视频理解算法有很多的应用场景,包括视频推荐、监控分析、人机交互等等。在这些真实的应用场景中,通常对算法的实时性有很高的要求。现有的行为识别方法还未能在分类的准确性和运行速度都达到比较好的效果(双流类的方法效果较好,但光流等步骤使得速度很受限;3D 网络类的方法目前的精度和速度也都还不够理想)。所以在保证分类效果的前提下,提高网络的运行速度是当前一个很重要的研究课题。
针对这个问题,这篇论文笔记主要介绍近期放到arXiv上(应该是ECCV-2018的投稿文章),来自弗莱堡大学Thomas Brox教授实验室的一篇文章” ECO: Efficient Convolutional Network for Online Video Understanding ” [1],算法的代码预期开源在mzolfaghari/ECO-efficient-video-understanding 。ECO网络仅采用RGB图像输入,其基本思路为:对视频均匀采样得到N帧图像,对这些图像使用共享的2D CNN网络获得一个2D feature map,再堆叠这些feature map,用一个3D CNN网络得到最后的分类结果。在获得了相近的性能的前提下,ECO网络比SOTA方法要快10-80倍。需要注意的是,虽然这篇文章的标题是online video understanding,但其主要还是在设计一个足够快且好的action recognition方法(足够快且好所以就可以用于online场景啦)。下面开始介绍文章内容,如有不足烦请指正。
Motivation
这篇文章在introduction部分主要提出了两点motivation:
- 使用单帧的图像,在很多情况下已经可以获得一个不错的初始分类结果了,而相邻帧间的很多信息都是冗余的。因此,ECO中在一个时序邻域内仅使用单帧图像。
- 为了获得长时程的图像帧间的上下文关系,仅仅使用简单的分数融合(aggregation) 是不足够的。因此,ECO中对较远帧之间采取对feature map 进行3D 卷积的方式进行end-2-end的融合。
相关工作
可以看出,ECO的motivation还是非常简单直接的,在此基础上设计出来网络也不复杂。那么ECO和之前的行为识别方法有什么区别呢,作者在相关工作一节进行了讨论。
- 大部分2stream类方法和所有3D卷积类型方法 都是在学习短时程的时序信息,即输入一个连续的video clip,输出一个分类结果。在video-level上,通常是对video中选取多个clip分别得到分类结果,再进行平均得到最后的分类结果,这样会带来较大的计算开销。
- 一些方法(比如去年deepmind的i3d [2] ) 选择增大输入clip的时序长度来获得更长时程的信息,但这样一方面会带来计算开销的提高,另外一方面则还是不能处理较长的视频。
- 一些方法[3][4]采用编码方法来获得video-level的表示,但作者表示这样忽略了帧间的信息。
与ECO最相似的是目前被广泛使用的TSN [5]网络:
- ECO和TSN的相似点:两者都是从video中均匀采样固定数量的视频帧,从而来覆盖长时程的时序结构。两者都是end-to-end训练的。
- ECO和TSN的不同点:TSN中直接用late-fusion的方式对每个segment的结果做融合,而ECO中则是进行了feature map层面的融合(文中除了3D卷积,也采用了2D卷积)。此外ECO的速度要远快于TSN。
模型结构
网络结构
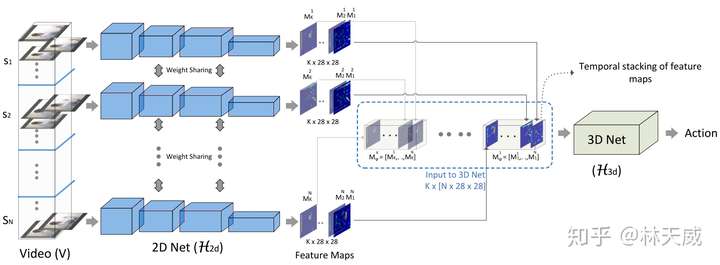
ECO网络的基本结构如上图所示,S1-SN是从视频中采样得到的N个RGB的segment。
- 对于每个segment,采用共享的2D卷积子网络 (文中的符号不知道咋打出来…)来得到96个28*28大小的feature map,堆叠后得到一个N*28*28*96 大小的特征volume。此处 使用的是BN-Inception网络中的第一部分(到inception-3c层前)。
- 对于得到的特征volume,采用一个3D子网络 进行处理,直接输出对应动作类别数目的一维向量。此处 采用了3D-Resnet18 [6]中的部分层。
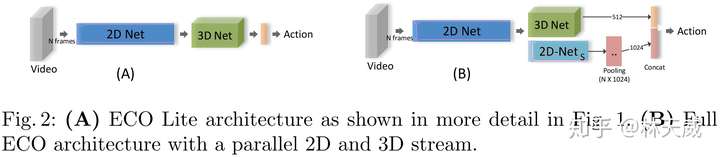
如上的两部分,就构建了这篇文章中构建的第一种网络结果ECO-Lite。除了用3D卷积进行融合,还可以同时使用2D卷积,如下图所示,即为ECO-Full网络结构。此处多的一个2D网络分支 采用的是BN-Inception网络中inception-4a到最后一个pooling层间的部分,最后再采用average-pooling得到video-level的表示,与3D net的结果concat后再得到最后的action分类结果。
采样策略
介绍完网络结构后,再回过头来介绍一下视频帧的采样方法。在ECO中,作者先将一个视频等分为N份,再在每份中随机选取一帧作为输入。作者认为这样的随机采样策略可以在训练中引入更多的多样性,并提高泛化能力。
测试
在TSN或是ARTNet等方法中,测试时通常都会对每段视频进行多次的cropping采样以及水平翻转等数据增强,从而增强测试的效果。这使得计算的效率较低,从而难以用于实时场景。
与之相反,ECO中对于一个视频,只需要计算一次前向就可以获得很好的效果,而不需要进行任何额外的融合或是增强,在效率上面有更好的保证。
在线视频理解
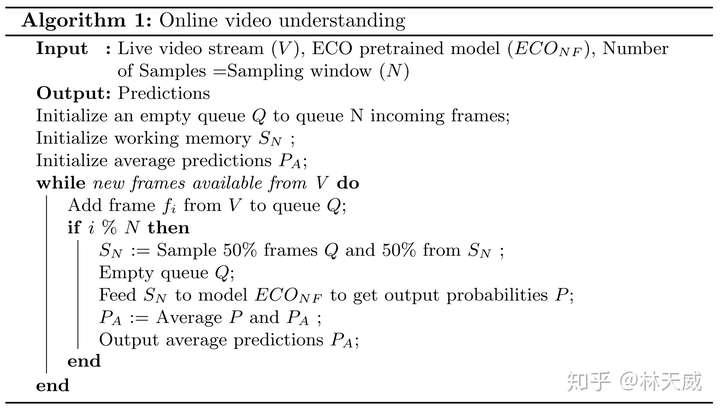
在介绍完网络结构后,作者介绍了在线视频理解这一问题以及将ECO应用在这个问题上的方法。在一般情况(offline)下,我们是获得了一整段视频后再做分析处理的。而在online情况下,视频是以视频流的形式呈现的,即我们只能获得当前时刻过去的视频。对于这个场景,一般的做法是将当前时刻之前的N帧作为一个窗口,输入网络来判断结果。作者认为这样主要有两个缺陷:一是这样会造成长程语义的缺失,二则是可能造成较长的delay。
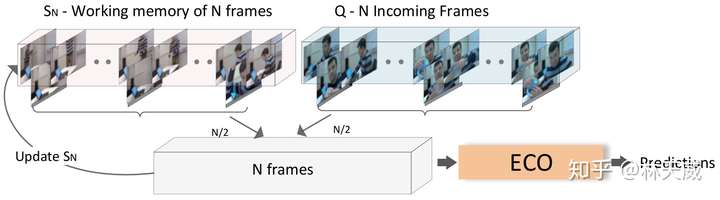
因此,作者基于ECO提出了以下的online处理框架。这个框架中主要维护了两个图像组,分别是存放较旧图像的工作记忆组和存放新的未处理图像的新收图像组。每次预测时,从两组视频中各采样一半来更新工作记忆组,并将其作为网络的输入得到当前的预测结果,将当前的预测结果和平均预测结果进行平均后得到最终的输出。这个框架在工作记忆组和平均输出两个层面保存了较长时程的信息,但同时依旧是以当前的图像为主。可以说是设计的很精巧的一个框架了。
下图则可视化的展现了这个过程。
实验内容
ECO在实验中的表现也非常出色,下面选取一些实验内容进行介绍。
基准数据集比较
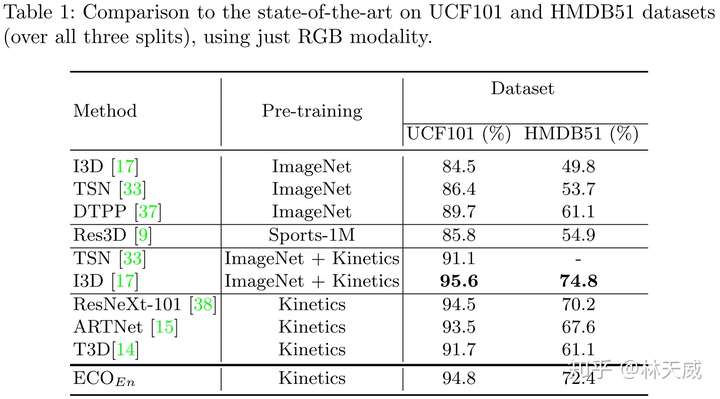
首先是在行为分类的两个常用数据集上进行比较,此处限定了只使用RGB图像。可以看出ECO在用Kinetics预训练的前提下,获得了最好的效果。此外在Kinetics和Something-Something数据集上,ECO也获得了很好的效果。
速度-精度比较
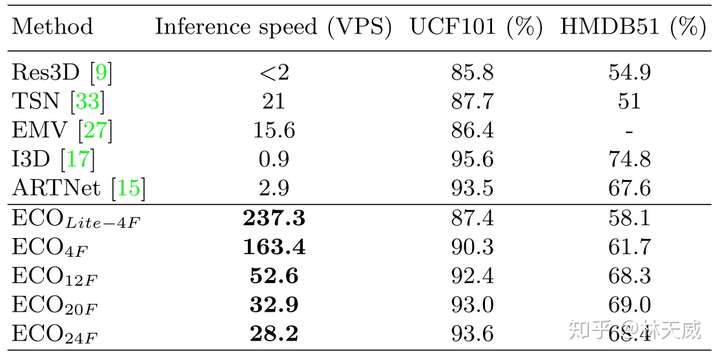
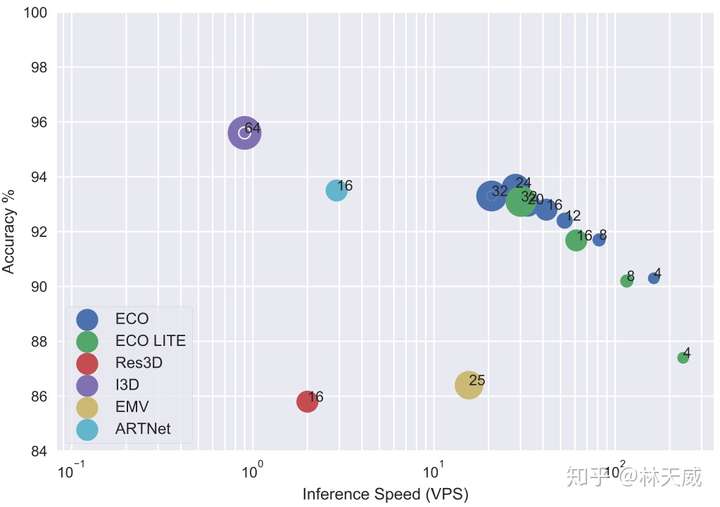
ECO的一个主要卖点就是速度快,上表就展示了ECO和其他方法的速度/精度性能比较(基于单卡Tesla P100)。ECO的右下标表示的是ECO的输入帧数N。可以看出,在获得相近精度的前提下,ECO的速度要远远快于现有方法。需要注意的是,此处作者使用的是VPS,即每秒处理的视频数量。很多方法为了获得video-level的结果,对于每个视频需要进行多次inference,而ECO只需要进行一次。下图则可视化地展示了速度-精度的效果,ECO的优势还是很大的。
在线视频理解
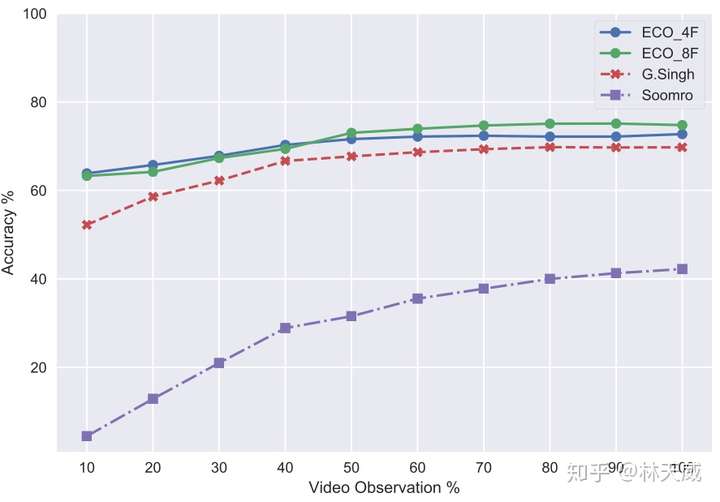
在线视频分类问题通常以early action recognition 的形式来评估。如上图所示,横轴显示的是可以看到的视频的前百分之几,纵轴则是对应的精度。基于上图的在J-HMDB数据集上的实验,可以看出ECO在精度上有明显的优势,并且只需要很小一部分视频就可以达到不错的精度。
视频描述生成
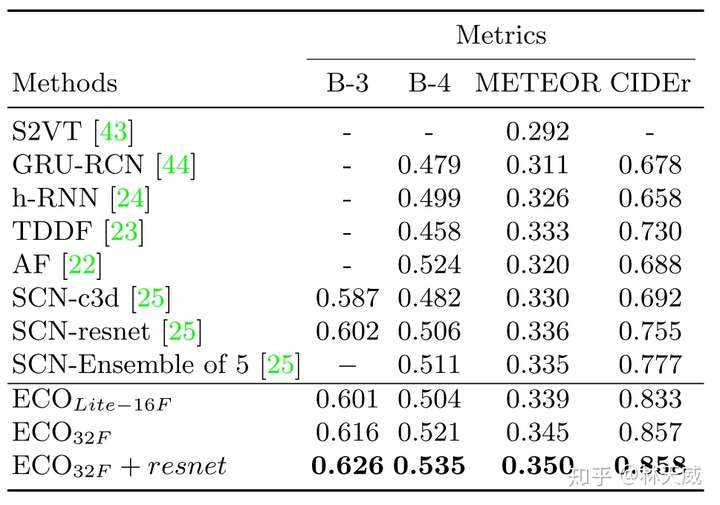
为了展现ECO可以被广泛应用于视频理解领域,作者还用ECO提取的特征在video captioning任务上做了实验(在MSVD数据集上)。将SOTA方法(即表中的SCN)的特征换为ECO,立马获得了非常显著的效果提升,这也表明了ECO的有效性。
论文小结
下面写一些自己的看法。写了这么多,其实ECO的核心点其实就是两块:一是与TSN方法类似的视频帧采样方法,二是用3D卷积来做融合,这点实际上在几年前的一篇two-stream 网络文章[7]中就采用过(不过[7]中是用于video clip内的融合)。所以这篇工作可以说是 直观的motivation + 简单有效的框架设计 相结合的一篇精彩的工作。优秀的效果同时也离不开没有写出来的大量网络设计方面的工作(从网络结构看,参数量和计算量应该都比较小,不是很深的网络)。文章的写作和绘图等方面也蛮值得自己学习。
ECO在速度/精度上的良好性能(并且只需要RGB图像)应该会使得它之后获得广泛的应用,就像之前的TSN和C3D一样。期待作者能尽快开源了。
本文投稿于AI科技评论公众号, 未经许可请勿转载。
参考文献
[1] Zolfaghari M, Singh K, Brox T. ECO: Efficient Convolutional Network for Online Video Understanding[J]. arXiv preprint arXiv:1804.09066, 2018.
[2] Carreira J, Zisserman A. Quo vadis, action recognition? a new model and the kinetics dataset[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017: 4724-4733.
[3] Xu Z, Yang Y, Hauptmann A G. A discriminative CNN video representation for event detection[C]//Computer Vision and Pattern Recognition (CVPR), 2015 IEEE Conference on. IEEE, 2015: 1798-1807.
[4] Qiu Z, Yao T, Mei T. Deep quantization: Encoding convolutional activations with deep generative model[C]//CVPR. 2017, 1(3): 4.
[5] Wang L, Xiong Y, Wang Z, et al. Temporal Segment Networks for Action Recognition in Videos[J]. arXiv preprint arXiv:1705.02953, 2017.
[6] Tran D, Ray J, Shou Z, et al. Convnet architecture search for spatiotemporal feature learning[J]. arXiv preprint arXiv:1708.05038, 2017.
[7] Feichtenhofer C, Pinz A, Zisserman A P. Convolutional two-stream network fusion for video action recognition[J]. 2016.