KVM高级功能包括半虚拟化驱动、VT-d、SR-IOV、热插拔、动态迁移、KSM、AVX、cgroups、从物理机或虚拟机中迁移到KVM,以及QEMU监控器和qemu-kvm命令行的各种选项的使用。
1、半虚拟化驱动
1. virtio概述
KVM是必须使用硬件虚拟化辅助技术(如Intel VT-x、AMD-V)的Hypervisor,在CPU运行效率方面有硬件支持,其效率是比较高的;在有Intel EPT特性支持的平台上,内存虚拟化的效率也较高。QEMU/KVM提供了全虚拟化环境,可以让客户机不经过任何修改就能运行在KVM环境中。不过,KVM在I/O虚拟化方面,传统的方式是使用QEMU纯软件的方式来模拟I/O设备(如网卡、磁盘、显卡等),其效率并不非常高。在KVM中,可以在客户机中使用半虚拟化驱动(Paravirtualized Drivers,PV Drivers)来提高客户机的性能(特别是I/O性能)。目前,KVM中实现半虚拟化驱动的方式是采用virtio这个Linux上的设备驱动标准框架。
QEMU模拟I/O设备的基本原理和优缺点:
QEMU以纯软件方式模拟现实世界中的I/O设备的基本过程模型。
QEMU模拟I/O设备:

在使用QEMU模拟I/O的情况下,当客户机中的设备驱动程序(Device Driver)发起I/O操作请求之时,KVM模块(Module)中的I/O操作捕获代码会拦截这次I/O请求,然后在经过处理后将本次I/O请求的信息存放到I/O共享页(sharing page),并通知用户控件的QEMU程序。
QEMU模拟程序获得I/O操作的具体信息之后,交由硬件模拟代码(Emulation Code)来模拟出本次的I/O操作,完成之后,将结果放回到I/O共享页,并通知KVM模块中的I/O操作捕获代码。最后,由KVM模块中的捕获代码读取I/O共享页中的操作结果,并把结果返回到客户机中。当然,在这个操作过程中客户机作为一个QEMU进程在等待I/O时也可能被阻塞。
另外,当客户机通过DMA(Direct Memory Access)访问大块I/O之时,QEMU模拟程序将不会把操作结果放到I/O共享页中,而是通过内存映射的方式将结果直接写到客户机的内存中去,然后通过KVM模块告诉客户机DMA操作已经完成。
QEMU模拟I/O设备的方式,其优点是可以通过软件模拟出各种各样的硬件设备,包括一些不常用的或很老很经典的设备,而且该方式不用修改客户机操作系统,就可以实现模拟设备在客户机中正常工作。在KVM客户机中使用这种方式,对于解决手上没有足够设备的软件开发及调试有非常大的好处。而QEMU模拟I/O设备的方式的缺点是,每次I/O操作的路径比较长,有较多的VMEntry、VMExit发生,需要多次上下文切换(context switch),也需要多次数据复制,所以它的性能较差。
2. virtio的基本原理和优缺点
virtio最初由澳大利亚的一个天才级程序员Rusty Russell编写,是一个在Hypervisor之上的抽象API接口,让客户机知道自己运行在虚拟化环境中,进而根据virtio标准与Hypervisor协作,从而在客户机中达到更好的性能(特别是I/O性能)。目前,有不少虚拟机都采用了virtio半虚拟化驱动来提高性能,如KVM和Lguest。
在QEMU/KVM中,virtio的基本结构框架:

其中前端驱动(frondend,如virtio-blk、virtio-net等)是在客户机中存在的驱动程序模块,而后端处理程序(backend)是在QEMU中实现的[2]。在前后端驱动之间,还定义了两层来支持客户机与QEMU之间的通信。其中,"virtio"这一层是虚拟队列接口,它在概念上将前端驱动程序附加到后端处理程序。一个前端驱动程序可以使用0个或多个队列,具体数量取决于需求。
例如,virtio-net网络驱动程序使用两个虚拟队列(一个用于接收,另一个用于发送),而virtio-blk块驱动程序仅使用一个虚拟队列。虚拟队列实际上被实现为跨越客户机操作系统和Hypervisor的衔接点,但该衔接点可以通过任意方式实现,前提是客户机操作系统和virtio后端程序都遵循一定的标准,以相互匹配的方式实现它。而virtio-ring实现了环形缓冲区(ring buffer),用于保存前端驱动和后端处理程序执行的信息,并且该环形缓冲区可以一次性保存前端驱动的多次I/O请求,并且交由后端驱动去批量处理,最后实际调用宿主机中设备驱动实现物理上的I/O操作,这样做就可以根据约定实现批量处理而不是客户机中每次I/O请求都需要处理一次,从而提高客户机与Hypervisor信息交换的效率。
virtio半虚拟化驱动的方式,可以获得很好的I/O性能,其性能几乎可以达到和native(即非虚拟化环境中的原生系统)差不多的I/O性能。所以,在使用KVM之时,如果宿主机内核和客户机都支持virtio,一般推荐使用virtio达到更好的性能。
当然,virtio也是有缺点的,它需要客户机必须安装特定的virtio驱动使其知道是运行在虚拟化环境中,并且按照virtio的规定格式进行数据传输,不过客户机中可能有一些老的Linux系统不支持virtio,还有一些主流的Windows系统需要安装特定的驱动才支持virtio。不过,较新的一些Linux发行版(如RHEL 6.3、Fedora 17等)默认都将virtio相关驱动编译为模块,可直接作为客户机使用,而主流Windows系统都有对应的virtio驱动程序可供下载使用。
3. 安装virtio驱动
virtio已经是一个比较稳定成熟的技术了,宿主机中比较新的KVM中都支持它,Linux 2.6.24及以上的Linux内核版本都是支持virtio的。由于virtio的后端处理程序是在位于用户空间的QEMU中实现的,所以,在宿主机中只需要比较新的内核即可,不需要特别地编译与virtio相关的驱动。
客户机需要有特定的virtio驱动的支持,以便客户机处理I/O操作请求时调用virtio驱动而不是其原生的设备驱动程序。下面分别介绍Linux和Windows中virtio相关驱动的安装和使用。
1)Linux中的virtio驱动
在一些流行的Linux发行版(如RHEL 6.x、Ubuntu、Fedora)中,其自带的内核一般都将virtio相关的驱动编译为模块,可以根据需要动态地加载相应的模块。其中,对于RHEL系列来说,RHEL 4.8及以上版本、RHEL 5.3及以上版本、RHEL 6.x的所有版本都默认自动安装有virtio相关的半虚拟化驱动。可以查看内核的配置文件来确定某发行版是否支持virtio驱动。
以RHEL 6.3中的内核配置文件为例,其中与virtio相关的配置有如下几项:
CONFIG_VIRTIO=m
CONFIG_VIRTIO_RING=m
CONFIG_VIRTIO_PCI=m
CONFIG_VIRTIO_BALLOON=m
CONFIG_VIRTIO_BLK=m
CONFIG_SCSI_VIRTIO=m
CONFIG_VIRTIO_NET=m
CONFIG_VIRTIO_CONSOLE=m
CONFIG_HW_RANDOM_VIRTIO=m
CONFIG_NET_9P_VIRTIO=m
根据这样的配置选项,在编译安装好内核之后,在内核模块中就可以看到virtio.ko、virtio_ring.ko、virtio_net.ko这样的驱动,如下所示:
[root@kvm-guest ~]# find /lib/modules/2.6.32-279.el6.x86_64/ -name "virtio*.ko"
/lib/modules/2.6.32-279.e16.x86_64/kernel/drivers/net/virtio_net,ko
/lib/modules/2.6.32-279.e16.x86_64/kernel/drivers/virtio/virtio_pci.ko
/lib/modules/2.6.32-279.e16.x86_64/kernel/drivers/virtio/virtio.ko
/lib/modules/2.6.32-279.el6.x86_64/kernel/drivers/virtio/virtio_balloon.ko /lib/modules/2.6.32-279.el6.x86_64/kernel/drivers/virtio/virtio_ring.ko
/lib/modules/2.6.32-279.e16.x86_64/kernel/drivers/scsi/virtio_scsi.ko
/lib/modules/2.6.32-279.el6.x86_64/kernel/drivers/char/hw_random/virtio-rng.ko /lib/modules/2.6.32-279.el6.x86_64/kernel/drivers/char/virtio_console.ko
在一个正在使用virtio_net网络前端驱动的KVM客户机中,已自动加载的virtio相关模块如下:
[root@kvm-guest ~]# 1smod | grep virtio
virtio_net 16760 0
virtio_pci 7113 0
virtio_ring 7729 2 virtio_net,virtio_pc
virtio 4890 2 virtio_net,virtio_pc其中virtio、virtio_ring、virtio_pci等驱动程序提供了对virtio API的基本支持,是使用任何virtio前端驱动都必需使用的,而且它们的加载还有一定的顺序,应该按照virtio、virtio_ring、virtio_pci的顺序加载,而virtio_net、virtio_blk这样的驱动可以根据实际需要进行选择性的编译和加载。
2)Windows中的virtio驱动
由于Windows这样的操作系统不是开源操作系统,而且微软也并没有在其操作系统中默认提供virtio相关的驱动,因此需要另外安装特定的驱动程序以便支持virtio。可以通过Linux系统发行版自带软件包安装(如果有该软件包),也可以到网上下载Windows virtio驱动自行安装。
(1)以RHEL 6.3为例,它有一个名为virtio-win的RPM软件包,能为如下版本的Windows提供virtio相关的驱动:
- Windows XP(仅32位版本);
- Windows Server 2003(32位和64位版本);
- Windows Server 2008(32位和64位版本);
- Windows 7(32位和64位版本);
可以通过yum来安装virtio-win这个软件包,代码如下:
[root@jay-linux kvm_demo]# yum install virto-win
[root@jay-linux kvm_demo]# rpm -q virtio-win
virtio-win-1.5.2-1.el6.noarch
[root@jay-linux kvm_demo]# 1s /usr/share/virtio-win/
drivers virtio-win-1.5.2.iso virtio-win-1.5.2.vfd virtio-win.iso
对于RHEL注册用户,也可以到如下的链接下载:
https://rhn.redhat.com/rhn/software/packages/details/Overview.do?pid=602010
在virtio-win软件包安装完成后,可以看到/usr/share/virtio-win/目录下有一个virtio-win.iso文件,其中包含了所需要的驱动程序。可以将virtio-win.iso文件通过网络共享到Windows客户机中使用,或者通过qemu-kvm命令行的"-cdrom"参数将virtio-win.iso文件作为客户机的光驱。下面以Windows 7客户机为例来介绍在Windows中如何安装virtio驱动。
启动Windows 7客户机,将virio-win.iso作为客户机的光驱,命令行操作如下:
[root@jay-linux kvm_demo]# qemu-system-x86_64 win7.img -smp 2 -m 2048 -cdrom /usr/share/virtio-win/virtio-win.iso -vnc :0 -usbdevice tablet
在Windows 7客户机中打开CD-ROM(virtio-win.iso)可看到其中的目录,如图所示,其中有4个子目录分别表示Windows的4个驱动:Balloon目录是内存气球相关的virtio_balloon驱动,NetKVM目录是网络相关的virtio_net驱动,vioserial目录是控制台相关的virtio_serial驱动,viostor是磁盘块设备存储相关的virtio_scsi驱动。
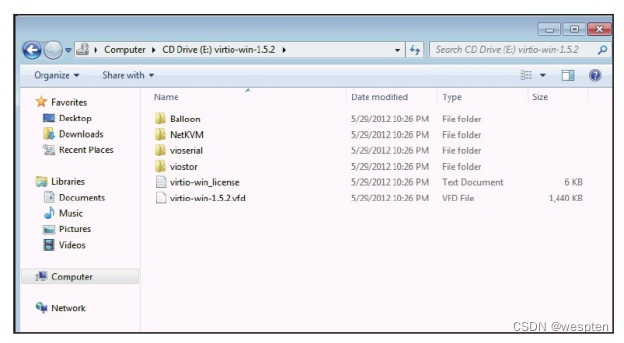
以NetKVM目录为例,其中又包含了各个Windows版本各自的驱动,分别对应Windows XP、Windows 2003、Windows 7、Windows 2008等4个不同的Windows版本。每个Windows版本的目录下又包含"amd64"和"x86"两个版本,分别对应Intel/AMD的x86-64架构和x86-32架构,即64位的Windows系统应该选择amd64中的驱动,而32位Windows选择x86中的驱动。
在安装驱动前,在Windows(此处示例为英文版)客户机中通过"Computer"右键单击选择"Manage",在选中的Device Manager(设备管理器)中查看磁盘和网卡驱动。
如图所示,磁盘驱动是QEMU模拟的IDE硬盘,网卡是QEMU模拟的rtl8139系列网卡。

(2)在启动客户机时,向其分配一些virtio相关的设备,在Windows中根据设备安装驱动。
这一步安装的驱动包括virtio_balloon、virtio_net、virtio_serial这3个驱动,而virtio_scsi是磁盘相关的驱动,相关内容将在步骤3)中单独介绍。
qemu-kvm命令行中有如下的参数分别对应这3个驱动:
- "-balloon virtio"提供了virtio_balloon相关的设备;
- "-net nic,model=virtio"提供了virtio_net相关的设备;
- "-device virtio-serial-pci"提供了virtio_serial相关的设备;
启动客户机的命令行如下:
[root@jay-linux kvm_demo]# qemu-system-x86_64 win7.img -smp 2 -m
2048 -cdrom /usr/share/virtio-win/virtio-win.iso -vne:0 -usbdevice tablet -net nic,model=virtio -net tap -balloon virtio -device virtio-serial-pci
在启动后,在Windows客户机的"Device Manager"的"Other devices"项目中会有3个设备没有找到合适的驱动,如图所示,而且网卡处于不可用状态,这是因为使用virtio模型的网卡,没有驱动可用。

在这3个设备中,"Ethernet Controller"是使用virtio的网卡、"PCI Device"是内存balloon的virtio设备、"PCI Simple Communication Controller"是使用virtio的控制台设备。
在未安装virtio驱动的设备上,右键单击,选择"update driver software"更新驱动程序,然后选择"Browser my computer for driver software",选择在virtio-win.iso中相对应的virtio驱动目录,单击"Next"按钮,就安装对应的virtio驱动了。安装或更新完驱动后,系统会提示"Windows has successfully updated your driver software"。
以virtio的网卡为例,选择驱动程序的操作,如图所示。

在依次安装完这3个virtio驱动程序后,在"Device Manager"中的"Network adapter"项目中有了"Red Hat VirtIO Ethernet Adapter"设备,在"System devices"项目中增加了"VirtIO Balloon Driver"和"VirtIO-Serial Driver"这两个设备。网卡驱动安装好后即可生效,网络连接已经正常,而内存的balloon驱动和控制台驱动需要在重启客户机Windows系统后才能生效。
(3)安装磁盘virtio驱动程序,其过程与之前的驱动安装略有不同,因为系统中没有virtio_scsi驱动就不能识别硬盘,系统就不能启动,所以可以通过两种方式来安装。其中一种是,在系统启动前从带有virtio驱动的可启动的光盘或软盘将驱动安装好,然后再重启系统从virtio的硬盘进系统。另一种方法是,使用一个非启动硬盘,将其指定为使用virtio驱动,在Windows客户机系统中会发现该非启动硬盘没有合适的驱动,像前面安装其他驱动那样安装即可,然后重启系统将启动硬盘的镜像文件也设置为virtio方式即可使用virtio驱动启动客户机系统。
这里选择第二种方式来演示磁盘virtio驱动的安装,代码如下,其目的是建立一个伪镜像文件,然后将其作为Windows客户机的一个非启动硬盘。
[root@jay-linux kvm_demo]# qemu-img create -f qcow2 fake.qcow2 10M
Formatting 'fake.qcow2',fmt=qcow2 size=10485760 encryption=off cluster size=65536
[root@jay-linux kvm demo]# qemu-system-x86_64 win7.img -drive file=fake.qcow2,if=virtio -smp 2 -m 2048 -cdrom
/usr/share/virtio-win/virtio-win.iso-vnc :0-usbdevice taSle@vespten
在Windows客户机的"Device Manager"中会看到"Other devices"项目下有一个没有驱动程序的"SCSI Controller",如图所示。

同前面步骤2)中更新驱动程序一样,选择virtio-win中的viostor目录下的对应驱动进行安装即可。安装完成后,用如下命令重启系统,使用virtio驱动的磁盘镜像。
[root@jay-linux kym demo]# qemu-system-x86_64 -drive file=win7.img,if=virtio -smp 2 -m 2048 -vnc :0 -usbdevice tablete
启动系统后,在Windows客户机的"Device Manager"的"Disk drives"项目下可看到"Red Hat VirtIO SCSI Disk Device","Storage Controller"项目下有"Red Hat VirtIO SCSI Controller"即表明正在使用virtio_scsi驱动。
(4)在安装好了这4个virtio驱动后,用下面的命令行重新启动这个客户机,使这4个virtio驱动全部处于使用状态。
[root@jay-linux kym_demo]# qemu-system-x86_64 -drive file=win7.img,if=virtio -smp 2 -m 2048 -net nic,model=virtio -net tap -balloon virtio -device virtio-serial-pci -vnc :0 -usbdevice tablet
可以在"Device Manager"中查看已经安装并使用的virtio驱动。
除了RHEL提供的virtio-win ISO文件之外,在github中也有最新KVM中Windows客户机的virtio驱动源代码仓库。访问https://github.com/YanVugenfirer/kvm-guest-drivers-windows,可以通过下载、编译得到所需要的驱动。当然编译过程可能比较复杂,可进行阅读代码仓库中的一些编译说明进行学习。
在64位的Windows系统中,从Windows Vista开始(如Windows 7、Windows 2008等),所安装的驱动就要求有数字签名。如果使用的发行版并没有提供Windows virtio驱动的二进制文件,或者没有对应的数字签名,则可以选择从Fedora项目中下载二进制ISO文件,它们都进行了数字签名,并且通过了在Windows系统上的测试。从http://alt.fedoraproject.org/pub/alt/virtio-win/latest/images/bin/可以下载Fedora项目提供的Windows virtio驱动,之后的安装过程与前面讲述的过程完全一致。
4. 使用virtio_balloon
1)ballooning简介
通常来说,要改变客户机占用的宿主机内存,要先关闭客户机,修改启动时的内存配置,然后重启客户机才能实现。而内存的ballooning(气球)技术可以在客户机运行时动态地调整它所占用的宿主机内存资源,而不需要关闭客户机。
ballooning技术形象地在客户机占用的内存中引入气球(balloon)的概念。气球中的内存是可以供宿主机使用的(但不能被客户机访问或使用),所以,当宿主机内存紧张,空余内存不多时,可以请求客户机回收利用已分配给客户机的部分内存,客户机就会释放其空闲的内存,此时若客户机空闲内存不足,可能还会回收部分使用中的内存,可能会将部分内存换出到客户机的交换分区(swap)中,从而使内存气球充气膨胀,进而使宿主机回收气球中的内存用于其他进程(或其他客户机)。反之,当客户机中内存不足时,也可以让客户机的内存气球压缩,释放出内存气球中的部分内存,让客户机使用更多的内存。
目前很多虚拟机,如KVM、Xen、VMware等,都对ballooning技术提供支持。
关于内存balloon的概念,其示意图如图所示:

2)KVM中ballooning的原理及优劣势
KVM中ballooning的工作过程主要有如下几步:
- Hypervisor(即KVM)发送请求到客户机操作系统让其归还一定数量的内存给Hypervisor。
- 客户机操作系统中的virtio_balloon驱动接收到Hypervisor的请求。
- virtio_balloon驱动使客户机的内存气球膨胀,气球中的内存就不能被客户机访问。如果此时客户机中内存剩余量不多(如某应用程序绑定/申请了大量的内存),并且不能让内存气球膨胀到足够大以满足Hypervisor的请求,那么virtio_balloon驱动也会尽可能多地提供内存使气球膨胀,尽量去满足Hypervisor的请求中的内存数量(即使不一定能完全满足)。
- 客户机操作系统归还气球中的内存给Hypervisor。
- Hypervisor可以将从气球中得来的内存分配到任何需要的地方。
- 即使从气球中得到的内存没有处于使用中,Hypervisor也可以将内存返还到客户机中,这个过程为:Hypervisor发请求到客户机的virtio_balloon驱动;这个请求使客户机操作系统压缩内存气球;在气球中的内存被释放出来,重新由客户机访问和使用。
ballooning在节约内存和灵活分配内存方面有明显的优势,其好处有如下3点。
- 因为ballooning能够被控制和监控,所以能够潜在地节约大量的内存。它不同于内存页共享技术(KSM是内核自发完成的,不可控),客户机系统的内存只有在通过命令行调整balloon时才会随之改变,所以能够监控系统内存并验证ballooning引起的变化。
- ballooning对内存的调节很灵活,既可以精细地请求少量内存,又可以粗犷地请求大量的内存。
- Hypervisor使用ballooning让客户机归还部分内存,从而缓解其内存压力。而且从气球中回收的内存也不要求一定要被分配给另外某个进程(或另外的客户机)。
从另一方面来说,KVM中ballooning的使用不方便、不完善的地方也是存在的,其缺点如下。
- ballooning需要客户机操作系统加载virtio_balloon驱动,然而并非每个客户机系统都有该驱动(如Windows需要自己安装该驱动)。
- 如果有大量内存需要从客户机系统中回收,那么ballooning可能会降低客户机操作系统运行的性能。一方面,内存的减少可能会让客户机中作为磁盘数据缓存的内存被放到气球中,从而使客户机中的磁盘I/O访问增加;另一方面,如果处理机制不够好,也可能让客户机中正在运行的进程由于内存不足而执行失败。
- 目前没有比较方便的、自动化的机制来管理ballooning,一般都采用在QEMU monitor中执行balloon命令来实现ballooning。没有对客户机的有效监控,没有自动化的ballooning机制,这可能会使在生产环境中实现大规模自动化部署不是很方便。
- 内存的动态增加或减少,可能会使内存被过度碎片化,从而降低内存使用时的性能。另外,内存的变化会影响到客户机内核对内存使用的优化,比如,内核起初根据目前状态对内存的分配采取了某个策略,而后突然由于balloon的原因使可用内存减少了很多,这时起初的内存策略就可能不是太优化了。
3)KVM中ballooning使用示例
KVM中的ballooning是通过宿主机和客户机协同实现的,在宿主机中应该使用Linux 2.6.27及以上版本的Linux内核(包括KVM模块),使用较新的qemu-kvm(如0.13版本以上),在客户机中也使用Linux 2.6.27及以上版本的Linux内核且将"CONFIG_VIRTIO_BALLOON"配置为模块或编译到内核。在很多Linux发行版中都已经配置有"CONFIG_VIRTIO_BALLOON=m",所以用较新的Linux作为客户机系统,一般不需要额外配置virtio_balloon驱动,使用默认内核配置即可。
在QEMU命令行中可用"-balloon virtio"参数来分配balloon设备给客户机使其调用virtio_balloon驱动来工作,而默认值为没有分配balloon设备(与"-balloon none"效果相同)。
-balloon virtio[,addr=addr]#使用virtio balloon设备,addr可配置客户机中该设备的PCI地址
在QEMU monitor中,有两个命令用于查看和设置客户机内存的大小。
#查看客户机内存占用量(balloon信息)
(qemu) info balloon
#设置客户机内存占用量为numMB CSDN@wespten
(qemu) balloon num
下面介绍在KVM中使用ballooning的操作步骤。
(1)QEMU启动客户机时分配balloon设备,命令行如下。也可以使用较新的"-device"的统一参数来分配balloon设备,如"-device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x4"。
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -smp 2 -m 2048 -balloon virtio
(2)在启动后的客户机中查看balloon设备及内存使用情况,命令行如下:
[root@kvm-guest ~]# 1spci
00:00.0 Host bridge:Intel Corporation 440FX - 82441FX PMC [Natoma] (rev 02)00:01.0 ISA bridge:Intel Corporation 82371SB PIIX3 ISA [Natoma/Triton II]00:01.1 IDE interface:Intel Corporation 82371SB PIIX3 IDE [Natoma/Triton II 00:01.3 Bridge:Intel Corporation 82371AB/EB/MB PIIX4 ACPI(rev 03)00:02.0 VGA compatible controller: Cirrus Logic GD 5446 00:03.0 Ethernet controller: Realtek Semiconductor Co., Ltd. RTL-8139/8139C/8139C+(rev 20)
00:04.0 Unclassified device [00ff]:Red Hat,Inc Virtio memory balloon
[root@kvm-guest~]# grep VIRTIO_BALLOON /boot/config-2.6.32-279.el6.x86_64 CONFIG_VIRTIO_BALLOON=m
[root@kvm-guest~]# lsmod | grep virtio
virtio_balloon 4856 0
virtio_pci 7113 0
virtio_ring 7729 2 virtio_balloon,virtio_pci
virtio 4890 2 virtio_balloon,virtio_pci
[root@kvm-guest~]# 1spci -s 00:04.0 -v
00:04.0 Unclassified device [00ff]: Red Hat, Inc Virtio memory balloon
Subsystem:Red Hat,Inc Device 0005
Physical Slot: 4
Flags: fast devsel,IRQ 10 I/O ports at cl00 [size=32]
Kernel driver in use: virtio-pci
Kernel modules:virtio_pci
[root@kvm-guest ~]# free -m
根据上面输出可知,客户机中已经加载virtio_balloon模块,有一个名为"Red Hat,Inc Virtio memory balloon"的PCI设备,它使用了virtio_pci驱动。如果是Windows客户机,则可以在“设备管理器”看到使用virtio balloon设备。
(3)在QEMU monitor中查看和改变客户机占用的内存,命令如下:
(qemu) info balloon
balloon: actual=2048
(qemu) balloon 512
(qemu) info balloon
balloon: actual=512
如果没有使用balloon设备,则在monitor中使用"info balloon"命令查看会得到"Device 'balloon' has not been activated"的警告提示。而"balloon 512"命令将客户机内存设置为512MB。
(4)设置了客户机内存为512 MB后,再到客户机中检查,检查命令:
[root@kvm-guest ~]# free -m对于Windows客户机(如Windows 7),当balloon使其可用内存从2GB降低到512MB时,在其“任务管理器”中看到的内存总数依然是2GB,但是看到它的内存已使用量会增大1536MB(例如从原来使用量350MB变为1886MB),这里占用的1536MB内存正是balloon设备占用的,Windows客户机系统的其他程序已不能使用这1536 MB内存,这时宿主机系统可以再次分配这里的1536MB内存用于其他用途。
另外,值得注意的是,当通过"balloon"命令使客户机内存增加时,其最大值不能超过QEMU命令行启动时设置的内存,例如在命令行中将内存设置为2048MB,如果在Monitor中执行"balloon 4096",则设置的4096MB内存不会生效,该值将会被设置为启动命令行中的最大值(即2048MB)。
4)通过ballooning过载使用内存
在“内存过载使用”中提到,内存过载使用主要有三种方式:swapping、ballooning和page sharing。在多个客户机运行时动态地调整其内存容量,ballooning是一种让内存过载使用得非常有效的机制,使用ballooning可以根据宿主机中对内存的需求,通过"balloon"命令调整客户机内存占用量,从而实现内存的过载使用。
在实际环境中,客户机系统的资源的平均使用率一般并不高,通常是一段时间负载较重,一段时间负载较轻。可以在一个物理宿主机上启动多个客户机,通过ballooning的支持,在某些客户机负载较轻时减少其内存使用,将内存分配给此时负载较重的客户机。
例如,在一个物理内存为8GB的宿主机上,可以在一开始就分别启动6个内存为2GB的客户机(A、B、C、D、E、F等6个),根据平时对各个客户机中资源使用情况的统计可知,在当前一段时间内,A、B、C的负载很轻,就可以通过ballooning降低其内存为512 MB,而D、E、F的内存保持2 GB不变。
内存分配的简单计算为:
512MB×3+2GB×3+512MB(用于宿主机中其他进程)=8GB而在某些其他时间段,当A、B、C等客户机负载较大时,也可以增加它们的内存量(同时减少D、E、F的内存量)。这样就在8GB物理内存上运行了看似需要大于12GB内存才能运行的6个2GB内存的客户机,从而较好地实现了内存的过载使用。
如果客户机中有virtio_balloon驱动,则使用ballooning来实现内存过载使用是非常方便的。而前面提到“在QEMU monitor中使用balloon命令改变内存的操作执行起来不方便”的问题,如果使用libvirt工具来使用KVM,则对ballooning的操作会比较方便,在libvirt工具的"virsh"管理程序中就有"setmem"这个命令来动态更改客户机的可用内存容量,该方式的完整命令为:
virsh setmem<domain-id or domain-name><Amount of memory in KB>5. 使用virtio_net
1)配置和使用virtio_net
在选择KVM中的网络设备时,一般来说优先选择半虚拟化的网络设备而不是纯软件模拟的设备。使用virtio_net半虚拟化驱动,可以提高网络吞吐量(thoughput)和降低网络延迟(latency),从而让客户机中网络达到几乎和非虚拟化系统中使用原生网卡的网络差不多的性能。
要使用virtio_net,需要两部分的支持,宿主机中的QEMU工具的支持和客户机中virtio_net驱动的支持。较新的qemu-kvm都对virtio网卡设备提供支持,且较新的流行Linux发行版中都已经将virtio_net作为模块编译到系统之中了,所以使用起来还是比较方便的。
可以通过如下步骤来使用virtio_net。
(1)检查QEMU是否支持virtio类型的网卡。
[root@jay-linux kvm_demo]# qemu-system-x86_64-net nic,model=?
qemu: Supported NIC models: ne2k pci,i82551,i82557b,i82559er,rtl8139,e1000,pcnet,virtio
从输出信息中支持网卡类型可知,当前qemu-kvm支持virtio网卡模型。
(2)启动客户机时,指定分配virtio网卡设备。
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -smp 2 -m 1024 -net nic,model=virtio,macaddr=00:16:3e:22:22 -net tap
VNC server running on '::1:5900'
(3)在客户机中查看virtio网卡的使用情况。
[root]kvm-guest ~]# grep VIRTIO_/boot/config-2.6.32-279.e16.x86_64
CONFIG_VIRTIO_BLK=m
CONFIG_VIRTIO_NET=m
CONFIG_VIRTIO_CONSOLE=m
CONFIG_VIRTIO_RING=m
CONFIG_VIRTIO_PCI=m
CONFIG_VIRTIO_BALLOON=m
[root@kvm-guest ~]# 1spci
00:00.0 Host bridge:Intel Corporation 440FX - 82441FX PMC [Natoma] (rev 02)
00:01.0 ISA bridge:Intel Corporation 82371SB PIIX3 ISA [Natoma/Triton II]
00:01.1 IDE interface:Intel Corporation 82371SB PIIX3 IDE
[root@kvm-guest ~]# 1spci -vv -s 00:03.0
00:03.0 Ethernet controller:Red Hat,Inc Virtio network device
Subsystem:Red Hat,Inc Device 0001
Physical Slot: 3
Control:I/O+ Mem+ BusMaster- SpecCycle- MemWINV-VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+
[root@kvm-guest~]#lsmod | grep virtio
virtio_net 16760 0
virtio_pci 7113 0
virtio_ring 7729 2 virtio_net,virtio_pci
virtio 4890 2 virtio_net,virtio_pci
[root@kvm-guest~]# ethtool -i eth1
driver: virtio_net
version:
firmware-version:
bus-info: virtio0
[root@kvm-guest ~]# ifconfig eth1
[root@kvm-guest ~]# ping 192.168.199.98 -c 1
根据上面的输出信息可知,网络接口eth1使用了virtio_net驱动,并且当前网络连接正常工作。如果启动Windows客户机使用virtio类型的网卡,则在Windows客户机的“设备管理器”中看到的一个名为"Red Hat VirtIO Ethernet Adapter"的设备即是客户机中的网卡。
2)宿主机中TSO和GSO的设置
据Redhat文档[3]的介绍,如果在使用半虚拟化网络驱动(即virtio_net)时得到的依然是较低的性能,可以检查宿主机系统中对GSO和TSO[4]特性的设置。关闭GSO和TSO可以使半虚拟化网络驱动的性能更加优化。
通过如下命令可以检查宿主机中GSO和TSO的设置,其中eth0是建立bridge供客户机使用的网络接口。
[root@jay-linux ~]# brctl show
bridge name bridge id STP enabled interfaces
br0 8000.001320fb4fa8 yes eth0
tap0
[root@jay-linux ~]# ethtool -k eth0
Offload parameters for eth0:
rx-checksumming: on
tx-checksumming: on
scatter-gather: on
#这个就是Tso的状态
tcp-segmentation-offload: on
udp-fragmentation-offload: off
#这是Gso的状态
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off
通过如下命令可以关闭宿主机的GSO和TSO功能:
[root@jay-linux ~]# ethtool -K eth0 gso off
[root@jay-linux ~]# ethtool -K eth0 tso off
[root@jay-linux ~]## ethtool -k eth0
Offload parameters for eth0:
rx-checksumming: on
tx-checksumming: on
scatter-gather: on
tcp-segmentation-offload: off
udp-fragmentation-offload: off
generic-segmentation-offload: off
generic-receive-offload: on
large-receive-offload: off3)用vhost_net后端驱动
前面提到virtio在宿主机中的后端处理程序(backend)一般是由用户空间的QEMU提供的,然而,如果对于网络IO请求的后端处理能够在在内核空间来完成,则效率会更高,会提高网络吞吐量和减少网络延迟。在比较新的内核中有一个叫做"vhost-net"的驱动模块,它作为一个内核级别的后端处理程序,将virtio-net的后端处理任务放到内核空间中执行,从而提高效率。
在“使用网桥模式”介绍网络配置时,提到有几个选项和virtio相关的,这里也介绍一下。
![]()
vnet_hdr=on|off,设置是否打开TAP设备的"IFF_VNET_HDR"标识:"vnet_hdr=off"表示关闭这个标识,而"vnet_hdr=on"表示强制开启这个标识,如果没有这个标识的支持,则会触发错误。IFF_VNET_HDR是tun/tap的一个标识,打开这个标识则允许发送或接受大数据包时仅做部分的校验和检查。打开这个标识,还可以提高virtio_net驱动的吞吐量。
vhost=on|off,设置是否开启vhost-net这个内核空间的后端处理驱动,它只对使用MIS-X[5]中断方式的virtio客户机有效。
vhostforce=on|off,设置是否强制使用vhost作为非MSI-X中断方式的virtio客户机的后端处理程序。
vhostfs=h,设置去连接一个已经打开的vhost网络设备。
用如下命令行启动一个客户机,就可以在客户机中使用virtio-net作为前端驱动程序,而在后端处理程序时使用vhost-net(当然需要当前宿主机内核支持vhost-net模块)。
[root@jay-linux kvm demo]# qemu-system-x86_64 rhel6u3.img -smp 2 -m 1024 -net nic,model=virtio,macaddr=00:16:3e:22:22 -net tap,vnet_hdr=on,vhost=on
VNC server running on '::1:5900'
启动客户机后,检查客户机网络,应该是可以正常连接的。
而在宿主机中可以查看vhost-net的使用情况,如下:
[root@jay-linux kym_demo]# grep VHOST /boot/config-3.5.0
CONFIG_VHOST_NET=m
[root@jay-linux kvm_demo]# 1smod | grep vhost
vhost_net 17161 1
tun 13220 3 vhost_net
[root@jay-linux kvm demo]# rmmod vhost-net
ERROR: Module vhost net is in use
可见,宿主机中内核将vhost-net编译为module,此时vhost-net模块处于使用中状态(试图删除它时会报告“在使用中”的错误)。
一般来说,使用vhost-net作为后端处理驱动可以提高网络的性能。不过,对于一些使用vhost-net作为后端的网络负载类型,可能使其性能不升反降。特别是从宿主机到其客户机之间的UDP流量,如果客户机处理接受数据的速度比宿主机发送的速度要慢,这时就容易出现性能下降。
在这种情况下,使用vhost-net将会使UDP socket的接受缓冲区更快地溢出,从而导致更多的数据包丢失。因此在这种情况下不使用vhost-net,让传输速度稍微慢一点,反而会提高整体的性能。
使用qemu-kvm命令行时,加上"vhost=off"(或不添加任何vhost选项)就会不使用vhost-net作为后端驱动,而在使用libvirt时,如果要选QEMU作为后端驱动,则需要对客户机的XML配置文件中的网络配置部分进行如下的配置,指定后端驱动的名称为"qemu"(而不是"vhost")。
<interface type="network">
...
<model type="virtio"/>
<driver name="qemu"/>
...
</interface>
6. 使用virtio_blk
virtio_blk驱动使用virtio API为客户机提供了一个高效访问块设备I/O的方法。在QEMU/KVM中对块设备使用virtio,需要在两方面进行配置:客户机中的前端驱动模块virtio_blk和宿主机中的QEMU提供后端处理程序。目前比较流行的Linux发行版都将virtio_blk编译为内核模块,可以作为客户机直接使用virtio_blk,而Windows中的virtio驱动的安装方法已介绍。并且较新的qemu-kvm都是支持virtio block设备的后端处理程序的。
启动一个使用virtio_blk作为磁盘驱动的客户机,其qemu-kvm命令行如下:
[root@jay-linux kym demo]# qemu-system-x86 64-smp 2 -m 1024 -net nic-net tap-drive file=rhel6u3.img,if=virtio
VNC server running on ':1:5900'
在客户机中,查看virtio_blk生效的情况如下所示:
[root@kvm-guest ~]# grep VIRTIO_BLK /boot/config-2.6.32-279.e16.x86_64
CONFIG_VIRTIO_BLK=m
[root@kvm-guest~]# lsmod | grep virtio
virtio_blk 7292 3
virtio_pci 7113 0
virtio_ring 7729 2 virtio_blk,virtio_pci
virtio 4890 2 virtio_blk,virtio_pci
[root@kvm-guest~]# lspci | grep -i block
00:04.0 SCSI storage controller:Red Hat,Inc Virtio block device
[root@kvm-guest~]# lspci -vv -s 00:04.0
00:04.0 SCSI storage controller:Red Hat,Inc Virtio block device
Subsystem: Red Hat, Inc Device 0002
Physical Slot: 4
Control: I/O+ Mem+ BusMaster- SpecCycle- MemWINV-VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast>TAbort-<TAbort-<MAbort->SERR-<PERR-INTx-
Interrupt: pin A routed to IRQ 11
可知客户机中已经加载了virtio_blk等驱动,QEMU提供的virtio块设备使用virtio_blk驱动(以上查询结果中显示为virtio_pci,因为它是任意virtio的PCI设备的一个基础的、必备的驱动)。使用virtio_blk驱动的磁盘显示为"/dev/vda",这不同于IDE硬盘的"/dev/hda"或SATA硬盘的"/dev/sda"这样的显示标识。
而"/dev/vd*"这样的磁盘设备名称可能会导致从前分配在磁盘上的swap分区失效,因为有些客户机系统中记录文件系统信息的"/etc/fstab"文件中有类似如下的对swap分区的写法。
/dev/sda2 swap swap default 0 0
或:
/dev/hda2 swap swap default 0 0
原因就是"/dev/vda2"这样的磁盘分区名称未被正确识别,解决这个问题的方法就很简单了,只需要修改它为如下形式并保存"/etc/fstab"文件,然后重启客户机系统即可。
/dev/vda2 swap swap default 0 0
如果启动的是已安装virtio驱动的Windows客户机,那么在客户机的“设备管理器”中的“存储控制器”中看到的是正在使用"Red Hat VirtIO SCSI Controller"设备作为磁盘。
7. kvm_clock配置
在保持时间的准确性方面,虚拟化环境似乎天生就面临几个难题和挑战。由于在虚拟机中的中断并非真正的中断,而是通过宿主机向客户机注入的虚拟中断,因此中断并不总是能同时且立即传递给一个客户机的所有虚拟CPU(vCPU)。在需要向客户机注入中断时,宿主机的物理CPU可能正在执行其他客户机的vCPU或在运行其他一些非QEMU进程,这就是说中断需要的时间精确性有可能得不到保障。
而在现实使用场景中,如果客户机中时间不准确,就可能导致一些程序和一些用户场景在正确性上遇到麻烦。这类程序或场景,一般是Web应用程序或基于网络的应用场景,如Web应用中的Cookie或Session有效期计算、虚拟机的动态迁移(Live Migration),以及其他一些依赖于时间戳的应用等。
而QEMU/KVM通过提供一个半虚拟化的时钟,即kvm_clock,为客户机提供精确的System time和Wall time,从而避免客户机中时间不准确的问题。kvm_clock使用较新的硬件(如Intel SandyBridge平台)提供的支持,如不变的时钟计数器(Constant Time Stamp Counter)。Constant TSC的计数的频率,即使当前CPU核心改变频率(如使用了一些省电策略),也能保持恒定不变。CPU有一个不变的constant TSC频率是将TSC作为KVM客户机时钟的必要条件。
物理CPU对constant TSC的支持,可以查看宿主机中CPU信息的标识,有"constant_tsc"的即是支持constant TSC的,如下所示(信息来源于运行在SandyBridge硬件平台的系统)。
[root@jay-linux kvm_demo]# grep constant_tsc /proc/cpuinfo
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr
pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht
tm pbe syscall nx pdpelgb rdtscp lm constant_tsc arch_perfmon pebs
bts rep good nopl xtopology nonstop tsc aperfmperf pni pclmulqdq
dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid
dca sse4_1 sse4_2 ×2apic popcnt tsc_deadline_timer aes xsave avx
lahf_lm ida arat epb xsaveopt pln pts dtherm tpr_shadow vnmi flexpriority ept vpid
一般来说,在较新的Linux发行版的内核中都已经将kvm_clock相关的支持编译进去了,可以查看如下的内核配置选项:
[root@kvm-guest ~]# grep PARAVIRT_GUEST /boot/config-2.6.32-279.el6.x86_64
CONFIG_PARAVIRT_GUEST=y
[root@kvm-guest ~]# grep KVM_CLOCK /boot/config-2.6.32-279.el6.x86_64
CONFIG_KVM_CLOCK=y
而在用QEMU命令行启动客户机时,已经会默认让其使用kvm_clock作为时钟来源。用最普通的命令启动一个Linux客户机,然后查看客户机中与时钟相关的信息如下,可知使用了kvm_clock和硬件的TSC支持。
[root@kvm-guest~]# dmesg | grep -i clock
kvm-clock: Using msrs 4b564d01 and 4b564d00
kvm-clock:cpu 0,msr 0:lclf601,boot clock
kvm-clock:cpu 0,msr 0:2216601,primary cpu clock hpet clockevent registered
kvm-clock: cpu 1, msr 0:2316601, secondary cpu clock Switching to clocksource kvm-clock
rtc_cmos 00:01: setting system clock to 2012-09-17 03:27:16 UTC(1347852436)Refined TSC clocksource calibration:3292.523 MHz.另外,Intel的一些较新的硬件还向时钟提供了更高级的硬件支持,即TSC Deadline Timer,在前面查看一个SandyBridge平台的CPU信息时已经有"tsc_deadline_timer"的标识了。TSC deadline模式,不是使用CPU外部总线的频率去定时减少计数器的值,而是软件设置了一个"deadline"(最后期限)的阀值,当CPU的时间戳计数器的值大于或等于这个"deadline"时,本地的高级可编程中断控制器(Local APIC)就产生一个时钟中断请求(IRQ)。正是由于这个特点(CPU的时钟计数器运行于CPU的内部频率而不依赖于外部总线频率),TSC Deadline Timer可以提供更精确的时间,也可以更容易避免或处理竞态条件(race condition[6])。
KVM模块对TSC Deadline Timer的支持开始于Linux 3.6版本,QEMU对TSC Deadline Timer的支持开始于qeum-kvm 0.12版本。而且在启动客户机时,在qemu-kvm命令行使用"-cpu host"参数才能将这个特性传递给客户机,使其可以使用TSC Deadline Timer。
2、设备直接分配(VT-d)
1. VT-d 概述
在QEMU/KVM中,客户机可以使用的设备大致可分为如下3种类型。
- Emulated device:QEMU纯软件模拟的设备。
- Virtio device:实现VIRTIO API的半虚拟化驱动的设备。
- PCI device assignment:PCI设备直接分配。
其中,前两种类型都已经进行了比较详细的介绍,这里再简单回顾一下它们的优缺点和适用场景。
模拟I/O设备方式的优点是对硬件平台依赖性较低、可以方便模拟一些流行的和较老久的设备、不需要宿主机和客户机的额外支持,因此兼容性高;而其缺点是I/O路径较长、VM-Exit次数很多,因此性能较差。一般适用于对I/O性能要求不高的场景,或者模拟一些老旧遗留(legacy)设备(如RTL8139的网卡)。
virtio半虚拟化设备方式的优点是实现了VIRTIO API,减少了VM-Exit次数,提高了客户机I/O执行效率,比普通模拟I/O的效率高很多;而其缺点是需要客户机中与virtio相关驱动的支持(较老的系统默认没有自带这些驱动,Windows系统中需要额外安装virtio驱动),因此兼容性较差,而且I/O频繁时的CPU使用率较高。
而第三种方式叫做PCI设备直接分配(Device Assignment,或PCI pass-through),它允许将宿主机中的物理PCI(或PCI-E)设备直接分配给客户机完全使用,正是要介绍的重点内容。较新的x86架构的主要硬件平台(包括服务器级、桌面级)都已经支持设备直接分配,其中Intel定义的I/O虚拟化技术规范为"Intel(R)Virtualization Technology for Directed I/O"(VT-d),而AMD的I/O虚拟化技术规范为"AMD-Vi"(也叫做IOMMU)。以在KVM中使用Intel VT-d技术为例来进行介绍(当然AMD IOMMU也是类似的)。
KVM虚拟机支持将宿主机中的PCI、PCI-E设备附加到虚拟化的客户机中,从而让客户机以独占方式访问这个PCI(或PCI-E)设备。通过硬件支持的VT-d技术将设备分配给客户机后,在客户机看来,设备是物理上连接在其PCI(或PCI-E)总线上的,客户机对该设备的I/O交互操作和实际的物理设备操作完全一样,不需要(或者很少需要)Hypervisor(即KVM)的参与。
在KVM中通过VT-d技术使用一个PCI-E网卡的系统架构示例,如图所示。

运行在支持VT-d平台上的QEMU/KVM,可以分配网卡、磁盘控制器、USB控制器、VGA显卡等供客户机直接使用。而为了设备分配的安全性,还需要中断重映射(interrupt remapping)的支持。尽管在使用QEMU命令行进行设备分配时并不直接检查中断重映射功能是否开启,但是在通过一些工具使用KVM时(如RHEL 6.3中的libvirt)默认需要有中断重映射的功能支持,才能使用VT-d分配设备供客户机使用。
设备直接分配让客户机完全占有PCI设备,这样在执行I/O操作时大量地减少甚至避免了VM-Exit陷入到Hypervisor中,极大地提高了I/O性能,可以达到几乎和Native系统中一样的性能。尽管virtio的性能也不错,但VT-d克服了其兼容性不够好和CPU使用率较高的问题。不过,VT-d也有自己的缺点,一台服务器主板上的空间比较有限,允许添加的PCI和PCI-E设备是有限的,如果一台宿主机上有较多数量的客户机,则很难向每台客户机都独立分配VT-d的设备。
另外,大量使用VT-d独立分配设备给客户机,让硬件设备数量增加,这会增加硬件投资成本。为了避免这两个缺点,可以考虑采用如下两个方案:一是,在一台物理宿主机上,仅少数的对I/O(如网络)性能要求较高的客户机使用VT-d直接分配设备(如网卡),而其余的客户机使用纯模拟(emulated)或使用virtio以达到多个客户机共享同一个设备的目的;二是,对于网络I/O的解决方法,可以选择SR-IOV使一个网卡产生多个独立的虚拟网卡,将每个虚拟网卡分别分配给一个客户机使用,这也正是后面“SR-IOV技术”要介绍的内容。另外,设备直接分配还有一个缺点是,对于使用VT-d直接分配了设备的客户机,其动态迁移功能将会受限,不过也可以用热插拔或libvirt工具等方式来缓解这个问题。
2. VT-d环境配置
在KVM中使用VT-d技术进行设备直接分配,需要以下几方面的环境配置。
1)硬件支持和BIOS设置
目前市面上有很多的x86硬件平台都有VT-d的支持,以使用过的几台机器为例,其中服务器平台Intel Xeon X5670、Xeon E5-2680、Xeon E5-4650等和SandyBridge、IvyBridge平台的桌面台式机都是支持VT-d的。
除了在硬件平台层面对VT-d支持之外,还需要在BIOS将VT-d功能打开使其处于"Enabled"状态。由于各个BIOS和硬件厂商的标识的区别,VT-d在BIOS中设置选项的名称也有所不同。BIOS中VT-d设置选项一般为"Intel(R)VT for Directed I/O"或"Intel VT-d"等,已经演示了在BIOS设置中打开VT-d选项的情况。
2)宿主机内核的配置
在宿主机系统中,内核也需要配置相应的选项。在较新的Linux内核(如3.5、3.6)中,应该配置如下几个VT-d相关的配置选项。在Fedora 17(使用3.3或3.4内核)中,也都已经使这些类似的配置处于打开状态,不需要重新编译内核即可直接使用VT-d。
CONFIG_IOMMU_SUPPORT=y
# CONFIG_AMD_IOMMU is not set #AMD平台的IOMMU设置
CONFIG_DMAR_TABLE=y
#Intel平台的VT-d设置
CONFIG_INTEL_IOMMU=y
CONFIG_INTEL_IOMMU_DEFAULT_ON=y
CONFIG_INTEL_IOMMU_FLOPPY_WA=y
CONFIG_IRQ_REMAP=y
而在较旧的Linux内核(3.0及以下,如2.6.32)中,应该配置如下几个VT-d相关的配置选项。与上面较新内核的配置有些不同,大约在发布Linux内核3.0、3.1时进行了一次比较大的选项调整,名称和代码结构有所改变。以RHEL 6.3的内核为例,默认就已经配置了如下的选项,其内核已经支持VT-d技术的使用。
CONFIG_DMAR=y
# CONFIG DMAR_DEFAULT_ON is not set
#本选项可设置为y,也可不设置
CONFIG_DMAR_FLOPPY_WA=y
CONFIG_INTR_REMAP=y
另外,为了配合接下来的第3步设置(用于隐藏设备),还需要配置pci-stub这个内核模块,相关的内核配置选项如下。在RHEL 6.3和Fedora 17系统的默认内核中,都将PCI_STUB配置为y(直接编译到内核),不作为模块来加载。
#如果配置为y(编译进内核),则不需作为模块来加载
CONFIG_PCI_STUB=m
在启动宿主机系统后,可以通过内核的打印信息来检查VT-d是否处于打开可用状态,如下所示。
[root@jay-linux kvm_demo]# dmesg | grep DMAR -i
ACPI:DMAR 0000000bdf96c98 00210 (v01 INTEL S4600LH 06222004 INTL 20090903)
DMAR: Host address width 46
DMAR: DRHD base: 0x00000ebffe000 flags: 0x0
DMAR:DRHD base:Ox00000f7ffe000flags:0x0
DMAR:DRHD base:0x00000fbffe000flags:0x0
DMAR:DRHD base:0x00000dfffc000flags:0x1
DMAR: RMRR base: 0x00000bdd07000 end: 0x000000bddldff
DMAR:ATSR flags:0x0
[root@jay-linux kvm_demo]# dmesg | grep IOMMU -i
IOMMU O: reg base addr ebffe000 ver 1:0 cap d2078c1061062 ecap f020fe
IOMMU 1: reg_base_addr f7ffe000 ver 1:0 cap d2078c106f0462 ecap f020fe
IOMMU 2: reg base addr fbffe000 ver 1:0 cap d2078c106f0462 ecap f020fe
IOMMU 3:reg_base_addr dfffc000 ver 1:0 cap d2078c10660462 ecap f020fe
IOAPIC id 4 under DRHD base Oxfbffe000 IOMMU 2
IOAPIC id 3 under DRHD base 0xf7ffe000 IOMMU 1
IOAPIC id 2 under DRHD base 0xebffe000 IOMMU 0
IOAPIC id 0 under DRHD base Oxdfffc000 IOMMU 3
IOAPIC id 1 under DRHD base 0xdfffc000 IOMMU 3
IOMMU 2 0xfbffe000: using Queued invalidation
IOMMU 1 0xf7ffe000: using Queued invalidation
IOMMU 0 0xebffe000: using Queued invalidation
IOMMU 3 0xdfffc000: using Queued invalidation
IOMMU: Setting RMRR:
IOMMU: Setting identity map for device 0000:00:1d.0 [0xbdd07000 - 0xbddldfff]
IOMMU: Setting identity map for device 0000:00:la.0 [0xbdd07000 - 0xbddldfff]
IOMMU:Prepare 0-16MiB unity mapping for LPC
IOMMU: Setting identity map for device0000:00:1f.0 [0x0 - 0xfffffff]
如果内核的IOMMU默认没有打开,也可以在GRUB的kernel行中加入"intel_iommu=on"这个内核启动选项。
3)在宿主机中隐藏设备
使用pci_stub这个内核模块来对需要分配给客户机的设备进行隐藏,从而让宿主机和未被分配该设备的客户机都无法使用该设备,达到隔离和安全使用的目的,需要通过如下三步来隐藏一个设备。
(1)加载pci_stub驱动(前面“2.宿主机内核的配置”中已提及将"CONFIG_PCI_STUB=m"作为内核编译的配置选项),如下所示。
[root@jay-linux kvm_demo]# modprobe pci_stub
[root@jay-linux kvm_demo]# 1smod | grep stub
pci_stub 1253 0
[root@jay-linux kvm_demo]# 1s /sys/bus/pci/drivers/pci-stub/
0000:06:00.1 bind module new_id remove_id
如果pci_stub已被编译到内核而不是作为module,则仅需最后一个命令来检查/sys/bus/pci/drivers/pci-stub/目录存在即可。
(2)查看设备的vendor ID和device ID,如下所示(假设此设备的BDF为08:00.0)。
[root@jay-linux kvm demo]# lspci -Dn -s 08:00.0
0000:08:00.0 0200: 8086:10b9 (rev 06)
在上面lspci命令行中,-D选项表示在输出信息中显示设备的domain,-n选项表示用数字的方式显示设备的vendor ID和device ID,-s选项表示仅显示后面指定的一个设备的信息。
在该命令的输出信息中,“0000:08:00.0”表示设备在PCI/PCI-E总线中的具体位置,依次是设备的domain(0000)、bus(08)、slot(00)、function(0),其中domain的值一般为0(当机器有多个host bridge时,其取值范围是0~0xffff),bus的取值范围是0~0xff,slot取值范围是0~0x1f,function取值范围是0~0x7,其中后面3个值一般用BDF(即bus:device:function)来简称。在输出信息中,设备的vendor ID是“8086”(“8086”ID代表Intel Corporation),device ID是"10b9"(代表82572网卡)。
(3)绑定设备到pci_stub驱动,命令行操作如下所示。
echo -n "8086 10b9" > /sys/bus/pci/drivers/pci-stub/new_id
echo0000:08:00.0 > /sys/bus/pci/devices/0000:08:00.0/driver/unbind
echo 0000:08:00.0 > /sys/bus/pci/drivers/pci-stub/bind在绑定前,用lspci命令查看BDF为08:00.0的设备使用的驱动是Intel的e1000e驱动,而绑定到pci_stub后,通过如下命令可以可查看到它目前使用的驱动是pci_stub而不是e1000e了,其中lspci的-k选项表示输出信息中显示正在使用的驱动和内核中可以支持该设备的模块。
[root@vt-nhm9 ~]# 1spci -k -s 08:00.0
08:00.0 Ethernet controller: Intel Corporation 82572EI Gigabit \
Ethernet Controller (Copper) (rev 06)
Subsystem: Intel Corporation PRO/1000 PT Desktop Adapter
Kernel driver in use: pci-stub
Kernel modules: el000e
而在客户机不需要使用该设备后,让宿主机使用该设备,则需要将其恢复到使用原本的驱动。
隐藏和恢复设备,手动操作起来还是有点效率低和容易出错,利用如下一个Shell脚本(命名为pcistub.sh脚本)可以方便地实现该功能,并且使用起来非常简单,仅供大家参考。
#!/bin/bash
# A script to hide/unhide PCI/PCIe device for KVM.(using 'pci stub' driver)
hide_dev=0
unhide_dev=0
driver=0
# check if the device exists
function dev_exist()
{
local line_num=$(lspci -s "$1" 2>/dev/null | wc -1)
if [ $line_num = 0 ]; then
echo "Device Spcidev doesn't exists. Please check your system or your command line."
exit 1
else
return 0
fi
}
# output a format "<domain>:<bus>:<slot>.<func>"(e.g.0000:01:10.0) of device
function canon()
{
f='expr "$1" : '.*\.\(.\)''
d='expr "$1" : ".*:\(.*\).$f"'
b='expr "$1" : "\(.*\):$d\.$f"'
if [ 'expr "$d" : '..'' == 0 ]
then
d=0$d
fi
if [ 'expr "$b" : '.*:'' != 0 ]
then
if [ 'expr "$b" : '.*:'' != 0 ]
then
p='expr "$b" : '\(.*\):''
b='expr "$b" : '.*:\(.*\)''
else
p=0000
fi
if [ 'expr "$b" : '..'' == 0 ]
then
b=0$b
fi
echo $p:$b:$d.$f
}
# output the device ID and vendor ID
function show_id()
{
1spci -Dn -s "$1" | awk '{print $3}' | sed "s/:/ /" > /dev/nu11 2>&1
if [ $? -eq 0 ]; then
lspci -Dn -s "$1" | awk '{print $3}' | sed "s/:/ /"
else
echo "Can't find device id and vendor id for device $1"
exit 1
fi
}
#hide a device using 'pci_stub' driver/module
function hide_pci(){
local pre_driver=NULL
local pcidev=$(canon $1)
local pciid=$(show_id $pcidev)
dev_exist $pcidev
if [ -h /sys/bus/pci/devices/"$pcidev"/driver ]; then
pre_driver=$(basename $(readlink /sys/bus/pci/devices/"$pcidev"/driver))
echo "Unbinding $pcidev from $pre_driver"
echo-n "$pciid" > /sys/bus/pci/drivers/pci-stub/new_id
echo -n "$pcidev" > /sys/bus/pci/devices/"$pcidev"/driver/unbind
fi
echo "Binding $pcidev to pci-stub"
echo -n "$pcidev" > /sys/bus/pci/drivers/pci-stub/bind
return $?
}
# unhide a device from 'pci_stub' driver and bind to a new driver
function unhide_pci(){
local driver=$2
local pcidev=$(canon $1)
local pciid=$(show_id $pcidev)
local pre_driver=NULL
dev_exist $pcidev
if [ $driver != 0 -a ! -d /sys/bus/pci/drivers/$driver ]; then
echo "No $driver interface under sys, return fail"
exit 1
fi
if [ -h /sys/bus/pci/devices/"$pcidev"/driver ]; then
pre_driver=$(basename $(readlink /sys/bus/pci/devices/"$pcidev"/driver))
if [ "$pre_driver" = "$driver" ]; then
echo "$1 has been already bind with $driver,no need to unhide and bind."
exit 1
elif [ "$pre_driver" != "pci-stub"]; then
echo "$1 is not bind with pci-stub,it is bind with $pre_driver,no need to unhide"
exit 1
else
echo "Unbinding $pcidev from $pre_driver"
if [ $driver != 0 ]; then
echo -n "$pciid" > /sys/bus/pci/drivers/$driver/new_id
fi
echo -n "$pcidev" > /sys/bus/pci/drivers/pci-stub/unbind
if [ $? -ne 0 ]; then
return $?
fi
fi
fi
if [ $driver != 0 ]; then
echo "Binding $pcidev to $driver"
echo-n "$pcidev" > /sys/bus/pci/drivers/$driver/bind
fi
return $?
}
# show the usage of this script
function usage(){
echo "Usage: pcistub -h pcidev [-u pcidev] [-d driver]"
echo "-h pcidev: <pcidev> is BDF number of the device you want to hide"
echo "-u pcidev: Optional. <pcidev> is BDF number of the device you want to unhide."
echo "-d driver: Optional. When unhiding the device, bind the device with <driver>. The option should be used together with '-u' option"
echo ""
echo "Examplel: sh pcistub.sh -h 06:10.0 # Hide device 01:10.0 to 'pci_stub' driver"
echo "Example2:sh pcistub.sh-u 08:00.0 -d e1000e # Unhide device 08:00.0 and bind the device with 'e1000e' driver"
exit 1
}
if [ $#-eq 0 ] ; then
usage
fi
# parse the options in the command line
OPTIND=1
while getopts ":h:u:d:" Option
do
case $option in
h ) hide_dev=$0PTARG;;
u ) unhide_dev-$OPTARG;;
d ) driver=$OPTARG;;
* ) usage;;
esac
done
if [ ! -d /sys/bus/pci/drivers/pci-stub ]; then
modprobe pci_stub
if [ ! -d /sys/bus/pci/drivers/pci-stub ]; then
echo "There's no 'pci-atub' module? Please check your kernel config."
exit 1
fi
fi
if [ $hide_dev != 0 -a $unhide_dev != 0 ]; then
echo "Do not use -h and -u option together."
exit 1
fi
if [ Sunhide_dev = 0 -a $driver != 0 ]; then
echo "You should set -u option if you want to use -d option to unhide a device and bind it with a specific driver"
exit 1
fi
if [ $hide_dev != 0 ]; then
hide_pci $hide_dev
elif [ $unhide_dev!= 0 ]; then
unhide_pci $unhide_dev $driver
fi
exit $?后面的VT-d/SR-IOV的操作实例就是使用这个脚本对设备进行隐藏和恢复的。
4)通过QEMU命令行分配设备给客户机
利用qemu-kvm命令行中"-device"选项可以为客户机分配一个设备,配合其中的"pci-assign"作为子选项可以实现设备直接分配。
![]()
其中driver是设备使用的驱动,有很多种类,如pci-assign表示PCI设备直接分配、virtio-balloon-pci(又为virtio-balloon)表示ballooning设备(这与前面提到的"-balloonvirtio"的意义相同)。prop[=value]是设置驱动的各个属性值。
"-device?"可以查看有哪些可用的驱动,"-device driver,?"可查看某个驱动的各个属性值,如下面命令行所示。
[root@jay-linux kvm_demo]# qemu-system-x86_64 -device ?
name "usb-kbd",bus USB
name "virtio-serial-pci",bus PCI,alias "virtio-serial"
name "sysbus-ohci", bus System, desc "OHCI USB Controller"
<! -此处省略数十行输出信息 -->
name "virtio-balloon-pci",bus PCI,alias "virtio-balloon"
name "pci-assign",bus PCI
[root@jay-linux kym_demo]# qemu-system-x86_64 -device pci-assign,?
kvm-pci-assign.host=pci-host-devaddr #qemu-kvm 1.1.0没这行
host 属性输出,算是个小bug(qemu-kvm1.2中已经fix了),但功能上正常
pci-assign.prefer_msi=on/off
pci-assign.share_intx=on/off
pci-assign.bootindex=int32
pci-assign.configfd=string
pci-assign.addr=pci-devfn
pci-assign.romfile=string
pci-assign.rombar=uint32
pci-assign.multifunction=on/off
pci-assign.command_serr_enable=on/off
pci-assign.id=string # qemu-kvm 1.1.0中也没有这行提示,但可正常使用espten
在-device pci-assign的属性中,host属性指定分配的PCI设备在宿主机中的地址(BDF号),addr属性表示设备在客户机中的PCI的slot编号(即BDF中的D-device的值),id属性表示该设备的唯一标识(可以在QEMU monitor中用"info pci"命令查看到)。
qemu-kvm命令行工具在启动时分配一个设备给客户机,命令行如下所示。
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -m 1024 -device pci-assign,host=08:00.0,id=mydev0,addr=0X6
如果要一次性分配多个设备给客户机,只需在qemu-kvm命令行中重复多次"-device pci-assign,host=$BDF"这样的选项即可。
由于设备直接分配是客户机独占该设备,因此一旦将一个设备分配给客户机使用,就不能再将其分配给另外的客户机使用了,否则在通过命令行启动另一个客户机也分配这个设备时,会遇到如下的错误:
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u2.img -m 1024 -device pci-assign,host=08:00.0
qemu-system-x86 64: -device pci-assign,host=08:00.0: Failed to assign device "(null)" : Device or resource busy
qemu-system-x86_64:-device pci-assign,host=08:00.0: **** The driver 'pci-stub' is occupying your device 0000:08:00.0.
qemu-system-x86_64:-device pci-assign,host=08:00.0: ***
qemu-system-x86_64:-device pci-assign,host=08:00.0: ***
除了在客户机启动时就直接分配设备之外,QEUM/KVM还支持设备的热插拔(hot-plug)在客户机运行时添加所需的直接分配的设备,这需要在QEMU monitor中运行相应的命令。
3. VT-d 操作示例
1)网卡直接分配
在如今的网络时代,有很多服务器对网卡性能要求较高,在虚拟客户机中也不例外。通过VT-d技术将网卡直接分配给客户机使用,会让客户机得到和native环境中使用网卡几乎一样的性能。通过示例来演示将一个Intel 82572型号的PCI-E网卡分配给一个RHEL 6.3客户机使用的过程,这里省略BIOS配置、宿主机内核检查等操作步骤。
(1)选择需要直接分配的网卡
[root@jay-linux kvm_demo]# 1spci -s 08:00.0
08:00.0 Ethernet controller: Intel Corporation 82572EI Gigabit
Ethernet Controller (Copper) (rev 06)
Subsystem:Intel Corporation PRO/1000 PT Desktop Adapter
Kernel driver in use: el000e
Kernel modules: el000e(2)隐藏该网卡(使用了前面介绍的pcistub.sh脚本)
[root@jay-linux kym demo]#./pcistub.sh-h 08:00.0
Unbinding 0000:08:00.0 from e1000e
Binding 0000:08:00.0 to pci-stub
[root@jay-linux kvm_demo]# 1spci -k -s 08:00.0
08:00.0 Ethernet controller: Intel Corporation 82572EI Gigabit
Ethernet Controller (Copper) (rev 06)
Subsystem: Intel Corporation PRO/1000 PT Desktop Adapter
Kernel driver in use:pci-stub
Kernel modules:e1000e(3)启动客户机时分配网卡。
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -smp 2 -m 1024 -device pci-assign,host=08:00.0,id=mynic -net none
VNC server running on '::1:5900'
命令行中的"-net none"表示不使其他的网卡设备(除了直接分配的网卡之外),否则在客户机中将会出现一个直接分配的网卡和另一个emulated的网卡。
在QEMU monitor中,可以用"info pci"命令查看分配给客户机的PCI设备的情况。
(qemu) info pci
<! -此处省略PCI设备的信息 -->(4)在客户机中查看网卡的工作情况。
[root@kvm-guest ~]#lspci -s 00:06.0
00:06.0 Ethernet controller: Intel Corporation 82572EI Gigabit
[root@kvm-guest ~]# ethtool -i eth2
driver: el000e
version: 1.9.5-k
firmware-version:5.11-10
bus-info:0000:00:06.0
[root@kvm-guest ~]# ping 192.168.199.98 -I eth2 -c 1
PING 192.168.199.98(192.168.199.98) from 192.168.199.69 eth2:
56(84) bytes of data.
64 bytes from 192.168.199.98: icmp_seq=1 ttl=64 time=0.367 ms
--- 192.168.199.98 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time Oms
rtt min/avg/max/mdev = 0.367/0.367/0.367/0.000 ms
由上面输出信息可知,在客户机中看到的网卡是使用e1000e驱动的Intel 82572网卡(和宿主机隐藏它之前看到的是一样的),eth2就是该网卡的网络接口,通过ping命令查看其网络是畅通的。
(5)关闭客户机后,在宿主机中恢复前面被隐藏的网卡。
在客户机关闭或网卡从客户机中虚拟地“拔出”来之后,如果想让宿主机继续使用该网卡,则可以使用pcistub.sh脚本来恢复其在宿主机中的驱动绑定情况,操作过程如下所示。
[root@jay-linux kvm_demo]# ./pcistub.sh -u 08:00.0 -d e1000e
Unbinding 0000:08:00.0 from pci-stub
Binding 0000:08:00.0 to e1000e
[root@jay-linux kvm_demo]# 1spci -k -s 08:00.0
08:00.0 Ethernet controller: Intel Corporation 82572EI Gigabit
Ethernet Controller (Copper) (rev 06)
Subsystem: Intel Corporation PRO/1000 PT Desktop Adapter
Kernel driver in use: el000e
Kernel modules: el000e
[root@jay-linux kvm_demo]# ethtool -i eth6
driver: e1000e
version: 2.0.0-k
firmware-version:5.11-10
bus-info:0000:08:00.0
其中,在pcistub.sh脚本中,"-u$BDF"是指定需要取消隐藏(unhide)的设备,"-d$driver"是指将从pci_stub的绑定中取消隐藏的设备绑定到另外一个新的驱动(driver)中。由上面的输出信息可知,08:00.0设备使用的驱动从pci_stub变回了e1000e,而且以太网络接口eth6正是该设备。
2)硬盘直接分配
在现代计算机系统中,一般SATA或SAS等类型硬盘的控制器(Controller)都是接入到PCI(或PCIe)总线上的,所以也可以将硬盘作为普通PCI设备直接分配给客户机使用。不过当SATA或SAS设备作为PCI设备直接分配时,实际上将其控制器作为一个整体分配到客户机中,如果宿主机使用的硬盘也连接在同一个SATA或SAS控制器上,则不能将该控制器直接分配给客户机,而是需要硬件平台中至少有两个或以上的SATA或SAS控制器。宿主机系统使用其中一个,然后将另外的一个或多个SATA/SAS控制器完全分配给客户机使用。
下面以一个SATA硬盘为实例介绍对硬盘的直接分配过程。
(1)先在宿主机中查看硬盘设备,然后隐藏需要直接分配的硬盘,其命令行操作如下所示。
[root@jay-linux kvm_demo]# ll
/dev/disk/by-path/pci-00000\:16\:00.0-sas-0x12210000000000-1un-0
lrwxrwxrwx 1 root root 9 Sep 24 11:17
/dev/disk/by-path/pci-00000:16:00.0-sas-0x122100000000000-lun-0->../../sda
[root@jay-linux kvm_demo]# 11
/dev/disk/by-path/pci-0000\:00\:1f.2-scsi-0\:0\:0\:0
lrwxrwxrwx 1 root root 9 Sep 24 11:17
/dev/disk/by-path/pci-0000:00:1f.2-scsi-0:0:0 -> .././sdb
[root@jay-linux kvm_demo]# lspci -k -s 16:00.0
16:00.0 SCSI storage controller:LSI Logic / Symbios Logic SAS1078
PCI-Express Fusion-MPT SAS(rev 04)
Subsystem:Intel Corporation Device 3505
Kernel driver in use:mptsas
Kernel modules:mptsas
[rootejay-linux kvm_demo]# lspci -k -s 00:1f.2
00:1f.2 SATA controller:Intel Corporation 82801JI (ICH10 Family)
SATA AHCI Controller
Subsystem:Intel Corporation Device 34f8
Kernel driver in use:ahci
Kernel modules: ahci
[root@jay-linux kvm_demo]# fdisk -l /dev/sdb
[root@jay-linux kvm_demo]# df -h
[rootθjay-linux kvm_demo]# ./pcistub.ah -h 00:1f.2
[rootθjay-linux kvm_demo]# lspci -k -s 00:1f.2
00:1f.2 SATA controller:Intel Corporation 82801JI (ICH10 Family)
SATA AHCI Controller
Subsystem:Intel Corporation Device 34f8
Kernel driver in use: pci-stub
Kernel modules: ahci
由上面的命令行输出可知,在宿主机中有两块硬盘sda和sdb,分别对应一个SAS Controller(16:00.0)和一个SATA Controller(00:1f.2),其中sdb大小为160GB,而宿主机系统安装在sda的第一个分区(sda1)上。在用pcistub.sh脚本隐藏SATA Controller之前,它使用的驱动是ahci驱动,之后,将其绑定到pci-stub驱动,为设备直接分配做准备。
(2)用如下命令行将STAT硬盘分配(实际是分配STAT Controller)给客户机使用。
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -m 1024 -device pci-assign,host=00:1f.2,addr=0x6 -net nic -net tap
VNC server running on '::1:5900'
(3)在客户机启动后,在客户机中查看直接分配得到的SATA硬盘,命令行如下所示。
[root@jay-linux kvm_demo]# fdisk -l /dev/sdb
[rootθjay-linux kvm_demo]# lspci -k -s 00:06.0由客户机中的以上命令行输出可知,宿主机中的sdb硬盘(BDF为00:06.0)就是设备直接分配的那个160GB大小的SATA硬盘。在SATA硬盘成功直接分配到客户机后,客户机中的程序就可以像普通硬盘一样对其进行读写操作(也包括磁盘分区等管理操作)。
3)USB直接分配
与SATA和SAS控制器类似,在很多现代计算机系统中,USB主机控制器(USB Host Controller)也是接入到PCI总线中去的,所以也可以对USB设备做设备直接分配。同样,这里的USB直接分配,也是指对整个USB Host Controller的直接分配,而并不一定仅分配一个USB设备。常见的USB设备,如U盘、键盘、鼠标等都可以作为设备直接分配到客户机中使用。这里以U盘为例来介绍USB直接分配,而USB键盘、鼠标的直接分配也与此类似。
VGA直接分配的示例时,也会将鼠标、键盘直接分配到客户机中。
(1)在宿主机中查看U盘设备,并将其隐藏起来以供直接分配,命令行操作如下所示。
[root@jay-linux kvm_demo]# fdisk -l /dev/sdb
[rootθjay-linux kvm_demo]# ls -l
[rootθjay-linux kvm_demo]# lspci -k -s 00:1d.0
[rootθjay-linux kvm_demo]# ./pcistub.ah -h 00:1d.0
[rootθjay-linux kvm_demo]# lspci -k -s 00:1d.0由宿主机中的命令行输出可知,sdb就是那个使用USB 2.0协议的U盘,它的大小为16GB,其PCI的ID为00:1d.0,在pci-stub隐藏之前使用的是ehci-hcd驱动,然后被绑定到pci-stub驱动隐藏起来以供后面直接分配给客户机使用。
(2)将U盘直接分配给客户机使用的命令行如下所示,与普通PCI设备直接分配的操作完全一样。

(3)在客户机中,查看通过直接分配得到的U盘,命令行如下。
[rootθjay-linux kvm_demo]# df -h
[root@jay-linux kvm_demo]# fdisk -l /dev/sdb
[rootθjay-linux kvm_demo]# lspci -k -s 00:05.0由客户机中的命令行输出可知,sdb就是那个16GB的U盘(BDF为00:05.0),目前使用ehci_hcd驱动。在U盘直接分配成功后,客户机就可以像普通系统使用U盘一样直接使用它了。
另外,对于USB2.0设备,也有其他的命令行参数(-usbdevice)来支持USB设备的分配。不同于前面介绍的对USB Host Controller的直接分配,-usbdevice参数用于分配单个USB设备。
在宿主机中不要对USB Host Controller进行隐藏(如果前面已经隐藏了,可以用"pcistub.sh-u 00:1d.0-d ehci_hcd"命令将其释放出来),用"lsusb"命令查看需要分配的USB设备的信息,然后在要启动客户机的命令行中使用"-usbdevice host:xx"这样的参数启动客户机即可,其操作过程如下。
[root@jay-linux kvm demo]# 1susb
Bus 001 Device 002:ID 8087:0024 Intel Corp. Integrated Rate Matching Hub
Bus 001 Device 001:ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 001 Device 003:ID 0781:5567 SanDisk Corp.Cruzer Blade
#用于分配的 SandDisk 的 u 盘设备
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -m 1024 -usbdevice host:0781:5667 -net nic -net tap
VNC server running on '::1:5900'
4)VGA显卡直接分配
在计算机系统中,显卡也是作为一个PCI或PCIe设备接入到系统总线之中的。在KVM虚拟化环境中,如果有在客户机中看一些高清视频和玩一些高清游戏的需求,也可以将显卡像普通PCI设备一样完全分配给某个客户机使用。目前,市面上显卡的品牌很多,有Nvidia、ATI等独立显卡品牌,也包括Intel等公司在较新的CPU中集成的GPU模块(具有3D显卡功能)。
显卡也有多种的接口类型,如VGA(Video Graphics Array)、DVI(Digital Visual Interface)、HDMI(High-Definition Multimedia Interface)等多种标准的接口。下面以一台服务器上的集成VGA显卡为例,介绍显卡设备的直接分配过程,在此过程中也将USB鼠标和键盘一起分配给客户机,以方便用服务器上直接连接的物理鼠标、键盘操作客户机。
(1)查看USB键盘和鼠标的PCI的BDF,查看VGA显卡的BDF,命令行操作如下所示。
[root@jay-linux ~]# dmesg | grep -e Keyboard -e Mouse
hid-generic 0003:0557:2217.0001:input:USB HID v1.10 Keyboard [ATEN ATEN CS-1716/08/04] on usb-0000:00:1a.0-1.5/input0
hid-generic 0003:0557:2217.0002:input:USB HID v1.10 Mouse [ATEN ATEN CS-1716/08/04] on usb-0000:00:la.0-1.5/input1
input: American Megatrends Inc.Virtual Keyboard and Mouse as /devices/pci000:00/000:00:1d.0/usb2/2-1/2-1.4/2-1.4:1.0/input/input2
hid-generic 0003:046B:FF10.0003: input:USB HID v1.10 Keyboard [American Megatrends Inc.Virtual Keyboard and Mouse] on usb-0000:00:1d.0-1.4/input0
input: American Megatrends Inc.Virtual Keyboard and Mouse as
/devices/pci000:00/000:00:1d.0/usb2/2-1/2-1.4/2-1.4:1.1/input/input3 hid-generic 0003:046B:FF10.0004:input:USB HID v1.10 Mouse [American Megatrends Inc.Virtual Keyboard and Mouse] on usb-0000:00:1d.0-1.4/input1
[root@jay-linux kvm_demo]# 1susb
Bus 003 Device 002:ID 046b;ff10 American Megatrends,Inc.Virtual Keyboard and Mouse
Bus 005 Device 002: ID 0557:2217 ATEN International Co., Ltd Bus 008 Device 002:ID 05e3:0719 Genesys Logic,Inc.SATA adapter
Bus 001 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 002 Device 001:ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 003 Device 001: ID ld6b:0001 Linux Foundation 1.1 root hub
Bus 004 Device 001: ID 1d6b:0001 Linux Foundation 1,1 root hub
Bus 005 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 006 Device 001:ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 007 Device 001:ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 008 Device 001: ID ld6b:0002 Linux Foundation 2.0 root hub
[root@jay-linux kvm_demo]# 1spci -k -s 00:1a.0
00:la.0 USB controller: Intel Corporation C600/X79 series chipset USB2 Enhanced Host Controller #2(rev 06)
Subsystem:Intel Corporation Device 35a0
Kernel driver in use:ehci_hcd
Kernel modules: ehci-hcd
[root@jay-linux-]# 1spci | grep-iVGA
09:00.0 VGA compatible controller: Matrox Electronics Systems Ltd. MGA G200e [Pilot] ServerEngines(SEP1)(rev 05)
[root@jay-linux~]# 1spci -k -s 09:00.0
09:00.0 VGA compatible controller: Matrox Electronics Systems Ltd. MGA G200e [Pilot]
ServerEngines (SEP1)(rev 05)
Subsystem:Intel Corporation Device 0103
由上面命令行的输出信息可知,USB鼠标和键盘的USB控制器的PCI设备BDF为00:1a.0(实验是用的一个USB转接器,然后在它上面接了一个键盘和一个鼠标,所以宿主机只能看到一个USB设备),宿主机VGA显卡是Matrox公司的G200e型号显卡,其BDF为09:00.0。
(2)分别将鼠标、键盘和VGA显卡隐藏起来,以便分配给客户机,命令行操作如下所示。
[root@jay-linux kvm_demo]# ./pcistub.sh -h 00:1a.0
Unbinding 0000:00:la.0 from ehci hcd
Binding 0000:00:la.0 to pci-stub
[root@jay-linux kvm_demo]# 1spci -k -s 00:la.0
00:la.0 USB controller: Intel Corporation C600/X79 series chipset
USB2 Enhanced Host Controller #2(rev 06)
Subsystem: Intel Corporation Device 35a0
Kernel driver in use:pci-stub
Kernel modules: ehci-hcd
[root@jay-linux kvm_demo]# ./pcistub.sh -h 09:00.0
0000:09:00.0 wasn't bound to any drirver
Binding 0000:09:00.0 to pci-stub
[root@jay-linux kvm_demo]# 1spci -k -s 09:00.0
09:00.0 VGA compatible controller: Matrox Electronics Systems Ltd. MGA G200e [Pilot] ServerEngines (SEP1)(rev 05)
Subsystem:Intel Corporation Device 0103
Kernel driver in use:pci-stub
(3)qemu-kvm命令行启动一个客户机,将USB鼠标键盘和VGA显卡都分配给它,其命令行操作如下所示。
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhe16u3.img -m 1024 -device pci-assign,host=09:00.0 -device pci-assign,host=00:la.0 -net nic -net tap
VNC server running on'::1:5900'
(4)在客户机中查看分配的VGA显卡和USB键盘鼠标,命令行操作如下所示。
[root@kvm-guest~]# lspci | grep USB
00:05.0 USB controller:Intel Corporation 82801JI (ICH10 Family)
USB UHCI Controller#2
[root@kvm-guest ~]# 1susb
Bus 001 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 001 Device 002: ID 0557:2217 ATEN International Co., Ltd
[root@kvm-guest ~]# 1spci | grep VGA
00:02.0 VGA compatible controller:Cirrus Logic GD 5446
00:04.0 VGA compatible controller: Matrox Electronics Systems Ltd. MGA G200e [Pilot] ServerEngines (SEP1)(rev 05)
[root@kvm-guest ~]# dmesg | grep -i VGA
Console: colour VGA+ 80x25
vgaarb: device added:
PCI:0000:00:02.0,decodes=io+mem,owns=io+mem,locks=none
vgaarb: device added:
PCI:0000:00:04.0,decodes=io+mem,owns=io+mem,locks=none
vgaarb: loaded
vgaarb: bridge control possible 0000:00:04.0
vgaarb: no bridge control possible 0000:00:02.0
由上面输出可以看出,客户机中这个USB设备与宿主机中的是一样的,客户机有两个VGA显卡,其中BDF 00:02.0是提到的QEMU纯软件模拟的Cirrus显卡,而另外的BDF 00:04.0就是设备直接分配得到的GMA G200e显卡,它的信息和在宿主机中查看到的是一样的。从dmesg信息可以看到系统启动后,00:04.0显卡才是最后真正使用的显卡,而00:02.0是不可用的(处于"no bridge control possible"状态)。
另外,在客户机中也启动了图形界面,对使用的显卡进行检查还可以在客户机中查看Xorg的日志文件:/var/log/Xorg.0.log,其中部分内容如下:
[ 29.220]
X.Org X Server 1.10.6
Release Date:2012-02-10
[ 29.221] X Protocol Version 11,Revision 0 L
[ 29.221] Build Operating System:x86-007 2.6.18-308.1.1.e15 一
[ 29.221 Current Operating System:Linux kvm-guest V
2.6.32-279.e16,x86_64 #1 SMP Wed Jun 13 18:24:36 EDT 2012 ×86_64
<!-- 省略数十行输出信息 -->
(--) PCI:(0:0:2:0)1013:00b8:1af4:1100 Cirrus Logic GD 5446 rev 0, Mem @ Oxfa00000/33554432, 0xfe834000/4096, BIOS @ 0x???????76536
(--) PCI:*(0:0:4:0)102b:0522:8086:0101 Matrox Graphics,Inc. MGA G200e [Pilot] ServerEngines(SEP1) rev 2,Mem @ 0xfc000000/
16777216,0xfe830000/16384,0xfe0000000/8388608,BIOS@0x???????/65536
(==) Using default built-in configuration(30 lines)
<!-- 省略数十行输出信息 -->
(II) MGA: driver for Matrox chipsets: mga2064w, mga1064sg, mga2164w,
mga2164w AGP, mgag100, mgag100 PCI, mgag200, mgag200 PCI,
mgag200 SE A PCI,mgag200 SE B PCI,mgag200 EV Maxim,
mgag200 ER SH7757, mgag200 eW Nuvoton, mgag200eH, mgag400, mgag50
(II) VESA: driver for VESA chipsets: vesa
(II) FBDEV:driver for framebuffer:fbdev
(II) Primary Device is:PCI 00@00:04:0
<!-- 省略后面的其他输出信息-->
由上面Xorg.0.log中的日志信息可知,X窗口程序检测到两个VGA显卡,最后使用的是BDF为00:04.0的显卡,使用了VESA程序来驱动该显卡。
在客户机内核的配置中,对VESA的配置已经变异到内核中去了,因此可以直接使用。
[root@rhel6u3-ga ~]# grep VESA
/boot/config-2.6.32-279.el6.x86_64
CONFIG_FB_BOOT_VESA_SUPPORT=y
# CONFIG_FB_UVESA is not set
CONFIG_FB_VESA=y
在本示例中,在RHEL 6.3客户机启动的前期默认使用的是QEMU模拟的Cirrus显卡,而在系统启动完成后打开用户登录界面(启动了X-window图形界面),客户机就自动切换到使用直接分配的设备GMA G200e显卡了,在连接物理显卡的显示器上就出现了客户机的界面。
对于不同品牌的显卡及不同类型的客户机系统,KVM对它们的支持有所不同,其中也存在部分bug,在使用显卡设备直接分配时,可能有的显卡在某些客户机中并不能正常工作,这就需要根据实际情况来操作。
另外,在Windows客户机中,如果在“设备管理器”中看到了分配给它的显卡,但是并没有使用和生效,可能需要下载合适的显卡驱动,并且在“设备管理器”中关闭纯软件模拟的那个显卡,而且需要开启设置直接分配得到的显卡,这样才能让接VGA显卡的显示器能显示Windows客户机中的内容。
3、SR-IOV技术
1. SR-IOV概述
前面介绍的普通VT-d技术实现了设备直接分配,尽管其性能非常好,但是它的一个物理设备只能分配给一个客户机使用。为了实现多个虚拟机能够共享同一个物理设备的资源,并且达到设备直接分配的性能,PCI-SIG[8]组织发布了SR-IOV(Single Root I/O Virtualization and Sharing)规范,该规范定义了一个标准化的机制用以原生地支持实现多个共享的设备(不一定是网卡设备)。不过,目前SR-IOV(单根I/O虚拟化)最广泛的应用还是在以太网卡设备的虚拟化方面。QEMU/KVM在2009年实现了对SR-IOV技术的支持,其他一些虚拟化方案(如Xen、VMware、Hyper-V等)也都支持SR-IOV了。
在详细介绍SR-IOV之前,先介绍一下SR-IOV中引入的两个新的功能(function)类型。
- Physical Function(PF,物理功能):拥有包含SR-IOV扩展能力在内的所有完整的PCI-e功能,其中SR-IOV能力使PF可以配置和管理SR-IOV功能。简言之,PF就是一个普通的PCI-e设备(带有SR-IOV功能),可以放在宿主机中配置和管理其他VF,它本身也可以作为一个完整独立的功能使用。
- Virtual Function(VF,虚拟功能):由PF衍生而来的“轻量级”的PCI-e功能,包含数据传送所必需的资源,但是仅谨慎地拥有最小化的配置资源。简言之,VF通过PF的配置之后,可以分配到客户机中作为独立功能使用。
SR-IOV为客户机中使用的VF提供了独立的内存空间、中断、DMA流,从而不需要Hypervisor介入数据的传送过程。SR-IOV架构设计的目的是允许一个设备支持多个VF,同时也尽量减小每个VF的硬件成本。Intel有不少高级网卡可以提供SR-IOV的支持。
下图展示了Intel以太网卡中的SR-IOV的总体架构:

一个具有SR-IOV功能的设备能够被配置为在PCI配置空间(configuration space)中呈现出多个Function(包括一个PF和多个VF),每个VF都有自己独立的配置空间和完整的BAR(Base Address Register,基址寄存器)。Hypervisor通过将VF实际的配置空间映射到客户机看到的配置空间的方式实现将一个或多个VF分配给一个客户机。
通过Intel VT-x和VT-d等硬件辅助虚拟化技术提供的内存转换技术,允许直接的DMA传输去往或来自一个客户机,从而绕过了Hypervisor中的软件交换机(software switch)。每个VF在同一个时刻只能被分配到一个客户机中,因为VF需要真正的硬件资源(不同于emulated类型的设备)。在客户机中的VF,表现给客户机操作系统的就是一个完整的普通的设备。
在KVM中,可以将一个或多个VF分配给一个客户机,客户机通过自身的VF驱动程序直接操作设备的VF而不需要Hypervisor(即KVM)的参与,其总体架构示意图如图所示。

为了让SR-IOV工作起来,需要硬件平台支持Intel VT-x和VT-d(或AMD的SVM和IOMMU)硬件辅助虚拟化特性,还需要有支持SR-IOV规范的设备,当然也需要QEMU/KVM的支持。支持SR-IOV的设备较多,其中Intel有很多中高端网卡支持SR-IOV特性,如Intel 82576网卡(代号"Kawella",使用igb驱动)、I350网卡(igb驱动)、82599网卡(代号"Niantic",使用ixgbe驱动)、X540(使用ixgbe驱动)等。
在宿主机Linux环境中,可以通过"lspci-v-s$BDF"的命令来查看网卡PCI信息的"Capabilities"项目,以确定设备是否具备SR-IOV的能力,如下命令行:
lspci -v -s 10:00.0
Capabilities:[160] Single Root I/O Virtualization (SR-IOV)
一个设备可支持多个VF,PCI-SIG的SR-IOV规范指出每个PF最多能拥有256个VF,而实际支持的VF数量是由设备的硬件设计及其驱动程序共同决定的。前面举例的几个网卡,其中使用"igb"驱动的82576、I350等千兆(1G)以太网卡的每个PF支持最多7个VF,而使用"ixgbe"驱动的82599、X540等万兆(10G)以太网卡的每个PF支持最多63个VF。
在宿主机系统中可以用"modinfo"命令来查看某个驱动的信息,其中包括驱动模块的可用参数,如下命令行演示了常用igb和ixgbe驱动的信息。
[root@jay-linux kvm_demo]# modinfo igb
filename: /lib/modules/3.5.0/kernel/drivers/net/ethernet/intel/igb/igb.ko
version: 3.4.7-k
license: GPL
description: Intel(R) Gigabit Ethernet Network Driver
author: Intel Corporation,<[email protected]>
srcversion: B905A7E217BFBA4F95FAEA8
alias: pci:v00008086d000010D6sv*sd*bc*sc*i*
<!-- 这里省略了数十行输出信息 -->
alias: pci:v00008086d00001539sv*sd*bc*sc*i*
depends:
intree: Y
vermagic: 3.5.0 SMP mod_unload modversions
parm: max_vfs:Maximum number of virtual functions to allocate per physical function(uint)
parm: debug:Debug level(0=none,...,16=all)(int)
[root@jay-linux kvm_demo]# modinfo ixgbe
filename: /lib/modules/3.5.0/kernel/drivers/net/ethernet/intel/ixgbe/ixgbe.ko
parm: allocate per physical function - default is zero and maximum value is 63(uint)
parm: allow_unsupported_sfp:Allow unsupported and untested SFP+ modules on 82599-based adapters(uint)
parm: debug:Debug level(O=none,...,16=all)(int)在宿主机中,在加载支持SR-IOV的PCI设备的驱动时,一般还需要加上相应的参数来指定启用多少个VF,比如利用上面"modinfo"命令查看的igb和ixgbe驱动,其关于启用的VF个数的参数为"max_vfs"。如果当前系统还没有启用VF,则需要卸载掉驱动后重新加载驱动(加上VF个数的参数)来开启VF。
如下命令行演示了开启igb驱动中VF个数的参数的过程及在开启VF之前和之后的系统中网卡的状态。
[root@jay-linux kvm_demo]# 1spci | grep Eth
0d:00.0 Ethernet controller:Intel Corporation 82576 Gigabit
Network Connection (rev 01)
0d:00.1 Ethernet controller: Intel Corporation 82576 Gigabit
Network Connection (rev 01)
#(或rmmod igb)
[root@jay-linux kvm_demo]# modprobe -r igb
[root@jay-linux kvm_demo]# modprobe igb max_vfs=7
[root@jay-linux kvm_demo]# 1spci | grep Eth
0d:00.0 Ethernet controller:Intel Corporation 82576 Gigabit
Network Connection(rev 01)
0d:00.1 Ethernet controller:Intel Corporation 82576 Gigabit
Network Connection(rev 01)
0e:10.0 Ethernet controller:Intel Corporation 82576 Virtual Function(rev 01)
Oe:10.1 Ethernet controller:Intel Corporation 82576 Virtual Function (rev 01)
0e:10.2 Ethernet controller:Intel Corporation 82576 Virtual Function(rev 01)
0e:10.3 Ethernet controller:Intel Corporation 82576 Virtual Function(rev 01)
0e:10.4 Ethernet controller:Intel Corporation 82576 Virtual Function(rev 01)
0e:10.5 Ethernet controller:Intel Corporation 82576 Virtual Function(rev 01)
0e:10.6 Ethernet controller:Intel Corporation 82576 Virtual Function(rev 01)
0e:10.7 Ethernet controller:Intel Corporation 82576 Virtual Function(rev 01)
0e:11.0 Ethernet controller:Intel Corporation 82576 Virtual Function(rev 01)
0e:11.1 Ethernet controller:Intel Corporation 82576 Virtual Function(rev 01)
0e:11.2 Ethernet controller:Intel Corporation 82576 Virtual Function(rev 01)
由上面的演示可知,BDF 0d:00.0和0d:00.1是PF,而在通过加了"max_vfs=7"的参数重新加载igb驱动后,对应的VF被启用了,每个PF启用了7个VF。为了让宿主机在启动时就能够默认自动开启VF,可以修改modprobe命令的配置文件,对于igb和ixgbe驱动,示例如下所示。
[root@jay-linux kvm_demo]# vim /etc/modprobe.d/igb.conf
option igb max_vfs=7
option ixgbe max_vfs=63
而通过如下的命令行可以查看到PF和VF的对应关系,以便清楚哪个VF是由哪个PF衍生而来的。
[root@jay-linux kvm_demo]# 1s -1/sy=/bus/pci/devices/0000\:0d\:00.0/virtfn*
lrwxrwxrwx 1 root root 0 Sep 26 17:13
/sys/bus/pci/devices/0000:0d:00.0/virtfn0->../0000:0e:10.0 1rwxrwxrwx 1 root root 0 Sep 26 17:13
/sys/bus/pci/devices/0000:0d:00.0/virtfn1->../0000:0e:10.2 lrwxrwx 1 root root 0 Sep 26 17:13
/sys/bus/pci/devices/0000:0d:00.0/virtfn2->../0000:0e:10.4 lrwxrwxrwx 1 root root 0 Sep 26 17:13
/sys/bus/pci/devices/0000:0d:00.0/virtfn3->../0000:0e:10.6 lrwxrwxrwx 1 root root 0 Sep 26 17:13
/sys/bus/pci/devices/0000:0d:00.0/virtfn4->../0000:0e:11.0 lrwxrwxrwx 1 root root 0 Sep 26 17:13
/sys/bus/pci/devices/0000:0d:00.0/virtfn5->../0000:0e:11.2 1rwxrwxrwx 1 root root 0 Sep 26 17:13
/sys/bus/pci/devices/0000:0d:00.0/virtfn6->../0000:0e:11.4
[root@jay-linux kvm_demo]# 1s -1 /sys/bus/pci/devices/0000\:0e\:10.0/physfn
lrwxrwxrwx 1 root root 0 Sep 26 17:14
/sys/bus/pci/devices/0000:0e:10.0/physfn->../0000:0d:00.0
其中,0d:00.0的VF为0e:10.0~0e:11.4之间的7个Function号为偶数的Virtual Function(还记得前面提及过的BDF的function位取值范围是0~7)。
另外,值得注意的是,由于VF还是共享和使用对应PF上的部分资源,因此要使SR-IOV的VF能够在客户机中工作,必须保证其对应的PF在宿主机中处于正常工作状态。
使用SR-IOV主要有如下3个优势:
- 真正实现了设备的共享(多个客户机共享一个SR-IOV设备的物理端口);
- 接近于原生系统的高性能(比纯软件模拟和Virtio设备的性能都要好);
- 相比于VT-d,SR-IOV可以用更少的设备支持更多的客户机,可以提高数据中心的空间利用率;
而SR-IOV的不足之处有如下两点:
- 对设备有依赖,只有部分PCI-E设备支持SR-IOV(如前面提到的Intel 82576、82599网卡)。
- 使用SR-IOV时,不方便动态迁移客户机。
2. SR-IOV操作示例
在了解了SR-IOV的基本原理及优劣势之后,将以一个完整的示例来介绍在KVM中使用SR-IOV的各个步骤。这给例子是这样的,在一个SandyBridge平台上,有一个两口的Intel 10G以太网卡(X540系列,使用ixgbe驱动),使用SR-IOV技术将其中的一个VF分配给一个RHEL 6.3的客户机使用。
1)重新加载ixgbe驱动,产生一定数量的VF,命令行操作如下:
[root@jay-linux kvm_demo]# modprobe -r ixgbe、
[root@jay-linux kvm_demo]# modprobe ixgbe max_vf=3
[root@jay-linux kvm_demo]# ifconfig eth1
[root@jay-linux kvm_demo]# 1spci | grep Eth
06:00.0 Ethernet controller: Intel Corporation Ethernet
Controller 10-Gigabit X540-AT2(rev 01)
06:00.1 Ethernet controller: Intel Corporation Ethernet
Controller 10-Gigabit X540-AT2(rev 01)
06:10.0 Ethernet controller: Intel Corporation X540 Ethernet
Controller Virtual Function(rev 01)
06:10.1 Ethernet controller: Intel Corporation X540 Ethernet
Controller Virtual Function(rev 01)
06:10.2 Ethernet controller: Intel Corporation X540 Ethernet
Controller Virtual Function(rev 01)
06:10.3 Ethernet controller: Intel Corporation X540 Ethernet
Controller Virtual Function(rev 01)
06:10.4 Ethernet controller: Intel Corporation X540 Ethernet
Controller Virtual Function(rev 01)
06:10.5 Ethernet controller: Intel Corporation X540 Ethernet
Controller Virtual Function(rev 01)
[root@jay-linux kvm demo]# 1s -1 /sys/bus/pci/devices/0000\:06\:00.1/virtfn*
lrwxrwxrwx 1 root root 0 Sep 27 17:22
/sys/bus/pci/devices/0000:06:00.1/virtfn0->../0000:06:10.1 lrwxrwxrwx 1 root root 0 Sep 27 17:22
/sys/bus/pci/devices/0000:06:00.1/virtfn1->../0000:06:10.3 lrwxrwxrwx 1 root root 0 Sep 27 17:22
/sys/bus/pci/devices/0000:06:00.1/virtfn2->../0000:06:10.5
由以上输出信息可知,两个PF分别为06:00.0和06:00.1,它们对应的VF分别为06:10.0、06:10.2、06:10.4和06:10.1、06:10.3、06:10.5。06:00.1这个PF在宿主机中是正常工作的,可以看到它有对应的IP地址。
2)将其中一个VF(06:10.1)隐藏,以供客户机使用,命令行操作如下:
[root@jay-linux kvm_demo]# 1spci -k -s 06:10.1
06:10.1 Ethernet controller: Intel Corporation X540 Ethernet
Controller Virtual Function(rev 01)
Subsystem:Intel Corporation Device 35a0
[root@jay-linux kvm_demo]# ./pcistub.sh -h 06:10.1
0000:06:10.1 wasn't bound to any drirver
Binding 0000:06:10.1 to pci-stub
[root@jay-linux kvm_demo]# 1spci -k -s 06:10.1
06:10.1 Ethernet controller: Intel Corporation X540 Ethernet
Controller Virtual Function (rev 01)
Subsystem:Intel Corporation Device 35a0
Kernel driver in use:pci-stub
这里隐藏的06:10.1这个VF对应的PF是06:00.1,该PF处于可用状态,才能让VF能在客户机中正常工作。其实这里的06:10.1 VF在使用pcistub.sh脚本前也没有在系统中加载ixgbevf驱动,它没有处于使用中状态(lspci-k-s$BDF命令的输出中没有"Kernel driver in use"这一行),这时不需要用pci_stub模块去隐藏它,也是可以直接将它分配给客户机使用的。而依然使用pci_stub去隐藏它,其中一个好处是标识它处于隐藏中,可能已被分配给客户机使用,另一个好处是宿主机加载ixgbevf驱动也对这个已被隐藏的VF没有影响。
3)在命令行启动客户机时分配一个VF网卡,命令行操作如下:
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -smp 2 -m 1024 -device pci-assign,host=08:00.0 -net none
VNC server running on ':1:5900'
4)在客户机中,查看VF的工作情况,命令行操作如下:
[root@kvm-guest ~]# lspci -k -s 00:03.0
00:03.0 Ethernet controller: Intel Corporation X540 Ethernet
Controller Virtual Function(rev 01)
Subsystem: Intel Corporation Device 35a0
Kernel driver in use:ixgbevf
Kernel modules:ixgbevf
[root@kvm-guest~]#1smod | grep ixgbevf
ixgbevf 37948 0
[root@kvm-guest~]# ethtool -i eth2
driver: ixgbevf
version: 2.2.0-k
firmware-version:
bus-info: 0000:00:03.0
[root@kvm-guest ~]# ifconfig eth2
[root@kvm-guest~]# ping 192.168.199.98-c 1
PING 192.168.199.98(192.168.199.98)56(84)bytes of data.
64 bytes from 192.168.199.98: icmp_seq=1 ttl=64 time=0.589 ms
--- 192.168.199.98 ping statistics ---
l packets transmitted, 1 received, 0% packet loss, time 676ms
rtt min/avg/max/mdev=1.794/1.794/1.794/0.000 ms
由上面的输出信息可知,00:03.0就是那个VF,它的PCI信息与在宿主机中看到的是一致的(X540 Ethernet Controller Virtual Function),使用的是ixgbevf驱动,而且它获得了IP地址,网络连接也是畅通的。不过,有时可能遇到客户机中VF的网络并没有连通的情况,可能需要重新加载对应的驱动程序(如igbvf、ixgbevf等)。
3. SR-IOV使用问题解析
在使用SR-IOV时,可能也会遇到各种小问题,根据经验来介绍一些可能会遇到的问题及其解决方法。
(1)VF在客户机中MAC地址全为零
如果使用Linux 3.9及之后的版本作为宿主机的内核,则可能会在使用igb或ixgbe驱动的网卡(如Intel 82576、I350、82599等)的VF进行SR-IOV时,在客户机中看到igbvf或ixgbevf网卡的MAC地址全为零(即00:00:00:00:00:00),从而导致VF不能正常工作。比如,在一个Linux客户机的dmesg命令的输出信息中,可能会看到如下的错误信息:
igbvf 0000:00:03.0:irq 26 for MSI/MSI-X
igbvf 0000:00:03.0:Invalid MAC Address:00:00:00:00:00:00
igbvf: probe of 0000:00:03.0 failed with error -5
关于这个问题,曾向Linux/KVM社区报过一个bug,其网页链接为:https://bugzilla.kernel.org/show_bug.cgi?id=55421。
这个问题的原因是,从Linux 3.9开始内核代码中的igb或ixgbe驱动程序在进行SR-IOV时,会将VF的MAC地址设置为全是零,而不是像之前那样使用一个随机生成的MAC地址。这样调整主要也是为了解决两个问题:一是随机的MAC地址对Linux内核中的设备管理器udev很不友好,多次使用VF可能会导致VF在客户机中的以太网络接口名称持续变化(如可能变为eth100);二是随机生成的MAC地址并不能完全保证其唯一性,有很小的概率可能与其他网卡的MAC地址重复而产生冲突。
对于VF的MAC地址全为零的问题,可以通过如下两种方法之一来解决。
在分配VF给客户机之前,在宿主机中用ip命令来设置需要使用的VF的MAC地址,命令行操作实例如下:
[root@jay-linux~]# ip link set eth0 vf 0 mac 0:1E:608
在上面的命令中,eth0为宿主机中PF对应的以太网接口名称,0代表设置的VF是该PF的编号为0的VF(即第一个VF)。那么,如何确定这个VF编号对应的PCI-E设备的BDF编号呢?可以使用如下的两个命令来查看PF和VF的关系。
[root@jay-linux ~]# ethtool -i eth0
driver: igb
version: 4.1.2-k
firmware-version: 1.64,0x800006fc
bus-info:0000: 0a:00.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: yes
supports-register-dump: yes
supports-priv-flags: no
[rootejay-linux-]# 1s -1 /sys/bus/pci/devices/0000:0a:00.0/virtfn*
lrwxrwx 1 root root 0 Apr 23 15:09 /sys/bus/pci/devices/0000:0a:00.0/virtfn0 -> ../0000:0b:10.0
1rwxrwxrwx 1 root root 0 Apr 23 15:09 /sys/bus/pci/devices/0000:0a:00.0/virtfn1 -> ../0000:0b:10.4
<!--此处省略其余VF的对应关系 -->可以升级客户机系统的内核或VF驱动程序,比如可以将Linux客户机升级到使用Linux 3.9之后的内核及其对应的igbvf驱动程序。最新的igbvf驱动程序可以处理VF的MAC地址为零的情况。
(2)Windows客户机中关于VF的驱动程序
对于Linux系统,宿主机中PF使用的驱动(如igb、ixgbe等)与客户机中VF使用的驱动(如igbvf、ixgbevf等)是不同的。当前流行的Linux发行版(如RHEL、Fedora、Ubuntu等)中都默认带有这些驱动模块。而对于Windows客户机系统,Intel网卡(如82576、82599等)的PF和VF驱动是同一个,只是分为32位和64位系统两个版本。有少数的最新Windows系统(如Windows 8、Windows 2012 Server等)默认带有这些网卡驱动,而多数的Windows系统(如Windows 7、Windows 2008 Server等)都没有默认带有相关的驱动,需要自行下载安装,例如前面提及的Intel网卡驱动可以到其官方网站(http://downloadcenter.intel.com/Default.aspx)下载。
(3)少数网卡的VF在少数Windows客户机中不工作
在进行SR-IOV的实验时,可能遇到VF在某些Windows客户机中不工作的情况。就遇到这样的情况,在用默认的qemu-kvm命令行(如步骤3所示)启动客户机后,Intel的82576、82599网卡的VF在32位Windows 2008Server版的客户机中不能正常工作,而在64位客户机中的工作正常。该问题的原因不在于Intel的驱动程序也不在于KVM中SR-IOV的逻辑不正确,而是在于默认的CPU模型是qemu64,它不支持MSI-X这种中断方式,而32位的Windows 2008 Server版本中的82576、82599网卡的VF只能用MSI-X中断方式来工作。
所以,需要在通过命令行启动客户机时指定QEMU模拟的CPU的类型,从而可以绕过这个问题。可以用"-cpu SandyBridge"、"-cpu Westmere"等参数来指定CPU类型,也可以用"-cpu host"参数来尽可能多地将物理CPU信息暴露给客户机,还可以用"-cpu qemu64,model=13"这样来改变qemu64类型CPU的默认模型。通过命令行启动一个32位Windows 2008 Server客户机,并分配一个VF给它使用,命令行操作如下:
[root@jay-linux kym demol# qemu-system-x86_64 32bit-win2k8.img -smp 2 -cpu SandyBridge -m 1024 -device pci-assign,host=08:00.0 -net none
在客户机中,网卡设备正常显示,网络连通状态正常。
4、热插拔
热插拔(hot plugging)即“带电插拔”,指可以在电脑运行时(不关闭电源)插上或拔除硬件。热插拔最早出现在服务器领域,是为了提高服务器扩展性、灵活性和对灾难的及时恢复能力。实现热插拔需要有几方面支持:总线电气特性、主板BIOS、操作系统和设备驱动。目前,在服务器硬件中,可实现热插拔的部件主要有SATA硬盘(IDE不支持热插拔)、CPU、内存、风扇、USB、网卡等。在KVM虚拟化环境中,在不关闭客户机的情况下,也可以对客户机的设备进行热插拔。目前,KVM对热插拔的支持还不够完善,主要支持PCI设备和CPU的热插拔,也可以通过ballooning间接实现内存的热插拔。
1. PCI 设备热插拔
前面5.2中介绍的VT-d设备直接分配和SR-IOV技术时都是在客户机启动时就分配相应的设备,将介绍可以通过热插拔来添加或删除这些PCI设备。QEMU/KVM不仅支持动态添加和动态移除设备,而且在启动客户机的qemu-kvm命令行中分配的普通VT-d设备或SR-IOV的VF设备也可以被动态移除。
PCI设备的热插拔,主要需要如下几个方面的支持。
(1)BIOS
QEMU/KVM默认使用SeaBIOS[9]作为客户机的BIOS,该BIOS文件路径一般为/usr/local/share/qemu/bios.bin,目前默认的BIOS已经可以支持PCI设备的热插拔。
(2)PCI总线
物理硬件中必须有VT-d的支持,且现在的PCI、PCIe总线都支持设备的热插拔。
(3)客户机操作系统
多数流行的Linux和Windows操作系统都支持设备的热插拔。可以在客户机的Linux系统的内核配置文件中看到一些相关的配置,如下是RHEL 6.3系统中的部分相关配置。
CONFIG_HOTPLUG=y
CONFIG_HOTPLUG_PCI_PCIE=y
CONFIG_HOTPLUG_PCI=y
CONFIG_HOTPLUG_PCI_FAKE=m
CONFIG_HOTPLUG_PCI_ACPI=y
CONFIG_HOTPLUG_PCI_ACPI_IBM=m
(4)客户机中的驱动程序
一些网卡驱动(如Intel的e1000e、igb、ixgbe、igbvf、ixgbevf等)、SATA或SAS磁盘驱动、USB2.0、USB3.0驱动都支持设备的热插拔。注意,在一些较旧的Linux系统(如RHEL 5.5)中需要加载"acpiphp"(使用"modprobe acpiphp"命令)这个模块后才支持设备的热插拔,否则热插拔完全不会对客户机系统生效;而较新内核的Linux系统(如RHEL 6.3、Fedora 17等)中已经没有该模块,不需要加载该模块,默认启动的系统就支持设备热插拔。
有了BIOS、PCI总线、客户机操作系统和驱动程序的支持后,热插拔功能只需要在QEMU monitor中的两个命令即可完成热插拔功能。
将一个BDF为02:00.0的PCI设备动态添加到客户机中(设置id为mydevice),在monitor中的命令如下:
device_add pci-assign,host=02:00.0,id=mydevice
将一个设备(id为mydevice)从客户机中动态移除,在monitor中的命令如下:
device_del mydevice
这里的mydevice是在添加设备时设置的唯一标识,可以通过"info pci"命令在QEMU monitor中查看到当前的客户机中的PCI设备及其id值。已经提及,在命令行启动客户机时分配设备也可以设置这个id值,如果这样,那么也就可以用"device_del id"命令将该PCI设备动态移除。
如果在动态添加PCI设备后,在客户机中用"lspci"命令可以查看到该设备,但是该设备实际并不可以使用,这有可能会是宿主机内核的一个bug。这需要在客户机卸载驱动后重新加载该设备的驱动才能让设备正常工作,就曾经遇到个这样的一个bug(https://bugzilla.kernel.org/show_bug.cgi?id=47451)。
2. PCI设备热插拔示例
在介绍了PCI设备热插拔所需的必要条件和操作命令之后,分别以网卡、U盘、SATA硬盘的热插拔为例来演示具体的操作过程。
1)网卡的热插拔
启动一个客户机,不向它分配任何网络设备,命令行如下:
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -m 1024 -smp 2 -net none
VNC server running on '::1:5900'选择并用pci-stub隐藏一个网卡设备供热插拔使用,命令行如下:
[root@jay-linux kvm_demo]# 1spci -s 06:10.1
06:10.1 Ethernet controller: Intel Corporation X540 Ethernet Controller Virtual Function(rev 01)
[root@jay-linux kym demo]# ./pcistub.sh-h 06:10.1
Unbinding 0000:06:10.1 from ixgbevf
Binding 0000:06:10.1 to pci-stub
这里选取了Intel X540网卡的一个SR-IOV VF作为热插拔的设备。
切换到QEMU monitor中,将网卡动态添加到客户机中,命令如下所示。一般可以用"Alt+Ctrl+2"快捷键进入到monitor中,也可以在启动时添加参数"-monitor stdio"将monitor定向到当前终端的标准输入输出中直接进行操作。
(qemu) device_add pci-assign,host=06:10.1,id=mynic在QEMU monitor中查看客户机的PCI设备信息,命令如下:
(qemu) info pci
Bus 0,device 0,function 0:
Host bridge:PCI device 8086:1237
id ""
<!-- 此处省略多行其他PCI设备的信息输出 -->
Bus 0, device 3, function 0:
Ethernet controller:PCI device 8086:1515
BAR0: 32 bit memory at 0x400000000 [0x40003fff].
BAR3: 32 bit memory at 0x40004000 [0x40007fff].
id "mynic"
由以上信息可知,"Bus 0,device 3,function 0"的设备就是动态添加的网卡设备。
在客户机中检查动态添加和网卡工作情况,命令行如下:
[root@kvm-guest~]# lspci | grep Eth
00:03.0 Ethernet controller:Intel Corporation X540 Ethernet
Controller Virtual Function(rev 01)
[root@kvm-guest ~]# ethtool -i eth2
driver: ixgbevf
version: 2.2.0-k
firmware-version:
bus-info: 0000:00:03.0
[root@kvm-guest ~]# ifconfig eth2
[root@kvm-guest~]# ping 192.168.199.103 -c 1 -I eth2
由以上输出信息可知,动态添加的网卡是客户机中唯一的网卡设备,其网络接口名称为"eth2",它的网络连接是通畅的。
将刚添加的网卡动态地从客户机中移除,命令行如下:
(qemu) device_del mynic
将网卡动态移除后,在monitor中用"info pci"命令将没有刚才的PCI网卡设备信息,在客户机中"lspci"命令也不能看到客户机中有网卡设备的信息。
2)USB设备的热插拔
USB设备是现代计算机系统中比较重要的一类设备,包括USB的键盘和鼠标、U盘,还有现在网上银行经常可能用到的USB认证设备(如工商银行的“U盾”)。如前面讲到的那样,USB设备也可以像普通PCI设备那样进行VT-d设备直接分配,而在热插拔方面也是类似的。下面以U盘的热插拔为例来介绍一下操作过程。
U盘的热插拔操作步骤和前面介绍网卡热插拔的步骤基本是一致的,只是需要注意:qemu-kvm默认没有向客户机提供USB总线,需要在启动客户机的qemu-kvm命令行中添加"-usb"参数(或"-device piix3-usb-uhci"参数)来提供客户机中的USB总线。另外,对于USB设备,在QEMU monitor中除了可以用"device_add"和"device_del"命令之外,也有两个专门的命令(usb_add和usb_del)用于对USB进行热插拔操作。
查看宿主机中的USB设备情况,然后启动一个带有USB总线控制器的客户机,命令行如下:
[root@jay-linux kvm_demo]# 1susb
Bus 002 Device 002:ID 8087:0024 Intel Corp. Integrated Rate Matching Hub
Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub 、
Bus 002 Device 004:ID 0781:5567 SanDisk Corp.Cruzer Blade
Bus 002 Device 003: ID 046b:ff10 American Megatrends, Inc. Virtual
Keyboard and Mouse
[root@jay-linux kym demo]# qemu-system-x86_64 rhel6u3.img -m 1024 -smp 2 -net none
VNC server running on ':1:5900'
切换到QEMU monitor窗口,动态添加SanDisk的U盘给客户机,使用"usb_add"命令行如下:
(qemu) usb_add host:002.004
或者:
(qemu) usb_add host:0781:5567
在“VT-d操作示例”中那样查找到宿主机中USB controller对应的PCI BDF,对其进行隐藏,然后使用device_add命令动态添加设备的命令如下:
(qemu) device_add pci-assign,host=00:1d.0,id=myusb
解释一下"usb_add"这个用于动态添加一个USB设备的命令,在monitor中命令格式如下:
usb_add devname
其中devname是对该USB设备的唯一标识,该命令支持两种devname的格式:一种是USB hub中的Bus和Device号码的组合,一种是USB的vendor ID和device ID的组合。
举个例子,对于该宿主机中的一个SanDisk的U盘设备(前一步的lsusb命令),devname可以设置为“002.004”和“0781:5567”两种格式。另外,需要像上面命令行操作的那样,用"host:002.004"或"host:0781:5567"来指定分配宿主机中的USB设备给客户机。
在客户机中,查看动态添加的USB设备,命令行如下:
[root@kvm-guest~]# lsusb
Bus 001 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 001 Device 002:ID 0781:5567 SanDisk Corp.Cruzer Blade
[root@kvm-guest~]# fdisk -1 /dev/sdb
Disk /dev/sdb:16.0 GB,16008609792 bytes 21 heads, 14 sectors/track, 106349 cylinders
Units = cylinders of 294 * 512 = 150528 bytes
Sector size(logical/physical):512bytes / 512 bytes
I/O size(minimum/optimal):512bytes / 512 bytes
Disk identifier: 0xcad4ebea
可见,USB设备已经添加成功了,在客户机中可以正常使用该U盘了。
在QEMU monitor中查看USB设备,然后动态移除USB设备命令行操作如下:
(qemu) info usb
Device 0.2,Port 1,Speed 480 Mb/s,Product Cruzer Blade
(qemu) usb_del 0.2
(qemu) info usb
由上面的输出信息可知,移除前,"info usb"命令可以看到USB设备,在用"usb_del"命令移除后,"info usb"就没有查看到任何USB设备了。注意,usb_del命令后的参数是"info usb"命令查询出来的"Device"后的地址标识,这里为“0.2”。
发现在qemu-kvm 1.1版本中有个bug,在"usb_del 0.2"命令执行后,客户机qemu-kvm进程发生core dumped的错误,然后客户机进程被杀掉,换用较新的qemu-kvm1.2版本就正常操作了。
当然,如果使用device_add命令动态添加的USB设备,则使用如下device_del命令将其移除:
(qemu) device_del myusb
3. SATA硬盘的热插拔
与5“VT-d操作示例”类似,宿主机从一台机器上的SAS硬盘启动,然后将SATA硬盘动态添加给客户机使用,接着动态移除该硬盘。
检查宿主机系统,得到需要动态热插拔的SATA硬盘(实际上用的是整个SATA控制器),并将其用pci-stub模块隐藏起来以供热插拔使用,命令行操作如下:
[root@jay-linux kvm_demo]# 1spci | grep SATA
00:1f.2 SATA controller:Intel Corporation 82801JI
SATA AHCI Controller
[root@jay-linux kvm_demo]# 1spci | grep SAS
16:00.0 SCSI storage controller:LSI Logic / Symbios Logic SAS1078
PCI-Express Fusion-MPT SAS (rev 04)
[root@jay-linux kvm_demo]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sdal 197G 76G 112G 41% /
tmpfs 12G 76K 12G 1% /dev/shm
[root@jay-linux kvm_demo]# 11
/dev/disk/by-path/pci-00000\:16\:00.0-sas-0x12210000000000-1un-0
1rwxrwx 1 root root 9 Oct 29 15:28
/dev/disk/by-path/pci-00000:16:00.0-sas-0x122100000000000-lun-0 -> ../../sda
[root@jay-linux kvm_demo]# 11
/dev/disk/by-path/pci-0000\:00\:1f.2-scsi-0\:0\:0\:0\:0
lrwxrwxrwx 1 root root 9 Oct 29 15:28
/dev/disk/by-path/pci-0000:00:1f.2-scsi-0:0:0:0->././sdb
[root@jay-linux kvm_demo]# 1spci -k -s 00:1f.2
00:1f.2 SATA controller:Intel Corporation 82801JI (ICH10 Family)
SATA AHCI Controller
Subsystem:Intel Corporation Device 34f8
Kernel driver in use: ahci
Kernel modules: ahci
[root@jay-linux kvm_demo]#./pcistub.sh -h 00:1f.2
Unbinding 0000:00:1f.2 from ahci
Binding 0000:00:1f.2 to pci-stub
[root@jay-linux kvm_demo]# 1spci -k -s 00:1f.2
00:1f.2 SATA controller:Intel Corporation 82801JI(ICH10 Family)
SATA AHCI Controller
Subsystem:Intel Corporation Device 34f8
Kernel driver in use:pci-stub
Kernel modules:ahci启动一个客户机,命令行如下:
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -m 1024 -smp 2 -net nic -net tap
VNC server running on ':1:5900'
在QEMU monitor中,动态添加该SATA硬盘,命令行如下:
(qemu) device_add pci-assign,host=00:1f.2,id=sata,addr=0x06
(qemu) info pci #查看客户机中pci设备,可以看到动态添加的SATA控制器
Bus 0,device 6,function 0:
SATA controller:PCI device 8086:3a22
IRQ 9.
BAR0: I/O at 0x1020 [0x1027].
BAR1: I/O at 0x1030 [0x1033].
BAR2:I/O at 0x1028 [0x102f].
BAR3:I/O at 0x1034 [0x1037].
BAR4:I/O at 0x1000 [0x101f].
BAR5:32 bit memory at 0x40000000 [0x400007ff].
id "sata"
在客户机中查看动态添加的SATA硬盘,命令行如下:
[root@kvm-guest ~]# fdisk -1 /dev/sdb
[root@kvm-guest~]# lspci -k -s 00:06.0
00:06.0 SATA controller:Intel Corporation 82801JI(ICH10 Family)
SATA AHCI Controller
Subsystem:Intel Corporation Device 34f8
Kernel driver in use: ahci
Kernel modules: ahci
由以上信息可知,客户已经能够获取到SATA硬盘(/dev/sdb)的信息,然后就可以正常使用动态添加的该硬盘了。
在客户机中使用完SATA硬盘后,可以动态移除SATA硬盘,在QEMU monitor中命令行如下:
(qemu) device_del sata
在动态移除SATA硬盘后,客户机中将没有SATA硬盘的设备,宿主机又可以控制SATA硬盘,将其用于其他用途(包括分配给另外的客户机使用)。
4. CPU和内存的热插拔
CPU和内存的热插拔是RAS(Reliability、Availability和Serviceability)的一个重要特性,在非虚拟化环境中,只有较少的x86服务器硬件支持CPU和内存的热插拔(曾在Intel的Westmere-EX平台上做过物理CPU和内存的热插拔)。在操作系统方面,拥有较新内核的Linux系统(如RHEL6.3)等已经支持CPU和内存的热插拔,在其内核配置文件中可以看到类似如的下选项。
CONFIG_HOTPLUG=y
CONFIG_MEMORY_HOTPLUG=y
CONFIG_HOTPLUG_CPU=y
CONFIG_ARCH_ENABLE_MEMORY_HOTPLUG=y
CONFIG_ARCH_ENABLE MEMORY HOTREMOVE=y
CONFIG_ACPI_HOTPLUG_CPU=y
CONFIG_ACPI_HOTPLUG_MEMORY=y而在QEMU/KVM虚拟化环境中,对CPU和内存的热插拔支持也不完善。CPU的热插拔功能有一段时间在QEMU/KVM中是可以工作的,下面简单介绍一下CPU热插拔的操作步骤。
在qemu-kvm命令行中启动客户机时,使用"-smp n,maxvcpus=N"的参数,如下:
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -m 1024 -smp 2,maxvcpus=8 -net nic -net tap
VNC server running on '::1:5900'
这就是在客户机启动时使用的两个vCPU,而最多支持客户机动态添加到8个vCPU。
在客户机中检查CPU的状态,如下:
[root@kvm-guest ~]# 1s /sys/devices/system/cpu/
cpu0 cpul cpufreq cpuidle kernel_max offline online
通过QEMU monitor中的"cpu_set n online"命令为客户机添加n个vCPU,如下:
(qemu) cpu_set 4 online
而动态移除n个vCPU的命令为"cpu_set n offline"。
检查客户机中vCPU的数量是否与预期的相符,如果看到"/sys/devices/system/cpu/"目录下CPU的数量增加(或减少)了n个,则表示操作成功了。另外,如果是动态添加CPU,客户机中新增的CPU没有自动上线工作,可以用"echo 1>/sys/devices/system/cpu/cpu2/online"命令使其进入可用状态。
也是可以动态改变客户机中可用的内存大小,可以算是间接地实现内存热插拔功能。
另外,据了解,QEMU/KVM社区也考虑将CPU和内存的热插拔做成普通PCI/PCI-e设备热插拔的形式,但没有具体的时间点实现该功能,目前也没有太多的补丁去实现这个功能。
5、动态迁移
迁移(migration)包括系统整体的迁移和某个工作负载的迁移。系统整体迁移,是将系统上的所有软件(也包括操作系统)完全复制到另一台物理硬件机器之上。而工作负载的迁移,是将系统上的某个工作负载转移到另一台物理机器上继续运行。服务器系统迁移的作用在于简化了系统维护管理,提高了系统负载均衡,增强了系统容错性并优化了系统电源管理。
虚拟化的概念和技术的出现,给迁移带来了更丰富的含义和实践。在传统应用环境中,没有虚拟化技术的支持,系统整体的迁移主要都是静态迁移。这种迁移主要依靠系统备份和恢复技术,将系统的软件完全复制到另一台机器上,可以通过先做出系统的镜像文件,然后复制到其他机器上,或者通过直接的硬盘相互复制来实现迁移的目的。在非虚拟化环境中也有动态迁移的概念,但都是对某个(或某一组)工作负载的迁移,需要特殊系统的支持才能实现,而且技术也不够成熟,如哥伦比亚大学的Zap[11]系统,它通过在操作系统上提供了一个很薄虚拟化层(这和现在主流的虚拟化技术不一样),可以实现将工作负载迁移到另一台机器上。
在虚拟化环境中的迁移,又分为静态迁移(static migration)和动态迁移(live migration),也有少部分人称之为冷迁移(cold migration)和热迁移(hot migration),或者离线迁移(offline migration)和在线迁移(online migration)。静态迁移和动态迁移最大的区别就是,静态迁移有明显一段时间客户机中的服务不可用,而动态迁移则没有明显的服务暂停时间。虚拟化环境中的静态迁移,也可以分为两种,一种是关闭客户机后,将其硬盘镜像复制到另一台宿主机上然后恢复启动起来,这种迁移不能保留客户机中运行的工作负载;另一种是两台宿主机共享存储系统,只需要在暂停(而不是完全关闭)客户机后,复制其内存镜像到另一台宿主机中恢复启动,这种迁移可以保持客户机迁移前的内存状态和系统运行的工作负载。
动态迁移,是指在保证客户机上应用服务正常运行的同时,让客户机在不同的宿主机之间进行迁移,其逻辑步骤与前面静态迁移几乎一致,有硬盘存储和内存都复制的动态迁移,也有仅复制内存镜像的动态迁移。不同的是,为了保证迁移过程中客户机服务的可用性,迁移过程仅有非常短暂的停机时间。动态迁移允许系统管理员将客户机在不同物理机上迁移,同时不会断开访问客户机中服务的客户端或应用程序的连接。一个成功的动态迁移,需要保证客户机的内存、硬盘存储、网络连接在迁移到目的主机后依然保持不变,而且迁移过程的服务暂停时间较短。
另外,对于虚拟化环境的迁移,不仅包括相同Hypervisor之间的客户机迁移(如KVM迁移到KVM、Xen迁移到Xen),还包括不同Hypervisor之间的客户机迁移。
1. 动态迁移的效率和应用场景
虚拟机迁移主要增强了系统的可维护性,其主要目标是在客户没有感觉的情况下,将客户机迁移到了另一台物理机器上,并保证其各个服务都正常使用。
可以从如下几个方面来衡量虚拟机迁移的效率。
- 整体迁移时间:从源主机(source host)中迁移操作开始到客户机被迁移到目的主机(destination host)并恢复其服务所花费的时间。
- 服务器停机时间(service down-time):在迁移过程中,源主机和目的主机上客户机的服务都处于不可用状态的时间,此时源主机上客户机已暂停服务,目的主机上客户机还未恢复服务。
- 对服务的性能影响:不仅包括迁移后的客户机中应用程序的性能与迁移前相比是否有所降低,还包括迁移后对目的主机上的其他服务(或其他客户机)的性能影响。
动态迁移的整体迁移时间受诸多因素的影响,如Hypervisor和迁移工具的种类、磁盘存储的大小(如果需要复制磁盘镜像)、内存大小及使用率、CPU的性能及利用率、网络带宽大小及是否拥塞等,整体迁移时间一般为几秒钟到几十分钟不等。
动态迁移的服务停机时间,也是受Hypervisor的种类、内存大小、网络带宽等因素的影响,服务停机时间一般在几毫秒到几秒钟不等。其中,服务停机时间在几毫秒到几百毫秒,而且在终端用户毫无察觉的情况下实现迁移,这种动态迁移也被称为无缝的动态迁移。而静态迁移的服务暂停时间一般都较长,少则几秒钟,多则几分钟,需要依赖于管理员的操作速度和CPU、内存、网络等硬件设备。所以说,静态迁移一般适合于对服务可用性要求不高的场景,而动态迁移的停机时间很短,适合对服务可用性要求较高的场景。动态迁移一般对服务的性能影响不大,这与两台宿主机的硬件配置情况、Hypervisor是否稳定等因素相关。
动态迁移的好处是非常明显的了,下面来看一下动态迁移的几个应用场景。
- 负载均衡:当一台物理服务器的负载较高时,可以将其上运行的客户机动态迁移到负载较低的宿主机服务器中,以保证客户机的服务质量(QoS)。而前面提到的,CPU、内存的过载使用可以解决某些客户机的资源利用问题,之后当物理资源长期处于超负荷状态时,对服务器稳定性能和服务质量都有损害的,这时需要动态迁移来进行适当的负载均衡。
- 解除硬件依赖:当系统管理员需要在宿主机上升级、添加、移除某些硬件设备的时候,可以将该宿主机上运行的客户机非常安全高效地动态迁移到其他宿主机上。在系统管理员升级硬件系统之时,使用动态迁移,可以让终端用户完全感知不到服务有任何暂停时间。
- 节约能源:在目前的数据中心的成本支出中,其中有一项重要的费用是电能的开销。当有较多服务器的资源使用率都偏低时,可以通过动态迁移将宿主机上的客户机集中迁移到其中几台服务器上,而在某些宿主机上的客户机完全迁移走之后,就可以将关闭电源以节省电能消耗,从而降低数据中心的运营成本。
- 实现客户机地理位置上的远程迁移:假设某公司的运行某类应用服务的客户机本来仅部署在上海电信的IDC中,然后发现来自北京及其周边地区的网通用户访问量非常大,但是由于距离和网络互联带宽拥堵(如电信与网通之间的带宽),北方用户使用该服务的网络延迟较大,这时系统管理员可以将上海IDC中的部分客户机通过动态迁移部署到位于北京的北京网通的IDC中,从而让终端用户使用该服务的质量更高。
2. KVM动态迁移原理和实践
在KVM中,既支持离线的静态迁移,又支持在线的动态迁移。对于静态迁移,可以在源宿主机上某客户机的QEMU monitor中,用"savevm my_tag"命令来保存一个完整的客户机镜像快照(标记为my_tag),然后在源宿主机中关闭或暂停该客户机,然后将该客户机的镜像文件复制到另外一台宿主机中,用于源宿主机中启动客户机时以相同的命令启动复制过来的镜像,在其QEMU monitor中用"loadvm my_tag"命令来恢复刚才保存的快照即可完全加载保存快照时的客户机状态。这里的"savevm"命令保存的完整客户机状态包括CPU状态、内存、设备状态、可写磁盘中的内容。注意,这种保存快照的方法需要qcow2、qed等格式的磁盘镜像文件,因为只有它们才支持快照这个特性。
主要介绍KVM中比静态迁移更实用、更方便的动态迁移。如果源宿主机和目的宿主机共享存储系统,则只需要通过网络发送客户机的vCPU执行状态、内存中的内容、虚拟设备的状态到目的主机上。否则,还需要将客户机的磁盘存储发送到目的主机上去。
KVM中一个基于共享存储的动态迁移过程如图所示:

在不考虑磁盘存储复制的情况下(基于共享存储系统),KVM动态迁移的具体迁移过程为:在客户机动态迁移开始后,客户机依然在源宿主机上运行,与此同时,客户机的内存页被传输到目的主机之上。QEMU/KVM会监控并记录下迁移过程中所有已被传输的内存页的任何修改,并在所有的内存页都被传输完成后即开始传输在前面过程中内存页的更改内容。QEMU/KVM也会估计迁移过程中的传输速度,当剩余的内存数据量能够在一个可设定的时间周期(目前qemu-kvm中默认为30毫秒)内传输完成之时,QEMU/KVM将会关闭源宿主机上的客户机,再将剩余的数据量传输到目的主机上去,最后传输过来的内存内容在目的宿主机上恢复客户机的运行状态。
至此,KVM的一个动态迁移操作就完成了。迁移后的客户机状态尽可能与迁移前一致,除非目的主机上缺少一些配置,例如,在源宿主机上有给客户机配置好网桥类型的网络,但目的主机上没有网桥配置会导致迁移后客户机的网络不通。而当客户机中内存使用量非常大且修改频繁,内存中数据被不断修改的速度大于KVM能够传输的内存速度之时,动态迁移过程是不会完成的,这时要进行迁移只能进行静态迁移。就曾遇到这样的情况,KVM宿主机上一个拥有4个vCPU、4GB内存的客户机中运行着一个SPECjbb2005(一个基准测试工具),使客户机的负载较重且内存会频繁更新,这时进行动态迁移无论怎样也不能完成,直到客户机中SPECjbb2005测试工具停止运行后,迁移过程才能真正完成。
在KVM中,动态迁移服务停机时间会与实际的工作负载和网络带宽等诸多因素有关,一般在数十毫秒到几秒钟之间,当然如果网络带宽过小或网络拥塞,会导致服务停机时间变长。
必要的时候,服务器端在动态迁移时暂停数百毫秒或数秒钟后恢复服务,对于一些终端用户来说是可以接受的,可能会表现为:浏览器访问网页速度会慢一点,或者ssh远程操作过程中有一两秒不能操作但ssh连接并没有断开(不需要重新建立连接)。曾经测试过KVM动态迁移过程中的服务停机时间,当时在客户机中运行了一个UnixBench(一个基准测试工具),然后进行动态迁移,经过测量,某次动态迁移中服务停机时间约为900毫秒。
这次测试是通过在客户机中运行netperf(一个测试网络的基准测试工具)的服务端,在另外一台机器上运行netperf的客户端,通过查看netperf客户端收到服务端响应数据包在迁移过程中中断的间隔时间来粗略地估算客户机迁移过程中服务停机时间。
当次实验的粗略结果如图所示,可以看出时间从4.6秒到5.5秒为动态迁移过程中大致的服务停机时间。

从上面的介绍可知,KVM的动态迁移是比较高效也是很有用处的功能,在实际测试中也是比较稳定的(而且在多数情况下,就算迁移不成功,源宿主机上的客户机依然在运行)。
不过,对于KVM动态迁移,也有如下几点建议和注意事项。
- 源宿主机和目的宿主机之间尽量用网络共享的存储系统来保存客户机磁盘镜像,尽管KVM动态迁移也支持连同磁盘镜像一起复制(加上一个参数即可,后面会介绍到)。共享存储(如NFS)在源宿主机和目的宿主机上的挂载位置必须完全一致。
- 为了提高动态迁移的成功率,尽量在同类型CPU的主机上面进行动态迁移,尽管KVM动态迁移也支持从Intel平台迁移到AMD平台(或者反向)。不过在Intel的两代不同平台之间进行动态迁移一般是比较稳定的,如后面介绍实际操作步骤时,就是从一台Intel Westmere平台上运行的KVM中将一个客户机动态迁移到SandyBridge平台上。
- 64位的客户机只能在64位宿主机之间迁移,而32位客户机可以在32位宿主机和64位宿主机之间迁移。
- 动态迁移的源宿主机和目的宿主机对NX[12](Never eXecute)位的设置是相同,要么同为关闭状态,要么同为打开状态。在Intel平台上的Linux系统中,用"cat/proc/cpuinfo|grep nx"命令可以查看是否有NX的支持。
- 在进行动态迁移时,被迁移客户机的名称是唯一的,在目的宿主机上不能有与源宿主机中被迁移客户机同名的客户机存在。另外,客户机名称可以包含字母、数字和“_”、“.”、“-”等特殊字符。
- 目的宿主机和源宿主机的软件配置尽可能的相同,例如,为了保证动态迁移后客户机的中的网络依然正常工作,需要在目的宿主机上配置和源宿主机相同名称网桥,并让客户机以桥接的方式使用网络。
下面详细介绍在KVM上进行动态迁移的具体操作步骤,这里的客户机镜像文件存放在NFS的共享存储上面,源宿主机(vt-nhm9)和目的宿主机(vt-snb9)都对NFS上的镜像文件具有可读写权限。
在源宿主机挂载NFS的上客户机镜像,并启动客户机,命令行操作如下:
[root@vt-nhm9 jay]# mount my-nfs:/rw-images/ /mnt/
[root@vt-nhm9 jay]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sdal 197G 73G 115G 39% /
tmpfs 12G 76K 12G 1% /dev/shm
my-nfs:/rw-images/ 5.4T 2.3T 2.9T 45% /mnt
[root@vt-nhm9 jay]# qemu-system-x86_64 /mnt/ia32e_rhel6u3.img -smp 2 -m 2048 -net nic -net tap
VNC server running on '::1:5900'
这里的特别之处是没有指定客户机中的CPU模型,默认是qemu64这个基本的模型,当然也可自行设置为"-cpu SandyBridge"或"-cpu Westmere"等,不过要保证在目的主机上也用相同的命令。“CPU模型”中已提及,同时都指定相同的某个CPU模型是可以让客户机在不同的几代平台上迁移更加稳定。
另外,还在客户机中运行一个程序(这里执行了"top"命令),以便在动态迁移后检查它是否仍然正常地继续执行。
在动态迁移前,客户机可以运行了"top"命令查看状态。
目的宿主机上也挂载NFS上的客户机镜像的目录,并且启动一个客户机用于接收动态迁移过来内存内容等,命令行操作如下:
[root@vt-snb9 jay]# mount vt-nfs:/rw-images/ /mnt/
[root@vt-snb9 jay]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sdal 296G 172G 109G 62% /
tmpfs 16G 232K 16G 1% /dev/shm
my-nfs:/rw-images/ 5.4T 2.3T 2.9T 45% /mnt
[root@vt-snb9 jay]# qemu-system-x86_64 /mnt/ia32e_rhel6u3.img -smp 2 -m 2048 -net nic -net tap -incoming tcp:0:666
VNC server running on '::1:5901'在这一步骤中,目的宿主机上的操作,有两个值得注意的地方:一是NFS的挂载目录必须与源宿主机上保持完全一致;二是启动客户机的命令与源宿主机上的启动命令一致,但是需要增加"-incoming"的选项。
这里在启动客户机的qemu-kvm命令行中添加了"-incoming tcp:0:6666"这个参数,它表示在6666端口建立一个TCP Socket连接用于接收来自源主机的动态迁移的内容,其中“0”表示允许来自任何主机的连接。"-incoming"这个参数使这里的qemu-kvm进程进入到迁移监听(migration-listen)模式,而不是真正以命令行中的镜像文件运行客户机,从VNC中看到客户机是黑色的没有任何显示,没有像普通客户机一样启动,而是在等待动态迁移数据的传入。
在源宿主机的客户机的QEMU monitor(默认用Ctrl+Alt+F2快捷键进入monitor)中,使用命令"migrate tcp:vt-snb9:6666"即可进入动态迁移的流程。
这里的vt-snb9为目的宿主机的主机名(写为IP也是可以的),tcp协议和6666端口号与目的宿主机上qemu-kvm命令行的"-incoming"参数中的值保持一致。
在QEMU monitor中使用"migrate"命令进行动态迁移 :

在本示例中,migrate命令从开始到执行完成,大约用了十秒钟。在执行完迁移后,在目的主机上,之前处于迁移监听模式的客户机就开始正常运行了,其中运行的正是动态迁移过来的客户机,可以看到客户机中的"top"命令在迁移后继续运行。
动态迁移后,客户机中的"top"命令依然在继续运行。
至此,使用NFS作为共享存储的动态迁移就已经正确完成了。当然,QEMU/KVM中也支持增量复制磁盘修改部分数据(使用相同的后端镜像时)的动态迁移,以及直接复制整个客户机磁盘镜像的动态迁移。使用相同后端镜像文件的动态迁移过程如下,与前面直接使用NFS共享存储非常类似。
在源宿主机上,根据一个后端镜像文件,创建一个qcow2格式的镜像文件,并启动客户机,命令行如下:
[root@vt-nhm9 jay]# qemu-img create -f qcow2 -o backing_file=/mnt/ia32e_rhel6u3.img,size=20G rhe16u3.qcow2
Formatting 'rhel6u3.qcow2',fmt=qcow2 size=21474836480
backing_file='/mnt/ia32e_rhel6u3.img' encryption=off
cluster_size=65536 lazy refcounts=off
[root@vt-nhm9 jay]# qemu-system-x86_64 rhel6u3.qcow2 -smp 2 -m 2048 -net nic -net tap
VNC server running on '::1:5900'这里使用前面挂载的NFS上的镜像文件作为qcow2的后端镜像。关于qemu-img命令的详细使用方法,可以参考前面的“qemu-img命令”。
在目的宿主机上,也建立相同的qcow2格式的客户机镜像,并带有"-incoming"参数来启动客户机使其处于迁移监听状态,命令行如下:
[root@vt-snb9 jay]# qemu-img create -f qcow2 -o backing_file=/mnt/ia32e_rhel6u3.img,size=20G rhel6u3.qcow2
Formatting 'rhel6u3.qcow2',fmt=qcow2 size=21474836480
backing_file='/mnt/ia32e rhel6u3.img' encryption=off
cluster_size=65536 lazy_refcounts=off
[root@vt-snb9 jay]# qemu-system-x86_64 rhel6u3.qcow2 -smp 2 -m 2048 -net nic -net tap -incoming tcp:0:666
VNC server running on ':1:5901'
在源宿主机上的客户机的QEMU monitor中,运行"migrate-i tcp:vt-snb9:6666"命令即可进行动态迁移("-i"表示increasing,增量的),在迁移过程中,还有实时的迁移百分比显示,如果提示为"Completed 100%"即表示迁移完成。
与此同时,在目的宿主机上,在启动迁移监听状态的客户机的命令行所在标准输出中,也会提示正在传输的(增量的)磁盘镜像百分比,当传输完成时也会提示"Completed 100%",如下:
[root@vt-snb9 jay]# qemu-system-x86_64 rhel6u3.qcow2 -smp 2 -m 2048 -net nic -net tap -incoming tcp:0:6666
VNC server running on ':1:5901'
Receiving block device images
Completed 100 %
Completed 100 %
至此,基于相同后端镜像的磁盘增量动态迁移就已经完成,在目的宿主机上可以看到迁移过来的客户机已经处于正常运行状态。在本示例中,由于qcow2文件中记录的增量较小(小于1GB),因此整个迁移过程花费了约20秒钟的时间。
如果不使用后端镜像的动态迁移,将会传输完整的客户机磁盘镜像(可能需要更长的迁移时间),其步骤与上面类似,只有两点需要修改:一是不需要用"qemu-img"命令创建qcow2格式的增量镜像整个步骤;二是QEMU monitor中的动态迁移的命令变为"migrate-b tcp:vt-snb9:6666"(-b参数意为block,传输块设备)。
最后介绍在QEMU monitor中与动态迁移相关的几个命令,可以用"help command"来查询命令的用法,如下:
(qemu) help migrate
migrate [-d] [-b] [-i] uri -- migrate to URI (using -d to not wait for completion)
-b for migration without shared storage with full copy of disk
-i for migration without shared storage with incremental
copy of disk (base image shared between src and destination)
(qemu) help migrate_cancel
migrate_cancel -- cancel the current VM migration
(qemu) help migrate_set_speed
migrate_set_speed value -- set maximum speed (in bytes)
for migrations. Defaults to MB if no size suffix is specified,ie.B/K/M/G/T
(qemu) help migrate_set_downtime
migrate_set_downtime value -- set maximum tolerated downtime (in seconds) for migrations
(qemu) info migrate ##show migration status
对于"migrate[-d][-b][-i]uri"命令,其中uri为uniform resource identifier(统一资源标识符),在上面的示例中就是"tcp:vt-snb9:6666"这样的字符串,在不加"-b"和"-i"选项的情况下,默认是共享存储下的动态迁移(不传输任何磁盘镜像内容)。"-b"和"-i"选项前面也都提及过,"-b"选项表示传输整个磁盘镜像,"-i"选项是在有相同的后端镜像的情况下增量传输qcow2类型的磁盘镜像,而"-d"选项是不用等待迁移完成就让QEMU monior处于可输入命令的状态(在前面的示例中都没有使用"-d"选项,所以在动态迁移完成之前"migrate"命令会完全占有monitor操作界面,而不能输入其他命令)。
"migrate_cancel"命令,是在动态迁移进行过程中取消迁移(在"migrate"命令中需要使用"-d"选项才能有机会在迁移完成前操作"migrate_cancel"命令)。
"migrate_set_speed value"命令,设置动态迁移中的最大传输速度,可以带有B、K、G、T等单位,表示每秒钟传输的字节数。在某些生产环境中,如果动态迁移消耗了过大的带宽,可能会让网络拥塞,从而降低其他服务器的服务质量,这时也可以设置动态迁移用的合适的速度。
"migrate_set_downtime value"命令,设置允许的最大停机时间,单位是秒,value的值可以是浮点数(如0.5)。qeum-kvm会预估最后一步的传输需要花费的时间,如果预估时间大于这里设置的最大停机时间,则不会做最后一步迁移,直到预估时间小于等于设置的最大停机时间时才会完成最后迁移,暂停源宿主机上的客户机,然后传输内存中改变的内容。
3. VT-d/SR-IOV的动态迁移
前面已经介绍过,使用VT-d、SR-IOV等技术,可以让设备(如网卡)在客户机中获得非常良好的、接近原生设备的性能。不过,当QEMU/KVM中有设备直接分配到客户机中时,就不能对该客户机进行动态迁移,所以说VT-d、SR-IOV等的使用会破坏动态迁移的特性。
QEMU/KVM并没有直接解决这个问题,不过,可以使用热插拔设备来避免动态迁移的失效。比如,想使用VT-d或SR-IOV方式的一个网卡(包括虚拟功能VF),可以在qemu-kvm命令行启动客户机时并不分配这个网卡(而是使用网桥等方式为客户机分配网络),当在客户机启动后,再动态添加该网卡到客户机中使用。当该客户机需要动态迁移时,就动态移除该网卡,让客户机在迁移前后这一小段时间内使用启动时分配的网桥方式的网络,待动态迁移完成后,如果迁移后的目的主机上也有可供直接分配的网卡设备,就再重新动态添加一个网卡到客户机中。这样既满足了使用高性能网卡的需求,又没有损坏动态迁移的功能。
另外,如果客户机使用较新的Linux内核,还可以使用“以太网绑定驱动”(Linux Ethernet Bonding Driver),该驱动可以将多个网络接口绑定为一个逻辑上的单一接口。当在网卡热插拔场景中使用该绑定驱动时,可以提高网络配置的灵活性和网络切换时的连续性。关于Linux中的“以太网绑定驱动”,参考如下网页中Linux内核文档对该驱动的描述:http://www.kernel.org/doc/Documentation/networking/bonding.txt。
如果使用libvirt来管理QEMU/KVM,则在libvirt0.9.2及更新的版本中已经开始支持直接使用VT-d的普通设备和SR-IOV的VF且不丢失动态迁移的能力。在libvirt中直接使用宿主机网络接口需要KVM宿主机中macvtap驱动的支持,要求宿主机的Linux内核是2.6.38或更新的版本。在libvirt的客户机的XML配置文件中,关于该功能的配置示例如下:
···
<devices>
···
<interface type='direct'>
<source dev='eth0'mode='passthrough'/>
<model type='virtio'/>
</interface>
</devices>
其中,dev='eth0'表示使用宿主机中的eth0这个网络接口,如果需要在客户机中使用高性能的网络,则eth0可以是一个高性能的网络接口(当然eth0可以根据实际情况换为ethX)。
如果系统管理员对于客户机中网卡等设备的性能要求非常高,而且不愿意丢失动态迁移功能,那么可以考虑尝试使用本节介绍的PCI/PCI-e设备的动态热插拔或使用libvirt中提供的方法直接将宿主机中某个网络接口给客户机使用。
6、 嵌套虚拟化
嵌套虚拟化(nested virtualization、recursive virtualization)是指在虚拟化的客户机中运行一个Hypervisor,从而再虚拟化运行一个客户机。嵌套虚拟化不仅包括相同Hypervisor的嵌套(如KVM嵌套KVM、Xen嵌套Xen、VMware嵌套VMware等),也包括不同Hypervisor的相互嵌套(如VMware嵌套KVM、KVM嵌套Xen、Xen嵌套KVM等)。根据嵌套虚拟化这个概念可知,不仅包括两层嵌套(如KVM嵌套KVM),还包括多层的嵌套(如KVM嵌套KVM再嵌套KVM)。
嵌套虚拟化的使用场景是非常多的,至少包括如下五个较大的应用:
- IaaS(Infrastructure as a Service)类型的云计算提供商,如果有了嵌套虚拟化功能的支持,就可以为其客户提供让客户可以自己运行所需Hypervisor和客户机的能力。对于由于这类需求的客户来说,这样的嵌套虚拟化能力会成为吸引他们购买云计算服务的因素。
- 为测试和调试Hypervisor带来了非常大的便利,有了嵌套虚拟化功能的支持,被调试Hypervisor运行在更底层的Hypervisor之上,就算遇到被调试Hypervisor的系统崩溃,也只需要在底层的Hypervisor上重启被调试系统即可,而不需要真实地与硬件打交道。
- 在一些为了起到安全作用的带有Hypervisor的固件(firmware)上,如果有嵌套虚拟化的支持,则在它上面不仅可以运行一些普通的负载,还可以运行一些Hypervisor启动另外的客户机。
- 嵌套虚拟化的支持,对虚拟机系统的动态迁移也提供了新的功能,从而可以将一个Hypervisor及其上面运行的客户机作为一个单一的节点进行动态迁移。这对服务器的负载均衡及灾难恢复等方面也有积极意义。
- 嵌套虚拟化的支持,对于系统隔离性、安全性方面也提供更多的实施方案。
对于不同的Hypervisor,嵌套虚拟化的实现方法和难度都相差很大。对于完全纯软件模拟CPU指令执行的模拟器(如QEMU),实现嵌套虚拟化相对来说并不复杂;而对于QEMU/KVM这样的必须依靠硬件虚拟化扩展的方案,就必须在客户机中模拟硬件虚拟化特性(如vmx、svm)的支持,并且对上层KVM Hypervisor的操作指令进行模拟。
据所知,目前,Xen方面已经支持Xen on Xen和KVM on Xen,而且在某些平台上已经可以运行"KVM on Xen on Xen"的多级嵌套虚拟化;VMware已经支持VMware on VMware和KVM on VMware这两类型的嵌套。在KVM方面,KVM已经性能较好地支持KVM on KVM的情况,目前Xen on KVM还不能正常运行,KVM社区也会逐渐修复这些问题。
1. KVM嵌套KVM
KVM嵌套KVM,即是在KVM上面运行的第一级客户机中再加载kvm和kvm_intel(或kvm_amd)模块,然后在第一级的客户机中用qemu-kvm启动带有kvm加速的第二级客户机。
“KVM嵌套KVM”的基本架构示意图,如图所示。

其中底层是具有Intel VT或AMD-V特性的硬件系统,硬件层之上就是底层的宿主机系统(我们称之为L0,即Level 0),在L0宿主机中可以运行加载有KVM模块的客户机(我们称之为L1,即Level 1,第一级),在L1客户机中通过QEMU/KVM启动一个普通的客户机(我们称之为L2,即Level 2,第二级)。
如果KVM还可以做多级的嵌套虚拟化,各个级别的操作系统被依次称为:L0、L1、L2、L3、L4……,其中L0向L1提供硬件虚拟化环境(Intel VT或AMD-V),L1向L2提供硬件虚拟化环境,依此类推。而最高级别的客户机Ln可以是一个普通客户机,不需要下面的Ln-1级向Ln级中的CPU提供硬件虚拟化支持。
KVM对“KVM嵌套KVM”的支持从2010年就开始了,目前已经比较成熟了。“KVM嵌套KVM”功能的配置和使用,有如下几个步骤。
1)在L0中,加载kvm-intel(或kvm-amd)模块时需要添加"nested=1"的选项以打开“嵌套虚拟化”的特性,如下:
[root@jay-linux kvm_demo]# modprobe kvm
[root@jay-linux kvm_demo]# modprobe kvm_intel nested=1
[root@jay-linux kvm demo]# cat /sys/module/kvm_intel/parameters/nested
Y
如果kvm_intel模块已经处于使用中,则需要用"rmmod kvm_intel"命令移除kvm_intel模块后重新加载即可,然后要检查"/sys/module/kvm_intel/parameters/nested"这个参数是否为"Y"。对于AMD平台上的kvm-amd模块的操作也是一模一样的。
2)启动L1客户机时,在qemu-kvm命令中加上"-cpu host"或"-cpu qemu64,+vmx"选项以便将CPU的硬件虚拟化扩展特性暴露给L1客户机,如下:
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhe16u3.img -m 4096 -smp 2 -net nic -net tap -cpu host
VNC server running on '::1:5900'
这里的"-cpu host"参数的作用是尽可能将宿主机L0的CPU特性暴露给L1客户机,而"-cpu qemu64,+vmx"以qemu64这个CPU模型为基础,然后加上Intel VMX特性(即CPU的VT-x支持)。当然,以其他CPU模型为基础再加上VMX特性,如"-cpuSandyBridge,+vmx"、"-cpu Westmere,+vmx"都是可以的。在AMD平台上,则需要对应的CPU模型("qemu64"是通用的),再加上AMD-V特性即可,如"-cpu qemu64,+svm"。
3)在L1客户机中,查看CPU的虚拟化支持,然后加载kvm和kvm_intel模块,启动一个L2客户机,如下:
[root@kvm-guest ~]# cat /proc/cpuinfo | grep vmx
flags: fpu de pse tsc msr pae mce cx8 apic mtrr pge mca
cmov pat pse36 clflush mmx fxsr sse sse2 syscall nx rdtscp lm constant tsc
arch_perfmon rep_good unfair_spinlock pni palmulqdg vmx sse3 cx16
sse4_1 sse4_2 x2apic popcnt aes xsave avx hypervisor lahf_lm xsaveopt
flags: fpu de pse tsc msr pae mce cx8 apic mtrr pge mca
cmov pat pse36 clflush mmx fxsr sse sse2 syscall nx rdtscp lm constant_tsc
arch_perfmon rep_good unfair_spinlock pni pclmulqdq vmx sse3 cx16
sse4 1 sse4 2 x2apic popcnt aes xsave avx hypervisor lahf_lm xsaveopt
[root@kvm-guest ~]# modprobe kvm [
root@kvm-guest~]# modprobe kvm_intel
[root@kvm-guest~]# lsmod | grep kvm
kvm_intel 52570 0
kvm 314739 1 kvm_intel
[root@kvm-guest ~]# qemu-system-x86_64 rhel6u3.img -m 1024 -smp 2
VNC server running on ':1:5900'
如果L0没有向L1提供硬件虚拟化的CPU环境,则加载kvm_intel模块时会有错误,kvm_intel模块会加载失败。在L1中启动客户机,就与在普通KVM环境中的操作完全一样。不过对L1系统的内核要求并不高,一般选取较新Linux内核即可,如选用了RHEL 6.3系统自带的内核和Linux 3.5的内核,这都是可以的。
4)在L2客户机中查看是否正常运行,KVM嵌套KVM”,L0启动了L1,然后在L1中启动了L2系统。
由于KVM是全虚拟化Hypervisor,对于其他L1 Hypervisor(如Xen)嵌套运行在KVM上情况,在L1中启动L2客户机的操作就完全与在普通的Hypervisor中的操作步骤完全一样,因为KVM为L1提供了有硬件辅助虚拟化特性的透明的硬件环境。
7、KSM技术
在现代操作系统中,共享内存一个很普遍应用的概念。如在Linux系统中,当使用fork函数创建一个进程之时,子进程与其父进程共享全部的内存,而当子进程或父进程试图修改它们的共享内存区域之时,内核会分配一块新的内存区域,并将试图修改的共享内存区域复制到新的内存区域上,然后让进程去修改复制的内存。这就是著名的“写时复制”(copy-on-write,COW)技术。KSM技术却与这种内存共享概念有点相反。
KSM是"Kernel SamePage Merging"的缩写,中文可称为“内核同页合并”。KSM允许内核在两个或多个进程(包括虚拟客户机)之间共享完全相同的内存页。KSM让内核扫描检查正在运行中的程序并比较它们的内存,如果发现他们有内存区域或内存页是完全相同的,就将多个相同的内存合并为一个单一的内存页,并将其标识为“写时复制”。这样可以起到节省系统内存使用量的作用。之后,如果有进程试图去修改被标识为“写时复制”的合并的内存页时,就为该进程复制出一个新的内存页供其使用。
在QEMU/KVM中,一个虚拟客户机就是一个QEMU进程,所以使用KSM也可以实现多个客户机之间的相同内存合并。而且,如果在同一宿主机上的多个客户机运行的是相同的操作系统或应用程序,则客户机之间的相同内存页的数量就可能还比较大,这种情况下KSM的作用就更加显著。在KVM环境下使用KSM,KSM还允许KVM请求哪些相同的内存页是可以被共享而合并的,所以KSM只会识别并合并那些不会干扰客户机运行,不会影响宿主机或客户机的安全内存页。可见,在KVM虚拟化环境中,KSM能够提高内存的速度和使用效率,具体可以从以下两个方面来理解。
1)在KSM的帮助下,相同的内存页被合并了,减少了客户机的内存使用量,一方面,内存中的内容更容易被保存到CPU的缓存当中;另一方面,有更多的内存可用于缓存一些磁盘中的数据。因此,不管是内存的缓存命中率(CPU缓存命中率),还是磁盘数据的缓存命中率(在内存中命中磁盘数据缓存的命中率)都会提高,从而提高了KVM客户机中操作系统或应用程序的运行速度。
2)正如“内存过载使用”中提及的那样,KSM是内存过载使用的一种较好的方式。KSM通过减少每个客户机实际占用的内存数量,就可以让多个客户机分配的内存数量之和大于物理上的内存数量。而对于使用相同内存量的客户机,在物理内存量不变的情况,可以在一个宿主机中创建更多的客户机,提高了虚拟化客户机部署的密度,提高了物理资源的利用效率。
KSM是在Linux内核2.6.32中被加入到内核主干代码中去的。目前多数流行的Linux发型版都已经将KSM的支持编译到内核中了,其内核配置文件中有"CONFIG_KSM=y"项。Linux系统的内核进程ksmd负责扫描后合并进程的相同内存页,从而实现KSM功能。
root用户可以通过"/sys/kernel/mm/ksm/"目录下的文件来配置和监控ksmd这个守护进程。KSM只会去扫描和试图合并那些应用程序建议为可合并的内存页,应用程序(如qemu-kvm)通过调用如下的madvise系统调用来告诉内核哪些页可合并。
目前较新的qemu-kvm都是支持KSM的,也可以通过查看其代码中对madvise函数的调用情况来确定是否支持KSM,qemu-kvm中的关键函数简要分析如下:
/* 将地址标志为KSM可合并的系统调用*/
/* int madvise(addr,length,MADV_MERGEABLE)*/
/* madvise系统调用的声明在<sys/mman.h> 中*/
/* int madvise( void *start, size_t length, int advice ); */
/* qemu-kvm 代码的exec.c文件中,开启内存可合并选项 */
static int memory_try_enable_merging(void *addr, size_t len)
{
QemuOpts *opts;
opts = qemu_opts_find(qemu_find_opts("machine"), 0);
if(opts&&!qemu_opt_get_bool(opts, "mem-merge", true) {
/* disabled by the user */
return 0;
}
return qemu_madvise(addr, len, QEMU_MADV_MERGEABLE);
}
/* qemu-kvm代码的osdep.c文件中对 qemu_madvise()函数的定义*/
int qemu_madvise(void *addr,size_t len,int advice)
{
if (advice == QEMU_MADV_INVALID)
error = EINVAL;
return -1;
}
x
#if defined(CONFIG MADVISE)
return madvise(addr,len,advice);
#elif defined(CONFIG POSIX MADVISE)
return posix_madvise(addr,len,advice);
#else
errno = EINVAL;
return -1;
#endif
}KSM最初就是为KVM虚拟化中的使用而开发的,不过它对非虚拟化的系统依然非常有用。KSM可以在KVM虚拟化环境中非常有效地降低内存使用量,网上看到的资料显示,在KSM的帮助下,有人在物理内存为16GB的机器上,用KVM成功运行了多达52个1GB内存的Windows XP客户机。
由于KSM对KVM宿主机中的内存使用有较大的效率和性能的提高,所以一般建议打开KSM功能。不过,“金无足赤,人无完人”,KSM必须有一个或多个进程去检测和找出哪些内存页是完全相同可以用于合并的,而且需要找到那些不会经常更新的内存页,这样的页才是最适合于合并的。因此,KSM让内存使用量降低了,但是CPU使用率会有一定程度的升高,也可能会带来隐蔽的性能问题,需要在实际使用环境中进行适当配置KSM的使用,以便达到较好的平衡。
KSM对内存合并而节省内存的数量与客户机操作系统类型及其上运行的应用程序有关,如果宿主机上的客户机操作系统相同且其上运行的应用程序也类似,节省内存的效果就会很显著,甚至节省超过50%的内存都有可能的。反之,如果客户机操作系统不同,且运行的应用程序也大不相同,KSM节省内存效率就不好,可能连5%都不到。
另外,在使用KSM实现内存过载使用时,最好保证系统的交换空间(swap space)足够大。因为KSM将不同客户机的相同内存页合并而减少了内存使用量,但是客户机可能由于需要修改被KSM合并的内存页,从而使这些被修改的内存被重新复制出来占用内存空间,因此可能会导致系统内存的不足,这是需要足够的交换空间来保证系统的正常运行。
1. KSM操作实践
内核的KSM守护进程是ksmd,配置和监控ksmd的文件在"/sys/kernel/mm/ksm/"目录下。通过如下命令行可以查看该目录下的几个文件:
[root@jay-linux kvm_demo]# 1s -1 /sys/kernel/mm/ksm/*
-T---r---1 root root 4096 0ct 29 17:28 /sys/kernel/mm/ksm/full scans
-r--r---1 root root 4096 0ct 29 17:28 /sys/kernel/mm/ksm/pages shared
-r--r--r-- 1 root root 4096 Oct 29 17:28 /sys/kernel/mm/ksm/pages sharing
-rw-r--r-- 1 root root 4096 Oct 29 18:06 /sys/kernel/mm/ksm/pages_to_scan
-r--r--r-- 1 root root 4096 Oct 29 17:28 /sys/kernel/mm/ksm/pages_unshared
-r--r-r--1 root root 4096 Oct 2917:28/sys/kernel/mm/ksm/pagesvolatile
-rw-r--r--1 root root 4096 0ct 29 23:01 /sys/kernel/mm/ksm/run这里面的几个文件对于了解KSM的实际工作状态来说是非常重要的,下面简单介绍各个文件的作用:
- full_scans:记录着已经对所有可合并的内存区域扫描过的次数。
- pages_shared:记录着正在使用中的共享内存页的数量。
- pages_sharing:记录着有多少数量的内存页正在使用被合并的共享页,不包括合并的内存页本身。这就是实际节省的内存页数量。
- pages_unshared:记录了守护进程去检查并试图合并,却发现了并没有重复内容而不能被合并的内存页数量。
- pages_volatile:记录了因为其内容很容易变化而不被合并的内存页。
- pages_to_scan:在ksmd进程休眠之前会去扫描的内存页数量。
- sleep_millisecs:ksmd进程休眠的时间(单位:毫秒),ksmd的两次运行之间的间隔。
- run:控制ksmd进程是否运行的参数,默认值为0,要激活KSM必须要设置其值为1(除非内核关闭了sysfs的功能)。设置为0,表示停止运行ksmd但保持它已经合并的内存页;设置为1,表示马上运行ksmd进程;设置为2表示停止运行ksmd,并且分离已经合并的所有内存页,但是保持已经注册为可合并的内存区域给下一次运行使用。
通过前面查看这些sysfs中的ksm相关的文件可以看出,只有pages_to_scan、sleep_millisecs、run这3个文件对root用户是可读可写的,其余5个文件都是只读的。
可以向pages_to_scan、sleep_millisecs、run这3个文件中写入自定义的值以便控制ksmd的运行。例如,"echo 1200>/sys/kernel/mm/ksm/pages_to_scan"用来调整每次扫描的内存页数量,"echo 10>/sys/kernel/mm/ksm/sleep_millisecs"用来设置ksmd两次运行的时间间隔,"echo 1>/sys/kernel/mm/ksm/run"用来激活ksmd的运行。
pages_sharing的值越大,说明KSM节省的内存越多,KSM效果越好,如下命令计算了节省的内存数量。
[root@jay-linux~]# echo "KSM saved: $(( $(cat /sys/kernel/mm/ksm/pages_sharing) * $(getconf PAGESIZE) / 1024 / 1024 ))MB"
KSM saved:1375MB
而pages_sharing除以pages_shared得到的值越大,说明相同内存页重复的次数越多,KSM效率就是越高。pages_unshared除以pages_sharing得到的值越大,说明ksmd扫描不能合并的内存页越多,KSM的效率越低。可能有多种因素影响pages_volatile的值,不过较高的page_voliatile值预示着很可能有应用程序过多地使用了madvise(addr,length,MADV_MERGEABLE)系统调用来将其内存标志为KSM可合并。
在通过"/sys/kernel/mm/ksm/run"等修改了KSM的设置之后,系统默认不会再修改它的值,这样可能并不能更好地使用后续的系统状况,或者经常需要人工动态调节是比较麻烦的。Redhat系列系统(如RHEL 6.3)中提供了两个服务ksm和ksmtuned来动态调节KSM的运行情况,RHEL 6.3中ksm和ksmtuned两个服务都包含在qemu-kvm这个RPM安装包中。
在RHEL 6.3上,如果不运行ksm服务程序,则KSM默认只会共享2000个内存页,这样一般很难起到较好的效果。而在启动ksm服务后,KSM能够共享最多达到系统物理内存一半的内存页。而ksmtuned服务一直保持循环执行,以调节ksm服务的运行,其配置文件在/etc/ksmtuned.conf,配置文件的默认内容如下:
[root@jay-linux kvm_demo]# cat /etc/ksmtuned.conf
# Configuration file for ksmtuned.
# How long ksmtuned should sleep between tuning adjustments
# KSM_MONITOR_INTERVAL=60
# Millisecond sleep between ksm scans for 16Gb server.
# Smaller servers sleep more,bigger sleep less.
# KSM_SLEEP_MSEC=10
# KSM NPAGES BOOST=300 # KSM_NPAGES_DECAY=-50
# KSM_NPAGES_MIN=64
# KSM NPAGES MAX=1250
# KSM_THRES_COEF=20 # KSM THRES CONST=2048
# uncomment the following if you want ksmtuned debug info
# LOGFILE=/var/log/ksmtuned
# DEBUG=1
下面演示一下KSM带来的节省内存的实际效果。在物理内存为4GB的系统上,使用了Linux 3.5内核的RHEL 6.3系统作为宿主机,开始时将ksm和ksmtuned服务暂停,"/sys/kernel/mm/ksm/run"的默认值为0,KSM不生效,然后启动每个内存为1GB的4个Windows 7客户机(没有安装virtio-balloon驱动,没有以ballooning方式节省内存),启动ksm和ksmtuned服务,10分钟后检查系统内存的使用情况以确定KSM的效果。
实现该功能的一个示例脚本(ksm-test.sh)如下:
#!/bin/bash
# file: ksm-test.sh
echo "---stoping services: ksm and ksmtuned ..."
service ksm stop
service ksmtuned stop
echo "---'free -m' command output before starting any guest."
free -m
# start 4 Win7 guest
for i in $(seq 1 4)
do
qemu-img create -f qcow2 -o backing_file="/images/Windows/ia32e_win7_ent.img" win7-${i).qcow2
echo "starting the No. ${i} guest..."
qemu-system-x86_64 win7-${i}.qcow2 -smp 2 -m 1024 -net nic -net tap -daemonize
sleep 20
done
echo "---'free -m' command output with several guests running ."
free -m
echo "---starting services: ksm and ksmtuned ..."
service ksm start s
ervice ksmtuned start
sleep 600
echo "---'free -m' command output with ksm and ksmtuned running."
free -m
执行该脚本:
[root@jay-linux kvm_demo]# ./ksm-test.sh由于KSM的作用,运行脚本后,系统的空闲内存从126 MB提高到了1101MB,获得了差不多1GB的空闲可用内存。
此时查看"/sys/kernel/mm/ksm/"目录中KSM的状态,如下:
[root@jay-linux kvm_demo]# cat /sys/kernel/mm/ksm/full_scans
4
[root@jay-linux kvm_demo]# cat /sys/kernel/mm/ksm/pages_shared
109395
[root@jay-linux kvm_demo]# cat /sys/kernel/mm/ksm/pages_sharing
572100
[root@jay-linux kvm_demo]# cat /sys/kernel/mm/ksm/pages_to_scan
1200
[root@jay-linux kvm demo]# cat /sys/kernel/mm/ksm/pages_unshared
233589
[root@jay-linux kvm_demo]# cat /sys/kernel/mm/ksm/run
1
[root@jay-linux kvm_demo]# cat /sys/kernel/mm/ksm/sleep_millisecs
41
可见,KSM已经为系统提供了不少的共享内存页,而当前KSM的运行标志(run)设置为1。当然,查看到的run值也可能为0,因为RHEL 6.3中的ksm和ksmtuned这两个服务会根据系统状况,按照既定的规则来修改"/sys/kernel/mm/ksm/run"文件中的值,从而调节KSM的运行。
8、1GB大页
前面介绍的大页(huge page)主要是针对x86-64 CPU架构上的2MB大小的大页,将介绍更大的大页——1GB大页,这两者的基本用法和原理是大同小异的。总的来说,1GB大页与2MB大页一样,使用了hugetlbfs(一个基于内存的特殊文件系统)来直接利用硬件提供的大页支持,以便创建共享的或私有的内存映射,这样减少了内存页表数量,提高了TLB缓存的效率,从而提高了系统的内存访问的性能。而且在Intel EPT(或AMD NTP)技术的辅助下,KVM的客户机中内存访问性能还会有更明显的提高。
在KVM虚拟化环境中,一个客户机就是一个qemu-kvm进程,Linux宿主机系统可以向qemu-kvm进程分配大页,而且当客户机中有应用程序或程序库使用到大页时,就能很好地提高客户机中内存访问的性能。1GB和2MB大页的不同点,主要在于它们的内存页大小不同,且1GB大页的分配只能在Linux系统的内核启动参数中指定,而2MB大页既可以在启动时内核参数配置,又可以在系统运行中用命令行操作来配置。
下面介绍一下在KVM环境中使用1GB大页的具体操作步骤。
1)检查硬件和内核配置对1GB大页的支持,命令行如下:
[root@jay-linux ~]# cat /proc/cpuinfo | grep pdpelgb
flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr
pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht
tm pbe syscall nx pdpelgb rdtscp lm constant_tsc arch_perfmon pebs
bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni
pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr
pdcm pcid dca sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes
xsave avx lahf_lm ida arat epb xsaveopt pln pts dtherm tpr_shadow
vnmi flexpriority ept vpid
[root@jay-linux~]# grep HUGETLB /boot/config-3.5.0
CONFIG_HUGETLBFS=y
CONFIG_HUGETLB_PAGE=Y
Intel的一些新的服务器平台(如Westmere、SandyBridge、IvyBridge等)都是支持1GB大页特性的,部分桌面级平台可能不支持1GB大页。如上面的命令所示,在Linux系统中,可以查看"pdpe1gb"这个标志在/proc/cpuinfo中的存在来确定硬件和内核是否有1GB的支持,另外2MB大页在/proc/cpuinfo中的标志为"pse"。而在内核配置中,对大页(1GB和2MB)的支持主要查看"HUGETLB"相关的支持。
2)在宿主机的内核启动参数中配置1GB,例如,在启动时使用6个1GB大页的grub配置文件如下:
title KVM Demo
root (hd0,0)
kernel (hd0,0)/boot/vmlinuz-3.5.0 ro root=/dev/sdal \hugepagesz=1GB hugepages=6 default_hugepagesz=1GB
initrd (hd0,0)/boot/initrd-3.5.0.img
在上面的内核启动选项中,与大页相关的几个选项如下:
- hugepagesz表示HugeTLB内存页的大小,在x86-64平台上其值为"2MB"或"1GB"。
- hugepages表示在启动时大页分配的数量。
- default_hugepagesz表示在挂载hugetlb文件系统时,没有设置大页的大小时默认使用的大页的大小。如果不设置这个选项,在x86-64平台上,其默认值为2MB。
- 对于这3个选项,有如下两点需要注意:
- hugepagesz×hugepages的值一定不能大于系统的物理内存。
- "hugepagesz"和"hugepages"选项可以成对地多次使用,可以让系统在启动时同时保留多个大小不同的大页(在x86-64上有2MB和1GB两种)。例如,"hugepagesz=1GB hugepages=6 default_hugepagesz=1GB hugepagesz=2MB hugepages=512"选项表示启动时系统保留6个1GB大页和512个2MB大页的内存,在挂载hugetlb时默认使用1GB大小的大页。
3)在启动宿主机后,在宿主机中查看内存信息和大页内存信息,命令行如下:
[root@jay-linux ~]# cat /proc/meminfo
MemTotal: 33033956 kB
MemFree: 26107172 kB
Buffers: 37280 kB
Cached: 174316 kB
<!-- 此处省略数十行输出信息 -->
HugePages_Total: 6
HugePages_Free: 6
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 1048576 kB
<!-- 此处省略其余行的输出信息 -->
[root@jay-linux ~]# hugeadm --pool-list
Size Maximum Current Minimum Default
1073741824 6 6 6在上面的输出信息中,宿主机启动后,/proc/meminfo文件中的"MemFree"和"MemTotal"相差大于6GB,从侧面说明了系统启动时即保留了那6个1GB大页的内存。
/proc/meminfo中的"Hugepagesize:1048576 kB"表示大页的大小为1GB,"HugePages_Total:6"表示总共有6个大页,"HugePages_Free:6"表示未被使用的大页有6个,"HugePages_Rsvd:0"表示因为别的程序使用而保留的大页有0个。
"hugeadm"命令行工具是RHEL 6.3中"libhugetlbfs-utils" RPM包提供的配置大页资源池的一个工具,"hugeadm--pool-list"命令显示了系统当前大页资源池的状态。如果使用前面提到的在启动时同时保留2MB和1GB大小大页的设置,则用"hugeadm"工具查看到的大页资源池状态的示例为:
[root@jay-linux ~]# hugeadm --pool-list
Size Maximum Current Minimum Default
2097152 512 512 512
1073741824 6 6 6 *4)挂载hugetlbfs文件系统,命令行如下:
[root@jay-linux ~]# mount -t hugetlbfs hugetlbfs /dev/hugepages
如果使用了两种大小的大页,可以在挂载hugetlbfs文件系统时,通过"pagesize"选项来指定挂载hugetlbfs的大页的大小,如下命令行指定了使用2MB大页(而不是1GB):
mount-t hugetlbfs hugetlbfs /dev/hugepages -o pagesize=2M
5)使用qemu-kvm命令启动客户机,"-mem-path"参数为其提供1GB大页的支持,命令行操作如下:
[root@jay-linux~l# qemu-system-x86_64 -m 6G -smp 2 rhel6u3.gcow -net nic -net tap -mem-path /dev/hugepages/
VNC server running on '::1:5900'
在使用1GB大页时,发现,启动客户机的内存不能超过"-mem-path"指定的目录的1GB大页的内存量(这里为6GB),否则可能会出现"can't mmap RAM pages:Cannot allocate memory"的错信息,从而不会为客户机提供任何大页的实际支持。
6)此时,在宿主机中再次查看内存情况,命令行如下:
[root@jay-linux ~]# cat /proc/meminfo
MemTotal: 33033956 kB
MemFree: 25133412 kB
Buffers: 39284 kB :
Cached 1073284 kB
<!-- 此处省略数十行输出信息 -->
HugePages_Total: 6
HugePages_Free: 3
HugePages_Rsvd: 3
HugePages_Surp: 0
Hugepagesize: 1048576 kB
从/proc/meminfo中的"HugePages_Free:3"可以看出,只有3个1GB大页空闲了,说明已经分配3个1GB大页给客户机qemu-kvm进程了。从此,当客户机中应用程序真正请求分配1GB大页时,宿主机就可以帮它在物理内存上分配1GB大页了。
目前,由于对大页的支持需要显式调用libhugetlb库的函数,因此正式发布的应用程序中能使用大页的并不多,据了解,Oracle、Sybase等数据库这样的大程序可以配置使用大页。
和2MB大页一样,使用1GB的大页时,存在的问题也是一开始就需要预留大页的内存(不能分配给普通4KB页使用),不能被交换(swap)到交换分区,也不能使用ballooning方式使用大页内存。不过,在硬件、宿主机和客户机都支持1GB大页时,在客户机中使用1GB大页的应用程序对内存访问效率的提升是比较明显的,比2MB大页的效果更好。总之,在了解了它的利弊之后,对于对内存性能需求很高的应用,在KVM中可以选择使用1GB大页的特性。
9、透明大页
使用大页(huge page)可以提高系统内存的使用效率和性能,不过大页有如下几个缺点:
- 大页必须在使用前就预留下来(1GB大页还只能在启动时分配)。
- 应用程序代码必须显式使用大页(一般是调用libhugetlbfs API来分配大页)。
- 大页必须常驻物理内存中,不能给交换到交换分区中。
- 需要超级用户权限来挂载hugetlbfs文件系统。
- 如果预留了大页内存但没实际使用就会造成物理内存的浪费。
透明大页(Transparent Hugepage)正是发挥了大页的一些优点,又能避免了上述缺点。透明大页(THP)是Linux内核的一个特性,由Redhat的工程师Andrea Arcangeli在2009年实现的,然后在2011年的Linux内核版本2.6.38中被正式合并到内核的主干开发树中。目前一些流行的Linux发行版(如RHEL 6.3、Ubuntu 12.04等)的内核都默认提供了透明大页的支持。
透明大页,如它的名称描述的一样,对所有应用程序都是透明的(transparent),应用程序不需要任何修改即可享受透明大页带来的好处。在使用透明大页时,普通的使用hugetlbfs大页依然可以正常使用,而在没有普通的大页可供使用时,才使用透明大页。
透明大页是可交换的(swapable),当需要交换到交换空间时,透明的大页被打碎为常规的4KB大小的内存页。在使用透明大页时,如果因为内存碎片导致大页内存分配失败,这时系统可以优雅地使用常规的4KB页替换,而且不会发生任何错误、故障或用户态的通知。而当系统内存较为充裕、有很多的大页面可用时,常规的页分配的物理内存可以通过khugepaged进程自动迁往透明大页内存。内核进程khugepaged的作用是,扫描正在运行的进程,然后试图将使用的常规内存页转换到使用大页。
目前,透明大页仅仅支持匿名内存(anonymous memory)的映射,对磁盘缓存(page cache)和共享内存(shared memory)的透明大页支持还处于开发之中。
下面看一下使用透明大页的步骤。
1)在编译Linux内核时,配置好透明大页的支持,配置文件中的示例如下:
CONFIG_TRANSPARENT_HUGEPAGE=y
CONFIG_TRANSPARENT_HUGEPAGE_ALWAYS=y
# CONFIG_TRANSPARENT_HUGEPAGE_MADVISE is not set
这表示默认对所有应用程序的内存分配都尽可能地使用透明大页。当然,还可以在系统启动时修改Linux内核启动参数"transparent_hugepage"来调整这个默认值,其取值为如下3个值之一:
transparent hugepage=[always|madvise|newer]
2)在运行的宿主机中配置透明大页的使用方式,命令行如下:
[root@jay-linux ~]# cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
[root@jay-linux ~]# cat /sys/kernel/mm/transparent_hugepage/defrag [always]
madvise never
[root@jay-linux ~]# cat /sys/kernel/mm/transparent_hugepage/khugepaged/defrag
1
[root@jay-linux ~]# echo "never" > /sys/kernel/mm/transparent_hugepage/defrag
[root@jay-linux ~]# cat /sys/kernel/mm/transparent_hugepage/defrag
always madvise [never
在本示例的系统中,"/sys/kernel/mm/transparent_hugepage/enabled"接口的值为"always",表尽可能地在内存分配中使用透明大页;若将该值设置为"madvise",则表示仅在"MADV_HUGEPAGE"标识的内存区域使用透明大页(在嵌入式Linux系统中内存资源比较珍贵,为了避免使用透明大页可能带来的内存浪费,如申请一个2MB内存页但只写入了1 Byte的数据,可能选择"madvise"方式使用透明大页);若将该值设置为"never"则表示关闭透明内存大页的功能。
当设置为"always"或"madvise"之时,系统会自动启动"khugepaged"这个内核进程去执行透明大页的功能;当设置为"never"时,系统会停止"khugepaged"进程的运行。
"transparent_hugepage/defrag"这个接口是表示系统在发生页故障(page fault)时同步地做内存碎片的整理工作,其运行频率较高(某些情况下可能会带来额外的负担)。
"transparent_hugepage/khugepaged/defrag"接口表示在khugepaged进程运行时进行内存碎片的整理工作,它运行的频率较低。当然还可以在KVM客户机中也使用透明大页,这样在宿主机和客户机同时使用的情况下,更容易提高内存使用的性能。
一些Linux发型版对透明大页的sys文件系统的接口可能有些不一致,在RHEL 6.3系统默认的对透明大页的设置中,各个选项的取值也和Linux 3.5上的有点不一样。
下面就是RHEL 6.3中关于透明大页的默认设置:
# cat /sys/kernel/mm/redhat_transparent_hugepage/enabled
[always] never
# cat /sys/kernel/mm/redhat_transparent_hugepage/defrag
[always] never
# cat /sys/kernel/mm/redhat transparent hugepage/khugepaged/defrag
[yes] no
3)查看系统使用透明大页的效果,可以通过查看"/proc/meminfo"文件中的"AnonHugePages"这行来看系统内存中透明大页的大小,命令行如下:
[root@jay-linux ~]# cat /proc/meminfo | grep -i AnonHugePages
AnonHugePages: 688128 kB
[root@jay-linux ~]# echo $((688128/2048))
336由上面的输出信息可知,当前系统使用了336个透明大页,透明大页内存大小为688128 KB。
在KVM 2010年论坛(KVM Forum 2010)[13]上,透明大页的作者Andrea Arcangeli发表的一个题为"Transparent Hugepage Support"的演讲,其中展示了不少透明大页对性能提升的数据。
下图展示了在是否打开宿主机和客户机的透明大页(THP)、是否打开Intel EPT特性时,内核编译(kernel build)所需时间长度的对比,时间越短说明效率越高。
由图的数据可知,当打开EPT的支持且在宿主机和客户机中同时打开透明大页的支持时,内核编译的效率只比原生的非虚拟化环境中的系统降低了5.67%;而打开EPT但关闭宿主机和客户机的透明大页时,内核编译效率比原生系统降低了24.81%;EPT和透明大页都全部关闭时,内核编译效率比原生系统降低了260.15%。这些数据说明了,EPT对内存访问效率有很大的提升作用,透明大页对内存访问效率也有较大的提升作用。
10、AVX和XSAVE
AVX(Advanced Vector Extensions,高级矢量扩展)是Intel和AMD的x86架构指令集的一个扩展,它最早是Intel在2008年3月提出的指令集,在2011年Intel发布Sandy Bridge处理器时开始第一次正式支持AVX,随后AMD最新的处理器也支持AVX指令集。Sandy Bridge是Intel处理器微架构从2009年发布的Nehalem架构后的革新,而引入AVX指令集是Sandy Bridge处理中引入的一个较大的特性,甚至有人将AVX指令认为是Sandy Bridge中最大的亮点,其重要性堪比1999年Pentium Ⅲ处理中引入的SSE(流式SIMD扩展)指令集。AVX中的新特性有:将向量化宽度从128为提升到256位,且将XMM0~XMM15寄存器重命名为YMM0~YMM15;引入了三操作数、四操作数的SIMD指令格式;弱化了对SIMD指令中对内存操作对齐的要求,支持灵活的不对齐内存地址访问。
向量就是多个标量的组合,通常意味着SIMD(单指令多数据),就是一个指令同时对多个数据进行处理,达到很大的吞吐量。早期的超级计算机大多都是向量机,而随着图形图像、视频、音频等多媒体的流行,PC处理器也开始向量化。X86上最早出现的是1996年的MMX(多媒体扩展)指令集,之后是1999年的SSE(流式SIMD扩展)指令集,它们分别是64位向量和128位向量,比超级计算机用的要短得多,所以叫做“短向量”。SandyBridge的AVX指令集将向量化宽度扩展到了256位,原有的16个128位XMM寄存器扩充为256位的YMM寄存器,可以同时处理8个单精度浮点数和4个双精度浮点数。不过,目前AVX的256位向量仅支持浮点,不像128位的SSE那样能支持整数运算。
对于AVX指令的支持,在CPU硬件方面,Intel的Sandy Bridge、Ivy Bridge、Haswell(将于2013年发布)及AMD的Bulldozer处理都提供AVX指令集。在编译器方面,GCC(the GNU Compiler Collection)4.6版本、ICC(Intel C++Compiler)11.1版本、Visual Studio 2010都已经支持AVX了。在操作系统方面,Linux内核2.6.30、Window 7 SP1、Windows 2008 R2 SP1、Mac OS 10.6.8等操作系统都提供了对AVX的支持。不过在应用程序方面,目前只有较少的软件提供了对AVX的支持,因为新的指令集的应用需要一定的时间,就像当年SSE指令集出来后,也是过了几年后才被多数软件支持。
据了解,Prime95/MPrime(用于GIMPS[14]项目中搜索梅森素数的分布式网络计算的软件)在其27.7版本中提供了对AVX稳定的支持,相比于不支持AVX的26版本,27.7版本提升了大约30%的整体计算性能。AVX指令对浮点运算的性能提升是明显的,可主要应用于多媒体(音视频解码、3D图像渲染、3D游戏、HTML5展示等)、科学计算、金融分析计算及一些并行计算的领域。
另外,XSAVE指令(包括XSAVE、XRSTOR等)是在Intel Nehalem处理器中开始引入的,是为了保存和恢复处理器扩展状态的,在AVX引入后,XSAVE也要处理YMM寄存器状态。在KVM虚拟化环境中,客户机的动态迁移需要保存处理器状态,然后在迁移后恢复处理器的执行状态,如果有AVX指令要执行,在保存和恢复时也需要XSAVE/XRSTOR指令的支持。
下面介绍一下如何在KVM中为客户机提供AVX、XSAVE特性。
1)检查宿主机中AVX、XSAVE的支持,Intel Sandy Bridge之后的硬件平台都支持,较新的Linux内核(如3.x)也支持,命令行如下:
[root@jay-linux ~]# cat /proc/cpuinfo | grep avx | grep xsave
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr
pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht
tm pbe syscall nx pdpelgb rdtscp lm constant tsc arch perfmon pebs
bts rep_good nopl xtopology nonstop_tsc aperfmperf pni pclmulqdq
dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid
dca sse4 1 sse4 2 x2apic popcnt tsc deadline timer aes xsave avx
lahf_lm ida arat epb xsaveopt pln pts dtherm tpr_shadow vnmi flexpriority ept vpid
2)启动客户机,将AVX、XSAVE特性提供给客户机使用,命令行操作如下:
[root@jay-linux kvm_demo]# qemu-system-x86_6 4-smp 2-m 1024 rhel6u3.img -cpu host -net nic -net tap
VNC server running on '::1:5900'3)在客户机中,查看QEMU提供的CPU信息中是否支持AVX和XSAVE,命令行如下:
[root@kvm-guest ~]# cat /proc/cpuinfo | grep avx | grep xsave
flags :fpu vme de pse tsc msr pae mce cx8 apic mtrr pge
mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpelgb
rdtscp lm constant_tsc arch_perfmon rep_good unfair_spinlock pni
pclmulqdq vmx ssse3 cx16 sse4_1 sse4_2 x2apic popcnt aes xsave
avx hypervisor lahf_lm xsaveopt
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge
mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpelgb
rdtscp lm constant_tsc arch_perfmon rep_good unfair_spinlock pni
pclmulqdq vmx ssse3 cx16 sse4_1 sse4_2 x2apic popcnt aes xsave
avx hypervisor lahf_lm xsaveopt
由上面输出可知,客户机已经检测到CPU有AVX和XSAVE的指令集支持了,如果客户机中有需要使用到它们的程序,就可正常使用,从而提高程序执行的性能了。
另外,Intel将于2013年发布的Haswell处理器平台将会引入新的指令集AVX2(AVX指令集的扩展),它将会提供包括支持256位向量的整数运算在内的更多功能。在qemu-kvm命令行中,用"-cpu host"参数也可以将AVX2的特性提供给客户机使用。
11、AES新指令
AES(Advanced Encryption Standard,高级加密标准)是一种用于对电子数据进行加密的标准,它在2001年就被美国政府正式接纳和采用。软件工业界广泛采用AES用于对个人数据、网络传输数据、公司内部IT基础架构等进行加密保护。
AES的区块长度固定为128位,密钥长度则可以是128、192或256位。随着大家对数据加密越来越重视,以及AES应用越来越广泛,并且AES算法用硬件实现的成本并不高,一些硬件厂商(包括Intel、AMD等)都在自己的CPU中直接实现了针对AES算法的一系列指令,从而提高AES加解密的性能。
AES-NI(Advanced Encryption Standard new instructions,AES新指令)是Intel在2008年3月提出的在x86处理器上的指令集扩展。它包含了7条新指令,其中6条指令是在硬件上对AES的直接支持,另外一条是对进位乘法的优化,从而在执行AES算法的某些复杂的、计算密集型子步骤时使程序能更好地利用底层硬件,减少计算所需的CPU周期,提升AES加解密的性能。
Intel公司从Westmere平台开始就支持AES-NI,目前Westmere、SandyBridge、IvyBridge、Haswell等平台的服务器多数都支持AES-NI。目前有不少的软件都已经支持AES新指令了,如OpenSSL(1.0.l版本以上)、Oracle数据库(11.2.0.2版本以上)、7-Zip(9.1版本以上)、Libgcrypt(1.5.0以上)、Linux的Crypto API等。在KVM虚拟化环境中,如果客户机支持AES新指令(如RHEL6.0以上版本的内核都支持AES-NI),而且在客户机中用到AES算法加解密,那么将AES新指令的特性提供给客户机使用,会提高客户机的性能。
在KVM的客户机中对AES-NI进行了测试,对比在使用AES-NI新指令和不使用AES-NI的情况对磁盘进行加解密的速度。
下面介绍一下AES新指令的配置和测试过程及测试结果。
1)在进行测试之前,检查硬件平台是否支持AES-NI,一般来说如果CPU支持AES-NI,则会默认暴露到操作系统中去。而有一些BIOS中的CPU configuration下有一个"AES-NI Intel"这样的选项,也需要查看并且确认打开AES-NI的支持。
不过,在设置BIOS时需要注意,在一台Romley-EP的BIOS中设置了"Advanced"→"Processor Configuration"→"AES-NI Defeature"的选项,需要看清楚这里是设置"Defeature"而不是"Feature",所以这个"AES-NI Defeature"应该设置为"disabled"(其默认值也是"disabled"),表示打开AES-NI功能。而BIOS中没有AES-NI相关的任何设置之时,就需要到操作系统中加载"aesni_intel"等模块来确认硬件是否提供了AES-NI的支持。
2)需要保证在内核中将AES-NI相关的配置项目编译为模块或直接编译进内核。当然,如果不是通过内核来使用AES-NI而是直接应用程序的指令使用它,则该步对内核模块的检查来说不是必要的。
RHEL 6.3的内核关于AES的配置如下:
CONFIG_CRYPTO_AES=m
CONFIG_CRYPTO_AES_X86_64=m
CONFIG_CRYPTO_AES_NI_INTEL=m3)在宿主机中,查看/proc/cpuinfo中的AES-NI相关的特性,并加载"aseni_intel"这个模块,命令行操作如下:
[root@jay-linux ~]# cat /proc/cpuinfo | grep aes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr
pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm
pbe syscall nx pdpelgb rdtscp lm constant_tsc arch_perfmon pebs
bts rep_good nopl xtopology nonstop_tsc aperfmperf pni pclmulqdq
dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid
dca sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx lahf_lm
ida arat epb xsaveopt pln pts dthermtpr_shadow vnmi flexpriority ept vpid
[root@jay-linux~]# lsmod | grep aes
aes_x86_64 7316 0
aes_generic 25994 1 aes_x86_64
[root@jay-linux ~]# modprobe aesni_intel
[root@jay-linux~]# 1smod | grep aes
aesni_intel 39274 0
cryptd 6667 1 aesni_intel
aes_x86_64 7316 1 aesni_intel
aes_generic 25994 2 aesni_intel,aes_x86_64在加载"aesni_intel"模块的过程中,可能遇到如下的错误。这种情况是硬件不支持AES-NI或BIOS屏蔽了AES-NI特性造成的。
[root@jay-linux ~]# modprobe aesni_intel
FATAL:Error inserting aesni_intel
(/lib/modules/3.5.0/kernel/arch/x86/crypto/aesni-intel.ko):No SGDN File
如果是"aesni_intel"模块没有正确编译,则会出现如下的错误提示信息。
[root@jay-linux ~]# modprobe aesni_intel
FATAL: Module aesni_intel not found4)启动KVM客户机,默认qemu-kvm启动客户机时,没有向客户机提供AES-NI的特性,可以用"-cpu host"或"-cpu qemu64,+aes"选项来暴露AES-NI特性给客户机使用。
当然,由于前面提及一些最新的CPU系列是支持AES-NI的,所以也可用"-cpu Westmere"、"-cpu SandyBridge"这样的参数提供相应的CPU模型,从而提供对AES-NI特性的支持。
[root@jay-linux kvm_demo]# qemu-system-x86_64 -smp 4 -m 4096 rhel6u3.img -cpu host
VNC server running on '::1:5900'
5)在客户机中可以看到aes标志在/proc/cpuinfo中也是存在的,然后像宿主机中那样加载"aesni_intel"模块使其能够用到AES-NI,再执行使用AES-NI测试程序,即可得出使用了AES-NI的测试结果。
当然,为了衡量AES-NI带来的性能提升,还需要做对比测试,即不添加"-cpu host"等参数启动客户机从而没有AES-NI特性的测试结果。注意,如果在qemu-kvm启动命令行启动客户机时带了AES-NI参数,一些程序使用AES算法时可能会自动加载"aesni_intel"模块,所以,为了确保没有AES-NI的支持,也可以用"rmod aesni_intel"命令移除该模块,再找到aesni-intel.ko文件并将其删除以防被自动加载。
某次进行ASE-NI测试的硬件平台是一个IvyBridge桌面级平台的PC,宿主机内核是Linux3.5.0,qemu-kvm版本是1.1.1,客户机使用的是RHEL 6.3原生系统。测试工具是使用一个特定测试脚本来测试对ramdisk(内存磁盘)进行AES加密后的读写速度。
在测试脚本中调用"cryptsetup"这个命令行工具来对ramdisk建立设备映射(device mapper),然后用AES算法加密,最后cryptsetup会调用到Linux内核的Crypto API(前面已提到它是支持AES-NI的)。接着,用"dd"命令来分别读写ramdisk以得到读写速度的数据。
测试脚本的内容如下:
#!/bin/bash
# create a crypt device using cryptsetup (dmsetup)
create_dm()
{
echo 123456 | cryptsetup create $1 $2 -c aes-ecb-plain
# echo 123456 | cryptsetup create $1 $2 -c aes-cbc-plain
# echo 123456 I cryptsetup create $1 $2-c aes-ctr-plain
# echo 123456 | cryptsetup create $1 $2-c aes-lrw-plain
# echo 123456 | cryptsetup create $1 $2 -c aes-pobc-plain
# echo 123456 I cryptsetup create $1 $2-c aes-xts-plain
}
# remove the device-mapper using cryptsetup
remove_dm(){
if [ -d /sys/block/dm-0 ]; then
cryptsetup remove crypt0 $> /dev/null
fi
}
remove_dm
# try to write some data to ram-disk /dev/ram0; just a pre-test before the main test.
dd if=/dev/zero of=/dev/ram0 bs=1M count=128 >& /dev/null
if [ $? -ne 0 ]; then
echo "there may be no enough ramdisk space on /dev/ram0 ,"
echo "you may add 'ramdisk_size=154112' in kernel option to extend ram-disk size and reboot the system."
echo "Or,you can decrease the value of 'count=xx' option in the 'dd' command."
fi
create_dm crypt0 /dev/ram0
# check /dev/dm-0 ; if the previous command is executed successfully,/dev/md-0 should exists.
while ! [ -e /dev/dm-0 ];
do
echo "/dev/dm-0 doesn't exist."
echo "please check if the command 'cryptsetup create xx' is executed successfully."
sleep 1
done
# do read or write action for several times, so that you can calculate their average value.
for i in $(seq 10);do
# the following line is for read action
dd if=/dev/dm-0 of=/dev/null bs=1M count=128
# the following line is for write action
#dd of=/dev/dm-0 if=/dev/zero bs=1M count=128
done
remove_dm
在该脚本中,选取"/dev/ram0"这个ramdisk作为示例,在RHEL 6.3的默认内核启动时,默认有16个ramdisk,每个ramdisk大小为16MB。这里在脚本中使用dd命令读取或写入的数据是128MB,所以需要调整ramdisk大小,可以在其Grub配置文件的内核的启动行加上"ramdisk_size="参数来修改ramdisk大小,然后重启系统即可。"ramdisk_size="参数后数值的单位是KB,所以设置ramdisk大小为128MB,其参数就为"ramdisk_size=154112"(128*1024)。
另外,也可以修改脚本,将"dd"命令的"count"参数进行调整(变小),以匹配当前系统中ramdisk的实际大小。在RHEL 6.3内核中,对ramdisk的默认配置项如下:
CONFIG_BLK_DEV_RAM=y
CONFIG_BLK_DEV_RAM_COUNT=16
CONFIG_BLK_DEV_RAM_SIZE=16384
另外,在执行脚本中"cryptsetup create"命令时,会出现如下的错误:
[root@kvm-guest ~]# echo 123456 | cryptsetup create crypt0 /dev/ram0 -c aes-ctr-plain
device-mapper: reload ioctl on failed:No such file or cine@teften 这有可能是内核配置的问题,缺少一些加密相关的模块,在本示例中,需要确保内核配置中有如下的内核配置项:
CONFIG_CRYPTO_CBC=m
CONFIG_CRYPTO_CTR=m
CONFIG_CRYPTO_CTS=m
CONFIG_CRYPTO_ECB=m
CONFIG_CRYPTO_LRW=m
CONFIG_CRYPTO_PCBC=m
CONFIG_CRYPTO_XTS=m
CONFIG_CRYPTO_FPU=m
实验得到的测试结果如表所示,其中,"AES-NI-Read"表示有AES-NI支持的情况下读取ramdisk的速度,"Soft-AES-Read"表示没有AES-NI支持(用软件实现AES算法)的情况下读取ramdisk的速度,同理,带有"Write"字样的为写入ramdisk的速度。所有的速度数值的单位是"MB/s"(兆字节每秒),最后一行是各种AES在加密情况下综合起来的读写速度的平均值。

从表可以看出,在使用AES-NI硬件实现AES算法情况下对ramdisk的读写速度,是仅用软件实现AES算法时读写速度的2~3倍。
本小节首先对AES-NI新特性的介绍,然后对如何让KVM客户机也使用AES-NI的步骤进行了介绍,展示了曾经某次AES-NI在KVM客户机中的实验数据。对AES-NI新指令有了较好的认识后,在实际应用环境中如果物理硬件平台支持ASE-NI且客户机中用到AES相关的加解密算法,可以考虑将AES-NI特性暴露给客户机使用以便提高加解密性能。
12、完全暴露宿主机CPU特性
在“CPU模型”中介绍过,qemu-kvm提供qemu64作为默认的CPU模型,对于部分CPU特性,也可以通过“+”号来添加一个或多个CPU特性到一个基础的CPU模型之上,如前面介绍AES新指令时,可以选用"-cpu qemu64,+aes"参数来让客户机支持AES新指令。
当需要客户机尽可能使用宿主机和物理CPU支持的特性时,qemu-kvm也提供了"-cpu host"参数来尽可能多地暴露宿主机CPU特性给客户机,从而在客户机中可以看到和使用CPU的各种特性(如果QEMU/KVM都支持该特性)。在一个Intel IvyBridge平台上,对"-cpu host"参数的效果演示如下。
1)在KVM宿主机中查看CPU信息,命令行如下:
[root@kvm-guest ~]# cat /proc/cpuinfo2)用"-cpu host"参数启动一个RHEL 6.3客户机系统,命令行如下:
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -m 1024 -net nic -net tap -cpu host
VNC server running on '::1:5900'
3)在客户机中查看CPU信息,命令行如下:
[root@kvm-guest ~]# cat /proc/cpuinfo由上面客户机中CPU信息中可知,客户机看到的CPU模型与宿主机中一致,都是"Intel(R)Core(TM)i5-3550";CPUID等级信息(cpuid level)也和宿主机一致,在CPU特性标识(flags)中,也有了"aes"、"xsave"、"avx"、"rdrand"、"smep"等特性,这些较高级的特性是默认的"qemu64"CPU模型中没有的。说明"-cpu host"参数成功地将宿主机的特性尽可能多地提供给客户机使用了。
当然,"-cpu host"参数也并没有完全让客户机得到与宿主机同样多的CPU特性,这是因为QEMU/KVM对于其中的部分特性没有模拟和实现,如"EPT"、"VPID"等CPU特性目前就不能暴露客户机使用。
另外,尽管"-cpu host"参数尽可能多地暴露宿主机CPU特性给客户机,可以让客户机用上更多的CPU功能也能提高客户机的部分性能,与此同时,"-cpu host"参数还是可能会阻止客户机的动态迁移。例如,在Intel的SandyBridge平台上,用"-cpu host"参数让客户机使用了AVX新指令进行运算,此时试图将客户机机器迁移到没有AVX支持的Intel Westmere平台上去,就可能会导致动态迁移的失败。
所以,"-cpu host"参数尽管向客户机提供了更多的功能和更好的性能,还是需要根据使用场景谨慎使用。