MySQL的存储引擎架构中使用可插拔式的方式,可以在运行中的MySQL服务器上加载和卸载存储引擎,满足不同的场景。所以MySQL多种储引擎里必不可少。发展到至今InnoDB引擎是默认的,最通用的存储引擎。
但随着MySQL使用普遍,慢慢的很多引擎淡忘在视野中。目前MySQL支持的引擎有11种,有些特有的如:PERFORMANCE_SCHEMA 作为MySQL内存表引擎仅作用于内部收集的诊断信息。

| 引擎 | 说明 |
|---|---|
| InnoDB | MySQL默认的存储引擎,支持ACID事务,行锁。目前说目前最稳定的引擎。 |
| MyISAM | MyISAM版本早起版本存储引擎,无事务支持,表锁级别,5.6,5.7版本有些表还是这个引擎,系统表也存在引擎。 |
| Memory | 将所有数据存储在内存中,以便在需要快速查找非关键数据的环境中进行快速访问。这个引擎以前称为HEAP引擎。 |
| CSV | CSV表允许以CSV格式导入或转储数据,以便与读写相同格式的脚本和应用程序交换数据。因为CSV表没有索引,所以在正常操作过程中,通常将数据保存在InnoDB表中,只在导入或导出阶段使用CSV表。 |
| Archive | 紧凑的、未索引的表用于存储和检索大量很少引用的历史、归档或安全审计信息。 |
| Blackhole | MySQL在5.x系列提供了Blackhole引擎–“黑洞”,不存储数据,但会正常的记录下Binlog,而且这些Binlog还会被正常的同步到Slave上。binlog分发引擎。 |
| NDB | 分片方式实现数据冗余,分片机制,表会在集群进程之间被复制,企业版特有引擎。 |
| MRG_MYISAM | 对一系列相同的MyISAM表进行逻辑分组,并将引用为一个对象。适合于数据仓库等环境。 |
| Federated | 从多个物理服务器创建一个逻辑数据库,类似dblink。 |
| Example | 该引擎在MySQL源代码中作为示例引擎,演示如何开始编写新的存储引擎。 |
下面把一些特有的,能用到实际场景中的引擎特性,总结。
1.FEDERATED
FEDERATED存储引擎允许访问远程MySQL数据库中的数据,而无需使用复制或集群技术。查询本地FEDERATED表会自动从远程(联邦)表中提取数据。本地表中不存储任何数据,类似于dblink。

- 创建FEDERATED表时,表的定义是相同的,指定某些字段也可以,本地会产生数据字典表(frm,sdi),但数据的物理存储是在远程服务器上处理的。
- 插入、更新或删除信息的操作将通过C-API函数被发送到远程服务器执行,在远程服务器上更新远程服务器上的数据文件或从远程服务器返回匹配的行。
特性
- 远程服务器必须是MySQL服务器
- 在尝试通过FEDERATED表访问该表之前,FEDERATED表所指向的远程表必须存在。
- 不支持通常意义上的索引;因为对表数据的访问是远程处理的,所以实际上是远程表使用了索引。
- 表的索引定义可能不受支持。例如,对于VARCHAR、TEXT或BLOB列,创建带有索引前缀的FEDERATED表会失败。
- 支持SELECT、INSERT、UPDATE、DELETE、TRUNCATE TABLE和索引。它不支持ALTER TABLE或任何直接影响表结构的数据定义语言语句。DROP TABLE语句只删除本地表,而不删除远程表
- ON DUPLICATE KEY UPDATE语句,但如果发生重复键冲突,则语句失败并出错。
- 支持事务性的操作,发生错误时正确地执行语句回滚。
- insert_id和timestamp选项不会传播到数据提供程序,不能使用查询缓存,不支持用户定义分区
- FEDERATED表可以复制到其他副本,但必须确保副本服务器能够使用
实例
通过CONNECTION字符串访问远程服务器:包含服务器名、登录凭据、端口号和数据库/表等信息。
scheme://user_name[:password]@host_name[:port_num]/db_name/tbl_name
CONNECTION='mysql://username:password@hostname:port/database/tablename'
CREATE TABLE `t1` (
`id` int NOT NULL,
`name` varchar(20) ,
`age` int DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_age` (`age`)
) ENGINE=FEDERATED DEFAULT CHARSET=utf8mb4
CONNECTION='mysql://dbadmin:[email protected]:3381/db1/t1';访问多个表可以维护linkserver方式:
#创建server
mysql>CREATE SERVER fedlink
FOREIGN DATA WRAPPER mysql
OPTIONS (USER 'dbadmin', PASSWORD '123456',HOST '172.17.27.48', PORT 3381, DATABASE 'db1');
#查看server
mysql> select * from mysql.servers;
+-------------+--------------+-----+----------+----------+------+--------+---------+-------+
| Server_name | Host | Db | Username | Password | Port | Socket | Wrapper | Owner |
+-------------+--------------+-----+----------+----------+------+--------+---------+-------+
| fedlink | 172.17.27.48 | db1 | dbadmin | 123456 | 3381 | | mysql | |
+-------------+--------------+-----+----------+----------+------+--------+---------+-------+
1 row in set (0.00 sec)
#创建link表
mysql>CREATE TABLE `t3` (
`id` int NOT NULL,
`name` varchar(20) ,
`age` int DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_age` (`age`)
) ENGINE=FEDERATED
DEFAULT CHARSET=utf8mb4
CONNECTION='fedlink/t1';2.Blackhole
BLACKHOLE存储引擎就像一个“黑洞”,数据目录会创建表数据字典表(frm,sdi),接受数据,但将其丢弃,不存储数据。对BLACKHOLE表的插入不存储任何数据,但记录binlog,则SQL语句将被记录并复制到slave服务器。这可以作为binlog分发器。
特性
在通常情况下一主多从场景下,因为分发binlog到每个slave节点,会导致master过多的流量。在这种情况下,可以在源主机上下游建立一个“虚拟”副本进程,其默认存储引擎为BLACKHOLE,只有分发到其他replica节点。也适当的可以添加过滤规则。
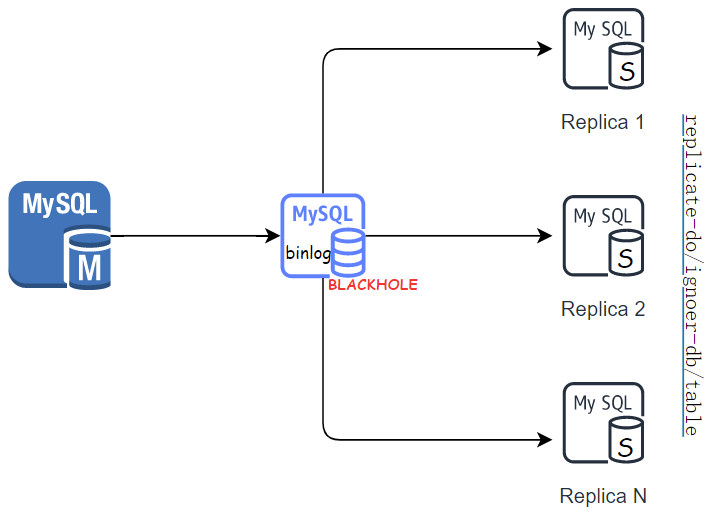
- 对于事务感知的,即commit的事务被写入二进制日志,而rolled-back的事务则不会。
- BLACKHOLE本质上是一个“无操作”存储引擎,除了IO,网络方面消耗,其他基本无性能瓶颈。
- 考虑自动递增的主键列的行为时,引擎不自动增加字段值,也不保留自动增加字段状态。
实例
操作和binlog信息:
mysql> CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO test VALUES(1,'record one'),(2,'record two');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM test;
Empty set (0.00 sec)
root@localhost: 19:38: [mysql]> binlog信息:
BEGIN
/*!*/;
# at 5879
#221107 19:38:44 server id 129 end_log_pos 5959 CRC32 0xf7aac519 Rows_query
# INSERT INTO test VALUES(1,'record one'),(2,'record two')
# at 5959
#221107 19:38:44 server id 129 end_log_pos 6016 CRC32 0xca30f968 Table_map: `mysql`.`test` mapped to number 99
# at 6016
#221107 19:38:44 server id 129 end_log_pos 6083 CRC32 0x3fcd208d Write_rows: table id 99 flags: STMT_END_F
### INSERT INTO `mysql`.`test`
### SET
### @1=1 /* INT meta=0 nullable=1 is_null=0 */
### @2='record one' /* STRING(40) meta=65064 nullable=1 is_null=0 */
### INSERT INTO `mysql`.`test`
### SET
### @1=2 /* INT meta=0 nullable=1 is_null=0 */
### @2='record two' /* STRING(40) meta=65064 nullable=1 is_null=0 */
# at 6083
#221107 19:38:44 server id 129 end_log_pos 6160 CRC32 0x86d6d733 Query thread_id=16 exec_time=0 error_code=0
SET TIMESTAMP=1667821124/*!*/;
COMMIT
3.CSV
CSV引擎可以将普通的CSV文件作为mysql的表来处理,但不支持索引,不支持NULL,不支持tablespace操作。CSV引擎可以作为一种数据交换的机制,非常实用。
特性
底层会创建扩展名为sdi,CSM,CSV 3个文件。sdi是表字典文件,CSV保存实际数据,CSM储表的状态和表中存在的行数。CSV存储引擎使用逗号分隔值的格式将数据存储在文本文件中,存储的数据直接可以在操作系统里,用文本编辑器,或者excel读取。对于数据的快速导入,导出是有明显优势的。

实例
mysql> CREATE TABLE test (i INT NOT NULL, c CHAR(10) NOT NULL) ENGINE = CSV;
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO test VALUES(1,'record one'),(2,'record two');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM test;
+---+------------+
| i | c |
+---+------------+
| 1 | record one |
| 2 | record two |
+---+------------+
2 rows in set (0.00 sec)备注:
通过关闭服务,手动更改CSV文件数据内容,可以把数据直接挂在上去。也是一种CSV数据格式的快速迁移的方式。
4.Memory
内存存储引擎(以前称为HEAP)创建具有存储在内存中的内容的专用表。因为数据容易受到崩溃、硬件问题或电源中断的影响,所以只能将这些表用作临时工作区或只读缓存,用于从其他表提取的数据。
内存存储引擎不会在磁盘上创建任何文件,表定义存储在MySQL数据字典中。
特性
- 涉及临时、非关键数据的操作,如会话管理或缓存。当MySQL服务器停止或重新启动时,内存表中的数据将丢失。
- 内存存储,快速访问和低延迟。数据卷可以完全放入内存中,而不会导致操作系统交换虚拟内存页。
- 只读或以读为主的数据访问模式
- 内存表不能分区
- 内存表的空间以小块的形式分配。表对插入使用100%动态哈希。不需要溢出区域或额外的键空间。空闲列表不需要额外的空间。删除的行被放入一个链表中,并在向表中插入新数据时重用。内存表也没有与哈希表中的删除和插入相关的常见问题。
- MEMORY表使用固定长度的行存储格式。VARCHAR等变长类型使用固定长度存储。
- 内存表不能包含BLOB或TEXT列。
- MEMORY包括对AUTO_INCREMENT列的支持。
- 非临时内存表在所有客户机之间共享,就像任何其他非临时表一样。
加载数据
因内存引擎的特性,需要在MySQL服务器启动时填充MEMORY表,可以使用init_file加载数据。例如,可以将INSERT INTO…SELECT或LOAD DATA到文件中以从持久数据源加载表。
#配置文件
[mysqld]
init-file=/opt/script/init_file.sql
#或 启动参数
mysqld --init-file=/opt/script/init_file.sql &
#脚本init_file.sql
USE test;
BEGIN;
DROP TABLE IF EXISTS mtable;
CREATE TABLE IF NOT EXISTS mtable(id int) ENGINE=MEMORY;
INSERT INTO mtable VALUES(1),(2);
END;内存表的复制
支持高可用架构下的Memory表的binlog记录信息。但服务关闭重启内存表将变为空,这将导致副本与源不同步,并可能导致其他故障或导致副本停止,维持高可用就比较麻烦的部分。这种情况下重新初始化数据,比如:TRUNCATE TABLE语句,之后再次加载数据。
使用内存表
如果从Memory表中删除单个行,则不会回收内存。只有在删除整个表时才回收内存。要释放被删除的行使用的内存,使用ALTER TABLE ENGINE= memory强制重新构建表。
max_heap_table_size变量设置内存表的最大大小限制。要控制单个表的最大大小,在创建每个表之前设置此变量的会话值。
mysql> SET max_heap_table_size = 1024*1024;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE TABLE t1 (id INT, UNIQUE(id)) ENGINE = MEMORY;
Query OK, 0 rows affected (0.01 sec)尽管MEMORY表在内存中进行处理,但在繁忙的服务器上,对于通用查询,或者在读写工作负载下,并不一定比InnoDB表快。还有内存不释放问题,需要谨慎。
总结
除了默认引擎,这些特有的引擎只能慎用。这些引擎实践的累计比较少,大醇小疵的问题,深入使用可能为害很大。在一些短暂的小技巧解决问题中建议使用。
除此之外,还有一些第三方引擎 如:TokuDB(高写性能高压缩存储引擎)引擎,BDB(BerkeleyDB)事务存储引擎 ,事务处理Falcon存储引擎 ,Infobright 列存储引擎 ,Percona的XtraDB 等。