文章目录
前言
本篇文章接着上一篇文章的节奏,继续来总结kafka在面试中经常会被问到的一些问题,主要围绕kafka日志保存了什么以及kafka集群相关知识展开。
一、kafka集群中zookeeper的作用是什么?
1.broker注册:Kafka使用了全局唯一的数字来指代每个Broker服务器,不同的Broker必须使用不同的Broker ID进行注册,Broker创建的节点类型是临时节点,一旦Broker宕机,则对应的临时节点也会被自动删除。
2.Topic注册:同一个Topic的消息会被分成多个分区并将其分布在多个Broker上,这些分区信息及与Broker的对应关系也都是由Zookeeper在维护
3.消费者注册:每个消费者服务器启动时,都会到Zookeeper的指定节点下创建一个属于自己的消费者节点。
4.生产者负载均衡:由于同一个Topic消息会被分区并将其分布在多个Broker上,因此,生产者需要将消息合理地发送到这些分布式的Broker上。
5.消费者负载均衡:通常,对于一个消费者分组,如果组内的消费者发生变更或Broker服务器发生变更,会发出消费者负载均衡,触发reblance机制。
注意:早期版本的 kafka 用zookeeper 做 meta 信息存储,consumer 的消费状态,group 的管理以及 offset的值。考虑到zookeeper本身的一些因素以及整个架构较大概率存在单点问题,新版本中确实逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖。
二、controller谁来充当以及作用是什么
集群中谁来充当controller ?
每个broker启动时会向Zookeeper创建⼀个临时序号节点,获得的序号最小的那个broker将会作为集群中controller。
controller 负责什么?
1.当集群中有⼀个副本的leader挂掉,需要在集群中选举出⼀个新的leader,选举的规则是 从isr集合中最左边获得。
2.当集群中有broker新增或减少,controller会同步信息给其他broker
3.当集群中有分区新增或减少,controller会同步信息给其他broker
二、rebalance机制和消费者分区分配策略
触发rebalance前提:消费组中的消费者没有指明分区来消费。
触发的条件:当消费组中的消费者和分区的关系发生变化的时候 ,例如一个消费组中,有一个消费者挂了,那么这个消费者之前消费的分区就要重新分配给其他消费者
消费者分区分配策略:在rebalance之前,分区怎么分配会有这么三种策略
1.range:根据公示计算得到每个消费消费哪几个分区:前⾯的消费者是分区总数/消费 者数量+1,之后的消费者是分区总数/消费者数量
2.轮询:大家轮着来 ,把所有的partition和consumer列出来,然后[轮询]consumer和partition,尽可能的让把partition均匀的分配给consumer
3.sticky:粘合策略,如果需要rebalance,会在之前已分配的基础上调整,不会改变之 前的分配情况。如果这个策略没有开,那么就要进行全部的重新分配。建议开启。
三、kafka日志保存了什么
Kafka消息以日志文件的形式存储,不同主题下不同分区的消息分开存储,同一个分区的不同副本分布在不同的broker上存储。
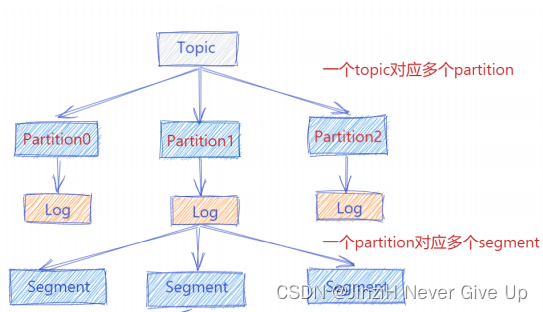
逻辑上看来日志是以副本为单位的,每个副本对应一个log对象,实际在物理上,一个log划分为多个logSegment,logSegment并不代表这个文件夹,logSegment代表逻辑上的一组文件,这组文件就是.log、.index、.timeindex
1、.log存储消息:00000.log: 这个⽂件中保存的就是消息
2、.index存储消息的索引
3、.timeIndex,时间索引文件,通过时间戳做索引,可以根据时间,去所有的partition中确定该时间对应的offset,然后去所有的partition中找到该 offset之后的消息开始消费(例如消费前一个小时的消息)
比较重要的两个日志文件:
1.00000.log: 这个⽂件中保存的就是消息
2.__consumer_offsets-49: kafka内部自己创建了consumer_offsets主题包含了50个分区。
这个主题⽤来存放消费者消费某个主题的偏移量。因为每个消费者都会⾃⼰维护着消费的主题的偏移量,也就是说每个消费者会把消费的主题的偏移量⾃主上报给kafka中的默认主题: consumer_offsets。
因此kafka为了提升这个主题的并发性,默认设置了50个分区。 提交到哪个分区:通过hash函数:hash(consumerGroupId) % __consumer_offsets 主题的分区数
提交到该主题中的内容是:key是consumerGroupId+topic+分区号,value就是当前 offset的值
⽂件中保存的消息,默认保存7天。七天到后消息会被删除。
四、数据传输的事务定义有哪三种?
数据传输的事务定义通常有以下三种级别:
1)最多⼀次: 消息不会被重复发送,最多 被传输⼀次,但也有可能⼀次不传输
2)最少⼀次: 消息不会被漏发送,最少被传输⼀ 次,但也有可能被重复传输.
3)精确的⼀次( Exactly once) : 不会漏传输也不会重复传输,每个消息都传输被⼀次⽽且仅仅被传输⼀次,这是⼤家所期望的
五、Kafka中的 ISR、AR 代表什么?ISR的伸缩又指什么
ISR:In-Sync Replicas 副本同步队列
AR(Assigned Replicas ):所有副本 ISR 是由 leader 维护,follower 从 leader 同步数据有⼀些延迟(包括延迟时间 和延迟条数 两个维度),任意⼀个超过阈值都 会把 follower 剔除出 ISR, 存⼊ OSR(Outof-Sync Replicas)列表,新加⼊的 follower 也会先存放在 OSR 中。
AR=ISR+OSR。
什么情况下⼀个broker会从isr中踢出去?
答:leader 会维护⼀个与其基本保持同步的 Replica 列表,该列表称为 ISR(in-sync Replica),每个 Partition 都会有⼀个 ISR,⽽且是由 leader 动态维护 ,如果⼀个 follower 比⼀个 leader 落 后太多,或者超过⼀定时间未发起数据复制请求,则 leader 将其重 ISR中移除 。
六、assign和subscribe的区别
1 subscribe: 自动安排分区, 通过group自动重新的负载均衡,例如消费者中有一个消费者挂了,那么这个消费者之前消费的分区就要重新分配给其他消费者;
2 assign:手动指定消费的分区(用户指定分区);不支持group的自动负载均衡(因为分区已经指定了,就不会在consumer之间负载均衡了),也就是当group内消费者数量变化的时候不会有reblance行为发生;
3.assign的方法不能和subscribe方法同时使用。
4.最好是使用subscribe()方法,让分区自动分配。毕竟Kafka的消费者组机制已经很优秀,为我们节省了很多功夫。哪怕你需要采用assign()指定的方式,也应该设置好对应的消费者组。尽量别混合使用。
总结
本篇文章的内容较多,主要围绕kafka集群的相关知识展开,副本同步队列和rebalance机制以及消费者分区分配策略是本篇文章的重点,面试中经常问到,需要特别注意。