一、Replica Sets 复制集
MongoDB 支持在多个机器中通过异步复制达到故障转移和实现冗余。多机器中同一时刻只有一台是用于写操作。正是由于这个情况,为 MongoDB 提供了数据一致性的保障。担当Primary 角色的机器能把读操作分发给 slave。
MongoDB 高可用可用分两种:
- Master-Slave 主从复制
只需要在某一个服务启动时加上–master参数,而另一个服务加上–slave与–source参数,即可实现同步。MongoDB 的最新版本已不再推荐此方案。
- Replica Sets 复制集
MongoDB 在 1.6 版本对开发了新功能 replica set,这比之前的 replication 功能要强大一些,增加了故障自动切换和自动修复成员节点,各个 DB 之间数据完全一致,大大降低了维护成功。auto shard 已经明确说明不支持 replication paris,建议使用 replica set,replica set 故障切换完全自动。
3-node Replica Sets:
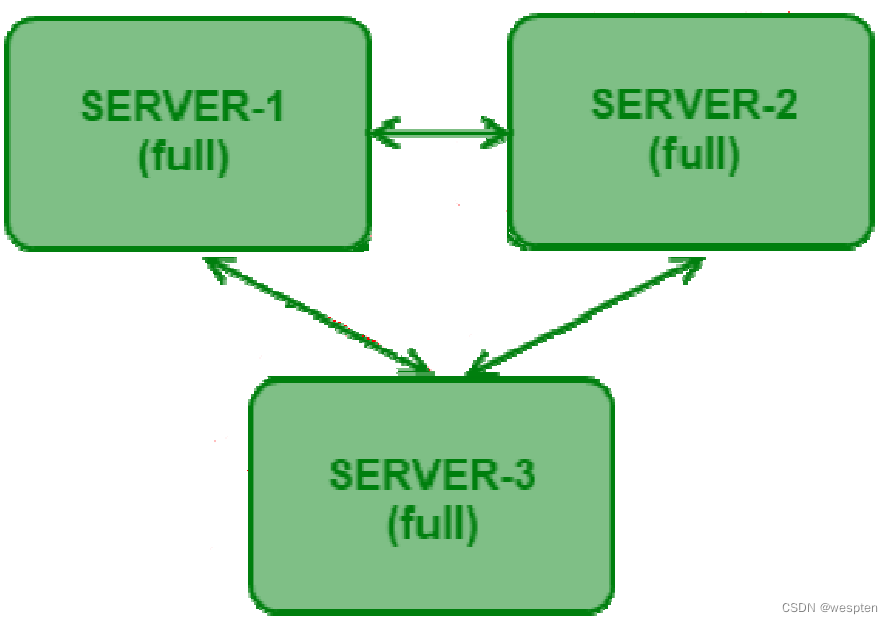
如果上图所示,Replica Sets 的结构非常类似一个集群。是的,你完全可以把它当成集群,因为它确实跟集群实现的作用是一样的,其中一个节点如果出现故障,其它节点马上会将业务接过来而无须停机操作。
1、部署 Replica Sets
创建数据文件存储路径:
[root@localhost ~]# mkdir -p /data/data/r0
[root@localhost ~]# mkdir -p /data/data/r1
[root@localhost ~]# mkdir -p /data/data/r2创建日志文件路径:
[root@localhost ~]# mkdir -p /data/log创建主从 key 文件,用于标识集群的私钥的完整路径,如果各个实例的 key file 内容不一致,程序将不能正常用。
[root@localhost ~]# mkdir -p /data/key
[root@localhost ~]# echo "this is rs1 super secret key" > /data/key/r0
[root@localhost ~]# echo "this is rs1 super secret key" > /data/key/r1
[root@localhost ~]# echo "this is rs1 super secret key" > /data/key/r2
[root@localhost ~]# chmod 600 /data/key/r*启动 3 个实例:
[root@localhost ~]# /Apps/mongo/bin/mongod --replSet rs1 --keyFile /data/key/r0 --fork --port
28010 --dbpath /data/data/r0 --logpath=/data/log/r0.log --logappend
all output going to: /data/log/r0.log
forked process: 6573
[root@localhost ~]# /Apps/mongo/bin/mongod --replSet rs1 --keyFile /data/key/r1 --fork --port
28011 --dbpath /data/data/r1 --logpath=/data/log/r1.log --logappend
all output going to: /data/log/r1.log
forked process: 6580
[root@localhost ~]# /Apps/mongo/bin/mongod --replSet rs1 --keyFile /data/key/r2 --fork --port
28012 --dbpath /data/data/r2 --logpath=/data/log/r2.log --logappend
all output going to: /data/log/r2.log
forked process: 6585
[root@localhost ~]#配置及初始化 Replica Sets:
[root@localhost bin]# /Apps/mongo/bin/mongo -port 28010
MongoDB shell version: 1.8.1
connecting to: 127.0.0.1:28010/test
> config_rs1 = {_id: 'rs1', members: [
... {_id: 0, host: 'localhost:28010', priority:1}, --成员 IP 及端口,priority=1 指 PRIMARY
... {_id: 1, host: 'localhost:28011'},
... {_id: 2, host: 'localhost:28012'}]
... }
{
"_id" : "rs1",
"members" : [
{
"_id" : 0,
"host" : "localhost:28010"
},
{
"_id" : 1,
"host" : "localhost:28011"
},
{
"_id" : 2,
"host" : "localhost:28012"
}
]
}
> rs.initiate(config_rs1); --初始化配置
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}查看复制集状态:
> rs.status()
{
"set" : "rs1",
"date" : ISODate("2018-05-31T09:49:57Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "localhost:28010",
"health" : 1, --1 表明正常; 0 表明异常
"state" : 1, -- 1 表明是 Primary; 2 表明是 Secondary;
"stateStr" : "PRIMARY", --表明此机器是主库
"optime" : {
"t" : 1338457763000,
"i" : 1
},
"optimeDate" : ISODate("2018-05-31T09:49:23Z"),
"self" : true
},
{
"_id" : 1,
"name" : "localhost:28011",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 23,
"optime" : {
"t" : 1338457763000,
"i" : 1
},
"optimeDate" : ISODate("2018-05-31T09:49:23Z"),
"lastHeartbeat" : ISODate("2018-05-31T09:49:56Z")
},
{
"_id" : 2,
"name" : "localhost:28012",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 23,
"optime" : {
"t" : 1338457763000,
"i" : 1
},
"optimeDate" : ISODate("2018-05-31T09:49:23Z"),
"lastHeartbeat" : ISODate("2018-05-31T09:49:56Z")
}
],
"ok" : 1
}
rs1:PRIMARY>还可以用 isMaster 查看 Replica Sets 状态:
rs1:PRIMARY> rs.isMaster()
{
"setName" : "rs1",
"ismaster" : true,
"secondary" : false,
"hosts" : [
"localhost:28010",
"localhost:28012",
"localhost:28011"
],
"maxBsonObjectSize" : 16777216,
"ok" : 1
}
rs1:PRIMARY>2、主从操作日志 oplog
MongoDB 的 Replica Set 架构是通过一个日志来存储写操作的,这个日志就叫做”oplog”。
oplog.rs 是一个固定长度的 capped collection,它存在于”local”数据库中,用于记录 Replica Sets 操作日志。在默认情况下,对于 64 位的 MongoDB,oplog 是比较大的,可以达到 5%的磁盘空间。oplog 的大小是可以通过 mongod 的参数”—oplogSize”来改变 oplog 的日志大小。
Oplog 内容样例:
rs1:PRIMARY> use local
switched to db local
rs1:PRIMARY> show collections
oplog.rs
system.replset
rs1:PRIMARY> db.oplog.rs.find()
{ "ts" : { "t" : 1338457763000, "i" : 1 }, "h" : NumberLong(0), "op" : "n", "ns" : "", "o" : { "msg" :"initiating set" } }
{ "ts" : { "t" : 1338459114000, "i" : 1 }, "h" : NumberLong("5493127699725549585"), "op" : "i", "ns" : "test.c1", "o" : { "_id" : ObjectId("4fc743e9aea289af709ac6b5"), "age" : 29, "name" : "Tony" } }
rs1:PRIMARY>字段说明:
ts:某个操作的时间戳。
op:操作类型,如下:
- i:insert
- d:delete
- u:update
ns:命名空间,也就是操作的 collection name 。
o:document 的内容。
查看 master 的 oplog 元数据信息:
rs1:PRIMARY> db.printReplicationInfo()
configured oplog size: 47.6837158203125MB
log length start to end: 1351secs (0.38hrs)
oplog first event time: Thu May 31 2018 17:49:23 GMT+0800 (CST)
oplog last event time: Thu May 31 2018 18:11:54 GMT+0800 (CST)
now: Thu May 31 2018 18:21:58 GMT+0800 (CST)
rs1:PRIMARY>字段说明:
- configured oplog size:配置的 oplog 文件大小;
- log length start to end:oplog 日志的启用时间段;
- oplog first event time:第一个事务日志的产生时间;
- oplog last event time:最后一个事务日志的产生时间;
- now:现在的时间;
查看 slave 的同步状态:
rs1:PRIMARY> db.printSlaveReplicationInfo()
source: localhost:28011
syncedTo: Thu May 31 2018 18:11:54 GMT+0800 (CST)
= 884secs ago (0.25hrs)
source: localhost:28012
syncedTo: Thu May 31 2018 18:11:54 GMT+0800 (CST)
= 884secs ago (0.25hrs)
rs1:PRIMARY>字段说明:
- source: 从库的 IP 及端口;
- syncedTo: 目前的同步情况,延迟了多久等信息;
3、主从配置信息
在 local 库中不仅有主从日志 oplog 集合,还有一个集合用于记录主从配置信息system.replset。
rs1:PRIMARY> use local
switched to db local
rs1:PRIMARY> show collections
oplog.rs
system.replset
rs1:PRIMARY> db.system.replset.find()
{ "_id" : "rs1", "version" : 1, "members" : [
{
"_id" : 0,
"host" : "localhost:28010"
},
{
"_id" : 1,
"host" : "localhost:28011"
},
{
"_id" : 2,
"host" : "localhost:28012"
}
] }
rs1:PRIMARY>从这个集合中可以看出,Replica Sets 的配置信息,也可以在任何一个成员实例上执行 rs.conf()来查看配置信息。
4、管理维护 Replica Sets
1. 读写分离
有一些第三方的工具,提供了一些可以让数据库进行读写分离的工具。我们现在是否有一个疑问,从库要是能进行查询就更好了,这样可以分担主库的大量的查询请求。
先向主库中插入一条测试数据:
[root@localhost bin]# ./mongo --port 28010
MongoDB shell version: 1.8.1
connecting to: 127.0.0.1:28010/test
rs1:PRIMARY> db.c1.insert({age:30})
db.c2rs1:PRIMARY> db.c1.find()
{ "_id" : ObjectId("4fc77f421137ea4fdb653b4a"), "age" : 30 }在从库进行查询等操作:
[root@localhost bin]# ./mongo --port 28011
MongoDB shell version: 1.8.1
connecting to: 127.0.0.1:28011/test
rs1:SECONDARY> show collections
Thu May 31 22:27:17 uncaught exception: error: { "$err" : "not master and slaveok=false", "code" : 13435 }
rs1:SECONDARY>当查询时报错了,说明是个从库且不能执行查询的操作。
让从库可以读,分担主库的压力:
rs1:SECONDARY> db.getMongo().setSlaveOk()
not master and slaveok=false
rs1:SECONDARY> show collections
c1
system.indexes
rs1:SECONDARY> db.c1.find()
{ "_id" : ObjectId("4fc77f421137ea4fdb653b4a"), "age" : 30 }
rs1:SECONDARY>看来我们要是执行 db.getMongo().setSlaveOk(), 我们就可查询从库了。
2. 故障转移
复制集比传统的 Master-Slave 有改进的地方就是他可以进行故障的自动转移,如果我们停掉复制集中的一个成员,那么剩余成员会再自动选举出一个成员,做为主库。
例如:我们将 28010 这个主库停掉,然后再看一下复制集的状态。
杀掉 28010 端口的 MongoDB:
[root@localhost bin]# ps aux|grep mongod
root 6706 1.6 6.9 463304 6168 Sl 21:49 0:26
/Apps/mongo/bin/mongod --replSet rs1 --keyFile /data/key/r0 --fork --port 28010
root 6733 0.4 6.7 430528 6044 ? Sl 21:50 0:06
/Apps/mongo/bin/mongod --replSet rs1 --keyFile /data/key/r1 --fork --port 28011
root 6747 0.4 4.7 431548 4260 ? Sl 21:50 0:06
/Apps/mongo/bin/mongod --replSet rs1 --keyFile /data/key/r2 --fork --port 28012
root 7019 0.0 0.7 5064 684 pts/2 S+ 22:16 0:00 grep mongod
[root@localhost bin]# kill -9 6706查看复制集状态:
[root@localhost bin]# ./mongo --port 28011
MongoDB shell version: 1.8.1
connecting to: 127.0.0.1:28011/test
rs1:SECONDARY> rs.status()
{
"set" : "rs1",
"date" : ISODate("2018-05-31T14:17:03Z"),
"myState" : 2,
"members" : [
{
"_id" : 0,
"name" : "localhost:28010",
"health" : 0,
"state" : 1,
"stateStr" : "(not reachable/healthy)",
"uptime" : 0,
"optime" : {
"t" : 1338472279000,
"i" : 1
},
"optimeDate" : ISODate("2018-05-31T13:51:19Z"),
"lastHeartbeat" : ISODate("2018-05-31T14:16:42Z"),
"errmsg" : "socket exception"
},
{
"_id" : 1,
"name" : "localhost:28011",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"optime" : {
"t" : 1338472279000,
"i" : 1
},
"optimeDate" : ISODate("2018-05-31T13:51:19Z"),
"self" : true
},
{
"_id" : 2,
"name" : "localhost:28018",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 1528,
"optime" : {
"t" : 1338472279000,
"i" : 1
},
"optimeDate" : ISODate("2018-05-31T13:51:19Z"),
"lastHeartbeat" : ISODate("2018-05-31T14:17:02Z")
}
],
"ok" : 1
}
rs1:SECONDARY>可以看到 28010 这个端口的 MongoDB 出现了异常,而系统自动选举了 28012 这个端口为主,所以这样的故障处理机制,能将系统的稳定性大大提高。
3. 增减节点
MongoDB Replica Sets 不仅提供高可用性的解决方案,它也同时提供负载均衡的解决方案,增减 Replica Sets 节点在实际应用中非常普遍,例如当应用的读压力暴增时,3 台节点的环境已不能满足需求,那么就需要增加一些节点将压力平均分配一下;当应用的压力小时,可以减少一些节点来减少硬件资源的成本;总之这是一个长期且持续的工作。
1)增加节点
官方给我们提了 2 个方案用于增加节点,一种是通过 oplog 来增加节点,一种是通过数据库快照(--fastsync)和 oplog 来增加节点,下面将分别介绍。
通过 oplog 增加节点:
配置并启动新节点 配置并启动新节点,启用启用 28013 这个端口给新的节点。
[root@localhost ~]# mkdir -p /data/data/r3
[root@localhost ~]# echo "this is rs1 super secret key" > /data/key/r3
[root@localhost ~]# chmod 600 /data/key/r3
[root@localhost ~]# /Apps/mongo/bin/mongod --replSet rs1 --keyFile /data/key/r3 --fork --port 28013 --dbpath /data/data/r3 --logpath=/data/log/r3.log --logappend
all output going to: /data/log/r3.log
forked process: 10553
[root@localhost ~]#添加此新节点到现有的 Replica Sets:
rs1:PRIMARY> rs.add("localhost:28013")
{ "ok" : 1 }查看查看 Replica Sets 我们可以清晰的看到内部是如何添加 28013 这个新节点的。
步骤一:进行初始化
rs1: PRIMARY > rs.status()
{
"set" : "rs1",
"date" : ISODate("2018-05-31T12:17:44Z"),
"myState" : 1,
"members" : [
……
{
"_id" : 3,
"name" : "localhost:28013",
"health" : 0,
"state" : 6,
"stateStr" : "(not reachable/healthy)",
"uptime" : 0,
"optime" : {
"t" : 0,
"i" : 0
},
"optimeDate" : ISODate("1970-01-01T00:00:00Z"),
"lastHeartbeat" : ISODate("2018-05-31T12:17:43Z"),
"errmsg" : "still initializing"
}
],
"ok" : 1
}步骤二:进行数据同步
rs1:PRIMARY> rs.status()
{
"set" : "rs1",
"date" : ISODate("2018-05-31T12:18:07Z"),
"myState" : 1,
"members" : [
……
{
"_id" : 3,
"name" : "localhost:28013",
"health" : 1,
"state" : 3,
"stateStr" : "RECOVERING",
"uptime" : 16,
"optime" : {
"t" : 0,
"i" : 0
},
"optimeDate" : ISODate("1970-01-01T00:00:00Z"),
"lastHeartbeat" : ISODate("2018-05-31T12:18:05Z"),
"errmsg" : "initial sync need a member to be primary or secondary to do our initial sync"
}
],
"ok" : 1
}步骤三:初始化同步完成
rs1:PRIMARY> rs.status()
{
"set" : "rs1",
"date" : ISODate("2018-05-31T12:18:08Z"),
"myState" : 1,
"members" : [
……
{
"_id" : 3,
"name" : "localhost:28013",
"health" : 1,
"state" : 3,
"stateStr" : "RECOVERING",
"uptime" : 17,
"optime" : {
"t" : 1338466661000,
"i" : 1
},
"optimeDate" : ISODate("2018-05-31T12:17:41Z"),
"lastHeartbeat" : ISODate("2018-05-31T12:18:07Z"),
"errmsg" : "initial sync done"
}
],
"ok" : 1
}步骤四:节点添加完成,状态正常
rs1:PRIMARY> rs.status()
{
"set" : "rs1",
"date" : ISODate("2018-05-31T12:18:10Z"),
"myState" : 1,
"members" : [
……
{
"_id" : 3,
"name" : "localhost:28013",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 19,
"optime" : {
"t" : 1338466661000,
"i" : 1
},
"optimeDate" : ISODate("2018-05-31T12:17:41Z"),
"lastHeartbeat" : ISODate("2018-05-31T12:18:09Z")
}
],
"ok" : 1
}验证数据已经同步过来了:
[root@localhost data]# /Apps/mongo/bin/mongo -port 28013
MongoDB shell version: 1.8.1
connecting to: 127.0.0.1:28013/test
rs1:SECONDARY> rs.slaveOk()
rs1:SECONDARY> db.c1.find()
{ "_id" : ObjectId("4fc760d2383ede1dce14ef86"), "age" : 10 }
rs1:SECONDARY>2)通过数据库快照(--fastsync) 和 oplog 增加节点
通过 oplog 直接进行增加节点操作简单且无需人工干预过多,但 oplog 是 capped collection,采用循环的方式进行日志处理,所以采用 oplog 的方式进行增加节点,有可能导致数据的不一致,因为日志中存储的信息有可能已经刷新过了。
不过没关系,我们可以通过数据库快照 (--fastsync)和 oplog 结合的方式来增加节点,这种方式的操作流程是,先取某一个复制集成员的物理文件来做为初始化数据,然后剩余的部分用 oplog 日志来追,最终达到数据一致性。
取某一个复制集成员的物理文件来做为初始化数据:
[root@localhost ~]# scp -r /data/data/r3 /data/data/r4
[root@localhost ~]# echo "this is rs1 super secret key" > /data/key/r4
[root@localhost ~]# chmod 600 /data/key/r4在取完物理文件后,在 c1 集中插入一条新文档,用于最后验证此更新也同步了。
rs1:PRIMARY> db.c1.find()
{ "_id" : ObjectId("4fc760d2383ede1dce14ef86"), "age" : 10 }
rs1:PRIMARY> db.c1.insert({age:20})
rs1:PRIMARY> db.c1.find()
{ "_id" : ObjectId("4fc760d2383ede1dce14ef86"), "age" : 10 }
{ "_id" : ObjectId("4fc7748f479e007bde6644ef"), "age" : 20 }
rs1:PRIMARY>启用启用 28014 这个端口给新的节点:
/Apps/mongo/bin/mongod --replSet rs1 --keyFile /data/key/r4 --fork --port 28014 --dbpath /data/data/r4 --logpath=/data/log/r4.log --logappend --fastsync添加添加 28014 节点:
rs1:PRIMARY> rs.add("localhost:28014")
{ "ok" : 1 }验证数据已经同步过来了:
[root@localhost data]# /Apps/mongo/bin/mongo -port 28014
MongoDB shell version: 1.8.1
connecting to: 127.0.0.1:28014/test
rs1:SECONDARY> rs.slaveOk()
rs1:SECONDARY> db.c1.find()
{ "_id" : ObjectId("4fc760d2383ede1dce14ef86"), "age" : 10 }
{ "_id" : ObjectId("4fc7748f479e007bde6644ef"), "age" : 20 }
rs1:SECONDARY>3)减少节点
下面将刚刚添加的两个新节点 28013 和 28014 从复制集中去除掉,只需执行 rs.remove 指令就可以了,具体如下:
rs1:PRIMARY> rs.remove("localhost:28014")
{ "ok" : 1 }
rs1:PRIMARY> rs.remove("localhost:28013")
{ "ok" : 1 }查看复制集状态,可以看到现在只有 28010、28011、28012 这三个成员,原来的28013和28014 都成功去除了。
rs1:PRIMARY> rs.status()
{
"set" : "rs1",
"date" : ISODate("2018-05-31T14:08:29Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "localhost:28010",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"optime" : {
"t" : 1338473273000,
"i" : 1
},
"optimeDate" : ISODate("2018-05-31T14:07:53Z"),
"self" : true
},
{
"_id" : 1,
"name" : "localhost:28011",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 34,
"optime" : {
"t" : 1338473273000,
"i" : 1
},
"optimeDate" : ISODate("2018-05-31T14:07:53Z"),
"lastHeartbeat" : ISODate("2018-05-31T14:08:29Z")
},
{
"_id" : 2,
"name" : "localhost:28012",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 34,
"optime" : {
"t" : 1338473273000,
"i" : 1
},
"optimeDate" : ISODate("2018-05-31T14:07:53Z"),
"lastHeartbeat" : ISODate("2018-05-31T14:08:29Z")
}
],
"ok" : 1
}
rs1:PRIMARY>二、Sharding 分片
这是一种将海量的数据水平扩展的数据库集群系统,数据分表存储在 sharding 的各个节点上,使用者通过简单的配置就可以很方便地构建一个分布式 MongoDB 集群。
MongoDB 的数据分块称为 chunk。每个 chunk 都是 Collection 中一段连续的数据记录,通常最大尺寸是 200MB,超出则生成新的数据块。
要构建一个 MongoDB Sharding Cluster,需要三种角色:
- Shard Server
即存储实际数据的分片,每个 Shard 可以是一个 mongod 实例,也可以是一组 mongod 实例构成的 Replica Set。为了实现每个 Shard 内部的 auto-failover,MongoDB 官方建议每个 Shard 为一组 Replica Set。
- Config Server
为了将一个特定的 collection 存储在多个 shard 中,需要为该 collection 指定一个 shard key,例如{age: 1} ,shard key 可以决定该条记录属于哪个 chunk。Config Servers 就是用来存储:所有 shard 节点的配置信息、每个 chunk 的 shard key 范围、chunk 在各 shard 的分布情况、该集群中所有 DB 和 collection 的 sharding 配置信息。
- Route Process
这是一个前端路由,客户端由此接入,然后询问 Config Servers 需要到哪个 Shard 上查询或保存记录,再连接相应的 Shard 进行操作,最后将结果返回给客户端。客户端只需要将原本发给 mongod 的查询或更新请求原封不动地发给 Routing Process,而不必关心所操作的记录存储在哪个 Shard 上。
下面我们在同一台物理机器上构建一个简单的 Sharding Cluster,架构图如下:
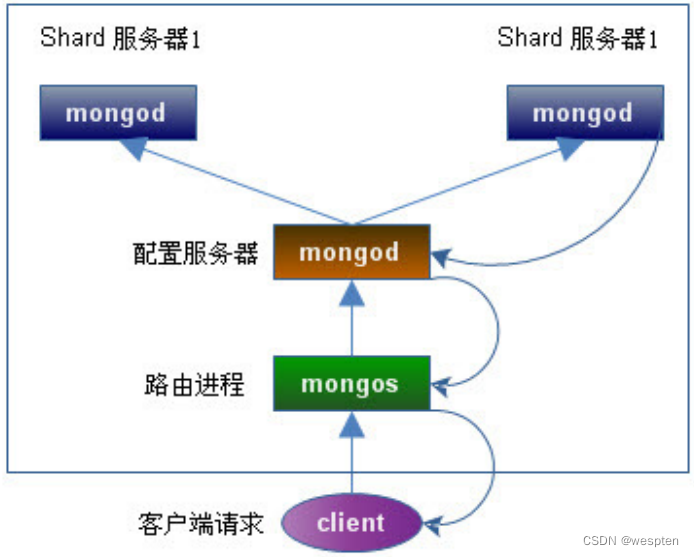
- Shard Server 1:20000;
- Shard Server 2:20001;
- Config Server :30000;
- Route Process:40000;
1、启动 Shard Server
mkdir -p /data/shard/s0 --创建数据目录
mkdir -p /data/shard/s1
mkdir -p /data/shard/log --创建日志目录
/Apps/mongo/bin/mongod --shardsvr --port 20000 --dbpath /data/shard/s0 --fork --logpath /data/shard/log/s0.log --directoryperdb --启动 Shard Server 实例 1
/Apps/mongo/bin/mongod --shardsvr --port 20001 --dbpath /data/shard/s1 --fork --logpath /data/shard/log/s1.log --directoryperdb --启动 Shard Server 实例 22、启动 Config Server
mkdir -p /data/shard/config --创建数据目录
/Apps/mongo/bin/mongod --configsvr --port 30000 --dbpath /data/shard/config --fork --logpath /data/shard/log/config.log --directoryperdb --启动 Config Server 实例3、启动 Route Process
/Apps/mongo/bin/mongos --port 40000 --configdb localhost:30000 --fork --logpath /data/shard/log/route.log --chunkSize 1 --启动 Route Server 实例mongos 启动参数中,chunkSize 这一项是用来指定 chunk 的大小的,单位是 MB,默认大小为 200MB,为了方便测试 Sharding 效果,我们把 chunkSize 指定为 1MB。
4、配置 Sharding
接下来,我们使用 MongoDB Shell 登录到 mongos,添加 Shard 节点。
[root@localhost ~]# /Apps/mongo/bin/mongo admin --port 40000 --此操作需要连接 admin 库
MongoDB shell version: 1.8.1
connecting to: 127.0.0.1:40000/admin
> db.runCommand({ addshard:"localhost:20000" }) --添加 Shard Server
{ "shardAdded" : "shard0000", "ok" : 1 }
> db.runCommand({ addshard:"localhost:20001" })
{ "shardAdded" : "shard0001", "ok" : 1 }
> db.runCommand({ enablesharding:"test" }) --设置分片存储的数据库
{ "ok" : 1 }
> db.runCommand({ shardcollection: "test.users", key: { _id:1 }}) --设置分片的集合名称,且必须指定 Shard Key,系统会自动创建索引
{ "collectionsharded" : "test.users", "ok" : 1 }
>5、验证 Sharding 正常工作
我们已经对 test.users 表进行了分片的设置,下面我们们插入一些数据看一下结果。
> use test
switched to db test
> for (var i = 1; i <= 500000; i++) db.users.insert({age:i, name:"wangwenlong", addr:"Beijing",
country:"China"})
> db.users.stats()
{
"sharded" : true, --说明此表已被 shard
"ns" : "test.users",
"count" : 500000,
"size" : 48000000,
"avgObjSize" : 96,
"storageSize" : 66655232,
"nindexes" : 1,
"nchunks" : 43,
"shards" : {
"shard0000" : { --在此分片实例上约有 24.5M 数据
"ns" : "test.users",
"count" : 254889,
"size" : 24469344,
"avgObjSize" : 96,
"storageSize" : 33327616,
"numExtents" : 8,
"nindexes" : 1,
"lastExtentSize" : 12079360,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 11468800,
"indexSizes" : {
"_id_" : 11468800
},
"ok" : 1
},
"shard0001" : { --在此分片实例上约有 23.5M 数据
"ns" : "test.users",
"count" : 245111,
"size" : 23530656,
"avgObjSize" : 96,
"storageSize" : 33327616,
"numExtents" : 8,
"nindexes" : 1,
"lastExtentSize" : 12079360,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 10649600,
"indexSizes" : {
"_id_" : 10649600
},
"ok" : 1
}
},
"ok" : 1
}
>我们看一下磁盘上的物理文件情况:
[root@localhost bin]# ll /data/shard/s0/test --此分片实例上有数据产生
总计 262420
-rw------- 1 root root 16777216 06-03 15:21 test.0
-rw------- 1 root root 33554432 06-03 15:21 test.1
-rw------- 1 root root 67108864 06-03 15:22 test.2
-rw------- 1 root root 134217728 06-03 15:24 test.3
-rw------- 1 root root 16777216 06-03 15:21 test.ns
[root@localhost bin]# ll /data/shard/s1/test --此分片实例上有数据产生
总计 262420
-rw------- 1 root root 16777216 06-03 15:21 test.0
-rw------- 1 root root 33554432 06-03 15:21 test.1
-rw------- 1 root root 67108864 06-03 15:22 test.2
-rw------- 1 root root 134217728 06-03 15:23 test.3
-rw------- 1 root root 16777216 06-03 15:21 test.ns
[root@localhost bin]#看上述结果,表明 test.users 集合已经被分片处理了,但是通过 mongos 路由,我们并感觉不到是数据存放在哪个 shard 的 chunk 上的,这就是 MongoDB 用户体验上的一个优势,即对用户是透明的。
6、管理维护 Sharding
列出所有的 Shard Server:
> db.runCommand({ listshards: 1 }) --列出所有的 Shard Server
{
"shards" : [
{
"_id" : "shard0000",
"host" : "localhost:20000"
},
{
"_id" : "shard0001",
"host" : "localhost:20001"
}
],
"ok" : 1
}查看 Sharding 信息:
> printShardingStatus() --查看 Sharding 信息
--- Sharding Status ---
sharding version: { "_id" : 1, "version" : 3 }
shards:
{ "_id" : "shard0000", "host" : "localhost:20000" }
{ "_id" : "shard0001", "host" : "localhost:20001" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "test", "partitioned" : true, "primary" : "shard0000" }
test.users chunks:shard0000 1
{ "_id" : { $minKey : 1 } } -->> { "_id" : { $maxKey : 1 } } on : shard0000 { "t" : 1000, "i" : 0 }
>判断是否是 Sharding:
> db.runCommand({ isdbgrid:1 })
{ "isdbgrid" : 1, "hostname" : "localhost", "ok" : 1 }
>对现有的表进行 Sharding ,刚才我们是对表 test.users 进行分片了,下面我们将对库中现有的未分片的表 test.users_2 进行分片处理。
表最初状态如下,可以看出他没有被分片过:
> db.users_2.stats()
{
"ns" : "test.users_2",
"sharded" : false,
"primary" : "shard0000",
"ns" : "test.users_2",
"count" : 500000,
"size" : 48000016,
"avgObjSize" : 96.000032,
"storageSize" : 61875968,
"numExtents" : 11,
"nindexes" : 1,
"lastExtentSize" : 15001856,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 20807680,
"indexSizes" : {
"_id_" : 20807680
},
"ok" : 1
}对其进行分片处理:
> use admin
switched to db admin
> db.runCommand({ shardcollection: "test.users_2", key: { _id:1 }})
{ "collectionsharded" : "test.users_2", "ok" : 1 }再次查看分片后的表的状态,可以看到它已经被我们分片了。
> use test
switched to db test
> db.users_2.stats()
{
"sharded" : true,
"ns" : "test.users_2",
"count" : 505462,
……
"shards" : {
"shard0000" : {
"ns" : "test.users_2",
……
"ok" : 1
},
"shard0001" : {
"ns" : "test.users_2",
……
"ok" : 1
}
},
"ok" : 1
}
>新增 Shard Server :
刚才我们演示的是新增分片表,接下来我们演示如何新增 Shard Server ,启动一个新 Shard Server 进程。
[root@localhost ~]# mkdir /data/shard/s2
[root@localhost ~]# /Apps/mongo/bin/mongod --shardsvr --port 20002 --dbpath /data/shard/s2 --fork --logpath /data/shard/log/s2.log --directoryperdb
all output going to: /data/shard/log/s2.log
forked process: 6772配置新 Shard Server:
[root@localhost ~]# /Apps/mongo/bin/mongo admin --port 40000
MongoDB shell version: 1.8.1
connecting to: 127.0.0.1:40000/admin
> db.runCommand({ addshard:"localhost:20002" })
{ "shardAdded" : "shard0002", "ok" : 1 }
> printShardingStatus()
--- Sharding Status ---
sharding version: { "_id" : 1, "version" : 3 }
shards:
{ "_id" : "shard0000", "host" : "localhost:20000" }
{ "_id" : "shard0001", "host" : "localhost:20001" }
{ "_id" : "shard0002", "host" : "localhost:20002" } --新增 Shard Server
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "test", "partitioned" : true, "primary" : "shard0000" }
test.users chunks:
shard0002 2
shard0000 21
shard0001 21
too many chunksn to print, use verbose if you want to force print
test.users_2 chunks:
shard0001 46
shard0002 1
shard0000 45
too many chunksn to print, use verbose if you want to force print查看分片表状态,以验证新 Shard Server:
> use test
switched to db test
> db.users_2.stats()
{
"sharded" : true,
"ns" : "test.users_2",
……
"shard0002" : { --新的 Shard Server 已有数据
"ns" : "test.users_2",
"count" : 21848,
"size" : 2097408,
"avgObjSize" : 96,
"storageSize" : 2793472,
"numExtents" : 5,
"nindexes" : 1,
"lastExtentSize" : 2097152,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 1277952,
"indexSizes" : {
"_id_" : 1277952
},
"ok" : 1
}
},
"ok" : 1
}
>我们可以发现,当我们新增 Shard Server 后数据自动分布到了新 Shard 上,这是由 MongoDB内部自已实现的。
有些时候有于硬件资源有限,所以我们不得不进行一些回收工作,下面我们就要将刚刚启用的 Shard Server 回收,系统首先会将在这个即将被移除的 Shard Server 上的数据先平均分配到其它的 Shard Server 上。
然后最终在将这个 Shard Server 踢下线, 我们需要不停的调用db.runCommand({"removeshard" : "localhost:20002"});来观察这个移除操作进行到哪里了:
> use admin
switched to db admin
> db.runCommand({"removeshard" : "localhost:20002"});
{
"msg" : "draining started successfully",
"state" : "started",
"shard" : "shard0002",
"ok" : 1
}
> db.runCommand({"removeshard" : "localhost:20002"});
{
"msg" : "draining ongoing",
"state" : "ongoing",
"remaining" : {
"chunks" : NumberLong(44),
"dbs" : NumberLong(0)
},
"ok" : 1
}
……
> db.runCommand({"removeshard" : "localhost:20002"});
{
"msg" : "draining ongoing",
"state" : "ongoing",
"remaining" : {
"chunks" : NumberLong(1),
"dbs" : NumberLong(0)
},
"ok" : 1
}
> db.runCommand({"removeshard" : "localhost:20002"});
{
"msg" : "removeshard completed successfully",
"state" : "completed",
"shard" : "shard0002",
"ok" : 1
}
> db.runCommand({"removeshard" : "localhost:20002"});
{
"assertion" : "can't find shard for: localhost:20002",
"assertionCode" : 13129,
"errmsg" : "db assertion failure",
"ok" : 0
}最终移除后,当我们再次调用 db.runCommand({"removeshard" : "localhost:20002"});的时候系统
会报错,已便通知我们不存在 20002 这个端口的 Shard Server 了,因为它已经被移除掉了。
接下来我们看一下表中的数据分布:
> use test
switched to db test
> db.users_2.stats()
{
"sharded" : true,
"ns" : "test.users_2",
"count" : 500000,
"size" : 48000000,
"avgObjSize" : 96,
"storageSize" : 95203584,
"nindexes" : 1,
"nchunks" : 92,
"shards" : {
"shard0000" : {
"ns" : "test.users_2",
"count" : 248749,
"size" : 23879904,
"avgObjSize" : 96,
"storageSize" : 61875968,
"numExtents" : 11,
"nindexes" : 1,
"lastExtentSize" : 15001856,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 13033472,
"indexSizes" : {
"_id_" : 13033472
},
"ok" : 1
},
"shard0001" : {
"ns" : "test.users_2",
"count" : 251251,
"size" : 24120096,
"avgObjSize" : 96,
"storageSize" : 33327616,
"numExtents" : 8,
"nindexes" : 1,
"lastExtentSize" : 12079360,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 10469376,
"indexSizes" : {
"_id_" : 10469376
},
"ok" : 1
}
},
"ok" : 1
}可以看出数据又被平均分配到了另外 2 台 Shard Server 上了,对业务没什么特别大的影响。
三、Replica Sets + Sharding
MongoDB Auto-Sharding 解决了海量存储和动态扩容的问题,但离实际生产环境所需的高可
靠、高可用还有些距离,所以有了” Replica Sets + Sharding”的解决方案:
- Shard:使用 Replica Sets,确保每个数据节点都具有备份、自动容错转移、自动恢复能力;
- Config:使用 3 个配置服务器,确保元数据完整性;
- Route:使用 3 个路由进程,实现负载平衡,提高客户端接入性能;
以下我们配置一个 Replica Sets + Sharding 的环境,架构图如下:
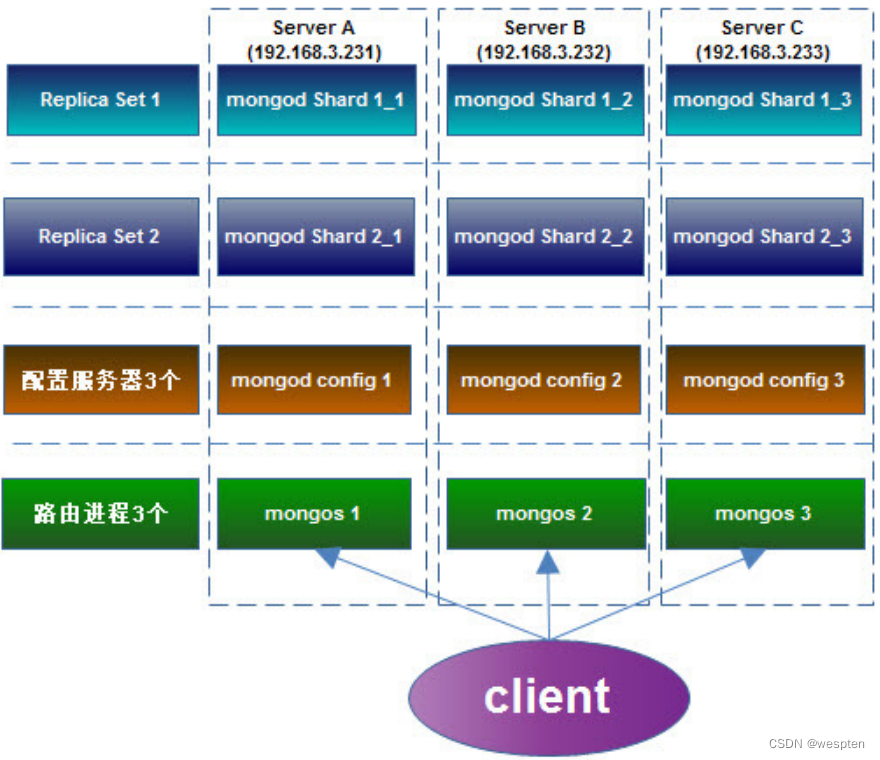
服务及开放的端口如下:
Server A(192.168.3.231 ):
- mongod shard1_1:27017;
- mongod shard2_1:27018;
- mongod config1:20000;
- mongs1:30000;
Server B (192.168.3.232):
- mongod shard1_2:27017;
- mongod shard2_2:27018;
- mongod config2:20000;
- mongs2:30000;
Server C (192.168.3.233):
- mongod shard1_3:27017;
- mongod shard2_3:27018;
- mongod config3:20000;
- mongs3:30000;
1、创建数据目录
在 Server A 上:
[root@localhost bin]# mkdir -p /data/shard1_1
[root@localhost bin]# mkdir -p /data/shard2_1
[root@localhost bin]# mkdir -p /data/config在 Server B 上:
[root@localhost bin]# mkdir -p /data/shard1_2
[root@localhost bin]# mkdir -p /data/shard2_2
[root@localhost bin]# mkdir -p /data/config在 Server C 上:
[root@localhost bin]# mkdir -p /data/shard1_3
[root@localhost bin]# mkdir -p /data/shard2_3
[root@localhost bin]# mkdir -p /data/config2、配置 Replica Sets
1. 配置 shard1 所用到的 Replica Sets
在 Server A 上:
[root@localhost bin]# /Apps/mongo/bin/mongod --shardsvr --replSet shard1 --port 27017 --dbpath /data/shard1_1 --logpath /data/shard1_1/shard1_1.log --logappend --fork
[root@localhost bin]# all output going to: /data/shard1_1/shard1_1.log
forked process: 18923在 Server B 上:
[root@localhost bin]# /Apps/mongo/bin/mongod --shardsvr --replSet shard1 --port 27017 --dbpath /data/shard1_2 --logpath /data/shard1_2/shard1_2.log --logappend --fork
forked process: 18859
[root@localhost bin]# all output going to: /data/shard1_2/shard1_2.log
[root@localhost bin]#在 Server C 上:
[root@localhost bin]# /Apps/mongo/bin/mongod --shardsvr --replSet shard1 --port 27017 --dbpath /data/shard1_3 --logpath /data/shard1_3/shard1_3.log --logappend --fork
all output going to: /data/shard1_3/shard1_3.log
forked process: 18768
[root@localhost bin]#用 mongo 连接其中一台机器的 27017 端口的 mongod,初始化 Replica Sets“shard1”,执行:
[root@localhost bin]# ./mongo --port 27017
MongoDB shell version: 1.8.1
connecting to: 127.0.0.1:27017/test
> config = {_id: 'shard1', members: [
... {_id: 0, host: '192.168.3.231:27017'},
... {_id: 1, host: '192.168.3.232:27017'},
... {_id: 2, host: '192.168.3.233:27017'}]
... }
……
> rs.initiate(config)
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}2. 配置 shard2 所用到的 Replica Sets
在 Server A 上:
[root@localhost bin]# /Apps/mongo/bin/mongod --shardsvr --replSet shard2 --port 27018 --dbpath /data/shard2_1 --logpath /data/shard2_1/shard2_1.log --logappend --fork
all output going to: /data/shard2_1/shard2_1.log
[root@localhost bin]# forked process: 18993
[root@localhost bin]#在 Server B 上:
[root@localhost bin]# /Apps/mongo/bin/mongod --shardsvr --replSet shard2 --port 27018 --dbpath /data/shard2_2 --logpath /data/shard2_2/shard2_2.log --logappend --fork
all output going to: /data/shard2_2/shard2_2.log
forked process: 18923
[root@localhost bin]#在 Server C 上:
[root@localhost bin]# /Apps/mongo/bin/mongod --shardsvr --replSet shard2 --port 27018 --dbpath /data/shard2_3 --logpath /data/shard2_3/shard2_3.log --logappend --fork
[root@localhost bin]# all output going to: /data/shard2_3/shard2_3.log
forked process: 18824
[root@localhost bin]#用 mongo 连接其中一台机器的 27018 端口的 mongod,初始化 Replica Sets “shard2”,执行:
[root@localhost bin]# ./mongo --port 27018
MongoDB shell version: 1.8.1
connecting to: 127.0.0.1:27018/test
> config = {_id: 'shard2', members: [
... {_id: 0, host: '192.168.3.231:27018'},
... {_id: 1, host: '192.168.3.232:27018'},
... {_id: 2, host: '192.168.3.233:27018'}]
... }
……
> rs.initiate(config)
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}3、配置 3 台 Config Server
在 Server A、B、C 上执行:
/Apps/mongo/bin/mongod --configsvr --dbpath /data/config --port 20000 --logpath /data/config/config.log --logappend --fork4、配置 3 台 Route Process
在 Server A、B、C 上执行:
/Apps/mongo/bin/mongos --configdb 192.168.3.231:20000,192.168.3.232:20000,192.168.3.233:20000 --port 30000 --chunkSize 1 --logpath /data/mongos.log --logappend --fork5、配置 Shard Cluster
连接到其中一台机器的端口 30000 的 mongos 进程,并切换到 admin 数据库做以下配置。
[root@localhost bin]# ./mongo --port 30000
MongoDB shell version: 1.8.1
connecting to: 127.0.0.1:30000/test
> use admin
switched to db admin
>db.runCommand({addshard:"shard1/192.168.3.231:27017,192.168.3.232:27017,192.168.3.233:27017"});
{ "shardAdded" : "shard1", "ok" : 1 }
>db.runCommand({addshard:"shard2/192.168.3.231:27018,192.168.3.232:27018,192.168.3.233:27018"});
{ "shardAdded" : "shard2", "ok" : 1 }
>激活数据库及集合的分片:
db.runCommand({ enablesharding:"test" })
db.runCommand({ shardcollection: "test.users", key: { _id:1 }})6、验证 Sharding 正常工作
连接到其中一台机器的端口 30000 的 mongos 进程,并切换到 test 数据库,以便添加测试数据。
use test
for(var i=1;i<=200000;i++) db.users.insert({id:i,addr_1:"Beijing",addr_2:"Shanghai"});
db.users.stats()
{
"sharded" : true,
"ns" : "test.users",
"count" : 200000,
"size" : 25600384,
"avgObjSize" : 128,
"storageSize" : 44509696,
"nindexes" : 2,
"nchunks" : 15,
"shards" : {
"shard0000" : {
……
},
"shard0001" : {
……
}
},
"ok" : 1
}可以看到Sharding搭建成功了,跟我们期望的结果一致。