
Presto committer教你构建海量数据OLAP查询引擎
活动回顾:在探索Alluxio系列活动中,Alluxio的资深软件工程师王北南博士,为我们介绍讲述了Presto+Alluxio 构建大规模交互式SQL查询引擎的实践与应用。
(以下为王北南博士在大会中的演讲实录)
王北南 Alluxio资深软件工程师,也是PrestoDB的committer。加入Alluxio之前,北南博士是Twitter Presto团队的技术负责人,并为Twitter的数据平台构建了大规模分布式SQL系统。他在性能优化、分布式缓存和大数据方面有12年的工作经验。王北南博士毕业于雪城大学计算机工程专业,专业方向是对分布式系统进行信号模型检测和运行验证。
Presto技术概览

可以给大家先简单介绍一下Presto,因为可能很多人是第一次接触这些大数据平台的技术。那Presto是什么呢?
其实它就是能查询大量、海量数据的一个SQL数据库,SQL数据库大家已经见了很多了,MySQL、oracle这些都是SQL数据库。很多人可能也有体会,SQL是个很方便的查询数据的语言。那为什么要有Presto呢?首先如果你使用MySQL,oracle的话,你会发现它查一些小规模的数据,如果可以很容易命中的话,它是很快的。但如果说你要查海量的数据,比如说有几亿条或者几十亿条的时候,性能就不断的下降,而且如果你要做一个全表的扫描的话,这个对它们来说就是个灾难,可能它就会变得非常的慢。那这时候就有了Presto分布式的SQL大数据查询引擎,这就是Bin(范斌——Alluxio创始成员和VP of Open Source)之前提到的计算和存储分离的计算引擎,它就不再像我们传统的数据库那样管理存储,Presto不管理存储,它把存储交给了第三方平台,可以是HDFS也可以是GCS也可以是S3,什么都可以。Presto只管计算,那这样的一个情况下,我们可以分开的scale up&down,然后达到处理海量数据的目的。
那现在是一个什么情况?我口说无凭,大家可以看网上的一些资料,互联网巨头的数据都是海量的,都是几十亿人的使用,这些互联网公司都是普遍采用Presto来进行数据的查询,那这个大概是一个什么量呢?一个基本的Presto集群,可能是200~400的服务器的Presto集群,它一秒钟可以处理几十个B,也就是几百亿行的数据,如果看这种生产环境的Presto,我们可以看到Presto一秒钟可以处理几百亿行的数据,这真的非常适合有海量数据的情况下来运行SQL的查询。
Presto瓶颈和部署Alluxio实例
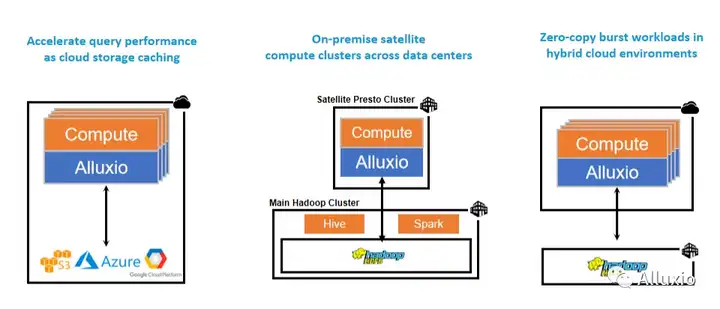
刚才也提到了, Presto是计算和存储分离,大家都知道互联网,虽然上网感觉好像到哪都很快,但其实是有距离的。比如说今天我们这个直播,大家可能看到,我们两个人的视频就没有那么流畅,为什么?因为我们距离有点远,从美国的硅谷到中国传输距离很长,有很多的网关路由器,延时就在增长,而Presto没有自己的数据,要查询任何东西,都要把要查的数据集给读出来,都要给load进来,一行一行地扫描一遍,那速度就很依赖于网络传输的速度,其实这也是Presto的瓶颈之一。我们可以把Alluxio和Presto或者其他的计算引擎部署到一起,它起到一个中间层的作用,就是说计算引擎只从Alluxio拿数据,然后Alluxio负责从实际的存储来拿数据。比如说我们最左边的这个例子,这个是现在很多新兴的互联网公司或者新的创业公司最常用的一个架构,它从创业第一天或者公司建立第一天起,数据就是完全的上云,自己不用建数据中心了,这是现在非常常见的一个模式。那数据都在云上,计算怎么办?从云上拿数据其实一方面是费用高,另外一方面是速度可能会慢,那怎么办?我们就通过Alluxio做一层缓存机制,如果数据在Alluxio集群里边,那我们从Alluxio可以拿到,如果说没在,我们的计算引擎也不用关心,让Alluxio去云上把数据拿回来,起到一个提速的作用。
那有些朋友说我们公司没上云,就是有一些数据中心。但很多公司的数据中心一个地方也放不下,很多公司可能是在北京有数据中心,西安有数据中心,杭州有数据中心,比如说西安的同事想跑一条计算,想跑一个SQL的查询,那怎么办?这个数据可能在杭州是吧?这又是一个异地的过程。它也是可以用Alluxio,Alluxio跟计算部署到一起,比如说计算Presto集群,500台服务器在西安,那我们同样把Alluxio跟它部署到一起。计算引擎到Alluxio来拿数据,Alluxio负责到异地的数据中心来拿数据,而且有了这个架构之后,可以支持多个异地的数据中心,反正就是到Alluxio找数据,Alluxio负责帮你把数据给拿回来。这是中间的一个情况。那最右边这个情况其实是我亲身经历的一种情况。这个公司本来数据都是在自己数据中心里的Hadoop上,但是可能是机器不够用了,公司想上云那怎么办?因为云上的机器可能会更便宜,而且要新机器会更容易。其实很多公司会想是不是要把数据往云上copy一份,或者比如说计算是在云上的,那我是不是把数据往云上copy,但是这个费用或者说成本、耗时都会很大那怎么办?我们云上的计算集群可以部署一个Alluxio,同样的道理做到提速。这个图就解决了长距离的,距离增大了或者说异地的这种情况。当然我们后面也会有一些具体的例子和数据,可以看到Alluxio会有加速,而且也方便访问的这么一个过程。
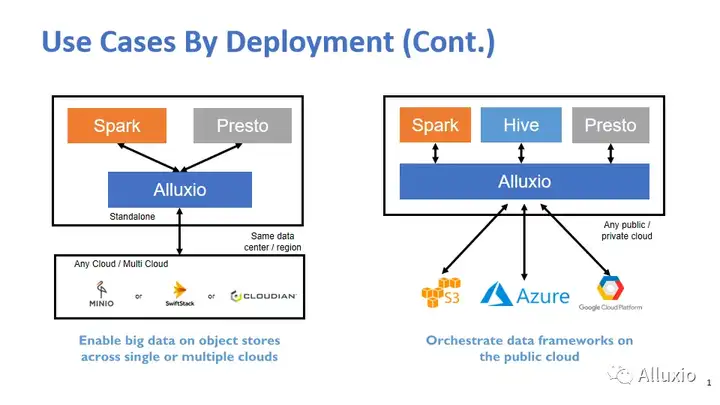
我们上云也好,或者使用第三方的存储服务也好,对我们的计算引擎也是一个挑战。其实对Presto和Spark还好,因为各种的object store基本上都还支持,但是如果说贵公司要是有很多种存储技术的话,那这个问题就有点麻烦了,可以通过Alluxio来做一个抽象层,帮你集中管理、集中使用各种存储方式。因为现在很多公司也是有价格上的策略,可能不愿意只局限于一种云的服务,对吧?或者它这个数据可能S3也放一点,GCP上也放一点,对吧?那其实就存在Bin刚才提到的数据孤岛的问题,数据哪里都有,怎么办?真正的数据的使用者,不是那么关心数据在哪,他只关心这种逻辑层面上的数据的查询和访问,并不关心数据底层是一种什么形式存在的。所以说通过Alluxio来做一层抽象,做一个隔离,这也减轻计算引擎方面的负担。
Presto+Alluxio黑魔法1-用于SQL分析

那我们搞这么一个抽象层,一个layer在中间,有什么好处?那第一个好处就是快,为什么会快?因为前面提到了互联网也是有距离的,网络有距离,那我们的Alluxio作为一个缓存层,它离计算引擎更近,甚至可以部署在一台机器上,数据的访问读取的延时就会变得很低。其实快就解决了很多问题,如果有维护过大数据计算引擎的朋友就会知道,速度一快整个系统的吞吐量也会上升,稳定性也会上升,各方面都会有提高。其实快也不是速度这么简单,它还提供速度的稳定性。不知道大家有没有遇到过,你用Presto的时候,同一条查询,可能今天需要5分钟,明天再运行一下两小时,它不稳定,为什么不稳定?一部分是网络延时的原因,一部分也是由于Presto有调度的问题,其他用户比较多,或者你的优先级被调低了,所以不稳定。那这个不稳定带来很多灾难,我们管它叫SLA。如果说你的用户是个人,他可能是个数据工程师或者是数据分析师,他本来一天要运行比如说10条SQL的查询,因为他要出报表,那他这个数不稳定,两小时没出来,可能要重试一下或怎么样,当天任务完成不了。如果说客户端是一个服务,如果延时不稳定,超过上限的话,那这个问题就更严重了。因为任何客户端都会有一个超时的设定,它直接就失败了。而且刚才也提到了网络I/O是一个瓶颈,如果有Alluxio,它能帮你挡掉一些网络的传输,减轻网络的负担,带宽腾出来又可以干很多事,对Presto来说各种SQL的各种join的连接,会变得更快。而且我们不单是有这个看起来像是缓存的服务,而且我们还有一些元数据的服务,叫 catalog service,然后我们还有一些数据转换的服务。因为其实有的时候有些数据格式并不是那么利于查询,那可以做一些转换,比如说把csv转换成parquet,就更加利于计算引擎来做查询和分析。
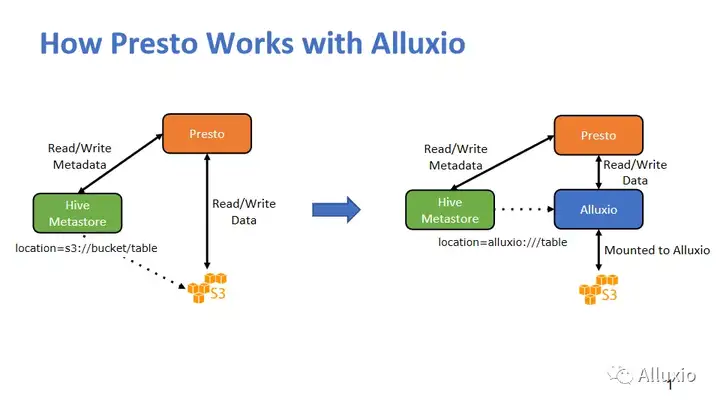
这个图就是在讲Presto和Alluxio怎么工作,先看一下Presto没有Alluxio之前自己怎么工作。其实任何一个Presto查询分两步走,第一步先去Hive Metastore拿元数据。你不是给我一个table吗?那我就要看看这个table存在哪,这个元数据会给它一系列的位置,一个很长的列表,可能几百个,几千个甚至几万个几十万个都有可能,其实就是一些文件或者路径。Presto拿到这一系列路径之后,这里也没有什么黑魔法,就是Presto把这些数据给读出来,做计算看哪些数据符合你的要求。
当我们有了Alluxio之后,我们会让元数据返回一个Alluxio地址,因为本来你可能是S3,HDFS,现在就是Alluxio了,我们后面有个真正的黑魔法,待会再讲。那它给我们一个Alluxio的table的路径,然后Presto就会拿这个路径去找Alluxio。你之前会把S3也好,HDFS也好,把它给挂载到了Alluxio,Alluxio知道你要的是这个东西,因为我们有元数据服务,然后我们就知道你是要这个文件,那Alluxio就会看,如果说我有,我就给你,我没有我去找底下的存储,把你要的数据给拿到。这里我们其实有两个改动,一个就是元数据这里会有URL的变化,然后另外一个工作就是我们需要挂载真实的存储,可能现在有些人会觉得这个好像有点麻烦,那么等下还会有个黑魔法。
Presto+Alluxio黑魔法2-Transparent URL+自动挂载
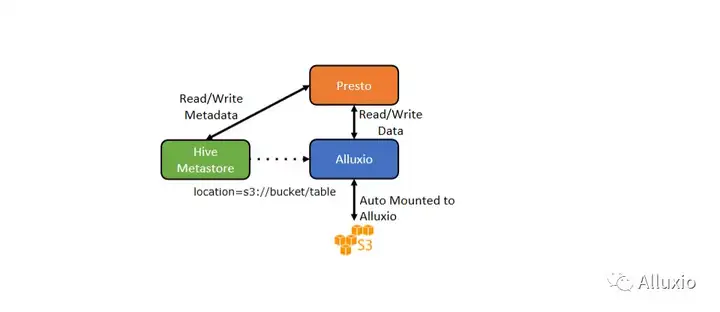
我们也是在最近的这一两个版本中,加入了一个叫Transparent URI和自动挂载的功能,现在我们不麻烦这个元数据和Hive Metastore给我们一个更新了的地址,原来你是S3还是HDFS,你还是给我这个,所以说对于Hive Metastore来说,它完全可以对Alluxio无感知。那等于说Presto还是拿到了S3的地址,我们不用修改代码,我们修改一下Presto的配置,把FS的默认实现换成Alluxio自己实现。就是当他看到这个是S3的,他会去Alluxio找,它会有一个自动挂载的机制,事先也会有一些配置,但是就一两行的配置加上之后,他自己到对应的S3 bucket上,把这个数据给挂载好。但对于我们的Hive Metastore也好,对于我们的这个Presto用户也好,都是无感知,因为它看起来这个表好像还在S3上或者在HDFS上,但实际上是到Alluxio这边走了一遭,如果说我们这个缓存有命中,Alluxio有这个数据了,它就会有非常好的提速效果。

那我们从用户角度会看到什么?
因为我前面讲了,Presto是存储和计算分离的,它并不太管理存储空间,你在Presto建表的时候,建这种external table时,那其实在干嘛?它就是指定一个路径,告诉Presto或者告诉Hive Metastore,我们这里建个表,这个表就是在某一个位置。那如果说你有了Alluxio的话,其实你在建表的时候就告诉Presto,这个表是在这个地方,我们是一个Alluxio打头的就好了。后面的这些工作全是其实都是由Presto和Alluxio来做的,用户的修改就已经是非常少了。那有了Transparent URI后,其实修改可以更少,我们都不用改原来的建表脚本,如果你原来有表,你是建在这个S3上,就不用动了,但如果你没建,你可以用这个命令,跟以前那个普通的S3也好还是HDFS也好都是一模一样的。然后你就在里边查询就好,你写任何一个SQL查询,你都不用管它的路径在哪,表一旦建好,对于普通的数据工程师或者数据设计师也好,他们知道这个table内容其实就够用了,就可以从table拿到数据。
Presto+Alluxio 真正的黑魔法-元数据缓存
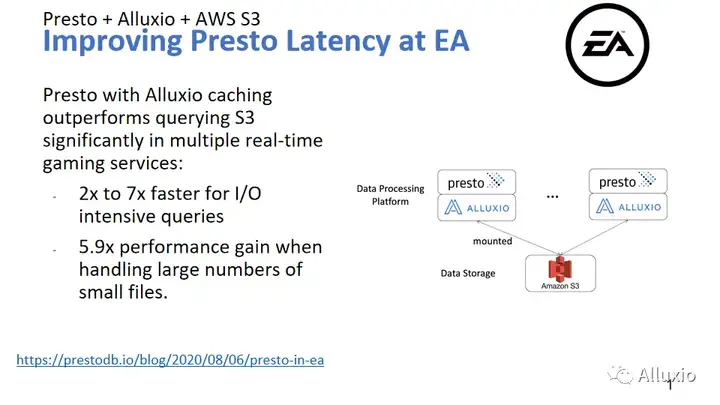
那我们再来就是稍微介绍一下我们的一些真实案例,让大家对我们的提速过程有一个直观的认识。因为我也是亲身运营维护Presto好些年,我感觉我收到的最大的抱怨也好,投诉也好,就是你们怎么这么慢?这个查询我一天都没跑完,我一天工作都被你耽误了。那怎么办?如果你也是在维护Presto,或者你们公司有Presto的话,试一试我们的Alluxio caching,在进行一些简单的配置和优化之后,你会看到几倍的提速。这里特地写是I/O密集型的查询,但如果说你真的运营Presto的话,你会发现大多数query都是I/O密集型访问。我们以前做了一个统计,90%的时间都是花在扫表上面的,那使用Alluxio会给这些查询一个非常漂亮的提速。
然后你看这里特意强调小文件,这个小文件其实我们后面还会有另外的直播,会讲这个元数据方面。它为什么会强调小文件,其实小文件的瓶颈,就有一部分从扫表变成了元数据的获取,因为前面讲了元数据给你一个文件列表,如果文件特别小,同样的数据量里面文件就会特别多,那它这个地方时间就会消耗比较长。对于这个案例,如果我们没有开元数据缓存的话,其实提速没有5点几倍,好像是1点几倍还是多少倍,我们开了这个元数据缓存之后,提速5.9倍。有兴趣的朋友可以关注我们的后续直播,我们会有一个catalog service的直播。
那么这个是怎么实现的呢? 可以看我们的右边的这个图,数据还是在这个S3上没有变化,对吧?这个图透露很多信息,可以看到Alluxio和Presto有一个一一对应的关系。其实我们就是这么部署的,我们把每一个Presto worker和每一个Alluxio worker部署到一起,为什么部署到一起?这里我要提一下,这两个东西真的是天作之合,因为它资源的使用是错位的,Presto会比较强调对CPU的使用,它要很多的CPU,它要很多的内存,但是Alluxio对CPU要的不多,对内存也没要多少,但它对磁盘要的很多。那你想一个物理机器,正好把它俩放一起。有朋友说这两个东西好像都要网络,怎么办?他俩在一起的话,如果能命中缓存,就不需要从外面拿,如果说没命中,那它俩也只要出去拿一份就好了,其实这个总量上还是没有提升,如果缓存命中率高,其实网络的压力是大幅下降的,所以它俩合作就可以达到查询提速的效果。
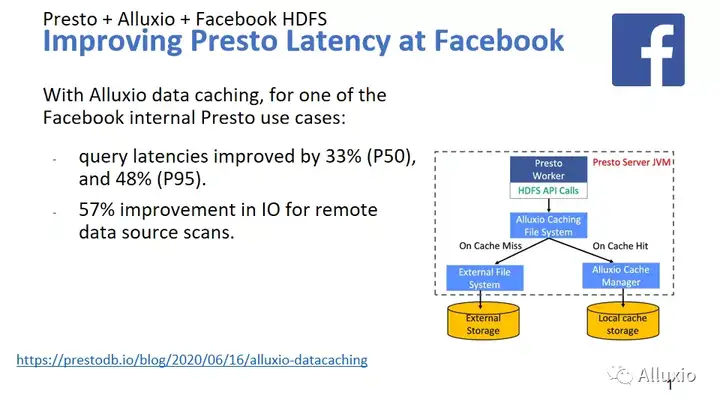
这个项目是我们跟Facebook脸书的合作,这也是BIN跟我一直在跟的一个项目。其实这个数据有点保守,从他们最近一次跟我们的讲座来看,他们是获得了10倍以上的提升。那这个技术跟前面略有不同,前面是一个分布式的缓存的设计,那这里我们管它叫Presto worker的local cache,略有不同,可以理解为一二级的缓存。那这个也是一样的逻辑,我们如果命中了,我们就本地拿给它,如果没命中就到远程去拿。这个项目在脸书已经得到非常广泛的使用,数以万计的服务器都在使用,具体的数字我可能不方便透露,这些服务器都是使用我们的local cache来做提速,而且我们还会有不少的后续工作,其实我们还有很大的潜力。
它的特点是,在图上也能看到local cache是运行在和Presto worker相同的JVM里面。Presto读文件,无论从HDFS读也好,从S3读也好,你都读一个文件,那我们有这个cache file system,就可以从我们这边来读这个文件,也会有一个非常好的效果。从这个数据也能看到我们提高了查询时间的稳定性,我们对p50,就是这个中位数提高33%,对p95,就是说95%的时间的查询是48。慢的查询可能会有更好的效果,而且我们还减轻了很多网络的负担,这个其实是很成功的一个标志。他们的服务的稳定性和速度都得到很好的提升。

我们还有更多的例子都在这里,非常多的公司都在跟我们合作,他们都取得了满意的效果,这只是一部分,很多公司也还在跟我们持续的合作,大家可以看底下这两个链接获得更多的信息,谢谢大家。
想要获取更多有趣有料的【活动信息】【技术文章】【大咖观点】,请关注[Alluxio智库]:
