大家好,我是微学AI,今天给大家介绍一下,深度学习中的模型融合。它是将多个深度学习模型或其预测结果结合起来,以提高模型整体性能的一种技术。
深度学习中的模型融合技术,也叫做集成学习,是指同时使用多个模型来进行预测或分类,将它们的结果结合起来,从而获得更准确、更鲁棒的结果。这种方法能够弥补单个模型的不足之处,提高模型的性能。
常见的深度学习模型包括卷积神经网络(CNN)、循环神经网络(RNN)等,在实际应用中,通常会使用多个模型来解决同一个任务。然而,单独使用每个模型可能会存在过拟合、欠拟合、训练时间长等一些问题。这时,模型融合技术就派上用场了。 对于模型融合技术,其主要的思想是结合多个模型的优点,减少缺点,从而提高整体的性能。
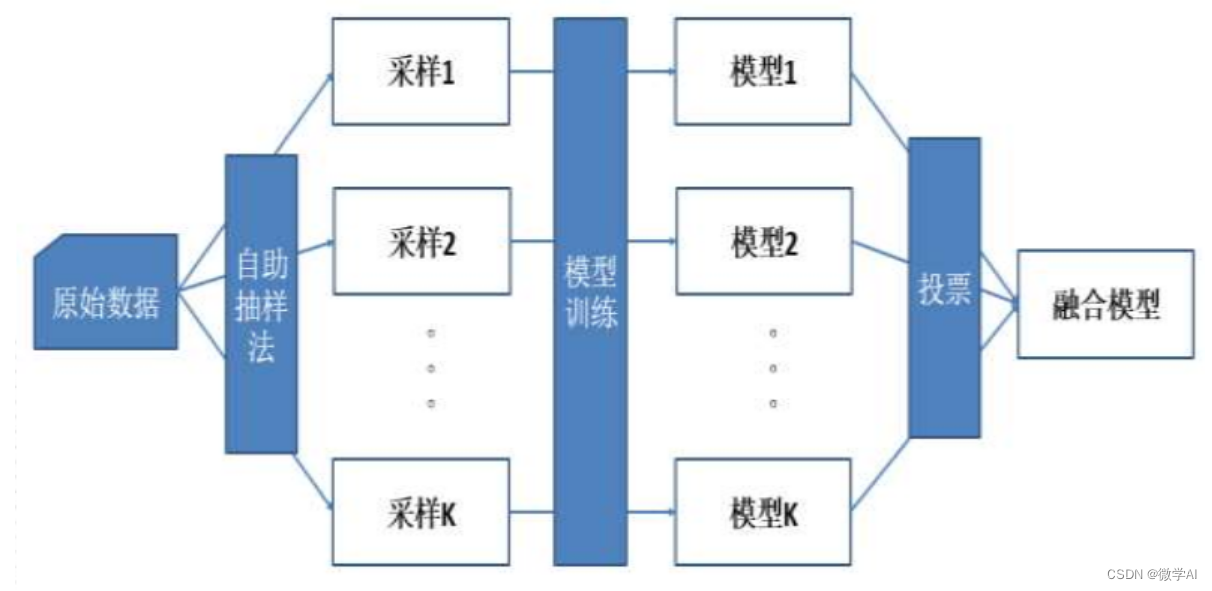
一、模型融合技巧主要包括以下几个方面:
1. 投票法: 对多个相同类型的模型进行训练,最后通过投票的方式选择输出结果最多的类别作为最终的预测结果。在实践中,通常会使用奇数个模型,以避免出现相同数量的投票结果。
2. 加权平均法: 对多个相同类型的模型的输出结果进行加权平均。采用加权平均法融合的模型,可以根据效果不同,分配不同的权重。
3. 集成多种不同类型的模型: 在深度学习中,常常会使用不同类型的模型,如 CNN、 RNN 、 LSTM 等,将它们进行集成,综合利用不同模型的优点,进一步提高系统的性能。
4. 提前停止模型训练: 训练多个模型时,如果其中一个模型已经达到了最优的状态,可以停止继续训练,以达到快速训练过程和提高融合效果的目的。
模型融合主要提高了深度学习模型的表现力和泛化性能,更好的解决了过拟合等问题。在选择模型融合技巧时,可以根据具体实际应用选择不同的融合方法,灵活运用各种方法,从而得到更好的模型效果。
应用场景想象:
想象你正在参加一个模型比赛,需要对一些数据进行预测。你仅使用了一个模型进行预测,但是你发现这个模型可能存在某些缺陷,导致预测结果不够准确,于是你想到使用模型融合技术。 你开始集成三个不同的模型,每一个模型都有自己的特点和优缺点。为了得到集成模型的预测结果,你可以采用堆叠法,即把三个模型的预测结果作为输入特征,再训练一个新的模型进行预测。通过堆叠,你得到了一个更加准确的预测结果。 如果你觉得模型之间存在评估的差异,你也可以使用加权平均法来集成模型。你可以根据每一个模型的表现,为它们分配一定的权重,然后根据这些权重,对它们输出的结果进行加权平均,从而得到更加精确的预测结果。 最后,你也可以使用投票法,这种方法是将多个模型的预测结果进行投票,选择获得最多票数的结果作为最终预测结果。它会适用于模型数量较多的情况,即使其中某个模型出现了不准确的情况,也不会对最终结果有太大的影响。 通过这些集成模型的方法,你可以在深度学习中获得更为准确、稳定的预测结果,从而提升模型的性能和可靠性。
二、模型融合代码样例:
下面我将利用投票法、加权平均法和集成模型法三种方式对CNN网络进行融合。
import numpy as np
from sklearn.metrics import accuracy_score
from tensorflow import keras
from tensorflow.keras import layers
# 加载 MNIST 数据集
(train_images, train_labels), (test_images, test_labels) = keras.datasets.mnist.load_data()
# 将像素值缩放到 0-1 范围内
train_images = train_images.astype('float32') / 255.
test_images = test_images.astype('float32') / 255.
# 将标签转换为 one-hot 编码
train_labels = keras.utils.to_categorical(train_labels, 10)
test_labels = keras.utils.to_categorical(test_labels, 10)
# 定义 CNN 模型
def create_model():
model = keras.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
return model
# 创建多个 CNN 模型
models = []
for i in range(3):
model = create_model()
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=128, verbose=1)
models.append(model)1.投票法:对测试集进行预测,并取预测结果的众数作为最终预测结果
predictions = []
for model in models:
predictions.append(model.predict(test_images))
y_pred = np.argmax(np.round(np.mean(predictions, axis=0)), axis=1)
y_true = np.argmax(test_labels, axis=1)
# 计算准确率
acc = accuracy_score(y_true, y_pred)
print("使用投票法进行模型融合的准确率:", acc)2.加权平均法:为每个模型定义一个权重,并将预测结果加权平均
weights = [0.2, 0.3, 0.5]
predictions = []
for i, model in enumerate(models):
prediction = model.predict(test_images)
predictions.append(weights[i] * prediction)
y_pred = np.argmax(np.sum(predictions, axis=0), axis=1)
y_true = np.argmax(test_labels, axis=1)
# 计算准确率
acc = accuracy_score(y_true, y_pred)
print("使用加权平均法进行模型融合的准确率:", acc)3.模型集成法:将多个 CNN 模型堆叠在一起,将其看作一个更强大的模型,并对测试集进行预测
inputs = keras.Input(shape=(28, 28, 1))
outputs = [model(inputs) for model in models]
y = layers.Average()(outputs)
ensemble_model = keras.Model(inputs=inputs, outputs=y)
ensemble_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练集成模型
ensemble_model.fit(train_images, train_labels, epochs=5, batch_size=64)
# 测试集成模型
predictions = ensemble_model.predict(test_images)
y_pred = np.argmax(predictions, axis=1)
y_true = np.argmax(test_labels, axis=1)
# 计算准确率
acc = accuracy_score(y_true, y_pred)
print("使用模型集成方法进行模型融合的准确率:", acc)最后我们可以看三种方法的准确率,在实战案例中根据业务需求进行方法的选择。