1 引言
算法工程师需要掌握的基础理论包括bias-variance tradeoff,VC Dimension,信息论,正则化,最优化理论;其中从面试的角度来看,bias-variance tradeoff和正则化是重点考察的内容。本文主要总结和学习bias-variance tradeoff和VC Dimension。
2 bias-variance tradeoff
所谓bias-variance tradeoff,是指偏差和方差权衡,它是解释机器学习模型的重要工具。
2.1 基本概念
偏差度量了学习算法的期望预测和真实结果的偏离程度,刻画了学习算法本身的拟合能力;
方差度量了同样大小的训练集的变动所导致的学习性能的变化,刻画了数据扰动所造成的影响;
噪声表达了当前任务上任何学习算法所达到的期望泛化误差的下界;
2.2 图形化定义
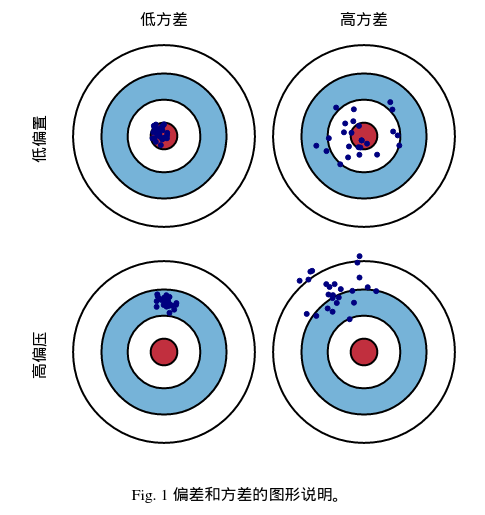
从图中可以看出:
- 对于某一真实值(红靶心),模型基于相同大小的训练集可以预测出多种结果,可以看出该模型的偏差和方差;
- 一般而言,偏差大往往指的是欠拟合,方差大指的是过拟合;
2.3 面试常考点
- 基于偏差和方差分析RF和GBDT的区别
随机森林(RF)作为一种集成学习方法,它是基于bagging的思想,能够降低方差提高模型的性能;
GBDT作为另一种集成学习方法,它是基于boosting的思想,能够降低偏差来提高模型的性能;
关于这两种方法在降低偏差和方差的证明,见为什么说bagging是减少variance,而boosting是减少bias?
- 基于偏差和方差分析K折交叉验证的K值
当K值大的时候,我们会有更少的偏差,更多的方差;原因:K值越大,数据的分布与原数据集分布类似,因此方差大;
当K值小的时候,我们会有更多的偏差,更少的方差;原因:K值越小,数据的分布与原数据集分布相差太大,因此偏差大;
2.4 参考博客
Bias-Variance Tradeoff(权衡偏差与方差)
3 VC Dimension
VC Dimension是统计学习理论用来衡量函数集性能的一种指标,VC维越大,则学习过程越复杂;但是目前并没有通用的理论来计算函数集的VC维,只知道一些特殊函数集的VC维,例如P维线性函数的VC维为P+1。
3.1 基本概念
对于一个指示函数集,如果存在h个数据样本能够被函数集中的函数按所有可能的2^h种形式分开,则称函数集能够把h个数据样本打散。则函数集的VC维就是能打散的最大数据样本数目h。
- 举个例子,对于二维线性指示函数,无论3个数据样本怎么安排,二维线性指示函数都能给你安排的明明白白的(打散),但是对于4个样本,那就没法安排了,见下图;因此二维线性指示函数的VC维为3;
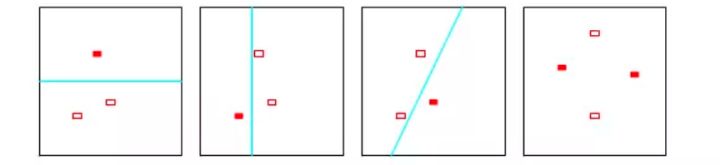

- 对于能够把任意数目的数据样本安排好的函数集(打散),该函数集的VC维为无穷大;
- 一般而言,函数集弯曲程度越大,函数集的VC维越大,模型越复杂;
3.2 面试常考点
关于VC维的面试考点,我还没有遇到过,但是我觉得重点是要理解VC维的意义,它可以衡量模型的复杂度和灵活度,VC维越高的模型,模型越复杂,学习过程也越复杂。
后续如果遇到VC维的考点,继续补充;