GAN Step By Step

心血来潮
GSBS,顾名思义,我希望我自己能够一步一步的学习GAN。GAN 又名 生成对抗网络,是最近几年很热门的一种无监督算法,他能生成出非常逼真的照片,图像甚至视频。GAN是一个图像的全新的领域,从2014的GAN的发展现在,在计算机视觉中扮演这越来越重要的角色,并且到每年都能产出各色各样的东西,GAN的理论和发展都蛮多的。我感觉最近有很多人都在学习GAN,但是国内可能缺少比较多的GAN的理论及其实现,所以我也想着和大家一起学习,并且提供主流框架下 pytorch,tensorflow,keras 的一些实现教学。
在一个2016年的研讨会,杨立昆描述生成式对抗网络是“机器学习这二十年来最酷的想法”。
Step6 LSGAN (Least Squares GAN)
Least Squares GAN
Least Squares Generative Adversarial Networks
Authors
Xudong Mao, Qing Li, Haoran Xie, Raymond Y.K. Lau, Zhen Wang, Stephen Paul Smolley
Abstract
Unsupervised learning with generative adversarial networks (GANs) has proven hugely successful. Regular GANs hypothesize the discriminator as a classifier with the sigmoid cross entropy loss function. However, we found that this loss function may lead to the vanishing gradients problem during the learning process. To overcome such a problem, we propose in this paper the Least Squares Generative Adversarial Networks (LSGANs) which adopt the least squares loss function for the discriminator. We show that minimizing the objective function of LSGAN yields minimizing the Pearson χ2 divergence. There are two benefits of LSGANs over regular GANs. First, LSGANs are able to generate higher quality images than regular GANs. Second, LSGANs perform more stable during the learning process. We evaluate LSGANs on five scene datasets and the experimental results show that the images generated by LSGANs are of better quality than the ones generated by regular GANs. We also conduct two comparison experiments between LSGANs and regular GANs to illustrate the stability of LSGANs.
近几年来 GAN 是十分火热的,由 Goodfellow 在 14 年发表论文 Generative Adversarial Nets 开山之作以来,生成式对抗网络一直都备受机器学习领域的关注,这种两人零和博弈的思想十分有趣,充分体现了数学的美感。从 GAN 到 WGAN的优化,再到本文介绍的 LSGANs,再到还有很火的 BigGAN ,可以说生成式对抗网络的魅力无穷,而且它的用处也是非常奇妙,如今还被用在例如无负样本的情况下如何训练分类器,例如 AnoGAN等等
LSGANs 这篇经典的论文主要工作是把交叉熵损失函数换做了最小二乘损失函数,这样做作者认为改善了传统 GAN 的两个问题,即传统 GAN 生成的图片质量不高,而且训练过程十分不稳定。
LSGANs 试图使用不同的距离度量来构建一个更加稳定而且收敛更快的,生成质量高的对抗网络。
LSGAN的损失函数
Least Squares GAN 比最原始的 GANs 的 loss 更加稳定,通过名字我们也能够看出这种 GAN 是通过最小平方误差来进行估计,而不是通过二分类的损失函数,下面我们看看 loss 的计算公式
ℓ G = 1 2 E z ∼ p ( z ) [ ( D ( G ( z ) ) − 1 ) 2 ] \ell_G = \frac{1}{2}\mathbb{E}_{z \sim p(z)}\left[\left(D(G(z))-1\right)^2\right] ℓG=21Ez∼p(z)[(D(G(z))−1)2]
ℓ D = 1 2 E x ∼ p data [ ( D ( x ) − 1 ) 2 ] + 1 2 E z ∼ p ( z ) [ ( D ( G ( z ) ) ) 2 ] \ell_D = \frac{1}{2}\mathbb{E}_{x \sim p_\text{data}}\left[\left(D(x)-1\right)^2\right] + \frac{1}{2}\mathbb{E}_{z \sim p(z)}\left[ \left(D(G(z))\right)^2\right] ℓD=21Ex∼pdata[(D(x)−1)2]+21Ez∼p(z)[(D(G(z)))2]
LSGAN两种模型架构和训练
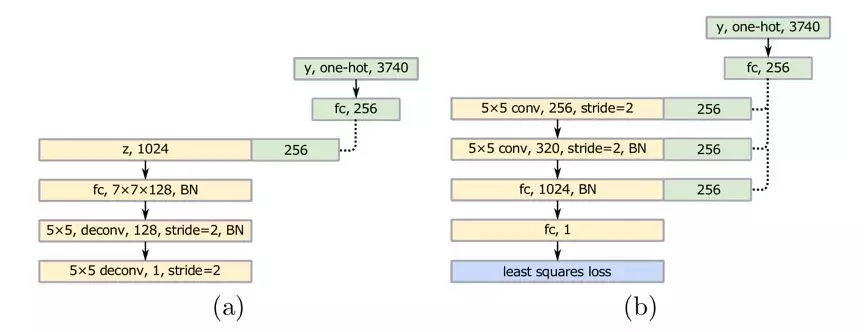
模型的结构
作者也提出了两类架构:
第一种处理类别少的情况,例如 MNIST、LSUN。网络设计如下:

第二类处理类别特别多的情形,实际上是个条件版本的 LSGAN。针对手写汉字数据集,有 3740 类,提出的网络结构如下:
传统GANs和LSGANs的比较
论文中使用了很多场景的数据集,然后比较了传统 GANs 和 LSGANs 的稳定性,最后还通过训练 3740 个类别的手写汉字数据集来评价 LSGANs。
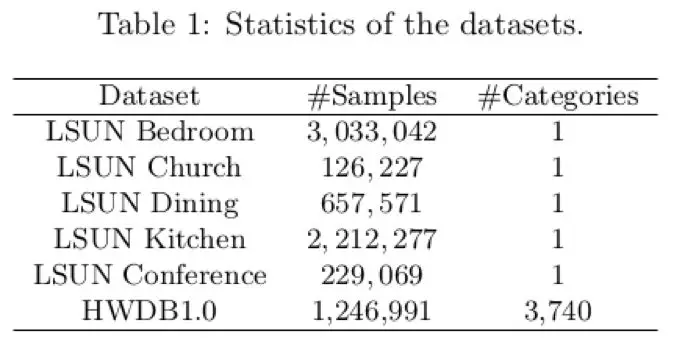
▲ 本文使用的数据集列表
在 LSUN 和 HWDB1.0 的这两个数据集上使用 LSGANs 的效果图如下,其中 LSUN 使用了里面的 bedroom, kitchen, church, dining room 和 conference room 五个场景,bedroom 场景还对比了 DCGANs 和 EBGANs 的效果在图 5 中,可以观察到 LSGANs 生成的效果要比那两种的效果好。


图 7 则体现了 LSGANs 和传统 GANs 生成的图片对比

通过实验观察,作者发现 4 点技巧:
\1. 生成器 G 带有 batch normalization 批处理标准化(以下简称 BN)并且使用 Adam 优化器的话,LSGANs 生成的图片质量好,但是传统 GANs 从来没有成功学习到,会出现 mode collapse 现象;
\2. 生成器 G 和判别器 D 都带有 BN 层,并且使用 RMSProp 优化器处理,LSGANs 会生成质量比 GANs 高的图片,并且 GANs 会出现轻微的 mode collapse 现象;
\3. 生成器 G 带有 BN 层并且使用 RMSProp 优化器,生成器 G 判别器 D 都带有 BN 层并且使用 Adam 优化器时,LSGANs 与传统 GANs 有着相似的表现;
\4. RMSProp 的表现比 Adam 要稳定,因为传统 GANs 在 G 带有 BN 层时,使用 RMSProp 优化可以成功学习,但是使用 Adam 优化却不行。
下面是使用 LSGANs 和 GANs 学习混合高斯分布的数据集,下图展现了生成数据分布的动态结果,可以看到传统 GAN 在 Step 15k 时就会发生 mode collapse 现象,但 LSGANs 非常成功地学习到了混合高斯分布。

MNIST数据集测试
下面没有给出所有的代码,因为大致是一样的,只是变化了损失函数
在上面可以看到 Least Squares GAN 通过最小二乘代替了二分类的 loss,下面我们定义一下 loss 函数
def ls_discriminator_loss(scores_real, scores_fake):
loss = 0.5 * ((scores_real - 1) ** 2).mean() + 0.5 * (scores_fake ** 2).mean()
return loss
def ls_generator_loss(scores_fake):
loss = 0.5 * ((scores_fake - 1) ** 2).mean()
return loss
这里定义判别器和损失函数,然后进行训练即可
D = discriminator().cuda()
G = generator().cuda()
D_optim = get_optimizer(D)
G_optim = get_optimizer(G)
train_a_gan(D, G, D_optim, G_optim, ls_discriminator_loss, ls_generator_loss)
Iter: 0, D: 0.5524, G:0.4728
Iter: 250, D: 0.2155, G:0.1959
…Iter: 3500, D: 0.1186, G:0.3989
Iter: 3750, D: 0.1621, G:0.228



比较实验结果
这里面也大概给个数据进行比较
LSGANs:
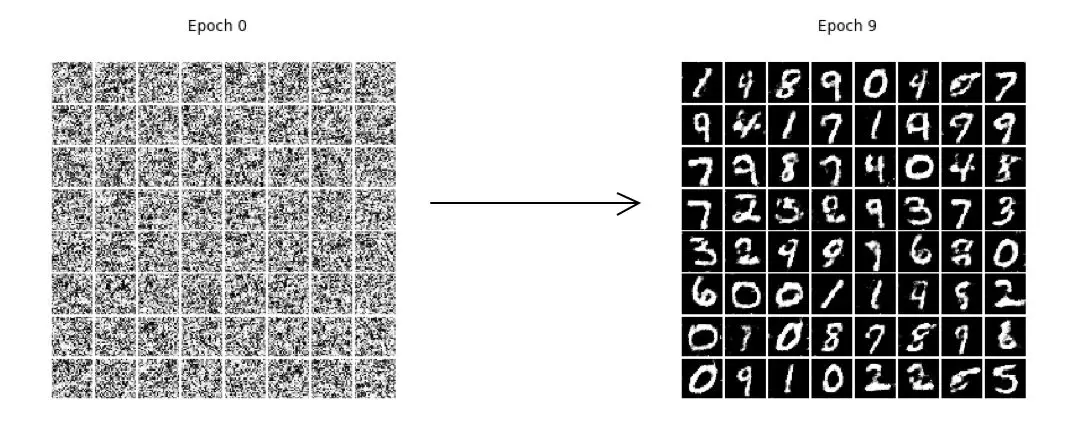
GAN:
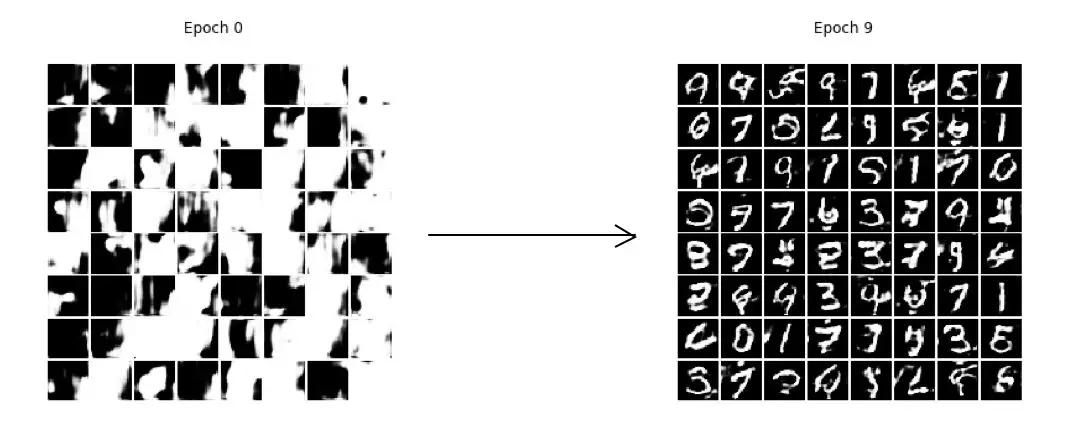
从本次用 MNIST 数据训练的效果来看,LSGANs 生成的效果似乎是比 GAN 的要清晰高质量一些。
总结
LSGANs 是对 GAN 的一次优化,从实验的情况中,有时候也发现了一些奇怪的现象。我本来是参考论文把判别器 D 的损失值,按真假两种 loss 加起来一并放入 Adam 中优化,但是无论如何都学习不成功,梯度还是弥散了,最后把 D_fake_loss 和 D_real_loss 分为两个 program,放入不同的 Adam 中优化判别器D 的参数才达到预期效果。
这篇论文中的思想是非常值得借鉴的,从最小二乘的距离的角度考量,并不是判别器分类之后就完事了,但是 LSGANs 其实还是未能解决判别器足够优秀的时候,生成器梯度弥散的问题。