- 一般假设训练集和测试集是独立同分布的,才能保证在训练集上表现良好的模型同样适用于测试集。当训练集和测试集不同分布时,就发生了dataset shift
- data shift类型:
- 协变量偏移(covariate shift):
- 协变量,隐变量可以理解为数据中的x及对应标签y
- 协变量的变化,比如模型应用场景中环境、位置的变化等(协变量,假设我们要拟合方程 y=wx,对于一个数据对(x,y):y为因变量,w为自变量,x为协变量。)
- 先验概率偏移:因变量的变化,比如根据月份预测销售额的模型,用平时月份训练的模型预测销售高峰月份的销售额。输入仍然为月份没有变化,但训练集和实际场景中的因变量完全不一样(一般月份和销售高峰月份的销售额本就不一样)。
- 概念偏移:自变量和因变量之间的关系发生了改变。
- 最常遇到的应该是Covariate Shift
- 协变量偏移(covariate shift):
- 当训练集和测试集差异较大时,训练往往是徒劳的。
- 如果数据发生了Covariate Shift的数据,那么理论上可以通过一个分类器以一个较高的准确率将原始数据和测试数据区分开(毕竟分布不同)。
- 检验步骤:
- 在训练集和测试集中随机采样(注意训练集和测试集的采样数量需要一致),然后将采样数据混合到一起形成新的训练数据,对数据增加一个新维度标签,取值取决于数据来源(比如训练集标识1,测试集标识0)。
- 得到了一个新的训练集. 将这个训练集的一部分数据(如80%)用来训练模型(KNN, SVM等), 剩下的数据(如20%)用来测试模型的性能。
- 计算模型在测试集上的AUC-ROC,如果指标较大(比如大于0.8),便可判定发生了Covariate Shift。(计算AUC-ROC,本质上就是为了衡量二元分类质量。还可以采用MCC(Matthews correlation coefficient)来衡量。一般MCC阈值可以设置为0.2。MCC>0.2说明出现了covariate shift的现象,反之亦然):
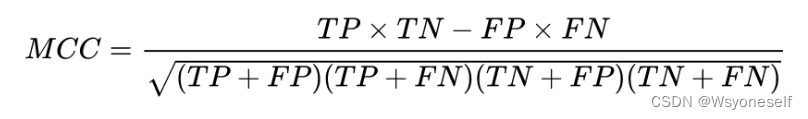 TP(True Positive):真实为1,预测为1 FN(False Negative):真实为1,预测为0 FP(False Positive):真实为0,预测为1 TN(True Negative):真实为0,预测为0
TP(True Positive):真实为1,预测为1 FN(False Negative):真实为1,预测为0 FP(False Positive):真实为0,预测为1 TN(True Negative):真实为0,预测为0
- 解决covariate shift的方法:
- 去除产生covariate shift现象的特征(Dropping of drifting features):
- 去除产生偏移的且不重要的特征。
- 具体:
- 逐个特征分类分析,找到产生偏移的特征
- 然后通过对比找出产生偏移的且不重要的特征去除掉
- 使用密度比的重要性加权(Importance weight using Density Ratio Estimation)。特征重要性评估方法:
- Mean decrease impurity 原理其实就是Tree-Model进行分类、回归的原理:特征越重要,对节点的纯度增加的效果越好。而纯度的判别标准有很多,如GINI、信息熵、信息熵增益。(sklearn中的树模型提供了feature_importances_采用的就是这种方法计算得到的)
- Mean decrease accuracy:看某个特征对模型精度的影响。把一个变量的取值变为随机数,随机森林预测准确性的降低程度。该值越大表示该变量的重要性越大。
- 去除产生covariate shift现象的特征(Dropping of drifting features):
- AUC-ROC:
- 当涉及分类问题时,可以使用AUC-ROC曲线进行评价
- ROC是概率曲线,AUC表示可分离的程度或测度,它告诉我们多少模型能够区分类别。AUC越高,模型在将0预测为0,将1预测为1时越好。
- AUC和ROC曲线中使用的术语
- TPR (真阳性率) / 召回 /敏感度 =TP/(TP+FN)
- 特异性=TN/(TN+FP)
- FPR=1-特异性=FP/(TN+FP)
- 出色的模型的AUC接近1,这意味着它具有良好的可分离性度量,较差的模型的AUC接近于0,这意味着它的可分离性度量最差。实际上,这意味着它正在回报结果。它预测0s但其实它是1s,1s但其实它是0s,当AUC为0.5时,表示模型没有类别分离能力。
data shift--学习笔记
猜你喜欢
转载自blog.csdn.net/weixin_45647721/article/details/128258398
今日推荐
周排行