一、设计一个考勤系统
考勤系统,包含员工表,考勤记录表。
①员工表:员工id、员工姓名;
②考勤记录表:考勤id、考勤状态、考勤时间
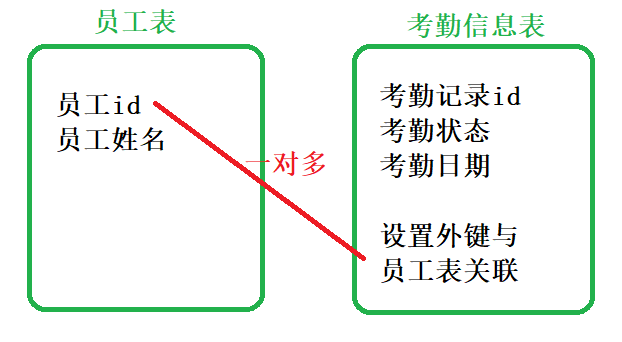
主要考虑记录表中的记录信息,是如何关联到员工表,员工与记录关系为1:m。
create table staff(
id int primary key,
name varchar(20)
);
create table information(
id int primary key,
staff_id int,
status bit,
information_date timestamp,
foreign key (staff_id) references staff(id)
);
二、设计一个学校宿舍管理系统
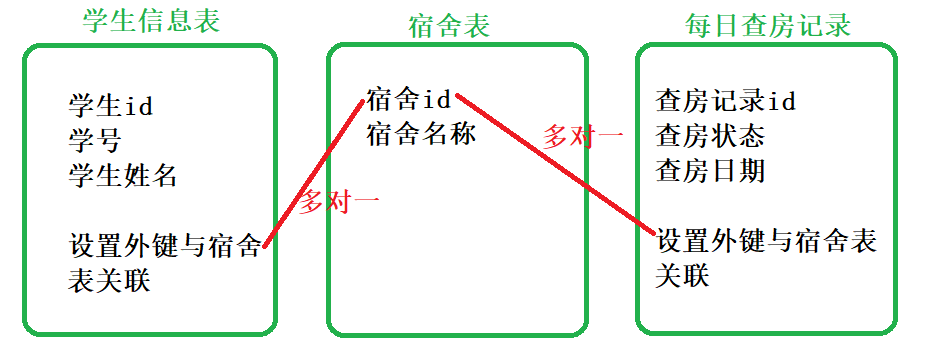
学校宿舍管理系统,要求包含宿舍信息,学生信息,每日的宿舍查房记录。
①宿舍信息:宿舍id、宿舍名称;
②学生信息:学生id、学号、学生姓名;
③每日查房记录:记录id、查房状态、查房日期
主要考虑学生与宿舍的关系:m:1,宿舍的查房记录是根据宿舍来查的,与宿舍有关系,一个宿舍可以多次查房,宿舍与查房记录是1:m的关系。
create table dormitory(
id int primary key,
number varchar(20)
);
create table student(
id int primary key,
name varchar(20),
sn int,
dormitory_id int,
foreign key (dormitory_id) references dormitory(id)
);
create table information(
id int primary key,
status bit,
dormitory_id int,
information_date timestamp,
foreign key (dormitory_id) references dormitory(id)
);
三、设计一个车辆违章系统
车辆违章系统,包含用户表,车辆表,违章信息表。违章信息表中包含用户和车辆的违章信息。
①用户表:用户id、用户姓名;
②车辆表:车辆id、车辆名称;
③违章记录表:违章记录id、违章描述、包括用户和车辆的违章信息

create table user(
id int primary key,
name varchar(20)
);
create table car(
id int primary key,
user_id int ,
foreign key (user_id) references user(id)
);
create table illegal_description(
id int primary key,
user_id int,
car_id int,
information_date timestamp,
foreign key (car_id) references car(id)
foreign key (user_id) references user(id)
);
四、设计一个学校食堂管理系统
自增约束(auto_increment):
在mysql中,可通过关键字auto_increment为列设置自增属性,只有整型列才能设置此属性,每个表只能定义一个auto_increment列,并且必须在该列上定义主键约束(primary
key)或候选键(unique)。
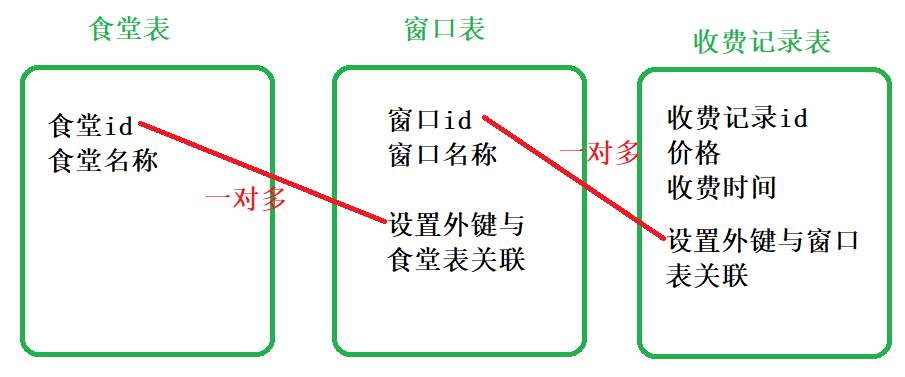
学校食堂管理系统,包含食堂表,食堂仓口表,仓口收费记录表。
①食堂表:食堂id、食堂名称;
②食堂窗口表:窗口id、窗口名称;
③窗口收费记录:收费记录id、价格、收费时间
create table canteen(
id int primary key auto_increment,
name varchar(20)
);
create table enteance(
id int primary key auto_increment,
name varchar(20)
canteen_id int,
foreign key (canteen_id) references canteen(id)
);
create table charge(
id int primary key auto_increment,
price decimal(5,2)
date_time timestamp,
enteance_id int,
foreign key (canteen_id) references enteance(id)
);
五、查询习题
有一张员工表emp,字段:姓名name,性别sex,部门depart,工资salary。
查询以下数据:
1、查询男女员工的平均工资
select sex,avg(salary)
from emp
group by sex;
说明:平均值使用聚合函数avg,并且按照性别男女分组,group by 性别字段
2、查询各部门的总薪水
select depart,sum(salary)
from emp
group by depart;
说明:总薪水使用聚合函数sum取薪水字段求和,并且按照部门字段分组,group by 部门字段
3、查询总薪水排名第二的部门
select depart,sum(salary)
from emp
group by depart
order by sum(salary) desc
limit 1,1;
说明:order by语句先按照总薪水排序,之后取第二条数据,可以使用分页,每一页1条数据,第二页就是该结果
4、查询姓名重复的员工信息
select name
from emp
group by name
having count(name)>1;
说明:名字重复,说明同一个名字有多条数据,可以先按照名字分组,分组之后再过滤行数大于1的,就表示同一个名字至少有2条记录,重复了
5、查询各部门薪水大于10000的男性员工的平均薪水
select depart,avg(salary)
from emp
where salary>10000 and sex='男'
group by depart;
说明:这里需要注意题目要求是查询薪水大于10000的男性员工,这个是在按部门分组前就过滤,在过滤后的结果集中再查询各个部门的平均薪水
6、有两个表分别如下:
表A(varchar(32) name, int grade) 数据:zhangshan 80, lisi 60, wangwu 84
表B(varchar(32) name, int age) 数据:zhangshan 26, lisi 24,wangwu 26, wutian 26
写SQL语句得到如下查询结果:
| NAME | GRADE | AGE |
|---|---|---|
| zhangshan | 80 | 26 |
| lisi | 60 | 24 |
| wangwu | 84 | 26 |
| wutian | null | 26 |
SELECT B.NAME,A.grade,B.age
FROM B left join A
ON A.NAME = B.NAME
这里wutian再A表中没有记录,但还是需要返回结果,所以应该将B表作为外表进行外连接查询。
7、现在有员工表、部门表和薪资表。
部门表:depart的字段有depart_id, name;
员工表:staff 的字段有 staff_id,name, age, depart_id;
薪资表:salary 的字段有 salary_id,staff_id,salary,month。
(问题a):求每个部门’2016-09’月份的部门薪水总额
SELECT dep.NAME,
sum( sal.salary )
FROM salary sal
JOIN staff sta ON sal.staff_id = sta.staff_id
JOIN depart dep ON sta.depart_id = dep.depart_id
WHERE YEAR ( sal.MONTH ) = 2016
AND MONTH ( sal.MONTH ) = 9
GROUP BY dep.depart_id
(问题b):求每个部门的部门人数,要求输出部门名称和人数
SELECT
dep.NAME,
count( sta.staff_id )
FROM staff sta
JOIN depart dep ON dep.depart_id = sta.depart_id
GROUP BY sta.depart_id
(问题c):求公司每个部门的月支出薪资数,要求输出月份和本月薪资总数
SELECT
dep.NAME,
sal.MONTH,
sum( sal.salary )
FROM depart dep
JOIN staff sta ON dep.depart_id = sta.depart_id
JOIN salary sal ON sta.staff_id = sal.staff_id
GROUP BY dep.depart_id, sal.MONTH
六、索引
1、索引的效果:索引能够加快查询效率
2、索引的代价:空间,使得增删改的效率降低
3、索引的核心数据结构:B+树,本质上面是(N叉操作数)