Font Classifier
字体分类器
Abstract
Font style recognition is a very interesting and valuable thing. We often have such a confusion when we see a very favorite font style, but we do not know what this style is. At this time, we can only go online to look for information or seek help from others, and it is not certain whether we can find it in the end. But if we have a classifier that can recognize different font styles, everything will be different and it will tell you the answer you want.
摘要
字体样式识别是一件非常有趣和有价值的事情。我们经常会有这样的困惑:当我们看到一个非常喜欢的字体样式时但我们不知道这种样式是什么。此时,我们只能上网查找信息或寻求他人的帮助,不确定最终是否能找到它。但是,如果我们有一个能够识别不同字体样式的分类器,一切都会不同,它会告诉你你想要的答案。
字体风格分类数据集共享(中英混读)
2、Evaluation (在EfficientnetV2模型上训练的效果)
1、Dataset
1.1 Introduce
The original dataset is in 3.47MB, which easily able to process on a personal computer.
原始数据集为3.47MB,可以在个人计算机上轻松处理。
The dataset is divided into three folders: train, test and val. It is a complete and qualified data set, which covers training set, test set and verification set. The three data sets are divided in the same way. They have ten directories, representing ten different font styles. These different font styles are the same language. In the training set, the data sets of ten font styles have nearly the same number. This is very beneficial for training the deep learning model.
数据集分为三个文件夹:train、test和val。它是一个完整的合格数据集,包括培训集、测试集和验证集。这三个数据集以相同的方式划分。它们有十个目录,代表十种不同的字体样式。这些不同的字体样式是相同的语言。在训练集中,十种字体样式的数据集具有几乎相同的数量。这对于训练深度学习模型非常有益。
Subdirectory
子目录

Subdirectories of subdirectories
子目录的子目录

Take samples of ten different styles of fonts to simply understand them:
选取十种不同风格的字体样本,简单地理解它们:

It has to be mentioned that we had a great time using this dataset.
必须提到的是,我们在使用这个数据集时玩得很开心。
1.2 Data preprocessing scheme
1.2 数据预处理方案
For the original data set, we consider the following scheme to preprocess the data in order to enhance the data and enable the model to learn more features.
对于原始数据集,我们考虑以下方案对数据进行预处理,以增强数据并使模型能够学习更多特征。
Our Schemes:
我们的方案:
Scheme I: Randomly enlarge and reduce the original data set.
方案一: 随机放大和缩小原始数据集。
Scheme 2: Crop the data set in the vertical direction. Considering the particularity of the data set, we have to crop it in the vertical direction, and strictly control not to divide the letters in words into two parts.
方案2:沿垂直方向裁剪数据集。考虑到数据集的特殊性,我们必须在垂直方向裁剪它,并严格控制不将单词中的字母分成两部分。
Scheme 3: We can translate the fonts in the image data up and left. This method is very helpful for enhancing the dataset.
方案3:我们可以将图像数据中的字体向上和向左平移。这种方法对于增强数据集非常有用。
2、Evaluation (在EfficientnetV2模型上训练的效果)
2.1 Train Log
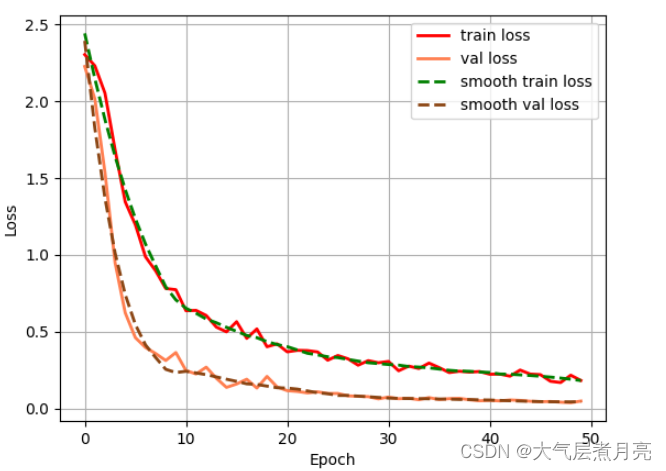
2. 2 Test Log

3、数据获取方式
提取码:b20s ![]() https://pan.baidu.com/s/11QuF0Tdh1c-5xd0U-RecSA%C2%A0祝您玩的开心~
https://pan.baidu.com/s/11QuF0Tdh1c-5xd0U-RecSA%C2%A0祝您玩的开心~