目的:解决数据同步性能问题,提高数据时效性。
适用场景:业务库和分析库分离、数据仓库ODS实时同步、ETL增量数据处理、跨局域网加速、数据库实时备份、异构数据库迁移。
前些日子和客户聊天,他们用FineReport报表工具5、6个年头了,先后做了财务报表、营收分析、生产分析等七八个模块,解决了企业信息化的不少难题。
后续聊到,之前的4个报表开发,2个专门去做ETL了,但总是被业务追着要数据,明明定好的跑数时间,经常要手动去运行拿到当前的数据。但一个任务又不是马上能跑完的,经常出现“业务急、IT忙”的现象。
然而时效性问题不是不想解决,种种原因,初期系统建设规范问题、实时技术限制或者是只能有部分数据支持实时等,所以体现业务上就是数据延迟T+1了。
然后就问我们有什么解决方案。然后,就从数据的高时效、增量聊起…
要做到数据的高时效,要做到两点:
数据的增量获取:就是之前需要处理100w,现在增量只需要算1w,出结果的速度就快了。
强大的计算能力:庞大的数据量,复杂的计算逻辑,最后的统计指标,都需要强大的计算能力支撑,即以前计算100w的数据需要10s,现在1s即可完成计算。
- 这一章主要介绍数据的实时增量获取,计算能力将在另外的文章进行介绍。
1、实时增量技术难吗?怎么实现
常用的ETL模式是增量ETL和全量ETL。其中增量ETL,每次只处理增、删、改的变化数据,减少大量非变化数据的同步,对比全量ETL,用最少的资源提高数据同步效率。
怎么才能具备增量的条件?一般的增量方法有以下5种:
时间戳:最常见的方式,简单、好判断,但很多时候业务系统并不是每张所需要的表都有时间戳。
触发器:数据库的一种机制,可靠性较高,但对业务系统数据库性能损耗较大。
全量对比得出增量数据更新:对源数据库的消耗小,但面对大数据量对比更新,对工具需要较大的性能开销。
全量对比MD5方式:建立一个结构类似的MD5临时表,通过MD5校验码比对,原理同上种方法。
日志解析:现在常见的数据库具备日志归档等功能,从日志获取变化数据,通过代码来开发和管理。
从对业务系统改造最少出发,排除掉时间戳和触发器的方式,从提高同步效率来说,排除掉全量对比获取增量的两种方式,那么就剩下日志解析的方式了。
FineDataLink的数据管道,通过MySQL binlog、Oracle LogMiner、和SQL Sever的CDC等日志解析,来实现对增量数据的获取。
同时采用流式引擎,实时捕获源数据库的变化,从而在毫秒内更新到目标数据库,从而实现多源、异构业务系统的数据实时同步。
让大批量的数据同步,分摊到每个数据发生变化的时间点上进行增量同步,而不是一个特定时间点执行大批量数据,既减轻了对源库的压力,同时还提高了数据获取的时效性。
实时同步过来的作为数据建设的ODS层,数据管道支持自主进行主键设置,逻辑删除、物理删除配置,以及自动新增时间戳,以弥补业务数据表进行分析的一些弊端,使得后续数据处理过程具备增量计算的条件。
2、管道任务是如何构建的?学习、管理成本高吗?
实时数据管道任务的配置,分以下五步骤:
1、消息队列配置
读写两端分离,以保证在持续增量同步过程中,读写两端不会互相阻塞,从而实现高性能;以及对不能正常写入目标库的脏数据进行暂存,保证数据的完整性。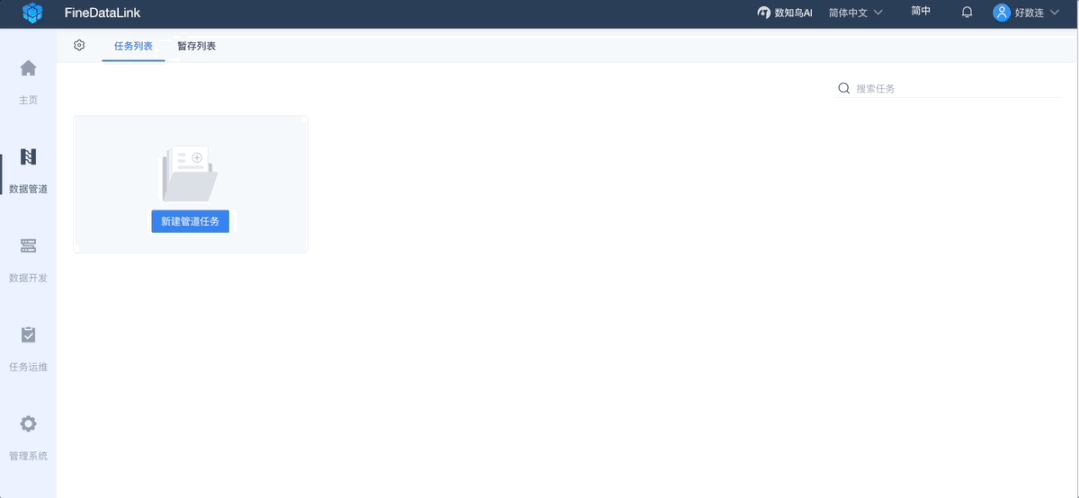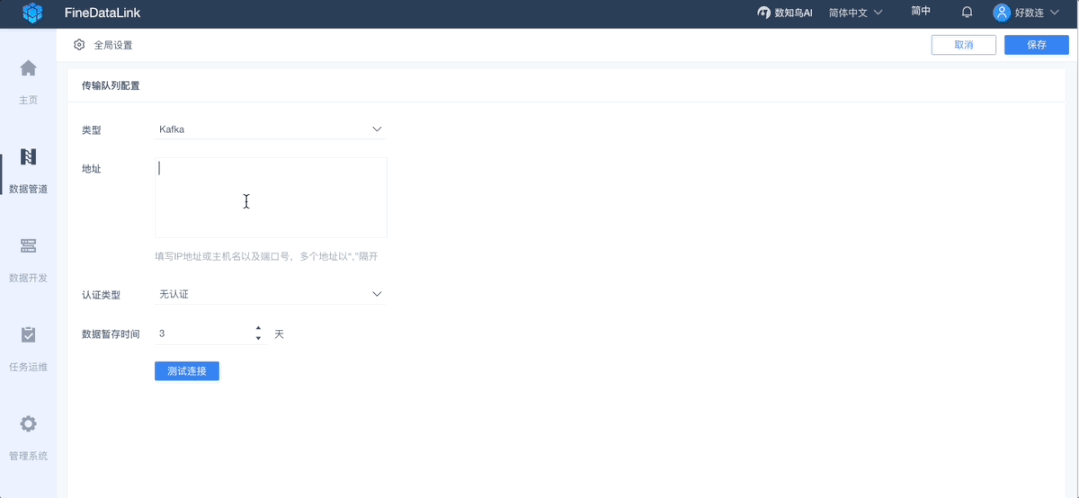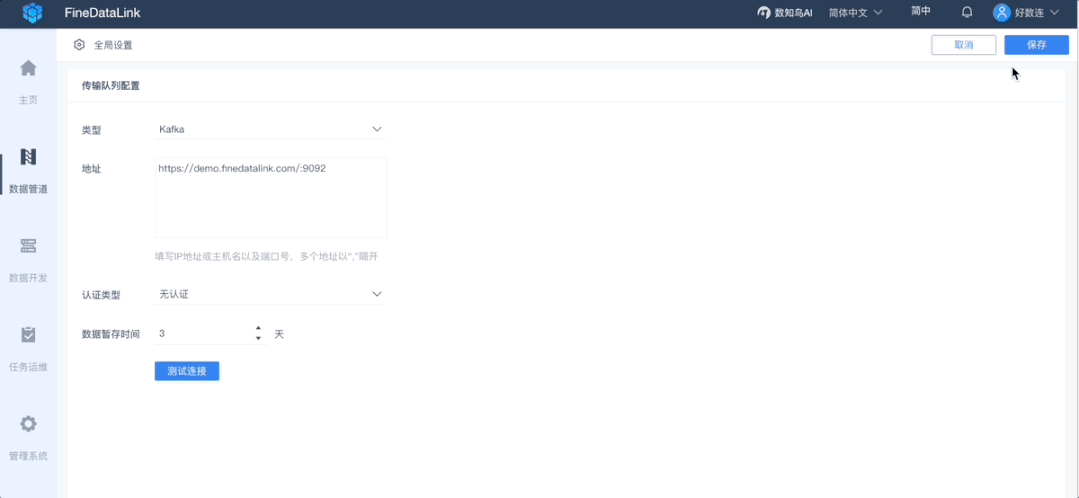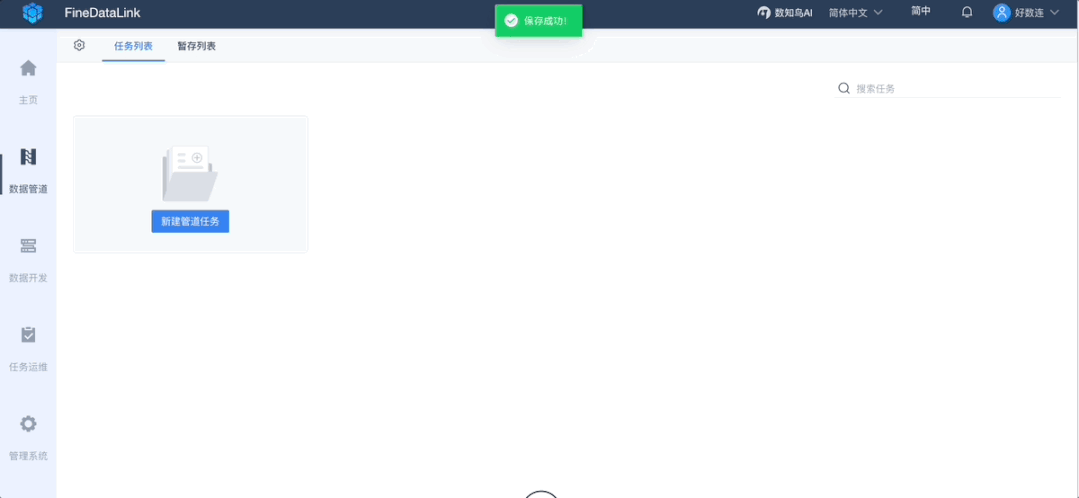
2、“多源、异构”数据源、目的地选择
屏蔽不同业务系统的独特性和差异性,从底层数据存储入手,扩大支撑范围,让数据实时同步简单易用。目前FineDataLink支持从MySQL、SQL Server、Oracle、PostgreSQL、GaussDB 200、GreenPlum等之间的整库全部表、多表进行数据实时同步。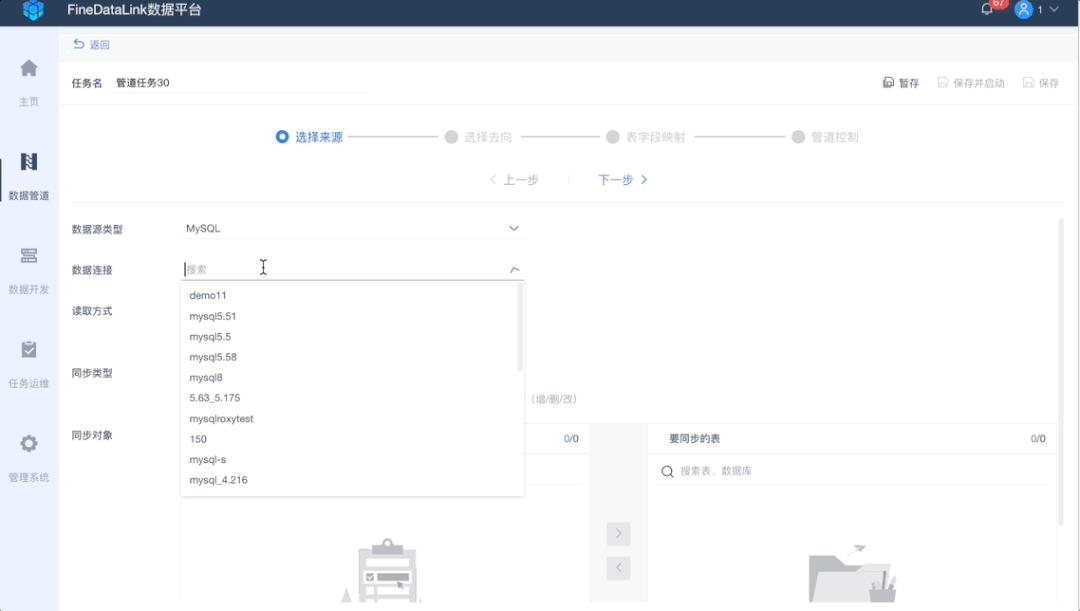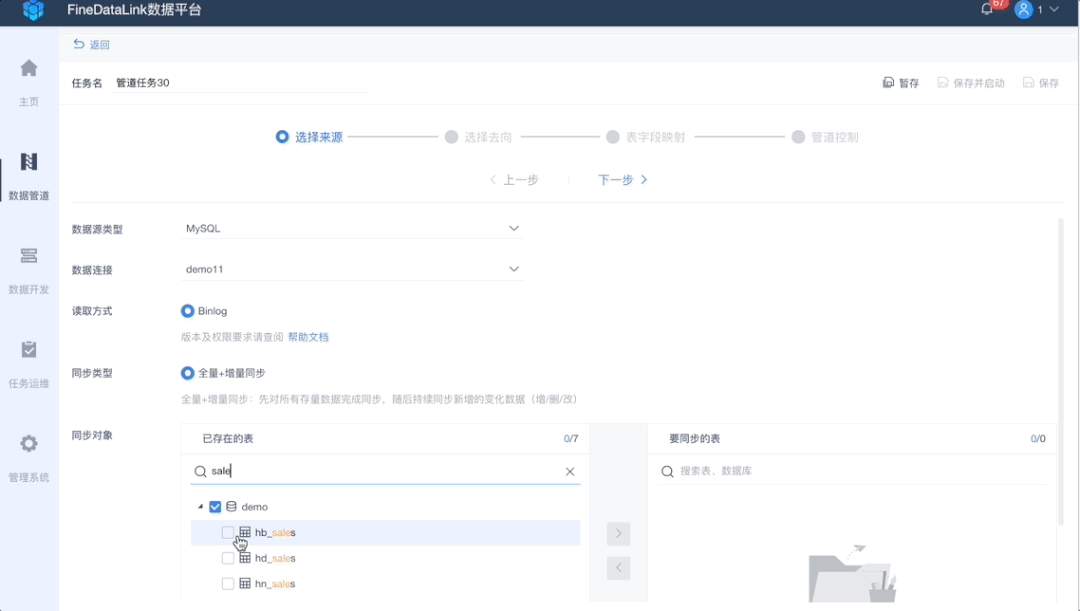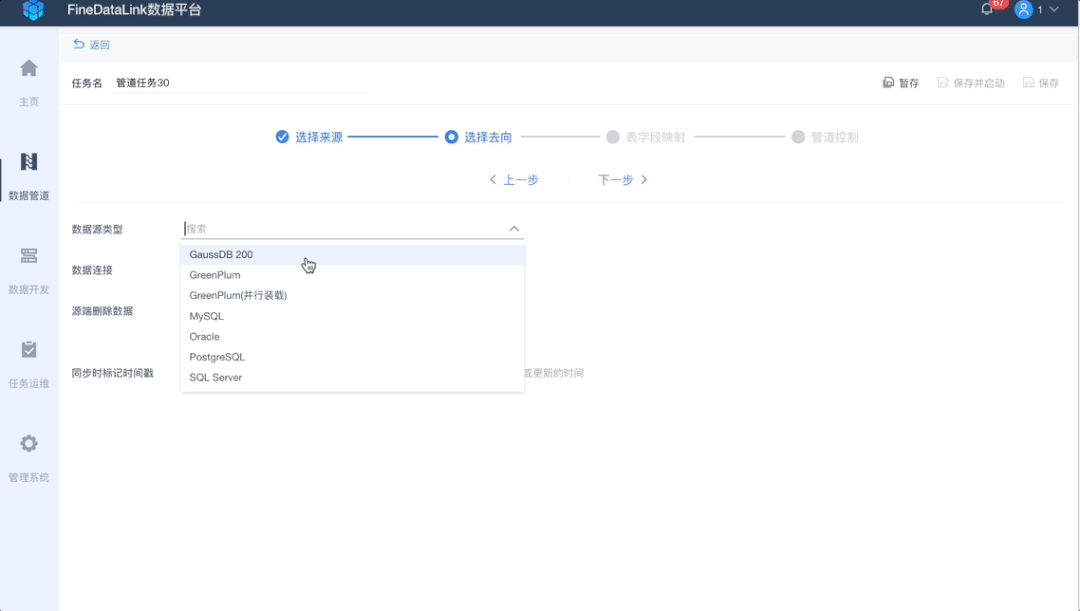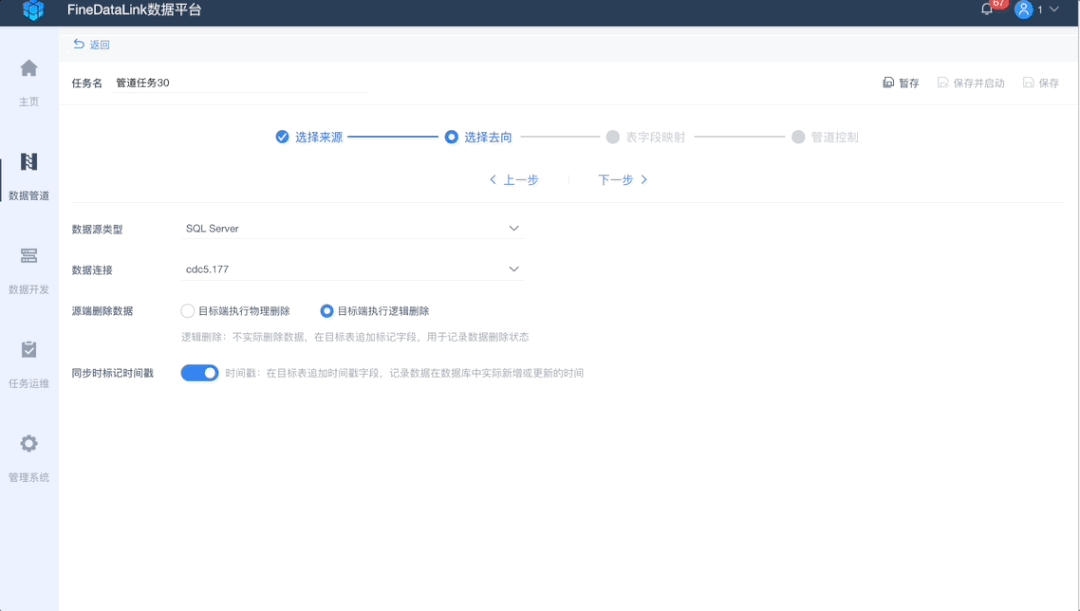
目标库的表既可以选择“自动创建”新的目标表,也可以选择“已存在表”,用于历史任务迁移、目标表已存在等场景。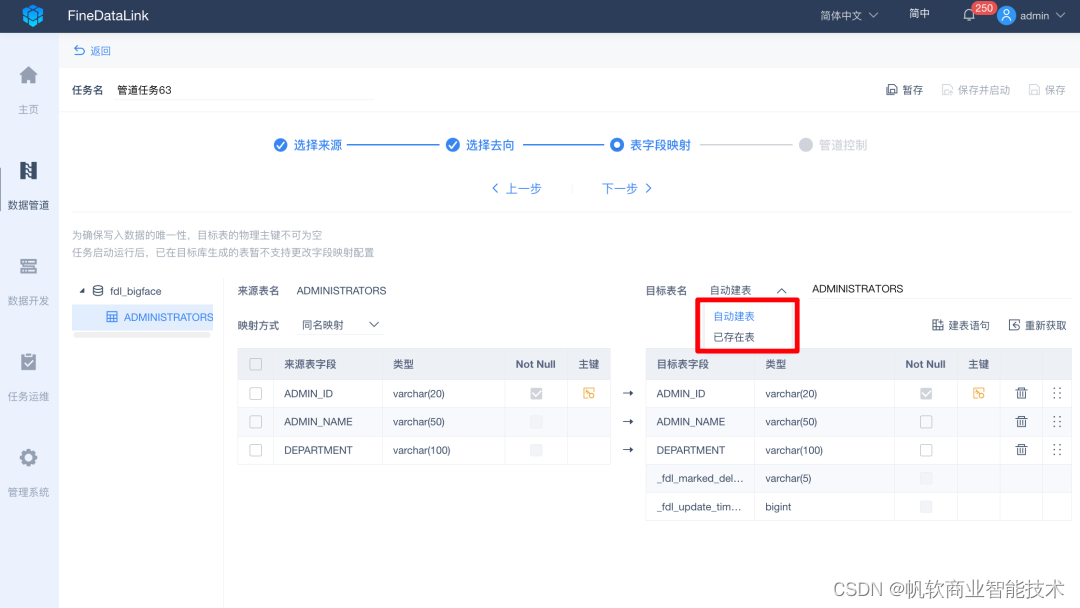
同时,在这里提供了新增“时间戳”和“逻辑删除标志位”,在目标表追加fdl_marked_deleted、fdl_update_timestamp标记字段,用于记录数据的删除状态,以及实际新增、更新的时间。
从而弥补业务系统表不一定都有时间戳和逻辑删除位的问题,那么后续的处理逻辑可以从原来的全量重刷大量数据,变为有选择性处理发生过变化的小部分数据,减少处理数据量,节省计算资源,提升处理效率,多用于增量计算、增量加载和拉链表计算等场景。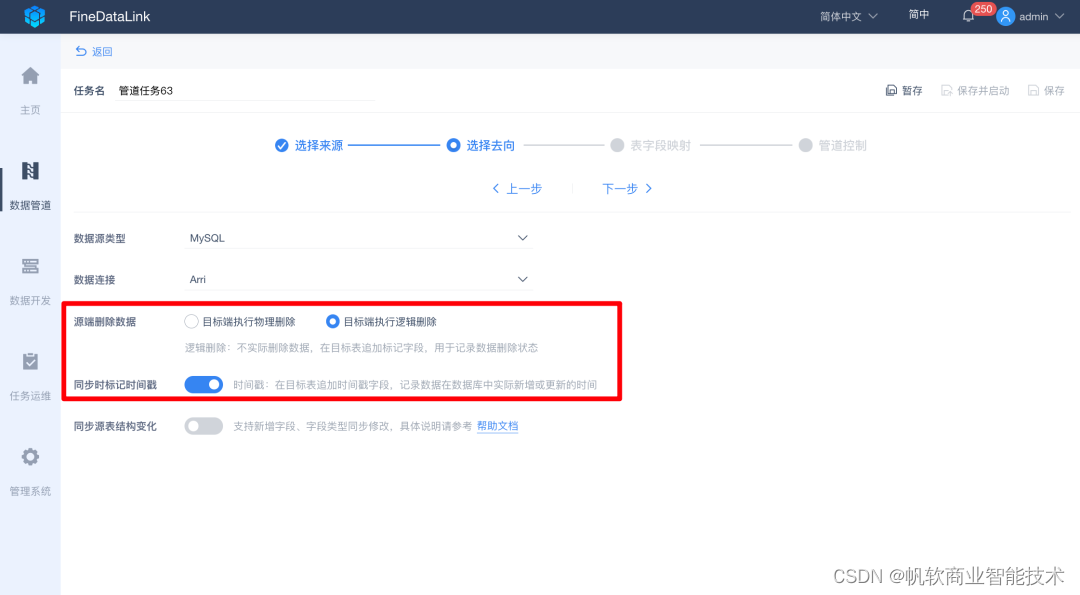
另外,在进行实时同步过程中,来源端结构可能因业务调整等原因发生变动,如增删表、增删字段、修改字段名称、修改字段类型等,目标端可以自动同步这些来源端的调整,不需要进行人为的调整适配。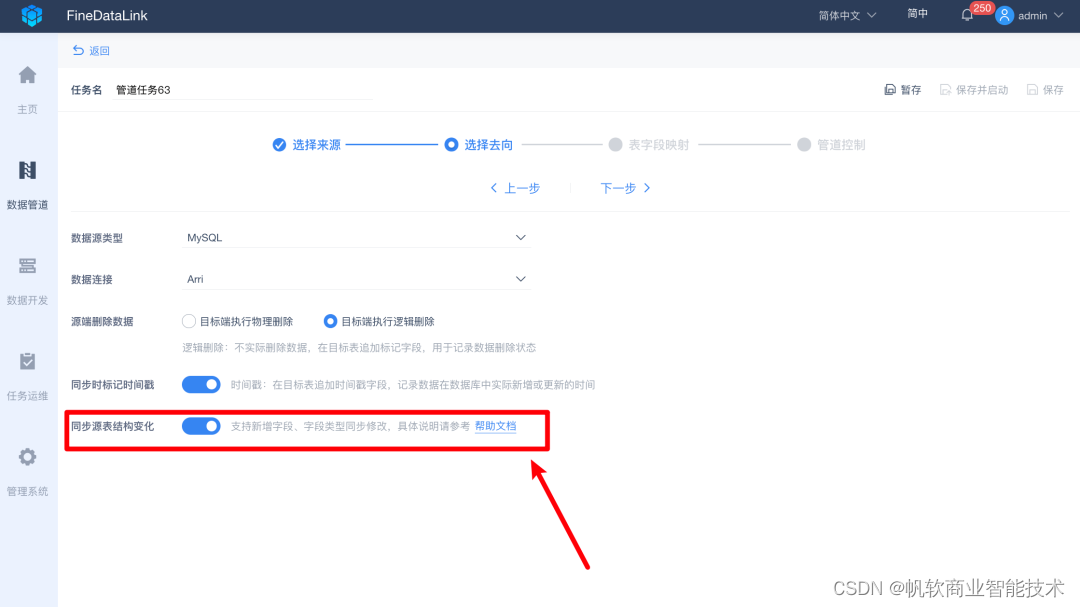
3、自动表字段映射
当需要异构数据库数据同步时,字段自动映射功能,不用手动进行自动映射,提高配置环节效率。
同时支持目标端的更多自定义修改,例如编辑表名,编辑、删除、重命名字段名,新增字段主键、非空等配置,规范数据输出标准。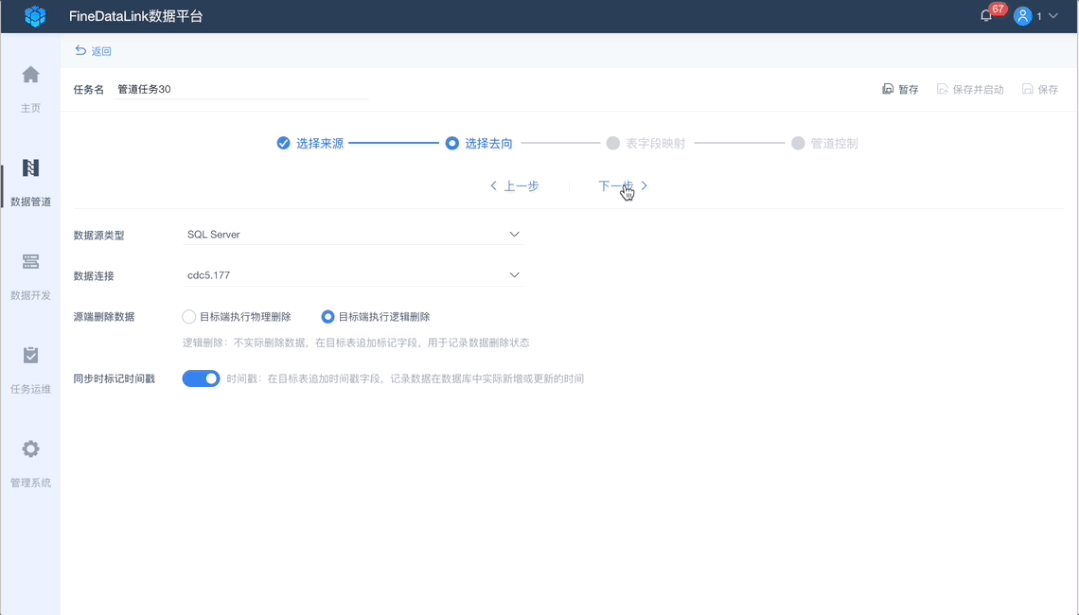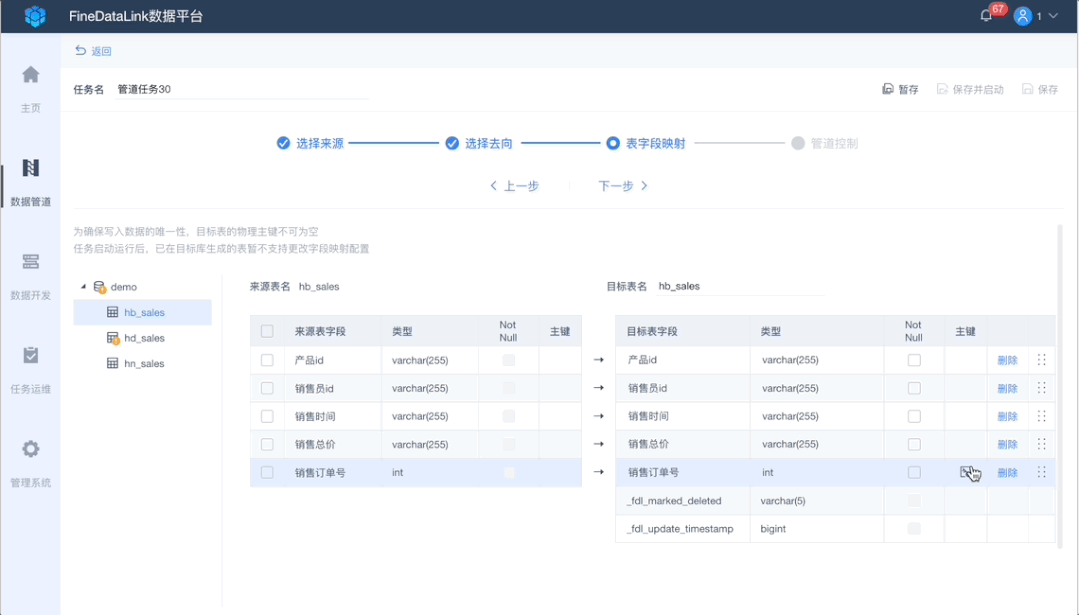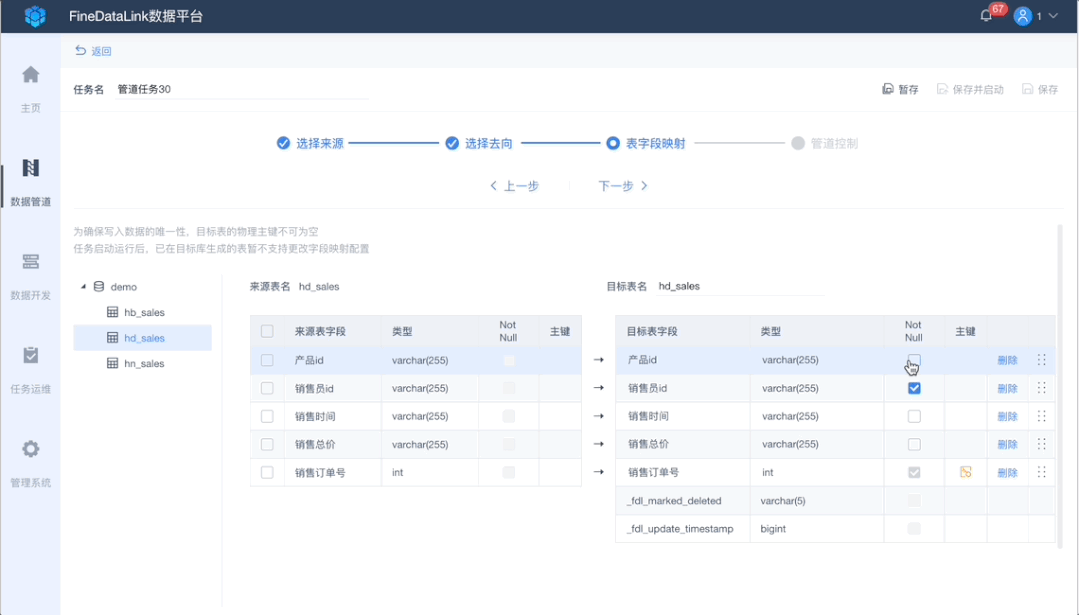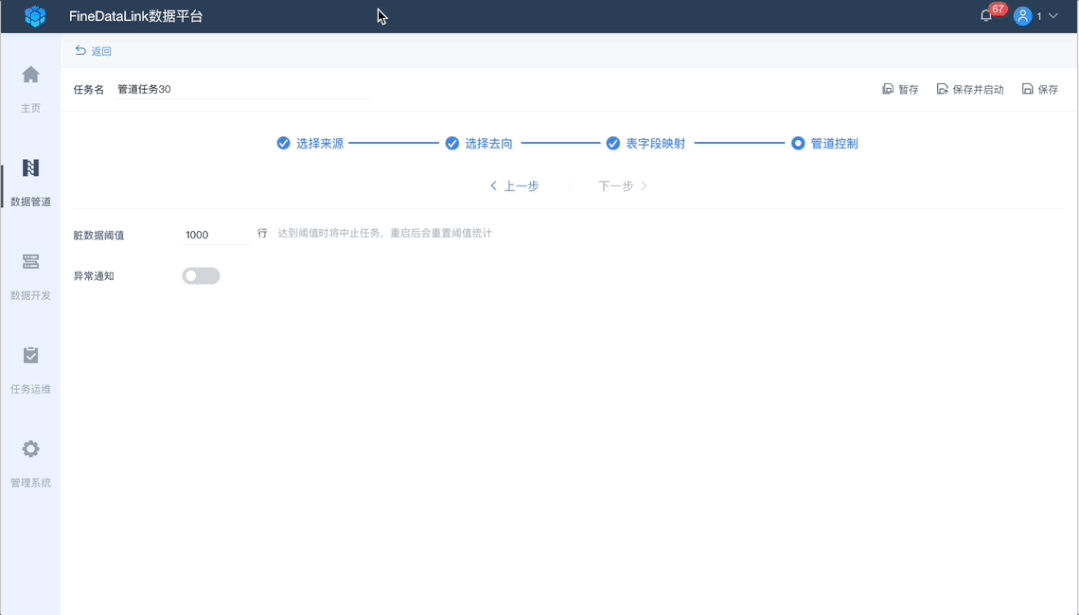
4、管道控制,保障数据质量
当遇到脏数据等时候,不希望影响正常数据的实时同步,那么通过设置阈值,让整个同步过程正常运行,脏数据到达一定程度,通过短信、邮件等的方式告知,然后进行异常数据的处理。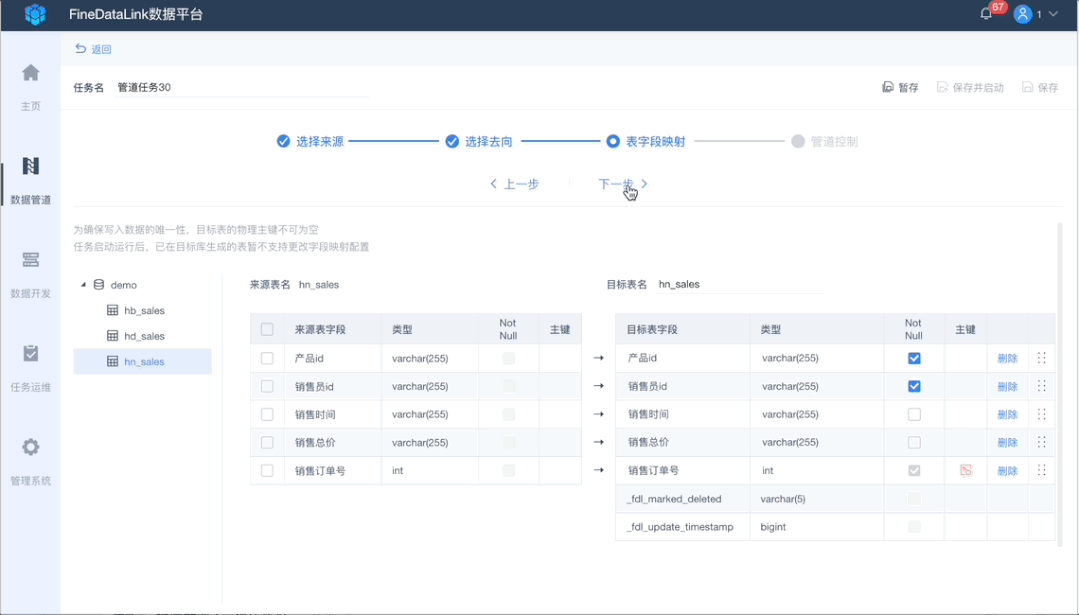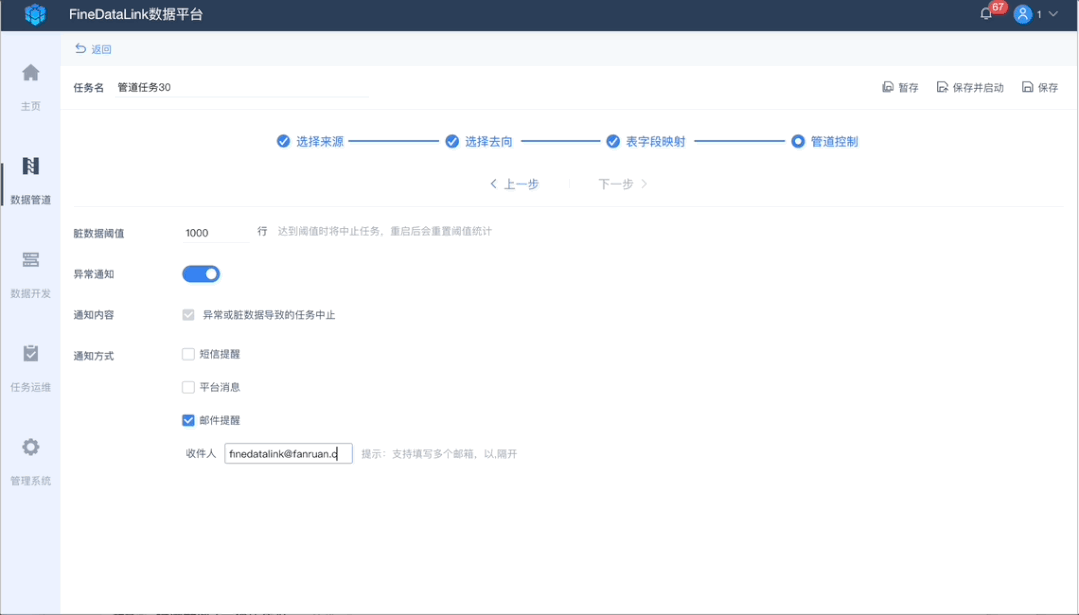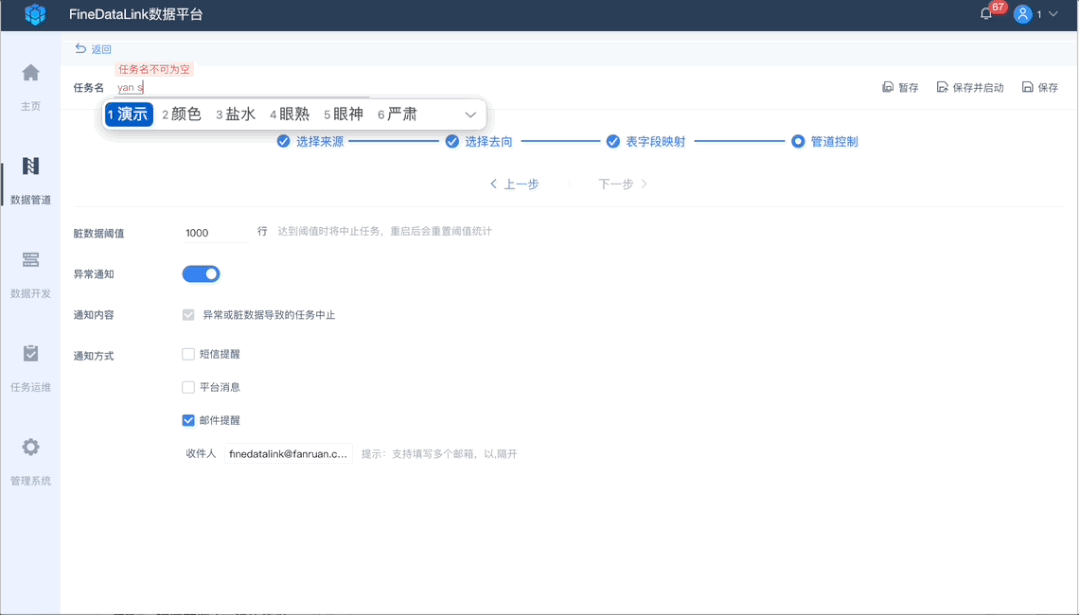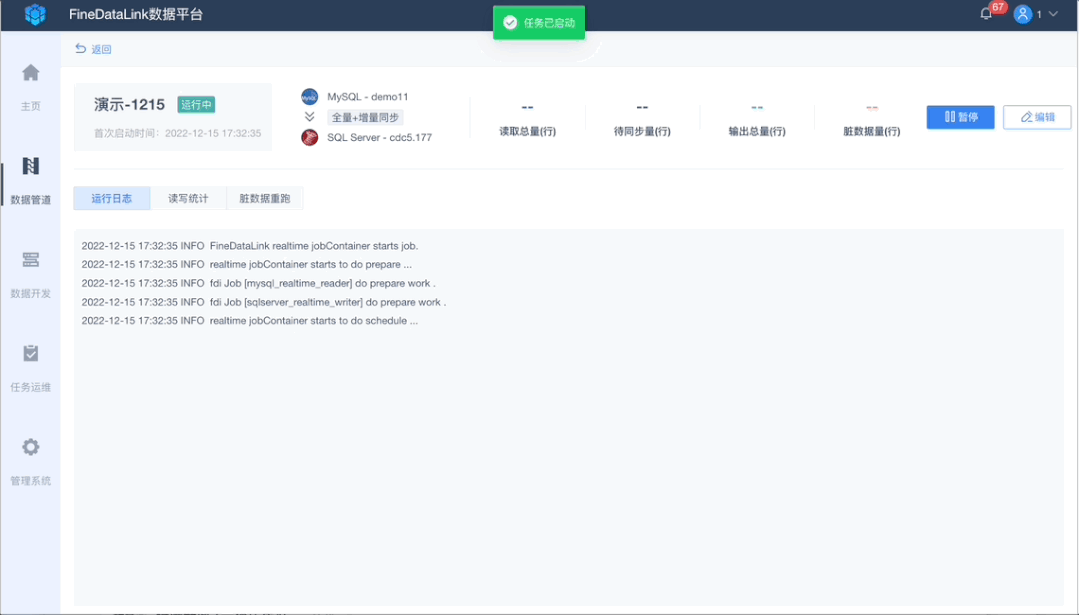
5、任务监控,运维安心
完成任务配置后,即可通过监控页面看到读取、输出的总量和速度,以及是否存在脏数据和待同步数据,让整个同步过程完全透明。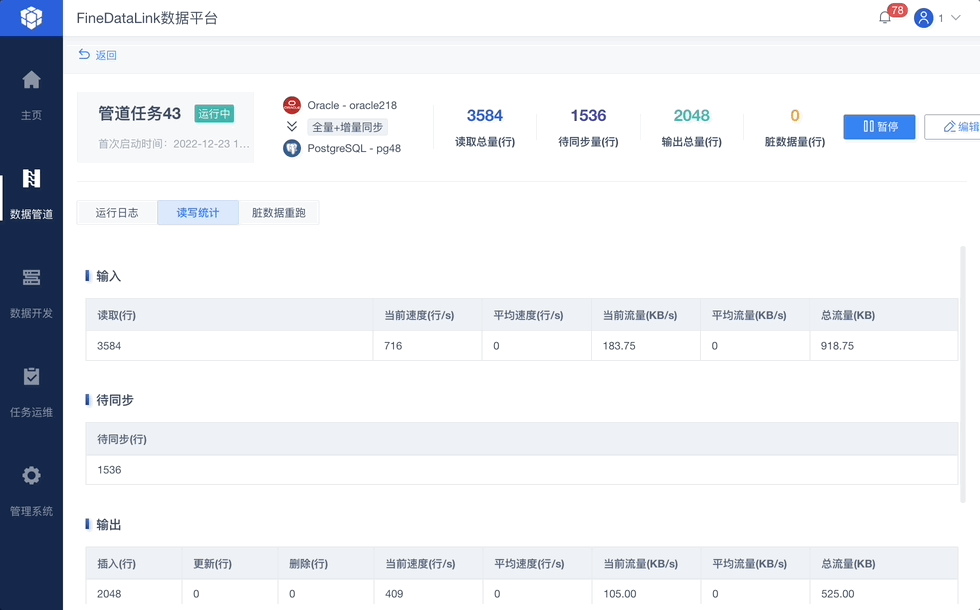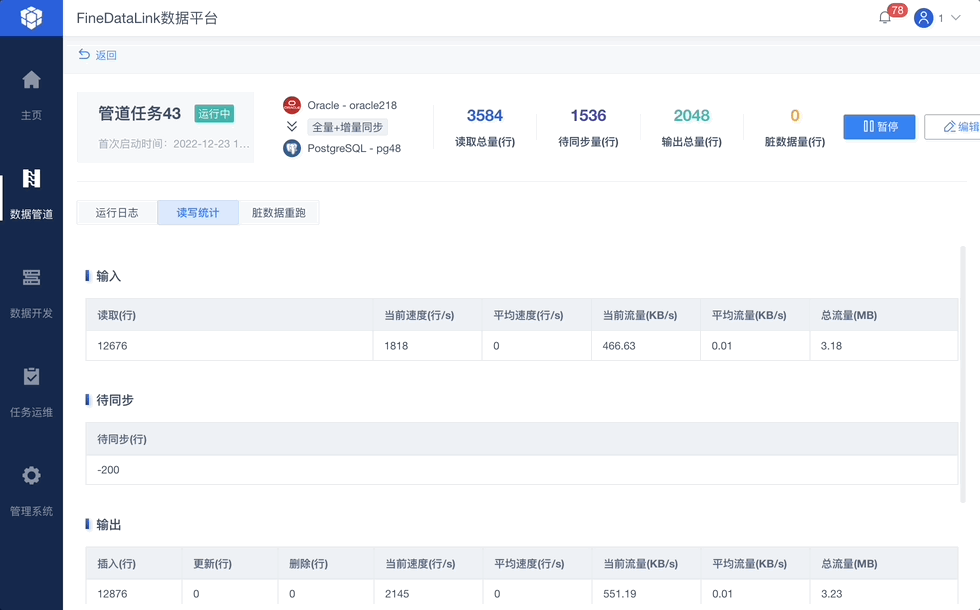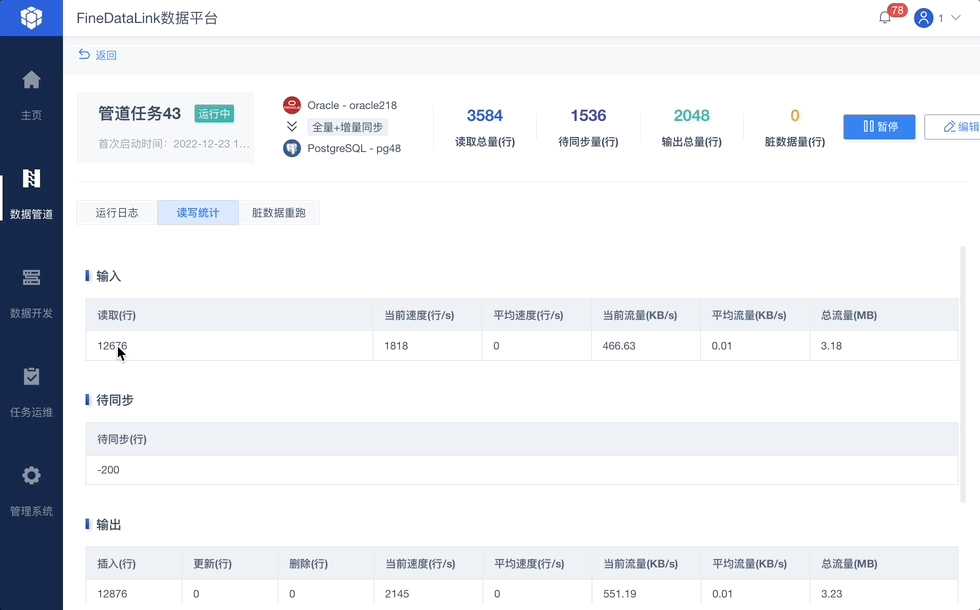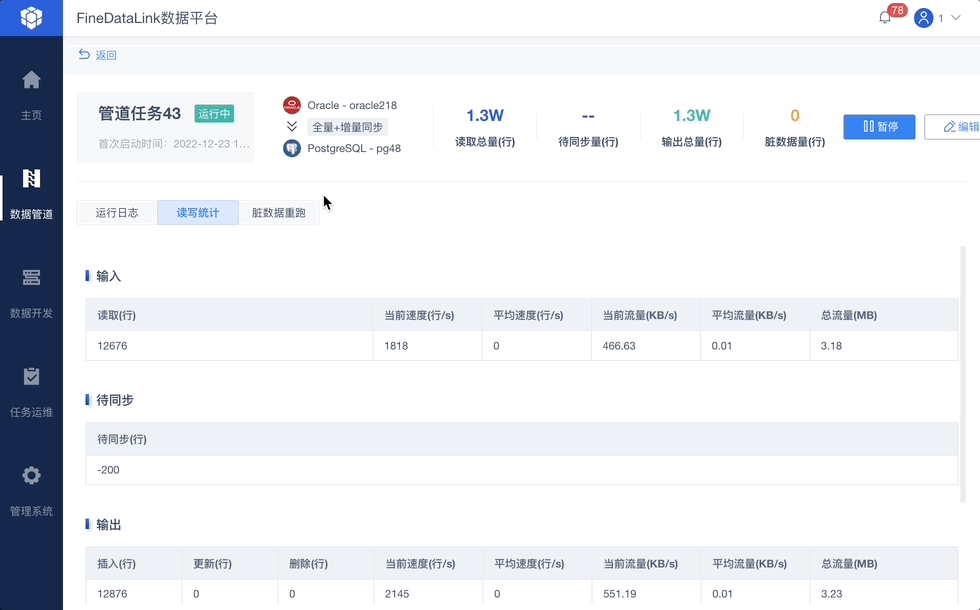
3、实践场景
实时为强依赖这部分数据而工作的的人提供了立即识别和快速解决问题的能力。
制造业某一客户,每天都需要进行生产回顾,根据当前的库存、订单、产线以及机器情况等,对当天生产进行计划排期。
工作人员每天早上6点,甚至更早开始工作,去MES系统导出数据、进行EXCEL汇总分析,准备会议材料,进行异常状况追踪。然后从8点起,开始进行从课>>部>>处>>厂逐层进行开会,完成当天的生产排期会议。
另外,由于数据的时效性,有时候存在两个小时甚至更长时间的数据偏差,并不能完全真实、准确把控当前计划是否合理,并且此类重复性人工处理的方式,希望将其智能化自动处理的,为企业带来更大的价值。
采用了实时数据同步和增量计算方案后,当需要开展生产排期会议时,各层级相关人员打开排产系统,即可看到由FineDataLink处理提供的最新库存、订单、产品情况、机器情况等数据。
这样工作人员通过数据,结合实际进行问题排查,在会议前上传异常报告,摆脱了之前需要提前几个小时进行数据准备且数据准确度不足的窘迫,方便会议高效进行,快速解决问题。