简述
YOLOR 是一种用于对象检测的最先进的机器学习算法,与 YOLOv1-YOLOv5 不同,原因在于作者身份、架构和模型基础设施的差异。YOLOR 代表“你只学习一种表示”,不要与 YOLO 版本 1 到 4 混淆,其中 YOLO 代表“你只看一次”。 YOLOR被提议为“将隐性知识和显性知识编码在一起的统一网络”。YOLOR研究论文的标题为“你只学习一种表示:多个任务的统一网络”的研究结果指出,结果证明了使用隐性知识的好处。
YOLOR 专门用于对象检测,而不是其他机器学习用例,例如对象识别或分析。这是因为对象检测侧重于使对象属于某个类别或类的一般标识符。相比之下,其他类型的机器学习用例需要更精确的流程。对象识别要求机器学习模型适应构成彼此对象的细微差别范围。
工作原理
人类能够基于视觉、听觉、触觉(显性知识)来学习和理解物理世界,但也基于过去的经验(内隐知识)。因此,人类能够利用通过正常学习获得并存储在大脑中的先前学习的丰富经验,有效地处理全新的数据。
基于这一想法,YOLOR研究论文描述了一种将显式知识(定义为基于给定数据和输入的学习)与潜意识学习的内隐知识相结合的方法。因此,YOLOR的概念是基于编码内隐和外显知识,类似于哺乳动物大脑如何结合内隐和外显知识来处理。 YOLOR 中提出的统一网络生成一个统一的表示,以同时服务于各种任务。 通过三个值得注意的过程,这种架构可以发挥作用:核空间对齐、预测细化和具有多任务学习的卷积神经网络 (CNN)。 根据结果,当将内隐知识引入已经用显式知识训练的神经网络时,该网络有利于各种任务的执行。
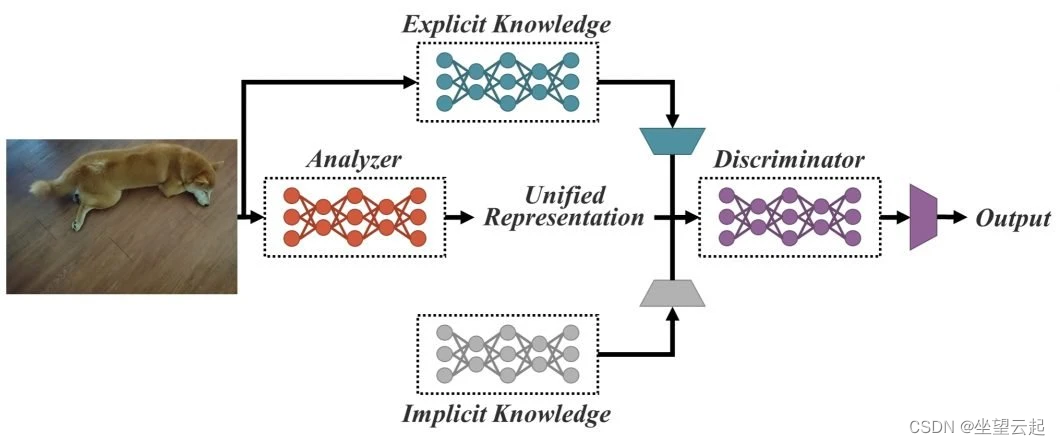
人类可以在单一输入的情况下回答不同的问题。给定一条数据,人类可以从不同的角度分析数据。例如,某物的照片可能会引起对所描绘的动作、位置等的不同反应。YOLOR 旨在为机器学习模型提供这种能力,以便它们能够在一个输入的情况下为许多任务提供服务。
卷积神经网络(CNN)通常实现一个特定的目标,而它们可以被训练为一次解决多个问题,这正是YOLOR的目标。CNN通常是在创建时考虑一个目标。当CNN学习如何分析输入以获得输出时,YOLOR试图让CNN既(1)学习如何获得输出,也(2)所有不同的输出可能是什么。它可以有多个输出,而不仅仅是一个输出。
性能和精度
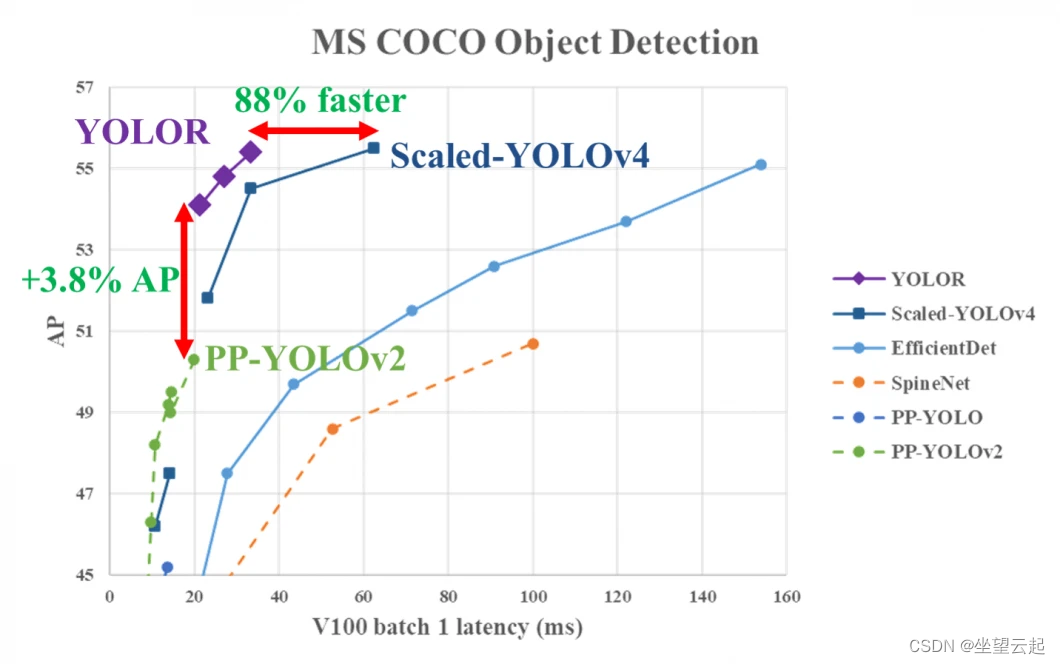
新的 YOLOR 算法旨在使用比较算法预测额外成本的一小部分来完成任务。因此,YOLOR 是一个统一的网络,可以一起处理隐性和显性知识,并产生由于该方法而改进的一般表示。 结合最先进的方法,YOLOR实现了与Scaled YOLOv4相当的目标检测精度,同时推理速度提高了88%。这使得 YOLOR 成为现代计算机视觉中最快的对象检测算法之一。在MS COCO数据集上,在相同的推理速度下,YOLOR 的平均精度比 PP-YOLOv2 高 3.8%。
显性/隐式信息
通过提供清晰的元数据或图像数据库,为神经网络提供明确的知识,这些元数据或图像数据库要么经过彻底注释,要么组织良好。
显式知识可以被认为是机器学习模型的抽认卡,具有清晰的定义和与这些图像相对应的图片/输入。 在模型通过抽认卡之后,它现在精通使用各自的定义或“类”对图像进行分类。
YOLOR 的显式知识是从神经网络的浅层获得的。这种知识直接对应于应该进行的观察。 显式深度学习是使用查询/密钥和非本地网络进行的,以获得使用输入数据的自我注意或自动选择内核。
隐性知识可以有效地帮助机器学习模型使用 YOLOR 执行任务。对于人类来说,隐性知识是潜意识中发展的。对于神经网络,隐式知识是通过深层的特征获得的。与观察不符的知识也被称为隐性知识。