5.1 一级缓存
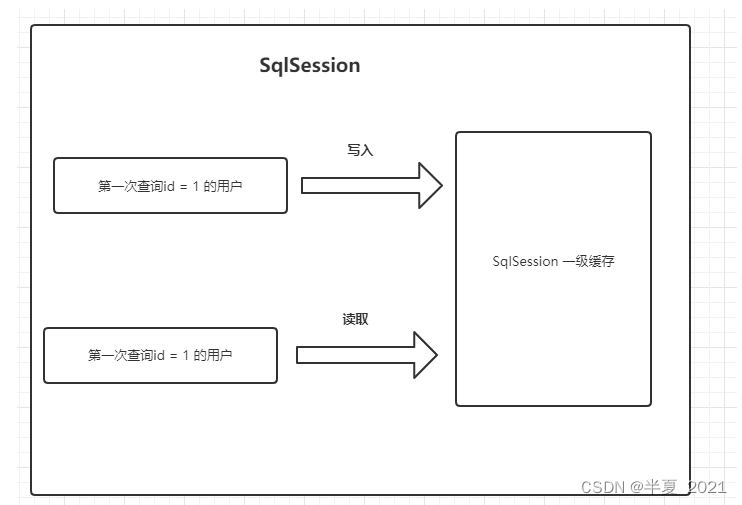
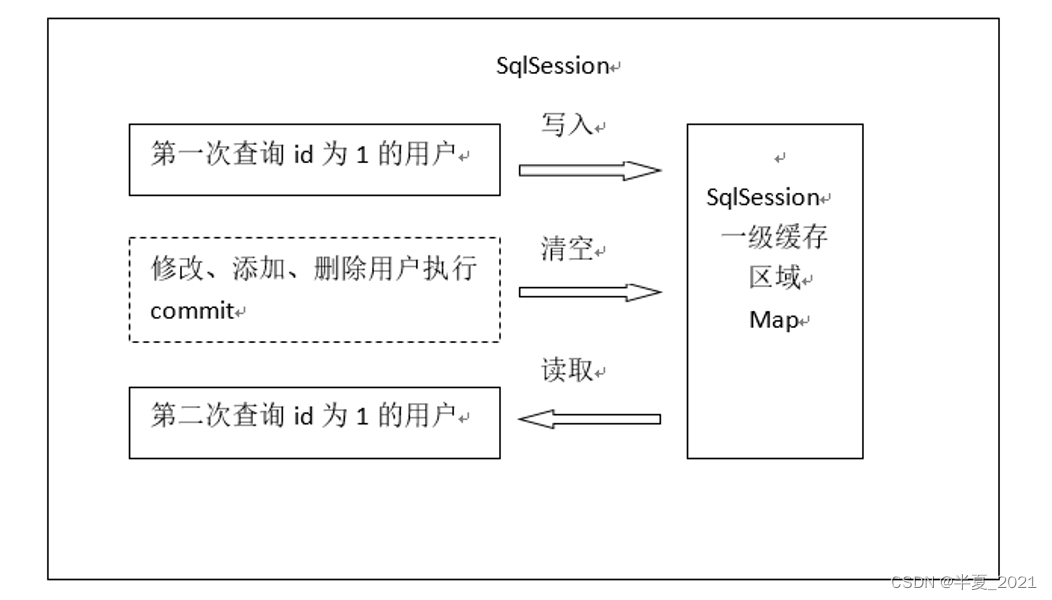
一级缓存(也叫本地缓存),默认会开启,并且不能控制。想要关闭一级缓存可以在select标签上配置flushCache=“true”;一级缓存存在于 SqlSession 的生命周期中,在同一个 SqlSession 中查询时, MyBatis 会把执行的方法和参数通过算法生成缓存的键值,将键值和查询结果存入一个 Map对象中。如果同一个 SqlSession 中执行的方法和参数完全一致,那么通过算法会生成相同的键值,当 Map 缓存对象中己经存在该键值时,则会返回缓存中的对象;任何的 **INSERT 、UPDATE 、 DELETE 操作都会清空一级缓存;
一级缓存的执行过程:
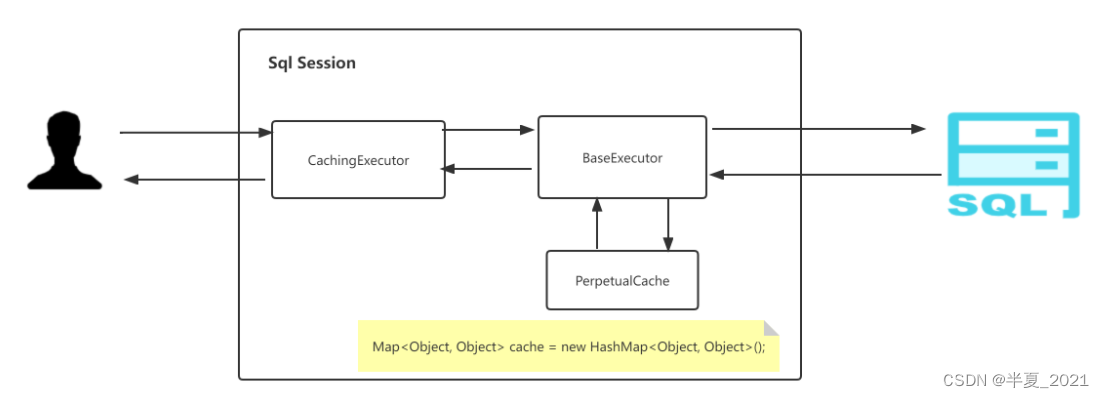
每个SqlSession中持有了Executor,每个Executor中有一个LocalCache。当用户发起查询时,MyBatis根据当前执行的语句生成MappedStatement,在Local Cache进行查询,如果缓存命中的话,直接返回结果给用户,如果缓存没有命中的话,查询数据库,结果写入Local Cache,最后返回结果给用户。具体实现类的类关系图如下图所示。
5.3.1 一级缓存的测试
下面举两个例子来说明一级缓存
案例一: 在同一个SqlSession 查询两次id = 1的客户
测试代码如下:
@Test
public void selectUserById(){
SqlSession sqlSession = sqlSessionFactory.openSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
// 查询id = 1 的用户
UserInfo userInfo = mapper.selectUserById(1L);
System.out.println("userInfo=="+userInfo);
// 查询id = 1 的用户
UserInfo userInfo2 = mapper.selectUserById(1L);
System.out.println("userInfo2=="+userInfo);
}finally{
sqlSession.close();
}
}
下面是执行的日志:
[org.apache.ibatis.transaction.jdbc.JdbcTransaction]-Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@57f23557]
[com.xa02.mapper.UserMapper.selectUserById]-==> Preparing: SELECT id,user_name,sex,birthday,address FROM t_user where id = ?
[com.xa02.mapper.UserMapper.selectUserById]-==> Parameters: 1(Long)
[com.xa02.mapper.UserMapper.selectUserById]-<== Total: 1
上面只执行了一次sql查询数据库,第二次查询走的是一级缓存。
案例二: 在同一个SqlSession 查询两次id = 1的客户的中间对客户进行更新
代码如下:
@Test
public void selectUserById(){
SqlSession sqlSession = sqlSessionFactory.openSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
// 查询id = 1 的用户
UserInfo userInfo = mapper.selectUserById(1L);
System.out.println("userInfo=="+userInfo);
//更新id = 1的用户
UserInfo ui = new UserInfo();
ui.setId(1L);
ui.setUserName("wanghan");
mapper.updateUser(ui);
// 查询id = 1 的用户
UserInfo userInfo2 = mapper.selectUserById(1L);
System.out.println("userInfo2=="+userInfo);
}finally{
sqlSession.close();
}
}
测试日志:
[com.xa02.mapper.UserMapper.selectUserById]-==> Preparing: SELECT id,user_name,sex,birthday,address FROM t_user where id = ?
[com.xa02.mapper.UserMapper.selectUserById]-==> Parameters: 1(Long)
[com.xa02.mapper.UserMapper.selectUserById]-<== Total: 1
userInfo==UserInfo{id=1, userName='zhangsan', sex='0', birthday=Tue Nov 17 15:07:08 CST 2020, address='上海市', orderInfoList=null}
[com.xa02.mapper.UserMapper.updateUser]-==> Preparing: update t_user SET user_name = ? where id = ?
[com.xa02.mapper.UserMapper.updateUser]-==> Parameters: wanghan(String), 1(Long)
[com.xa02.mapper.UserMapper.updateUser]-<== Updates: 1
[com.xa02.mapper.UserMapper.selectUserById]-==> Preparing: SELECT id,user_name,sex,birthday,address FROM t_user where id = ?
[com.xa02.mapper.UserMapper.selectUserById]-==> Parameters: 1(Long)
[com.xa02.mapper.UserMapper.selectUserById]-<== Total: 1
userInfo2==UserInfo{id=1, userName='zhangsan', sex='0', birthday=Tue Nov 17 15:07:08 CST 2020, address='上海市', orderInfoList=null}
说明:
-
第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息,将查询到的用户信息存储到一级缓存中。
-
如果中间sqlSession去执行commit操作(执行插入、更新、删除),清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
3.第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息。
注意:
如果不想让selectUserById 方法使用以及缓存,可以对该方法做如下修改:
<select id="selectUserById" parameterType="long" resultMap="userResultMap" flushCache="true">
SELECT
id,user_name,sex,birthday,address
FROM
t_user where id = #{id}
</select>
在原来的方法上加上 flushCache = true,会在查询数据前清空一级缓存,因此该方法每次都会从数据库查询,
一级缓存的使用条件:
-
必须是相同的SQL和参数
-
必须是相同的会话
-
必须是相同的namespace 即同一个mapper
-
必须是相同的statement 即同一个mapper 接口中的同一个方法
-
查询语句中间没有执行session.clearCache() 方法
-
查询语句中间没有执行 insert update delete 方法(无论变动记录是否与 缓存数据有无关系)
5.3.2 一级缓存源码分析
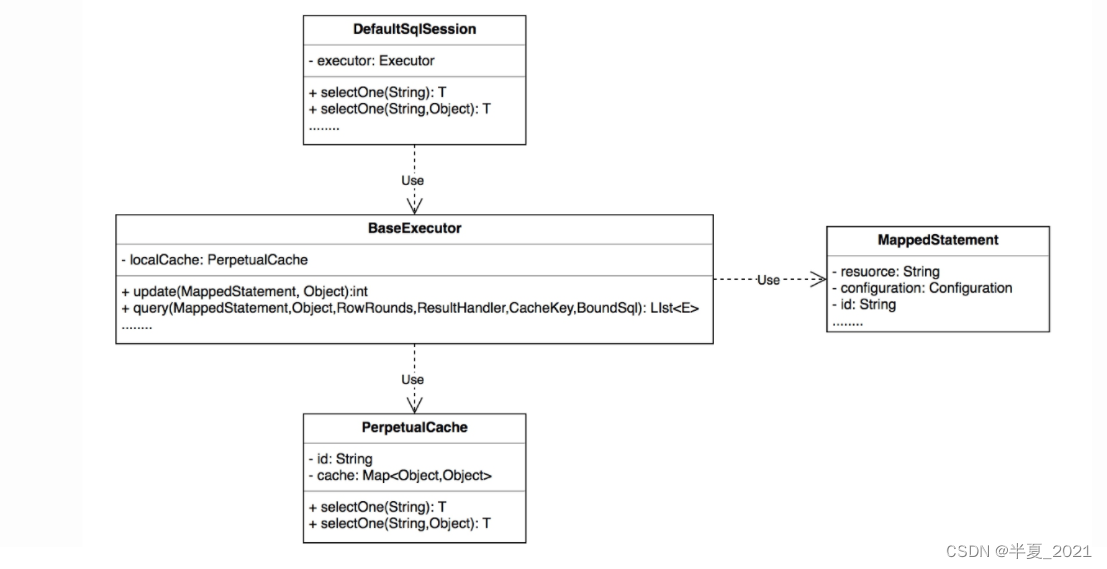
一级缓存的逻辑最终调用BaseExecutor执行器里面。当会话接收到一个查询请求时,会交给执行器的query方法执行,通过CacheKey的hashCode+checkNum + statementId + sql+ 参数等参数组成一个缓存key, 基于这个key去PerpetualCache 中查找对应的缓存值,如果有主直接返回。没有就会查询数据库,然后在填充缓存。
调试方法的Mapper.xml 如下:
<select id="selectUserList" parameterType="UserInfo" resultMap="userResultMap" flushCache="true">
SELECT
id,user_name,sex,birthday,address
FROM
t_user
<where>
<if test="userName!=null and userName !=''">
and user_name = #{userName}
</if>
<if test="sex!=null and sex !=''">
and sex = #{sex}
</if>
<if test="birthday!=null and birthday !=''">
and birthday = #{birthday}
</if>
<if test="address!=null and address !=''">
and address = #{address}
</if>
</where>
</select>
>mapper.mapper.selectList(UserInfo)
>org.apache.ibatis.session.defaults.DefaultSqlSession#selectList()
//statement: com.xa02.mapper.UserMapper.selectUserById
// parameter : 1
@Override
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
此时的执行器 是CacheExecutor,用的是装饰器模式
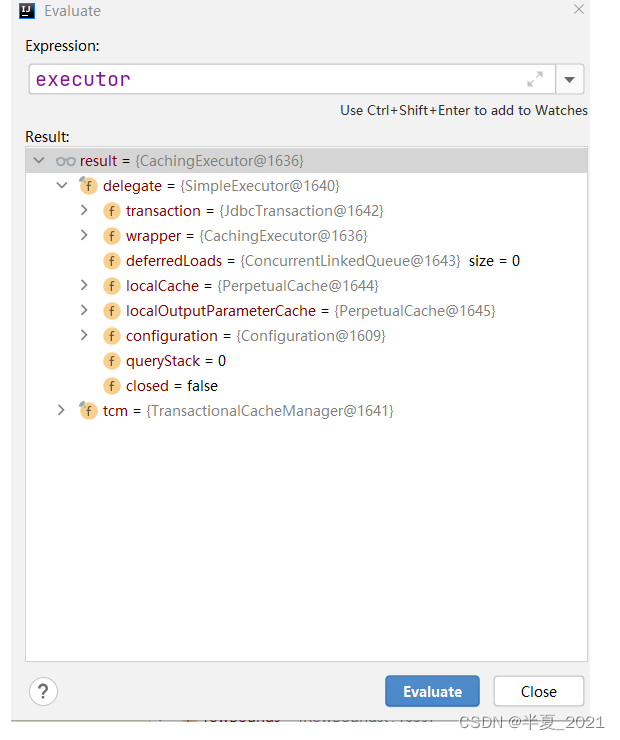
即 executor = CacheingExecutor(SimpleExecutor)
>org.apache.ibatis.executor.CachingExecutor#query()
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 创建缓存的key
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
此方法由两个任务
1.创建cachekey
2.从数据库中查询数据,并存储到缓存中
创建cachekey
CacheKey 类中的属性:
public class CacheKey implements Cloneable, Serializable {
public static final CacheKey NULL_CACHE_KEY = new NullCacheKey();
private static final int DEFAULT_MULTIPLYER = 37;
private static final int DEFAULT_HASHCODE = 17;
private final int multiplier;
private int hashcode;//CacheKey 的hashCode,初始值是17
private long checksum;//校验和
private int count;
// 8/21/2017 - Sonarlint flags this as needing to be marked transient. While true if content is not serializable, this is not always true and thus should not be marked transient.
private List<Object> updateList;// 由该集合中的所有对象共同决定两个cacheKey是否相同
// 此时的 delegate = SimpleExecutor
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
return delegate.createCacheKey(ms, parameterObject, rowBounds, boundSql);
}
# org.apache.ibatis.executor.SimpleExecutor#createCacheKey()
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
CacheKey cacheKey = new CacheKey();
// statementId其实就是select语句标签中的的id,如果两条select的id不同,那么必定不会命中。
// statementId:com.xa02.mapper.UserMapper.selectUserList
cacheKey.update(ms.getId());
// 这里的分页指的是mybatis自带的分页功能,它是查询出来数据库的所有数据到本地进行的一个物理分页。而不是从数据库获取分页之后的结果。不推荐使用。
cacheKey.update(rowBounds.getOffset());//默认为0
cacheKey.update(rowBounds.getLimit()); // 默认为 Integer.MAX_VALUE 即:-1355182933
cacheKey.update(boundSql.getSql())// SQL 语句 ,其中可能包含 ? 占位符
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);// 传入sql 每个参数的值
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId()); //获取Environmentid ,在mybatis全局文件中有配置
}
//-529818025:1137442865:com.xa02.mapper.UserMapper.selectUserById:0:2147483647:SELECT
id,user_name,sex,birthday,address
FROM
t_user where id = ?:1:mysql_jdbc2
return cacheKey;
}
此时的CacheKey
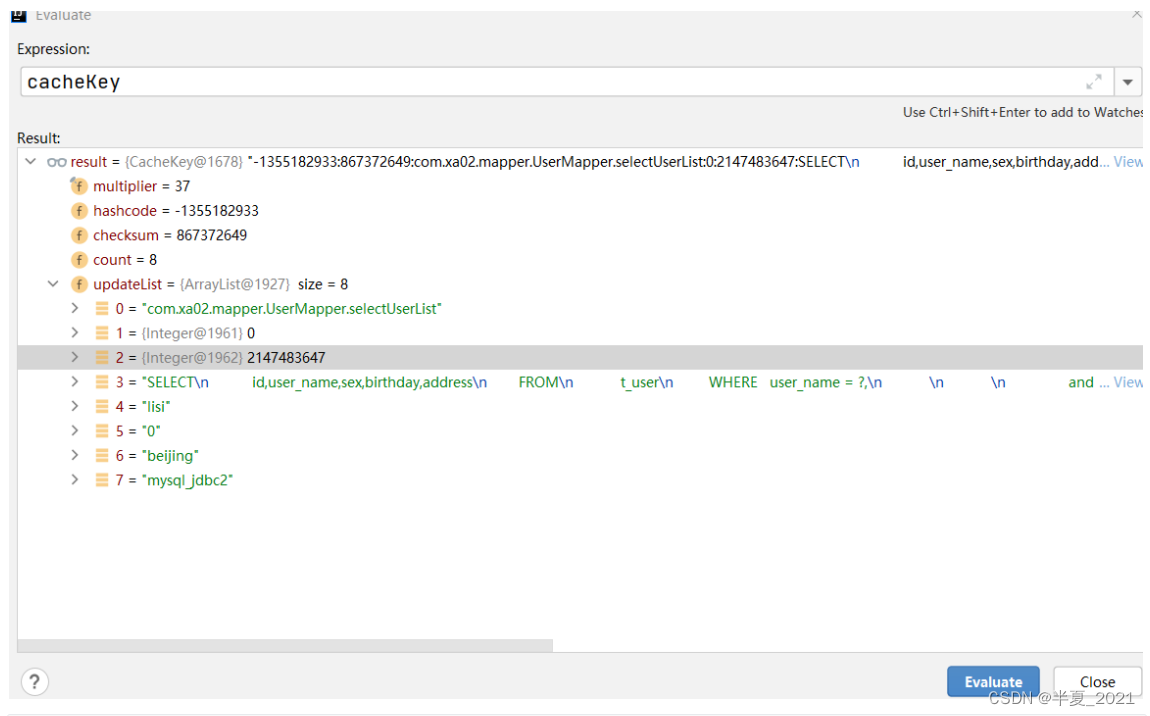
-1355182933:867372649:com.xa02.mapper.UserMapper.selectUserList:0:2147483647:SELECT
id,user_name,sex,birthday,address
FROM
t_user
WHERE user_name = ?,
and sex = ?,
and address = ?,:lisi:0:beijing:mysql_jdbc2
上面的冒号是分隔符。
整个key的组成如下:
Cache key HashCode:Cache key 的checksum 校验和:statementid:offset:limit:sql语句:每个参数:environmentId
查询数据,并存储到缓存中
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
// 判断是否开启了二级缓存,如果开启了,会执行 if 里的代码
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// delegate = SimpleExcutor 去数据库中查询数据
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 查询完成后放到缓存中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 调用 BaseExecutor 下的query方法
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
>org.apache.ibatis.BaseExecutor#query()
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//
// isFlushCacheRequired 是否刷新配置,清除hashMap的缓存
// 刷新缓存的时候需要检查有没有正在查询的操作
// queryStack 是全局变量,在高并发的时候会出问题
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
// 为什么需要做 ++,为了 安全。
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
>org.apache.ibatis.executor#queryFromDatabase
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// localCache = PerpetualCache
// 1. 把key存入缓存,value放一个占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//数据库查询数据 2. 与数据库交互
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
//3. 如果第2步出了什么异常,把第1步存入的key删除
localCache.removeObject(key);
}
//4.把结果放到本地缓存中
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
>org.apache.ibatis.cache.impl.PerpetualCache#putObject
public class PerpetualCache implements Cache {
private final String id;
private Map<Object, Object> cache = new HashMap<Object, Object>();
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
return getId().hashCode();
}
}
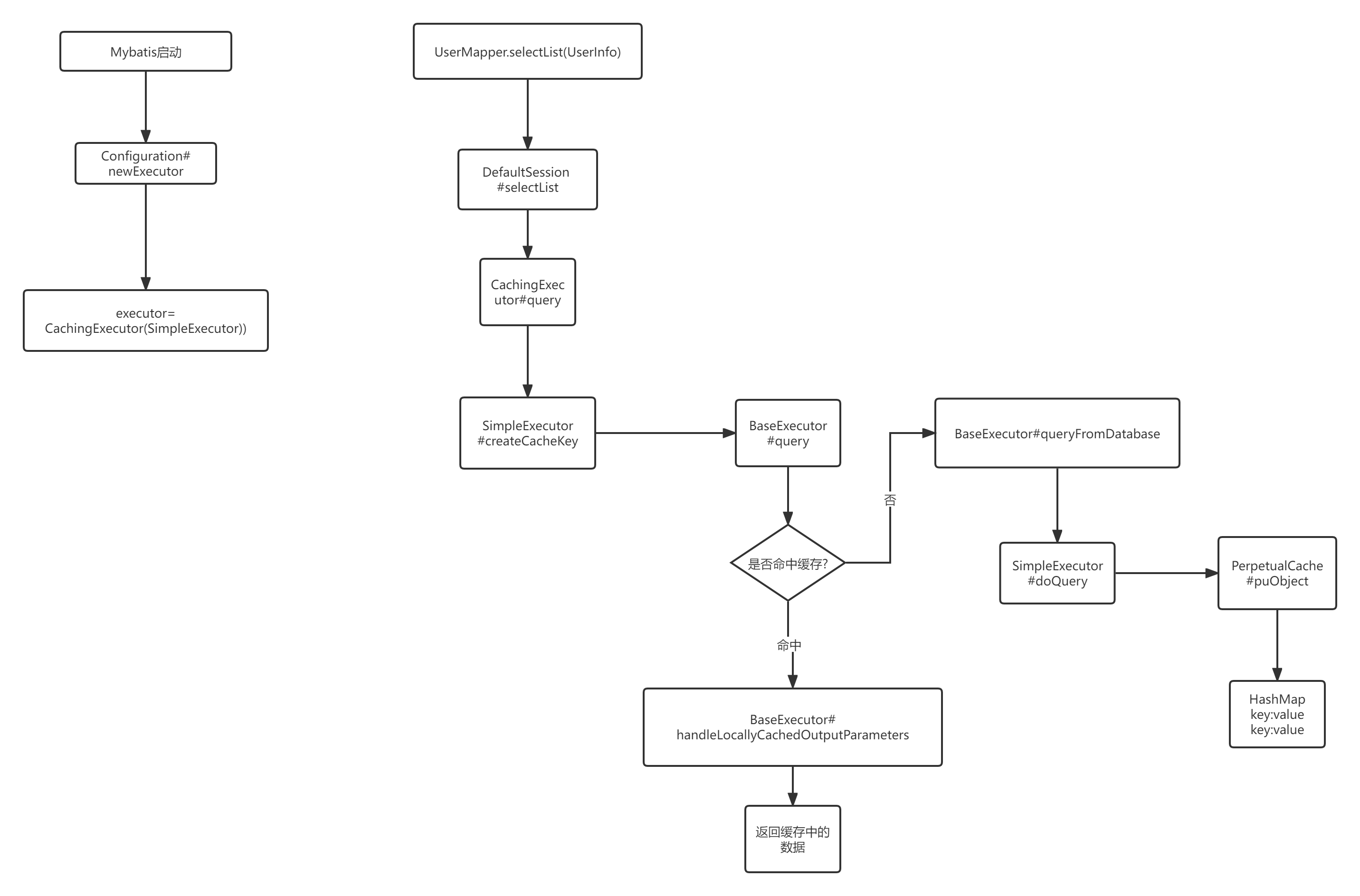
通过上图得知,最终的缓存存储在一个HashMap中。
触发清空缓存
- 手动调用 clearCache
- 执行提交回滚
- 执行 update
- 配置 flushCache=true
- 缓存作用域为 Statement
下面我们看 flushCache=true的参数
- 在执行 BaseExecutor # query 方法时,会判断 flushCache有没有设置,如果设置,会清空 本地缓存。
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
......
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
......
return list;
}
-
当执行update方法时,直接调用了 clearLocalCache() 方法
同时 insert 和 update 方法也调用了 update方法。
@Override
public int insert(String statement, Object parameter) {
return update(statement, parameter);
}
@Override
public int delete(String statement) {
return update(statement, null);
}
BaseExecutor#update
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
注意:clearLocalCache 不是清空某条具体数据,而清当前会话下所有一级缓存数据。
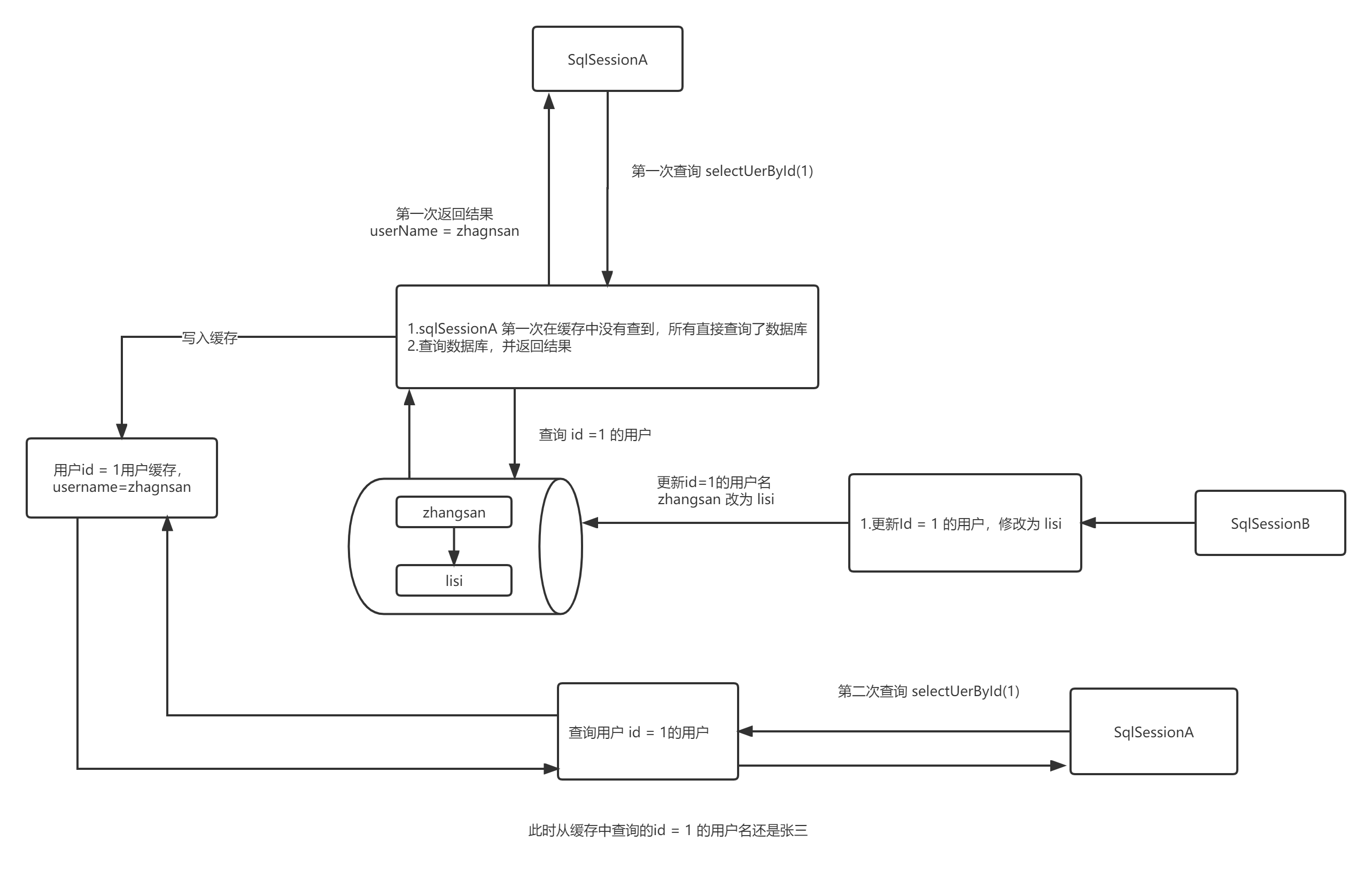
一级缓存存在的问题
一级缓存存在脏数据,因为无法感知其他sqlSession修改其数据。
比如SqlSessionA 执行 selectUserById(1) 两次,按照一级缓存的规则,第二次查询selectUserById() 不会查询数据库。假如在 sqlSessionA 两次查询之间
使用SqlSessionB 执行了 对用户ID=1的数据,此时 第二次执行selectUserById(1) 时,查到的就是脏数据。测试代码如下:
@Test
public void selectUserById(){
SqlSession sqlSessionA = sqlSessionFactory.openSession();
SqlSession sqlSessionB = sqlSessionFactory.openSession();
try{
UserMapper mapperA = sqlSessionA.getMapper(UserMapper.class);
UserMapper mapperB = sqlSessionB.getMapper(UserMapper.class);
UserInfo userInfo = new UserInfo();
userInfo.setId(1L);
List<UserInfo> userInfoList = mapperA.selectUserList(userInfo);
System.out.println("第一次查询......"+userInfoList);
UserInfo updateUserInfo = new UserInfo();
updateUserInfo.setId(1L);
updateUserInfo.setUserName("lisi");
mapperB.updateUser(updateUserInfo);
sqlSessionB.commit();
Thread.sleep(20000);
List<UserInfo> userInfoList2 =mapperA.selectUserList(userInfo);
System.out.println("第二次查询......"+userInfoList2);
} catch (InterruptedException e) {
e.printStackTrace();
} finally{
sqlSessionA.close();
sqlSessionB.close();
}
}
日志如下:
[com.xa02.mapper.UserMapper.selectUserList]-==> Preparing: SELECT id,user_name,sex,birthday,address FROM t_user WHERE id = ?
[com.xa02.mapper.UserMapper.selectUserList]-==> Parameters: 1(Long)
[com.xa02.mapper.UserMapper.selectUserList]-<== Total: 1
第一次查询结果......[UserInfo{id=1, userName='zhangsan', sex='0', birthday=Tue Nov 17 15:07:08 CST 2020, address='上海市', orderInfoList=null}]
[org.apache.ibatis.transaction.jdbc.JdbcTransaction]-Opening JDBC Connection
[org.apache.ibatis.datasource.pooled.PooledDataSource]-Created connection 341853399.
[org.apache.ibatis.transaction.jdbc.JdbcTransaction]-Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@146044d7]
[com.xa02.mapper.UserMapper.updateUser]-==> Preparing: update t_user SET user_name = ? where id = ?
[com.xa02.mapper.UserMapper.updateUser]-==> Parameters: lisi(String), 1(Long)
[com.xa02.mapper.UserMapper.updateUser]-<== Updates: 1
[org.apache.ibatis.transaction.jdbc.JdbcTransaction]-Committing JDBC Connection [com.mysql.jdbc.JDBC4Connection@146044d7]
第二次查询结果.....[UserInfo{id=1, userName='zhangsan', sex='0', birthday=Tue Nov 17 15:07:08 CST 2020, address='上海市', orderInfoList=null}]
从日志可以看到,在使用sqlSessionA 查询一次后,用sqlSessionB对id=1的用户名更新为lisi,但是第二次用sqlSessionA查询时,没有打印sql,即从缓存中获取的,取到的是修改前的记录,所以存在脏数据。
5.2 二级缓存
一级缓存的共享范围是SqlSession内部,如果多个SqlSesison之间需要共享呢?这时需要 用到二级缓存,二级缓存存在于SqlSessionFactory的生命周期;缓存以namespace为单位,不同的namespace下的操作互不影响。
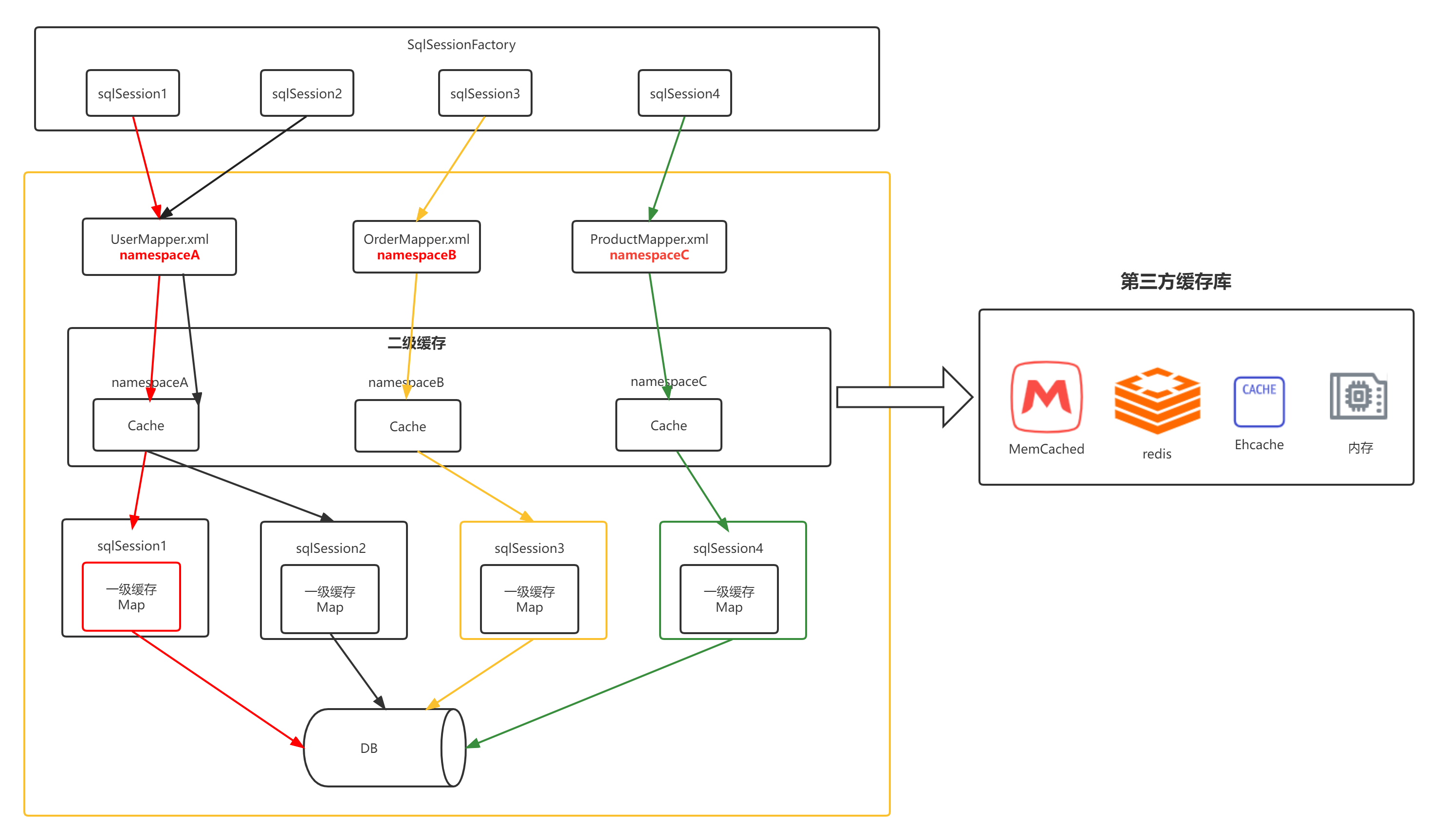
当开启缓存后,数据的查询执行流程是 二级缓存–> 一级缓存 --> 数据库。
5.2.1 二级缓存的配置
Mybatis 对二级缓存的粒度支持到每一个查询语句,在Mapper 的配置中,为 每个Mapper分配了一个Cache对象,这并不表示我们在mapper定义的查询语句
语句都会存放到缓存中,必须指定Mapper中的某条语句是否支持缓存。
在 节点中配置useCache=“true”,Mapper才会对此Select的查询支持缓存特性(默认useCache为true),否则,不会对此Select查询经过Cache缓存。
要使用二级缓存,需要完成以下的配置。
1.在myatis全局配置文件中开启二级缓存
<!-- 开启二级缓存总开关 -->
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
2.在UserMapper映射文件中,需要配置 cache 或者 caceh-ref
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xa02.mapper.UserMapper">
<!-- 开启本mapper下的namespace的二级缓存,默认使用的是mybatis提供的PerpetualCache -->
<cache></cache>
</mapper>
参数如下:
-
type: cache 的使用类型,默认是 PerpetualCache,
-
eviction: 定义收回的策略,常见的FIFO,LRU 等
- LRU 最近最少使用的:移除最长时间不被使用的对象,这是默认值
- FIFO 先进先出,按对象缓存的顺序来移除他们
- SOFT 软引用:移除基于垃圾回收状态和软引用规则的对象
- WEAK 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象
-
flushInterval: 配置一定时间自动刷新缓存,单位是毫秒。默认情况不设置,即没有刷新间隔,缓存仅仅在调用语句时刷新。
-
size: 最多缓存对象的个数。默认1024
-
readOnly: 是否只读,属性可以被设置为true 或 false。默认为false, 若配置可读写,则需要对应的实体类能够序列化。
-
blocking: 若缓存中找不到对应的key,是否会一直blocking,直到有对应的数据进入缓存。
cache-ref代表引用别的命名空间的Cache配置,两个命名空间的操作使用的是同一个Cache。
<cache-ref namespace=com.xa02.mapper.OrderMapper"/>
由于二级缓存的数据不一定都是存储到内存中,它的存储介质多种多样,比如说存储到文件系统中,所以需要给缓存的对象执行序列化。
如果该类存在父类,那么父类也要实现序列化
public class UserInfo implements Serializable {
private Long id;
private String userName;
private String sex;
private Date birthday;
private String address;
}
禁用二级缓存
默认二级缓存的粒度是Mapper级别的,但是如果在同一个Mapper文件中某个查询不想使用二级缓存的话,就需要对缓存的控制粒度更细。
在select标签中设置useCache=false,可以禁用当前select语句的二级缓存,即每次查询都是去数据库中查询,默认情况下是true,即该statement使用二级缓存。
<select id="selectUserById" parameterType="long" resultMap="userResultMap" useCache="false" >
SELECT
id,user_name,sex,birthday,address
FROM
t_user
where id = #{id}
</select>
刷新二级缓存
l 通过flushCache属性,可以控制select、insert、update、delete标签是否强制刷新缓存
l 默认设置
* 默认情况下如果是select语句,那么flushCache是false。
* 如果是insert、update、delete语句,那么flushCache是true。
l 默认配置解读
* 如果查询语句设置成true,那么每次查询都是去数据库查询,即意味着该查询的二级缓存失效。
* 如果增删改语句设置成false,即使用二级缓存,那么如果在数据库中修改了数据,而缓存数据还是原来的,这个时候就会出现脏读
flushCache设置如下:
<select id="selectUserById" parameterType="long" resultMap="userResultMap" useCache="false" flushCache="true">
SELECT
id,user_name,sex,birthday,address
FROM
t_user
where id = #{id}
</select>
二级缓存使用条件:
-
当会话提交或关闭之后才会填充二级缓存
-
必须是在同一个命名空间之下
-
必须是相同的statement 即同一个mapper 接口中的同一个方法
-
必须是相同的SQL语句和参数
-
如果readWrite=true ,实体对像必须实现Serializable 接口
二级缓存清除条件
-
xml中配置的update 不能清空 @CacheNamespace 中的缓存数据
-
只有修改会话提交之后 才会执行清空操作
-
任何一种增删改操作 都会清空整个namespace 中的缓存
5.2.2 二级缓存的测试
案例一
测试二级缓存效果,不关闭sqlSession,sqlSession1查询完数据后,sqlSession2相同的查询是否会从缓存中获取数据。
测试
@Test
public void selectUserById(){
SqlSession sqlSessionA = sqlSessionFactory.openSession();
SqlSession sqlSessionB = sqlSessionFactory.openSession();
UserMapper mapperA = sqlSessionA.getMapper(UserMapper.class);
UserMapper mapperB = sqlSessionB.getMapper(UserMapper.class);
UserInfo userInfo = new UserInfo();
userInfo.setId(1L);
// 第一次查询id = 1的用户
List<UserInfo> userInfoList = mapperA.selectUserList(userInfo);
System.out.println("first query:"+userInfoList);
// 第二次查询 id = 1 的用户
List<UserInfo> userInfoList2 =mapperB.selectUserList(userInfo);
System.out.println("second qyery: "+userInfoList2);
}
输出结果:
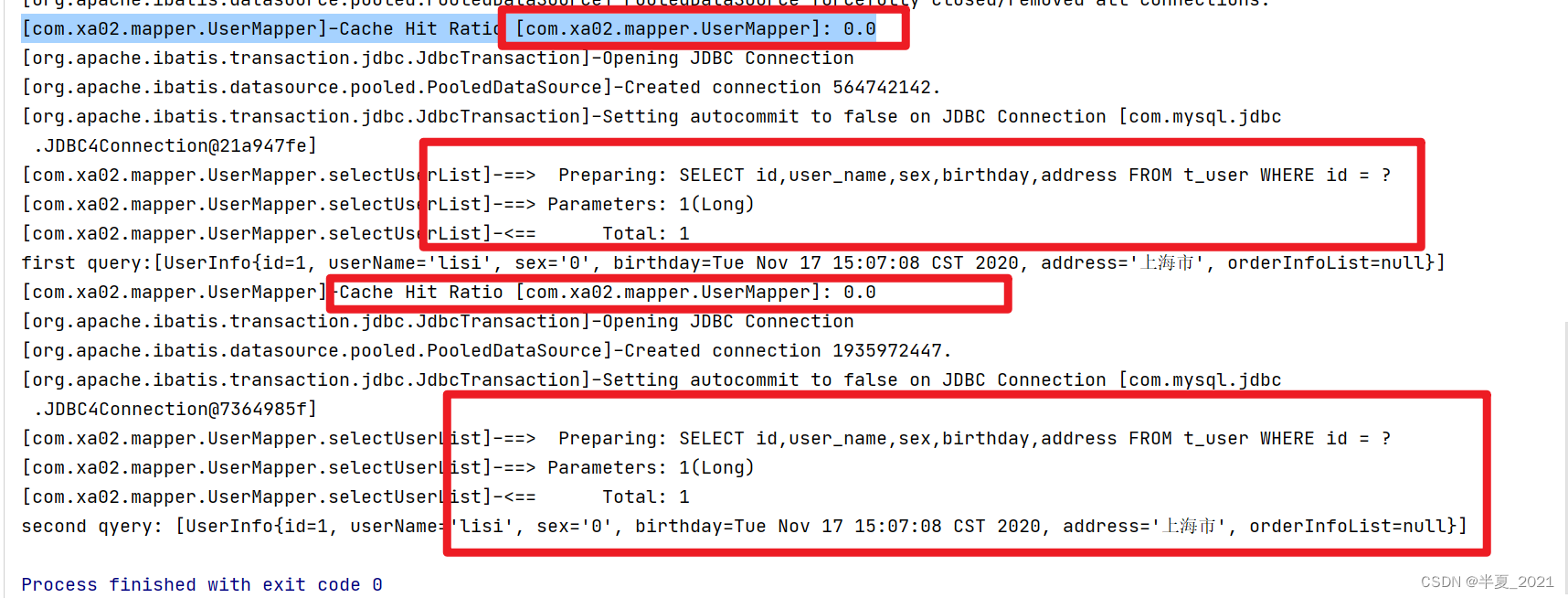
Cache Hit Radio : 缓存命中率
第一次缓存中没有记录,则命中率 0.0;
第二次缓存中没有记录,则命中率 0.0
结论: 如果sqlSession 不执行 commit 或者 close ,SqlSession 不会保存查询数据到二级缓存中,所以上面才会看到两次命中率都是0。
案例2
查询完成后,sqlSession 关闭
@Test
public void selectUserById(){
SqlSession sqlSessionA = sqlSessionFactory.openSession();
SqlSession sqlSessionB = sqlSessionFactory.openSession();
UserMapper mapperA = sqlSessionA.getMapper(UserMapper.class);
UserMapper mapperB = sqlSessionB.getMapper(UserMapper.class);
UserInfo userInfo = new UserInfo();
userInfo.setId(1L);
List<UserInfo> userInfoList = mapperA.selectUserList(userInfo);
System.out.println("first query:"+userInfoList);
sqlSessionA.close();
List<UserInfo> userInfoList2 =mapperB.selectUserList(userInfo);
System.out.println("second qyery: "+userInfoList2);
sqlSessionB.close();
}
SQL输出结果:
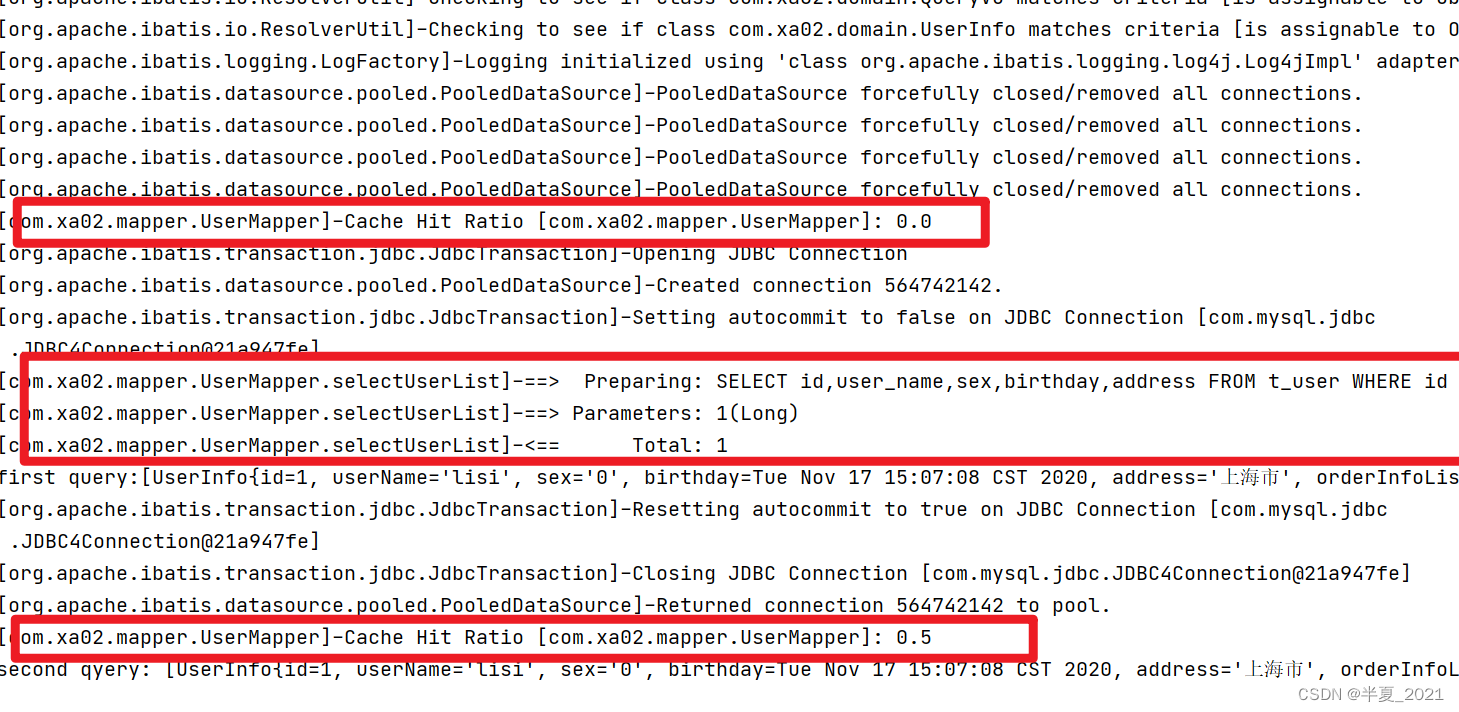
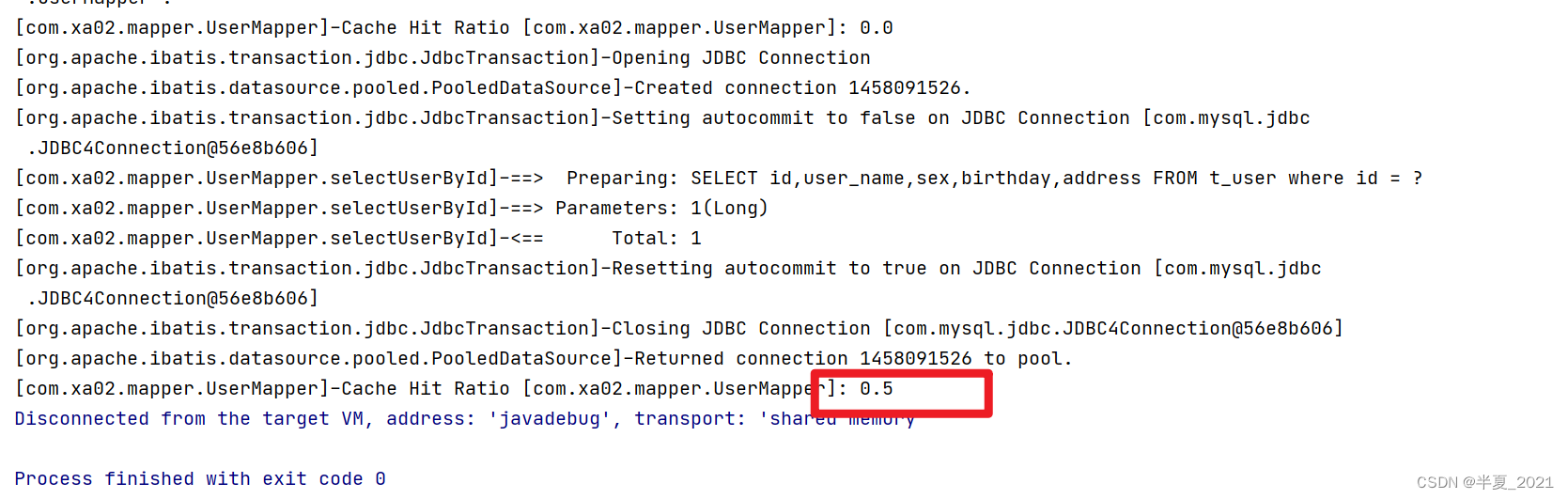
第一次缓存中没有记录,则命中率 0.0;
第二次缓存中没有记录,则命中率 0.5,因为执行了两次,一次命中,所以是 50%。
结论: 如果 sqlSession 执行 commit 或者 close ,SqlSessionA查询数据完成后会加入到缓存,然后sqlSessionB 会从缓存中查询。
案例3
测试 update 操作是否会清空namespace 下的二级缓存。
@Test
public void selectUserById(){
SqlSession sqlSessionA = sqlSessionFactory.openSession();
SqlSession sqlSessionB = sqlSessionFactory.openSession();
SqlSession sqlSessionC = sqlSessionFactory.openSession();
UserMapper mapperA = sqlSessionA.getMapper(UserMapper.class);
UserMapper mapperB = sqlSessionB.getMapper(UserMapper.class);
UserMapper mapperC = sqlSessionC.getMapper(UserMapper.class);
UserInfo userInfo = new UserInfo();
userInfo.setId(1L);
List<UserInfo> userInfoList = mapperA.selectUserList(userInfo);
sqlSessionA.commit();
System.out.println("first query ......"+userInfoList);
UserInfo updateUserInfo = new UserInfo();
updateUserInfo.setId(1L);
updateUserInfo.setUserName("Jack");
mapperB.updateUser(updateUserInfo);
sqlSessionB.commit();
List<UserInfo> userInfoList2 =mapperC.selectUserList(userInfo);
sqlSessionC.commit();
System.out.println("second query ......"+userInfoList2);
}
SQL输出结果:
根据SQL分析,确实是清空了二级缓存了。
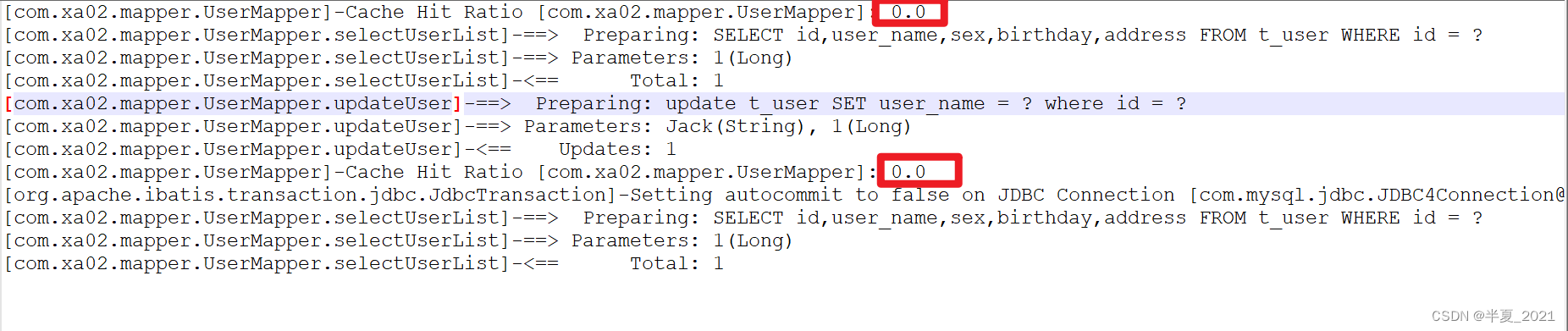
案例4
验证多表查询中,牵涉到多个namespace ,比如有一个用户表,订单表,一个用户有多个订单。测试如下:
1.查询id =1 的用户 的订单信息
2.更新id = 1的用户的某一条订单信息
3.再次查询id = 1的用户的订单信息
@Test
public void selectUserById(){
SqlSession sqlSessionA = sqlSessionFactory.openSession(true);
SqlSession sqlSessionB = sqlSessionFactory.openSession(true);
SqlSession sqlSessionC = sqlSessionFactory.openSession(true);
UserMapper userMapperA = sqlSessionA.getMapper(UserMapper.class);
OrderMapper orderMapper = sqlSessionB.getMapper(OrderMapper.class);
UserMapper userMapperC = sqlSessionC.getMapper(UserMapper.class);
UserInfo userInfo = new UserInfo();
userInfo.setId(1L);
// 第一次查询用户 id = 1 用户的所有订单
List<UserInfo> userInfoList = userMapperA.selectOrderListByUserId(1L);
sqlSessionA.close();
System.out.println("first query ......"+userInfoList);
// 更新 订单 id = 6 的订单
OrderInfo orderInfo = new OrderInfo();
orderInfo.setId(6L);
orderInfo.setAmount(new BigDecimal(66666));
orderMapper.updateOrder(orderInfo);
sqlSessionB.commit();
// 第二次查询用户id = 1 的所有订单
List<UserInfo> userInfoList2 =userMapperC.selectOrderListByUserId(1L);
sqlSessionC.close();
System.out.println("second query ......"+userInfoList2);
}
测试结果:
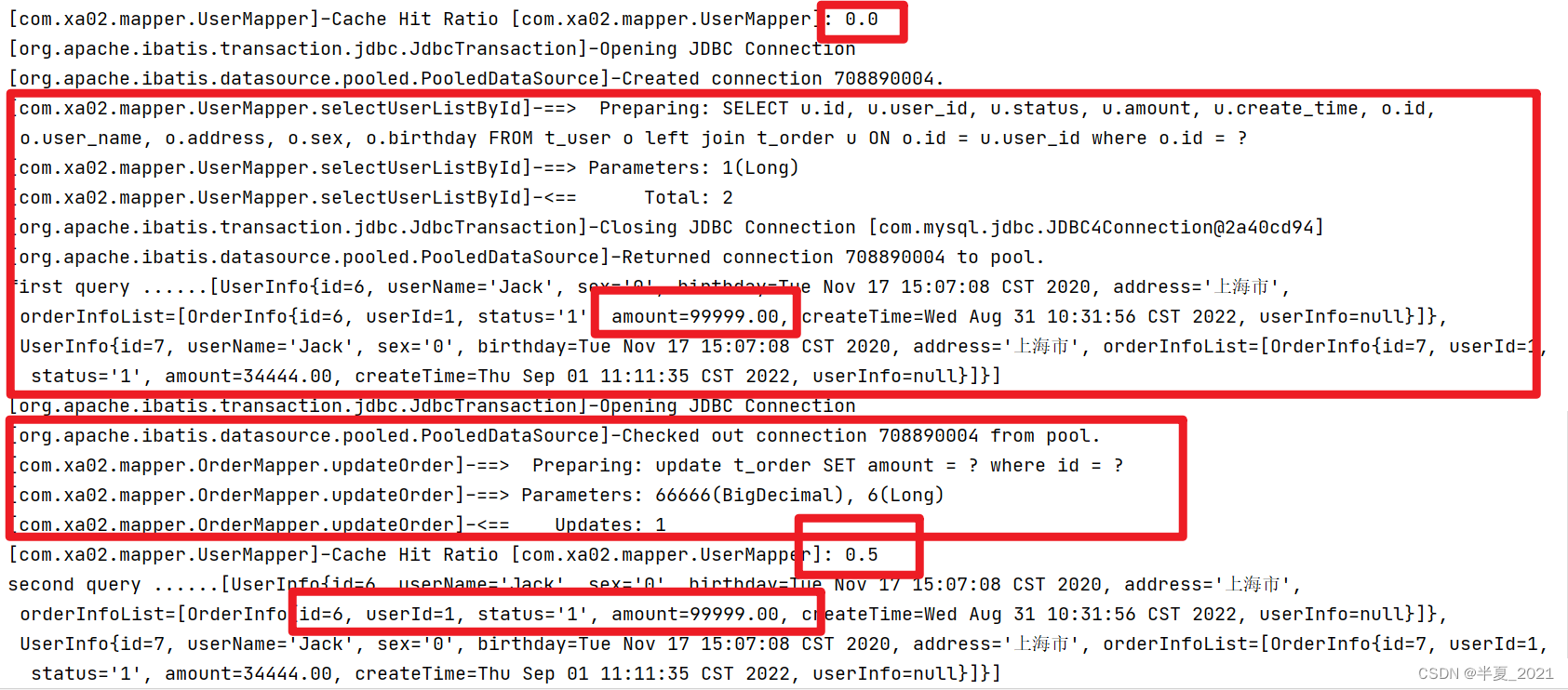
当sqlSessionA 通过 selectOrderListByUserId 查询id=1用户的订单列表,二级缓存失效。保存到 UserMapper 的namespace 下的cache,我们从上面能看到
查询到 订单Id= 6 的 金额是 99999.00
接下来我们使用sqlSessionB 去更新 OrderMapper 的 updateOrder(6L),更新orderId = 6 的订单金额为 66666。
然后使用sqlSessionC 通过 selectOrderListByUserId 查询id=1用户的订单列表,此时会从缓存中渠道,得到的订单id = 6 的订单金额还是 99999.00.
所以第二次查询到的是脏数据。
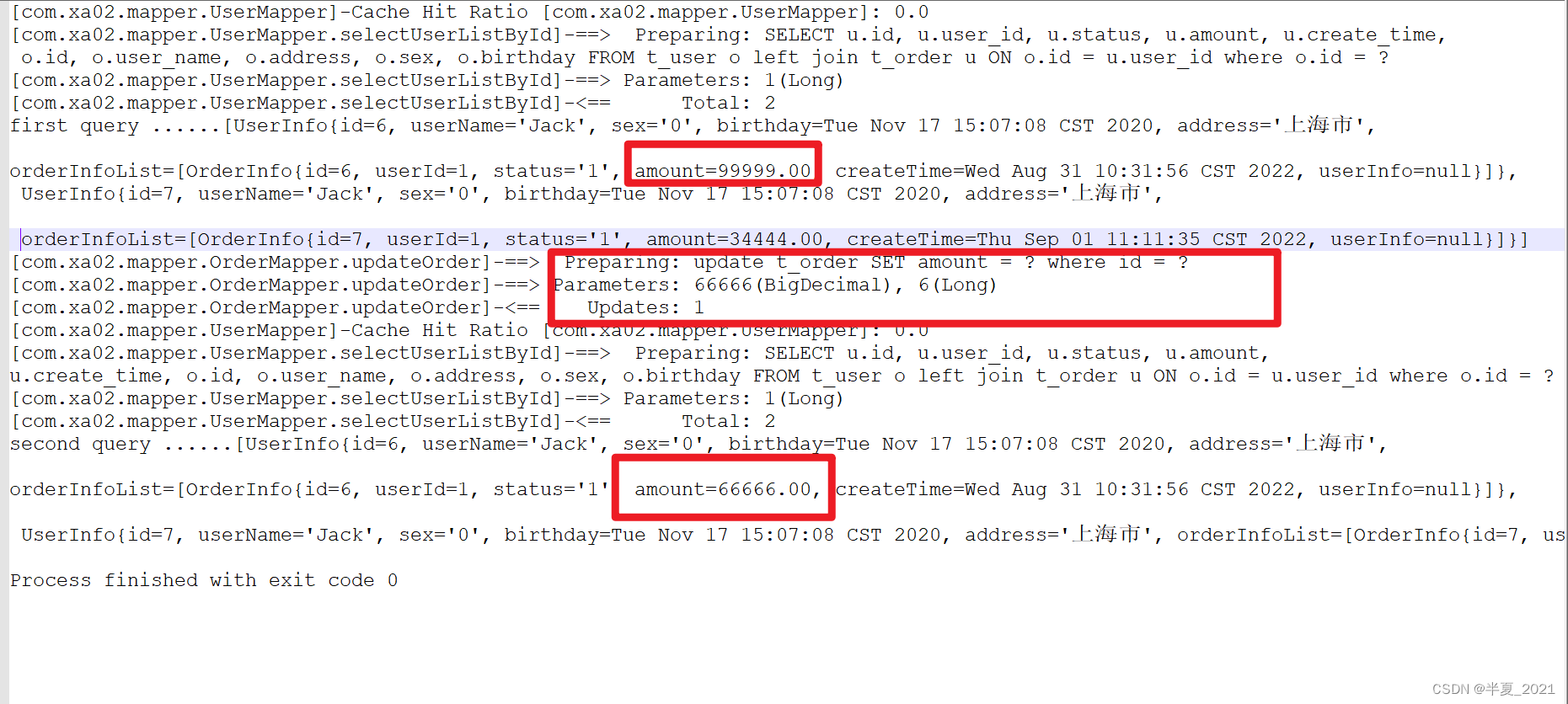
案例5
为了解决案例4的问题,我们使用cache ref ,让 OrderMapper 引用 UserMapper的命名空间,这样这两个映射文件对应的SQL操作都使用了同一块缓存。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xa02.mapper.OrderMapper">
<cache-ref namespace="com.xa02.mapper.UserMapper"/>
<update id="updateOrder" parameterType="OrderInfo">
update t_order
<set>
<if test="amount !=null">
amount = #{amount},
</if>
</set>
where id = #{id}
</update>
</mapper>
测试结果:
5.2.3 二级缓存的源码分析
源码模块主要分为两个部分: 二级缓存的创建和二级缓存的使用
5.2.3.1 二级缓存的创建
整个的创建流程如下:
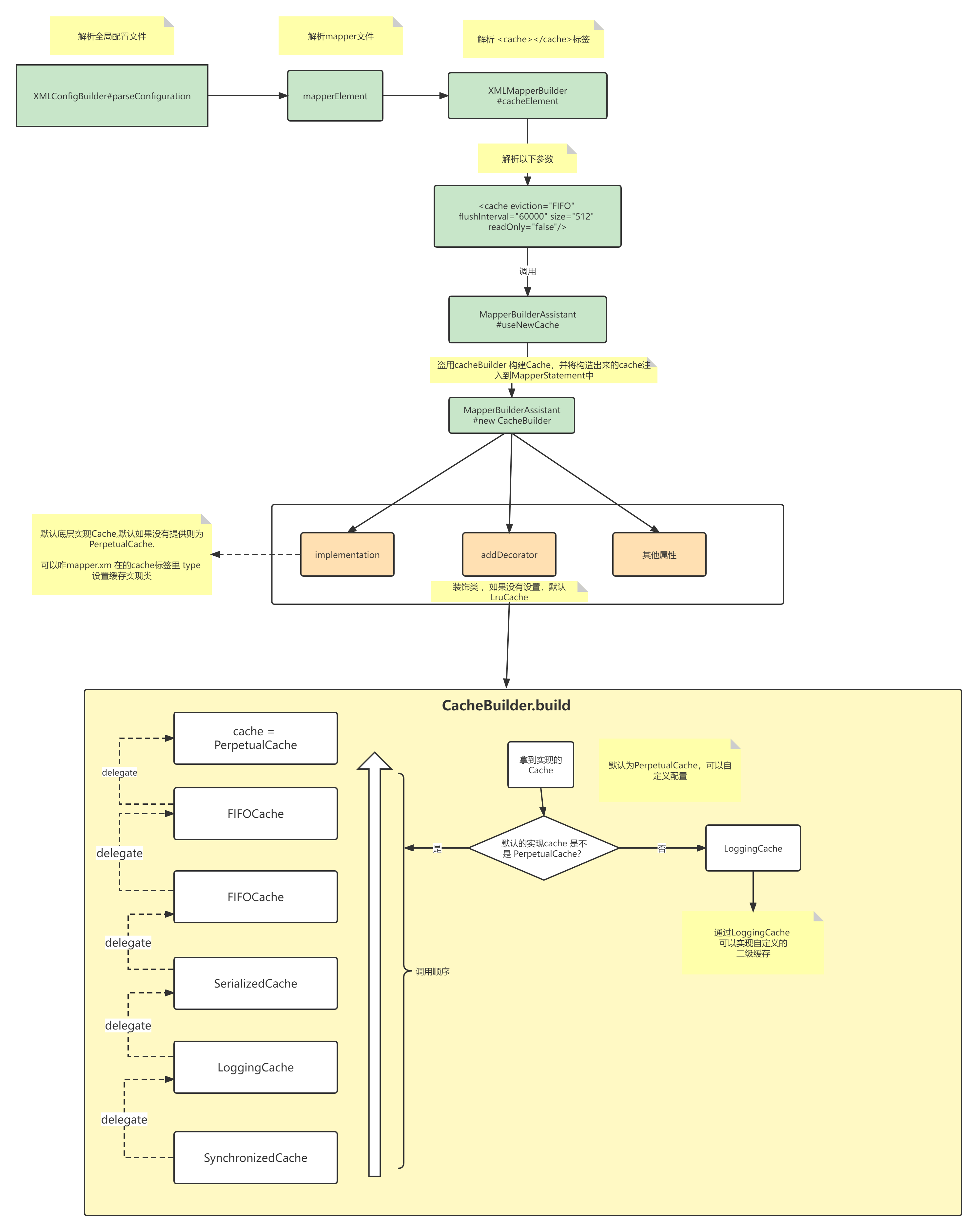
>org.apache.ibatis.builder.xml.XMLMapperBuilder#configurationElement
// 二级缓存 namespace 之间的引用
cacheRefElement(context.evalNode("cache-ref"));
// 二级缓存的开启
cacheElement(context.evalNode("cache"));
>org.apache.ibatis.builder.MapperBuilderAssistant#useNewCache
Cache cache = new CacheBuilder(currentNamespace)
// cache 最终的实现类是 PerpetualCache,可以自定义
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
// 默认使用 LruCache,可以自定义
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
>org.apache.ibatis.mapping.CacheBuilder#build
public Cache build() {
// 设置默认cache 实现类
setDefaultImplementations();
// 初始化默认cache实现类,默认是 PerpetualCache
Cache cache = newBaseCacheInstance(implementation, id);
setCacheProperties(cache);
// issue #352, do not apply decorators to custom caches
// 判断做cache实现类是否是PerpetualCache
if (PerpetualCache.class.equals(cache.getClass())) {
for (Class<? extends Cache> decorator : decorators) {
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache);
}
// 最终实现的装饰类如下:> SynchronizedCache -> LoggingCache -> SerializedCache -> ScheduledCache->FifoCache -> PerpetualCache。
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
cache = new LoggingCache(cache);
}
return cache;
}
此时的Cache 是 装饰器模式 + 责任链模式
SynchronizedCache -> LoggingCache -> SerializedCache -> ScheduledCache->FifoCache -> PerpetualCache。
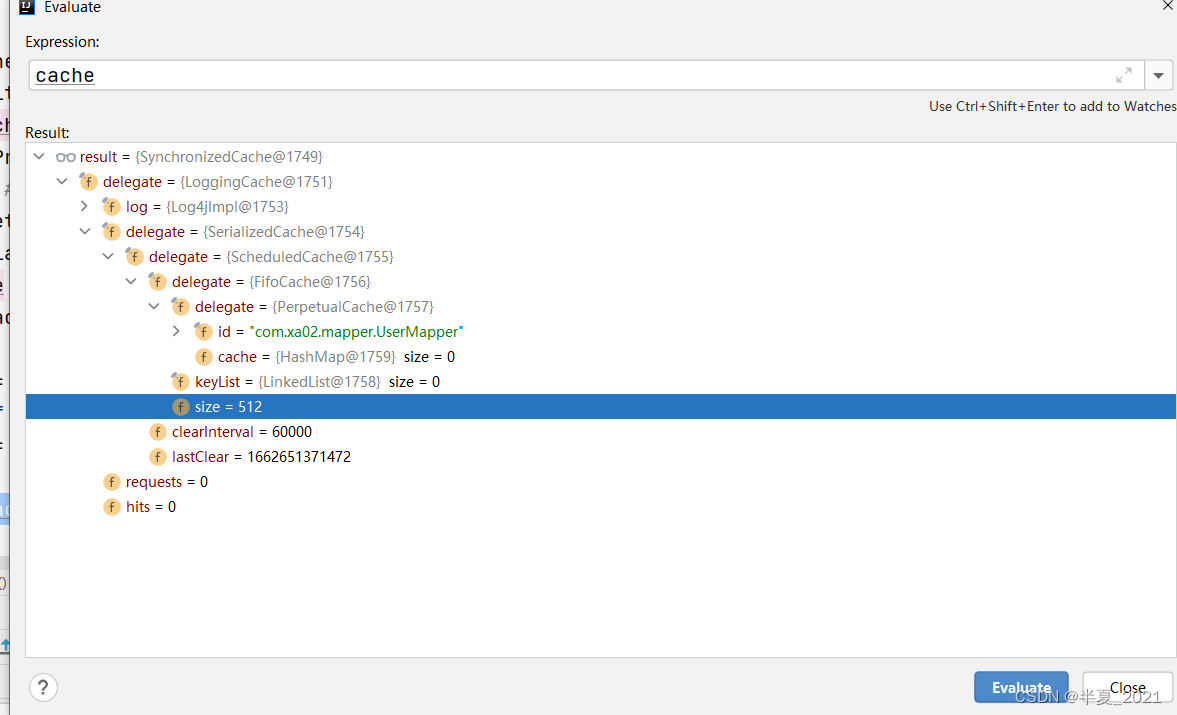

在上面的类图中,只有 PerpetualCache 是具体的实现类,其他都是装饰类。装饰类的特点都实现了Cache接口,持有 一个 Cache 成员变量。
按功能分类,缓存装饰器类可以分为以下几类:
- 同步装饰器: 为缓存增加同步功能,SynchronizedCache。
- 日志装饰器: 为缓存增加日志功能,用于记录缓存的命中率,如果开了DEBUG模式,则会出书命中率。LoggingCache。
- 清理装饰器: 为缓存中增加各种清理功能,如 LruCache, FifoCache,WeakCache等
- 阻塞装饰器:为缓存增加阻塞的功能,如BlockingCache。
- 定时清理装饰器: 为缓存添加定时清理的功能,如ScheduledCache
- 序列化装饰器:为缓存增加序列化功能,如SerializedCache
- 事务装饰器: 用于支持事务操作,如 TransactionalCache
最基础的缓存类(PerpetualCache): 只有 PerpetualCache 提供了Cache接口的基本实现,PerpetualCache在装饰器模式中扮演了ConcreteComponent,底层
实现比较简单,使用了HashMap 来缓存。
5.2.3.2 二级缓存的保存
源码分析还要从CachingExecutor的query 开始,具体为什么会执行这个类,可以参考 一级缓存的源码分析
>org.apache.ibatis.executor.CachingExecutor#query
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 每个 Mapper如果打开了缓存,都有自己的一个缓存空间。
// 二级缓存的装饰 Cache类 SynchronizedCache -> LoggingCache -> SerializedCache -> LruCache -> PerpetualCache。
Cache cache = ms.getCache();
if (cache != null) {
// 判断是否配置了flushCache=true,若配置了清空暂存区
// 在 <select> 标签中也可以配置flushCache属性来设置是否查询前要刷新缓存,默认增删改刷新缓存,查询不刷新缓存。
flushCacheIfRequired(ms);
// 判断这个mapper 是否开启了二级缓存
if (ms.isUseCache() && resultHandler == null) {
// 主要用来处理存储过程的
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
// 查询二级缓存
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {//若为空查询数据库并将数据填充到暂存区
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 一级缓存就在下面的方法调用的
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
Mybatis在查询数据时,首先判断这个mapper有没有开启二级缓存,如果开启了,则先从二级缓存中获取,如果二级缓存中没有,
1.首先判断是否要刷新缓存
flushCacheIfRequired(ms);
在默认情况下,select 语句不会刷新缓存,insert/update/delete 会刷新缓存,进入该方法,代码如下所示:
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
// 如果xml中配置了 flushCache = true,则会情况缓存
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}
org.apache.ibatis.cache.decorators.TransactionalCache#clear
@Override
public void clear() {
clearOnCommit = true;
// 清空暂存区
entriesToAddOnCommit.clear();
}
CachingExecutor 持有了一个 缓存类 TransactionalCacheManager 事务缓存类。
TransactionalCacheManager 是一个缓存事务管理器,内部用一个Map来记录Cache对象和对应事务TransactionalCache缓存对象。
内部事务提交、回滚等操作实际都是调用TransactionalCache。
final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<Cache, TransactionalCache>();
- key: cache 对象,每个 MappedStatement一个cache对象,即 一个Mapper.xml对应 一个Cache对象.
- value: 用 TransactionalCache 包裹的 cache对象
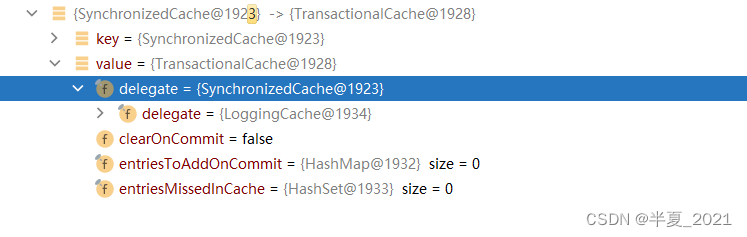
TransactionalCache 比其他 Cache 对象多出了 2 个方法:commit () 和 rollback ()。TransactionalCache 对象内部存在暂存区,所有对缓存对象的写操作都不会
直接作用于缓存对象,而是被保存在暂存区,只有调用 TransactionalCache 的 commit () 方法时,所有的更新操作才会真正同步到缓存对象中。
2.继续 CachingExecutor#query往下走
从二级缓存中获取数据
List<E> list = (List<E>) tcm.getObject(cache, key);
org.apache.ibatis.cache.decorators.TransactionalCache#getObject
@Override
public Object getObject(Object key) {
// issue #116
Object object = delegate.getObject(key);
if (object == null) {
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}
此时的delegate = SynchronizedCache -> LoggingCache -> SerializedCache -> ScheduledCache->FifoCache -> PerpetualCache。最终到PerpetualCache。
如果没有查到,会把key加入到 entriesMissedInCache 集合中,主要功能是统计命中率。
继续 CachingExecutor#query往下走
if (list == null) {
//若为空查询数据库并将数据填充到暂存区
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
上面方法首先从一级缓存—>数据库查询,然后加入二级缓存中。
org.apache.ibatis.cache.decorators.TransactionalCache#putObject
@Override
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}
// 事务提交前,把从数据库查询出的结果缓存到该集合中
private final Map<Object, Object> entriesToAddOnCommit;
到现在为止,查询的数据放到 二级缓存中的暂存区中,并没有真正的保存到内存中或则第三方存储中。
那么 ,什么时候才会真正的存储到内存或者第三方存储中。
只有 SqlSession 调用 close 方法或 commit方法 缓存才会生效:
源码调用栈如下:
> org.apache.ibatis.executor.CachingExecutor#commit
@Override
public void commit(boolean required) throws SQLException {
// BaseExecutor#commit
delegate.commit(required);
tcm.commit();
}
tcm.commit 最终会调用 TrancationalCache的commit方法
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
// 把暂存区的数据委托给包装后的Cache类,进行 putObject操作
flushPendingEntries();
//清空暂存区
reset();
}
这里的清理标志 ,是在上面方法 flushCacheIfRequired 中设置的标志位,真正的清理 cache是放到这里进行的。具体清理的职责委托给了包装的cache类
flushPendingEntries 方法是把暂存区的缓存数据
>org.apache.ibatis.cache.decorators.TransactionalCache#flushPendingEntries
private void flushPendingEntries() {
// 把暂存区的数据委托给包装后的Cache类,进行 putObject操作
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
}
>org.apache.ibatis.cache.decorators.SynchronizedCache#putObject
>org.apache.ibatis.cache.decorators.LoggingCache#putObject
>org.apache.ibatis.cache.decorators.SerializedCache#putObject
>org.apache.ibatis.cache.decorators.ScheduledCache#putObject
>org.apache.ibatis.cache.decorators.LruCache#putObject
>org.apache.ibatis.cache.impl.PerpetualCache#putObject
到此为止,二级缓存的源码分析已分析完。
5.2.4 二级缓存的扩展
Mybatis 默认提供的缓存实现是基于Map实现的内存缓存,但是当需要缓存大量的数据时,不能仅仅通过提高内存来适用Mybatis的二级缓存,还可以
选择Ehcache 或者 redis缓存数据库等工具来保存Mybatis 的二级缓存数据。
为了提高mybatis的性能,所以需要mybatis和第三方缓存数据库整合,比如ehcache、memcache、redis等
5.2.4.1 集成Ehcache 缓存
1.Ehcache 介绍
Ehcache是一种广泛使用的开源Java分布式缓存。主要面向通用缓存,Java EE和轻量级容器。它具有内存和磁盘存储,缓存加载器,缓存扩展,缓存异常处理程序,一个gzip缓存servlet过滤器,支持REST和SOAP api等特点。
特点:
-
快速
-
简单
-
多种缓存策略
-
缓存数据有两级:内存和磁盘,因此无需担心容量问题
-
缓存数据会在虚拟机重启的过程中写入磁盘
-
可以通过RMI、可插入API等方式进行分布式缓存
-
具有缓存和缓存管理器的侦听接口
-
支持多缓存管理器实例,以及一个实例的多个缓存区域
-
整合ehcache的步骤
2.1 添加项目依赖
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.2</version>
</dependency>
2.2 配置 Ehcache
在src/main/resources 目录下 新增 ehcache.xml文件
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="../config/ehcache.xsd">
<diskStore path="d:/cache" />
<defaultCache maxElementsInMemory="1000"
maxElementsOnDisk="10000000" eternal="false" overflowToDisk="false"
timeToIdleSeconds="120" timeToLiveSeconds="120"
diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU">
</defaultCache>
</ehcache>
- diskStore:指定数据在磁盘中的存储位置。
- defaultCache: 当借助CacheManager.add(“demoCache”)创建Cache时,EhCache便会采用指定的的管理策略
- 以下属性是必须的:
- maxElementsInMemory - 在内存中缓存的element的最大数目
- maxElementsOnDisk- 在磁盘上缓存的element的最大数目,若是0表示无穷大
- eternal - 设定缓存的elements是否永远不过期。如果为true,则缓存的数据始终有效,如果为false那么还要根据timeToIdleSeconds,timeToLiveSeconds判断
- overflowToDisk - 设定当内存缓存溢出的时候是否将过期的element缓存到磁盘上
- 以下属性是可选的:
- timeToLiveSeconds:- 缓存element的有效生命期,默认是0.,也就是element存活时间无穷大 diskSpoolBufferSizeMB
这个参数设置DiskStore(磁盘缓存)的缓存区大小.默认是30MB.每个Cache都应该有自己的一个缓冲区. - diskPersistent - 在VM重启的时候是否启用磁盘保存EhCache中的数据,默认是false。
- diskExpiryThreadIntervalSeconds - 磁盘缓存的清理线程运行间隔,默认是120秒。每个120s,相应的线程会进行一次EhCache中数据的清理工作
- memoryStoreEvictionPolicy - - 当内存缓存达到最大,有新的element加入的时候, 移除缓存中element的策略。默认是LRU(最近最少使用),可选的有LFU(最不常使用)和FIFO(先进先出) -->
2.3 在Mapper文件中,配置cache标签的type为ehcache对cache接口的实现类
修改UserMapper.xm 中的配置如下:
<cache eviction="FIFO" flushInterval="60000" size="512"
type="org.mybatis.caches.ehcache.EhcacheCache"/>
2.4 测试
@Test
public void selectUserById(){
SqlSession sqlSessionA = sqlSessionFactory.openSession();
SqlSession sqlSessionB = sqlSessionFactory.openSession();
UserMapper mapperA = sqlSessionA.getMapper(UserMapper.class);
UserMapper mapperB = sqlSessionB.getMapper(UserMapper.class);
UserInfo userInfo = mapperA.selectUserById(1L);
sqlSessionA.close();
UserInfo userInfo2 = mapperB.selectUserById(1L);
sqlSessionB.close();
}
2.5 源码分析
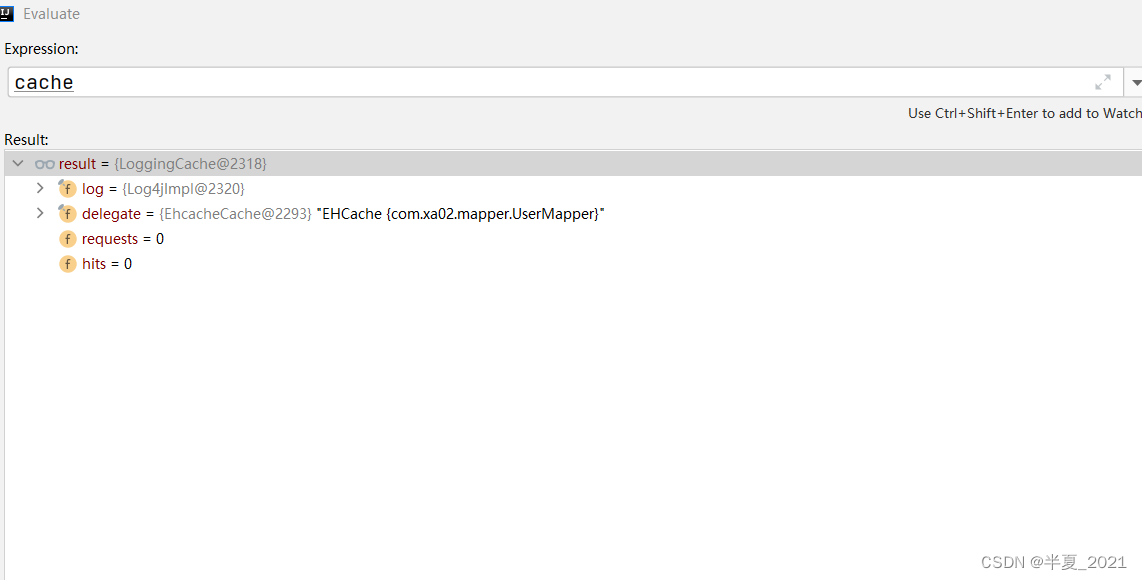
我们值需要分析Cache创建的职责链即可,其他同 二级缓存源码分析章节。
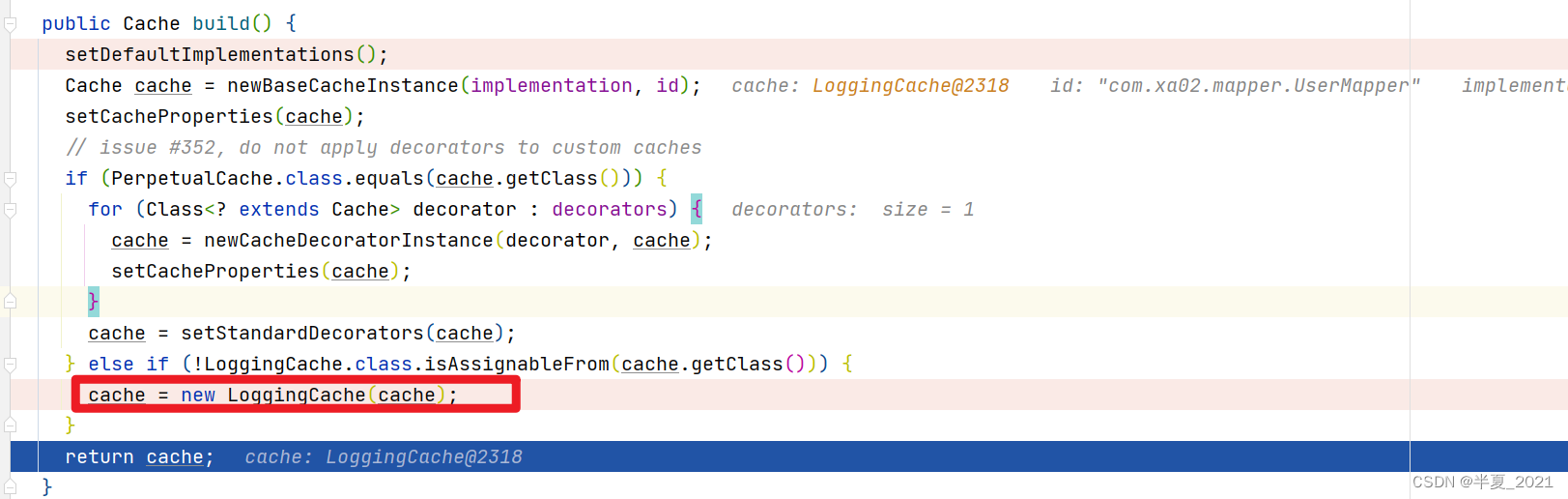
此时职责链式: Loggingcache --> EhcacheCache
2.6 使用场景:
对于访问响应速度要求高,但是实时性不高的查询,可以采用二级缓存技术。
注意事项:
在使用二级缓存的时候,要设置一下刷新间隔(cache标签中有一个flashInterval属性)来定时刷新二级缓存,这个刷新间隔根据具体需求来设置,比如设置30分钟、60分钟等,单位为毫秒。
2.7 Mybatis二级缓存对细粒度的数据级别的缓存实现不好。
l 场景:
对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次查询都是最新的商品信息,此时如果使用二级缓存,就无法实现当一个商品发生变化只刷新该商品的缓存信息而不刷新其他商品缓存信息,因为二级缓存是mapper级别的,当一个商品的信息发送更新,所有的商品信息缓存数据都会清空。
l 解决方法
此类问题,需要在业务层根据需要对数据有针对性的缓存。
比如可以对经常变化的 数据操作单独放到另一个namespace的mapper中。
5.2.4.2 集成redis缓存
Mybatis自身无法实现分布式缓存,需要和其它分布式缓存框架进行整合。
如果不使用分布式缓存,缓存的数据在各个服务单独存储,会存在缓存不一致等问题。所以要使用分布式缓存对缓存数据进行集中式管理。
集成步骤如下:
1.添加POM依赖
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-redis</artifactId>
<version>1.0.0-beta2</version>
</dependency>
2.配置redis
在src/main/resources 目录下新增 redis.properties配置文件
host=localhost
port=6379
connectionTimeout=5000
password=
database=0
3.修改 UserMapper
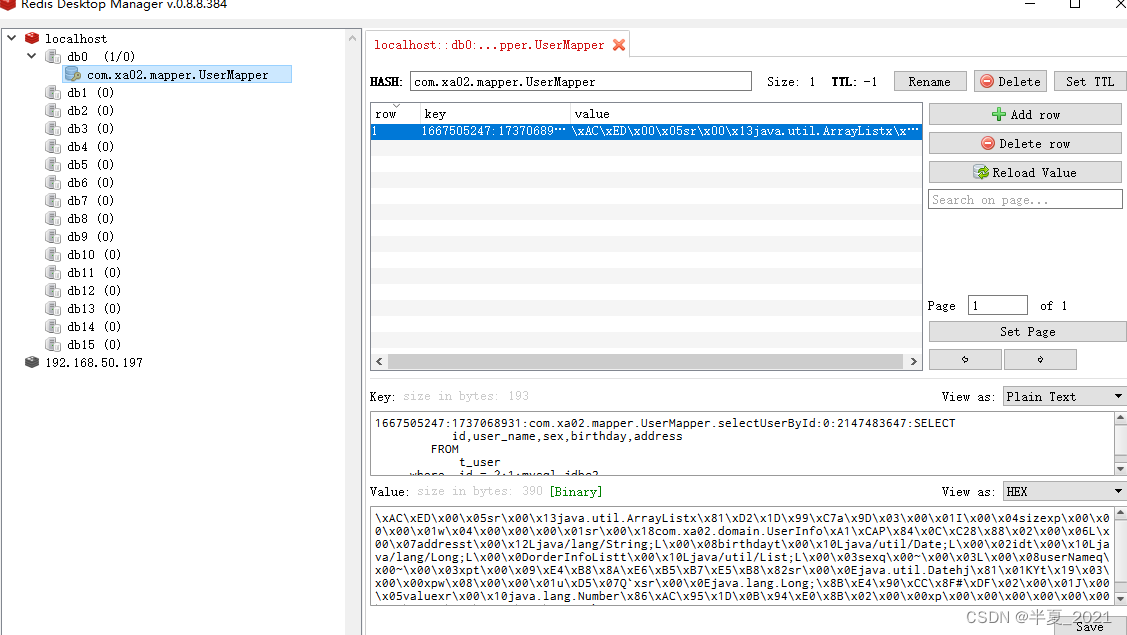
<cache type="org.mybatis.caches.redis.RedisCache"/>
RedisCache 在保存数据和获取缓存数据的时候,使用了Java的序列化和反序列化,因为 java中被缓存的对象需要实现Serializable 接口。
4.测试
@Test
public void selectUserById(){
SqlSession sqlSessionA = sqlSessionFactory.openSession();
SqlSession sqlSessionB = sqlSessionFactory.openSession();
UserMapper mapperA = sqlSessionA.getMapper(UserMapper.class);
UserMapper mapperB = sqlSessionB.getMapper(UserMapper.class);
UserInfo userInfo = mapperA.selectUserById(1L);
sqlSessionA.close();
UserInfo userInfo2 = mapperB.selectUserById(1L);
sqlSessionB.close();
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-67eOOfb4-1662994753807)(C:\Users\wyy\AppData\Roaming\Typora\typora-user-images\image-20220909235235589.png)]
redis中缓存如下: