个人项目:论文查重
github地址
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834/homework/11146 |
| 这个作业的目标 | 学习使用PSP表格,学习commit规范 |
一、模块接口的设计与实现过程
1.1文件读写类

文件读写类为了增加开发效率,我引入了糊涂工具包,引用了里面的FileReader,然后对异常进行了封装
1.2分词与计算类

分词部分也是引入了糊涂工具包的TokenizerEngine,并通过hankcs当作引擎来进行分词处理。
1.3 自定义异常类
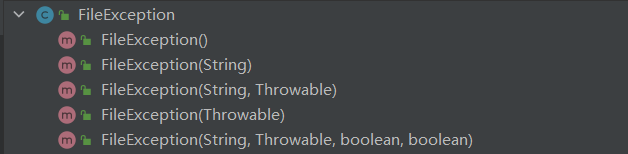
1.4 程序流程
- 流程图

-
实现逻辑
通过查找网上的资料,主要找到的是阮一峰的文章,介绍的是 TF-IDF与余弦相似性的应用
主要说的是离用余弦相似性来比较两个句子的相似性,这样的思路同然可以运用到一整篇文章。所以我们需要做的第一步是进行分词,并统计词频。但是这里用的是位置向量分析。主要思路是,每一个词在全文的分布大概是如何的,从宏观上来分析两篇文章的相似度。
这里我用到的是hanlp分词。然后遍历存放着词与词频信息的map,计算cos值。最后比对得出答案。
-
这里有一个点需要注意的是分词之后统计的时候还需要对字符char进行判断,值判断汉字。[\u4e00-\u9fa5]
最后的结果
orig_0.8_add.txt 0.8695990639733713
orig_0.8_del.txt 0.7498838191640381
orig_0.8_dis_1.txt 0.9206491294709916
orig_0.8_dis_10.txt 0.804067893296461
orig_0.8_dis_15.txt 0.6575365154781483
二、测试
- 测试分别从两个完全相同的文件和完全不同的文件,到5个测试用例去测试。
同时也测试了假如文件路径有问题和文件为空,也考虑到了各种异常的情况。
package com.free;
import com.free.util.FileUtil;
import com.free.util.TokenizerUtil;
import org.junit.Test;
import java.util.List;
import java.util.Map;
/**
* @ClassNamemain
* @Description
* @Author Free
* @Date2020/9/22 11:39
* @Version V1.0
**/
public class MainStart {
@Test
public void sameTest(){
String path = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig_0.8_add.txt";
String path2 = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig_0.8_add.txt";
Map<String, List<Integer>> stringListMap = TokenizerUtil.CountWord(path);
Map<String, List<Integer>> stringListMap2 = TokenizerUtil.CountWord(path2);
Double aDouble = TokenizerUtil.CountCos(stringListMap, stringListMap2);
FileUtil.writeFile("D:\\Free\\课程\\软件工程\\数据源\\test\\test\\res.txt",String.valueOf(aDouble));
System.out.println(aDouble);
}
@Test
public void addTest(){
String path = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig.txt";
String path2 = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig_0.8_add.txt";
Map<String, List<Integer>> stringListMap = TokenizerUtil.CountWord(path);
Map<String, List<Integer>> stringListMap2 = TokenizerUtil.CountWord(path2);
Double aDouble = TokenizerUtil.CountCos(stringListMap, stringListMap2);
FileUtil.writeFile("D:\\Free\\课程\\软件工程\\数据源\\test\\test\\res.txt",String.valueOf(aDouble));
System.out.println(aDouble);
}
@Test
public void delTest(){
String path = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig.txt";
String path2 = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig_0.8_del.txt";
Map<String, List<Integer>> stringListMap = TokenizerUtil.CountWord(path);
Map<String, List<Integer>> stringListMap2 = TokenizerUtil.CountWord(path2);
Double aDouble = TokenizerUtil.CountCos(stringListMap, stringListMap2);
FileUtil.writeFile("D:\\Free\\课程\\软件工程\\数据源\\test\\test\\res.txt",String.valueOf(aDouble));
System.out.println(aDouble);
}
@Test
public void disTest(){
String path = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig.txt";
String path2 = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig_0.8_dis_1.txt";
Map<String, List<Integer>> stringListMap = TokenizerUtil.CountWord(path);
Map<String, List<Integer>> stringListMap2 = TokenizerUtil.CountWord(path2);
Double aDouble = TokenizerUtil.CountCos(stringListMap, stringListMap2);
FileUtil.writeFile("D:\\Free\\课程\\软件工程\\数据源\\test\\test\\res.txt",String.valueOf(aDouble));
System.out.println(aDouble);
}
@Test
public void dis10Test(){
String path = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig.txt";
String path2 = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig_0.8_dis_10.txt";
Map<String, List<Integer>> stringListMap = TokenizerUtil.CountWord(path);
Map<String, List<Integer>> stringListMap2 = TokenizerUtil.CountWord(path2);
Double aDouble = TokenizerUtil.CountCos(stringListMap, stringListMap2);
FileUtil.writeFile("D:\\Free\\课程\\软件工程\\数据源\\test\\test\\res.txt",String.valueOf(aDouble));
System.out.println(aDouble);
}
@Test
public void dis15Test(){
String path = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig.txt";
String path2 = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig_0.8_dis_15.txt";
Map<String, List<Integer>> stringListMap = TokenizerUtil.CountWord(path);
Map<String, List<Integer>> stringListMap2 = TokenizerUtil.CountWord(path2);
Double aDouble = TokenizerUtil.CountCos(stringListMap, stringListMap2);
FileUtil.writeFile("D:\\Free\\课程\\软件工程\\数据源\\test\\test\\res.txt",String.valueOf(aDouble));
System.out.println(aDouble);
}
@Test
public void Test(){
String path = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig.txt";
String path2 = "D:\\Free\\课程\\软件工程\\数据源\\test\\orig_0.8_dis_15.txt";
Map<String, List<Integer>> stringListMap = TokenizerUtil.CountWord(path);
Map<String, List<Integer>> stringListMap2 = TokenizerUtil.CountWord(path2);
Double aDouble = TokenizerUtil.CountCos(stringListMap, stringListMap2);
FileUtil.writeFile("D:\\Free\\课程\\软件工程\\数据源\\test\\test\\res.txt",String.valueOf(aDouble));
System.out.println(aDouble);
}
@Test
public void NullpointTest(){
String path = "";
String path2 = "";
Map<String, List<Integer>> stringListMap = TokenizerUtil.CountWord(path);
Map<String, List<Integer>> stringListMap2 = TokenizerUtil.CountWord(path2);
Double aDouble = TokenizerUtil.CountCos(stringListMap, stringListMap2);
FileUtil.writeFile("D:\\Free\\课程\\软件工程\\数据源\\test\\test\\res.txt",String.valueOf(aDouble));
System.out.println(aDouble);
}
@Test
public void DIYpointTest(){
String path = "D:\\Free\\test\\1000.txt";
String path2 = "D:\\Free\\test\\4.txt";
Map<String, List<Integer>> stringListMap = TokenizerUtil.CountWord(path);
Map<String, List<Integer>> stringListMap2 = TokenizerUtil.CountWord(path2);
Double aDouble = TokenizerUtil.CountCos(stringListMap, stringListMap2);
FileUtil.writeFile("D:\\Free\\课程\\软件工程\\数据源\\test\\test\\res.txt",String.valueOf(aDouble));
System.out.println(aDouble);
}
}
JProfiler> Protocol version 63
JProfiler> Java 11 detected.
JProfiler> 64-bit library
JProfiler> Listening on port: 34227.
JProfiler> Enabling native methods instrumentation.
JProfiler> Can retransform classes.
JProfiler> Can retransform any class.
JProfiler> Native library initialized
JProfiler> VM initialized
JProfiler> Retransforming 122 base class files.
JProfiler> Base classes instrumented.
JProfiler> Waiting for a connection from the JProfiler GUI ...
JProfiler> Using sampling (5 ms)
JProfiler> Time measurement: elapsed time
JProfiler> CPU profiling enabled
0.804067893296461
0.6575365154781483
0.8695990639733713
文件为空
null
0.6575365154781483
0.7498838191640381
0.9206491294709916
文件路径为空
文件路径为空
null
1.0
Process finished with exit code 0
-
覆盖率
总方法覆盖率为77%,主要原因是自定义异常中只用到一个方法,但是line覆盖率达到了93%

细看覆盖率是

FileUtil中没有覆盖到的地方是还没能测试到输出结果文件异常的部分。但是这个异常我已经做了处理,初步想的是在linux中会有文件读写权限,这时可以覆盖到。

三、性能检测
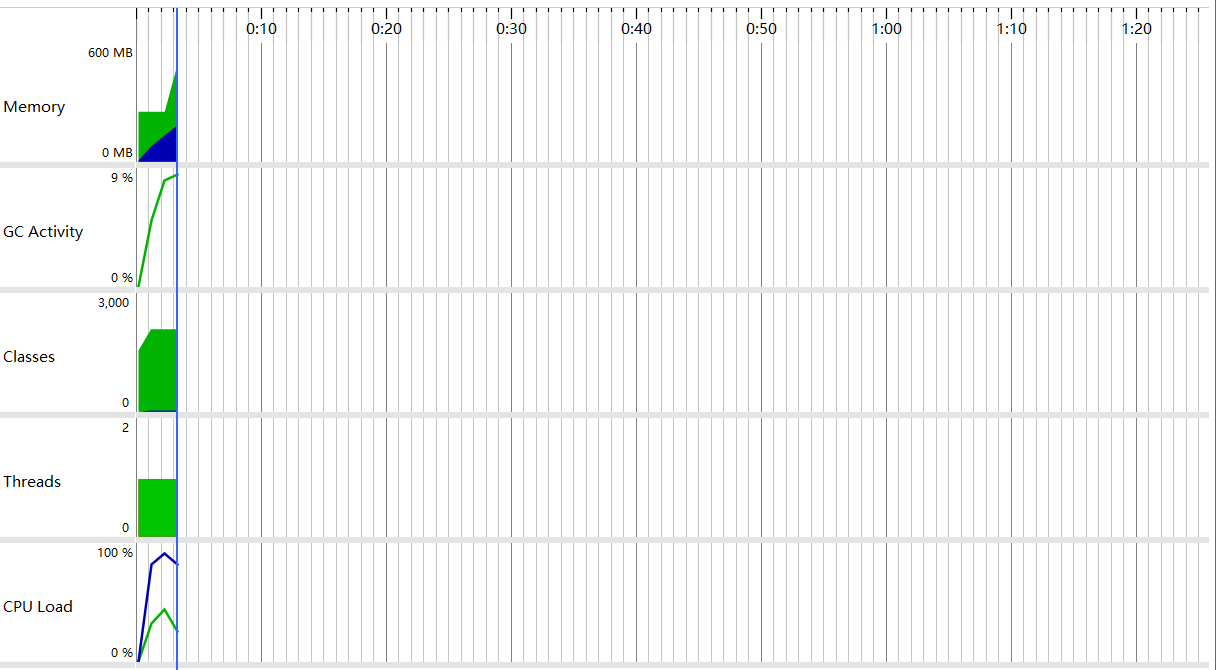
速度还是很快的,3秒左右完成了9个测试。
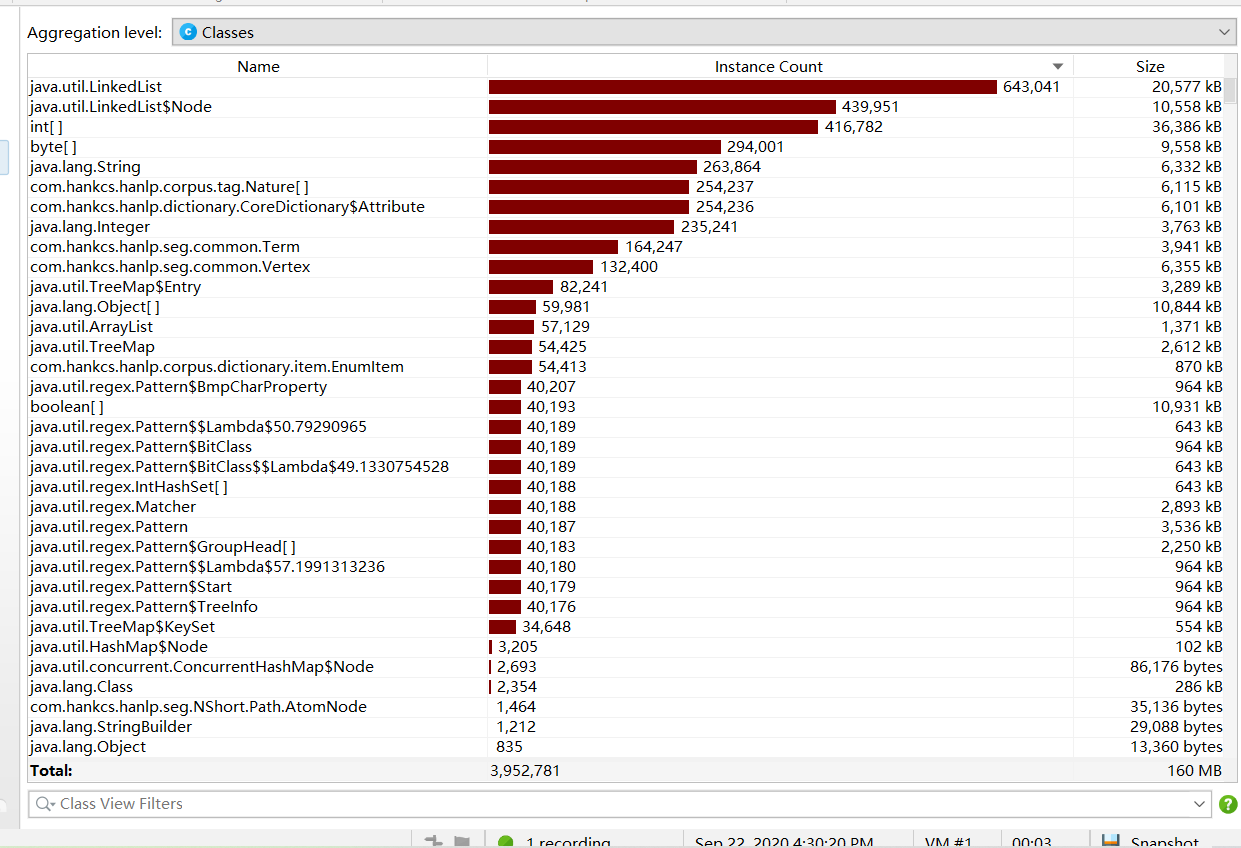
内存方面list用了最多 ,因为一个词就开了一个list来存储。
四、算法评价
这个算法实际有一些比较缺陷的地方,就是假如测试用例为
句子1:这是软件工程作业
句子2:这是软件工程作业,但是有点难。
在整体句子混杂的情况下算法效果比较好,但在上述情况,这两个句子最后得出的结果是1,效果明显不是很好。原因在于遍历只遍历到了第一个句子有的词。第二个句子有的词但第一个句子没有的词,并不会加入到计算中。
所以这是算法缺陷的点。这样是采用位置向量的缺陷。希望以后有机会再去修改,使得效果更加好。
五、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 90 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 28 |
| Development | 开发 | 480 | 640 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 120 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 | 60 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 180 | 300 |
| · Code Review | · 代码复审 | 60 | 80 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 60 | 60 |
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1290 | 1750 |