回异常。
在输出方向,系统内核尝试将发送缓冲区的数据发送给对端,并最后向对端发送一个 FIN 报文,接下来如果再对该套接字进行写操作会返回异常。
如果对端没有检测到套接字已关闭,还继续发送报文,就会收到一个 RST 报文,告诉对端:“Hi, 我已经关闭了,别再给我发数据了。”
我们会发现,close 函数并不能帮助我们关闭连接的一个方向,那么如何在需要的时候关闭一个方向呢?幸运的是,设计 TCP 协议的人帮我们想好了解决方案,这就是 shutdown 函数。
8.2 shutdown()
int shutdown(int sockfd, int howto)
howto 是这个函数的设置选项,它的设置有三个主要选项:
- SHUT_RD(0):关闭连接的“读”这个方向,对该套接字进行读操作直接返回 EOF。从数据角度来看,套接字上接收缓冲区已有的数据将被丢弃,如果再有新的数据流到达,会对数据进行 ACK,然后悄悄地丢弃。也就是说,对端还是会接收到 ACK,在这种情况下根本不知道数据已经被丢弃了。
- SHUT_WR(1):关闭连接的“写”这个方向,这就是常被称为”半关闭“的连接。此时,不管套接字引用计数的值是多少,都会直接关闭连接的写方向。套接字上发送缓冲区已有的数据将被立即发送出去,并发送一个 FIN 报文给对端。应用程序如果对该套接字进行写操作会报错。
- SHUT_RDWR(2):相当于 SHUT_RD 和 SHUT_WR 操作各一次,关闭套接字的读和写两个方向。
用 SHUT_RDWR 来调用 shutdown 和 close 虽然都是关闭连接的读和写两个方向,但还是有区别的:
- close 会关闭连接,并释放所有连接对应的资源,而 shutdown 并不会释放掉套接字和所有的资源。
- close 存在引用计数的概念,并不一定导致该套接字不可用;shutdown 则不管引用计数,直接使得该套接字不可用,如果有别的进程企图使用该套接字,将会受到影响。
- close 的引用计数导致不一定会发出 FIN 结束报文,而 shutdown 则总是会发出 FIN 结束报文,这在我们打算关闭连接通知对端的时候,是非常重要的。
8.3 对比 close() 和 shutdown()
下面,我们通过构建一组 client 和 server 程序,来进行 close 和 shutdown 的实验。
client 端,从 stdin 不断接收用户输入,把输入的字符串通过套接字发送给 server,同时,将 server 的应答显示到 stdout 上。代码如下:
- 如果用户输入了“close”,则会调用 close 函数关闭连接,休眠一段时间,等待 server 处理后退出;
- 如果用户输入了“shutdown”,调用 shutdown 函数关闭连接的写方向,注意我们不会直接退出,而是会继续等待 server 的应答,直到 server 完成自己的操作,在另一个方向上完成关闭。
- 在这里,我们会第一次接触到 select 多路复用,这里不展开讲,你只需要记住,使用 select 使得我们可以 同时完成 对 连接套接字 和 标准输入 两个 I/O 对象的处理。
# include "lib/common.h"
# define MAXLINE 4096
int main(int argc, char **argv) {
if (argc != 2) {
error(1, 0, "usage: graceclient <IPaddress>");
}
// 创建了一个 TCP 套接字
int socket_fd;
socket_fd = socket(AF_INET, SOCK_STREAM, 0);
// 设置了连接的目标服务器 IPv4 地址,绑定到了指定的 IP 和端口
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERV_PORT);
inet_pton(AF_INET, argv[1], &server_addr.sin_addr);
// 使用创建的套接字,向目标 IPv4 地址发起连接请求
socklen_t server_len = sizeof(server_addr);
int connect_rt = connect(socket_fd, (struct sockaddr *) &server_addr, server_len);
if (connect_rt < 0) {
error(1, errno, "connect failed ");
}
char send_line[MAXLINE], recv_line[MAXLINE + 1];
int n;
fd_set readmask;
fd_set allreads;
// 为使用 select 做准备,初始化描述字集合
FD_ZERO(&allreads);
FD_SET(0, &allreads);
FD_SET(socket_fd, &allreads);
// 程序主体部分:用 select 多路复用观测在 连接套接字 和 标准输入 上的 I/O 事件
for (;;) {
readmask = allreads;
int rc = select(socket_fd + 1, &readmask, NULL, NULL, NULL);
if (rc <= 0)
error(1, errno, "select failed");
// 当连接套接字上有数据可读,将数据读入到程序缓冲区中
if (FD_ISSET(socket_fd, &readmask)) {
n = read(socket_fd, recv_line, MAXLINE);
if (n < 0) {
error(1, errno, "read error"); // 如果有异常则报错退出
} else if (n == 0) {
error(1, 0, "server terminated \n"); // 如果读到 server 发送的 EOF 则正常退出
}
recv_line[n] = 0;
fputs(recv_line, stdout);
fputs("\n", stdout);
}
// 当标准输入上有数据可读,读入后进行判断。
// 如果输入的是“shutdown”,则关闭标准输入的 I/O 事件感知,并调用 shutdown 函数关闭写方向
// 如果输入的是”close“,则调用 close 函数关闭连接
if (FD_ISSET(0, &readmask)) {
if (fgets(send_line, MAXLINE, stdin) != NULL) {
if (strncmp(send_line, "shutdown", 8) == 0) {
FD_CLR(0, &allreads);
if (shutdown(socket_fd, 1)) {
error(1, errno, "shutdown failed");
}
} else if (strncmp(send_line, "close", 5) == 0) {
FD_CLR(0, &allreads);
if (close(socket_fd)) {
error(1, errno, "close failed");
}
sleep(6);
exit(0);
} else {
// 处理正常的输入,将回车符截掉,调用 write 函数,通过套接字将数据发送给 server 。
int i = strlen(send_line);
if (send_line[i - 1] == '\n') {
send_line[i - 1] = 0;
}
printf("now sending %s\n", send_line);
size_t rt = write(socket_fd, send_line, strlen(send_line));
if (rt < 0) {
error(1, errno, "write failed ");
}
printf("send bytes: %zu \n", rt);
}
}
}
}
}
server 端,连接建立之后,打印出接收的字节,并重新格式化后,发送给 client。代码如下:
#include "lib/common.h"
static int count;
static void sig_int(int signo) {
printf("\nreceived %d datagrams\n", count);
exit(0); // exit后,操作系统内核协议栈会接管后续的处理: 即发送 FIN 报文
}
int main(int argc, char **argv) {
// 创建了一个 TCP 套接字
int listenfd;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
// 设置了本地服务器 IPv4 地址,绑定到了 ANY 地址和指定的端口
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(SERV_PORT);
// 使用创建的套接字,以此执行 bind、listen 和 accept 操作,完成连接建立
int rt1 = bind(listenfd, (struct sockaddr *) &server_addr, sizeof(server_addr));
if (rt1 < 0) {
error(1, errno, "bind failed ");
}
int rt2 = listen(listenfd, LISTENQ);
if (rt2 < 0) {
error(1, errno, "listen failed ");
}
signal(SIGINT, sig_int);
signal(SIGPIPE, SIG_IGN);
int connfd;
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
if ((connfd = accept(listenfd, (struct sockaddr *) &client_addr, &client_len)) < 0) {
error(1, errno, "bind failed ");
}
char message[MAXLINE];
count = 0;
// 程序的主体:通过 read 函数获取 client 传送来的数据流,并回送给 client
for (;;) {
int n = read(connfd, message, MAXLINE);
if (n < 0) {
error(1, errno, "error read");
} else if (n == 0) {
error(1, 0, "client closed \n");
}
message[n] = 0;
printf("received %d bytes: %s\n", n, message); // 显示收到的字符串
count++;
char send_line[MAXLINE];
sprintf(send_line, "Hi, %s", message); // 对原字符串进行重新格式化
sleep(5); // 发送之前,让 server 程序休眠了 5 秒,以模拟 server 处理的时间
int write_nc = send(connfd, send_line, strlen(send_line), 0); // 调用 send 函数将数据发送给 client
printf("send bytes: %zu \n", write_nc);
if (write_nc < 0) {
error(1, errno, "error write");
}
}
}
-------=
效果如下:
我们启动 server ,再启动 client,依次在标准输入上输入 data1、data2 和 close,观察一段时间后我们看到:
$./graceclient 127.0.0.1
data1
now sending data1
send bytes:5
data2
now sending data2
send bytes:5
Hi,data1
close
$./graceserver
received 5 bytes: data1
send bytes: 9
received 5 bytes: data2
send bytes: 9
client closed
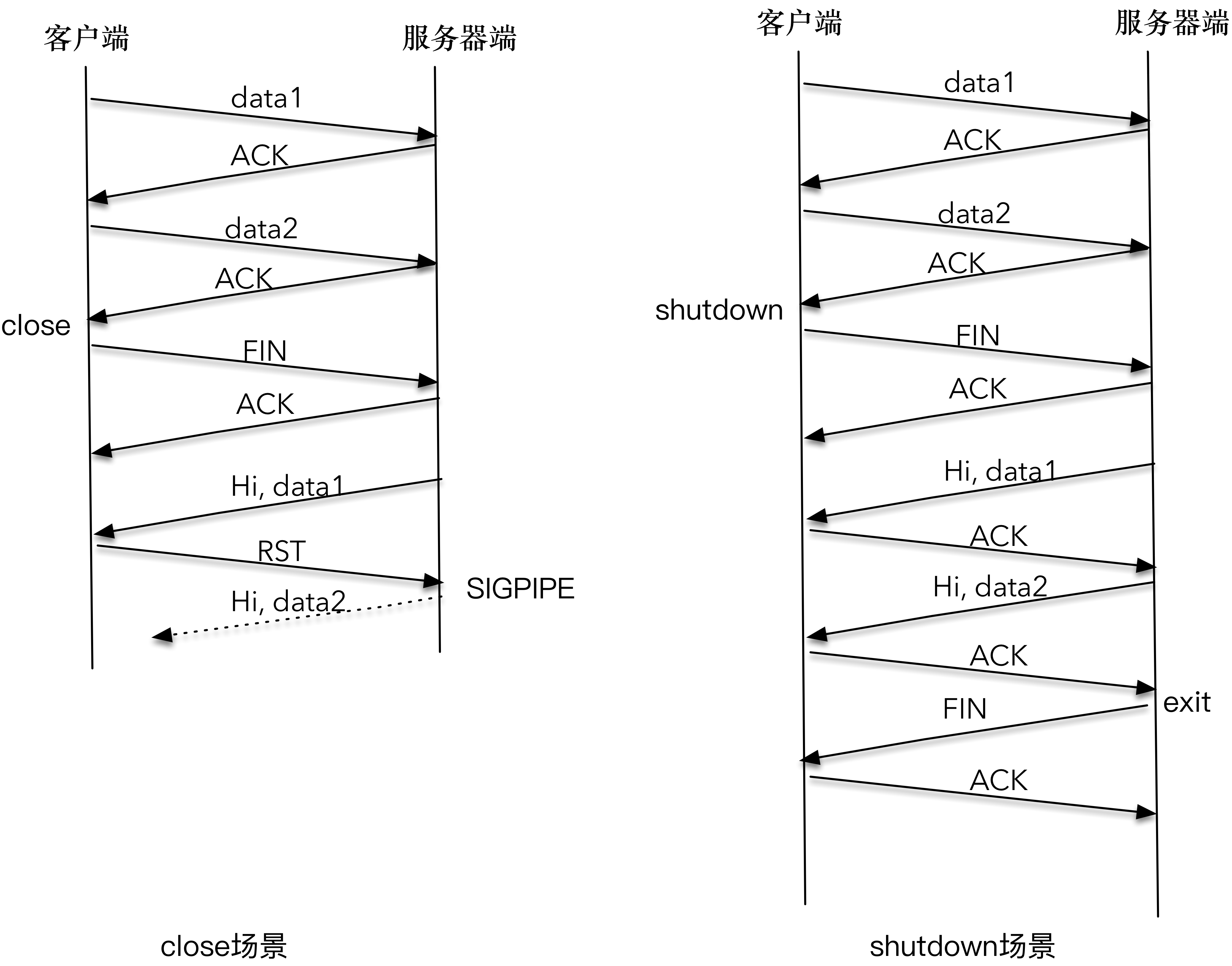
client 依次发送了 data1 和 data2,server 也正常接收到 data1 和 data2。在 client 端 close 掉整个连接之后,server 接收到 SIGPIPE 信号,直接退出。client 并没有收到 server 的应答数据。
下图详细解释了 client 和 server 交互的时序图。
- 因为 client 调用 close() 关闭了整个连接,当 server 发送的 “Hi, data1” 分组到达时, client 给回送一个 RST 分组;
- server 再次尝试发送 “Hi, data2” 第二个应答分组时,系统内核通知 SIGPIPE 信号。这是因为,在 RST 的套接字进行写操作,会直接触发 SIGPIPE 信号。
- 这就是程序莫名其妙终止的原因
- 我们可以像这样注册一个信号处理函数,对 SIGPIPE 信号进行处理,避免程序莫名退出:
static void sig_pipe(int signo) {
printf("\nreceived %d datagrams\n", count);
exit(0);
}
signal(SIGINT, sig_pipe);
接下来,再次启动 server,再启动 client,依次在标准输入上输入 data1、data2 和 shutdown 函数,观察一段时间后我们看到:
- 和前面的结果不同,server 输出了 data1、data2;
- client 也输出了 “Hi,data1” 和 “Hi,data2”
- client 和 server 各自完成了自己的工作后,正常退出。
$./graceclient 127.0.0.1
data1
now sending data1
send bytes:5
data2
now sending data2
send bytes:5
shutdown
Hi, data1
Hi,data2
server terminated
$./graceserver
received 5 bytes: data1
send bytes: 9
received 5 bytes: data2
send bytes: 9
client closed
我们再看下 client 和 server 交互的时序图。
- 因为 client 调用 shutdown() 只是关闭连接的一个方向, server 到 client 的这个方向还可以继续进行数据的发送和接收,所以 “Hi,data1” 和 “Hi,data2” 都可以正常传送;
- 当 server 读到 EOF 时,立即向 client 发送了 FIN 报文, client 在 read 函数中感知了 EOF,也进行了正常退出。
close 函数关闭连接有两个需要明确的地方。
- close 函数只是把套接字引用计数减 1,未必会立即关闭连接;
- close 函数如果在套接字引用计数达到 0 时,立即终止读和写两个方向的数据传送。
基于这两个确定,在期望关闭连接其中一个方向时,应该使用 shutdown 函数。
九、tcp 探活
udp不需要连接,为了连接而保活是不必要的,如果为了探测对端是否正常工作而做ping-pong也是可行的。
之前我们讲到了如何使用 close 和 shutdown 来完成连接的关闭,在大多数情况下,我们会优选 shutdown 来完成对连接一个方向的关闭,待对端处理完之后,再完成另外一个方向的关闭。
在很多情况下,连接的一端需要一直感知连接的状态,如果连接无效了,应用程序可能需要报错,或者重新发起连接等。(例如打游戏 朋友的电脑突然蓝屏死机 朋友的角色还残留于游戏中,所以服务器为了判定他是否真的存活还是需要一个心跳包 隔了一段时间过后把朋友角色踢下线)。本文将体验连接状态的检测。
案例:做过一个基于 NATS 消息系统的项目,多个消息的提供者 (pub)和订阅者(sub)都连到 NATS 消息系统,通过这个系统来完成消息的投递和订阅处理。
突然有一天,线上报了一个故障,一个流程不能正常处理。经排查,发现消息正确地投递到了 NATS 服务端,但是消息订阅者没有收到该消息,也没能做出处理,导致流程没能进行下去。
通过观察消息订阅者后发现,消息订阅者到 NATS 服务端的连接虽然显示是“正常”的,但实际上,这个连接已经是无效的了。为什么呢?这是因为 NATS 服务器崩溃过,NATS 服务器和消息订阅者之间的连接中断 FIN 包,由于异常情况,没能够正常到达消息订阅者,这样造成的结果就是消息订阅者一直维护着一个“过时的”连接,不会收到 NATS 服务器发送来的消息。
这个故障的根本原因在于,作为 NATS 服务器的客户端,消息订阅者没有及时对连接的有效性进行检测,这样就造成了问题。
保持对连接有效性的检测,是我们在实战中必须要注意的一个点。
9.1 TCP Keep-Alive 选项
TCP 有一个保持活跃的机制叫做 Keep-Alive。其机制如下:
定义一个时间段,在这个时间段内,如果没有任何连接相关的活动,TCP 保活机制会开始作用,每隔一个时间间隔,发送一个探测报文,该探测报文包含的数据非常少,如果连续几个探测报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。
有三个变量控制,可通过 sysctl 修改:
- 保活时间长度 net.ipv4.tcp_keepalive_time,默认 7200 秒(2 小时)
- 保活时间间隔 net.ipv4.tcp_keepalive_intvl,默认 75 秒
- 保活探测次数 net.ipv4.tcp_keepalve_probes,默认 9 次探测
如果开启了 TCP 保活,需要考虑以下几种情况:
- 第一种,对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
- 第二种,对端程序崩溃并重启。当 TCP 保活的探测报文发送给对端后,对端是可以响应的,但由于没有该连接的有效信息,会产生一个 RST 报文,这样很快就会发现 TCP 连接已经被重置。
- 第三种,是对端程序崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
TCP 保活机制默认是关闭的,当我们选择打开时,可以分别在连接的两个方向上开启,也可以单独在一个方向上开启。如果开启服务器端到客户端的检测,就可以在客户端非正常断连的情况下清除在服务器端保留的“脏数据”;而开启客户端到服务器端的检测,就可以在服务器无响应的情况下,重新发起连接。
为什么 TCP 不提供一个频率很好的保活机制呢?我的理解是早期的网络带宽非常有限,如果提供一个频率很高的保活机制,对有限的带宽是一个比较严重的浪费。
9.2 应用层探活
如果使用 TCP 自身的 keep-Alive 机制,在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个“死亡”连接。这个时间是怎么计算出来的呢?其实是通过 2 小时,加上 75 秒乘以 9 的总和。实际上,对很多对时延要求敏感的系统中,这个时间间隔是不可接受的。
所以,必须在应用程序这一层来寻找更好的解决方案。
我们可以通过在应用程序中模拟 TCP Keep-Alive 机制,来完成在应用层的连接探活。
我们可以设计一个 PING-PONG 的机制,需要保活的一方,比如客户端,在保活时间达到后,发起对连接的 PING 操作,如果服务器端对 PING 操作有回应,则重新设置保活时间,否则对探测次数进行计数,如果最终探测次数达到了保活探测次数预先设置的值之后,则认为连接已经无效。
这里有两个比较关键的点:第一个是需要使用定时器,这可以通过使用 I/O 复用自身的机制来实现;第二个是需要设计一个 PING-PONG 的协议。下面我们尝试来完成这样的一个设计。
消息格式设计如下:我们的程序是客户端来发起保活,为此定义了一个消息对象。你可以在文稿中看到这个消息对象,这个消息对象是一个结构体,前 4 个字节标识了消息类型,为了简单,这里设计了MSG_PING、MSG_PONG、MSG_TYPE 1和MSG_TYPE 2四种消息类型。
typedef struct {
u_int32_t type;
char data[1024];
} messageObject;
#define MSG_PING 1
#define MSG_PONG 2
#define MSG_TYPE1 11
#define MSG_TYPE2 21
client 端如下:完全模拟 TCP Keep-Alive 的机制,在保活时间达到后,探活次数增加 1,同时向服务器端发送 PING 格式的消息,此后以预设的保活时间间隔,不断地向服务器端发送 PING 格式的消息。如果能收到服务器端的应答,则结束保活,将保活时间置为 0。这里我们使用 select I/O 复用函数自带的定时器,select 函数将在后面详细介绍。
#include "lib/common.h"
#include "message_objecte.h"
#define MAXLINE 4096
#define KEEP_ALIVE_TIME 10
#define KEEP_ALIVE_INTERVAL 3
#define KEEP_ALIVE_PROBETIMES 3
int main(int argc, char **argv) {
if (argc != 2) {
error(1, 0, "usage: tcpclient <IPaddress>");
}
int socket_fd;
socket_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERV_PORT);
inet_pton(AF_INET, argv[1], &server_addr.sin_addr);
socklen_t server_len = sizeof(server_addr);
int connect_rt = connect(socket_fd, (struct sockaddr *) &server_addr, server_len);
if (connect_rt < 0) {
error(1, errno, "connect failed ");
}
char recv_line[MAXLINE + 1];
int n;
fd_set readmask;
fd_set allreads;
struct timeval tv;
int heartbeats = 0;
tv.tv_sec = KEEP_ALIVE_TIME; // 设置了超时时间为 KEEP_ALIVE_TIME,这相当于保活时间
tv.tv_usec = 0;
messageObject messageObject;
FD_ZERO(&allreads); // 初始化 select 函数的套接字
FD_SET(socket_fd, &allreads);
for (;;) {
readmask = allreads;
int rc = select(socket_fd + 1, &readmask, NULL, NULL, &tv); // 调用 select 函数,感知 I/O 事件。这里的 I/O 事件,除了套接字上的读操作之外,还有在 39-40 行设置的超时事件。当 KEEP_ALIVE_TIME 这段时间到达之后,select 函数会返回 0,于是进入 53-63 行的处理
if (rc < 0) {
error(1, errno, "select failed");
}
if (rc == 0) {
// 客户端已经在 KEEP_ALIVE_TIME 这段时间内没有收到任何对当前连接的反馈,于是发起 PING 消息,尝试问服务器端:”喂,你还活着吗?“这里我们通过传送一个类型为 MSG_PING 的消息对象来完成 PING 操作,之后我们会看到服务器端程序如何响应这个 PING 操作
if (++heartbeats > KEEP_ALIVE_PROBETIMES) {
error(1, 0, "connection dead\n");
}
printf("sending heartbeat #%d\n", heartbeats);
messageObject.type = htonl(MSG_PING);
rc = send(socket_fd, (char *) &messageObject, sizeof(messageObject), 0);
if (rc < 0) {
error(1, errno, "send failure");
}
tv.tv_sec = KEEP_ALIVE_INTERVAL;
continue;
}
if (FD_ISSET(socket_fd, &readmask)) {
// 客户端在接收到服务器端程序之后的处理。为了简单,这里就没有再进行报文格式的转换和分析。在实际的工作中,这里其实是需要对报文进行解析后处理的,只有是 PONG 类型的回应,我们才认为是 PING 探活的结果。这里认为既然收到服务器端的报文,那么连接就是正常的,所以会对探活计数器和探活时间都置零,等待下一次探活时间的来临。
n = read(socket_fd, recv_line, MAXLINE);
if (n < 0) {
error(1, errno, "read error");
} else if (n == 0) {
error(1, 0, "server terminated \n");
}
printf("received heartbeat, make heartbeats to 0 \n");
heartbeats = 0;
tv.tv_sec = KEEP_ALIVE_TIME;
}
}
}
server 端设计如下:server 的程序接受一个参数,这个参数设置的比较大,可以模拟连接没有响应的情况。
- 服务器端程序在接收到客户端发送来的各种消息后,进行处理,其中如果发现是 PING 类型的消息,在休眠一段时间后回复一个 PONG 消息,告诉客户端:”嗯,我还活着。“
- 当然,如果这个休眠时间很长的话,那么客户端就无法快速知道服务器端是否存活,这是我们模拟连接无响应的一个手段而已,实际情况下,应该是系统崩溃,或者网络异常。
#include "lib/common.h"
#include "message_objecte.h"
static int count;
int main(int argc, char **argv) {
if (argc != 2) {
error(1, 0, "usage: tcpsever <sleepingtime>");
}
int sleepingTime = atoi(argv[1]);
int listenfd;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(SERV_PORT);
int rt1 = bind(listenfd, (struct sockaddr *) &server_addr, sizeof(server_addr));
if (rt1 < 0) {
error(1, errno, "bind failed ");
}
int rt2 = listen(listenfd, LISTENQ);
if (rt2 < 0) {
error(1, errno, "listen failed ");
}
int connfd;
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
if ((connfd = accept(listenfd, (struct sockaddr *) &client_addr, &client_len)) < 0) {
error(1, errno, "bind failed ");
}
messageObject message;
count = 0;
for (;;) {
int n = read(connfd, (char *) &message, sizeof(messageObject));
if (n < 0) {
error(1, errno, "error read");
} else if (n == 0) {
error(1, 0, "client closed \n");
}
printf("received %d bytes\n", n);
count++;
switch (ntohl(message.type)) {
case MSG_TYPE1 :
printf("process MSG_TYPE1 \n");
break;
case MSG_TYPE2 :
printf("process MSG_TYPE2 \n");
break;
case MSG_PING: {
// 处理 MSG_PING 类型的消息。通过休眠来模拟响应是否及时,然后调用 send 函数发送一个 PONG 报文,向客户端表示”还活着“的意思;
messageObject pong_message;
pong_message.type = MSG_PONG;
sleep(sleepingTime);
ssize_t rc = send(connfd, (char *) &pong_message, sizeof(pong_message), 0);
if (rc < 0)
error(1, errno, "send failure");
break;
}
default :
error(1, 0, "unknown message type (%d)\n", ntohl(message.type));
}
}
}
基于上面的程序设计,让我们分别做两个不同的实验:
第一次实验,服务器端休眠时间为 60 秒。我们看到,客户端在发送了三次心跳检测报文 PING 报文后,判断出连接无效,直接退出了。之所以造成这样的结果,是因为在这段时间内没有接收到来自服务器端的任何 PONG 报文。当然,实际工作的程序,可能需要不一样的处理,比如重新发起连接。
$./pingclient 127.0.0.1
sending heartbeat #1
sending heartbeat #2
sending heartbeat #3
connection dead
$./pingserver 60
received 1028 bytes
received 1028 bytes
第二次实验,我们让服务器端休眠时间为 5 秒。我们看到,由于这一次服务器端在心跳检测过程中,及时地进行了响应,客户端一直都会认为连接是正常的。
$./pingclient 127.0.0.1
sending heartbeat #1
sending heartbeat #2
received heartbeat, make heartbeats to 0
received heartbeat, make heartbeats to 0
sending heartbeat #1
sending heartbeat #2
received heartbeat, make heartbeats to 0
received heartbeat, make heartbeats to 0
$./pingserver 5
received 1028 bytes
received 1028 bytes
received 1028 bytes
received 1028 bytes
十、tcp 的动态数据传输
本文将通俗易懂的解释发送窗口、接收窗口、拥塞窗口的含义。
应用程序使用 write 或者 send 方法来进行数据流的发送,用这些接口并不意味着数据被真正发送到网络上,其实,这些数据只是从应用程序中被拷贝到了系统内核的套接字缓冲区中,或者说是发送缓冲区中,等待协议栈的处理。至于这些数据是什么时候被发送出去的,对应用程序来说,是无法预知的。对这件事情真正负责的,是运行于操作系统内核的 TCP 协议栈实现模块。
10.1 流量控制和生产者 - 消费者模型
可以把理想中的 TCP 协议可以想象成一队运输货物的货车,运送的货物就是 TCP 数据包,这些货车将数据包从发送端运送到接收端,就这样不断周而复始。
我们仔细想一下,货物达到接收端之后,是需要卸货处理、登记入库的,接收端限于自己的处理能力和仓库规模,是不可能让这队货车以不可控的速度发货的。接收端肯定会和发送端不断地进行信息同步,比如接收端通知发送端:“后面那 20 车你给我等等,等我这里腾出地方你再继续发货。”
其实这就是发送窗口和接收窗口的本质,我管这个叫做“TCP 的生产者 - 消费者”模型。
发送窗口和接收窗口是 TCP 连接的双方,一个作为生产者,一个作为消费者,为了达到一致协同的生产 - 消费速率、而产生的算法模型实现。
说白了,作为 TCP 发送端,也就是生产者,不能忽略 TCP 的接收端,也就是消费者的实际状况,不管不顾地把数据包都传送过来。如果都传送过来,消费者来不及消费,必然会丢弃;而丢弃反过使得生产者又重传,发送更多的数据包,最后导致网络崩溃。
我想,理解了“TCP 的生产者 - 消费者”模型,再反过来看发送窗口和接收窗口的设计目的和方式,我们就会恍然大悟了。
10.1.1 拥塞控制和数据传输
TCP 的生产者 - 消费者模型,只是在考虑单个连接的数据传递,但是, TCP 数据包是需要经过网卡、交换机、核心路由器等一系列的网络设备的,网络设备本身的能力也是有限的,当多个连接的数据包同时在网络上传送时,势必会发生带宽争抢、数据丢失等,这样,TCP 就必须考虑多个连接共享在有限的带宽上,兼顾效率和公平性的控制,这就是拥塞控制的本质。
举个形象一点的例子,有一个货车行驶在半夜三点的大路上,这样的场景是断然不需要拥塞控制的。
我们可以把网络设备形成的网络信息高速公路和生活中实际的高速公路做个对比。正是因为有多个 TCP 连接,形成了高速公路上的多队运送货车,高速公路上开始变得熙熙攘攘,这个时候,就需要拥塞控制的接入了。
在 TCP 协议中,拥塞控制是通过拥塞窗口来完成的,拥塞窗口的大小会随着网络状况实时调整。
拥塞控制常用的算法有“慢启动”,它通过一定的规则,慢慢地将网络发送数据的速率增加到一个阈值。超过这个阈值之后,慢启动就结束了,另一个叫做“拥塞避免”的算法登场。在这个阶段,TCP 会不断地探测网络状况,并随之不断调整拥塞窗口的大小。
现在你可以发现,在任何一个时刻,TCP 发送缓冲区的数据是否能真正发送出去,至少取决于两个因素,一个是当前的发送窗口大小,另一个是拥塞窗口大小,而 TCP 协议中总是取两者中最小值作为判断依据。比如当前发送的字节为 100,发送窗口的大小是 200,拥塞窗口的大小是 80,那么取 200 和 80 中的最小值,就是 80,当前发送的字节数显然是大于拥塞窗口的,结论就是不能发送出去。
这里千万要分清楚发送窗口和拥塞窗口的区别。
- 发送窗口反应了作为单 TCP 连接、点对点之间的流量控制模型,它是需要和接收端一起共同协调来调整大小的;
- 而拥塞窗口则是反应了作为多个 TCP 连接共享带宽的拥塞控制模型,它是发送端独立地根据网络状况来动态调整的。
10.1.2 一些有趣的场景
注意我在前面的表述中,提到了在任何一个时刻里,TCP 发送缓冲区的数据是否能真正发送出去,用了“至少两个因素”这个说法,细心的你有没有想过这个问题,除了之前引入的发送窗口、拥塞窗口之外,还有什么其他因素吗?
我们考虑以下几个有趣的场景:
第一个场景,接收端处理得急不可待,比如刚刚读入了 100 个字节,就告诉发送端:“喂,我已经读走 100 个字节了,你继续发”,在这种情况下,你觉得发送端应该怎么做呢?
第二个场景是所谓的“交互式”场景,比如我们使用 telnet 登录到一台服务器上,或者使用 SSH 和远程的服务器交互,这种情况下,我们在屏幕上敲打了一个命令,等待服务器返回结果,这个过程需要不断和服务器端进行数据传输。这里最大的问题是,每次传输的数据可能都非常小,比如敲打的命令“pwd”,仅仅三个字符。这意味着什么?这就好比,每次叫了一辆大货车,只送了一个小水壶。在这种情况下,你又觉得发送端该怎么做才合理呢?
第三个场景是从接收端来说的。我们知道,接收端需要对每个接收到的 TCP 分组进行确认,也就是发送 ACK 报文,但是 ACK 报文本身是不带数据的分段,如果一直这样发送大量的 ACK 报文,就会消耗大量的带宽。之所以会这样,是因为 TCP 报文、IP 报文固有的消息头是不可或缺的,比如两端的地址、端口号、时间戳、序列号等信息, 在这种情形下,你觉得合理的做法是什么?
TCP 之所以复杂,就是因为 TCP 需要考虑的因素较多。像以上这几个场景,都是 TCP 需要考虑的情况,一句话概况就是如何有效地利用网络带宽。
第一个场景也被叫做糊涂窗口综合症,这个场景需要在接收端进行优化。也就是说,接收端不能在接收缓冲区空出一个很小的部分之后,就急吼吼地向发送端发送窗口更新通知,而是需要在自己的缓冲区大到一个合理的值之后,再向发送端发送窗口更新通知。这个合理的值,由对应的 RFC 规范定义。
第二个场景需要在发送端进行优化。这个优化的算法叫做 Nagle 算法,Nagle 算法的本质其实就是限制大批量的小数据包同时发送,为此,它提出,在任何一个时刻,未被确认的小数据包不能超过一个。这里的小数据包,指的是长度小于最大报文段长度 MSS 的 TCP 分组。这样,发送端就可以把接下来连续的几个小数据包存储起来,等待接收到前一个小数据包的 ACK 分组之后,再将数据一次性发送出去。
第三个场景,也是需要在接收端进行优化,这个优化的算法叫做延时 ACK。延时 ACK 在收到数据后并不马上回复,而是累计需要发送的 ACK 报文,等到有数据需要发送给对端时,将累计的 ACK捎带一并发送出去。当然,延时 ACK 机制,不能无限地延时下去,否则发送端误认为数据包没有发送成功,引起重传,反而会占用额外的网络带宽。
10.2 禁用 Nagle 算法
有没有发现一个很奇怪的组合,即 Nagle 算法和延时 ACK 的组合。
这个组合为什么奇怪呢?我举一个例子你来体会一下。
比如,客户端分两次将一个请求发送出去,由于请求的第一部分的报文未被确认,Nagle 算法开始起作用;同时延时 ACK 在服务器端起作用,假设延时时间为 200ms,服务器等待 200ms 后,对请求的第一部分进行确认;接下来客户端收到了确认后,Nagle 算法解除请求第二部分的阻止,让第二部分得以发送出去,服务器端在收到之后,进行处理应答,同时将第二部分的确认捎带发送出去。
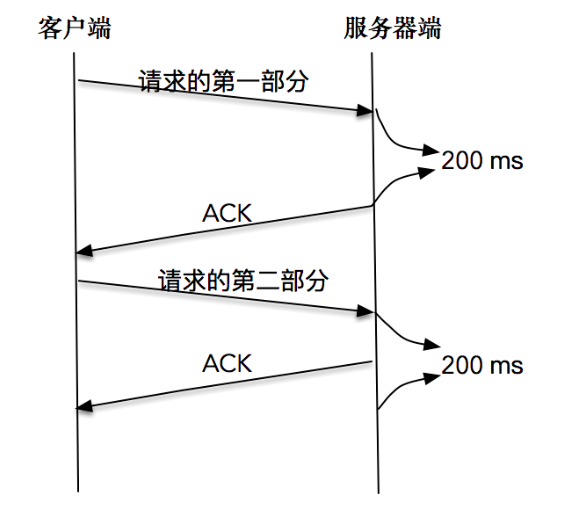
你从这张图中可以看到,Nagle 算法和延时确认组合在一起,增大了处理时延,实际上,两个优化彼此在阻止对方。
从上面的例子可以看到,在有些情况下 Nagle 算法并不适用, 比如对时延敏感的应用。
幸运的是,我们可以通过对套接字的修改来关闭 Nagle 算法。
int on = 1;
setsockopt(sock, IPPROTO_TCP, TCP_NODELAY, (void *)&on, sizeof(on));
值得注意的是,除非我们对此有十足的把握,否则不要轻易改变默认的 TCP Nagle 算法。因为在现代操作系统中,针对 Nagle 算法和延时 ACK 的优化已经非常成熟了,有可能在禁用 Nagle 算法之后,性能问题反而更加严重。
10.3 合并写操作
其实前面的例子里,如果我们能将一个请求一次性发送过去,而不是分开两部分独立发送,结果会好很多。所以,在写数据之前,将数据合并到缓冲区,批量发送出去,这是一个比较好的做法。不过,有时候数据会存储在两个不同的缓存中,对此,我们可以使用如下的方法来进行数据的读写操作,从而避免 Nagle 算法引发的副作用。
ssize_t writev(int filedes, const struct iovec *iov, int iovcnt)
ssize_t readv(int filedes, const struct iovec *iov, int iovcnt);
这两个函数的第二个参数都是指向某个 iovec 结构数组的一个指针,其中 iovec 结构定义如下:
struct iovec {
void *iov_base; /* starting address of buffer */
size_t iov_len; /* size of buffer */
};
下面的程序展示了集中写的方式:
int main(int argc, char **argv) {
if (argc != 2) {
error(1, 0, "usage: tcpclient <IPaddress>");
}
int socket_fd;
socket_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERV_PORT);
inet_pton(AF_INET, argv[1], &server_addr.sin_addr);
socklen_t server_len = sizeof(server_addr);
int connect_rt = connect(socket_fd, (struct sockaddr *) &server_addr, server_len);
if (connect_rt < 0) {
error(1, errno, "connect failed ");
}
char buf[128];
struct iovec iov[2];
char *send_one = "hello,";
iov[0].iov_base = send_one;
iov[0].iov_len = strlen(send_one);
iov[1].iov_base = buf;
while (fgets(buf, sizeof(buf), stdin) != NULL) {
iov[1].iov_len = strlen(buf);
int n = htonl(iov[1].iov_len);
if (writev(socket_fd, iov, 2) < 0)
error(1, errno, "writev failure");
}
exit(0);
}
这个程序的前半部分创建套接字,建立连接就不再赘述了。关键的是 24-33 行,使用了 iovec 数组,分别写入了两个不同的字符串,一个是“hello,”,另一个通过标准输入读入。
在启动该程序之前,我们需要启动服务器端程序,在客户端依次输入“world”和“network”:
world
network
接下来我们可以看到服务器端接收到了 iovec 组成的新的字符串。这里的原理其实就是在调用 writev 操作时,会自动把几个数组的输入合并成一个有序的字节流,然后发送给对端。
received 12 bytes: hello,world
received 14 bytes: hello,network
总结:
- 发送窗口用来控制发送和接收端的流量;阻塞窗口用来控制多条连接公平使用的有限带宽。
- 小数据包加剧了网络带宽的浪费,为了解决这个问题,引入了如 Nagle 算法、延时 ACK 等机制。
- 在程序设计层面,不要多次频繁地发送小报文,如果有,可以使用 writev 批量发送。
十一、Address already in use 错误
当服务器端程序重启之后,总是碰到“Address in use”的报错信息,服务器程序不能很快地重启。那么这个问题是如何产生的?我们又该如何避免呢?
为了引入讨论,我们从之前讲过的一个 TCP 服务器端程序开始说起:
static int count;
static void sig_int(int signo) {
printf("\nreceived %d datagrams\n", count);
exit(0);
}
int main(int argc, char **argv) {
int listenfd;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(SERV_PORT);
int rt1 = bind(listenfd, (struct sockaddr *) &server_addr, sizeof(server_addr));
if (rt1 < 0) {
error(1, errno, "bind failed ");
}
int rt2 = listen(listenfd, LISTENQ);
if (rt2 < 0) {
error(1, errno, "listen failed ");
}
signal(SIGPIPE, SIG_IGN);
int connfd;
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
if ((connfd = accept(listenfd, (struct sockaddr *) &client_addr, &client_len)) < 0) {
error(1, errno, "bind failed ");
}
char message[MAXLINE];
count = 0;
for (;;) {
int n = read(connfd, message, MAXLINE);
if (n < 0) {
error(1, errno, "error read");
} else if (n == 0) {
error(1, 0, "client closed \n");
}
message[n] = 0;
printf("received %d bytes: %s\n", n, message);
count++;
}
}
这个 server 绑定到一个本地 port,用的是通配地址 ANY,当连接建立后,从该连接读取输入的字符流。启动 server 后,再用 telnet 向此 server 输入字符:
和我们期望的一样,服务器端打印出 Telnet 客户端的输入。在 Telnet 端关闭连接之后,服务器端接收到 EOF,也顺利地关闭了连接。服务器端也可以很快重启,等待新的连接到来。
root@server:/home/yolanda/build/bin# ./addressused
received 3 bytes: a
received 3 bytes: b
received 3 bytes: c
client closed
root@server:/home/yolanda/build/bin# netstat -nultp | grep addressused
tcp 0 0 0.0.0.0:43211 0.0.0.0:* LISTEN 16053/addressused
root@client:/home/yolanda/build/bin# telnet -h
telnet: invalid option -- 'h'
Usage: telnet [-4] [-6] [-8] [-E] [-L] [-a] [-d] [-e char] [-l user]
[-n tracefile] [ -b addr ] [-r] [host-name [port]]
root@client:/home/yolanda/build/bin# telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
a
b
c
telnet> q # 用 ctrl+]然后再输入 q 来退出 telnet
Connection closed.
接下来,我们改变一下连接的关闭顺序。和前面的过程一样,先启动服务器,再使用 Telnet 作为客户端登录到服务器,在屏幕上输入一些字符。注意接下来的不同,我不会在 Telnet 端关闭连接,而是直接使用 Ctrl+C 的方式在服务器端关闭连接。
root@k8s-master-163:/home/yolanda/build/bin# ./addressused
received 3 bytes: a
received 3 bytes: b
received 3 bytes: c
^C
root@client:/home/yolanda/build/bin# telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
a
b
c
Connection closed by foreign host.
我们看到,连接已经被关闭,Telnet 客户端也感知连接关闭并退出了。接下来,我们尝试重启服务器端程序。你会发现,这个时候服务端程序重启失败,报错信息为:bind failed: Address already in use。
root@k8s-master-163:/home/yolanda/build/bin# ./addressused
received 3 bytes: a
received 3 bytes: b
received 3 bytes: c
^C
root@k8s-master-163:/home/yolanda/build/bin# ./addressused
bind failed : Address already in use (98)
这个错误实际是由于 TIME_WAIT 造成的:当连接的一方主动关闭连接,在接收到对端的 FIN 报文之后,主动关闭连接的一方会在 TIME_WAIT 这个状态里停留一段时间,这个时间大约为 2MSL。
如果我们此时使用 netstat 去查看服务器程序所在主机的 TIME_WAIT 的状态连接,你会发现有一个服务器程序生成的 TCP 连接,当前正处于 TIME_WAIT 状态。这里 9527 是本地监听端口,36650 是 telnet 客户端端口。当然了,Telnet 客户端端口每次也会不尽相同。
# 启动 server:
root@server:/home/yolanda/build/bin# ./addressused
# 启动 server 后,网络状态如下。都是 LISTEN 的:
root@server:~# netstat -alepn | grep 43211
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode PID/Program name
tcp 0 0 0.0.0.0:43211 0.0.0.0:* LISTEN 0 1177104853 39821/addressused
# 启动 telnet 作为 client,连接 server:
#
root@server:~# netstat -alepn | grep 43211
tcp 0 0 0.0.0.0:43211 0.0.0.0:* LISTEN 0 1177104853 39821/addressused
tcp 0 0 127.0.0.1:43211 127.0.0.1:42510 ESTABLISHED 0 1177104854 39821/addressused
tcp 0 0 127.0.0.1:42510 127.0.0.1:43211 ESTABLISHED 0 1177100853 40842/telnet
# 关闭 server 后,再启动会报错 Address in used 错误,同时网络状态有 TIME_WAIT
root@server:/home/yolanda/build/bin# ./addressused
bind failed : Address already in use (98)
root@server:~# netstat -alepn | grep 43211
tcp 0 0 127.0.0.1:43211 127.0.0.1:42510 TIME_WAIT 0 0 -
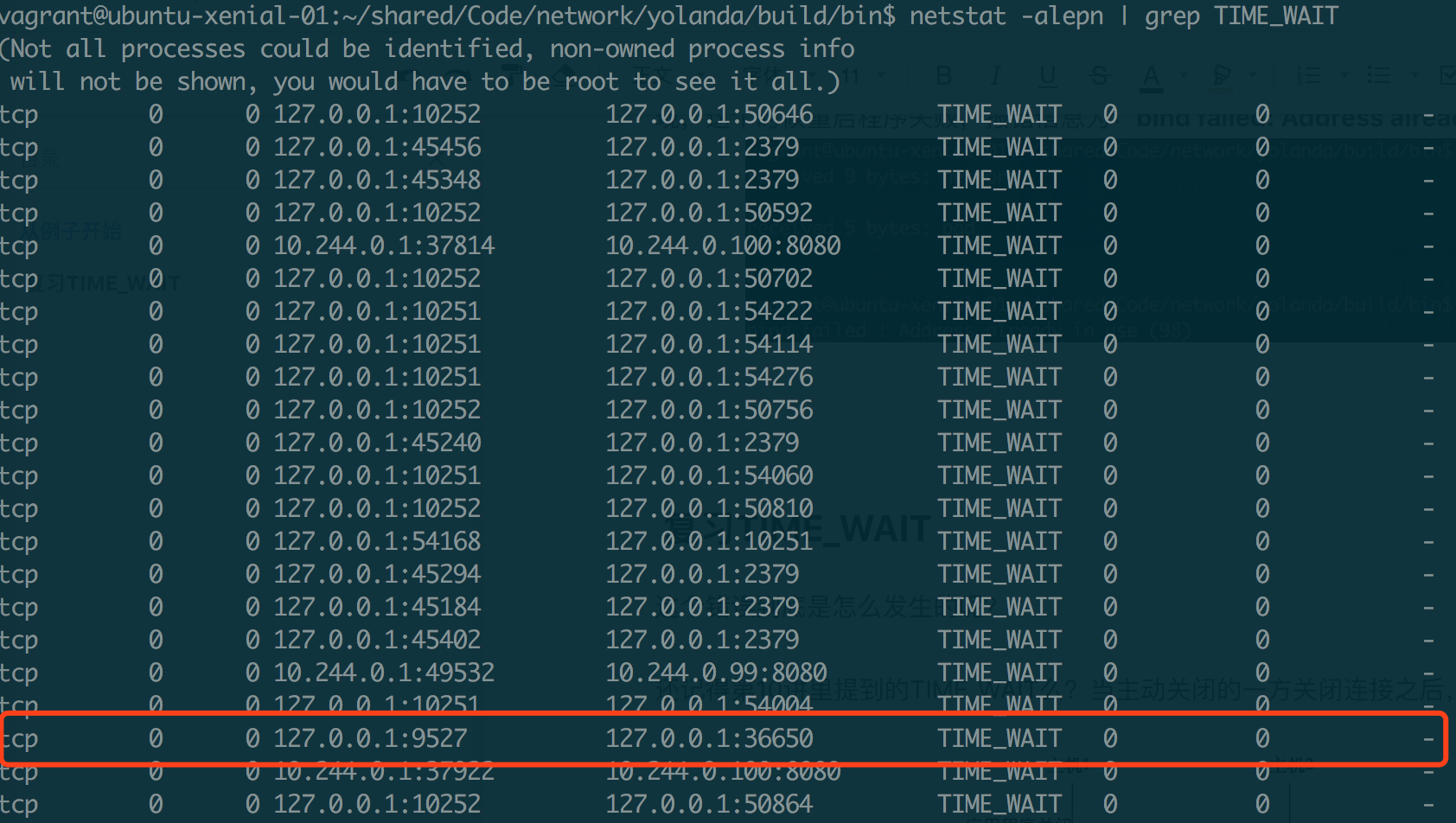
通过服务器端发起的关闭连接操作,引起了一个已有的 TCP 连接处于 TME_WAIT 状态,正是这个 TIME_WAIT 的连接,使得服务器重启时,继续绑定在 127.0.0.1 地址和 9527 端口上的操作,返回了Address already in use的错误。
11.1 重用 socket 选项
11.1.1 防止 Address already in use 错误
我们知道,一个 TCP 连接是通过四元组(源地址、源端口、目的地址、目的端口)来唯一确定的,如果每次 Telnet 客户端使用的本地端口都不同,就不会和已有的四元组冲突,也就不会有 TIME_WAIT 的新旧连接化身冲突的问题。
事实上,即使在很小的概率下,客户端 Telnet 使用了相同的端口,从而造成了新连接和旧连接的四元组相同,在现代 Linux 操作系统下,也不会有什么大的问题,原因是现代 Linux 操作系统对此进行了一些优化。
- 第一种优化是新连接 SYN 告知的初始序列号,一定比 TIME_WAIT 老连接的末序列号大,这样通过序列号就可以区别出新老连接。
- 第二种优化是开启了 tcp_timestamps,使得新连接的时间戳比老连接的时间戳大,这样通过时间戳也可以区别出新老连接。
在这样的优化之下,一个 TIME_WAIT 的 TCP 连接可以忽略掉旧连接,重新被新的连接所使用。
这就是重用套接字选项,通过给套接字配置可重用属性,告诉操作系统内核,这样的 TCP 连接完全可以复用 TIME_WAIT 状态的连接。代码片段已经放在文章中了:
int on = 1;
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
SO_REUSEADDR 套接字选项,允许启动绑定在一个端口,即使之前存在一个和该端口一样的连接。前面的例子已经表明,在默认情况下,服务器端历经创建 socket、bind 和 listen 重启时,如果试图绑定到一个现有连接上的端口,bind 操作会失败,但是如果我们在创建 socket 和 bind 之间,使用上面的代码片段设置 SO_REUSEADDR 套接字选项,情况就会不同。
下面我们对原来的服务器端代码进行升级,升级的部分主要在 11-12 行,在 bind 监听套接字之前,调用 setsockopt 方法,设置重用套接字选项:
int main(int argc, char **argv) {
int listenfd;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(SERV_PORT);
int on = 1;
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
int rt1 = bind(listenfd, (struct sockaddr *) &server_addr, sizeof(server_addr));
if (rt1 < 0) {
error(1, errno, "bind failed ");
}
int rt2 = listen(listenfd, LISTENQ);
if (rt2 < 0) {
error(1, errno, "listen failed ");
}
signal(SIGPIPE, SIG_IGN);
int connfd;
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
if ((connfd = accept(listenfd, (struct sockaddr *) &client_addr, &client_len)) < 0) {
error(1, errno, "bind failed ");
}
char message[MAXLINE];
count = 0;
for (;;) {
int n = read(connfd, message, MAXLINE);
if (n < 0) {
error(1, errno, "error read");
} else if (n == 0) {
error(1, 0, "client closed \n");
}
message[n] = 0;
printf("received %d bytes: %s\n", n, message);
count++;
}
}
重新编译过后,重复上面那个例子,先启动服务器,再使用 Telnet 作为客户端登录到服务器,在屏幕上输入一些字符,使用 Ctrl+C 的方式在服务器端关闭连接。马上尝试重启服务器,这个时候我们发现,服务器正常启动,没有出现Address already in use的错误。这说明我们的修改已经起作用。
$./addressused2
received 9 bytes: network
received 6 bytes: good
client closed
$./addressused2
11.1.2 不同地址上使用相同的端口提供服务
SO_REUSEADDR 套接字选项还有一个作用,那就是本机服务器如果有多个地址,可以在不同地址上使用相同的端口提供服务。
比如,一台服务器有 192.168.1.101 和 10.10.2.102 连个地址,我们可以在这台机器上启动三个不同的 HTTP 服务,第一个以本地通配地址 ANY 和端口 80 启动;第二个以 192.168.101 和端口 80 启动;第三个以 10.10.2.102 和端口 80 启动。
这样目的地址为 192.168.101,目的端口为 80 的连接请求会被发往第二个服务;目的地址为 10.10.2.102,目的端口为 80 的连接请求会被发往第三个服务;目的端口为 80 的所有其他连接请求被发往第一个服务。
我们必须给这三个服务设置 SO_REUSEADDR 套接字选项,否则第二个和第三个服务调用 bind 绑定到 80 端口时会出错。
11.1.3 最佳实践
最佳实践: 服务器端程序,都应该设置 SO_REUSEADDR 套接字选项,以便服务端程序可以在极短时间内复用同一个端口启动。
有些人可能觉得这不是安全的。其实,单独重用一个套接字不会有任何问题。
- 我在前面已经讲过,TCP 连接是通过四元组唯一区分的,只要客户端不使用相同的源端口,连接服务器是没有问题的,即使使用了相同的端口,根据序列号或者时间戳,也是可以区分出新旧连接的。
- 而且,TCP 的机制绝对不允许在相同的地址和端口上绑定不同的服务器,即使我们设置 SO_REUSEADDR 套接字选项,也不可能在 ANY 通配符地址下和端口 9527 上重复启动两个服务器实例。如果我们启动第二个服务器实例,不出所料会得到Address already in use的报错,即使当前还没有任何一条有效 TCP 连接产生。
注意:tcp_tw_reuse 的内核配置选项,这里又提到了 SO_REUSEADDR 套接字选择,这两个东西一点关系也没有。
- tcp_tw_reuse 是内核选项,主要用在连接的发起方。TIME_WAIT 状态的连接创建时间超过 1 秒后,新的连接才可以被复用,注意,这里是连接的发起方;tcp_tw_reuse是为了缩短time_wait的时间,避免出现大量的time_wait链接而占用系统资源,解决的是accept后的问题
- SO_REUSEADDR 是用户态的选项,SO_REUSEADDR 选项用来告诉操作系统内核,如果端口已被占用,但是 TCP 连接状态位于 TIME_WAIT,可以重用端口。如果端口忙,而 TCP 处于其他状态,重用端口时依旧得到 “Address already in use” 的错误信息。注意,这里一般都是连接的服务方。SO_REUSEADDR是为了解决time_wait状态带来的端口占用问题,以及支持同一个port对应多个ip,解决的是bind时的问题。
十二、tcp 的流
12.1 tcp 是流式协议
在前面的章节中,我们讲的都是单个客户端 - 服务器的例子,可能会给你造成一种错觉,好像 TCP 是一种应答形式的数据传输过程,比如发送端一次发送 network 和 program 这样的报文,在前面的例子中,我们看到的结果基本是这样的:
发送端:network ----> 接收端回应:Hi, network
发送端:program -----> 接收端回应:Hi, program
这其实是一个假象,之所以会这样,是因为网络条件比较好,而且发送的数据也比较少。
为了让大家理解 TCP 数据是流式的这个特性,我们分别从发送端和接收端来阐述。
我们知道,在发送端,当我们调用 send 函数完成数据“发送”以后,数据并没有被真正从网络上发送出去,只是从应用程序拷贝到了操作系统内核协议栈中,至于什么时候真正被发送,取决于发送窗口、拥塞窗口以及当前发送缓冲区的大小等条件。也就是说,我们不能假设每次 send 调用发送的数据,都会作为一个整体完整地被发送出去。
如果我们考虑实际网络传输过程中的各种影响,假设发送端陆续调用 send 函数先后发送 network 和 program 报文,那么实际的发送很有可能是这个样子的。
第一种情况,一次性将 network 和 program 在一个 TCP 分组中发送出去,像这样:
...xxxnetworkprogramxxx...
第二种情况,program 的部分随 network 在一个 TCP 分组中发送出去,像这样:
TCP 分组 1:
...xxxxxnetworkpro
TCP 分组 2:
gramxxxxxxxxxx...
第三种情况,network 的一部分随 TCP 分组被发送出去,另一部分和 program 一起随另一个 TCP 分组发送出去,像这样。
TCP 分组 1:
...xxxxxxxxxxxnet
TCP 分组 2:
workprogramxxx...
实际上类似的组合可以枚举出无数种。不管是哪一种,核心的问题就是,我们不知道 network 和 program 这两个报文是如何进行 TCP 分组传输的。换言之,我们在发送数据的时候,不应该假设“数据流和 TCP 分组是一种映射关系”。就好像在前面,我们似乎觉得 network 这个报文一定对应一个 TCP 分组,这是完全不正确的。
如果我们再来看客户端,数据流的特征更明显。我们知道,接收端缓冲区保留了没有被取走的数据,随着应用程序不断从接收端缓冲区读出数据,接收端缓冲区就可以容纳更多新的数据。如果我们使用 recv 从接收端缓冲区读取数据,发送端缓冲区的数据是以字节流的方式存在的,无论发送端如何构造 TCP 分组,接收端最终受到的字节流总是像下面这样:
xxxxxxxxxxxxxxxxxnetworkprogramxxxxxxxxxxxx
关于接收端字节流,有两点需要注意:
- 第一,这里 netwrok 和 program 的顺序肯定是会保持的,也就是说,先调用 send 函数发送的字节,总在后调用 send 函数发送字节的前面,这个是由 TCP 严格保证的;
- 第二,如果发送过程中有 TCP 分组丢失,但是其后续分组陆续到达,那么 TCP 协议栈会缓存后续分组,直到前面丢失的分组到达,最终,形成可以被应用程序读取的数据流。
12.2 网络字节排序
我们知道计算机最终保存和传输,用的都是 0101 这样的二进制数据,字节流在网络上的传输,也是通过二进制来完成的。
从二进制到字节是通过编码完成的,比如著名的 ASCII 编码,通过一个字节 8 个比特对常用的西方字母进行了编码。
这里有一个有趣的问题,如果需要传输数字,比如 0x0201,对应的二进制为 00000010000000001,那么两个字节的数据到底是先传 0x01,还是相反?

在计算机发展的历史上,对于如何存储这个数据没有形成标准。比如这里讲到的问题,不同的系统就会有两种存法,一种是将 0x02 高字节存放在起始地址,这个叫做大端字节序(Big-Endian)。另一种相反,将 0x01 低字节存放在起始地址,这个叫做小端字节序(Little-Endian)。
但是在网络传输中,必须保证双方都用同一种标准来表达,这就好比我们打电话时说的是同一种语言,否则双方不能顺畅地沟通。这个标准就涉及到了网络字节序的选择问题,对于网络字节序,必须二选一。我们可以看到网络协议使用的是大端字节序,我个人觉得大端字节序比较符合人类的思维习惯,你可以想象手写一个多位数字,从开始往小位写,自然会先写大位,比如写 12, 1234,这个样子。
为了保证网络字节序一致,POSIX 标准提供了如下的转换函数:
uint16_t htons (uint16_t hostshort)
uint16_t ntohs (uint16_t netshort)
uint32_t htonl (uint32_t hostlong)
uint32_t ntohl (uint32_t netlong)
这里函数中的 n 代表的就是 network,h 代表的是 host,s 表示的是 short,l 表示的是 long,分别表示 16 位和 32 位的整数。
这些函数可以帮助我们在主机(host)和网络(network)的格式间灵活转换。当使用这些函数时,我们并不需要关心主机到底是什么样的字节顺序,只要使用函数给定值进行网络字节序和主机字节序的转换就可以了。
你可以想象,如果碰巧我们的系统本身是大端字节序,和网络字节序一样,那么使用上述所有的函数进行转换的时候,结果都仅仅是一个空实现,直接返回。
比如这样:
# if __BYTE_ORDER == __BIG_ENDIAN
/* The host byte order is the same as network byte order,
so these functions are all just identity. */
# define ntohl(x) (x)
# define ntohs(x) (x)
# define htonl(x) (x)
# define htons(x) (x)
12.3 报文读取和解析
应该看到,报文是以字节流的形式呈现给应用程序的,那么随之而来的一个问题就是,应用程序如何解读字节流呢?
这就要说到报文格式和解析了。报文格式实际上定义了字节的组织形式,发送端和接收端都按照统一的报文格式进行数据传输和解析,这样就可以保证彼此能够完成交流。
只有知道了报文格式,接收端才能针对性地进行报文读取和解析工作。
报文格式最重要的是如何确定报文的边界。常见的报文格式有两种方法,一种是发送端把要发送的报文长度预先通过报文告知给接收端;另一种是通过一些特殊的字符来进行边界的划分。
12.3.1 显式编码报文长度
这个报文的格式很简单,首先 4 个字节大小的消息长度,其目的是将真正发送的字节流的大小显式通过报文告知接收端,接下来是 4 个字节大小的消息类型,而真正需要发送的数据则紧随其后。

发送端(client)程序如下:
int main(int argc, char **argv) {
if (argc != 2) {
error(1, 0, "usage: tcpclient <IPaddress>");
}
int socket_fd;
socket_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERV_PORT);
inet_pton(AF_INET, argv[1], &server_addr.sin_addr);
socklen_t server_len = sizeof(server_addr);
int connect_rt = connect(socket_fd, (struct sockaddr *) &server_addr, server_len);
if (connect_rt < 0) {
error(1, errno, "connect failed ");
}
// 图示的报文格式转化为结构体
struct {
u_int32_t message_length;
u_int32_t message_type;
char buf[128];
} message;
int n;
while (fgets(message.buf, sizeof(message.buf), stdin) != NULL) {
n = strlen(message.buf);
message.message_length = htonl(n);
message.message_type = 1;
// 实际发送的字节流大小为消息长度 4 字节,加上消息类型 4 字节,以及标准输入的字符串大小
if (send(socket_fd, (char *) &message, sizeof(message.message_length) + sizeof(message.message_type) + n, 0) < 0)
error(1, errno, "send failure");
}
exit(0);
}
解析端(server)程序如下:
static int count;
static void sig_int(int signo) {
printf("\nreceived %d datagrams\n", count);
exit(0);
}
int main(int argc, char **argv) {
int listenfd;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(SERV_PORT);
int on = 1;
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
int rt1 = bind(listenfd, (struct sockaddr *) &server_addr, sizeof(server_addr));
if (rt1 < 0) {
error(1, errno, "bind failed ");
}
int rt2 = listen(listenfd, LISTENQ);
if (rt2 < 0) {
error(1, errno, "listen failed ");
}
signal(SIGPIPE, SIG_IGN);
int connfd;
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
if ((connfd = accept(listenfd, (struct sockaddr *) &client_addr, &client_len)) < 0) {
error(1, errno, "bind failed ");
}
char buf[128];
count = 0;
while (1) {
int n = read_message(connfd, buf, sizeof(buf));
if (n < 0) {
error(1, errno, "error read message");
} else if (n == 0) {
error(1, 0, "client closed \n");
}
buf[n] = 0;
printf("received %d bytes: %s\n", n, buf);
count++;
}
exit(0);
}
解析报文:read_message() 和 readn() 函数:
// 第 6 行通过调用 readn 函数获取 4 个字节的消息长度数据,紧接着,第 11 行通过调用 readn 函数获取 4 个字节的消息类型数据。第 15 行判断消息的长度是不是太大,如果大到本地缓冲区不能容纳,则直接返回错误;第 19 行调用 readn 一次性读取已知长度的消息体。
size_t read_message(int fd, char *buffer, size_t length) {
u_int32_t msg_length;
u_int32_t msg_type;
int rc;
rc = readn(fd, (char *) &msg_length, sizeof(u_int32_t));
if (rc != sizeof(u_int32_t))
return rc < 0 ? -1 : 0;
msg_length = ntohl(msg_length);
rc = readn(fd, (char *) &msg_type, sizeof(msg_type));
if (rc != sizeof(u_int32_t))
return rc < 0 ? -1 : 0;
if (msg_length > length) {
return -1;
}
rc = readn(fd, buffer, msg_length);
if (rc != msg_length)
return rc < 0 ? -1 : 0;
return rc;
}
// 读取报文预设大小的字节,readn 调用会一直循环,尝试读取预设大小的字节,如果接收缓冲区数据空,readn 函数会阻塞在那里,直到有数据到达。
// readn 函数中使用 count 来表示还需要读取的字符数,如果 count 一直大于 0,说明还没有满足预设的字符大小,循环就会继续。第 9 行通过 read 函数来服务最多 count 个字符。11-17 行针对返回值进行出错判断,其中返回值为 0 的情形是 EOF,表示对方连接终止。19-20 行要读取的字符数减去这次读到的字符数,同时移动缓冲区指针,这样做的目的是为了确认字符数是否已经读取完毕。
size_t readn(int fd, void *buffer, size_t length) {
size_t count;
ssize_t nread;
char *ptr;
ptr = buffer;
count = length;
while (count > 0) {
nread = read(fd, ptr, count);
if (nread < 0) {
if (errno == EINTR)
continue;
else
return (-1);
} else if (nread == 0)
break; /* EOF */
count -= nread;
ptr += nread;
}
return (length - count); /* return >= 0 */
}
实验:
我们依次启动作为报文解析的服务器一端,以及作为报文发送的客户端。我们看到,每次客户端发送的报文都可以被服务器端解析出来,在标准输出上的结果验证了这一点。
root@server:/home/yolanda/build/bin# ./streamserver
received 2 bytes: a
received 2 bytes: b
received 2 bytes: c
root@client:/home/yolanda/build/bin# ./streamclient 127.0.0.1
a
b
c
12.3.2 特殊字符作为边界
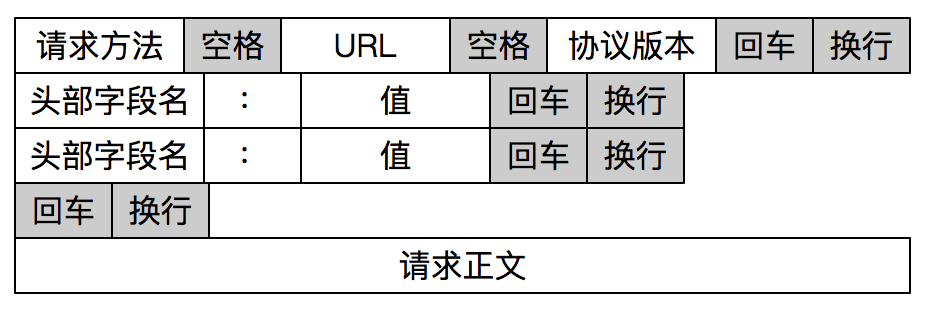
HTTP 是一个非常好的例子。HTTP 通过设置回车符、换行符做为 HTTP 报文协议的边界。
因为 windos 和mac linux 的换行不一样。\r 或\r\n,所以 HTTP 报文要同时处理 \r 或\r\n。
下面的 read_line 函数就是在尝试读取一行数据,也就是读到回车符\r,或者读到回车换行符\r\n为止。这个函数每次尝试读取一个字节,第 9 行如果读到了回车符\r,接下来在 11 行的“观察”下看有没有换行符,如果有就在第 12 行读取这个换行符;如果没有读到回车符,就在第 16-17 行将字符放到缓冲区,并移动指针。
int read_line(int fd, char *buf, int size) {
int i = 0;
char c = '\0';
int n;
while ((i < size - 1) && (c != '\n')) {
n = recv(fd, &c, 1, 0);
if (n > 0) {
if (c == '\r') {
n = recv(fd, &c, 1, MSG_PEEK);
if ((n > 0) && (c == '\n'))
recv(fd, &c, 1, 0);
else
c = '\n';
}
buf[i] = c;
i++;
} else
c = '\n';
}
buf[i] = '\0';
return (i);
}
十三、tcp 并不完全可靠
你可能会认为,TCP 是一种可靠的协议,这种可靠体现在端到端的通信上。这似乎给我们带来了一种错觉,从发送端来看,应用程序通过调用 send 函数发送的数据流总能可靠地到达接收端;而从接收端来看,总是可以把对端发送的数据流完整无损地传递给应用程序来处理。
事实上,如果我们对 TCP 传输环节进行详细的分析,你就会沮丧地发现,上述论断是不正确的。
前面我们已经了解,发送端通过调用 send 函数之后,数据流并没有马上通过网络传输出去,而是存储在套接字的发送缓冲区中,由网络协议栈决定何时发送、如何发送。当对应的数据发送给接收端,接收端回应 ACK,存储在发送缓冲区的这部分数据就可以删除了,但是,发送端并无法获取对应数据流的 ACK 情况,也就是说,发送端没有办法判断对端的接收方是否已经接收发送的数据流,如果需要知道这部分信息,就必须在应用层自己添加处理逻辑,例如显式的报文确认机制。
从接收端来说,也没有办法保证 ACK 过的数据部分可以被应用程序处理,因为数据需要接收端程序从接收缓冲区中拷贝,可能出现的状况是,已经 ACK 的数据保存在接收端缓冲区中,接收端处理程序突然崩溃了,这部分数据就没有办法被应用程序继续处理。
你有没有发现,TCP 协议实现并没有提供给上层应用程序过多的异常处理细节,或者说,TCP 协议反映链路异常的能力偏弱,这其实是有原因的。要知道,TCP 诞生之初,就是为了美国国防部服务的,考虑到军事作战的实际需要,TCP 不希望暴露更多的异常细节,而是能够以无人值守、自我恢复的方式运作。
TCP 连接建立之后,能感知 TCP 链路的方式是有限的,一种是以 read 为核心的读操作,另一种是以 write 为核心的写操作。接下来,我们就看下如何通过读写操作来感知异常情况,以及对应的处理方式。
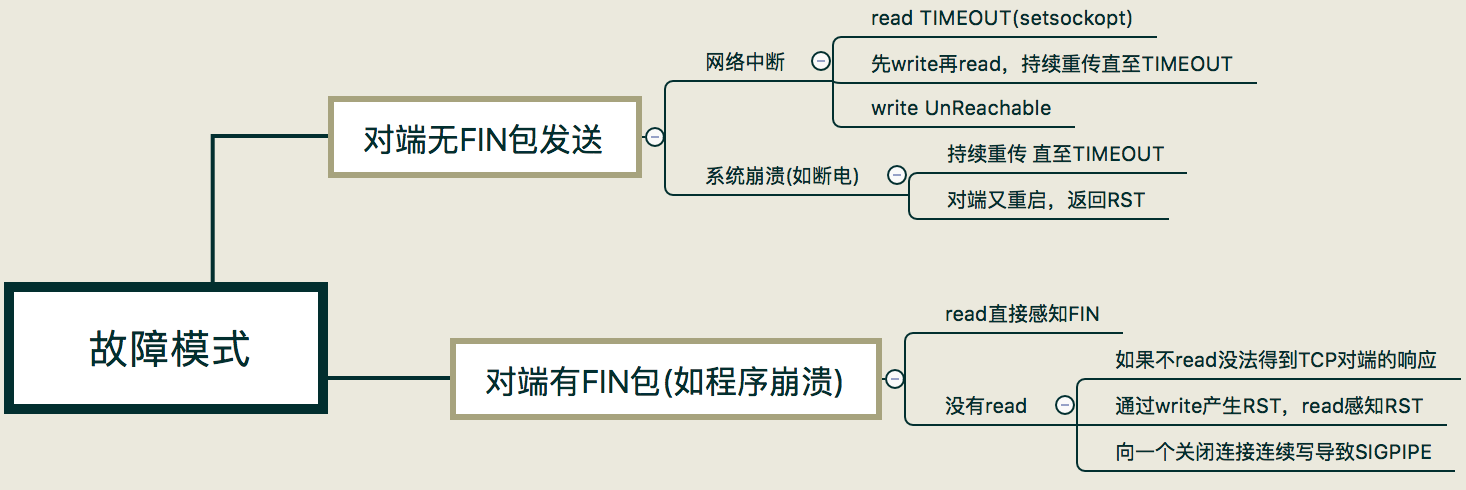
故障模式总结:在实际情景中,我们会碰到各种异常的情况。在这里我把这几种异常情况归结为两大类:
- 第一类,是对端无 FIN 包发送出来的情况,需要通过巡检或超时来发现。
- 第二类,是对端有 FIN 包发送出来,需要通过增强 read 或 write 操作的异常处理来发现。
- 而这两大类情况又可以根据应用程序的场景细分,接下来我们详细讨论。
13.1 网络中断造成的对端无 FIN 包
很多原因都会造成网络中断,在这种情况下,TCP 程序并不能及时感知到异常信息。除非网络中的其他设备,如路由器发出一条 ICMP 报文,说明目的网络或主机不可达,这个时候通过 read 或 write 调用就会返回 Unreachable 的错误。
可惜大多数时候并不是如此,在没有 ICMP 报文的情况下,TCP 程序并不能理解感应到连接异常。如果程序是阻塞在 read 调用上,那么很不幸,程序无法从异常中恢复。这显然是非常不合理的,不过,我们可以通过给 read 操作设置超时来解决,在接下来的第 18 讲中,我会讲到具体的方法。
如果程序先调用了 write 操作发送了一段数据流,接下来阻塞在 read 调用上,结果会非常不同。Linux 系统的 TCP 协议栈会不断尝试将发送缓冲区的数据发送出去,大概在重传 12 次、合计时间约为 9 分钟之后,协议栈会标识该连接异常,这时,阻塞的 read 调用会返回一条 TIMEOUT 的错误信息。如果此时程序还执着地往这条连接写数据,写操作会立即失败,返回一个 SIGPIPE 信号给应用程序。
13.2 系统崩溃造成的对端无 FIN 包
当系统突然崩溃,如断电时,网络连接上来不及发出任何东西。这里和通过系统调用杀死应用程序非常不同的是,没有任何 FIN 包被发送出来。
这种情况和网络中断造成的结果非常类似,在没有 ICMP 报文的情况下,TCP 程序只能通过 read 和 write 调用得到网络连接异常的信息,超时错误是一个常见的结果。
不过还有一种情况需要考虑,那就是系统在崩溃之后又重启,当重传的 TCP 分组到达重启后的系统,由于系统中没有该 TCP 分组对应的连接数据,系统会返回一个 RST 重置分节,TCP 程序通过 read 或 write 调用可以分别对 RST 进行错误处理。
- 如果是阻塞的 read 调用,会立即返回一个错误,错误信息为连接重置(Connection Resest)。
- 如果是一次 write 操作,也会立即失败,应用程序会被返回一个 SIGPIPE 信号。
13.3 对端有 FIN 包发出
对端如果有 FIN 包发出,可能的场景是对端调用了 close 或 shutdown 显式地关闭了连接,也可能是对端应用程序崩溃,操作系统内核代为清理所发出的。从应用程序角度上看,无法区分是哪种情形。
阻塞的 read 操作在完成正常接收的数据读取之后,FIN 包会通过返回一个 EOF 来完成通知,此时,read 调用返回值为 0。这里强调一点,收到 FIN 包之后 read 操作不会立即返回。你可以这样理解,收到 FIN 包相当于往接收缓冲区里放置了一个 EOF 符号,之前已经在接收缓冲区的有效数据不会受到影响。
13.4 实验
为了展示这些特性,我分别编写了服务器端和客户端程序。
// 服务端程序: 是一个简单的应答程序,在收到数据流之后回显给客户端,在此之前,休眠 5 秒,以便完成后面的实验验证。
int main(int argc, char **argv) {
int connfd;
char buf[1024];
connfd = tcp_server(SERV_PORT);
for (;;) {
int n = read(connfd, buf, 1024);
if (n < 0) {
error(1, errno, "error read");
} else if (n == 0) {
error(1, 0, "client closed \n");
}
sleep(5);
int write_nc = send(connfd, buf, n, 0);
printf("send bytes: %zu \n", write_nc);
if (write_nc < 0) {
error(1, errno, "error write");
}
}
exit(0);
}
// 客户端程序: 从标准输入读入,将读入的字符串传输给服务器端
int main(int argc, char **argv) {
if (argc != 2) {
error(1, 0, "usage: reliable_client01 <IPaddress>");
}
int socket_fd = tcp_client(argv[1], SERV_PORT);
char buf[128];
int len;
int rc;
while (fgets(buf, sizeof(buf), stdin) != NULL) {
len = strlen(buf);
rc = send(socket_fd, buf, len, 0);
if (rc < 0)
error(1, errno, "write failed");
rc = read(socket_fd, buf, sizeof(buf));
if (rc < 0)
error(1, errno, "read failed");
else if (rc == 0)
error(1, 0, "peer connection closed\n");
else
fputs(buf, stdout);
}
exit(0);
}
13.4.1 read 直接感知 FIN 包
我们依次启动服务器端和客户端程序,在客户端输入 good 字符之后,迅速结束掉服务器端程序,这里需要赶在服务器端从睡眠中苏醒之前杀死服务器程序。
屏幕上打印出:peer connection closed。客户端程序正常退出。
$./reliable_client01 127.0.0.1
$ good
$ peer connection closed
这说明客户端程序通过 read 调用,感知到了服务端发送的 FIN 包,于是正常退出了客户端程序。
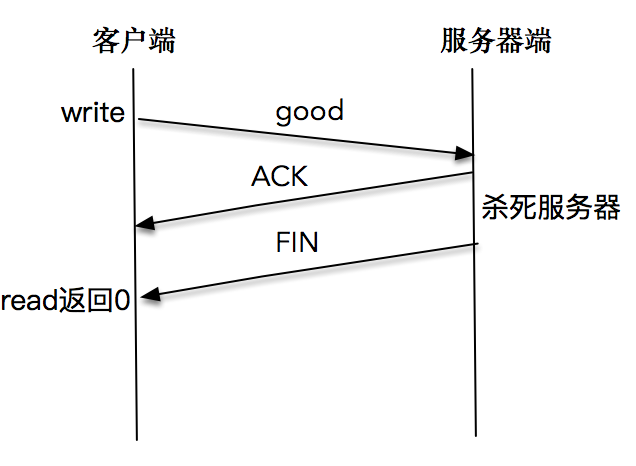
注意如果我们的速度不够快,导致服务器端从睡眠中苏醒,并成功将报文发送出来后,客户端会正常显示,此时我们停留,等待标准输入。如果不继续通过 read 或 write 操作对套接字进行读写,是无法感知服务器端已经关闭套接字这个事实的。
13.4.2 通过 write 产生 RST,read 调用感知 RST
这一次,我们仍然依次启动服务器端和客户端程序,在客户端输入 bad 字符之后,等待一段时间,直到客户端正确显示了服务端的回应“bad”字符之后,再杀死服务器程序。客户端再次输入 bad2,这时屏幕上打印出”peer connection closed“。
# linux
$./reliable_client01 127.0.0.1
$bad
$bad
$bad2
$peer connection closed
下文是时序图:
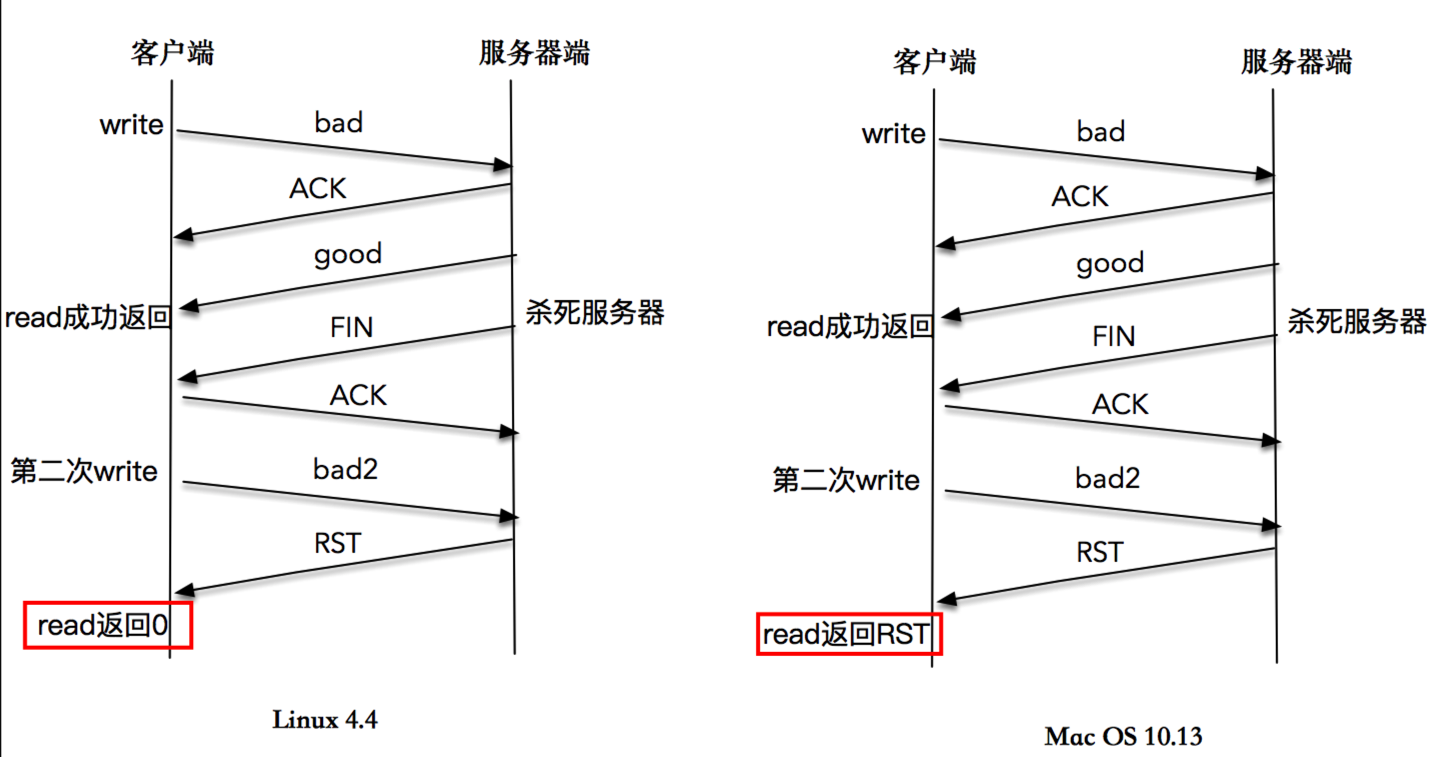
在很多书籍和文章中,对这个程序的解读是,收到 FIN 包的客户端继续合法地向服务器端发送数据,服务器端在无法定位该 TCP 连接信息的情况下,发送了 RST 信息,当程序调用 read 操作时,内核会将 RST 错误信息通知给应用程序。这是一个典型的 write 操作造成异常,再通过 read 操作来感知异常的样例。
- 不过,我在 Linux 4.4 内核上实验这个程序,多次的结果都是,内核正常将 EOF 信息通知给应用程序,而不是 RST 错误信息。
- 我又在 Max OS 10.13.6 上尝试这个程序,read 操作可以返回 RST 异常信息。输出和时序图也已经给出。
# macos
$./reliable_client01 127.0.0.1
$bad
$bad
$bad2
$read failed: Connection reset by peer (54)
13.4.3 向一个已关闭连接连续写,最终导致 SIGPIPE
为了模拟这个过程,我对服务器端程序和客户端程序都做了如下修改。
// 服务器端每次读取 1K 数据后休眠 1 秒,以模拟处理数据的过程。
int main(int argc, char **argv) {
int connfd;
char buf[1024];
int time = 0;
connfd = tcp_server(SERV_PORT);
while (1) {
int n = read(connfd, buf, 1024);
if (n < 0) {
error(1, errno, "error read");
} else if (n == 0) {
error(1, 0, "client closed \n");
}
time++;
fprintf(stdout, "1K read for %d \n", time);
usleep(1000);
}
exit(0);
}
// 客户端程序在第 8 行注册了 SIGPIPE 的信号处理程序,在第 14-22 行客户端程序一直循环发送数据流。
int main(int argc, char **argv) {
if (argc != 2) {
error(1, 0, "usage: reliable_client02 <IPaddress>");
}
int socket_fd = tcp_client(argv[1], SERV_PORT);
signal(SIGPIPE, SIG_IGN);
char *msg = "network programming";
ssize_t n_written;
int count = 10000000;
while (count > 0) {
n_written = send(socket_fd, msg, strlen(msg), 0);
fprintf(stdout, "send into buffer %ld \n", n_written);
if (n_written <= 0) {
error(1, errno, "send error");
return -1;
}
count--;
}
return 0;
}
如果在服务端读取数据并处理过程中,突然杀死服务器进程,我们会看到客户端很快也会退出,并在屏幕上打印出“Connection reset by peer”的提示。
$./reliable_client02 127.0.0.1
$send into buffer 5917291
$send into buffer -1
$send: Connection reset by peer
这是因为服务端程序被杀死之后,操作系统内核会做一些清理的事情,为这个套接字发送一个 FIN 包,但是,客户端在收到 FIN 包之后,没有 read 操作,还是会继续往这个套接字写入数据。这是因为根据 TCP 协议,连接是双向的,收到对方的 FIN 包只意味着对方不会再发送任何消息。 在一个双方正常关闭的流程中,收到 FIN 包的一端将剩余数据发送给对面(通过一次或多次 write),然后关闭套接字。
当数据到达服务器端时,操作系统内核发现这是一个指向关闭的套接字,会再次向客户端发送一个 RST 包,对于发送端而言如果此时再执行 write 操作,立即会返回一个 RST 错误信息。
你可以看到针对这个全过程的一张描述图,你可以参考这张图好好理解一下这个过程。
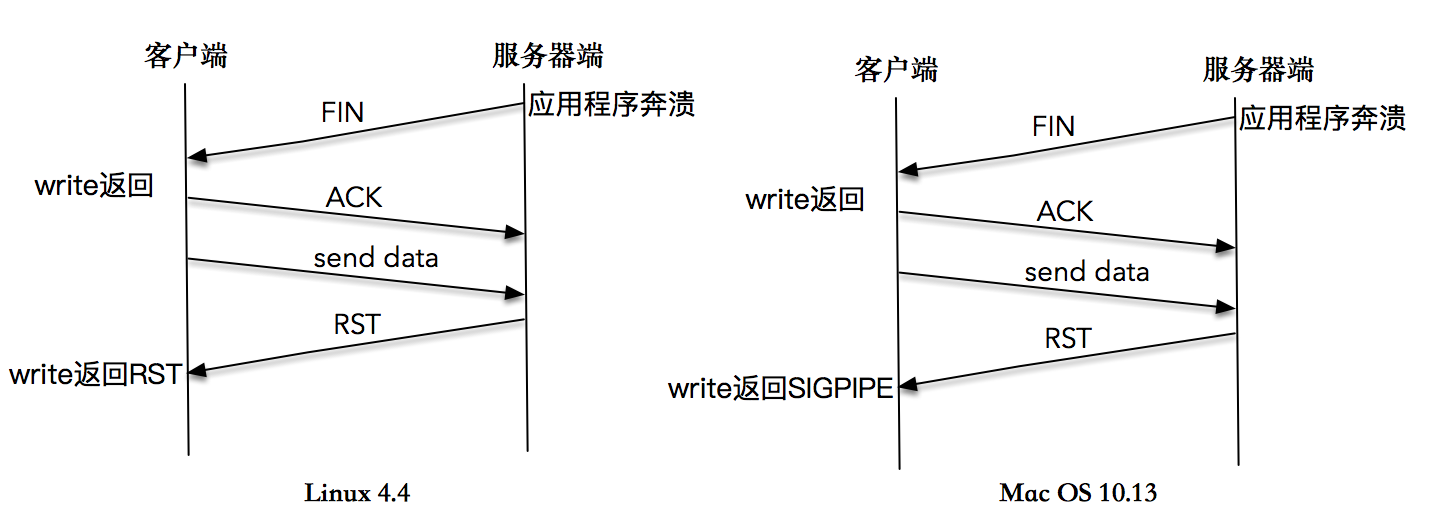
在很多书籍和文章中,对这个实验的期望结果不是这样的。大部分的教程是这样说的:在第二次 write 操作时,由于服务器端无法查询到对应的 TCP 连接信息,于是发送了一个 RST 包给客户端,客户端第二次操作时,应用程序会收到一个 SIGPIPE 信号。如果不捕捉这个信号,应用程序会在毫无征兆的情况下直接退出。
我在 Max OS 10.13.6 上尝试这个程序,得到的结果确实如此。你可以看到屏幕显示和时序图。
#send into buffer 19
#send into buffer -1
#send error: Broken pipe (32)
这说明,Linux4.4 的实现和类 BSD 的实现已经非常不一样了。限于时间的关系,我没有仔细对比其他版本的 Linux,还不清楚是新的内核特性,但有一点是可以肯定的,我们需要记得为 SIGPIPE 注册处理函数,通过 write 操作感知 RST 的错误信息,这样可以保证我们的应用程序在 Linux 4.4 和 Mac OS 上都能正常处理异常。