版面分析
版面分析指的是对图片形式的文档进行区域划分,定位其中的关键区域,如文字、标题、表格、图片等。

在上图中,最上面有图片区域,中间是标题和表格区域,下面是文字区域。
命令行使用
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure --table=false --ocr=false
Python代码使用
import os import cv2 from paddleocr import PPStructure,save_structure_res if __name__ == '__main__': table_engine = PPStructure(table=False, ocr=False, show_log=True) save_folder = './output' img_path = 'ppstructure/docs/table/1.png' img = cv2.imread(img_path) result = table_engine(img) save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0]) for line in result: img = line.pop('img') print(line) while True: cv2.imshow('img', img) key = cv2.waitKey() if key & 0xFF == ord('q'): break cv2.destroyAllWindows()
运行结果
{'type': 'text', 'bbox': [11, 729, 407, 847], 'res': '', 'img_idx': 0}
{'type': 'text', 'bbox': [442, 754, 837, 847], 'res': '', 'img_idx': 0}
{'type': 'title', 'bbox': [443, 705, 559, 719], 'res': '', 'img_idx': 0}
{'type': 'figure', 'bbox': [10, 1, 841, 294], 'res': '', 'img_idx': 0}
{'type': 'figure_caption', 'bbox': [70, 317, 707, 357], 'res': '', 'img_idx': 0}
{'type': 'figure_caption', 'bbox': [160, 317, 797, 335], 'res': '', 'img_idx': 0}
{'type': 'table', 'bbox': [453, 359, 822, 664], 'res': '', 'img_idx': 0}
{'type': 'table', 'bbox': [12, 360, 410, 716], 'res': '', 'img_idx': 0}
{'type': 'table_caption', 'bbox': [494, 343, 785, 356], 'res': '', 'img_idx': 0}
{'type': 'table_caption', 'bbox': [69, 318, 706, 357], 'res': '', 'img_idx': 0}
 'text', 'bbox': [11, 729, 407, 847]
'text', 'bbox': [11, 729, 407, 847]
 'text', 'bbox': [442, 754, 837, 847]
'text', 'bbox': [442, 754, 837, 847]
 'title', 'bbox': [443, 705, 559, 719]
'title', 'bbox': [443, 705, 559, 719]
 'figure', 'bbox': [10, 1, 841, 294]
'figure', 'bbox': [10, 1, 841, 294]
 'figure_caption', 'bbox': [70, 317, 707, 357]
'figure_caption', 'bbox': [70, 317, 707, 357]

 'figure_caption', 'bbox': [160, 317, 797, 335]
'figure_caption', 'bbox': [160, 317, 797, 335]
 'table', 'bbox': [453, 359, 822, 664]
'table', 'bbox': [453, 359, 822, 664]
 'table', 'bbox': [12, 360, 410, 716]
'table', 'bbox': [12, 360, 410, 716]
 'table_caption', 'bbox': [494, 343, 785, 356]
'table_caption', 'bbox': [494, 343, 785, 356]
 'table_caption', 'bbox': [69, 318, 706, 357]
'table_caption', 'bbox': [69, 318, 706, 357]
从运行的结果来看,它是将原始图像拆成了图像、图像标题、表格、表格标题、文字和文字标题六个分类。
模型训练
下载PaddleDection框架代码
PaddleDetection: PaddleDetection的目的是为工业界和学术界提供丰富、易用的目标检测模型 (gitee.com)
下载,解压,进入PaddleDection主目录,安装需要的Python库
pip install -r .\requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
cocotools安装错误的话可以使用如下命令安装
git clone https://github.com/pdollar/coco.git
cd coco/PythonAPI
python setup.py build_ext --inplace
python setup.py build_ext install
数据集:这是一个英文数据集,包含5个类{0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}
wget https://dax-cdn.cdn.appdomain.cloud/dax-publaynet/1.0.0/publaynet.tar.gz
tar -xzvf publaynet.tar.gz
这是一个COCO数据集,随便打开一张图像大概是这个样子的
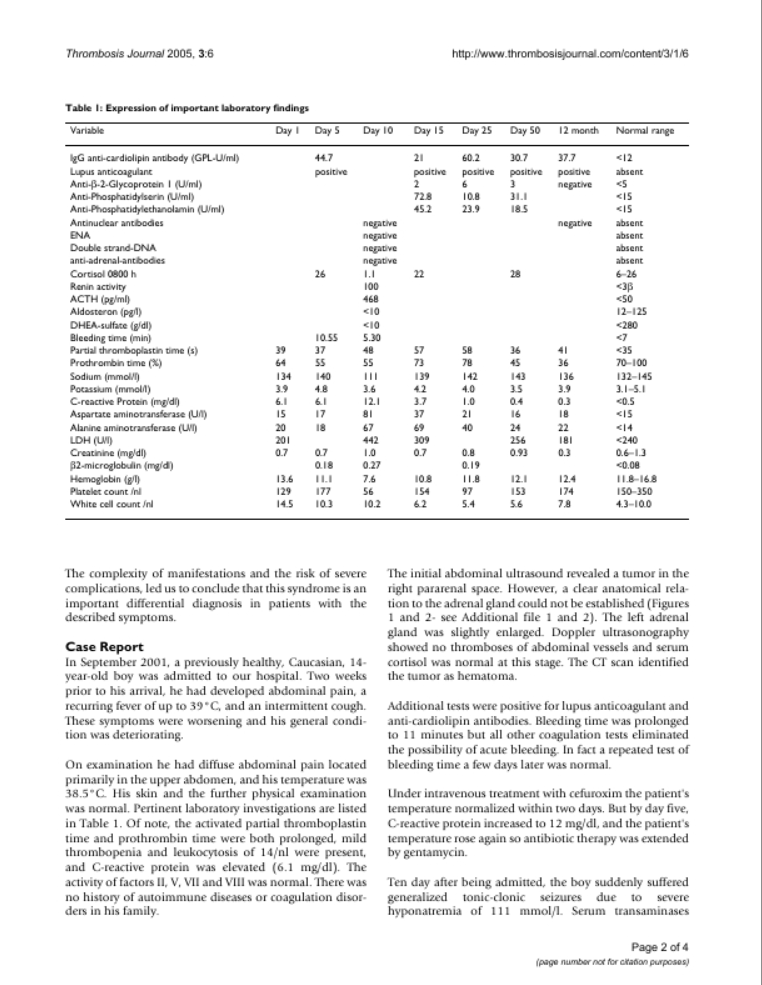
它的标签文件是json文件,里面的内容如下
{"file_name": "PMC1087888_00001.jpg", "width": 612, "id": 410520, "height": 792}
{"segmentation": [[55.14, 456.69, 296.1, 456.69, 296.1, 467.82, 296.1, 467.82, 296.1, 480.15, 296.1, 480.15, 296.1, 491.28, 144.06, 491.28, 144.06, 503.04, 55.14, 503.04, 55.14, 491.92, 55.14, 480.15, 55.14, 468.46, 55.14, 456.69]],
"area": 9380.344594193506,
"iscrowd": 0,
"image_id": 410520,
"bbox": [55.14, 456.69, 240.96, 46.35],
"category_id": 1,
"id": 4010177}
第一行表示标注文件中图像信息列表,每个元素是一张图像的信息。第二行到最后一个行表示标注文件中目标物体的标注信息列表,每个元素是一个目标物体的标注信息。这里只是其中一个区域的标注,其他还有几个区域标注,这里没有列出。
{
'segmentation': # 物体的分割标注
'area': # 物体的区域面积
'iscrowd': # 是否多区域
'image_id': # image id
'bbox': # bbox [x1,y1,w,h]
'category_id': # 图片类别
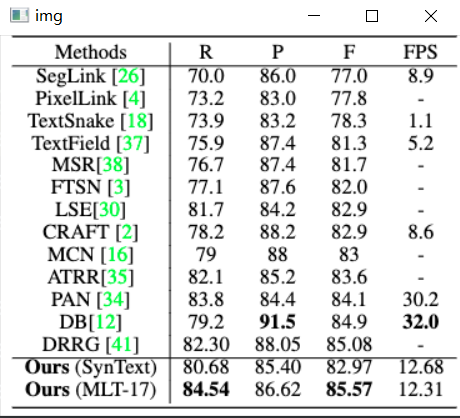
'id': # 区域 id
}
这里我们可以看到category_id为1,表示这个区域是一个Title。
修改配置文件configs/picodet/legacy_model/application/layout_analysis/picodet_lcnet_x1_0_layout.yml ,内容如下
PP-PicoDet模型原理
PP-PicoDet是一个目标检测模型,对比于YOLO系列在轻量级检测中(移动端)表现更好
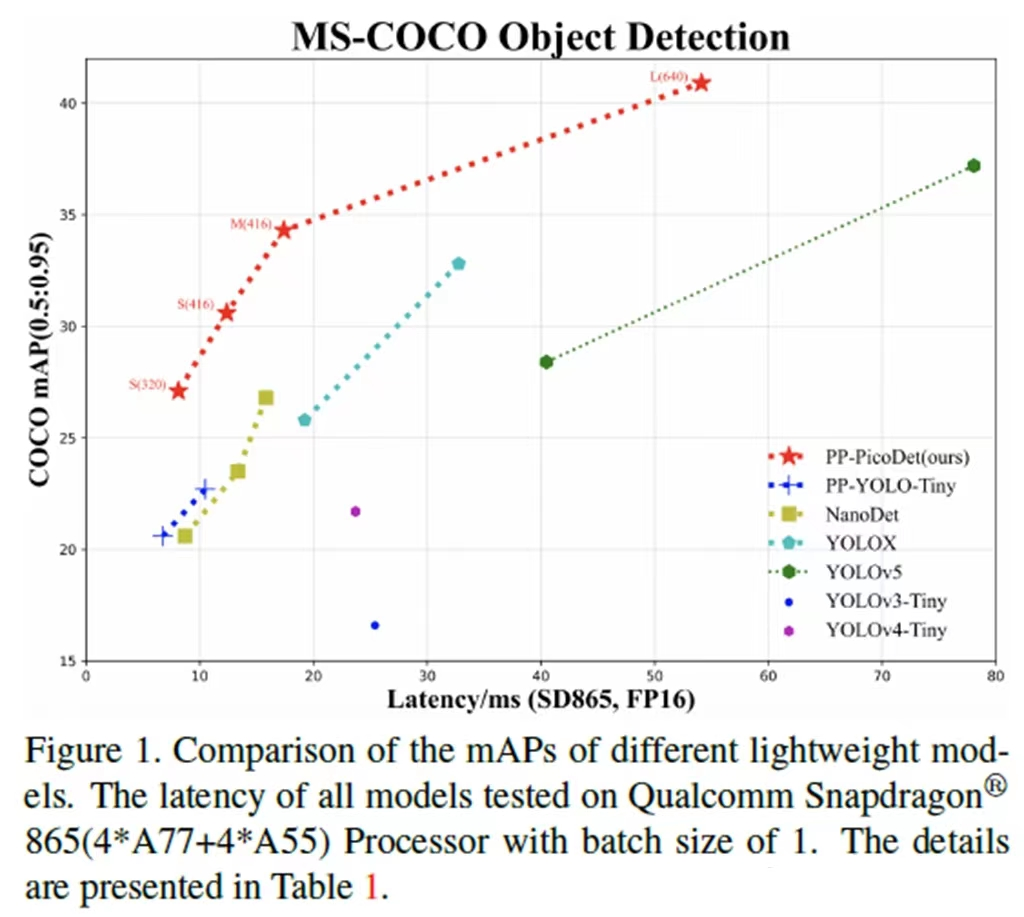

PicoDet-S以0.99M参数以及1.08G-FLOPs实现30.06%mAP。它在移动端ARM-CPU上实现了150FPS,输入尺寸为320。PicoDet-M在仅2.15M参数和2.5G-FLOPs的情况下实现34.3%mAP。PicoDet-L在仅3.3M参数和8.74G-FLOPs情况下实现40.9%mAP。本文提供了小、中、大三种模型来支持不同的部署场景。
- 整体网络结构

我们先来看它的主干网(Backbone),是百度自研的轻量级网络ESNet。它是根据ShuffleNet V2进行的改进,有关ShuffleNet V2的内容可以参考深度学习网络模型的改进与调整 中的ShuffleNet V2。

第一个改进是引入了 SE block,主要作用是对通道加权,增强特征的提取能力。有关SE block的内容可以参考深度学习网络模型的改进与调整 的MobileNet V3。第二个改进是使用了一组深度可分离卷积在stride=2的时候,替换掉了channel shuffle。channel shuffle可以增强不同通道中的信息交换,但是这个信息交换是不容于1*1卷积的,1*1卷积的计算速度通常比较慢,这里在每次进行下采样的时候就会替换掉channel shuffle。第三个改进是引入了Ghost block,主要目的是降低网络的冗余性,有关Ghost block的内容可以参考深度学习网络模型的改进与调整 中的GhostNet的Ghost bottleneck。
Backbone的权重占整个网络的60%以上,并且Backbone的特征提取作用也是至关重要的。优化Backbone对检测的性能提升还是非常有帮助的。