越来越多的数据处理使用NVIDIA 计算来实现大规模并行。加速计算的发展意味着无论是在分析、人工智能 (AI) 还是机器学习 (ML) 过程中,对存储的访问也需要更快。
如果数据访问很大程度影响执行时间,那么GPU加速带来的好处将是有限的。基于GPU的处理与基于CPU 的集群相比,可以驱动更高的数据访问吞吐量。随着用于分析和人工智能的处理集群与数据存储系统的分离,加速数据访问将变得更加重要。
NVIDIA已经和Alluxio社区开展合作,对大规模数据集缓存和GPU数据可用性进行高性能数据编排系统测试。Apache Spark 3.0,RAPIDS Accelerator for Apache Spark和 Alluxio 可用于:(1) 数据分析和商业智能;(2) 数据科学的数据预处理和特征工程。对于模型训练或推理,GPU 集群上的Spark 和分布式 TensorFlow 或PyTorch 都受益于使用分布式平台无关(distributed platform agnostic)的编排层所带来的 I/O 加速。
在本文中,我们将探讨:
在数据工作流的各个阶段,包括从数据提取-转换-加载(ETL) 到分析和人工智能/机器学习(AI/ML)阶段使用Alluxio数据编排平台的部署架构。
如何通过用于RAPIDS Accelerator for Apache Spark和Alluxio在无需修改任何代码的情况下加速Spark SQL/Dataframe。
使用Alluxio和RAPIDS Accelerator for Apache Spark的最佳实践。
GPU加速的Apache Spark,TensorFlow 或PyTorch在使用 Alluxio时的部署选项。
统一I/O 加速用于数据导入、ETL、分析和模型训练
典型的分析、机器学习或人工智能工作流是包含数据导入到数据准备,再到分析或人工智能的一系列步骤。为模型训练准备数据涉及数据预处理和特征工程,我们将其称为 ETL(提取-转换-加载)。分析工作流中的数据清理需要采用类似的步骤。
数据分析和ETL多使用Spark SQL和Dataframe API,二者通常都是迭代程序。随着GPU 和大型数据集的使用越来越多,对数据源的直接处理将得益于分布式缓存起到的I/O加速作用。
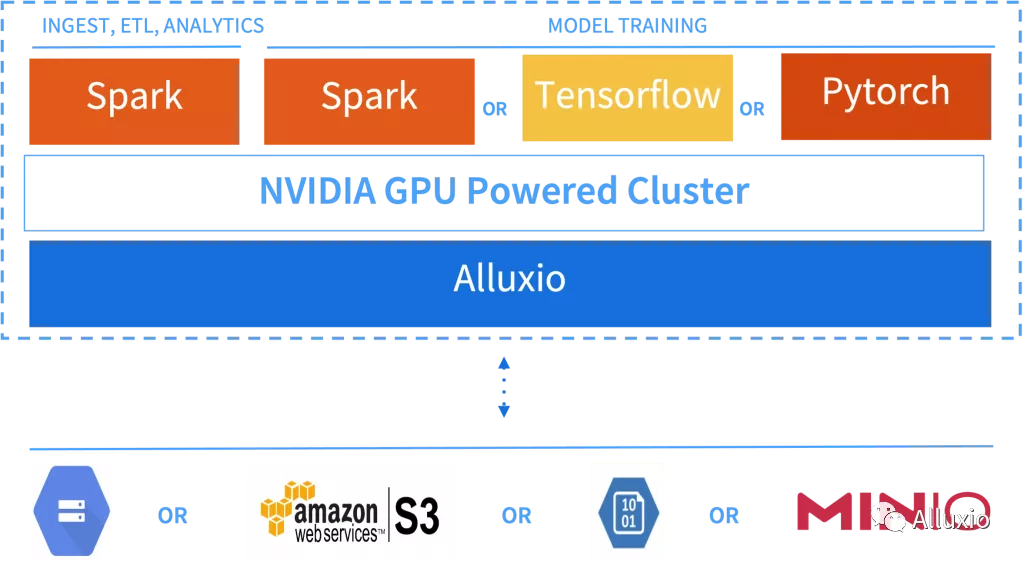
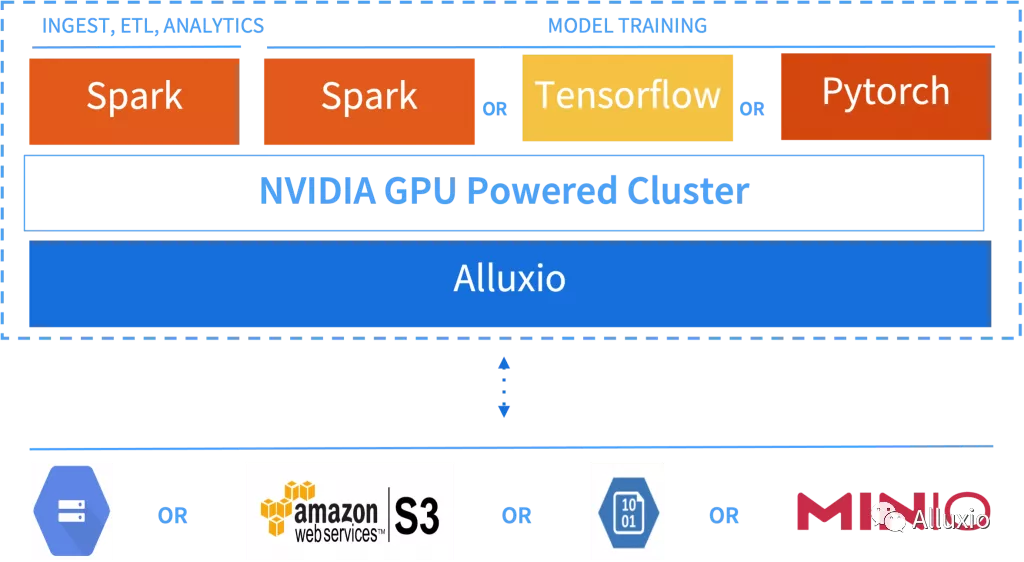
Alluxio数据编排层可用作数据流多个步骤共享的多数据源分布式缓存。Alluxio不受平台影响,提供了与平台的解耦,无论平台是部署在本地还是云上托管的 Hadoop 或 Kubernetes上。如图 1 所示,该架构通常适用于多种环境,可以根据当前阶段和工作负载类型灵活选择最适合的数据处理技术和基础架构。
RAPIDS用于Spark SQL和DataFrame的I/O加速
使用 RAPIDS Accelerator for Apache Spark的Apache Spark 3.0 能够在GPU加速的集群上对Spark SQL 或 DataFrame 作业进行并行计算。但是,此类作业的很大一部分是从远程数据源读取数据。如果数据访问速度缓慢,I/O 可能会影响端到端的应用程序执行时间。
使用Spark SQL和DataFrames的处理作业可以在NVIDIA GPU上运行,无需修改任何代码,且处理作业也得益于Apache Spark的RAPIDS 加速器中包含的优化。同样,如果使用 Alluxio 作为 Spark 应用程序的数据源,在不修改代码的情况下,就可以从部署数据编排层所带来的 I/O 加速中获益。图2显示了可用于GPU支持实例的推荐软件堆栈,在这里Alluxio利用CPU 和本地存储介质(如 NVMe)来管理缓存数据,而Spark利用GPU资源进行计算。

图 2. NVIDIA GPU 上的 Apache Spark 用于基于 SQL 的分析或用于ETL进行数据处理。
数据加载
使用RAPIDS Accelerator for Apache Spark和Alluxio时无需修改应用程序。下文讨论了用户最初可能遇到的两种场景。
场景1:对于使用Alluxio架构读取数据的现有用户,在使用RAPIDS Accelerator for Apache Spark时无需进行任何修改。可以像以前一样将数据加载到 Spark DataFrame 中,无需修改代码。
val df = spark.read.parquet(“alluxio://ALLUXIO_MASTER_IP:PORT/foo”)
场景2:对于正在使用 Spark 应用程序但想要首次部署Alluxio和RAPIDS加速器的用户,将使用Spark配置参数把现有存储路径映射到Alluxio路径。
用户应使用RAPIDS Spark配置参数来配置此映射,如下所示:
–conf spark.rapids.alluxio.pathsToReplace=“gs://foo->alluxio://ALLUXIO_MASTER_IP:PORT/foo”
使用配置参数集后,替换后的路径无需修改应用程序。例如,下述加载的Spark DataFrame 将按照路径 alluxio://ALLUXIO_MASTER_IP:PORT/foo 从Alluxio读取数据。
val df = spark.read.parquet(“gs://foo”)
此示例假设Bucket foo挂载在Alluxio FileSystem命名空间中的 /foo 位置。
基准测试结果
本节对高性能数据编排系统(使用 RAPIDS Accelerator for Apache Spark和 Alluxio)对于大型数据集的缓存和用于GPU处理的数据可用性的影响进行评估。我们使用了近 90 个 NVIDIA 决策支持 (NDS) 查询以及来自主流数据分析基准套件的相应数据集。这些基准查询运行3 TB 数据集, 该数据集以Parquet 格式存储在 Google Cloud Storage bucket中。
下图显示,在将90个NDS查询的总运行时间进行比较后发现,部署 Alluxio的NVIDIA GPU集群的性能提高了近 2 倍,与CPU集群相比,投资回报率(ROI)提高了70%。Google Cloud Dataproc 用于在CPU和GPU 集群的计算实例上部署服务。使用的实例配置见下图。
这些提升大多归功于Alluxio对于大型数据集的缓存能力,因此可以避免重复访问云存储。数据处理能力的增强使得数据科学家在整个数据科学生命周期中执行多项任务(例如数据导入、数据准备和数据探索)时都可获益,从而提高性能并降低成本。
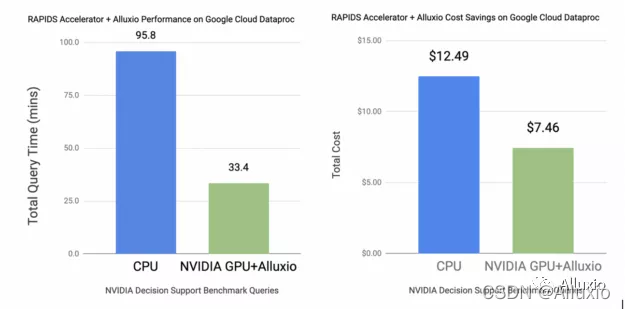
图 3:CPU 硬件配置:Master:n1-standard-4,Slave:4 x n1-standard-32(128 核,480GB RAM),GPU 硬件配置:Master:n1-standard-4,Slave:4 x n1- standard-32(128 核,480GB RAM + 16 x T4),CPU 云成本:7.82 美元/小时(基于 4 x n1-standard-32 的标准定价 + Dataproc 定价),GPU 云成本:13.41 美元/小时(基于 4 x n1-standard-32 + 16 xT4 的标准定价+ DataProc 定价)
部署Alluxio和Spark RAPIDS的最佳实践
Alluxio和 RAPIDS Accelerator for Apache Spark在默认配置下就能实现显著的性能改进,进行额外调优可进一步提高ROI。本节提供了此类推荐列表。
1. 将Alluxio工作节点与Spark工作节点部署在一起(co-locate)
Co-location使得应用程序能够对本地Alluxio worker执行短路读取和写入,比从Alluxio worker远程获取数据更高效。
2. 根据工作集大小配置缓存
为 Alluxio 分配足够的空间来缓存工作集至关重要。实际上,我们建议为频繁访问的数据的多个副本提供足够的缓存空间,以减少单个worker 的过载。副本数可通过不同配置参数进行控制。
3. 选择正确的缓存介质
用户可以选择内存和/或固态硬盘作为Alluxio worker的缓存介质。除非数据小到可以放入内存,并且每次查询所需的数据很小,否则宜部署更经济的固态硬盘作为缓存层,从而显著降低集群成本和总拥有成本(TCO)。
4.在 RAPIDS Spark 中进行并发配置
Spark中任务执行的并发性由每个executor的任务数控制。如果使用 Spark RAPIDS,那么将会有一个名为 spark.rapids.sql.concurrentGpuTasks的附加参数, 来进一步控制 GPU 任务并发,从而避免内存不足(OOM)异常。
将该值设置为2到4之间时,一些查询可实现显著性能提升,值设为2时通常性能提升最大,而随着值升高性能效益递减。一般来说Executor中有多个任务时对资源的使用会更优化。例如,有4个任务(包含两个concurrentGpuTask),来平衡对I/O和CPU的使用。比如一个任务可能正在与分布式文件系统通信以读取输入缓存,而另一个任务正在对GPU 上的输入缓存进行解码。在 executor 上配置过多的任务可能会导致过多的 I/O 和主机内存过载。一般来说,executor中的任务数量如果是并发concurrentGpuTasks数量的两倍时,是一个较好的起始配置。
5. 将CPU内存固定到GPU内存
设置 spark.rapids.memory.pinnedPool.size 可显著提高 GPU 和主机内存之间的数据传输性能,因为传输可以通过CPU 异步执行。在理想情况下,分配的固定内存(pinned memory)的输入分区足够容纳Spark能为executor调度的并发任务数量。
6. 限制shuffle分区的数量
分区对于 GPU 处理的增量成本高于CPU处理,因此建议在不耗尽任务内存的情况下尽可能减少分区数量。
有关Alluxio,请查阅Alluxio tuning tips document 获取更多信息。有关RAPIDS Spark,请查阅 RAPIDS Spark tuning guide获取更多信息。
NVIDIA GPU加速的集群使用Alluxio的部署选项
用户可以在任何云基础架构即服务 (IaaS) 产品(例如 Amazon EC2、Azure VM 或 Google Compute Engine)上部署装有NVIDIA GPU 和 Alluxio的Apache Spark集群。其他选项包括任何容器云平台 (CaaS) 产品,例如 Amazon EKS、Azure Kubernetes Service 或 Google Kubernetes Engine。
Apache Spark的RAPIDS加速器和Alluxio都可以与主要云数据托管服务进行集成。以下指南适用于Amazon EMR, Google Dataproc,并包含Alluxio使用说明。
下一步:
想要了解更多有关RAPIDS 如何加速 Apache Spark 的 I/O 的信息,请注册GTC 2021大会演讲——“将RAPIDS加速器用于数据编排”。
想了解如何开始使用Alluxio和RAPIDS Accelerator for Apache Spark,请查阅此文档: https://nvidia.github.io/spark-rapids/docs/get-started/getting-started-alluxio.html
想获取RAPIDS Accelerator for Apache Spark 3.0相关信息和入门指南,请查阅GitHub repo:https://github.com/nvidia/spark-rapids
有关如何在Kubernetes 中使用Alluxio加速基于GPU的深度学习I/O的更多信息,请阅读开发者博客: https://www.alluxio.io/blog/efficient-model-training-in-the-cloud-with-kubernetes-tensorflow-and-alluxio/
想要获取更多有趣有料的【活动信息】【技术文章】【大咖观点】,请关注[Alluxio智库]:
