作者:~小明学编程
文章专栏:MySQL
格言:目之所及皆为回忆,心之所想皆为过往

今天给大家分享的是增删查改中的一些比较核心的东西同时也是难点,希望能给大家带来一些帮助吧。
目录
数据库的约束
NULL约束

我们首先创建一个student的表,然后我们查看该表可以看到Null这一栏,里面是YES这意味着我们插入的数据可以是NULL,接着我们尝试去插入了一个NULL的数据,显示插入成功。

接着我们将原表删除,然后重新创建该表给我们的id属性加上约束不能为null,下面可以看到在我们想要插入null的时候给我们error报错了。

Unique的唯一约束
unique的唯一约束意味着我们当前的这一列不能插入重复的数字。

在我们给id加上约束unique之后,我们插入的数据中有相同的id就会提醒报错。
default的默认值约束
默认值约束意味着我们我们在插入一个数据的时候如果我们没有指定这个值是啥那么这个值将会是我们default后面的这个值。

primary key 主键约束
主键就像我们的身份证一样是一个唯一的标识,其意义在于不可重复,并且也不能为空,相当于not null和unique的结合体,主键标识的那一列不可能会出现两个相同的数据。

下面进行插入,我们可以看到当我们插入的id的数值一样就会报错。

对于整数类型的主键,常配搭自增长auto_increment来使用,其作用是当我们不给其赋值的时候会将最大值+1,赋给我们当前的key.

当我们给了个5,然后下一个就变成了6。

注意:

这里我们前面已经限制了not null,但是不影响我么后面的插入null,因为这里是自增主键,null就意味着我们会自动分配一个值,而不是真正意义上的插入
foreige key 外键约束
所谓的外键约束就是我们一个表中的某一列的元素必须是另外一个表中某一列元素中的数值,也就是用其他表中某一列的元素去约束我们当前表中当前列的值,这就叫做我们的外键约束,其写法如下所示:
foreign key 列 references 外表(外列);下面我们就在具体的数据库中操作去了解这种约束,首先我们创建一个class留作我们的外键约束的表。

接着创建student表,然后将其中的id的外键约束设置为class中的id,接着向student里面插入数据,


上面是我们的class表,然后下面是我们插入数据出现的问题,大哥我们插入的id是1的时候是没问题的,但是当我们插入的id为4的时候因为class中的id列里面没有4所以显示插入失败。

然后我们发现现在我们想要删除或者更改我们的class表也是做不到的,因为父表在约束子表的同时也被子表约束着,因为id=1的哪一行已经被子表利用着呢,不能随意的进行删除。

表的结构
关于表的设计有三种方式分别是:一对一,一对多,多对多,下面我们分别简单的介绍这三种方式。
一对一
例如我们的个人信息表和我们的账户这种对应形式,一般情况下我们一个人只能有一个账户,同时我们一个账户也只能对应我们一个人。这种模式叫做一对一,对于这种模式我们一般情况下会设计成一张表,或者其中的一张表直接包含另外一张表。
一对多
像我们的学生对考场,我们一个考场里面可以有很多个考生,但是一个考生只能有一个考场,这种就叫作一对多的关系,我们在设计表的时候有两种方式。
1.我们可以对考场那张表加上一列,这一列是个数组里面是该考场中的所有学生。
2.我们不动考场这张表,转而在学生那张表上加上一列,这一列中就是我们的考场信息,这样也能做到一对多。
很显然第一种我们的MySQL是实现不了的,我们MySQL中是没有数组的,所以一般采用第二种方法。
多对多
如:我们的学生与老师的关系,我们一个学生会有很多位老师来教我们,同时我们每位老师也教很多位的学生,这就是多对多的关系。
在设计表的时候我们要是想表现出这种关系的话可以用一个关联表来表示我们学生和老师的对应关系。
查询进阶
上一章的文章给大家简单的介绍了查询简单的查询语句,今天就来给大家介绍一些比较复杂的查询。
插入查询
所谓的插入查询就是将我们所查询到的数据插入到另外一个表中去。

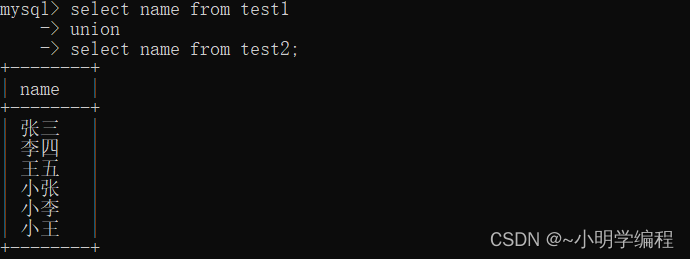
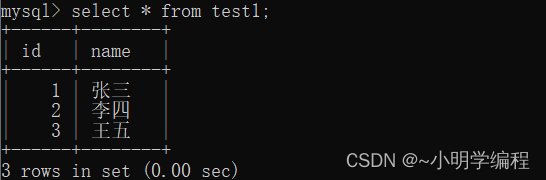
现在我们有两个表一个test1,一个test2, 我们想要做的是把test1中的数据插入到test2中

简单的总结该语句就是如下的用法:
insert into 待插入的表 (列,列) select 条件 from 原表;聚合查询
说到聚合查询的话就要先了解我们的聚合函数:
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
聚合函数的作用主要是在于让我们对不同的行进行一个运算和操作。

拿我们呢先前的一个表来举例子,count可以返回给我们所查询的数量例如

这里说明一点我们count是不会计算null值的,如果我们count的那一列有null的话那么我们将不会进行计算,计算平均值等一样也是不考虑null的。

这里求总和,并且和其它的一些语句嵌套使用。
group by 语句
grop by语句的作用在于让我们可以对指定的列进行分组,其中我们想要查询的列必须是分组依据的列,如果其它的列想要出现的话那就必须和聚合函数一起使用,下面演示使用

这是我们当前的一张表,现在我们的目的是,让我们以role进行分组。

having语句
having和where一样都是条件语句,但是与where不同的是having是后面执行的,而where是先执行的,所以一般情况下我们having和group by一起使用,但是有时候也需要和where联合起来一起去使用。
显示平均工资小于等于2000的角色和其薪资:

联合查询
内连接
select 字段 from 表1 别名1 join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;说到联合查询就得先说说我们的笛卡尔积了,像这种相当于把两个表直接相乘了一样

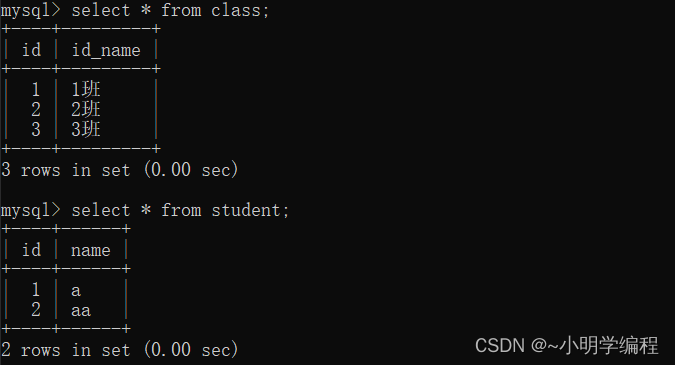
这是我们先前的两张表,现在我们对其进行多表查询。

我们看到查询的结果,其实很多的东西都没啥用,我们想要的应该是id相同的数据,所以我们就可以在其后面增加一些条件语句。

这里我们就拿到了我们想要的数据了,值得我们注意的是遇到相同的列名的时候我们要指定我们的表是谁形如上面的语句,不然的话就会报错。
下面我们就来几个比较复杂的语句:

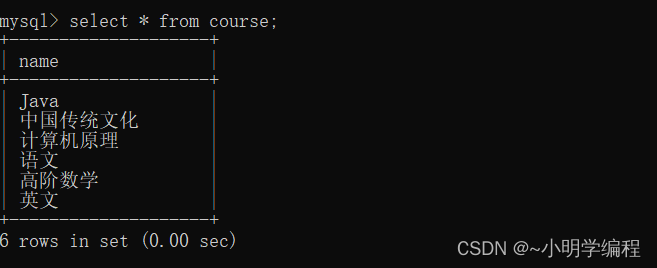

1.我们想要查询许仙同学的成绩:
select score from student, score where student.classes_id=score.student_id and
student.name = '许仙';2.查询所有同学的总成绩,及同学的个人信息:
select sn,name,qq_mail,sum(score) from student, score
where student.classes_id=score.student_id
group by student_id;外连接
说到外连接我们首先要介绍的就是join on的语句,前面我们连接两个表都是,
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;其实对于连接两个表的话我们也可以使用join on 的语句进行连接
select 字段 from 表1 别名1 inner join 表2 别名2 on 连接条件 and 其他条件;其中当我们内连接的时候inner是可以省略的,我们看下面两个表


这时候我们发现我们不能查到所有的人,因为只有id12是相同的,这个时候我们就要引进我们左连接和右连接了。
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;左连接:

我们可以看到所谓的左连接就是比较的照顾左边的那张表会将左边表的所有的id都会给显示出来即使后面的内容是null。
右连接:

右连接就是比较的照顾right右边的那张表,会显示所有右边那张表里面的id的信息。
当然想要显示两张表里面的所有信息也是可以的,只不过我们的MySQL做不到,其它的数据库有的可以做到。
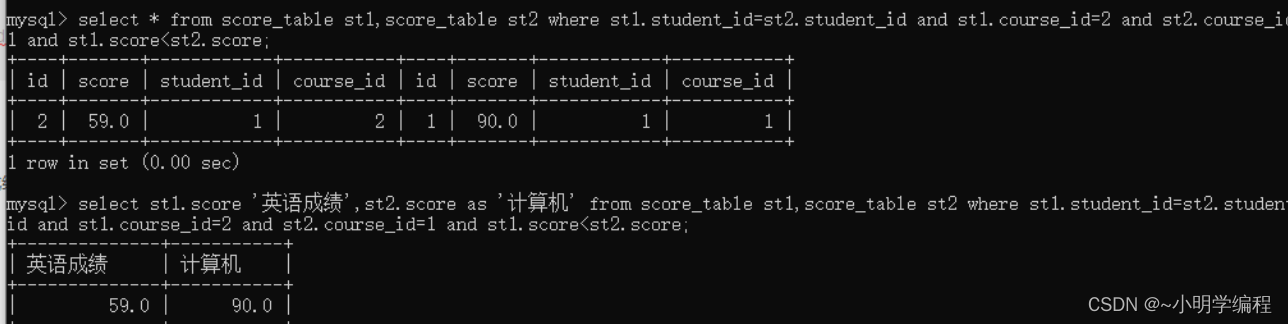
自连接
自连接是指在同一张表连接自身进行查询。
现在我们想要查询英语成绩小于计算机成绩的数据:

然后去查询id为1和2的数据我们会发现我们要的数据是行与行的比较的他们都在score那一列,所以要进行自连接,采用笛卡尔积将自己乘自己,然后筛选我们想要的数据。

子查询(嵌套查询)
所谓的子查询就是在我们的查询中再次的嵌套一个查询:
select * from score where course_id in (select id from course where
name='语文' or name='英文');写法如上所示,这种写法不是很推荐,比较的繁琐。
合并查询
合并查询就是将两条的查询语句合并为一条,
对于这张表我们现在想要查询student_id=1或者course_id=1 怎么查。

下面我们用联合查询来写

select * from score where student_id=1
union -- 将会去掉重复的行
select * from score where course_id=1;
select * from score where student_id=1
union all -- 不会去掉重复的行
select * from score where course_id=1;一般联合查询都是多个表的查询然后将查询结果拼接到一起