目录
集合类图
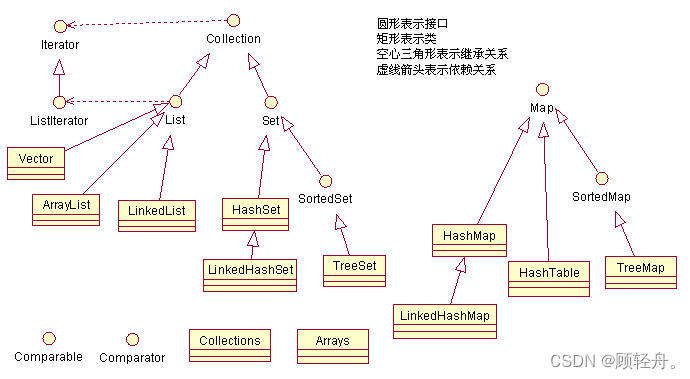
在UML类图中,常见的几种关系:
泛化:是一种继承关系,表示一般与特殊关系,指定了子类如何特化父类的所有特征行为。例如:老虎是动物的一种,即老虎的特性也有动物的共性
实现:类与接口的关系,表示接口所有特征和行为的实现。
关联:是一种拥有的关系,它使一个类知道另一个类的属性和方法,关联分为双向和单向。例如:老师与学生是双向关联,老师有多名学生,学生也可能有多名老师。但学生与某课程间的关系为单向关联,一名学生可能要上多门课程,课程是个抽象的东西他不拥有学生。
聚合:整体与部分的关系,且部分可以离开整体单独存在。例如:车和轮胎是整体和部分的关系,轮胎离开车仍然可以存在
组合:是整体与部分的关系.,没有公司就不存在部门。组合关系是关联关系的一种,是比聚合关系还要强的关系,它要求普通的聚合关系中代表整体的对象负责代表部分的对象的生命周期
依赖:是一种使用的关系,即一个类的实现需要另一个类的协助,所以要尽量不使用双向的互相依赖。
关系的强弱顺序:泛化= 实现> 组合> 聚合> 关联> 依赖
List集合
list集合特点:元素有序,且可重复
遍历方法:下标,foreach,迭代器
list集合实现方法:ArrayList、LinkedList、Vector、CopyOnWriteArrayList
使用junit测试,代码更简单
基本的遍历循环方法
@Test
public void listAdd() {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(3);
list.add(5);
list.add(4);
System.out.println(list);
}
private List<Integer> list = new ArrayList<>();
@Before
public void setup() {
list.add(1);
list.add(3);
list.add(5);
list.add(4);
}
// 第一种遍历方法
@Test
public void list1() {
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
//第二种遍历方法
@Test
public void list2() {
for (Integer integer : list) {
System.out.println(integer);
}
}//迭代器
@Test
public void list3() {
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
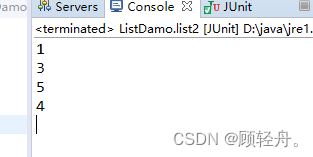
}
ArrayList是最常用的集合
特点:1、简单数据结构,超出容量自动扩容,动态数组
2、内部实现是基于基础的对象数组的
3、随机访问快
缺点:1、不适合随机增加或删除
2、线程不安全
ListedList
特点:1、LinkedList提供额外的get,remove,insert方法在LinkedList的首部或尾部
2、LinkedList可被用作堆栈(stack)【包括了push,pop方法】,队列(queue)或双向队列(deque)
3、以双向链表实现,链表无容量限制,允许元素为null,线程不安全
4、适合做随机的增加或删除Vector
Vector内部实现类似于ArrayList。它支持线程同步,某时刻只能有一个线程能够写Vector。但花费很高,所以访问Vector比访问ArrayList慢。(线程安全,并行性能慢)
CopyOnWriteArrayList
特点:1、写时复制
2、线程安全
3、 适合于读多,写少的场景
4、写时复制出一个新的数组,完成插入、修改或者移除操作后将新数组赋值给array
5、比Vector性能高
6、最终一致性
7、实现了List接口,使用方式与ArrayList类似
ArrayList删除方法
package com.zking.list;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.junit.Before;
import org.junit.Test;
public class ListDamo2 {
private List<Integer> list;
@Before
public void setup() {
list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list.add(4);
}
// 下标循环删除方式1
@Test
public void remove1() {
for (int i = 0; i < list.size(); i++) {
if (list.get(i) == 3)
list.remove(i);
}
System.out.println(list);
}
// 下标循环删除方式2
@Test
public void remove2() {
for (int i = 0; i < list.size(); i++) {
if (list.get(i) == 3)
list.remove(i--);
}
System.out.println(list);
}
// 下标循环倒序删除
@Test
public void remove3() {
for (int i = list.size() - 1; i >= 0; i--) {
if (list.get(i) == 3)
list.remove(i);
}
System.out.println(list);
}
// foreach循环删除
@Test
public void remove4() {
for (Integer integer : list) {
if (integer == 3)
list.remove(integer);
}
System.out.println(list);
}
// 第五种删除方法
@Test
public void remove5() {
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
if (it.next() == 3) {
it.remove();
}
}
System.out.println(list);
}
// 第六种删除方法
@Test
public void remove6() {
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
Integer value = it.next();
if (value == 3) {
list.remove(value);
}
}
System.out.println(list);
}
// 删除的参数是基本型的函数
@Test
public void remove7() {
list.remove(2);
System.out.println(list);
}
}
Set集合
set集合特点:元素无序,且不重复
遍历方法:foreach,迭代器
Set集合实现方法:Hashset、TreeSet
它存储唯一元素并允许空值(依据对象的hashcode来确定该元素是否存在)
依据对象的hashcode来确定该元素是否存在
由HashMap支持
不保持插入顺序
非线程安全
思考问题?
1.如何对list容器中的元素去重?
2.如何给ArrayList集合去重
先将重复的list丢到HashSet,借助HashSet把重复的数据去除,然后通过HashSet找一个新的ArrayList.
public class SetDamo { private List<Integer> list = new ArrayList<>(); @Before public void setup() { list.add(1); list.add(1); list.add(2); list.add(2); list.add(3); list.add(3); } @Test public void set1() { List<Integer> list2 = new ArrayList<>(new HashSet<Integer>(list)); System.out.println(list2); }运行结果如下:
3. set有ArrayList中存在的通过下标删除,或foreach循环删除时的问题吗? 为什么
set是无序集合,无下标,没有办法通过下标获取,只能通过foreach循环或迭代器
4. set是否存在List删除,传入整数需要区分是基本型还是对象型的问题,为什么?举例:list.remove(Integer.valueof(2)); 是对象型,
list.remove(2); 是基本型
两者结果不同
但是,set集合无下标,直接通过对象删除的
5. HashSet是如何实现的?通过map实现 因为map是键值对,键不能重复,值能重复,数值保存在键里面。运行时只用了键没有用值
编写student类
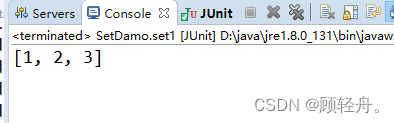
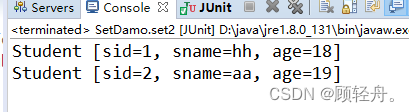
package com.zking.set; public class Student { private Integer sid; private String sname; private Integer age; public Student(Integer sid, String sname, Integer age) { super(); this.sid = sid; this.sname = sname; this.age = age; } public Integer getSid() { return sid; } public void setSid(Integer sid) { this.sid = sid; } public String getSname() { return sname; } public void setSname(String sname) { this.sname = sname; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + ((age == null) ? 0 : age.hashCode()); result = prime * result + ((sid == null) ? 0 : sid.hashCode()); result = prime * result + ((sname == null) ? 0 : sname.hashCode()); return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Student other = (Student) obj; if (age == null) { if (other.age != null) return false; } else if (!age.equals(other.age)) return false; if (sid == null) { if (other.sid != null) return false; } else if (!sid.equals(other.sid)) return false; if (sname == null) { if (other.sname != null) return false; } else if (!sname.equals(other.sname)) return false; return true; } @Override public String toString() { return "Student [sid=" + sid + ", sname=" + sname + ", age=" + age + "]"; } }public class SetDamo { @Test public void set2() { Set<Student> stu = new HashSet<>(); stu.add(new Student(1, "hh", 18)); stu.add(new Student(1, "hh", 18)); stu.add(new Student(2, "aa", 19)); stu.add(new Student(2, "aa", 19)); for (Student student : stu) { System.out.println(student); } } }运行结果如下:
TreeSet集合特点:元素有序,且没有重复
作用:提供有序的Set集合,自然排序或者根据提供的Comparator进行排序
TreeSet是基于TreeMap实现的
- HashSet集合是无序的,有时需要一个有序的集合,这时可以使用TreeSet.
- 在使用TreeSet存储对象的时候, add()方法内部就会自动调用compareTo()方法进行比较,
- 根据比较结果使用二叉树形式进行存储。(TreeSet内部是直接使用TreeMap进行实现的)
自然排序:
//如果保存的是数值型,则按数值排序 @Test public void set4() { TreeSet<Integer> set=new TreeSet<>(); set.add(4); set.add(2); set.add(3); set.add(1); System.out.println(set); } //如果保存的是字符,则按字符对应的ASCII进行排序 @Test public void demo2() { TreeSet<String> ts = new TreeSet<>(); ts.add("a"); ts.add("d"); ts.add("b"); ts.add("c"); System.out.println(ts); }比较器(Comparator)排序
TreeSet通过构造函数传入比较器
@Test public void set4() { TreeSet<Integer> set = new TreeSet<>(new Comparator<Integer>() { // 比较方法 @Override public int compare(Integer o1, Integer o2) { return o2 - o1; } }); set.add(4); set.add(2); set.add(3); set.add(1); System.out.println(set); }运行结果:
实现排序接口
@Test public void set6() { TreeSet<Student> set = new TreeSet<>(new Comparator<Student>() { // 比较方法 @Override public int compare(Student o1, Student o2) { return o2.getAge() - o1.getAge(); } }); set.add(new Student(1, "aa", 18)); set.add(new Student(2, "bb", 19)); set.add(new Student(3, "cc", 20)); set.add(new Student(4, "dd", 21)); for (Student student : set) { System.out.println(student); } }编写Student类实现接口
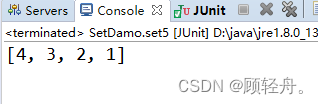
package com.zking.set; public class Student implements Comparable<Student>{ private Integer sid; private String sname; private Integer age; public Student(Integer sid, String sname, Integer age) { super(); this.sid = sid; this.sname = sname; this.age = age; } public Integer getSid() { return sid; } public void setSid(Integer sid) { this.sid = sid; } public String getSname() { return sname; } public void setSname(String sname) { this.sname = sname; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + ((age == null) ? 0 : age.hashCode()); result = prime * result + ((sid == null) ? 0 : sid.hashCode()); result = prime * result + ((sname == null) ? 0 : sname.hashCode()); return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Student other = (Student) obj; if (age == null) { if (other.age != null) return false; } else if (!age.equals(other.age)) return false; if (sid == null) { if (other.sid != null) return false; } else if (!sid.equals(other.sid)) return false; if (sname == null) { if (other.sname != null) return false; } else if (!sname.equals(other.sname)) return false; return true; } @Override public String toString() { return "Student [sid=" + sid + ", sname=" + sname + ", age=" + age + "]"; } @Override public int compareTo(Student o) { if (this.getAge()==o.getAge()) { return o.getSid()-this.getSid(); } return o.getAge()-this.getAge(); } }@Test public void set6() { TreeSet<Student> set = new TreeSet<>(); set.add(new Student(1, "aa", 18)); set.add(new Student(5, "ee", 18)); set.add(new Student(2, "bb", 19)); set.add(new Student(3, "cc", 20)); set.add(new Student(4, "dd", 21)); for (Student student : set) { System.out.println(student); } }运行结果:
Map集合
map集合特点:无序,是键值对,键不能重复,值可以重复;键重复则覆盖,没有继承Collection接口
遍历方法:先获取所有键的Set集合,再遍历(通过键获取值);取出保存所有Entry的Set,再遍历Set
map集合实现方法:HashMap、HashTable、ConcurrentHashMap、TreeMap、LinkedHashMap
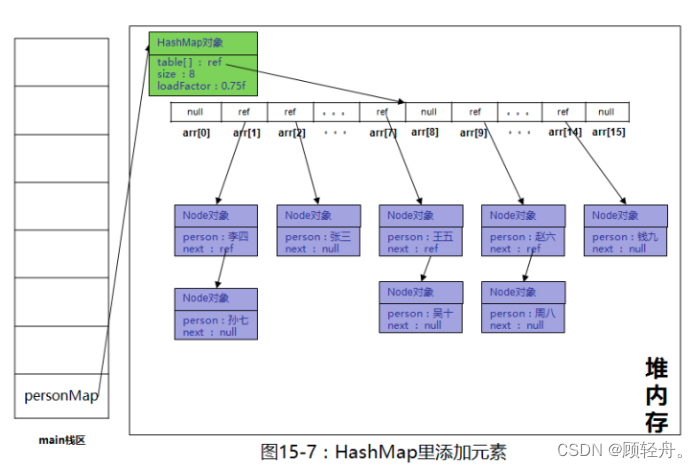
HashMap集合特点:线程不安全,最常用,速度快;内部采用数组来存放数据
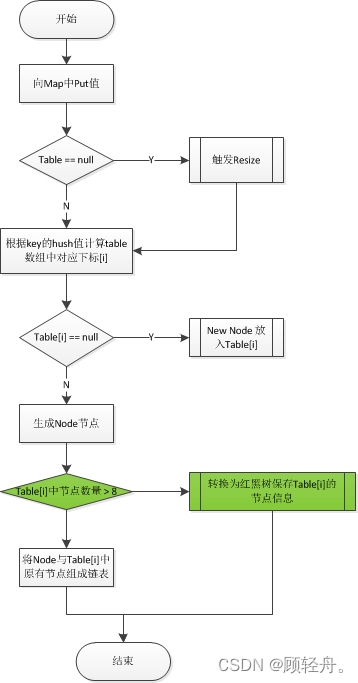
基本原理:put执行过程
Table数组中的Node
链表结构示意图
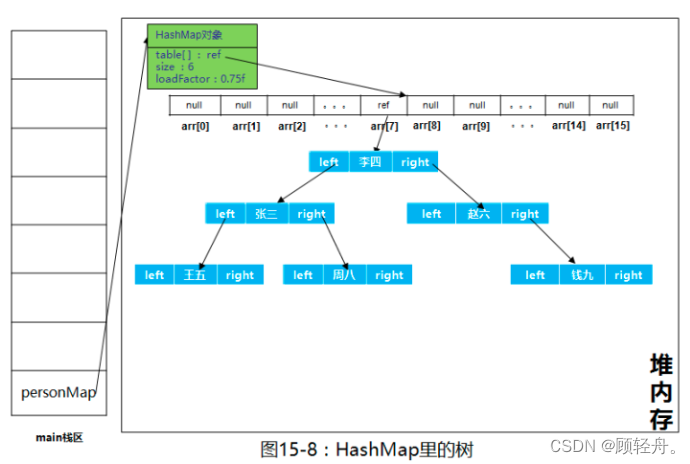
红黑树结构示意图
流程图中绿色标出的部分为JDK8新增的处理逻辑,目的是在Table[i]中的Node节点数量大于8时,通过红黑树提升查找速度。
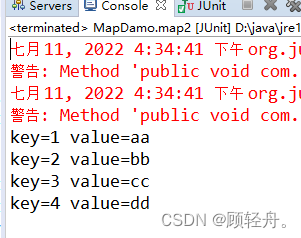
public class MapDamo { private Map<String, Object> map = new HashMap<>(); @Before public void setup() { map.put("1", "aa"); map.put("1", "aa"); map.put("2", "bb"); map.put("3", "cc"); map.put("4", "dd"); } @Test public void map1() { Iterator<String> it = map.keySet().iterator(); while (it.hasNext()) { String key = it.next();// 获取键 String object = (String) map.get(key);// 获取值 System.out.println(object); } } @Test public void map2() { Iterator<Entry<String, Object>> it = map.entrySet().iterator(); // 遍历所有集合 while (it.hasNext()) { Entry<String, Object> entry = it.next(); System.out.println("key=" + entry.getKey() + " value=" + entry.getValue()); } }
- map1 循环时 键值相同,后面覆盖前面
- map2 entry可以理解成一个实体,在实体对象中包括两个值(key,value)
HashTable:线程安全,不太常用
@Test public void map3() { Map<String, Object> table = new HashMap<>(); table.put("1", "aa"); table.put("1", "bb"); table.put("2", "cc"); table.put("3", "dd"); Iterator<String> it = table.keySet().iterator(); while (it.hasNext()) { String key = it.next(); System.out.println(table.get(key)); } System.out.println("------------"); Iterator<Entry<String, Object>> it1 = table.entrySet().iterator(); while (it1.hasNext()) { Entry<String, Object> entry = it1.next(); System.out.println("key=" + entry.getKey() + " value=" + entry.getValue()); } }运行结果:
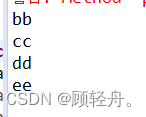
ConcurrentHashMap:线程安全,比HashTable性能高
@Test public void map4() { Map<String, Object> map = new ConcurrentHashMap<>(); map.put("1", "aa"); map.put("1", "bb"); map.put("2", "cc"); map.put("3", "dd"); map.put("4", "ee"); Iterator<String> it = map.keySet().iterator(); while (it.hasNext()) { String key = it.next();// 获取键 String object = (String) map.get(key);// 获取值 System.out.println(object); } }运行结果 :
TreeMap:key值按一定的顺序排序;添加或获取元素时性能较HashMap慢;因为需求维护内部的红黑树,用于保证key值的顺序@Test public void map5() { TreeMap<Integer, String> treeMap = new TreeMap<>(new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o1-o2; } }); treeMap.put(1, "zs"); treeMap.put(2, "ls"); treeMap.put(3, "ww"); Iterator<Integer> it = treeMap.keySet().iterator(); while (it.hasNext()) { Integer key = it.next();// 获取键 String object = (String) treeMap.get(key);// 获取值 System.out.println(object); } }运行结果:
LinkedHashMap特点:继承HasMap集合;有序且默认为插入顺序;当我们希望有顺序地去存储key-value时就需要用LinkedHashMap了
@Test public void map6() { Map<String, String> linkedHashMap = new LinkedHashMap<>(); linkedHashMap.put("1", "张三"); linkedHashMap.put("2", "李四"); linkedHashMap.put("3", "王五"); Set<Entry<String, String>> set = linkedHashMap.entrySet(); Iterator<Entry<String, String>> iterator = set.iterator(); while (iterator.hasNext()) { Entry entry = iterator.next(); String key = (String) entry.getKey(); String value = (String) entry.getValue(); System.out.println("key:" + key + ",value:" + value); } }运行结果: