你好,我是卢誉声。
上一讲,我们了解了后续C++标准演进中,极有可能到来的特性或库变更——静态反射、异步任务框架、网络库和Freestanding库。
从未来标准的演进路线中,我们其实可以一窥究竟,不难发现,C++有着极为清晰的演进路线。
与此同时,C++标准还在努力弥补不足之处,比如缺乏标准化的高性能计算能力、异步编程库、针对大数据处理的Ranges扩展等等。接下来,就让我们继续漫游之旅,畅想未来C++标准演进可能迎来的另外六个变化吧。
高性能计算支持
对于C++26来说,另一个重要目标是提供对高性能计算的支持。
不得不说,C++至今依然能焕发生机,得益于人工智能等领域对高性能计算的需求,C++几乎是唯一一个同时合理兼顾性能和抽象两个层面的编程语言。
但是,C++缺乏对高性能计算的标准支持,无论是基础的多维向量、对CPU SIMD的指令封装,还是更高层的线性代数算法都是一片空白。
因此,从C++20标准开始,不断有相关特性添加到标准库中,C++20中的一维数组视图span和C++23中的多维数组视图mdspan,都是线性代数的基础类型向量的前置特性。同时,C++23的多元索引操作符,也让多维向量访问变得更加方便了。
在C++26中,预计添加许多关键的线性代数支持。
首先,可能会加入的就是多维数组mdarray。多维数组mdarray的设计和C++23中的多维数组视图mdspan是一致的,都可以用于表示多维数组。我在这里着重说明它们之间的差异。
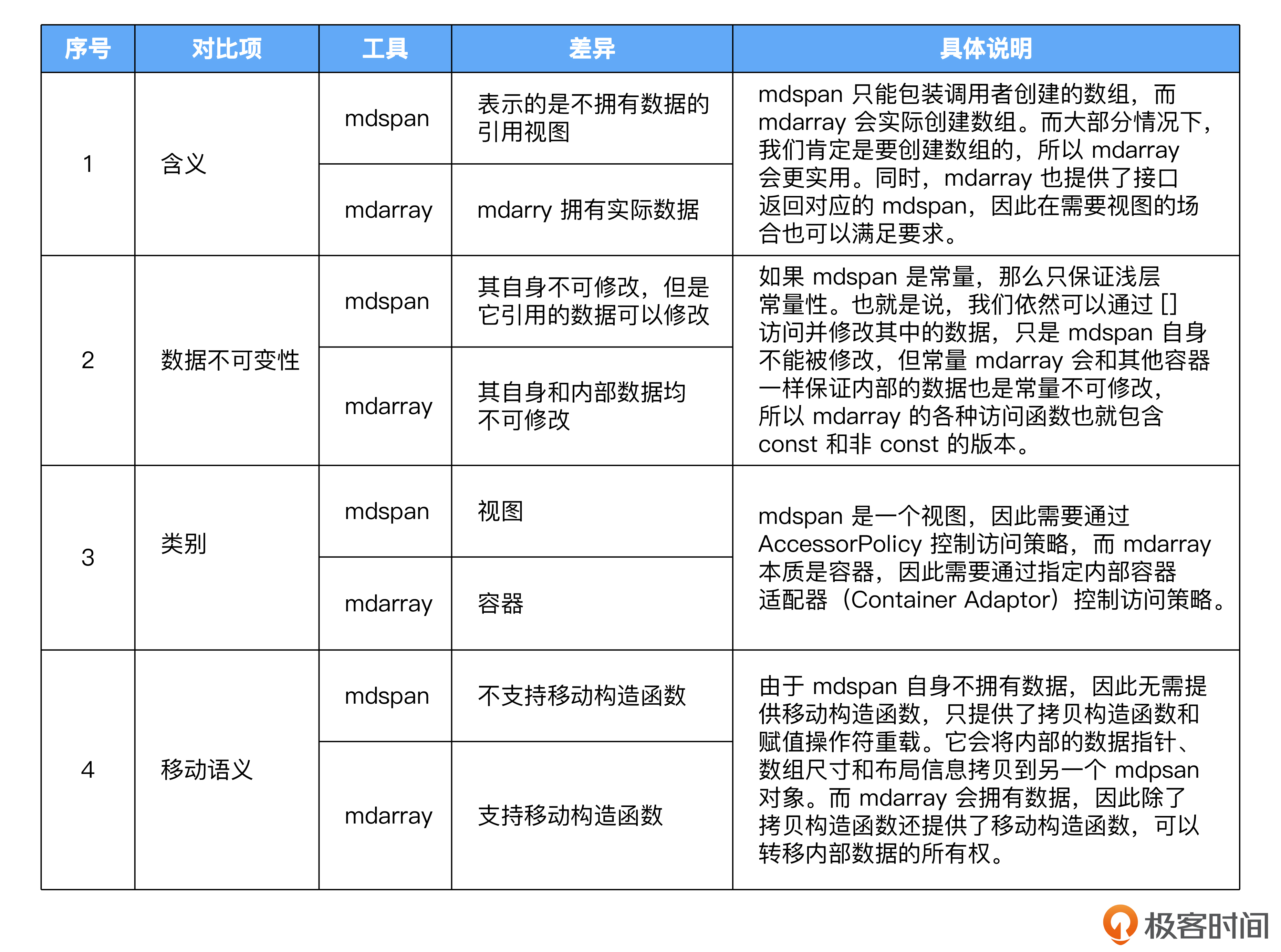
另一个C++26可能支持的特性是提供SIMD指令的封装。
在高性能计算中,SIMD(单指令多数据流)是常见的计算优化处理模式,各个CPU指令集都有相应指令提供支持,其目标是通过一条CPU指令计算多个多维向量。
目前C++编译器可能会在部分的计算优化中,自动使用这些指令。但是,在高性能计算中,我们往往需要手动指定使用这些指令。由于标准库没有提供这些接口,导致我们只能使用汇编指令或者类似Intel的Intrinsics接口来实现,经常需要做大量的平台适配工作。
为了解决这个问题,C++计划引入针对SIMD类型与指令的封装——这也是后续线性代数接口实现的计算基础。
最后,C++26可能会基于mdarray、mdspan提供线性代数函数库。
由于BLAS(Basic Linear Algebra Subprograms)库基本已经成为C/C++中线性代数的事实标准,CBLAS、ATLAS和OpenBLAS等基于BLAS接口的库,也成了大部分科学计算库的基础设施(比如Python著名的NumPy就是基于BLAS开发的)。
因此,C++的线性代数接口也就以BLAS接口为基础设计。C++的BLAS接口会使用mdspan描述向量数据类型,可能使用SIMD实现部分计算加速。至于与BLAS同时设计的LAPACK,虽然补充了更多线性代数功能,但由于各种原因可能要留待以后的C++标准决定何时实现。
Coroutines扩展
C++20中的Coroutines只提供了一套协议,具体实现需要开发者自己来实现。而C++23里的generator提供了在生成器这种场景下的coroutine标准实现。
而在C++26中,我们终于可以看到面向普通协程任务的coroutine实现——std::lazy。
那么什么是std::lazy呢?我们可以结合这段代码来理解。
#include <experimental/lazy>
#include <string>
struct Person {
int id;
std::string name;
};
std::lazy<Person> loadPerson(int id);
std::lazy<> savePerson(Person p);
std::lazy<void> modifyPerson() {
Person person = co_await loadPerson(1);
person.name = "学生名称";
co_await savePerson(person);
}通过代码可以看到,自定义的coroutine换成lazy之后,我们不再需要自己实现协程的调度过程,直接通过co_await就能调用loadPerson和savePerson,这可太棒了!
std::lazy甚至可以允许我们指定具体的executor调度协程,比如后面的代码。
co_await f().via(e);这里的e就是一个executor,这样我们可以控制协程到底要通过哪个executor来唤醒执行,提供了更高的灵活性和更简单的接口。
说白了,std::lazy就是一个通用协程任务封装,起了这么一个名字,是因为标准委员会的SG1倾向于将task这个名字保留给以后的其他概念使用,最后LEGW(Library Evolution Work Group,即标准委员会负责库改进的工作组)就选用了lazy这个名字……
Ranges扩展
到C++23为止,Ranges已经相当完善了,唯一问题就是我们无法像Python、JavaScript和Rust一样,方便地将序列(包括vector、map和set)打印到控制台上。
在C++26中,可能会提出容器和ranges的格式化接口方案,也就是我们可以写出这种代码:
#include <ranges>
#include <string>
#include <vector>
#include <cstdint>
#include <fmt/ranges.h>
int main() {
std::vector<int32_t> v{
1, 2, 3
};
fmt::print("{}\n", v);
std::string s = "xyx";
auto parts = s | std::views::split('x');
fmt::print("{}\n", parts);
fmt::print("<<{}>>\n", fmt::join(parts, "--"));
return 0;
}可以看出,相比原来的形式,这样的代码无论是调试代码,还是将容器ranges输出到文件中,编码都会更加方便。
Hive:Bucket Array容器框架
如今,C++依然是高性能交易与游戏编程的核心支撑,在这些领域中,经常需要完成大量数据块的申请、释放与快速检索,我们经常采用一种名为 Bucket array的技术来解决此类问题。
这种数据结构的原理是,将一个元素数组划分成块的数组,每个块包含多个实际的元素,每个元素有一个布尔标记位,表示这个元素是否被删除了。当遍历元素时,会跳过这些被标记删除的元素,只有一个块中的所有元素被标记删除后,这个块才会被真正释放。这么做,可以避免遍历时遇到全空的块。插入元素时,所有块都满了才会申请新的块。
这种方式大幅度减少了小对象的内存申请(都以块为单位申请内容),避免过多零散的删除操作引起的移位拷贝,所以性能损耗大大降低。而且,还能确保很多相关元素连续存储在一个块中,保证很多场景下随机访问的性能。可以说,这是一种在特定场景下权衡了插入、删除和检索性能的数据结构。
由于在C++的主要支持场景中,会大量用到这种数据结构,因此C++标准提出了相关提案,可能会在C++26中正式纳入标准。
多线程无锁内存模型支持
基于多线程的高并发业务也是C++的重要应用场景,尤其在现在的高并发Web服务中有大量应用。
在这种场景中,性能的核心瓶颈可能并非长时间的计算,而是持续的高并发访问。这种情况下,多个线程可能需要频繁地同时访问相同数据,自然就需要解决高并发场景下的数据竞争问题。
如果我们采用常用的锁来解决问题,极端情况下会将本可并行的执行流变成串行执行流,严重拖慢并发性能。
为此,有针对不同场景的大量“无锁”内存模型,Hazard Pointer就是一种面向“单写者、多读者”场景的无锁内存模型与基础数据结构。
你不妨联想一下,在很多Web服务中我们可能都会采用类似“读写分离”的机制来处理数据的读写,Hazard Pointer的原理也是一样的。这种数据结构的特点是,永远只有一个线程具备其所有权,并可以写入数据,其他线程只能访问并读取其中的值,所以我们用这种特性做无锁化的优化非常方便。
为了支持Hazard Pointer,C++采用了RCU(read copy update)实现了一种面向多读少写特性的链式数据结构,也就是我们熟知的“无锁队列”。
RCU结合Hazard Pointer为我们提供了一种“单写者、多读者”的多读少写的高并发无锁内存模型,可以为我们解决特定的高并发业务提供基础设施支持。
定制点对象调整
最后我们聊聊定制点对象,这是为了解决ADL(Argument-Dependent Lookup,实参依赖查找)问题提出来的。
本质上,引入它是为了让用户能方便地使用命名空间中的符号。我们还是结合代码示例理解。
#include <ranges>
#include <string>
#include <vector>
#include <cstdint>
#include <iostream>
namespace cp {
struct Person {
friend void swap(Person& lhs, Person& rhs);
int32_t id;
std::string name;
};
void swap(Person& lhs, Person& rhs) {
std::cout << "Person swap" << std::endl;
Person temp = lhs;
lhs = rhs;
rhs = temp;
}
std::ostream& operator<<(std::ostream& os, const Person& person) {
os << person.id << " " << person.name << std::endl;
return os;
}
}
int main() {
cp::Person p1{
.id = 1,
.name = "姓名1"
};
cp::Person p2{
.id = 2,
.name = "姓名2"
};
std::cout << p1 << std::endl;
// 通过p2找到cp::operator<<
operator<<(std::cout, p2) << std::endl;
// 通过p1,p2找到cp::swap
swap(p1, p2);
cp::operator<<(std::cout, p1) << std::endl;
return 0;
}可以看到,在代码第8行定义了Person类,第14行定义了swap函数,第22行定义了<<的操作符重载。这些符号都被定义在命名空间cp中。
现在来看一下代码41和43行,我们都知道其实C++的操作符重载只是一个语法糖,std::cout << p1的本质相当于operator<<(std::cout, p1),所以43行的用法没有什么问题。
但是,代码46行就很奇怪了,我们分明没有using cp::swap,也没有using namespace cp,为什么这里C++能找到cp::swap这个函数呢?
命名空间是为了解决名称隔离的问题引入的,但也让我们引用符号变得比较麻烦。比如说,我们为了避免命名空间污染,基本上不会使用using namespace,而是在每次引用符号时,都加上完整的命名空间(比如使用cp::swap)。
不过有些问题,我们必须要交给编译器来解决。比如说,代码中的operator<<重载。既然std::cout << p1只是operator<<(std::cout, p1)的语法糖,而operator<<(std::ostream&, const Person&)是在cp这个命名空间中定义的函数,那么编译器要怎么找到cp:: operator<<这个函数呢?
为此,C++提出了ADL。简单来说,就是调用函数时,只要有一个参数的类型属于函数所在的命名空间,那么调用的时候就不用加命名空间前缀(当然实际情况肯定复杂得多......)。
这样一来,编译器就可以通过operator<<(std::cout, p1)将std::operator<<或者cp::operator<<作为候选符号,最后匹配满足调用条件的版本。
这个能力,最终在C++标准中从操作符重载被扩展到了普通函数,就变成了我们现在所知的ADL,这也解释了为什么代码46行能够编译成功。
不过,这种特性在后续过程中被“合法”运用到了C++的其他部分,来实现用户自定义的扩展(想想模板元编程是怎么出现的)。比如C++20 Ranges中的begin、end等函数,都需要类似的特性。但这种场景下使用ADL并不在语言设计的预期中,自然会存在各种各样的问题。
因此,C++在标准中不断对它修修补补。CPO(定制点对象)就是其中一种。你可以这样理解,C++给我们提供了一个以特定对象作为扩展点,让开发者可以针对自己的类型定制对应的行为,这就是为什么叫做定制点。
不过CPO依然存在很多问题,在准备推出的execution中,就有很多符号需要此类支持以供第三方定制扩展。因此,C++本来准备引入tag_invoke来缓解这个问题,但这只不过又是一个给ADL收烂摊子的方案。
所幸,由于execution特性延迟,标准委员会才有机会在tag_invoke这种治标不治本的方案进入标准之前,在C++26之后(大概率在C++26),彻底消除在扩展点中使用ADL带来的问题,最终完全统一扩展点的技术方案。
总结
人工智能技术发展和高性能计算领域,既需要接近硬件层,又需要提供上层接口。唯一一个兼顾性能和抽象两方面的编程语言,几乎只有C++。
不过,虽然C++具备如此素质,但标准库一致缺乏对这些领域所依赖的底层技术的支持。因此工程师们被迫引入大量第三方库,但集成过程里的问题(比如不同库之间的适配问题、体系结构、操作系统的兼容性问题)也是层出不穷,令人头大。
如今,从C++11再到C++20以及后续演进标准,我们能清楚看到C++的改变以及演进路线,C++标准将提供更多“标准化的解决方案”,这些发展有望大幅降低开发者编写代码的复杂度。
由此,我们有理由推测,之后C++在机器学习和高性能计算等重要应用领域中,会大放异彩,越战越勇。
我们在课程中曾自己实现了几乎所有的C++ Coroutines接口约定。但是可以看到,在后续的标准演进中,coroutine库即将到来,届时,我们就可以通过std::lazy来彻底简化异步编程的工作。这可太让人期待了。
最后,Ranges针对format的扩展也让代码调试与容器输出变得更加方便。
这些新特性的提出和对现有标准中的特性的补足,将会把C++推向一个全新的高度。C++26或其后续标准,将是一个极为令人激动的重大变更。让我们一起期待它们的到来,以及编译器对新标准的支持吧。
课后思考
最后给你留两道思考题。
1.在人工智能领域,C++无处不在。那么,你能说出哪些技术或工具在使用C++呢?
2.我在这一讲中提到了名为Bucket array的技术,用于解决内存碎片的问题。那么,你在日常工作中,是如何避免内存碎片导致的性能下降问题呢?
欢迎说出你的实践,与大家一起分享。我们一起讨论,下一讲见。
文章来源:极客时间《现代 C++20 实战高手课》