目录
前言
之前我们已经进行了pyspark环境的搭建以及经过jupyter notebook进行过开发以及实现了一系列的函数功能.
但是一般我们跑spark都是在集群上面跑,只有测试一般在本地上测试,而且每个公司配置的spark集群的端口和设置的参数都有很大出入,故每种情况都有可能发生。所以一般任务提交的参数最好都需要能够清楚的明白对应功能。很多spark任务都会吃大量的内存以及队列资源,合理的安排spark资源十分重要,这些都需要我们在spark-submit指令上面配置。本篇文章将会将spark-submit的各类参数以及参数对应选项和其功能都会列举出来,并且写有对应场景的pyspark任务提交时参数配置,希望能够帮助到大家,还请点赞支持一下博主。
一、PySpark集群运行原理
我在之前的文章中对pyspark集群运行原理有过比较详细的解答:
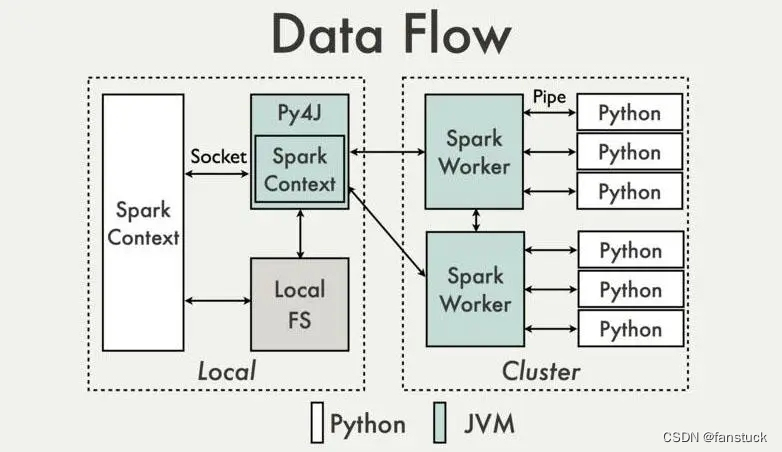
主节点的Python通过Py4j通信传递SparkContext,最后在JVM Driver上面生成SparkContxt。主节点JVM Driver与其他从节点的JVM Executor通信传输SparkContext,JVM Executor通过分解SparkContext为许多Task,给pyspark.daemon调用pyspark.work 从socket中读取要执行的python函数和数据,开始真正的数据处理逻辑。数据处理完成之后将处理结果写回socket,jvm中通过PythonRDD的read方法读取,并返回结果。最终executor将PythonRDD的执行结果上报到drive上,返回给用户。
总体而言也就是spark和python程序的一种转换,可以理解为将python程序转换成了scala的spark任务去执行,本质上还是spark任务的提交。故配置是和spark任务应该是一致的,从官方文档也能够了解:
二、spark-submit参数详解
在运行spark-submit指令的时候一般还是直接提交shell命令,或是在dolphinscheduler上,总之在集群上都可提交。spark的bin目录中的spark-submit脚本用于在集群上启动应用程序。它可以通过统一的接口使用Spark支持的所有集群管理器,因此不必为每个集群管理器配置应用程序。
对于Python,可以使用spark-submit的--py-files参数来添加.py、.zip或.egg文件,以便随应用程序一起分发。如果依赖多个Python文件,可以将它们打包成.zip或.egg文件。
1.指定运行目录
一旦绑定了用户应用程序,就可以使用bin/spark提交脚本启动它。该脚本负责使用Spark及其依赖项设置类路径,并可以支持Spark支持的不同集群管理器和部署模式:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]其中指定Hadoop配置可以通过HADOOP_CONF_DIR 指定conf目录。
2.--deploy-mode
使用--deploy-mode,指定运行Spark应用程序驱动程序的位置。Spark支持集群和客户端部署模式。
可选参数有两种:
| 选项 | 说明 |
| cluster | 在集群模式下,驱动程序在其中一个工作节点上运行,该节点在应用程序的Spark Web UI上显示为驱动程序。集群模式用于运行生产作业。逻辑运算与任务执行均在cluster上。 |
| client | 在客户端模式下,驱动程序在提交应用程序的本地运行。客户端模式主要用于交互和调试目的。注意,在客户端模式下,只有驱动程序在本地运行,所有其他执行器在集群上的不同节点上运行。这样逻辑运算在client上执行,任务执行在cluster上 |
3.--master
使用--master选项,可以指定要使用哪个集群管理器来运行应用程序。Spark目前支持Yarn、Mesos、Kubernetes、Stand-alone和local。这些的用途如下所述。
| 集群管理器 | 选项参数 | 说明 |
| Yarn | yarn | 提交到yarn模式部署的集群中,前提是集群是使用yarn管理的 |
| Mesos | mesos://HOST:PORT | 提交到mesos模式部署的集群中,并指定主节点的IP与端口 |
| Standalone | spark://HOST:PORT | 提交到standalone模式部署的spark集群中,并指定主节点的IP与端口 |
| Kubernetes | k8s://HOST:PORT k8s://https://HOST:PORT |
提交到Kubernetes模式部署的spark集群中,并指定主节点的IP与端口 |
| local | local local[k] local[K,F] |
local:提交到本地服务器执行,并分配单个线程 local[k]:提交到本地服务器执行,并分配k个线程 使用local[k,F]并指定F及其失败时应运行的尝试次数。 |
如果我们想要提交一个jar包使用,就可以这样写:
./bin/spark-submit \
--deploy-mode cluster \
--master yarn \
--class org.apache.spark.examples.SparkPi \
/spark-home/examples/jars/spark-examples_versionxx.jar 804.驱动程序和执行器资源
在提交应用程序时,还可以指定要为驱动程序和执行程序提供多少内存和内核。
| 选项 | 说明 |
| --driver-memory | Spark驱动程序使用的内存。 |
| --driver-cores | Spark驱动程序使用的CPU内核 |
| --num-executors | 要使用的执行器总数。 |
| --executor-memory | 用于执行器进程的内存量。 |
| --executor-cores | 用于执行器进程的CPU内核数。 |
| --total-executor-cores | 要使用的执行器颜色总数。 |
使用案例仍旧和上述差不多:
./bin/spark2-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 8g \
--executor-memory 16g \
--executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
/spark-home/examples/jars/spark-examples_versionxx.jar 80
5.--files和--verbose
这两个是经常使用到的选项:
| 选项 | 说明 |
| --file | 使用要使用的逗号分隔文件。 通常,这些文件可以是资源文件夹中的文件。 使用此选项,Spark将所有这些文件提交到集群。 |
| --verbose | 显示详细信息。例如,将spark应用程序使用的所有配置写入日志文件。 |
示例:下面的示例使用集群部署模式将应用程序提交给yarn集群管理器,每个执行器具有8g驱动程序内存、16g和2个内核。
./bin/spark2-submit \
--verbose
--master yarn \
--deploy-mode cluster \
--driver-memory 8g \
--executor-memory 16g \
--executor-cores 2 \
--files /path/log4j.properties,/path/file2.conf,/path/file3.json
--class org.apache.spark.examples.SparkPi \
/spark-home/examples/jars/spark-examples_versionxx.jar 80
6.Spark提交配置
Spark提交支持使用--config的几种配置,这些配置用于指定应用程序配置、洗牌参数和运行时配置。
大多数这些配置对于用Java、Scala和Python(PySpark)编写的Spark应用程序是相同的
| 配置参数 | 配置说明 |
| spark.sql.shuffle.partitions | 为更广泛的无序转换(联接和聚合)创建的分区数。 |
| spark.executor.memoryOverhead | 集群模式下每个执行器进程要分配的额外内存量,通常是JVM开销的内存。(PySpark不支持) |
| spark.serializer | org.apache.spark.serializer.<br>JavaSerializer(默认) org.apache.spark.serializer.KryoSerializer |
| spark.sql.files.maxPartitionBytes | 读取文件时每个分区使用的最大字节数。默认128MB。 |
| spark.dynamicAllocation.enabled | 指定是根据工作负载动态增加还是减少执行者的数量。默认为true。 |
| spark.dynamicAllocation .minExecutors |
启用动态分配时要使用的最小执行器数。 |
| spark.dynamicAllocation .maxExecutors |
启用动态分配时要使用的最大执行器数。 |
| spark.executor.extraJavaOptions | 指定JVM选项(请参见下面的示例) |
./bin/spark2-submit \
--master yarn \
--deploy-mode cluster \
--conf "spark.sql.shuffle.partitions=20000" \
--conf "spark.executor.memoryOverhead=5244" \
--conf "spark.memory.fraction=0.8" \
--conf "spark.memory.storageFraction=0.2" \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \
--conf "spark.sql.files.maxPartitionBytes=168435456" \
--conf "spark.dynamicAllocation.minExecutors=1" \
--conf "spark.dynamicAllocation.maxExecutors=200" \
--conf "spark.dynamicAllocation.enabled=true" \
--conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps" \
--files /path/log4j.properties,/path/file2.conf,/path/file3.json \
--class org.apache.spark.examples.SparkPi \
/spark-home/examples/jars/spark-examples_repace-spark-version.jar 80
或者,也可以将这些全局@$SPARK_HOME/conf/SPARK-defaults.conf设置为适用于每个SPARK应用程序。还可以通过编程方式使用SparkConf进行设置。Pyspark的配置我已经在另一篇文章有写:
PySpark数据分析基础:pyspark.sql.SparkSession类方法详解及操作+代码展示
三.PySpark程序提交配置选项
一般跑这种带有pyspark的python程序会有两种情况:
1.集群中没有安装python环境。
2.集群中没有程序依赖的第三方库。
下面将对于上面这两种情况提供解决方案:
对于已经安装了python环境的话,只要加入--py-file .py文件就好。当想要提交PySpark应用程序时,需要指定要运行的.py文件,并为依赖库指定.egg文件或.zip文件。这里有一下四个参数需要编辑:
| PYSPARK特定配置 | 说明 |
| --py-files | 使用--py文件添加.py、.zip或.egg文件。 |
| --config spark.executor.pyspark.memory | PySpark为每个执行器使用的内存量。 |
| --config spark.pyspark.driver.python | Python二进制可执行文件,用于驱动程序中的PySpark。 |
| --config spark.pyspark.python | Python二进制可执行文件,用于驱动程序和执行器中的PySpark。 |
对于没有加入第三方库采取上述参数直接配置就好了,若是需要加入简单的第三方库(例如jieba库)时,也只需要打包成zip,然后spark-submit命令中动态加载该模块即可。但是如果要使用复杂的第三方库(含.dll,.so文件,即动态加载库,如numpy、pandas),则处理起来就比较特殊,需要将整个python环境都打包,这有点像Pyinstaller。
解决方法如下:
1.构建一套虚拟环境
我们可以通过anaconda生成虚拟环境也可以通过pipenv来打包,总之我们需要包含提交的任务所包含所以依赖的环境,关于pipenv打包我认为是最简单的,大家可以参考这篇文章:
anaconda的打包可以使用可视化UI这样比较便捷,我们可以创建一个新的虚拟环境,只打上我们需要的依赖包,再将整个虚拟Python环境打包为zip,或tar.gz包
进入到虚拟环境下,如/home/hadoop/anaconda3/envs,使用以下命令将虚拟环境进行打包:
zip -r conda_env.zip conda_env # 虚拟环境为conda_env, 打包为conda_env.zip 文件
提交Pyspark Application,通过 --archives 选项指定 zip 包路径(可以将虚拟环境zip上传到HDFS或某个节点下 ),然后是在cluster、client模式下提交application,示例如下
HADOOP_CONF_DIR=/etc/hadoop/conf /data/anaconda3/envs/py3.6.13/bin/spark-submit
--master yarn \
--queue default \
--deploy-mode client \
--conf spark.yarn.dist.archives=hdfs:/py3-6-13.zip#python \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=python/py3.6.13/bin/python3.6\
--conf spark.pyspark.python=python/py3.6.13/bin/python3.6\
--conf spark.pyspark.driver.python=/data/anaconda3/envs/py3.6.13/bin/python3.6\
--conf spark.sql.catalogImplementation=hive\
--py-files hdfs:/.py.zip ./.py 2. 模块依赖问题原因
1.Driver 负责把本地的资源分发给 Container。
2.在 client 模式下,Driver 就找在 Client 端,可以把 client 端的资源分发,而 cluster 模式下,Driver 可在集群任一节点,该节点是没有资源的。
普通依赖:
在 client 模式下,Driver 可以自动收集资源,分发,无需上传依赖;
在 cluster 模式下,Driver 无法收集资源,必须上传依赖;
复杂依赖:
在工业环境中,使用的多是 cluster 模式,cluster 模式必须上传依赖。
在调试环节,多使用 client 模式,client 只需上传复杂依赖即可。