前言
哈喽啊,友友们
有喜欢玩桌游或者剧本杀的吗
其实我自己对这个不太感兴趣哈哈,但是也玩过
正好又有朋友约着出去,就是不知道哪家店更值得去
所以趁着还有几天就用python来采集一些 店家的数据信息
并做个可视化演示吧

环境使用:
- Python 3.8
- Pycharm
模块使用:
- requests >>> pip install requests
- re
- csv
如果安装python第三方模块:
- win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests)回车
- 在pycharm中点击Terminal(终端) 输入安装命令
基本流程思路: <通用>
一. 数据来源分析
- 抓包分析我们想要数据内容, 请求的那个网站 url地址得到
- F12 或者 鼠标右键点击检查选择network, 点击第二页
- 选中xhr 第一个数据包就是我们想要的内容 用到开发者工具搜索功能
二. 代码实现步骤过程: 固定四大步骤
- 发送请求, 对于刚刚分析得到url地址发送请求
- 获取数据, 获取服务器返回响应数据 —> 开发者工具里面response
- 解析数据, 提取我们想要数据内容 —> 店铺基本信息
- 保存数据, 保存数据, 保存表格里面
- 多页数据采集
多页数据采集 —> 循环 for <目的>
分析请求url地址参数变化

扫描二维码关注公众号,回复:
14561730 查看本文章

代码
# 导入数据请求模块 ---> 第三方模块 需要 pip install requests
import requests
# 导入格式化输出模块 --> 内置模块 不需要安装
from pprint import pprint
# 导入csv模块 --> 内置模块 不需要安装
import csv
# 导入时间模块 --> 内置模块 不需要安装
import time
# 导入正则模块 --> 内置模块 不需要安装
import re

python学习交流Q群:770699889 ### 源码领取
# 3. 发送请求
html_data = requests.get(url=link, headers=headers).text
# 4. 获取数据print(html_data)
"""
5. 解析数据, re正则 会用 1 不会 2
re.findall() 找到所有我们想要数据
告诉程序: 从什么地方 去找什么数据
从 html_data 去找 "address":"(.*?)","phone":"(.*?)","openTime":"(.*?)", 这段内容
其中 (.*?) 就是我们要的数据
"""
shop_info = re.findall('"address":"(.*?)","phone":"(.*?)","openTime":"(.*?)",', html_data)[0]
print(shop_info)
# shop_info 元组 ---> [0] 根据索引位置取值 / 计数从0开始计数
address = shop_info[0]
# [1] 什么意思?
phone = shop_info[1]
# replace 是什么 字符串替换方法 把 \\n 替换 空的 \<转义字符串> \n 还换行符
openTime = shop_info[2].replace('\\n', '')
print(address, phone, openTime)
# 创建文件 相对路径 你代码在哪里 文件就写在哪里
f = open('男人的小秘密多页.csv', mode='a', encoding='utf-8', newline='')
# 字典写入 f ---> 文件对象 fieldnames 字段名 表头表格第一行内容
csv_writer = csv.DictWriter(f, fieldnames=[
'店铺',
'店铺类型',
'商圈',
'人均消费',
'最低消费',
'评分',
'评论',
'纬度',
'经度',
'详情页',
])
# 写入表头
csv_writer.writeheader()
发送请求, 模拟浏览器发送请求
代码都是可以复制粘贴
- 长链接可以分段写入
- 批量替换 —> 批量添加引号和逗号
1.选中替换内容
2.按 ctrl + R
3.勾选上.* 输入正则命令
(.*?): (.*)
'$1': '$2',
如果当你请求网站, 被反爬的时候
一种最简单反反爬手段, 用headers请求头伪装成浏览器去发送请求
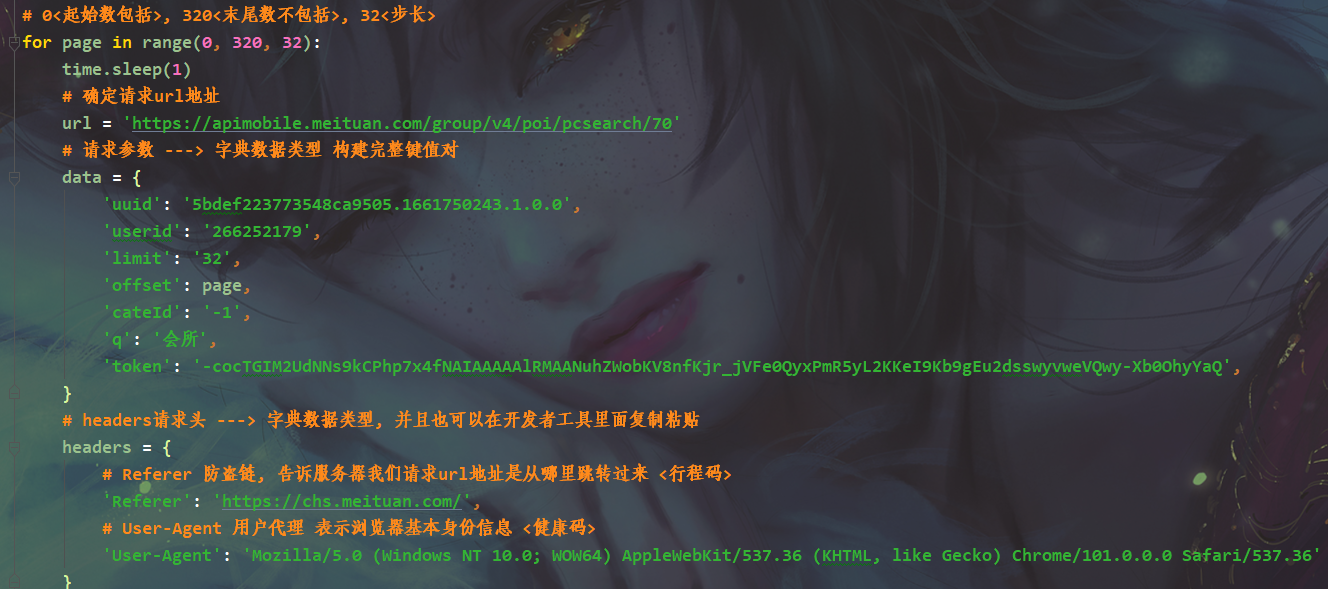
python学习交流Q群:770699889 ### 源码领取
# 发送请求
response = requests.get(url=url, params=data, headers=headers)
# <Response [403]>: 整体表示响应对象 403状态码 表示 没有访问权限
# <Response [200]> 200 状态码表示请求成功 print(response)
# 2. 获取数据, 获取服务器返回响应数据 ---> 开发者工具里面response --> response.json() 获取响应对象json字典数据 print(response.json())
# 3. 解析数据, 提取我们想要的数据内容 ---> 字典取值: 键值对取值 <根据冒号左边的内容[键], 提取冒号右边的内容[值]>
for index in response.json()['data']['searchResult']: # for循环遍历, 把列表里面元素一个一个提取出来
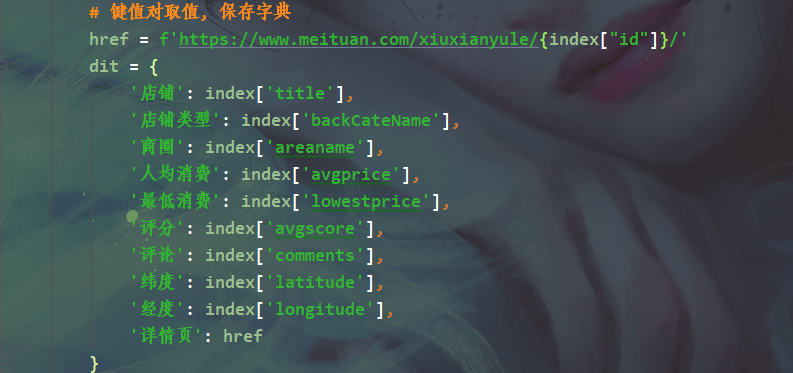
# 写入数据
csv_writer.writerow(dit)
print(dit)
可视化代码
最后
给大家推荐一些Python视频教程,希望对大家有所帮助:
对文章有问题的,或者有其他关于python的问题,可以在评论区留言或者私信我哦
觉得我分享的文章不错的话,可以关注一下我,或者给文章点赞(/≧▽≦)/
