Redis是什么?
Redis是一种非关系型数据库,数据都在内存中,读写速度非常快。Redis是单线程架构,所以它是线程安全的,内部采用IO多路复用。包含了我们常用的数据结构,同时支持持久化和集群模式。也可以作为分布式锁,消息中间件来使用。
Redis的数据类型
Redis支持常用的数据结构有String、Hash、List、Set、Sorted Set。redis内部使用了一个redisObject对象来表示所有key-value如下图:

type表示数据是哪种数据类型,encoding表示数据在redis内部的存储方式随着数据的长度变大redis可能会对数据进行压缩处理。
String:字符串类型是Redis最基础的数据类型。首先key都是字符串,同时其他几种数据结构都是在字符串类型基础上构建的。String的value可以是字符串(简单字符串,复杂的JSON、XML)、数字、甚至是二进制(图片,音频,视频),但是最大值不能超过512M。
Hash:哈希是一个key-value的集合。redis 的hash是一个String的key-value的映射表

List:列表类型用来存储多个有序字符串。列表中的元素是有序的,就意味着可以通过索引下标获取某个元素或者某个范围的元素。redis的list递增实现是一个双向链表,可以添加一个元素到列表的头部或者尾部,也可以走位消息队列来使用。
Set:集合(Set)类型也是用来保存多个字符串元素,和列表不同的是,集合中允许有重复的元素,并且集合是无序的必能通过索引获取元素。底层通过hashtable来实现。而且set提供了判断某个成员是否在一个set集合中非常好用。
ZSet:有序集合保留了集合不允许重复成员的特性,同时支持排序。提供给没一个元素score作为排序依据。所以有序集合可以获取指定分数和元素范围的查询。

有序集合内部使用HashMap和跳跃表来保证数据的存储和有序,Hash里面存放的是成员到score的映射,而跳跃表里面存放所有的成员。排序依据是根据HashMap里面存member到score的映射,使用跳跃表的结构可以获得比较高的查询效率。
Redis为什么这么快
Redis使用C语言,一般来说C语言实现的程序“距离”操作系统更近,执行速度相对更快。
Redis完全基于内存操作,所以CPU不会成为Redis的瓶颈。能成为瓶颈的只有机器的内存大小和网络带宽。多线程是为了更好的压榨CPU,既然CPU不会成为Redis的瓶颈,那么采用单线程的结构就减少了不必要的上下文切换和竞争条件。也不存在多线程环境中锁的问题。采用非阻塞的IO多路复用模型。
Redis的持久化机制
Redis为了保证效率,数据都是存放再内存中的,但是当redis挂掉或者服务器重启,再次启动内存中的数据将会丢失。所以redis会周期性的持久化数据到磁盘中,保证数据的持久化。目前来说持久化策略有两种:
- RDB:RDB持久化就是把当前进程数据生成快照文件保存到磁盘的过程
优点:RDB是一个紧凑的的压缩二进制文件,非常适合于备份和全量复制场景,同时恢复比较快。
缺点:没有办法做到实时持久化,持久化的时候redis进程会执行fork创建子进程,rbd的持久化过程由子进程负责,完成后自动结束,fork创建子进程是阻塞的属于重量级操作,频繁执行成本比较高。rdb使用的是特定格式的二进制保存,redis版本演进过程中有多个版本的reb文件,会存在老版本无法兼容新版rdb格式的问题
- AOP:以独立日志的方式记录每次的写明命令,重启时执行AOP文件中的命令就能达到恢复数据的命令
Redis默认是以快照RDB的持久化方式,但是重启是会优先使用AOF文件来还原数据。因为AOF文件保存的数据集通常比RDB文件所保存的数据集更完整。
AOF可以做到全程持久化,配置中开启AOF。这样redis没执行一个修改数据的命令,都会被追加到AOF文件中。我们可以根据需求设置不同的同步测量,例如是每秒同步一次,这样即使发生宕机,重启后最多也丢失一秒钟的数据。所以就造成AOF文件通常要大于RDB文件。所以根据AOF回访恢复数据,可能相对于RDB慢一点。
redis支持同时开启两种持久化方式,所以我们可以综合AOF和RDB两种来选择。用AOF保证数据不丢失,作为恢复的第一选择;用RDB来做不同程度的冷备,这样在AOF文件丢失或者损坏不可用的时候,还可以使用RDB来进行快速的数据恢复。
到底什么是缓存穿透,缓存雪崩,缓存击穿
https://blog.csdn.net/qq_25448409/article/details/86566859
缓存和数据库一致性问题
分布式环境下非常容易出现缓存和数据库间数据不一致问题。如果项目对缓存要求是强一致性的,那么久不要使用缓存。也或者说采用合适的策略来降低缓存和数据库不一致的概率,包括合适的更新策略、更新数据库后及时更新缓存、缓存失败增加重试机制等。
说一说redis的集群方案
redis集群方案主要包Redis Sentinal和Redis Cluster
- Redis Sentinal:哨兵模式着眼于高可用。
Redis主从模式下主节点虽然可以将数据发送给从节点,但是主节点一旦发生宕机。这时候还需要人为的修改应用放的主节点地址,并且命令所有从节点去复制新的主节点,整个过程需要认为干预很麻烦。为了让一切不需要认为干预,所以有了Redis Sentinel架构。sentinel主要包含活性检测和自动故障切换,应用方从sentinel集群获取redis主节点信息然后连接。当redis的主节点挂掉,sentinel集群会投票将一个从节点升级为主节点,并将其他从节点指向新的主节点。客户端应用在初始化时连接sentinel节点集合,并从中获取主节点信息。
https://blog.csdn.net/qq_25448409/article/details/106985362
- Redis Cluster:着眼于扩展性,在单个redis发生内存不足时,使用Cluster进行分片存储。
https://blog.csdn.net/qq_25448409/article/details/86013885
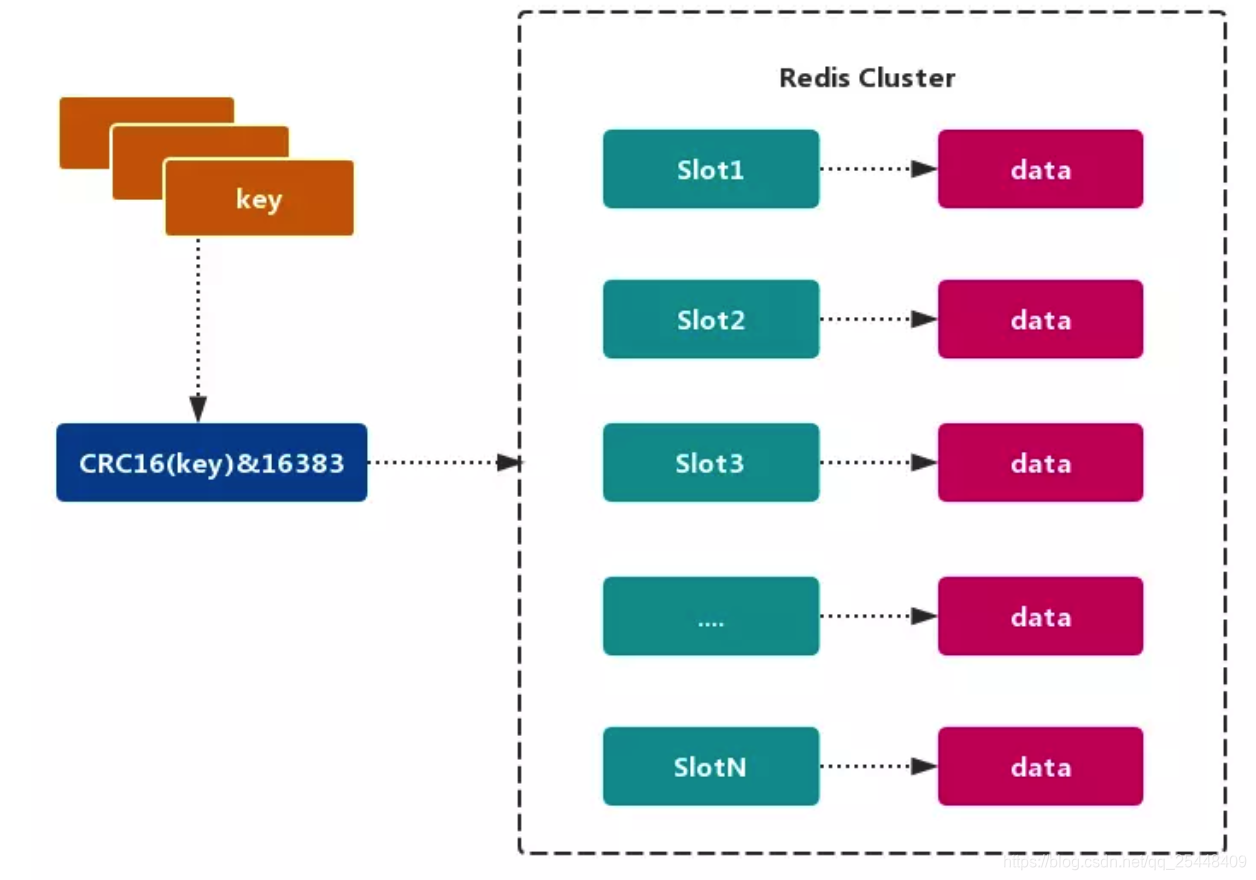
Redis Cluster采用了虚拟槽分区,其实我感觉和一致性哈希算法大同小异。它是将所有的key根据哈希函数映射到0~16383的整数槽内。每个节点维护一部分的槽以及槽映射的键值数据。
说一说Redis的分布式锁吧
如果Redis单机条件下,我们只需要利用String数据类型的nx、px就可以实现一个简单的分布式锁
SET resource_name my_random_value NX PX 30000- NX:表示只有 key 不存在的时候才会设置成功。(如果此时 redis 中存在这个 key,那么设置失败,返回 nil)
- PX 30000:意思是 30s 后锁自动释放。别人创建的时候如果发现已经有了就不能加锁了。
为了防止客户端获取了锁,然后某些操作阻塞导致时间超过了该锁的有效时间,然后又删除了另一个客户端获得的锁。我们可以使用原子性的lua脚本。加锁时设置一个期望值,只有key里面存的value是我们加锁是设置的那个,才可以释放。
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end上面的实现,都是基于单台Redis,如果我们搭建了集群key就会被分散在不同的机器里面,这时候又怎么办。官方给出多节点Redis的解决方案成为RedLock,我看过之后发现没卵用,问题还是很多。如果你们的Redis都多节点了,分布式锁就直接用Zookeeper吧,这个才是分布式锁的最优解。