在学习可复用和可维护的设计模式时,对各种设计模式理解不是很透彻,现总结如下。内容参考《设计模式:可复用面向对象软件的基础》(这也是23种设计模式的出处,MIT课件中也有部分原文),书中采用C++/Smalltalk描述,这里将描述语言改为Java,并对书中示例进行了简化处理,以便更好地说明思想。若有理解上的偏差还请指出。
创建型模式
创建型设计模式抽象了实例化过程。它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给另一个对象。
Factory Method(工厂方法)
首先考虑一个应用场景(这个示例取自原书,但进行了简化)。我们需要实现一个应用框架——Application类,它可以新建并打开文件(接口MyFile,以区别于java的File类)、删除文件等。Application的子类型可以有图片应用、文本应用,分别打开图片文件(如JPG格式)和文本文件(如TXT格式)。同时假定Application有一个文件列表,用来保存所有已经打开的文件。Application和MyFile大致的框架如下:
class Application {
private final List<MyFile> Files = new ArrayList<MyFile>();
/**
* 创建并打开文件,并将其存入列表中
*/
void newFile();
//...
}
interface MyFile {
//打开文件
void open();
//...
}
我们可以发现newFile方法的行为是相当固定的:创建文件并打开文件,将其加入列表。而且其它更具体的Application类应当继承Application,可以对其他不同的方法进行重写。因此我们考虑将Application变为抽象类,只实现newFile方法,其它方法留待子类自己实现。修改后的Application类如下:
abstract class Application {
private final List<MyFile> Files = new ArrayList<MyFile>();
/**
* 创建、打开文件,并将其加入应用的文件列表
* 问题:在父类中需要将文件实例化,但又不知道是哪种文件
*/
void newFile() {
//实现上述功能
}
}
这里有一个问题:由于需要打开文件(调用它的open方法),又需要把它加入列表中,我们难以避免地需要将文件实例化。但是在父类Application中我们无法得知继承它的子类到底是谁,是要打开JPG还是TXT,也就无法直接实例化。我们可能会想放弃采用抽象类来实现公用方法newFile,这就需要我们在每个子类中都重写一次newFile。但工厂方法模式可以解决这个问题,代码如下:
abstract class Application {
private final List<MyFile> Files = new ArrayList<MyFile>();
/**
* 创建、打开文件,并将其加入应用的文件列表
* 问题:在父类中需要将文件实例化,但又不知道是哪种文件
*/
void newFile() {
MyFile file = createFile();
file.open();
Files.add(file);
}
/**
* 工厂方法,将“产品”的创建留待子类实现
* @return 新的文件
*/
abstract MyFile createFile();
}
工厂方法模式引入工厂方法createFile().可以看到它是一个返回MyFile类的抽象方法,也就是让子类来实现这个方法。在newFile中直接调用该方法来获取一个新的对象,在子类的createFile方法被实现后,它的newFile方法中调用的createFile就会变为它想创建的具体“产品”(JPG/TXT)。如:
abstract class Application {
private final List<MyFile> Files = new ArrayList<MyFile>();
/*
* 创建、打开文件,并将其加入应用的文件列表
*/
void newFile() {
MyFile file = createFile();
file.open();
Files.add(file);
}
abstract MyFile createFile();
}
interface MyFile {
void open();
//...
}
class JPG implements MyFile {
public void open() {
System.out.println("Open JPG!");
}
}
class PictureApplication extends Application {
public MyFile createFile() {
return new JPG();
}
}
public class FactoryMethod {
static public void main(String[] args) {
Application app = new PictureApplication();
app.newFile();
}
}
这样我们无需在父类中指定具体的产品类(文件),就可以方便地定义共性的newFile方法,这是通过在子类PictureApplication中重写工厂方法createFile实现的。
工厂方法模式更一般的结构如下:
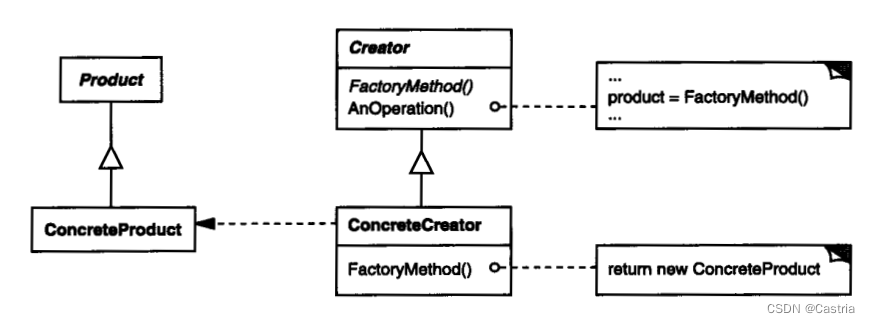
Creator对应的就是上面的Application抽象类;ConcreteCreator对应Application的子类(如图片应用);FactoryMethod即工厂方法,AnOperation对应我们要用工厂方法实现的共性操作。Product为产品接口(例子中的文件),ConcreteProduct是Product的实现类。
事实上我们已经在Lab2中见过这种设计模式了(虽然当时并不是我们自己写的)。回想一下测试文件GraphInstanceTest.java:
public abstract class GraphInstanceTest {
/**
* Overridden by implementation-specific test classes.
*
* @return a new empty graph of the particular implementation being tested
*/
public abstract Graph<String> emptyInstance();
@Test
public void testAdd() {
//...
}
当时我们需要测试两个类:ConcreteEdgesGraph和ConcreteVerticesGraph。由于二者测试有相似性,所以我们把二者的共同点提取到抽象类GraphInstanceTest中实现。我们此时遭遇了同样的问题:在GraphInstanceTest中,我们不知道继承它的子类到底想实例化哪种Graph(ConcreteEdgesGraph/ConcreteVerticesGraph).因此采用工厂方法模式,引入工厂方法emptyInstance,留待两个子测试类实现(在这里,“产品”为两种图):
public class ConcreteEdgesGraphTest extends GraphInstanceTest {
/*
* Provide a ConcreteEdgesGraph for tests in GraphInstanceTest.
*/
@Override public Graph<String> emptyInstance() {
return new ConcreteEdgesGraph<>();
}
//...
}
适用性
在以下场景下可以考虑使用工厂方法模式:
1.当一个类不知道它所必须创建的对象的类时;
2.当一个类希望由它的子类来指定它所创建的对象的时候;
3.当类将创建对象的职责委托给多个帮助子类中的某一个,并且你希望将哪一个帮助子类是代理者这一信息局部化的时候。(原文:Delegates responsibility to one of multiple helper subclasses, and you need to localize the knowledge of which helper is the delegate.这句话比较难懂,个人理解与2.的目的类似)
优点
工厂方法不再将与特定应用有关的类绑定到你的代码中。代码仅处理Product接口,因此它可以与用户定义的任何ConcreteProduct类一起使用。
(原文:Eliminates the need to bind application-specific classes to your code.Code deals only with the Product interface, so it can work with any user-defined ConcreteProduct.个人觉得中文翻译版有的地方会导致迷惑,故附上原文)
个人理解这段话的意思是,工厂方法模式提供了一种避免直接操作产品类(依赖转置原则)的方法。
缺点
工厂方法的潜在缺点在于,客户可能仅仅为了创建一个特定的ConcreteProduct对象就不得不创建Creator的子类(如,为了创建一个JPG就不得不创建一个PictureApplication)。
当Creator子类不是必须的时,客户现在必然要处理类演化的其他方面。但是当客户无论如何必须创建Creator的子类时,创建子类也是可行的。
(原文:This would be acceptable if the client has to subclass the Creator anyway, but if not then the client has to deal with another point of evolution.这句话的译文尤其迷惑,个人理解为:由于客户不需要Creator,就必然要操作具体的产品类,违反了依赖转置原则——面向接口编程)
结构型模式
结构型模式涉及如何组合类和对象以获得更大的结构。
Adapter(适配器)
同样以一个例子引入。假如我们要实现一个描述平面上几何图形的类,其接口Shape如下:
interface Shape {
/**
* 把图形移动到指定位置
* @param x 目的横坐标
* @param y 目的纵坐标
*/
void moveTo(double x, double y);
/**
* 计算图形面积
* @return 图形的面积
*/
double calculateArea();
/**
* 计算图形周长
* @return 图形的周长
*/
double calculatePerimeter();
//...
}
我们计划实现圆、正方形、椭圆等图形(在学习里氏替换原则LSP时,我们们知道正方形不应该继承长方形,同理椭圆也不应当是圆的子类)。其中圆和正方形已经实现如下:
class Circle implements Shape {
private double x, y;
private double radius;
public Circle(double radius) {
this.radius = radius;}
@Override
public void moveTo(double x, double y) {
this.x = x;
this.y = y;
}
@Override
public double calculateArea() {
return Math.PI * radius * radius;}
@Override
public double calculatePerimeter() {
return 2 * Math.PI * radius;}
}
class Square implements Shape {
private double x, y;
private double side;
//...重写方法
}
现在我们还要实现椭圆类。我们知道椭圆没有初等的精确周长计算公式(需要积分),所以想偷个懒用别人实现好的库来实现我们自己的类。但是我们不一定直接能拿到该类的源码,别人实现好的类也基本不可能和我们的类的方法完全一致。但是我们复用代码一定能获取到它的方法列表。比如它的方法签名长这个样子:
//OtherOval.java
/**
* 修改位置
* @param x 目的横坐标
* @param y 目的纵坐标
*/
public void setPosition(double x, double y);
/**
* 计算椭圆面积
* @return 椭圆面积
*/
public double getArea();
/**
* 计算椭圆周长
* @return 椭圆周长
*/
public double getPerimeter();
这时需要采用适配器模式,对其进行适配。我们可以定义一个自己的椭圆类,采用委派(Delegation)的方式,保留一个对OtherOval的引用,把计算周长/面积的任务交给它做:
class Oval implements Shape {
private OtherOval oval;
public Oval(double radius) {
this.oval = new OtherOval(radius);}
@Override
public void moveTo(double x, double y) {
this.oval.setPosition(x, y);
}
@Override
public double calculateArea() {
return this.oval.getArea();}
@Override
public double calculatePerimeter() {
return this.oval.getPerimeter();}
}
这样我们既复用了代码,又保留了自己类的接口。适配器方法的一般结构如下:
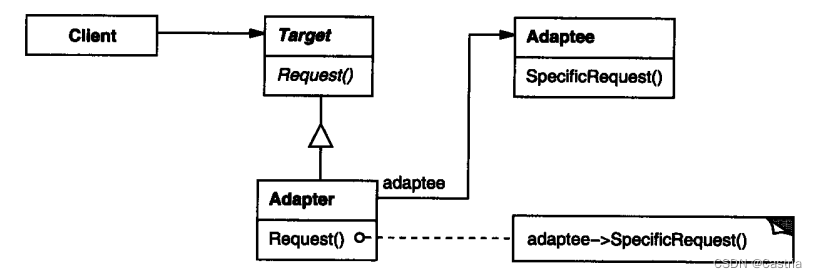
其中Target为我们的类接口;Adapter为我们想要复用代码的同时保留Target方法接口的子类;Adaptee为被复用的代码。Adapter为了实现Request请求,调用Adaptee的各种方法实现该任务。这幅图是对象匹配器(适配器),书上还提到了类适配器,采用同时继承Target和Adaptee方式实现。由于Java只支持接口的“多继承”,使用起来不太方便,这里不加介绍。
适用性
以下情况使用Adapter模式:
1.你想使用一个已经存在的类,而它的接口不符合你的需求。
2.你想创建一个可以复用的类,该类可以与其他不相关的类或不可预见的类(即那些接口可能不一定兼容的类)协同工作。
3.(仅适用于对象Adapter)你想使用一些已经存在的子类,但是不可能对每一个都进行子类化以匹配它们的接口。对象适配器可以适配它的父类接口。
个人觉得第一点最普适(拿来主义)。
缺点
Adapter的优点很明显:可以复用接口不同但功能相同的代码。但该模式使得重定义Adaptee的行为比较困难:需要用其他子类继承Adaptee并使Adapter重新适配。(不过比起重新造轮子,适配的难度要小得多)
Decorator(装饰器)
引入:假如我们需要写一个文本框TextView。但是我们希望用户可以根据需要给它添加一些其他组件,如滚动条和边框、输入框等。它的大体框架如下:
class TextView {
private String text;
public TextView(String text) {
this.text = text;
}
public void print() {
System.out.println(this.text);
}
}
为了增加一些额外的职责(比如给文本框加一个粗边框),我们首先想到可以采用继承/组合的方式:
//继承方式
class BorderTextView extends TextView{
int borderWidth;
public BorderTextView(String text, int borderWidth) {
super(text);
this.borderWidth = borderWidth;
}
@Override
public void print() {
super.print();
System.out.println("Border width:" + borderWidth);
}
}
//组合方式
class BorderTextView {
int borderWidth;
TextView textView;
public BorderTextView(String text, int borderWidth) {
this.textView = new TextView(text);
this.borderWidth = borderWidth;
}
public void print() {
textView.print();
System.out.println("Border width:" + borderWidth);
}
}
但是这两种实现方式都有一个问题:不够灵活。如果我们需要一个同时具有滚轮和边框的文本框呢?我们还需要继承下来一个BorderScrollTextView,如果组件的个数多到一定程度,组合个数呈指数级,软件的维护难度是不可想象的。装饰器模式被用于解决该问题。它的一般结构如下:
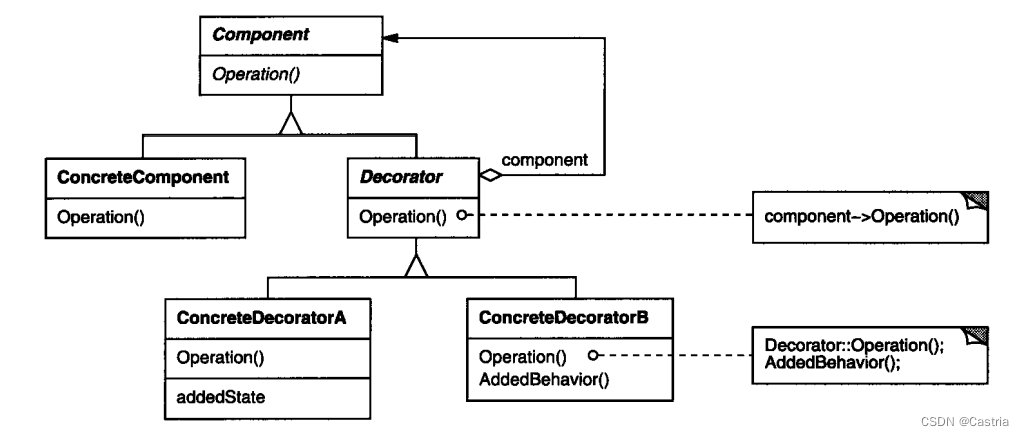
我们引入装饰器类Decorator,它是一个抽象类,实现自Component接口。Component接口是一个最高级别的基类,被修饰对象ConcreteComponent(本例中为文本框TextView)直接继承自它。Decorator有一些具体的子类ConcreteDecoratorA等,它们定义着额外的行为。我们用例子看一下如何应用装饰器模式:
interface Component {
void print();
}
class TextView implements Component{
private String text;
public TextView(String text) {
this.text = text;
}
public void print() {
System.out.println(this.text);
}
}
abstract class Decorator implements Component {
protected Component component;
public Decorator(Component c) {
this.component = c;
}
abstract public void print();
}
class BorderDecorator extends Decorator {
int borderWidth;
public BorderDecorator(Component c, int borderWidth) {
super(c);
this.borderWidth = borderWidth;
}
@Override
public void print() {
component.print();
System.out.println("Border width:" + borderWidth);
}
}
public class DecoratorTest {
public static void main(String[] args) {
Component borderTextView = new BorderDecorator(new TextView("Hello world"), 1);
borderTextView.print();
}
}
//output:
//Hello world
//Border width:1
我们如前文所述,声明一个公共的接口Component(组件),分别让装饰器和被装饰对象TextView实现它。TextView相比前文,除了要实现Component没有什么变化。Decorator是一个抽象类,它保存一个TextView的引用,并不直接实现print方法,而是留待装饰器的具体子类实现。BorderDecorator继承装饰器Decorator,保存一个额外的边框信息borderWidth并重写print方法:它调用Decorator保存的TextView的print方法,在此基础上进行“装饰”:添加边框(在这里表现为在控制台上输出)。
我们再看我们前面遭遇的问题:对于增添的小组件的组合。采用装饰器模式,我们可以灵活地给原本的文本框增加职责了:
interface Component {
void print();
}
class TextView implements Component{
private String text;
public TextView(String text) {
this.text = text;
}
public void print() {
System.out.println(this.text);
}
}
abstract class Decorator implements Component {
protected Component component;
public Decorator(Component c) {
this.component = c;
}
abstract public void print();
}
class BorderDecorator extends Decorator {
int borderWidth;
public BorderDecorator(Component c, int borderWidth) {
super(c);
this.borderWidth = borderWidth;
}
@Override
public void print() {
component.print();
System.out.println("Border width:" + borderWidth);
}
}
class ScrollDecorator extends Decorator {
public ScrollDecorator(Component c) {
super(c);
}
@Override
public void print() {
component.print();
System.out.println("Scroll attached");
}
}
public class DecoratorTest {
public static void main(String[] args) {
Component scrollBorderTextView = new ScrollDecorator(new BorderDecorator(new TextView("Hello world"), 1));
scrollBorderTextView.print();
}
}
//output:
//Hello world
//Border width:1
//Scroll attached
适用性
在以下情况下使用Decorator模式:
1.在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责。
2.处理那些可以撤销的职责(可以通过保存一个未修饰的引用)。
3.当不能采用生成子类的方法进行扩充时。一种情况是,可能有大量独立的扩展,为支持每一种组合将产生大量的子类,使得子类数目呈爆炸性增长(即我们上面遭遇的情况)。另一种情况可能是,类定义被隐藏,或类定义不能用于生成子类(final修饰符)。
优点
装饰器模式比静态继承更灵活。与对象的静态继承相比,装饰器模式提供了更加灵活地向对象添加职责的方式。此外,还可以重复地添加一个特性(如添加两层边框,只需要用两个装饰器进行修饰)。
行为型模式
行为型模式涉及算法和对象间职责的分配。行为型模式不仅描述对象或类的模式,还描述它们之间的通信模式。
Iterator(迭代器)
只要我们用过java的迭代器,对这个设计模式也就不会感到陌生了。它的使用场合也比较固定,主要用于:
1.访问一个聚合对象的内容而无需暴露它的内部表示;
2.支持对聚合对象的多种遍历;
3.为遍历不同的聚合结构提供一个统一的接口(即支持多态迭代)。
为了保证完整性,我们还是从例子开始。假如我们实现了一个链表MyLinkedList,它实现一个接口MyList:
interface MyList <L>{
void add(L value);
L get(int index);
}
class MyLinkedList <L> implements MyList<L> {
private class Node <L> {
public L value;
public Node next;
public Node(L value, Node next) {
this.value = value;
this.next = next;
}
}
private Node head = null, tail = null;
@Override
public void add(L value) {
if(tail == null) {
head = tail = new Node<L>(value, null);
}
else {
Node newNode = new Node<L>(value, null);
tail.next = newNode;
tail = newNode;
}
}
@Override
public L get(int index) {
if(index < 0) {
// throw ...
}
Node<L> node = head;
if(node == null) {
// throw...
}
for(int i = 0; i < index; i++) {
node = node.next;
if(node == null) {
// throw...
}
}
return node.value;
}
}
我们现在想要使List支持遍历操作,能够获取所有元素以进行某种统计(求和等)。我们不想暴露MyLinkedList内部的实现(Node类的存在),因此我们不能直接给用户返回一个Node。一种方式是让List内部保存一个信息,指向当前元素的位置,并增加一些辅助方法,进行遍历:
private Node<L> iterator;
public void resetIterator() {
iterator = head;
}
public boolean iteratorNull() {
return iterator == null;
}
public L currentElement() {
return iterator.value;
}
public void nextElement() {
iterator = iterator.next;
}
public class IteratorTest {
public static void main(String[] args) {
MyList<String> list = new MyLinkedList<String>();
list.add("hello");
list.add("world");
list.resetIterator();
while(!list.iteratorNull()) {
System.out.println(list.currentElement());
list.nextElement();
}
}
}
但是这种实现有一些问题。如果我们想对该列表进行其它种类的遍历,比如倒序遍历,需要继续在List中加入其他方法、维护其它引用。此外,如果我们想要同时进行多个遍历,也非常麻烦,List内需要维护多个引用,客户端也需要传入额外的参数指明对哪个遍历进行操作。迭代器模式解决了这个问题。它的一般结构如下:
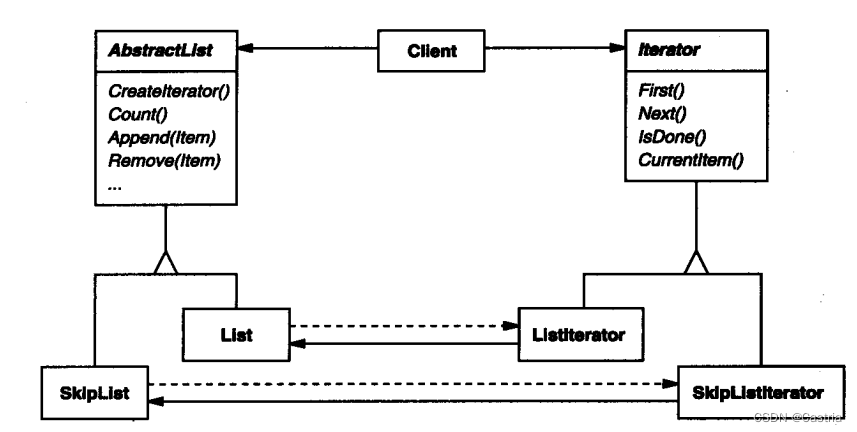
interface Iterator <L> {
boolean iteratorNull();
L currentElement();
void nextElement();
}
//为了访问Node类,需要继承MyLinkedList类并将其中的Node改为protected
//在C++中这可以通过友元实现
class MyLinkedListIterator<L> extends MyLinkedList<L> implements Iterator<L> {
Node<L> current;
public MyLinkedListIterator(Node head) {
this.current = head;
}
@Override
public boolean iteratorNull() {
return this.current == null;
}
@Override
public L currentElement() {
return this.current.value;
}
@Override
public void nextElement() {
this.current = this.current.next;
}
}
//MyLinkedList类中
public Iterator<L> iterator() {
return new MyLinkedListIterator(this.head);
}
我们将遍历操作与列表类分离开,这样我们解决了上述问题:可以支持多种遍历方式而又不过度“污染”List的接口(可以通过自定义迭代器的子类来实现),还可以同时进行多个遍历。此外,客户端面向Iterator接口编程,而不需要知道具体的迭代器类是什么就可以使用(因为迭代器的具体类型是内置在具体的列表类里的)。
优点
1.支持以不同的方式遍历一个聚合。这一点在上面已经讨论过了,可以通过自定义迭代器的子类实现。
2.简化了聚合的接口。在我们最初的实现里,List类需要很多仅与遍历相关的操作(currentElement等),污染了接口。采用迭代器可以将这些操作封装在迭代器类内。
3.在同一个聚合上可以有多个遍历。每个迭代器保持它自己的遍历状态,因此可以同时进行多个遍历。
Strategy(策略)
策略模式可以使一系列不同算法进行便捷的替换。还是以例子引入:假如我们的文本框类需要指定一种打印格式,打印的规则可以是:每 k k k个单词换一行;对于每个标点符号换一行;只按照文本中换行符来换行,不添加额外换行等等。我们首先想到可以对各种换行算法各添加一种方法:
class TextView {
private String text;
public TextView(String text) {
this.text = text;
}
public void wrapPerKWords(int k) {
//...
}
public void wrapPerSentence() {
//...
}
public void simpleWrap() {
//...
}
}
可以但是这种方法有一个缺点。TextView类中会充斥着大量的换行方法,并且我们每想新增一种方法就需要到TextView类中作修改。或者我们可以采用继承方法,每一种子类对应一种换行算法,但这种方式同样很复杂。策略模式把算法与类分离,使得切换算法、添加新算法更加灵活。它的结构如下:
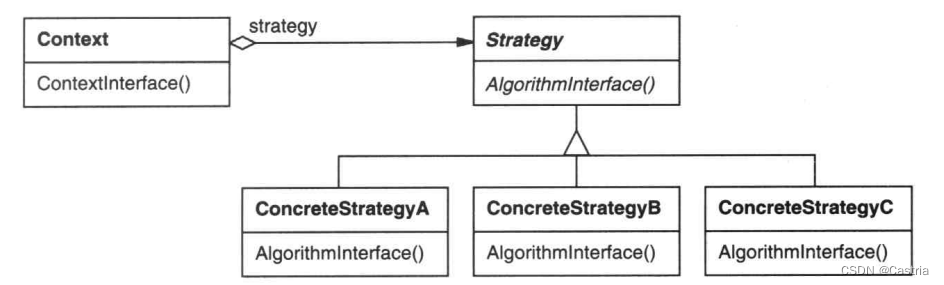
Context将具体问题的算法委托给Strategy类,这种委托可以是Dependency(依赖,即只把Strategy作为参数传给ContextInterface(),而不保存引用,Lab3中采用的就是这种方法)或者是Association(聚合,即在Context类中保存一个Strategy的引用,书中示例代码给的就是这种方法)。下面给出针对换行问题的具体实现:
class TextView {
private String text;
public TextView(String text) {
this.text = text;
}
public void wrapText(Strategy s) {
s.wrap(text);
}
}
interface Strategy {
void wrap(String text);
}
class wrapPerKWords implements Strategy {
private int k;
public wrapPerKWords(int k) {
this.k = k;
}
@Override
public void wrap(String text) {
String[] words = text.split("[,.:?!;\\s]");
StringBuilder stringBuilder = new StringBuilder();
for(int i = 0; i < words.length; i++) {
stringBuilder.append(words[i]);
if(i % k == k - 1) stringBuilder.append("\n");
else stringBuilder.append(" ");
}
System.out.println(stringBuilder);
}
}
class wrapPerSentence implements Strategy {
@Override
public void wrap(String text) {
System.out.println(text.replaceAll("[,.:?!;]", "\n"));
}
}
class simpleWrap implements Strategy {
@Override
public void wrap(String text) {
System.out.println(text);
}
}
public class StrategyTest {
public static void main(String[] args) {
TextView textView = new TextView("To be or not to be,this is a question.");
textView.wrapText(new wrapPerSentence());
}
}
我们把每种换行算法分别包装到一个类里,在Client调用时,通过具体的算法类来调用。(如main方法中,通过new wrapPerSentence传入wrapText调用)
适用性
考虑了上面的例子后,我们看看策略模式的适用场合:
1.许多相关的类仅仅是行为有异。“策略”提供了一种用多个行为中的一个行为来配置一个类的方法。
2.需要使用一个算法的不同变体。例如,你可以会定义一些反映不同的空间/时间权衡的算法。
3.算法使用客户不应该知道的数据。可以使用策略模式以避免暴露复杂的、与算法相关的数据结构(通过把实现细节隐藏在Strategy类中,而Context类直接将参数委托给Strategy类)
4.一个类定义了多种行为,而且这种行为在这个类的操作中以多个条件语句的形式出现。将相关的条件分支移入它们各自的Strategy类以代替这些条件语句。(可以减少类中冗长的条件分支语句,而将不同的行为分散到各个Strategy类中)
优点
1.策略模式有助于析取各种算法中的公共功能。
2.策略模式能够消除条件语句。如果我们不采用策略模式,也可以采用switch-case语句来决定使用哪种算法(传入一个参数来选择,而非暴露一些公共的方法)。但是这样会引入一大堆条件分支语句,难以维护。策略模式采用多态的方式避免了这一点。
3.替代继承。(显然,通过继承实现不同的算法更难以理解和维护、难以扩展)
4.给用户实现的选择。Strategy模式可以提供相同行为的不同实现。客户可以根据不同时间/空间取舍要求从不同策略中进行选择。(比如,最小生成树有 O ( N 2 ) O(N^2) O(N2)的Prim算法和 O ( E l o g E ) O(ElogE) O(ElogE)的Kruskal算法,客户可能想根据图的稀疏程度选择更快的算法)
缺点
1.策略模式使得客户必须了解不同的策略。这时可能需要向客户暴露具体的实现。因此尽量只在这些不同行为与客户(的需求)相关时再使用策略模式。
2.Strategy和Context之间的通信开销。(个人理解,即参数传递过程)由于各个策略之间必须要有相同的接口,对于其中的某些策略有可能不会用到传递的所有参数,这就造成了额外开销。可以对Strategy和Context进行更为紧密的耦合来弥补这一点。(上面举的例子就采用了这种方法:由于只有k个词一换行需要k这个参数,为了避免给其它策略类也传递相同参数造成额外开销,选择把这个参数保存在k词一换行的策略类中。)
3.增加了对象的数目。对于每个不同的策略,我们都需要新建一个具体的Strategy类。这可能使程序的体积增大。
Template Method(模板方法)
模板方法模式定义一个操作中的算法的骨架,将一些步骤延迟到子类当中进行。它部分类似于前面提到的工厂方法,但它的特点是将行为各异的方法留到子类中实现,而工厂方法强调将需要的对象留到子类中实例化。假如我们现在有一个制作汉堡、三明治和热狗的工厂(这里的工厂只是工厂,跟工厂方法的工厂没什么关系),它们的结构都很相似,都需要先放底层的面包,再放填充物,再放顶层面包:
abstract class FoodFactory {
abstract public void addBottomBread();
abstract public void addFillings();
abstract public void addTopBread();
public void makeFood() {
addBottomBread();
addFillings();
addTopBread();
}
}
我们可以在父类FoodFactory类中先写好这三个步骤,把这三个步骤的具体实现留待各种食物的子类:
class HamburgerFactory extends FoodFactory {
@Override
public void addBottomBread() {
System.out.println("Add bottom round bread");// 放底层的圆形面包
}
@Override
public void addFillings() {
System.out.println("Add patty");// 放肉饼
}
@Override
public void addTopBread() {
System.out.println("Add top round bread");// 放顶层的圆形面包
}
}
public class TemplateTest {
public static void main(String[] args) {
FoodFactory foodFactory = new HamburgerFactory();
foodFactory.makeFood();
}
}
如果想要一个制作别的食物的工厂,只需要创建一个新的类继承FoodFactory,重写子类的这三个方法即可。比如我们想要一个三明治工厂:
class SandwichFactory extends FoodFactory {
@Override
public void addBottomBread() {
System.out.println("Add bottom square bread");// 放底层的方形面包
}
@Override
public void addFillings() {
System.out.println("Add bacon and egg");// 放培根和煎蛋
}
@Override
public void addTopBread() {
System.out.println("Add top square bread");// 放顶层的方形面包
}
}
为了获得一个三明治,只需要将引用指向三明治工厂即可。通用的模板方法结构如下图:
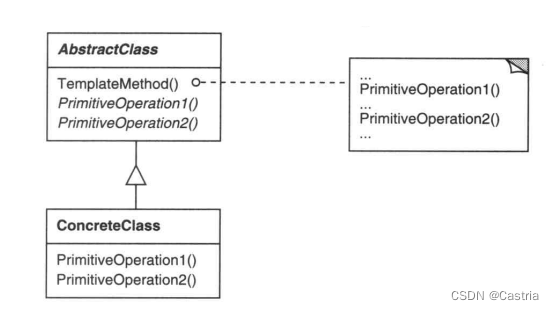
适用性
模板方法适用于以下的情况:
1.一次性实现一个算法的不变部分,并将可变的行为留给子类来实现;
2.各子类中公共的行为应被提取出来并集中到一个公共父类中以避免代码重复。
3.控制子类扩展。模板方法只在特定点调用钩子操作(钩子:Hook,各个地方都会用到这个词,但含义不尽相同。这里指留给子类的可以扩展的操作)
优点
模板方法是一种代码复用的基本技术(避免了在子类中进行重复的操作)。它导致一种反向的控制结构,这种结构也被称为好莱坞法则(Don‘t call us, we‘ll call you),即父类调用子类的操作。
Visitor(访问者)
Visitor模式使我们在不修改ADT的条件下定义对于ADT内部各种不同元素的新操作。还是以例子引入:
我们现在要写一个表示购物车的ADT(比如我们点外卖的时候出现的)。它维护一个餐品的列表:
class FoodShoppingCart {
private final List<Item> foodList = new ArrayList<Item>();
public void addFood(Item item) {
this.foodList.add(item);
}
}
其中餐品表示为一个抽象类Item(商品),可以分出食物、饮品、甜点等。餐品可能会有不同的属性,比如食物我们一般在意它的重量,饮品一般看它的净含量而不看重量:(比如500ml)
abstract class Item {
String name;
double price;
public Item(String name, double price) {
this.name = name;
this.price = price;
}
String getName() {
return this.name;
}
double getPrice() {
return this.price;
}
}
class Food extends Item {
double weight;
public Food(String name, double price, double weight) {
super(name, price);
this.weight = weight;
}
public double getWeight() {
return this.weight;
}
}
class Drink extends Item {
double volume;
public Drink(String name, double price, double volume) {
super(name, price);
this.volume = volume;
}
public double getVolume() {
return this.volume;
}
}
现在我们需要完善我们的购物车ADT了。首先一定要知道所有商品的总价:
public double calculatePrice() {
double price = 0;
for(Item item: foodList) {
price += item.getPrice();
}
return price;
}
但是需求总是要发生变化的。假如现在客户又想知道这一次购物的重量总和,我们肯定第一时间想到在购物车ADT中再加一个方法:
public double calculateWeight() {
double weight = 0;
for(Item item: foodList) {
if(item instanceof Food) {
weight += ((Food)item).getWeight();
}
}
return weight;
}
这次我们实现起来没有那么自如了。为了安全地向下转型以调用Food特有的方法getWeight,我们用到了instanceof运算符,这在java中是不被提倡的。此外,我们可能会意识到可能以后还有很多增加的需求,比如统计饮品出现的比例或食物的价格占比。为了不把引用暴露给客户,我们每次都必须在购物车ADT中增加方法来满足客户需求。这不满足开闭原则(对修改封闭,对扩展开放):到最后,购物车ADT中可能充斥着各种满足特定需求才产生的方法。Visitor模式用于解决这类问题。它的一般结构如下:
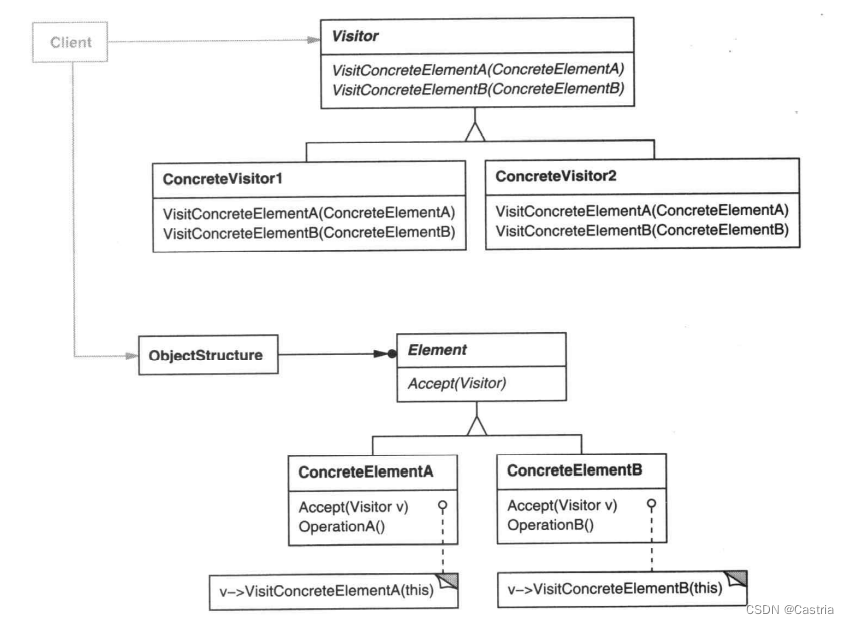
光看这个类图可能比较难以理解。我们看看实际上怎么修改我们的程序:
(1)增加Visitor接口。它需要访问所有具体的商品类(在上面的例子里包括食物和饮品),为每个商品类定义一个visit方法。
interface Visitor {
void visitFood(Food food);
void visitDrink(Drink drink);
}
(2)在商品类及其具体类中增加accept方法,接受一个Visitor对象。它简单地调用该visitor对象的访问自身的方法(参数为this指针)。
abstract class Item {
//其它部分省略,仅保留新增部分
abstract void accept(Visitor visitor);
}
class Food extends Item {
//其它部分省略,仅保留新增部分
@Override
public void accept(Visitor visitor) {
visitor.visitFood(this);
}
}
(3)在购物车ADT中添加accept方法,接受一个Visitor对象。它需要遍历商品列表,分别调用各个商品的accept方法。(注意,这与MIT的课件中略有不同,但这是更一般的形式,稍后会解释)
class FoodShoppingCart {
//其它部分省略,仅保留新增部分
public void accept(Visitor visitor) {
for(Item item: foodList) {
item.accept(visitor);
}
}
}
(4)针对具体的要求,创建Visitor的子类。比如我们要计算购物车中所有商品的价格,创建PriceVisitor子类:
class PriceVisitor implements Visitor {
private double price;
public PriceVisitor() {
this.price = 0;}
@Override
public void visitFood(Food food) {
price += food.getPrice();
}
@Override
public void visitDrink(Drink drink) {
price += drink.getPrice();
}
//新增的方法,用于获取visitor统计的结果
public double getPrice() {
return this.price;
}
}
(5)创建具体的Visitor对象,调用购物车的accept方法,并获取统计信息。
public class VisitorTest {
public static void main(String[] args) {
Item steak = new Food("steak", 20.0, 100);
Item juice = new Drink("juice", 5.0, 500);
FoodShoppingCart cart = new FoodShoppingCart();
cart.addFood(steak);
cart.addFood(juice);
PriceVisitor visitor = new PriceVisitor();
cart.accept(visitor);
System.out.println(visitor.getPrice());
}
}
//output:25.0
在上面的例子中,我们通过创建新的Visitor子类来访问购物车ADT中的各个对象。为了完成这一点,需要在ADT和各个具体商品中都添加accept方法。其中具体商品(食品、饮料)的accept方法与想要获取的信息无关,它仅仅是把自己的数据交给Visitor(委托Delegation),由具体的Visitor来决定获取自身的什么信息。而ADT的accept方法只需要确保遍历所有的商品,调用各个商品的accept方法以收集信息。可以看到,具体信息的统计全权交给Visitor负责,ADT只是给Visitor提供了一种遍历自身元素的方法。因此,每当新增一种统计需求,只需要新建一种Visitor而不需要改变ADT的实现,这满足了开闭原则。
此外,我们避免了instanceof的使用,这是通过双分派(double-dispatch)实现的。双分派指一个方法的调用与两个类型都有关,在访问者模式中这两个类型分别指ADT中的具体类(食物/饮品)和具体的访问者。我们回想一下是怎么不使用向下转型又能调用到Food的getWeight方法的:购物车ADT调用列表中Food的accept方法(这个过程是运行时决定的),而Food的accept方法把自身传给具体的Visitor类,这个具体的Visitor类发现这个商品是一个Food类,再调用这个Food的getWeight方法。这个visit的过程不是通过多态实现的,它取决于遍历时调用了哪个具体类的accept方法,这时类型也就固定下来,调用Visitor类中的对应visit方法,避免了向下转型。
刚才还提到accept的实现与课件略有不同。课件的部分代码如下(不再介绍具体代码环境):
public interface ItemElement {
public int accept(ShoppingCartVisitor visitor);
}
public class Book implements ItemElement{
private double price;
...
int accept(ShoppingCartVisitor visitor) {
visitor.visit(this);
}
}
这部分代码把accept和返回值设为int(也是要统计各个商品的总价)。显然这不总是适用的,我们还可能希望返回其它类型的信息(String/boolean)。因此更普适的做法是在Visitor的实现类中保存一些统计变量(如示例代码中的price),在void型的visit方法中统计数据,再新增一个获取结果的方法(示例代码中的getPrice()),这样可以根据需要获取不同的结果。
看了上面的示例后,我们再系统地看看Visitor模式的适用性及主要优缺点。
适用性
在下列情况中使用Visitor模式:
1.一个对象结构包含很多类对象,它们有不同的接口,而你想对这些对象实施一些依赖于其具体类的操作。(这一点在示例中食物和饮品的不同属性得以体现。需要分别对重量和净含量进行统计)
2.需要对一个对象结构中的对象进行很多不同且不相关的操作,而你想避免让这些操作“污染”这些对象的类。Visitor使得你可以将相关的操作集中起来定义在一个类中。当该对象结构被很多应用共享时,用Visitor模式让每个应用仅包含需要用到的操作。(这一点也在上文有解释。如果我们仅仅是在购物车ADT中增加不同的统计方法,会导致乱七八糟的方法“污染”ADT的接口。Visitor模式保证了ADT操作的“纯洁”。)
3.定义对象结构的类很少改变,但经常需要在此结构上定义新的操作。改变对象结构类需要重定义对所有访问者的接口,这可能需要很大的代价。(在示例中,购物车ADT包括商品类型可能不太常改变,但客户可能总是想统计一些奇奇怪怪的信息,比如商品名中“芝士”出现了多少次)如果对象结构类经常改变,那么可能还是在这些类中定义这些操作比较好。
优点
1.访问者模式使得易于增加新的操作。这一点我们在上面已经体会过了:只需要新建一个Visitor的子类,重写访问所有商品的visit方法即可。
2.访问者集中相关的操作而分离无关的操作。这一点在适用性部分也已经解释过了。访问者模式避免“污染”ADT,而把所有统计方法全聚集在Visitor的子类当中。
3.无需考虑具体类型。迭代器模式也许也可以实现统计信息的操作。但是它难以适当地获取每个对象的具体类型。比如在示例中,我们有食品和饮品两种类型,但如果用迭代器模式我们只能获知它们是商品(不考虑instanceof)。Visitor模式解决了这个问题,具体方法在上面适用性部分也解释过了(双分派)。
缺点
1.增加新的具体类型很困难。在示例中,如果我们还想增加一种甜品商品,我们要把所有的Visitor子类中都添加上visit甜品的方法,以确保之前的Visitor也能正常工作,这可能使得程序较难以维护。因此如果具体类型频繁地发生变动,应当考虑是否应用访问者模式。
2.破坏封装。访问者模式需要确保各个具体类型的信息都能被访问到(有public的getter),这可能会违背我们的本意。比如,可能我们本来不想暴露具体类中的某个属性,但为了访问者模式能够统计所需信息,需要额外设置一个getter方法,就可能把信息暴露给其它使用该具体类的客户。
至此,本学期涉及的7种设计模式已经全部介绍完毕。由于成文时间短(3个晚上),难免疏漏,若文章有知识性错误还请指出。