系统虚拟化有很多的好处,如提高物理资源利用率、让系统资源更方便监控和管理、提高系统运维的效率、节约硬件投入的成本等等。
那么,在真正实施生产环境的虚拟化时,到底选择哪种虚拟化方案呢?选择商业软件VMware ESXi、开源的KVM和Xen,还是微软的Hyper-V,或者有其他的虚拟化方案?
在进行虚拟化方案的选择时,需要重点考虑的因素中至少有两个至关重要:虚拟化方案的功能和性能,这二者缺一不可。
功能是实现虚拟化的基础,而性能是虚拟化效率的关键指标。即便是功能非常丰富的虚拟化技术,如果它的性能非常不好,我们也很难想象将其应用到生产环境中的效果到底是“利大于弊”还是“弊大于利”。
1、虚拟化性能测试简介
虚拟化性能测试包括的范围比较广泛,可能包含CPU、内存、网络、磁盘的性能,也可能包含虚拟客户机动态迁移时的性能,也可能需要考虑多种物理平台上的性能,也可能需要考虑很多个虚拟客户机运行在同一个宿主机上时的性能。
目前,有一些针对各个虚拟化软件的性能分析工具(profiling),也有一些衡量虚拟化系统中单个方面性能的基准测试工具(benchmark),不过还没有一个能集成所有这些性能测试于一体的比较权威的专门针对虚拟化的性能测试工具。由于虚拟化性能测试涉及计算机系统的方方面面,而且没有一个标准化的测试工具,因此,虚拟化性能测试与性能分析也是一个比较具有挑战性的工程研究领域。
虚拟化性能测试,初看起来是比较复杂和难以操作的,不过,只要细心研究并从用户的角度出发,会发现虚拟化性能测试也并不是多么的高深。对于绝大多数普通用户来说,他们所接触到的无非是一些应用软件(如微软的Office办公套件、杀毒软件等)和互联网中的网页(如Google、百度等),所以,不管是否使用虚拟化,终端用户最关心的还是实际使用的应用软件和互联网站点的性能。应用软件、网络站点的性能才是直接地真正关系到用户体验。从这个角度来看,在虚拟化环境中,只要能保证普通应用程序的性能良好,自然就能为用户带来良好的性能体验。
评价一个系统的性能标准,一般可以用响应时间(response time)、吞吐量(throughput)、并发用户数(concurrent users)和资源占用率(utilization)等几个指标来衡量。
下面简单介绍一下这几个指标的含义。
1. 响应时间
指的是客户端从发出请求到得到响应的整个过程所花费的时间。响应时间是用户能感受到的最直接、最关键的性能指标,试想,如果一个网页,尽管其中内容质量比较良好,但是每次在浏览器中输入URL后需要10分钟才能得到响应打开网页,这样的网页你愿意再次访问吗?
2. 吞吐量
指的是在一次性能测试过程中网络上传输的数据量的总和。在一定的时间长度内,系统能达到的吞吐量当然是越大越好,因为吞吐量越大越可能为用户传输更多的数据。
3. 并发用户数
指的是同时使用一个系统服务的用户数量。对于一个系统来说,能支持的并发用户数当然是越多越好。2011年6月推出的12306铁路购票网站,在2012年春节之前不久,由于很多人同时登录网站购票,而且没买到票的人会不停刷新网页,并发用户数量达到很大的数量级别,从而导致12306网站几乎瘫痪。
4. 资源利用率
指的是在使用某项服务时,客户端和服务器端物理资源占用情况,包括CPU、内存等的利用率。在达到同样的响应时间、吞吐量和并发用户数的指标时,系统的资源利用率当然是越小越好。例如,我们在使用一个应用程序时,都不希望它将我们宝贵的CPU和内存全都占用,因为同一个系统还需要并行运行其他的程序。
系统中应用程序的数量和类型都非常多,如Office等办公软件、数据库服务器软件、文件存储系统、Web服务、缓存服务、邮件服务、科学计算服务、各种单机的或网络版的游戏等。应用程序不但数量众多,而且它们对使用系统的使用特点也不同,有CPU密集型的(如科学计算),有网络I/O密集型的(如Web服务),也有磁盘I/O密集型的(如数据库服务),也有内存密集型的(如缓存服务)。
功能相似的应用程序,使用不同编程语言来开发,其性能差别可能很大,而且,选择不同的中间件(middle ware)来部署同一套应用程序,其性能也很可能大不相同。所以,衡量KVM虚拟化的性能最直接的方法就是:将准备实施虚拟化的系统中运行的应用程序迁移到KVM虚拟客户机中试运行,如果性能良好且稳定,则可以考虑真正实施该系统的虚拟化。
尽管系统中运行的应用程序可能是数量繁多,种类也千差万别,但是它们几乎都会使用CPU、内存、网络、磁盘等基本的子系统。
主要对KVM虚拟化中的几个最重要的子系统进行性能对比测试,具体方法是:在非虚拟化的原生系统(native)中执行某个基准测试程序,然后将该测试程序放到与原生系统配置相近的虚拟客户机中执行,接着对比在虚拟化和非虚拟化环境中该测试程序执行的性能。由于QEMU/KVM的性能测试与硬件配置、测试环境参数、宿主机和客户机系统的种类和版本等都有千丝万缕的联系,而且性能测试本身也很可能有一定的误差存在,部分测试结果可能在不同的测试环境中并不能重现,所有测试数据和结论都仅供参考。在实施KVM虚拟化之前,请以实际应用环境中的测试数据为准。
2、CPU性能测试
CPU是计算机系统中最核心的部件,CPU的性能直接决定了系统的计算能力,故对KVM虚拟化进行性能测试首先选择对客户机中CPU的性能进行测试。任何程序的执行都会消耗CPU资源,所以任何程序几乎都可以作为衡量CPU性能的基准测试工具,不过最好是选择CPU密集型的测试程序。有很多的测试程序可用于CPU性能的基准测试,包括SPEC组织的SPEC CPU和SPECjbb系列、UnixBench、SysBench、PCMark、PC内核编译、Super PI等,下面对其中的几种工具进行简单的介绍。
1. CPU性能测试工具
1)SPECCPU2006
SPEC(Standard Performance Evaluation Corporation)是一个非营利组织,专注于创建、维护和支持一系列标准化的基准测试程序(benchmark),让这些基准测试程序可以应用于高性能计算机的性能测试。许多公司,如IBM、Microsoft、Intel、HP、Oracle、Cisco、EMC、华为、联想、中国电信等,都是SPEC组织的成员。
SPEC系列的基准测试工具,针对不同的测试重点,有不同的测试工具,如测试CPU的SPEC CPU、测试Java应用的SPECjbb、测试电源管理的SPECpower、测试Web应用的SPECweb、测试数据中心虚拟化服务器整合的SPECvirt_sc等。相对来说,SPEC组织的各种基准测试工具在业界的口碑都比较良好,也具有一定的权威性。
SPEC CPU2006是SPEC CPU系列的最新版本,之前的版本有CPU2000、CPU95等,其官方主页是http://www.spec.org/cpu2006/。SPEC CPU2006既支持在Linux系统上运行又支持在Windows系统上运行,是一个非常强大的CPU密集型的基准测试集合,里面包含分别针对整型计算和浮点型计算的数十个基准测试程序[2]。
在SPEC CPU2006的测试中,有bzip2数据压缩测试(401.bzip2)、人工智能领域的象棋程序(458.sjeng)、基于隐马尔可夫模型的蛋白质序列分析(456.hmmer)、实现H.264/AVC标准的视频压缩(464.h264ref)、2D地图的路径查找(473.astar)、量子化学中的计算(465.tonto)、天气预报建模(481.wrf)、来自卡内基梅隆大学的一个语音识别程序(482.sphinx3),等等。
当然,其中一些基准测试也是内存密集型的,如429.mcf的基准测试既是CPU密集型又是内存密集型的。在测试完成后,可以生成HTML、PDF等格式的测试报告。测试报告中有分别对整型计算和浮点型计算的总体分数,并且有各个具体的基准测试程序的分数。分别在非虚拟化原生系统和KVM虚拟化客户机系统中运行SPEC CPU2006,然后对比它们的得分即可大致衡量虚拟化中CPU的性能。
2)SPECjbb2005
SPECjbb2005是SPEC组织用于评估服务器端Java应用性能的基准测试程序,其官方主页为http://www.spec.org/jbb2005/。该基准测试主要测试Java虚拟机(JVM)、JIT编译器、垃圾回收、Java线程等各个方面,也可以对CPU、缓存、内存结构的性能进行度量。
SPECjbb2005既是CPU密集型也是内存密集型的基准测试程序,它利用Java应用能够比较真实地反映Java程序在某个系统上的运行性能。
3)UnixBench
UnixBench(即曾经的BYTE基准测试)为类UNIX系统提供了基础的衡量指标,其官方主页为http://code.google.com/p/byte-unixbench/。它并不是专门测试CPU的基准测试,而是测试系统的许多方面,测试结果不仅会受系统CPU、内存、磁盘等硬件的影响,也会受操作系统、程序库、编译器等软件系统的影响。UnixBench中包含许多测试用例,如文件复制、管道的吞吐量、上下文切换、进程创建、系统调用、基本的2D和3D图形测试等。
4)SysBench
SysBench是一个模块化的、跨平台的、支持多线程的基准测试工具,主要评估的是系统在模拟的高压力的数据库应用中的性能,其官方主页为http://sysbench.sourceforge.net/。
其实,SysBench并非一个完全CPU密集型的基准测试,它主要用来衡量CPU调度器、内存分配和访问、文件系统I/O操作、线程创建等多方面的性能。
5)PCMark
PCMark由Futuremark公司开发,是针对一个计算机系统整体及其部件进行性能评估的基准测试工具,其官方网站是http://www.futuremark.com/benchmarks/pcmark。在PCMark的测试结果中,会对系统整体和各个测试组件进行评分,得分的高低直接反映其性能的好坏。目前,PCMark只能在Windows系统中运行。PCMark分为几个不同等级的版本,其中基础版可以免费下载和使用,而高级版和专业版都需要支付一定的费用才能合法使用。
6)内核编译
内核编译(kernel build或kernel compile)就是以固定的配置文件对Linux内核代码进行编译,它是Linux开发者社区(特别是内核开发者社区)中最常用的系统性能测试方法,可以算作是一个典型的基准测试。
内核编译是CPU密集型,也是内存密集型,而且是磁盘I/O密集型的基准测试,在使用make命令进行编译时,可以添加"-j N"参数来使用N进程协作编译,所以它也可以评估系统在多处理器(SMP)系统中多任务并行执行的可扩展性。只要使用相同的内核代码,使用相同的内核配置,使用相同的命令进行编译,然后对比编译时间的长短即可评价系统之间的性能差异。
7)Super PI
Super PI是一个典型的CPU密集型基准测试工具,最初是1995年日本数学家金田康正[3]用于计算圆周率π的程序,当时他将圆周率计算到了小数点后4G(2的32次方)个数据位。Super PI基准测试程序的原理非常简单,它根据用户的设置计算圆周率π小数点后N个位数,然后统计消耗的时间,根据时间长度的比较就能初步衡量CPU计算能力的优劣。
Super PI最初是一个Windows上的应用程序,可以从http://www.superpi.net/网站下载,目前支持计算小数点后32M(2的25次方)个数据位。不过,目前也有Linux版本的Super PI,可以从http://superpi.ilbello.com/网站下载,它也支持计算到小数点后32M个数据位。目前的Super PI都支持单线程程序,可以执行多个实例从而实现多个计算程序同时执行,另外,也有一些测试程序实现了多线程的Super PI,如Hyper PI(http://virgilioborges.com.br/hyperpi/)。
在实际生产环境中,运行实际的CPU密集型程序(如可以执行MapReduce的Hadoop)当然是测试CPU性能较好的方法,不过,为了体现更普通而不是特殊的应用场景,选择了3个基准测试程序用于测试KVM虚拟化中的CPU性能,包括比较权威的SPEC CPU2006、Linux社区中常用的内核编译和非常简单的Super PI。
2. 测试环境配置
本次对CPU性能测试的硬件环境为一台使用Intel Xeon E5-4650处理器的服务器,在BIOS中打开Intel VT和VT-d技术的支持,默认开启Intel CPU的超线程(Hyper-threading)技术。
本次测试使用的宿主机内核是根据手动下载的Linux 3.7.0版本的内核源代码然后自己编译的,qemu-kvm使用的是1.2.0版本。用于对比测试的原生系统和客户机系统使用完全相同的操作系统,都是使用默认配置的RHEL 6.3 Linux系统。
更直观的测试环境基本描述如表所示:
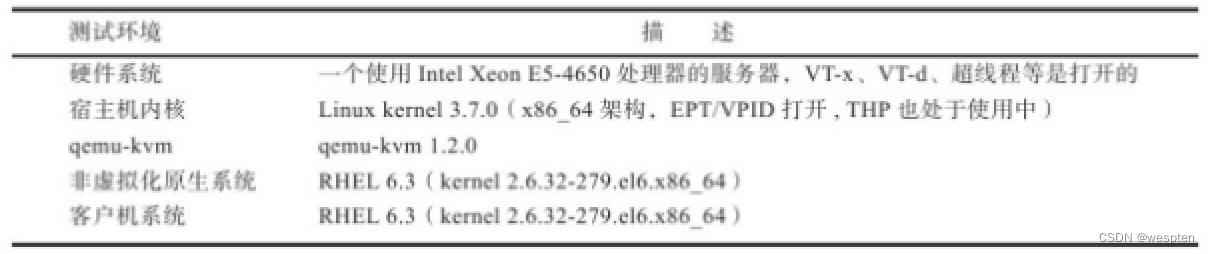
在KVM宿主机中,EPT、VPID等虚拟化特性是默认处于打开状态的,透明大页(THP)的特性也默认处于打开状态,这几个特性对本次测试的结果的影响是比较大的。所有性能测试,若没有特别注明,就是使用下表所示的软硬件测试环境。注意:本次CPU性能测试并没有完全使用Xeon E5-4650处理器中的CPU资源,而是对服务器上的CPU和内存资源都进行了限制,KVM宿主机限制使用了4个CPU线程和12 GB内存,原生系统使用4个CPU线程和10GB内存。
为了防止图形桌面对结果的影响,原生系统、KVM宿主机、KVM客户机系统的运行级别都是3(带有网络的多用户模式,不启动图形界面)。
在本次测试中,对各个Linux系统的内核选项添加的额外配置如下表所示,它们既可以设置在GRUB配置文件中,又可以在系统启动到GRUB界面时进行编辑。

在本次测试中,为客户机分配了4个vCPU和9.5GB内存,与原生系统基本保持一致以便进行性能对比(将客户机内存设置为9.5GB而不是10GB是为了给宿主机多留一点内存,分配给客户机9GB或是10GB内存,对本次CPU性能测试结果的影响不大)。由于SPEC CPU2006的部分基准测试消耗较多的内存,例如在429.mcf执行时每个执行进程就需要大约2GB内存,所以这里设置的内存数量是比较大的。
将客户机的磁盘驱动设置为使用virtio-blk驱动,启动客户机的qemu-kvm命令行如下:
qemu-system-x86_64 -smp 4 -m 9728 -drive rhel6u3.img,if=virtio -net nic -net tap -vnc :0 --daemonize
从上面命令可以看出,本次测试并没有指定虚拟CPU的模型,默认使用了qemu64这个CPU模型,如果应用程序中需要更多CPU特性,可以用-cpu SandyBridge或-cpu host参数设置CPU模型。
3. 性能测试方法
CPU性能测试选取SPEC CPU2006、内核编译和Super PI这三个基准测试来对比KVM客户机与原生系统的性能。下面分别介绍在本次性能测试中使用的具体测试方法。
1)SPEC CPU2006
在获得SPEC CPU2006的测试源代码并进入其主目录后,运行install.sh脚本即可安装SPEC CPU2006,然后通过source命令执行shrc脚本来配置运行环境,最后执行bin/runspec这个Perl脚本即可正式开始运行基准测试。SPEC CPU2006还提供了在Windows系统中可以执行的对应的.BAT脚本文件。在Linux系统中,将这些基本执行步骤整合到一个Shell脚本中,代码如下:
#!/bin/bash
cd /root/cpu2006/
./install.sh
echo "starting SPECCPU2006 at $(date)"
source shrc
bin/runspec --action=validate -o all -r 4 -c Example-linux64-amd64-gcc43.cfg all
echo "SPECCPU2006 ends at $(date)"
在本示例中,runspec脚本用到的参数有:--action=validate表示执行validate这个测试行为(包括编译、执行、结果检查、生成报告等步骤),-o all表示输出测试报告的文件格式为尽可能多的格式(包括html、pdf、text、csv、raw等),-r 4(等价于--rate--copies 4)表示本次将会使用4个并发进程执行rate类型的测试(这样可以最大限度地消耗分配的4个CPU线程资源),--config xx.cfg表示使用xx.cfg配置文件来运行本次测试,最后的all表示执行整型(int)和浮点型(fp)两种测试类型。runspec的参数比较多也比较复杂,可以参考其官方网站的文档了解各个参数的细节。
执行完上面整合的测试脚本后,在SPEC CPU2006主目录下的result目录中,就会出现关于本次运行测试的各种测试报告,本次示例使用的报告是HTML格式的CINT2006.001.ref.html(对整型的测试报告)和CFP2006.001.ref.html(对浮点型的测试报告)。
这两个报告文件中,报告的第一部分中有总体的测试分数,报告中部的结果表格中记录了各个具体的基准测试的得分情况。分别在非虚拟化的原生系统和KVM客户机系统执行SPEC CPU2006,然后对比它们的测试报告中的分数即可得到对KVM虚拟化环境中CPU虚拟化性能的评估。
2)内核编译
本次内核编译的基准测试中采用的方法是:对Linux 3.7.0正式发布版本的内核进行编译,并用time命令对编译过程进行计时。关于内核编译测试中的内核配置,可以随意进行选择。
需要注意的是:不同的内核配置,它们的编译时间长度可能会相差较大,命令行操作如下。
[root@kvm-guest linux.git]# time make -j 4
<!--省略编译过程的输出信息;下面的时间只是演示需要,并非编译用的真实时间 -->
real 1m0.259s
user 0ml8.103s
sys 0m3.825s在time输出信息中,第一行real的时间标识表示实际感受到的从程序开始执行到程序终止所经过的时间长度,第二行user的时间表示CPU在用户空间执行的时间长度,第三行sys表示CPU在内核空间执行的时间长度。
在本次内核编译测试中,统计的时间是time命令输出信息的第一行(用real标识)中的时间长度。
3)Super PI
从http://superpi.ilbello.com/网页下载Linux版本的Super PI,然后运行super_pi可执行程序,本次Super PI的基准测试中选择执行了计算圆周率π的小数点后1048576(2的20次方)个数据位。在计算完成后,程序会输出本次计算花费的时间,命令行操作如下:
[root@kvm-guest super-pi]# ./super_pi 20
<!--省略其余输出信息-->
Start of PI calculation up to 1048576 decimal digits
<!--省略其余输出信息-->
Total calculation(I/O) time= 10.236( 0.284)
在x86-64架构的系统上运行Super PI执行程序,可能会提示找不到ld-linux.so.2共享库,这是由于Super PI程序比较老,是用32位的glibc链接而生成的,所以只需要在该64位系统中安装32位的glibc库即可,命令行操作如下:
[root@kvm-guest super-pi]# ./super_pi 20
./super pi: ./pi:/lib/ld-linux.so.2: bad ELF interpreter: No such file or directory
[root@kym-guest super-pi]# yum install glibc-2.12-1.80.e16.i686
4. 性能测试数据
注意,由于使用的硬件平台、操作系统、内核、qemu-kvm等对本次CPU性能测试都有较大影响,而且本次仅仅使用了Intel Xeon E5-4650处理器上的4个CPU线程,所以本次CPU性能测试数据并不代表该处理器的实际处理能力,测试数据中绝对值的参考意义不大,主要参考其中的相对值(即KVM客户机中的测试结果占原生系统中测试结果的百分比)。
1)SPEC CPU2006
在非虚拟化的原生系统和KVM客户机中,分别执行了SPEC CPU2006的rate base类型的整型和浮点型测试,总体结果如下图所示,测试的分数越高表明性能越好。

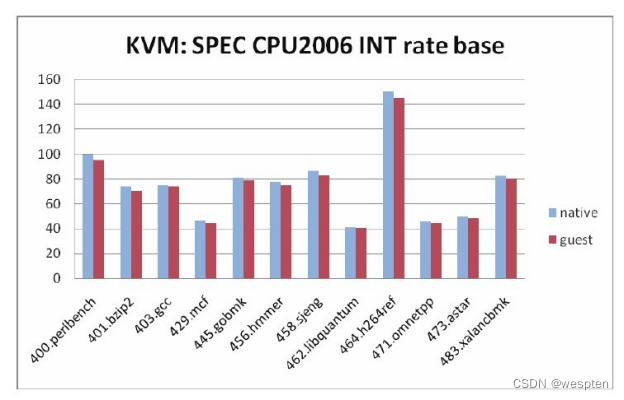
由图中的数据可知,通过SPEC CPU2006基准测试的度量,KVM虚拟化客户机中CPU执行整型计算的性能达到原生系统的97.04%,浮点型计算的性能达到原生系统的96.89%。
在SPEC CPU2006的整型计算测试中,各个基准测试的性能得分对比如下图所示,各个基准测试的结果都比较稳定,波动较小。
在SPEC CPU2006的浮点型计算测试中,各个基准测试的性能得分对比如下图所示。
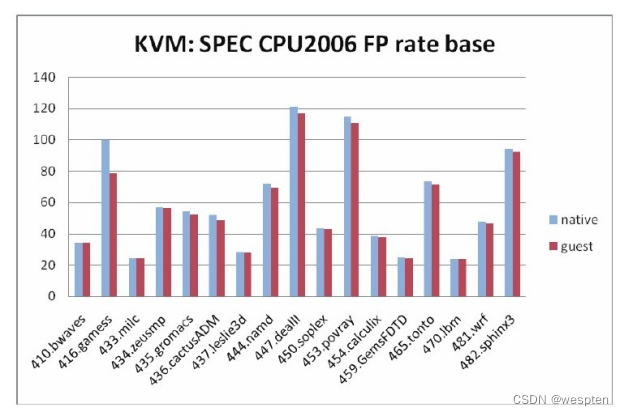
其中有两项测试(410.bwaves和470.lbm)的对比结果为100%,也有一项测试(416.gamess)的对比性能稍微差一点(为78.40%)。
2)内核编译
分别在原生系统和KVM客户机中编译Linux内核,记录所花费的时间。这里为了测试结果的准确性,下图展示的内核编译时间都是测试3次后计算的平均值。
如下图所示,时间越短说明CPU性能越好,在本次示例中,总体来说,KVM客户机中编译内核的性能为同等配置原生系统的94.15%左右。
3)Super PI
分别在原生系统和KVM客户机中执行Super PI基准测试程序,分别重复执行3次取平均值,一次计算所花费的平均时间对比如下图所示,其中时间越短说明性能越好。
从下图看来,本次Super PI测试示例中,客户机CPU性能约为原生系统的97.17%。

从SPEC CPU2006、内核编译、Super PI这3个基准测试的数据看来,其中有两个测试(CPU2006和Super PI)显示KVM虚拟化中CPU性能为原生系统的97%左右,另一个测试(内核编译)显示KVM中CPU性能为原生系统的94%。
由于内核编译也同时是磁盘I/O密集型的计算,所以可能是由于磁盘I/O的性能差异而导致效果与另外两个测试的结果稍微有一点差距。
3、内存性能测试
与CPU的重要性类似,内存也是一个计算机系统中最基本、最重要的组件,因为任何应用程序的执行都需要用到内存。将内存密集型的应用程序分别在非虚拟化的原生系统和KVM客户机中运行,然后根据它们的运行效率就可以粗略评估KVM的内存虚拟化性能。
对于内存的性能测试,可以选择SPECjbb2005、SysBench、内核编译等基准测试(因为它们同时也是内存密集型的测试),还可以选择LMbench、Memtest86+、STREAM等测试工具。下面简单介绍几种内存性能测试工具。
1. 内存性能测试工具
1)LMbench
LMbench是一个使用GNU GPL许可证发布的免费和开源的自由软件,可以运行在类UNIX系统中以便比较它们的性能,其官方网址是http://www.bitmover.com/lmbench/。LMbench是一个用于评价系统综合性能的可移植性良好的基准测试工具套件,主要关注两个方面:带宽(bandwidth)和延迟(latency)。LMbench中包含很多简单的基准测试,覆盖了文档读写、内存操作、管道、系统调用、上下文切换、进程创建和销毁、网络等多方面的性能测试。
另外,LMbench能够对同级别的系统进行比较测试,反映不同系统的优劣势,通过选择不同的库函数就能够比较库函数的性能;更重要的是,作为一个开源软件,LMbench提供一个测试框架,假如测试者对测试项目有更高的测试需要,能够通过修改少量的源代码达到目的(比如现在只能评测进程创建、终止的性能和进程转换的开销,通过修改部分代码即可实现线程级别的性能测试)。
2)Memtest86+
Memtest86+是基于Chris Brady所写的著名的Memtest86改写的一款内存检测工具,其官方网址为http://www.memtest.org/。该软件的目标是提供一个可靠的软件工具,进行内存故障检测。Memtest86+同Memtest86一样是基于GNU GPL许可证进行开发和发布的,它也是免费和开源的。
Memtest86+对内存的测试不依赖于操作系统,它提供了一个可启动文件镜像(如ISO格式的镜像文件),将其烧录到软盘、光盘或U盘中,启动系统时就从软驱、光驱或U盘中的Memtest86+启动,之后就可以对系统的内存进行测试。在运行Memtest86+时,操作系统都还没有启动,所以此时的内存基本上是未使用状态(除了BIOS等可能占用小部分内存)。一些高端计算机主板甚至将Mestest86+默认集成到BIOS中。
3)STREAM
STREAM是一个基准测试程序,用于衡量系统在运行一些简单矢量计算内核时能达到的最大内存带宽和相应的计算速度,其官方网址为http://www.cs.virginia.edu/stream/。STREAM可以运行在DOS、Windows、Linux等系统上。
另外,STREAM的作者还开发了对STREAM进行扩充和功能增强的工具STREAM2,可以参考其主页http://www.cs.virginia.edu/stream/stream2/。
对KVM内存虚拟化性能的测试,使用LMbench基准测试工具。
2. 测试环境配置
对KVM的内存虚拟化性能测试的测试环境配置,环境配置基本相同,下面仅说明不同之处和需要强调的地方。
本次对内存的性能测试中,使用的CPU资源为两个CPU线程,非虚拟化原生系统使用2GB内存,KVM宿主机拥有4GB内存,这是通过GRUB配置文件中的内核选项来控制的,如表所示。

KVM客户机使用两个vCPU和2GB内存,在宿主机中启动客户机的命令如下:
qemu-system-x86_64 -smp 2 -m 2G -drive rhel6u3.img,if=virtio -net nic -net tap -vnc :0 --daemonize
值得注意的是,本次测试的Intel平台是支持EPT和VPID的,对于内存测试,只要硬件支持,KVM也默认使用EPT、VPID。EPT和VPID(特别是EPT)对KVM中内存虚拟化的加速效果是非常明显的,所以要保证能使用它们。
3. 性能测试方法
选取LMbench工具进行内存的性能测试,分别在原生系统和KVM客户机系统中执行LMbench基准测试,然后对比各项测试的得分即可评估KVM内存虚拟化的性能。
1)下载LMbench
从其官方网址http://www.bitmover.com/lmbench/get_lmbench.html下载LMbench测试程序的第3版。
2)编译LMbench
对下载的lmbench3.tar.gz文件进行解压,然后运行make命令即可进行编译。在编译过程中,可能遇到如下编译错误提示。
[root@kvm-guest lmbench3]# make
<!--此处省略输出信息-->
gmake[2]:*** No rule to make target'../SCCS/s.ChangeSet',needed by 'bk.ver'. Stop. gmake[2]:Leaving directory '/root/memory/lmbench3/src'
make[1]:*** [lmbench] Error 2
make[1]: Leaving directory '/root/memory/lmbench3/src'
make:*** [build] Error 2
该编译错误并不影响实际的测试功能,有两个方法用来绕过这个编译错误。一个方法是建立SCCS目录,然后在SCCS目录中建立s.ChangeSet文件,命令行操作如下:
[root@kvm-guest lmbench3]# mkdir SCCS
[root@kvm-guest lmbench3]# touch SCCS/s.ChangeSet
另一个方法是修改src/Makefile,将其中的下面一行的bk.ver字符删除,从而不需要编译bk.ver这个目标。
$O/lmbench : ../scripts/lmbench3)执行LMbench基准测试
运行make results命令即可执行LMbench中的默认测试,命令行操作如下:
[root@kvm-guest lmbench3]# make results
运行make results后,在正式运行测试之前,会有一些交互式的操作以便确认测试时使用的具体配置,多数的提示只需要按Enter键选择默认值即可。在本次测试中,没有使用默认值的配置有3个,分别是LMbench测试的内存值、处理器时钟频率,以及是否将测试结果发到LMbench3的官方邮箱,如下:
MB [default 1393] 1024 #这个值如果过大,需要很长的测试时间
Processor mhz [default 3289 MHz,0.3040 nanosec clock] 2700
# 这里默认的时钟频率不准确,所以根据 /proc/cpuinfo中的如下值来填写
# "model name :Intel(R) Xeon(R) CPU E5-4650 0 @ 2.70GHz"
Mail results [default yes] no #不将结果发Email给开发者
4)查看测试结果
LMbench根据配置文档执行完所需要的测试项之后,在results目录下根据系统类型、系统名和操作系统类型等生成一个子目录,测试结果文档按照“主机名+序号”的命令方式存放于该目录下。
运行make see命令可以查看测试结果报告及其说明:
[root@kvm-guest lmbench3]# make see
在本次测试中,分别在原生系统和KVM客户机中执行了LMbench基准测试,将测试结果文档统一放在lmbench3/results/x86_64-linux-gnu/目录中,然后运行make see命令即可查看到非常直观的两次测试结果进行对比的报告。
4. 性能测试数据
分别在非虚拟化原生系统和KVM客户机的RHEL 6.3系统中执行LMbench基准测试,然后将测试结果文档放在同一目录下,运行make see命令即可查看到比较清晰的性能对比。make see命令的输出信息代表的测试结果的示例如下:



从上面的测试结果可以看出,KVM虚拟化中内存的带宽和延迟,与原生系统相比都是比较接近的。
所以,可以粗略地得出结论:在硬件提供的内存虚拟化技术(如Intel的EPT)支持下,QEMU/KVM的内存虚拟化性能比较良好,可以达到原生系统95%以上的性能。
4、网络性能测试
如果KVM客户机中运行网络服务器对外提供服务,那么客户机的网络性能也是非常关键的。只要是需要快速而且大量的网络数据传输的应用都可以作为网络性能基准测试工具,可以是专门用于测试网络带宽的Netperf、Iperf、NETIO、Ttcp等,也可以是常用的Linux上文件传输工具SCP。
下面简单介绍几种常用的网络性能测试工具。
1. 网络性能测试工具
1)Netperf
Netperf是由HP公司开发的网络性能基准测试工具,是非常流行网络性能测试工具,其官方主页是http://www.netperf.org/netperf/。
Netperf工具可以运行在UNIX、Linux和Windows操作系统中。Netperf的源代码是开放的,不过它和普通开源软件使用的许可证协议不完全一样,如果想使用完全开源的软件,可以考虑采用GNU GPLv2许可证发布的netperf4工具(http://www.netperf.org/svn/netperf4/)。
Netperf可以测试网络性能的多个方面,主要包括使用TCP、UDP等协议的单向的批量数据传输模式和请求-响应模式的传输性能。Netperf主要测试的项目包括:使用BSD Sockets的TCP和UDP连接(IPv4和IPv6)、使用DLPI接口的链路级别的数据传输、Unix Domain Socket、SCTP协议的连接(IPv4和IPv6)。
Netperf采用客户机/服务器(Client/Server)的工作模式:服务端是netserver,用来侦听来自客户端的连接,客户端是netperf,用来向服务端发起网络测试。在客户端与服务端之间,首先建立一个控制连接,用于传递有关测试配置的信息和测试完成后的结果;在控制连接建立并传递了测试配置信息以后,客户端与服务端之间会另外建立一个测试数据连接,用来传递指定测试模式的所有数据;当测试完成数据连接就断开,控制连接会收集好客户端和服务端的测试结果然后让客户端展示给用户。为了尽可能模拟更多真实的网络传输场景,
Netperf有非常多的测试模式供选择,包括TCP_STREAM、TCP_MAERTS、TCP_SENDFILE、TCP_RR、TCP_CRR、TCP_CC、UDP_STREAM、UDP_RR等。
2)Iperf
Iperf是一个常用的网络性能测试工具,它是用C++编写的跨平台的开源软件,可以在Linux、UNIX和Windows系统上运行,其项目主页是http://sourceforge.net/projects/iperf/。
Iperf支持TCP和UDP的数据流模式的测试,用于衡量其吞吐量。与Netperf类似,Iperf也实现了客户机/服务器模式,Iperf有一个客户端和一个服务端,可以测量两端的单向和双向数据吞吐量。当使用TCP功能时,Iperf测量有效载荷的吞吐带宽;当使用UDP功能时,Iperf允许用户自定义数据包大小,并最终提供一个数据包吞吐量值和丢包值。另外,有一个项目叫做Iperf3(项目主页为http://code.google.com/p/iperf/),它完全重新实现了Iperf,其目的是使用更小、更简单的源代码来实现相同的功能,同时也开发了可用于其他程序的一个函数库。
3)NETIO
NETIO也是个跨平台的源代码公开的网络性能测试工具,它支持UNIX、Linux和Windows平台,其作者的关于NETIO的主页是http://www.ars.de/ars/ars.nsf/docs/netio。NETIO也是基于客户机/服务器的架构,它可以使用不同大小的数据报文来测试TCP和UDP网络连接的吞吐量。
4)SCP
SCP是Linux系统上最常用的远程文件复制程序,它可以作为实际的应用来测试网络传输的效率。用SCP远程传输同等大小的一个文件,根据其花费时间的长短可以粗略评估出网络性能的好坏。
在本次网络性能测试中,采用Netperf基准测试工具和SCP工具来评估KVM虚拟化中客户机的网络性能。
2. 测试环境配置
对KVM的网络虚拟化性能测试的测试环境配置,环境配置基本相同,下面仅说明不同之处和需要强调的地方。
本次对网络的性能测试中,使用的CPU资源为4个CPU线程,非虚拟化原生系统使用8GB内存,KVM宿主机拥有12GB内存,这是通过GRUB配置文件中的内核选项来控制的,如喜爱表所示。

网络测试需要增加相应的网卡,本次测试分别使用Intel 82576(代号Kawela)和Intel 82599(代号Niantic)两种型号的网卡进行测试。
在测试SR-IOV类型的网络时,在加载这两种网卡的驱动程序时,打开SR-IOV的功能,使用的命令分别为modprobe igb max_vfs=2和modprobe ixgbe max_vfs=2。
通过lspci命令查看已经打开SR-IOV功能后的网卡具体信息,示例如下:
02:00.0 Ethernet controller:Intel Corporation 82599EB
10-Gigabit SFI/SFP+ Network Connection(rev 01) #82599 PF
02:10.0 Ethernet controller: Intel Corporation 82599 Ethernet
Controller Virtual Function (rev 01) #82599 VF
<!--省略其他PCI设备的输出信息-->
08:00.0 Ethernet controller: Intel Corporation 82576 Gigabit
Network Connection (rev 01) #82576 PF
09:10.0 Ethernet controller: Intel Corporation 82576 Virtual
Function (rev 01) #82576 VF
在本次测试中,分别对KVM客户机中使用默认rtl8139模式的网桥网络、使用e1000模式的网桥网络、使用virtio-net模式(QEMU做后端驱动)的网桥网络、使用virtio-net模式(vhost-net做后端驱动)的网桥网络、VT-d直接分配PF、SR-IOV直接分配VF等6种模式进行测试。
为了实现这6种模式,启动客户机的qemu-kvm命令示例如下(使用82576网卡测试时没有使用第4种vhost=on配置):
# 1.默认rt18139网卡的网桥网络
qemu-system-x86_64 -smp 4 -m 8G -drive file=rhel6u3.img,if=virtio -net nic -net tap
# 2.e1000网卡的网桥网络
qemu-system-x86_64 -smp 4 -m 8G -drive file=rhe16u3.img,if=virtio -net nic,model=e1000 -net tap
# 3.virtio-net模式的网桥网络(vhost=off)
qemu-system-x86_64 -smp 4 -m 8G -drive file=rhel6u3.img,if=virtio -netdev tap,id=nicl,vhost=off,vnet_hdr=on -device virtio-net-pci,netdev=nicl
# 4.virtio-net模式的网桥网络(vhost=on)
qemu-system-x86_64 -smp 4 -m 8G -drive file=rhel6u3.img,if=virtio -netdev tap,id=nicl,vhost=on,vnet_hdr=on -device virtio-net-pci,netdev=nicl
# 5. VT-d直接分配PF
qemu-system-x86_64 -smp 4 -m 8G -drive file=rhe16u3.img,if=virtio -device pci-assign,host=02:00.0 -net none
# 6. SR-IOV直接分配VF
qemu-system-x86_64 -smp 4 -m 8G -drive
file=rhe16u3.img,if=virtio -device pci-assign,host=02:10.0 -net none
在本次测试中,网桥网络在宿主机中都绑定在82576或82599的PF上。另外,为了尽量排除交换机等瓶颈的影响,客户端和服务端是使用网线直连两块相同网卡来测试网络带宽的,在测试一块网卡在虚拟化中的性能时,客户端也使用同样型号的网卡,并且配置保持不变,同时调整服务器端KVM虚拟化启动客户机时使用的网卡参数,然后使用Netperf测试工具测试即可对比各种配置的网卡性能。
使用SCP进行文件远程复制的测试时,需要在客户端准备一个20GB大小的文件,然后记录在服务端用SCP工具复制这个文件所需的时间。
3. 性能测试方法
在本次网络性能测试中,将被测试的原生系统或者KVM客户机作为服务端,分别测试服务端在各种配置方式下的网络性能。
1)Netperf
首先下载Netperf最新的2.6.0版本,然后配置、编译、安装即可得到Netperf的客户端和服务端测试工具,分别是位于src目录下的netperf和netserver两个可执行文件,命令行操作示例如下:
[root@kvm-guest ~]# wget\
ftp://ftp.netperf.org/netperf/netperf-2.6.0.tar.gz
[root@kvm-guest ~]#tar -zxvf netperf-2.6.0.tar.gz
[root@kvm-guest ~]#cd netperf-2.6.0
[root@kvm-guest netperf-2.6.0]# ./configure
[root@kvm-guest netperf-2.6.0]# make
[root@kvm-guest netperf-2.6.0]# 1s src/netperf
[root@kvm-guest netperf-2.6.0]# 1s src/netserver
[root@kvm-guest netperf-2.6.0]# make install
在服务端运行netserver程序即可,命令行操作如下:
[root@kvm-quest~]# netserver
Starting netserver with host 'IN(6)ADDR_ANY'port '12865' and family AF
然后,在客户端运行netperf程序对服务端进行网络性能测试。假设服务端的IP地址为10.0.0.1,客户端IP地址为10.0.0.2。在客户端发起的Netperf测试的命令如下:
# 使用Intel 82576网卡时的netperf客户端命令
[root@net-client ~]# netperf -H 10.0.0.1 -1 60 -t TCP_STREAM --m 1500
# 使用Intel 82599网卡时的netperf客户端命令
[root@net-client~]# netperf -H 10.0.1 -l 60 -t TCP_STREAM
<!--此处省略其余输出信息-->
87380 16384 16384 60.00 9397.11从上面的示例可以看出,使用Intel 82576千兆网卡时,某次测试的吞吐量(这里指带宽)为940.73 Mb/s,使用82599万兆网卡时带宽达到了9397.11 Mb/s。
在netperf命令中,-H name|IP表示连接到远程服务端的主机名或IP地址,-l testlen表示测试持续的时间长度(单位是秒),-t testname表示执行的测试类型(这里指定为TCP_STREAM这个很典型的类型)。“--”符号后面的是表示特定测试的一些选项,比如测试Intel 82576时用"-- -m 1500"指定客户端发送缓冲为1500字节。
可以使用netperf -h(或man netperf)命令查看netperf程序的帮助文档,更详细的解释可以参考Netperf 2.6.0的官方在线文档。
在Netperf测试过程的60秒内,同时使用sar命令记录KVM宿主机的40秒内的CPU使用率,命令行操作如下:
[root@jay-linux ~]# sar -u 2 20 &>sar-1.log
该命令表示每2秒采样一次CPU使用率,共采样20次,得到CPU利用率的采样日志。
_x86_64_
Linux 3.7.0 (jay-linux) 12/27/2012
CPU
*user
&iowait nice 0.00
11:08:04 AM
0.00 0.00
11:08:06 AM all 13.03 0.00 5.78 11:08:08 AM all 11.78 0.00 14.45 <!--此处省略其余信息-->
0.00
73.19 0.09
Average:all 12.18 0.00 14.54
(4 CPU)
steal
%system
%idle
71.19 73.77
CSDN @wespten
0.00
在本次实验中,主要观测了CPU空闲(idle)百分比的平均值(如上面信息的最后一行的最后一个数值),而将其余部分都视为已经被占用的CPU资源。在带宽能达到基本相同的情况下,CPU空闲的百分比越高,说明Netperf服务端消耗的CPU资源越少,这样的系统性能就越高。
另外,在本次Netperf的测试过程中,发现在宿主机中KSM相关进程消耗了一些CPU资源,在内存资源充足的情况下,在KVM宿主机中选择将KSM关闭能让82599网卡测试时得到的网络带宽数值稍微高一些,命令行操作如下:
[root@jay-linux ~]# service ksmtuned stop
Stopping ksmtuned: [OK]
[root@jay-linux ~]# echo 0 >/sys/kernel/mm/ksm/run
2)SCP
在非虚拟化原生系统和KVM客户机中分别用SCP命令从一台用网卡直连的客户端机器远程复制一个20 GB的文件,复制完成后SCP命令会打印花费的时间。通过比较SCP时间的长短,即可以粗略地反映网络性能。
SCP命令行操作如下:
[root@kvm-guest~]# scp 10.0.0.2:/root/temp.img /tmp/4. 性能测试数据
本次KVM虚拟化网络性能测试的Netperf和SCP基准测试都是分别收集了3次测试数据后计算的平均值。
1)Netperf
使用Intel 82576、82599网卡对KVM网络虚拟化的性能进行测试得到的数据,与非虚拟化原生系统测试数据的对比。图中显示的吞吐量(throughput)越大越好,吞吐量相近时,CPU空闲百分比也是越大越好。
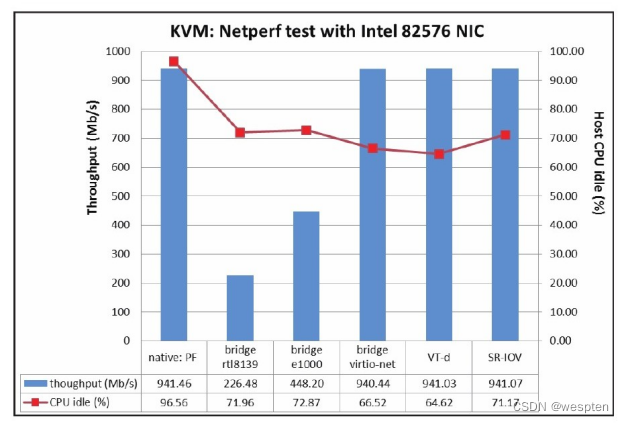
Netperf使用Intel 82599网卡的测试数据对比 :
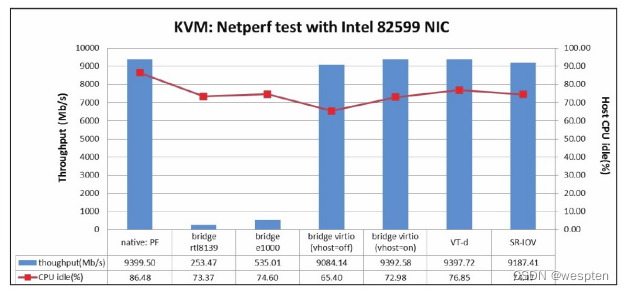
由上图信息可知,使用virtio、VT-d、SR-IOV等方式的网卡虚拟化可以达到和原生系统上的网卡差不多的高性能。其中,VT-d、SR-IOV方式直接分配网卡设备给客户机使用时,其CPU使用率比virtio的方式略低3%~5%(由于宿主机是4个CPU线程,CPU资源节省量相当于一个CPU线程的12%~20%),不过VT-d、SR-IOV的使用可能会丧失动态迁移的灵活性。
virtio方式的网络设备比纯软件模拟的rtl8139、e1000型号网卡的性能要好得多,不过virtio方式要求客户机有virtio-net驱动才能使用网络。
另外,在达到非常大的网络带宽时,使用vhost-net作为后端网络驱动的性能比使用QEMU作为后端驱动的virtio性能要好一些。在本次实验中纯软件模拟的rtl8139、e1000网卡的性能相对较差,吞吐量比较低,一般在500 Mb/s以内。也曾使用其他型号的千兆以太网卡,比如采用e1000模式的虚拟网卡在KVM虚拟化客户机中的吞吐量也能达到800 Mb/s。
2)SCP
在原生系统和采用各种网络配置的KVM客户机中,使用SCP命令远程复制一个20GB的文件,记录其所花费时间,其中所用的时间越短,表明网络性能越好。

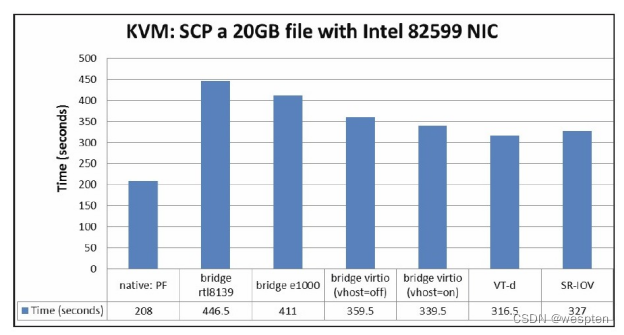
SCP测试结果对比的趋势与Netperf的测试结果相似。不过,客户机中采用几个不同的网络方式对它们传输时间的影响不是太大,这是因为SCP复制受到本地磁盘I/O的限制,即使网络性能很好也不能达到非常快的SCP复制速度。而在客户机中的SCP比原生系统的速度都要慢得多,这同样是因为原生系统的磁盘I/O速度比客户机中要快得多。
对KVM的网络性能测试数据中,可以谨慎而粗略地得出如下推论:
- virtio、VT-d和SR-IOV等方式的网络,可以达到和原生系统网络差不多的性能;
- 在达到相同网络带宽时,VT-d和SR-IOV方式占用的CPU资源比virtio略少;
- 使用vhost-net做后端驱动比使用QEMU做后端驱动的virtio网络性能略好;
- 纯软件模拟的rtl8139和e1000网卡的性能相对较差;
当然,这里的测试还不够完善(如Netperf工具仅测试了TCP_STREAM类型),与真正应用程序的网络使用情况并不完全相同。另外,由于QEMU纯软件模拟的rtl8139网卡的配置非常简单且兼容性很好,在对网络带宽不敏感的情况下,它依然是一个不错的选择,而且QEMU也默认提供模拟的rtl8139网卡。
5、 磁盘I/O性能测试
在一个计算机系统中,CPU获取自身缓存数据的速度非常快,读写内存的速度也比较快,内部局域网速度也比较快(特别是使用万兆以太网),但是磁盘I/O的速度是相对比较慢的。
很多日常软件的运行都会读写磁盘,而且大型的数据库应用(Oracle、MySQL等)都是磁盘I/O密集型的应用,所以在KVM虚拟化中磁盘I/O的性能也是比较关键的。测试磁盘I/O性能的工具有很多,如DD、IOzone、Bonnie++、Fio、iometer、hdparm等。下面简单介绍其中几个工具。
1. 磁盘I/O性能测试工具
1)DD
DD(命令为dd)是Linux上一个非常流行文件复制工具,在复制文件的同时可以根据其具体选项进行转换和格式化等操作。通过DD工具复制同一个文件(相同数据量)所需要的时间长短即可粗略评估磁盘I/O的性能。一般的Linux系统中都自带这个工具,用man dd命令即可查看DD工具的使用手册。
2)IOzone
IOzone是一个常用的文件系统基准测试工具,它通过多种文件操作(如普通的读写、重读、重写、随机的读写)来衡量一个文件系统的性能。IOzone的官方主页是http://www.iozone.org/。IOzone可以运行在包括Linux、UNIX、Windows等在内的多个操作系统平台上。在测试完成之后,它还提供一个工具,可以根据测试结果绘制出3D图形以便看出I/O性能趋势。
3)Bonnie++
Bonnie++是基于Bonnie[7]代码编写的软件,使用一系列对硬盘驱动器和文件系统的简单测试来衡量其性能。Bonnie++可以模拟数据库去访问一个单一的大文件,也可以模拟Squid创建、读取和删除许多小文件。它可以实现有序地读写一个文件,也可以随机地查找一个文件中的某个部分,而且支持按字符方式和按块方式读写。
4)hdparm
hdparm是一个用于获取和设置SATA和IDE设备的参数的工具,在RHEL 6.3中可以用yum install hdparm命令来安装hdparm工具。hdparm可以粗略地测试磁盘的I/O性能,通过如下的命令即可粗略评估sdb磁盘的读性能。
hdparm -tT /dev/sdb选择DD、IOzone、Bonnie++这三种工具用于KVM虚拟化的磁盘I/O性能测试。
2. 测试环境配置
对KVM的磁盘I/O虚拟化性能测试的测试环境配置,环境配置基本相同,下面仅说明不同之处和需要强调的地方。
在本次对磁盘I/O的性能测试中,尽量减少页面缓存的作用,使用较少内存。使用的CPU资源为两个CPU线程,非虚拟化原生系统使用2GB内存,KVM宿主机拥有4GB内存,这是通过GRUB配置文件中的内核选项来控制的。
在实验中使用西部数据生产的1 TB的SATA硬盘,型号如下:
WDC-WD1002FAEX-00Z3A0(西部数据1TB硬盘)
由于文件系统的类型对磁盘I/O的性能是有影响的,因此本次磁盘I/O性能测试中,原生系统、KVM宿主机、KVM客户机系统中统一使用ext4格式的文件系统。
本次测试评估了QEMU/KVM中的纯软件模拟的IDE磁盘和使用virtio-blk驱动的磁盘,启动客户机的qemu-kvm命令行分别如下:
#1.使用IDE磁盘
qemu-system-x86_64 -smp 2 -m 2G -drive file=rhel6u3.img,if=none,id=ide-disk0,format=raw,cache=none -device ide-hd,drive=ide-disk0 -net nic -net tap
#2.使用virtio-blk磁盘
qemu-system-x86_64 -smp 2 -m 2G -drive file=rhel6u3.img,if=none,id=virtio-disk0,format=raw,cache=none -device virtio-blk-pci,drivewvirtio-disk0 -net nic -net tap
从上面的命令行中可以看出,客户机镜像文件都是raw格式的,并且配置"cache=none"用来绕过页面缓存。配置"cache=none"虽然绕过了页面缓存,但是没有绕过磁盘自身的磁盘缓存;如果要在宿主机中彻底绕过这两种缓存,可以在启动客户机时配置"cache=directsync"。不过由于"cache=directsync"配置会让客户机中磁盘I/O效率比较低,所以这种配置用得比较少,常用的配置一般为"cache=writethrough"、"cache=none"等。
由于启动客户机时使用的磁盘配置选项"cache=xx"的设置对磁盘I/O测试结果的影响非常大,所以本次结果仅能代表"cache=none"这样配置下的一次基准测试。
3. 性能测试方法
对非虚拟化的原生系统和KVM客户机都执行相同的磁盘I/O基准测试,然后对比其测试结果。
1)DD
DD工具对读取磁盘上文件的测试,测试4种不同的块大小,使用的命令如下:
dd if=file.dat of=/dev/nulliflag=direct bs=1k count=100k
dd if=file.dat of=/dev/nulliflag=direct bs=8k count=100k
dd if=file.dat of=/dev/nulliflag=direct bs=1M count=10k
dd if=file.dat of=/dev/nulliflag=direct bs=8M count=2k 在上面命令中,if=xx表示输入文件(即被读取的文件),of=xx表示输出文件(即写入的文件),这里为了测试读磁盘的速度,所以读取一个磁盘上的文件,然后将其写到/dev/null[8]这个空设备中。iflag=xx表示打开输入文件时的标志,此处设置为direct是为了绕过页面缓存,得到更真实的读取磁盘的性能。bs=xx表示一次读写传输的数据量大小,count=xx表示执行多少次数据的读写。
DD工具向磁盘上写入文件的测试,也测试4种不同的块大小,使用的命令如下:
dd if=/dev/zero of=dd1.dat conv=fsync oflag=direct bs=1k count=100k
dd if=/dev/zero of=dd1.dat conv=fsync oflag=direct bs=8k count=100k
dd if=/dev/zero of=ddl,dat conv=fsync oflag=direct bs=1M count=10k
dd if=/dev/zero of=dd1,dat conv=fsync oflag=direct bs=8M count=2k
在上面的命令中,为了测试磁盘写入的性能,使用了/dev/zero[9]这个提供空字符的特殊设备作为输入文件。conv=fsync表示每次写入都要同步到物理磁盘设备后才返回,oflag=direct表示使用直写的方式绕过页面缓存。conv=fsync和oflag=direct这两个配置都是为了写入数据是尽可能地绕过缓存,从而尽可能真实地反映磁盘的实际I/O性能。
关于dd命令的详细参数,可以用man dd命令查看其帮助文档。
2)IOzone
下载IOzone源代码(http://www.iozone.org/src/current/iozone3_414.tar),解压后进入iozone3_414/src/current目录下运行make linux-AMD64命令即可编译。在编译完成后,当前目录就生成了iozone可执行程序。命令行操作示例如下:
[root@jay-linux ~]# cdiozone3_414
[root@jay-linuxiozone3_414]# cdsrc/current
[root@jay-linux current]# make linux-AMD64
[root@jay-linux current]# 1s iozone在RHEL 6.3系统上,也可以用yum install iozone命令直接安装IOzone。
在本次磁盘I/O性能测试中,使用IOzone工具的测试命令为:
iozone -s 512m -r 8k -S 20480 -L 64 -I -i 0 -i 1 -i 2 -Rab iozone.xls在上面的命令参数中,-s 512m表示用于测试的文件大小为512 MB,-r 8k表示一条记录的大小(一次读写操作的数据大小)为8 KB,-S 20480表示本机的缓存大小是20480KB,-L 64表示缓存线路大小为64字节,-I表示使用直接I/O方式读写而绕过页面缓存,-i 0-i 1-i 2表示运行"0=write/rewrite,1=read/re-read,2=random-read/write"这三种测试,-Rab iozone.xls表示运行完整的自动模式进行测试并生成Excel格式的报告iozone.xls。
其中-S、-L的值通过如下命令查询得到,当然,也可不填写而让IOzone自己决定。
[root@jay-linux ~]# cat /proc/cpuinfo | grep cache
cache size: 20480 KB
cache_alignment: 64
IOzone是一个非常强大磁盘I/O测试工具,不同的参数可以得到不同的结果,关于其参数的详细信息,可以用man iozone命令查看,或者参考IOzone的官方文档[10]。
3)Bonnie++
从http://www.coker.com.au/bonnie++/网页下载bonnie++-1.03e.tgz文件,然后解压,对其进行配置、编译、安装的命令行操作如下:
[root@kvm-guest ~]# cdbonnie++-1.03e
[root@kvm-guest bonnie++-1.03e]# ./configure
[root@kvm-guest bonnie++-1.03e]# make
[root@kvm-guest bonnie++-1.03e]# make install
本次测试使用Bonnie++的命令如下:
bonnie++ -D -m kvm-guest -x 3 -u root
其中,-D表示在批量I/O测试时使用直接I/O的方式(O_DIRECT),-m kvm-guest表示Bonnie++得到的主机名为kvm-guest,-x 3表示循环执行3次测试,-u root表示以root用户运行测试。
在执行完测试后,默认会在当前终端上输出测试结果。可以将其CSV格式的测试结果通过Bonnie++提供的bon_csv2html转化为更容易读的HTML文档,命令行操作如下:
[root@kvm-guest bonnie++-1.03e]# echo
"native,4G,102817,88,58631,25,56712,4,108330,91,151383,7,299.
0,1,16,++++++,+++,++++++,+++,+++++,+++,+++++,+++,+++++,+++++,+++,+++++,+++"
| perl bon_csv2html > native-bonnie-1.html
Bonnie++是一个强大的测试硬盘和文件系统的工具,关于Bonnie++命令的用法,可以用man bonnie++命令获取帮助手册,关于Bonnie++工具的原理及测试方法的简介,可以参考其源代码中的readme.html文档。
4. 性能测试数据
分别用DD、IOzone、Bonnie++这3个工具在原生系统和KVM客户机中进行测试,然后对比其测试结果数据。为了尽量减小误差,每个测试项目都收集了3次测试数据,下面提供的测试数据都是根据3次测试计算出的平均值。
1)DD
使用DD工具测试磁盘读写性能,将得到的测试数据进行对比,如图所示,读写速度越大,说明磁盘I/O性能越好。

由数据可知,virtio方式的磁盘比纯模拟的IDE磁盘读写性能要好,特别是当一次读写的数据块较小时(bs=1k,bs=8k),virtio的读写速度大约是IDE的两倍。当一次读写的数据块较大时(如bs=1M,bs=8M),KVM客户机中virtio和IDE两种方式的磁盘的读写性能都与原生系统相差不大。另外,当bs=1M和bs=8M时,客户机的磁盘读性能比原生系统略好,出现这种情况是因为宿主机使用的是3.7.0的Linux内核,其磁盘I/O读性能比原生系统RHEL 6.3的性能更好一些。
2)IOzone
IOzone的测试数据。virtio方式的磁盘顺序读写性能比纯模拟的IDE磁盘要高不少,不过与原生系统的磁盘I/O性能相比仍然有不少的差距。在随机读写测试场景中,virtio和IDE方式都与原生系统的性能差别不大。另外,本次IOzone测试的是一次读写8 KB大小的数据块(-r 8k参数),本次测试结果与使用DD工具测试与bs=8k时的测试数据基本一致。
3)Bonnie++
Bonnie++的测试结果对,其中s-w表示顺序写(sequential write)、s-r表示顺序读(sequential read),s-w-per-char就表示按字符的顺序写,s-w-block表示按块的顺序写,s-rewrite表示顺序重写,s-r-per-char按字符的顺序读,s-r-block表示按块的顺序读,Random Seeks表示随机改变文件读写指针偏移量(使用lseek()和random()函数)。
本次Bonnie++测试没有指定一次读写数据块的大小,默认值是8 KB,所以图的测试结果与前面DD、IOzone工具测试每次读写8 KB数据时的测试结果是基本一致的。
可以看出,当一次读写的数据块较小时,KVM客户机中的磁盘读写速度比非虚拟化原生系统慢得比较多,而一次读写数据块较大时,磁盘I/O性能差距不大。在一般情况下,用virtio方式的磁盘I/O性能比纯模拟的IDE磁盘要好一些。
6、 KVM性能优化
1. CPU优化
优化一:(默认开启,不需要操作)
Inter的cpu运行级别,按权限级别高低Ring3->Ring1->Ring0(Ring2和Ring1暂时不使用)Ring3为用户态;Ring0为内核态。
如下图所示:

Ring3的用户态是没有权限管理硬件的,需要切换到内核态Ring0,这样的切换(系统调用)称为上下文切换,物理机到虚拟机多次的上下文切换,势必会导致性能出现问题。对于全虚拟化,inter实现了技术VT-x,在CPU硬件上实现了加速转换,CentOS7默认是不需要开启的。
优化二:CPU缓存绑定
[root@linux-node1 ~]# lscpu|grep cache
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 3072KL1是静态缓存,造价高。
L2,L3是动态缓存,通过脉冲的方式写入0和1,造价较低。
cache解决了cpu处理快,内存处理慢的问题,类似于memcaced和数据库。
如果cpu调度器把进程随便调度到其他cpu上,而不是当前L1,L2,L3的缓存cpu上,缓存就不生效了,就会产生miss,为了减少cache miss,需要把KVM进程绑定到固定的cpu上。
使用taskset进行绑定KVM进程到固定的CPU,减少Cache Miss。
taskset设定cpu亲和力,cpu亲和力是指CPU调度程序属性关联性是“锁定”一个进程,使他只能在一个或几个cpu线程上运行。对于一个给定的系统上设置的cpu。给定CPU亲和力和进程不会运行在任何其他CPU。
指定1和2号cpu运行25718线程的程序:
taskset -cp 1,2 25718让某程序运行在指定的cpu上:
taskset -c 1,2,4-7 tar jcf test.tar.gz test指定在1号CPU上后台执行指定的perl程序:
taskset –c 1 nohup perl pi.pl &2. 内存优化
优化一:内存转化
原本实现方式:
虚拟机的虚拟内存-->虚拟机的物理内存
宿主机的虚拟内存-->虚拟机的物理内存
现在实现方式:EPT(inter)
虚拟机的虚拟内存=====EPT=====宿主机的物理内存
VMM通过采用影子列表解决内存转换的问题,影子页表是一种比较成熟的纯软件的内存虚拟化方式,但影子页表固有的局限性,影响了VMM的性能,例如,客户机中有多个CPU,多个虚拟CPU之间同步页面数据将导致影子页表更新次数幅度增加,测试页表将带来异常严重的性能损失。
如下图为影子页表的原理图:

在此之际,Inter在最新的Core I7系列处理器上集成了EPT技术(对应AMD的为RVI技术),以硬件辅助的方式完成客户物理内存到机器物理内存的转换,完成内存虚拟化,并以有效的方式弥补了影子页表的缺陷,该技术默认是开启的,如下图为EPT技术的原理。

优化二:KSM内存合并
宿主机上默认会开启ksmd进程,该进程作为内核中的守护进程存在,它定期执行页面扫描,识别副本页面并合并副本,释放这些页面以供它用,CentOS7默认是开启状态。
[root@linux-node1 ~]# ps aux |grep ksmd
root 280 0.0 0.0 0 0 ? SN 20:37 0:00 [ksmd]优化三:大页内存
Linux默认的内存页面大小都是4K,HugePage进程会将默认的每个内存页面可以调整为2M,CentOS7默认开启的。
[root@linux-node1 ~]# cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
[root@linux-node1 ~]# ps aux|grep hugepage|grep -v grep
root 2810.0 0.0 00 ? SN 04:220:03 [khugepaged]3. 磁盘IO优化
IO调度算法,也叫电梯算法,详情请看:Linux I/O 调度算法 - 新运维社区。
下面为四种调度算法介绍:
Noop Scheduler:简单的FIFO队列,最简单的调度算法,由于会产生读IO的阻塞,一般使用在SSD硬盘,此时不需要调度,IO效果非常好
Anticipatory IO Scheduler(as scheduler)适合大数据顺序顺序存储的文件服务器,如ftp server和web server,不适合数据库环境,DB服务器不要使用这种算法。
Deadline Schedler:按照截止时间的调度算法,为了防止出现读取被饿死的现象,按照截止时间进行调整,默认的是读期限短于写期限,就不会产生饿死的状况,一般应用在数据库
Complete Fair Queueing Schedule:完全公平的排队的IO调度算法,保证每个进程相对特别公平的使用IO
查看本机Centos7默认所支持的调度算法:
[root@linux-node1 ~]# dmesg|grep -i “scheduler”
[ 1.332147] io scheduler noop registered
[ 1.332151] io scheduler deadline registered (default)
[ 1.332190] io scheduler cfq registered临时更改某个磁盘的IO调度算法,将deadling模式改为cfq模式:
[root@linux-node1 ~]# cat /sys/block/sda/queue/scheduler
noop [deadline] cfq
[root@linux-node1 ~]# echo cfq >/sys/block/sda/queue/scheduler
[root@linux-node1 ~]# cat /sys/block/sda/queue/scheduler
noop deadline [cfq]使更改的IO调度算法永久生效,需要更改内核参数:
[root@linux-node1 ~]# vim /boot/grub/menu.lst
kernel /boot/vmlinuz-3.10.0-229.el7 ro root=LABEL=/ elevator=deadline rhgb quiet