一、集群概述
1、集群简介
简单的说,集群就是指一组(若干个)相互独立的计算机,利用高速通信网络组成的一个较大的计算机服务系统、每个集群节点(即集群中的每台计算机)都是运行各自服务的独立服务器。这些服务器之间可以彼此通信,协同向用户提供应用程序、系统资源和数据,并以单一系统的模式加以管理。当用户客户机请求集群系统时,集群给用户的感觉就是一个单一独立的服务器,而实际上用户请求的是一组集群服务器。
打开谷歌、百度的页面,相信你会觉得看起来好简单啊,也许你用几分钟就可以制作出相似的网页,而实际上,这个页面是由成千上万台服务器集群协同工作的结果。那么,这么多的服务器维护和管理,以及相互协调工作就是读者你的工作职责了。
一句话,集群就是一堆服务器做同一件事,这些机器可能需要整个技术团队架构、设计、统一协调管理,这些机器可以分布在一个机房,也可以分布在全国全球各个地区的多个机房。
2、集群基本特点
1. 高性能(Performance)
一些国家重要的计算密集型应用(如:天气预报、核试验模拟等),需要计算机有很强的运算处理能力。以全世界现有的技术,即使是大型机,其计算能力也是有限的,很难单独完成此任务。因为计算时间可能会相当长,也许几天,甚至几年或更久。因此,对于这类复杂的计算业务,一般都会使用计算机集群技术,集中有几十上百台,甚至成千上万台计算机。
大家耳熟能详的大型网站谷歌、百度、淘宝等,都不是几台大型机可以搞定的,都有成千上万台服务器组成的高性能集群,分布于不同的地点。
假如你配一个LNMP环境,每次只需要服务10个并发请求,那么单台服务器一定会比多个服务器集群要快。只有当并发或总请求数量超过单台服务器的承受能力时,服务器集群才会体现出优势。
2. 价格有效性(Cost-effectiveness)
通常一套系统集群架构,只需要几台或数十台服务器主机即可。与动则价值上百万的专用超级计算机相比便宜了很多。在达到同样性能需求的条件下,采用计算机集群架构比采用同等运算能力的大型计算机具有更高的性价比。
3. 可伸缩性(Scalability)
当服务负载、压力增长时,针对集群系统进行较简单的扩展即可满足需求,且不会降低服务质量。通常情况下,硬件设备若想扩展性能能力,不得不购买增加新的CPU和存储器设备,如果加不上去了,就不得不购买更高性能的服务器,就拿我们现有的服务器来讲,可以增加的设备总是有限的。如果采用集群技术,则只需要将新的单个服务器加入现有集群架构中即可,从访问的客户角度来看,系统服务无论是连续性还是性能上都几乎没有变化,系统在不知不觉中完成了升级,加大了访问能力,轻松地实现了扩展。集群系统中的结点数目可以增长到几千乃至上万个,其伸缩性远超过单台超级计算机。
4. 高可用性(Availability)
单一的计算机系统总会面临设备损毁的问题,例如:CPU、内存、主板、电源、硬盘等,只要一个部件坏掉,这个计算机系统就可能会宕机,无法正常提供服务。在集群系统中,尽管部分硬件和软件也还是会发生故障,但整个系统的服务可以是每天24x7可用的。集群架构技术,可以使得系统在若干硬件设备故障发生时仍可以继续工作,这样就将系统的停机时间减少到了最小。集群系统在提高系统可靠性的同时,也大大减小了系统故障带来的业务损失,目前几乎100%的互联网的网站都要求7*24小时提供服务的。
二、集群分类
1、集群的常见分类
计算机集群架构按功能和结构可以分成以下几类:
- 负载均衡集群(load balancing clusters),简称LBC或者LB。
- 高可用性集群(High-availiability(HA) clusters),简称HAC。
- 高性能计算集群(High-performance(HPC) clusters),简称HPC。
- 网格计算(Grid computing)。
提示:负载均衡集群和高可用性集群是互联网行业常用的集群架构模式。
2、LB(Load Balancing)负载均衡集群
Load Balancing,负载均衡(增加处理能力),有一定高可用能力,但不是高可用集群,是以提高服务的并发处理能力为根本着眼点
负载平衡(Load balancing)是一种计算机网络技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁盘驱动器或其他资源中分配负载,以达到最佳化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。这是来自维基百科的介绍。负载均衡的目的,就在于平衡负载,给用户提供优质,可靠,稳定的服务。
负载均衡集群中有一个分发器或者叫调度器,我们将其称之为Director,它处在多台服务器的上面,分发器根据内部锁定义的规则或调度方式从下面的服务器群中选择一个以此来响应客户端发送的请求。

负载均衡集群为企业提供了更为实用、性价比更高的系统架构解决方案。负载均衡集群可以把很多客户集中的访问请求负载压力尽可能平均地分摊在计算机集群中处理。客户访问请求负载通常包括应用程序处理负载和网络流量负载。这样的系统非常适合使用同一组应用程序为大量用户提供服务的模式,每个节点都可以承担一定的访问请求负载压力,并且可以实现访问请求在各节点之间动态分配,以实现负载均衡。
负载均衡集群运行时,一般通过一个或多个前端负载均衡器将客户访问请求分发到后端的一组服务器上,从而达到整个系统的高性能和高可用性。这样的计算机集群有时也被称为服务器群(ServerFarm)。一般高可用性集群和负载均衡集群会使用类似的技术,或同时具有高可用和负载均衡的特点。
负载均衡集群的作用:
- 分担用户访问请求或数据流量(负载均衡)。
- 保持业务连续性,即7*24小时服务(高可用性)。
- 应用web业务,以及数据库从库.当然也包括其他应用业务
负载均衡产品分类:
1)软件负载均衡设备
① LVS
LVS(四层路由设备),是由中国人章文松研发的(阿里巴巴的副总裁)根据用户请求的IP与端口号,实现将用户的请求分发至不同的主机。
② HAproxy
主要功能是针对http协议实现负载均衡,也可以实现tcp(mysql,smtp)等协议的负载均衡
③ NGINX
是由俄罗斯人开发的,主要功能是针对http,smtp,pop3,imap等协议实现负载均衡,只负责解析有限的七层协议
对比:

2)硬件负载均衡设备
负载均衡器
是一种采用各种分配算法把网络请求分散到一个服务器集群中的可用服务器上去,通过管理进入的Web数据流量和增加有效的网络带宽,从而使网络访问者获得尽可能最佳的联网体验的硬件设备。负载均衡器有多种多样的形式,除了作为独立意义上的负载均衡器外,有些负载均衡器集成在交换设备中,置于服务器与Internet链接之间,有些则以两块网络适配器将这一功能集成到PC中,一块连接到Internet上,一块连接到后端服务器群的内部网络上。一般而言,硬件负载均衡在功能、性能上优于软件方式,不过成本昂贵。当Web服务器为图像服务、SSL(安全套接层)会话或数据库事务而进行优化时,负载均衡器可以体现特别的价值。
软件与硬件负载均衡的比较:
基于硬件的方式,能够直接通过智能交换机实现,处理能力更强,而且与系统无关,这就是其存在的理由.但其缺点也很明显:
首先是贵,这个贵不仅是体现在一台设备上,而且体现在冗余配置上.很难想象后面服务器做一个集群,但最关键的负载均衡设备却是单点配置,一旦出了问题就全趴了.
第二是对服务器及应用状态的掌握:硬件负载均衡,一般都不管实际系统与应用的状态,而只是从网络层来判断,所以有时候系统处理能力已经不行了,但网络可能还来得及反应(这种情况非常典型,比如应用服务器后面内存已经占用很多,但还没有彻底不行,如果网络传输量不大就未必在网络层能反映出来)。 所以硬件方式更适用于一大堆设备、大访问量、简单应用。
软件方式,其实也分多种情况,这里只讲一下典型的专业负载均衡软件。看了硬件方式的不足就比较容易理解专业负载均衡软件的优点了:
首先是基于系统与应用的负载均衡,能够更好地根据系统与应用的状况来分配负载。这对于复杂应用是很重要的。
第二是性价比,实际上如果几台服务器,用F5之类的绝对是杀鸡用牛刀(而且得用两把牛刀),而用软件就要合算得多,因为服务器同时还可以跑应用。
3、HA(High Availability)高可用集群
高可用性(HA)集群通过一组计算机系统提供透明的冗余处理能力,从而实现不间断应用的目标。
高可用性(High Availability,简称HA)集群是共同为客户机提供网络资源的一组计算机系统。其中每一台提供服务的计算机称为节点(Node)。当一个节点不可用或者不能处理客户的请求时,该请求会及时转到另外的可用节点来处理,而这些对于客户端是透明的,客户不必关心要使用资源的具体位置,集群系统会自动完成。
一般是指在集群中任意一个节点失效的情况下,该节点上的所有任务会自动转移到其他正常的节点上。此过程并不影响整个集群的运行。
提示:不同的业务会有若干秒的切换时间,db业务明显长于web业务切换时间。
当集群中的一个节点系统发生故障时,运行着的集群服务会迅速做出反应,将该系统的服务分配到集群中其他正在工作的系统上运行。考虑到计算机硬件和软件的容错性,高可用性集群的主要目的是为了使集群的整体服务尽可能可用。如果高可用性集群中的主节点发生了故障,那么这段时间内将由次节点代替它。次节点通常是主节点的镜像。当它代替主节点时,它可以完全接管主节点(包括正地址及其他资源),因此,使集群系统环境对于户来说是一致的,即不会影响用户的访问
高可用性集群使服务器系统的运行速度和响应速度会尽可能地快。它们经常利用在多台机器上运行的冗余节点和服务来相互跟踪。如果某个节点失败,它的替补者将在几秒钟或更短时间内接管它的职责。因此对于用户而言,集群里的任意一台机器宕机,业务都不会受影响(理论情况下)
高可用性集群的作用:
- 当一台机器宕机时,另外一台机器接管(IP资源和服务资源)
- 负载均衡器之间,主数据库及主存储之间。
HA集群系统硬件拓扑形式:
基于共享磁盘的HA集群系统通过共享盘柜实现集群中各节点的数据共享,包含主服务器、从服务器、存储阵列三种主要设备,以及设备间的心跳连接线。
而基于磁盘镜像的HA集群系统不包含存储阵列。集群中两种服务器的本地硬盘通过数据镜像技术,实现集群中各节点之间的数据同步,从而实现集群的功能。
实际应用中,将节点1配置成“主服务器”,节点2配置成“从服务器”,主从服务器有各自的IP地址,通过HA集群软件控制,主从服务器有一个共同的虚拟IP地址,客户端仅需使用这个虚拟IP,而不需要分别使用主从IP地址。这种措施是HA集群的首要技术保证,该技术确保集群服务的切换不会影响客户IP层的访问。
公网(Public Network)是应用系统实际提供服务的网络,私网(Private Network)是集群系统内部通过心跳线连接成的网络。
心跳线是HA集群系统中主从节点通信的物理通道,通过HA集群软件控制确保服务数据和状态同步。不同HA集群软件对于心跳线的处理有各自的技巧,有的采用专用板卡和专用的连接线,有的采用串并口或USB口处理,有的采用TCP/IP网络处理,其可靠性和成本都有所不同。近几年,基于TCP/IP技术的心跳线因其成本低、性能优异而被广泛采用。具体实现中主从服务器上至少各需配置两块网卡。

HA集群软件体系结构:
HA集群软件是架构在操作系统之上的程序,其主要由守护进程、应用程序代理、管理工具、开发脚本等四部分构成,应用服务系统是为客户服务的应用系统程序,比如MS SQL Server,Oracle,Sybase,DB2 UDB,Exchange,Lotus Notes等应用系统软件。
不是每一个应用程序都能够实现HA集群管理,也不是每一个HA集群软件可以管理所有的应用程序,这是因为其代理模块(Agent)有不同的功能。HA软件的代理模块一般支持使用频度最高的软件,如上述所列举的数据库系统和邮件系统,但为了能够支持更多应用实现HA集群,有的HA软件开放二次开发接口。
HA集群软件体系结构:
HA集群软件是架构在操作系统之上的程序,其主要由守护进程、应用程序代理、管理工具、开发脚本等四部分构成,应用服务系统是为客户服务的应用系统程序,比如MS SQL Server,Oracle,Sybase,DB2 UDB,Exchange,Lotus Notes等应用系统软件。
不是每一个应用程序都能够实现HA集群管理,也不是每一个HA集群软件可以管理所有的应用程序,这是因为其代理模块(Agent)有不同的功能。HA软件的代理模块一般支持使用频度最高的软件,如上述所列举的数据库系统和邮件系统,但为了能够支持更多应用实现HA集群,有的HA软件开放二次开发接口。

主/从 英文名称“Active/Standby”,或者“Active/Passive”。为了提供最大的可用性,以及对性能的最小影响,“主/从”模型需要一个节点在正常工作时处于备用状态,主节点处理客户机的请求,而备用节点处于空闲状态。当主节点出现故障时,备用节点会接管主节点的工作,继续为客户机提供服务,并且不会有任何性能上的影响。
混合型(Hybrid) 是上面两种模型的结合,只针对关键应用进行故障转移,这样可以对这些应用实现可用性的同时让非关键的应用在正常运作时也可以在服务器上运行。当出现故障时,出现故障服务器上的不太关键的应用就不可用了,但是那些关键应用会转移到另一个可用的节点上,从而达到性能和容错两方面的平衡。
不同HA集群软件支持不同的部署模式,一般有以下三种情况:
双机模式 非常普遍使用的一种方式,俗称“双机热备”。使用在应用系统单一、要求可用性高的环境中,由一个主服务器、一个从服务器和一个存储阵列等三个设备组成。
1+I模式:系统由一个主节点、若干个(I个)从节点以及一些辅助设备(存储阵列)等组成。使用在应用系统单一,要求可用性能极高的核心业务系统中。
N+I模式:系统由多个主节点、若干个从节点以及一些辅助设备(存储阵列、交换机)等组成。在实际应用中,一些用户并不满足上述两种模式,认为“冗余设备”太多,需要多个主节点(N个)可以灾备到任意多个(I个)节点上。根据应用的级别,调整从节点的数量,可以为一个,也可以为多个。主节点的数量可以为一个或者多个,根据应用需要随时调整搭配,但主节点为多个并不是同一个应用的“并行处理”,而是不同的应用。
集群系统状态监测和故障响应:
1. 网卡故障
集群结构中每个节点都通过双网卡与工作网络相连,即一主(H)一备(B)两条链路。在各节点正常工作的时候,工作网络除用于传递工作数据外,也用于传递H-B信号。同时心跳网络只传递H-B信号。即每隔一段时间各节点之间相互传递H-B信号,确认各节点都处于正常工作状态。
因此,有了H-B后,集群可以很轻易地发现节点的网卡故障,因为一旦某块网卡发生故障,发往该块网卡的H-B就会丢失。此时节点上的集群管理软件会产生一个网卡互换的事件,即将主备网卡互换,包括各种地址的互换和工作状态的互换。并通知集群中各节点及工作网络。网卡互换通常在几秒内就可完成,并且这种转换对应用来说是透明的,只发生延迟但连接并不中断。
2. 网络故障
如果发往某一个节点双网卡上的H-B包全都丢失,而心跳网络上的H-B仍然存在,那么集群软件可以断定集群节点仍然正常,是工作网络发生故障。此时集群软件则只能发出告警,并提供系统一个中断入口,可以通过该入口确定系统执行其他网络恢复的操作。
3. 节点故障
如果不仅工作网络上的H-B信号全部丢失,而且心跳网络上的H-B也丢失,那么集群软件将断定该节点发生故障。放在共享存储上的资源将由其他节点接管(根据N节点配置和N+1节点配置的不同,接管的节点将不同),接管的操作将由集群软件和节点的操作系统共同配合来完成。
当整个节点发生故障时,集群软件将故障节点的工作地址转移到接管节点上,对于网络上的Client来讲,服务地址没有发生变化。
高可用性集群的作用:
- 当一台机器宕机时,另外一台机器接管(IP资源和服务资源)
- 负载均衡器之间,主数据库及主存储之间。
高可用性集群典型常用开源软件:keepalived、heartbeat
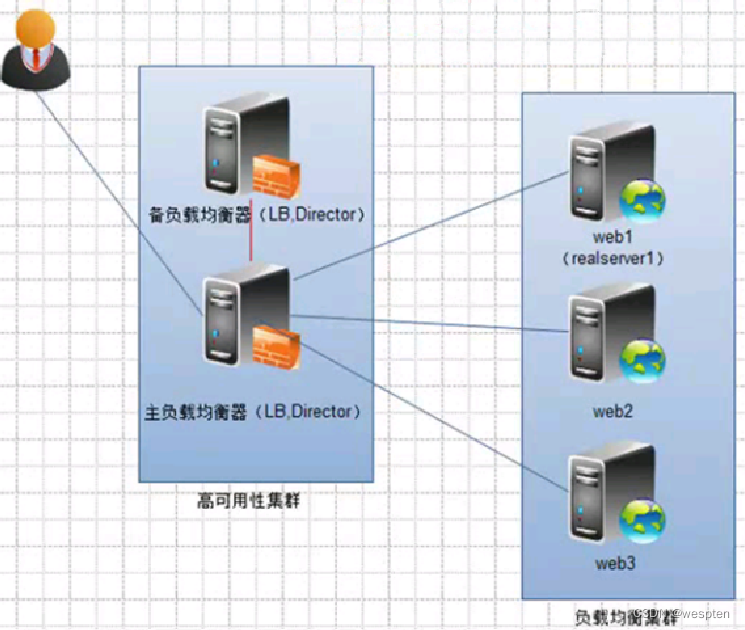
建议:能做负载均衡就不做高可用。
4、HPC(High performance)高性能计算集群
HPC是高性能计算(High Performance Computing)机群的简称。指能够执行一般个人电脑无法处理的大资料量与高速运算的电脑,其基本组成组件与个人电脑的概念无太大差异,但规格与性能则强大许多。现有的超级计算机运算速度大都可以达到每秒一兆(万亿,非百万)次以上。“超级计算”(supercomputing)这名词第一次出现,是在1929年《纽约世界报》关于IBM为哥伦比亚大学建造大型报表机(tabulator)的报道。
计算机群:
高性能计算(High Performance Computing)机群,简称HPC机群。构建高性能计算系统的主要目的就是提高运算速度,要达到每秒万亿次级的计算速度,对系统的处理器、内存带宽、运算方式、系统I/O、存储等方面的要求都十分高,这其中的每一个环节都将直接影响到系统的运算速度。这类机群主要解决大规模科学问题的计算和海量数据的处理,如科学研究、气象预报、计算模拟、军事研究、CFD/CAE、生物制药、基因测序、图像处理等等。
信息服务机群的应用范围很广,包括如数据中心、电子政务、电子图书馆、大中型网站、网络游戏、金融电信服务、城域网/校园网、大型邮件系统、VOD、管理信息系统等等。就其实现方式上分,还可以分为负载均衡机群、高可用机群等。
简单的说,高性能计算(High Performance Computing)是计算机科学的一个分支,研究并行算法和开发相关软件,致力于开发高性能计算机(High Performance Computer)。
随着信息化社会的飞速发展,人类对信息处理能力的要求越来越高,不仅石油勘探、气象预报、航天国防、科学研究等需求高性能计算机,而金融、政府信息化、教育、企业、网络游戏等更广泛的领域对高性能计算的需求迅猛增长。
集群分为下面几种:
1. 主/主 (Active/active)
这是最常用的集群模型,它提供了高可用性,并且在只有一个节点在线时提供可以接受的性能,该模型允许最大程度的利用硬件资源。每个节点都通过网络对客户机提供资源,每个节点的容量被定义好,使得性能达到最优,并且每个节点都可以在故障转移时临时接管另一个节点的工作。所有的服务在故障转移后仍保持可用,但是性能通常都会下降。
2. 主/从(Active/passive)
为了提供最大的可用性,以及对性能最小的影响,Active/passive模型需要一个在正常工作时处于备用状态,主节点处理客户机的请求,而备用节点处于空闲状态,当主节点出现故障时,备用节点会接管主节点的工作,继续为客户机提供服务,并且不会有任何性能上影响。
3. 混合型(Hybrid)
混合是上面两种模型的结合,只针对关键应用进行故障转移,这样可以对这些应用实现可用性的同时让非关键的应用在正常运作时也可以在服务器上运行。当出现故障时,出现故障的服务器上的不太关键的应用就不可用了,但是那些关键应用会转移到另一个可用的节点上,从而达到性能和容错两方面的平衡。
HPC集群性能优化:
1. 高性能计算集群选择适合的内存
高性能计算集群依赖于并行处理系统,所以高性能计算集群信息需要快速的传入与传出内存。高性能计算集群系统往往是I/O密集型的,因此高性能计算集群选择正确的内存配置,可以显著提升高性能计算集群应用程序性能。
高性能计算集群系统依赖于DIMM模块,因为高性能计算集群是针对并行系统设计的。
高性能计算集群有三种DIMM内存可用:UDIMM内存、RDIMM内存和LRDIMM内存。高性能计算集群在处理较大型工作负载时,无缓冲DIMM速度快、廉价但不稳定。寄存器式DIMM内存稳定、扩展性好、昂贵,高性能计算集群对内存控制器的电气压力小。高性能计算集群同样在许多传统服务器上使用。降载DIMM内存是寄存器式内存的替代品,高性能计算集群能提供高内存速度,降低服务器内存总线的负载,而且功耗更低。
2. 高性能计算集群升级设施
高性能计算集群应用程序正在迅速增长,所以高性能计算集群体系未来的扩展能力需要重视。
高性能计算集群系统设计与传统数据中心基础设施设计的一大区别就是选择现成工具或定制系统。现成的高性能计算集群只能在很小的范围内进行扩展,高性能计算集群限制了未来增长。HPC定制可以保持一个开放式的设计,让企业在将来获得更好的扩展功能。然而,高性能计算集群额外的功能对于定制系统来说是一笔不小的代价,比购买现成高性能计算集群系统要高得多。
3. 高性能计算集群系统一致
高性能计算集群系统初次上线时,高性能计算集群所有的配置都很完美,但随着时间流逝,高性能计算集群配置会变得不一致。
高性能计算集群中出现不一致,高性能计算集群管理员可能会看到一些零星的异常货变化,高性能计算集群影响应用程序性能。考虑到潜在的性能, IT部门需要实施策略来确认高性能计算集群系统中都运行着什么应用程序, 并想办法让高性能计算集群配置同步。这些高性能计算集群检查每季度应该进行,或者每年不少于两次。
4. 高性能计算集群能耗
高性能计算集群在过去15年中,高性能计算集群能源成本随着高性能计算密度增加而急剧上升。现在高性能计算集群普通的服务器开销为每机柜30kw,高性能计算集群这个数字还在不断上升。由于高性能计算集群高密度,高性能计算集群高效率数据中架构基础设施与高性能计算集群冷却系统变得至关重要。
在高性能计算集群数据中心,高性能计算集群高电压电直接供给到机架,而不是采用传统的208伏降压,这样可以节约电子电力设备因电力转换的损耗。高性能计算集群利用节能型泵取代了嘈杂、低效率的风扇。
三、常用的集群软硬件介绍及选型
1、常见的集群软硬件产品
互联网企业常用的开源集群软件有:nginx,lvs,haproxy,keepalived,heartbeat。
互联网企业常用的商业集群硬件有:F5,Netscaler,Radware,A10等,工作模式相当于haproxy的工作模式。
2、集群软硬件产品如何选型
当企业业务重要,技术力量又薄弱,并且希望出钱购买产品及更好的服务时,可以选择硬件负载均衡产品,如FS、Netscaler、Radware等,此类公司多为传统的大型非互联网企业,如银行、证券、金融、宝马、奔驰等。
对于门户网站来说,大多会并用软件及硬件产品来分担单一产品的风险,如淘宝、腾讯、新浪等。融资了的企业会购买硬件产品,如赶集、58等网站。
中小型互联网企业,由于起步阶段无利润可赚或者利润很低,会希望通过使用开源免费的方案来解决问题,并且会雇佣专门的运维人员进行维护。例如:51cto.com等
相比较而言,商业的负载均衡产品成本高,性能好,更稳定,缺点不能二次开发,特别是大型网站,而且开源的负载均衡软件对运维人员的运维能力要求较高,如果运维开发、优化能力强,那么开源软件的负载均衡也是可以用的。
3、企业运维中如何选择开源集群软件产品
中小企业互联网公司网站并发访问和总访问量不是很大的情况下,建议首选nginx负载均衡,理由是nginx负载均衡配置简单、使用方便,安全稳定,社区活跃,使用的人逐渐增多,曾流行趋势,另外一个实现负载均衡的类位产品为Haproxy(支持L4和L7负载,同样优秀,但社区不如Nginx活跃)。
如果要考虑nginx负载均衡的高可用功能,建议首选keepalived软件,理由是安装、配置简覃令使用方便,安全稳定,和keepalived服务类似的高可用软件还有heartbeat。
四、负载均衡主要方式
负载均衡&代理
负载均衡也叫代理,是代理的一种。
正向代理:
只用于代理内部网络对Internet的连接请求,客户机必须指定代理服务器,并将本来要直接发送到Web服务器上的http请求发送到代理服务器中,正向代理指的是客户端代理,是由用户控制并知晓的代理方式,如我不能访问fb,然后使用了某国外服务器作为跳板机,最后成功访问了就是正向代理。
反向代理:
指以代理服务器来接受Internet上的连接请求,然后将请求转发给内部网络上的服务器;并将从服务器上得到的结果返回给Internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器,反向代理指的是服务端代理,在大型网站背后并不是只有一台机器提供服务,比如我访问微博,微博的某一个反向代理服务器将我解析到内部服务器的一台机器,然后这台机器给我提供微博的消息(当然实际情况比这个复杂的多),这些对于用户都是不可见的,我们只会感觉只有一台机器与我交互。
1、http重定向
原理:
下载网站用的较多,其实也算一种负载均衡,工作在应用层的业务代码中 根据用户的http请求计算出一个真实的web服务器地址,并将该web服务器地址写入http重定向响应中返回给客户浏览器,由浏览器重新进行访问。

优缺点:
优点:
1. 比较简单。
缺点:
1. 客户浏览器需要多次请求服务器才能完成一次访问,性能较差。
2. http重定向服务器自身的处理能力可能成为瓶颈。
3. 使用http302响应重定向,有可能使搜索引擎判断为SEO作弊,降低搜索排名。
2、DNS负载均衡
原理:
DNS负载提供域名到IP解析的过程,我们实例查看百度的域名解析其实是这时候DNS服务器也就充当了负载均衡,很多域名运营商提供的智能dns以及多线解析都是利用了DNS负载均衡的技术,开源的BIND就可提供电信联通多线解析等强大的技术。
在DNS服务器上配置多个域名对应IP的记录。例如一个域名www.baidu.com对应一组web服务器IP地址,域名解析时经过DNS服务器的算法将一个域名请求分配到合适的真实服务器上。


优缺点:
优点:
将负载均衡的工作交给了DNS,省却了网站管理维护负载均衡服务器的麻烦,同时许多DNS还支持基于地理位置的域名解析,将域名解析成距离用户地理最近的一个服务器地址,加快访问速度吗,改善性能。
缺点:
目前的DNS解析是多级解析,每一级DNS都可能化缓存记录A,当摸一服务器下线后,该服务器对应的DNS记录A可能仍然存在,导致分配到该服务器的用户访问失败。
DNS负载均衡的控制权在域名服务商手里,网站可能无法做出过多的改善和管理。
不能够按服务器的处理能力来分配负载。DNS负载均衡采用的是简单的轮询算法,不能区分服务器之间的差异,不能反映服务器当前运行状态,所以其的负载均衡效果并不是太好。
可能会造成额外的网络问题。为了使本DNS服务器和其他DNS服务器及时交互,保证DNS数据及时更新,使地址能随机分配,一般都要将DNS的刷新时间设置的较小,但太小将会使DNS流量大增造成额外的网络问题。
3、反向代理负载均衡
原理:
反向代理处于web服务器这边,反向代理服务器提供负载均衡的功能,同时管理一组web服务器,它根据负载均衡算法将请求的浏览器访问转发到不同的web服务器处理,处理结果经过反向服务器返回给浏览器。
例如:浏览器访问请求的地址是反向代理服务器的地址114.100.80.10,反向代理服务器收到请求,经过负载均衡算法后得到一个真实物理地址10.0.0.3,并将请求结果发给真实服务器,真实服务器处理完后通过反向代理服务器返回给请求用户。
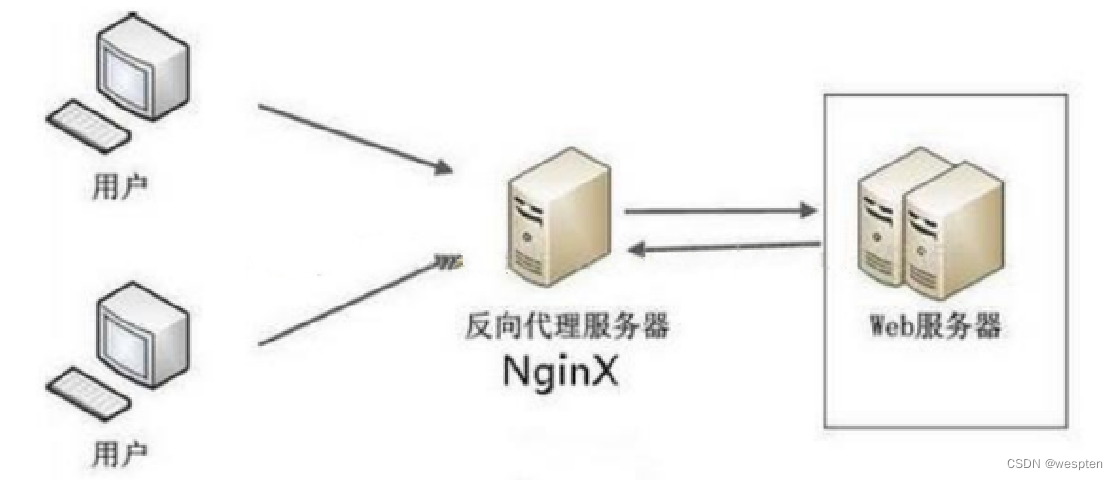
优缺点:
优点:
部署简单,处于http协议层面。
缺点:
使用了反向代理服务器后,web 服务器地址不能直接暴露在外,因此web服务器不需要使用外部IP地址,而反向代理服务作为沟通桥梁就需要配置双网卡、外部内部两套IP地址。
4、IP网络层负载均衡
原理:
在网络层和传输层(IP和端口)通过修改目标地址进行负载均衡。用户访问请求到达负载均衡服务器,负载均衡服务器在操作系统内核进程获取网络数据包,根据算法得到一台真实服务器地址,然后将用户请求的目标地址修改成该真实服务器地址,数据处理完后返回给负载均衡服务器,负载均衡服务器收到响应后将自身的地址修改成原用户访问地址后再讲数据返回回去。类似于反向服务器负载均衡。
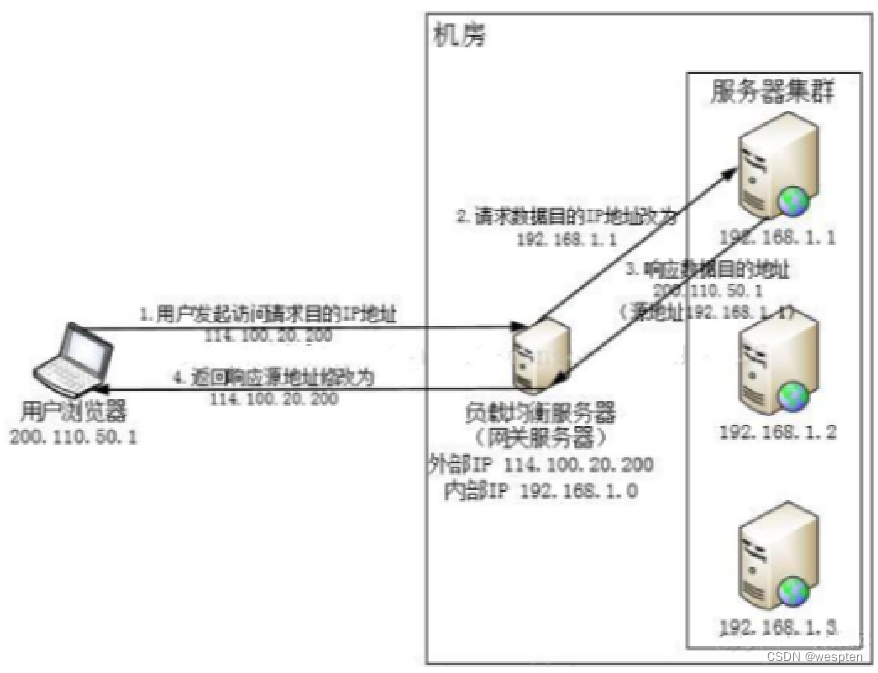
优缺点:
优点:在响应请求时速度较反向服务器负载均衡要快。
缺点:无法处理更高级的请求
5、数据链路层负载均衡
原理:
在数据链路层修改Mac地址进行负载均衡。 负载均衡服务器的IP和它所管理的web 服务群的虚拟IP一致; 负载均衡数据分发过程中不修改访问地址的IP地址,而是修改Mac地址; 通过这两点达到不修改数据包的原地址和目标地址就可以进行正常的访问。

优缺点:
优点:
不需要负载均衡服务器进行IP地址的转换。
数据响应时,不需要经过负载均衡服务器。
缺点:
负载均衡服务器的网卡带宽要求较高。
6、F5硬件负载均衡
原理:
F5 BIG-IP提供12种灵活的算法将所有流量均衡的分配到各个服务器,而面对用户,只是一台虚拟服务器。
健康性检查。F5 BIG-IP可以确认应用程序能否对请求返回对应的数据。假如F5 BIG-IP后面的某一台服务器发生服务停止、死机等故障,F5会检查出来并将该服务器标识为宕机,从而不将用户的访问请求传送到该台发生故障的服务器上。这样,只要其它的服务器正常,用户的访问就不会受到影响。宕机一旦修复,F5 BIG-IP就会自动查证应用保证对客户的请求作出正确响应并恢复向该服务器传送。
F5 BIG-IP具有动态Session的会话保持功能,笔者也是在网站中使用的F5将用户IP与Session通过F5进行的绑定,使其Session保持一致。
F5 BIG-IP的iRules功能可以做HTTP内容过滤,根据不同的域名、URL,将访问请求传送到不同的服务器。
优缺点:
优点:性能好
缺点:成本高,配置冗余
7、四层负载和七层负载
所谓四层就是基于IP+端口的负载均衡,主要代表有lvs。
七层负载也称内容交换,就是基于URL等应用层信息的负载均衡,主要代表有nginx。

五、Nginx负载均衡集群实战
1、负载均衡介绍
服务器负载均衡有三大基本Feature:负载均衡算法,健康检查和会话保持,这三个Feature是保证负载均衡正常工作的基本要素。
负载均衡设备的实现原理是把多台服务器的地址映射成一个对外的服务IP(我们通常称之为VIP,关于服务器的映射可以直接将服务器IP映射成VIP地址,也可以将服务器IP:Port映射成VIP:Port,不同的映射方式会采取相应的健康检查,在端口映射时,服务器端口与VIP端口可以不相同),这个过程对用户端是透明的,用户实际上不知道服务器是做了负载均衡的,因为他们访问的还是一个目的IP,那么用户的访问到达负载均衡设备后,如何把用户的访问分发到合适的服务器就是负载均衡设备要做的工作了。
2、Nginx配置负载均衡使用的算法
- 轮询(默认)每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
- weight指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
- ip_hash每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
- fair(第三方)按后端服务器的响应时间来分配请求,响应时间短的优先分配。
- url_hash(第三方)按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
3、健康检查
健康检查用于检查服务器开放的各种服务的可用状态。负载均衡设备一般会配置各种健康检查方法,例如Ping,TCP,UDP,HTTP,FTP,DNS等。Ping属于第三层的健康检查,用于检查服务器IP的连通性,而TCP/UDP属于第四层的健康检查,用于检查服务端口的UP/DOWN,如果要检查的更准确,就要用到基于7层的健康检查,例如创建一个HTTP健康检查,Get一个页面回来,并且检查页面内容是否包含一个指定的字符串,如果包含,则服务是UP的,如果不包含或者取不回页面,就认为该服务器的Web服务是不可用(DOWN)的。创建健康检查时可以设定检查的间隔时间和尝试次数,例如设定间隔时间为5秒,尝试次数为3,那么负载均衡设备每隔5秒发起一次健康检查,如果检查失败,则尝试3次,如果3次都检查失败,则把该服务标记为DOWN,然后服务器仍然会每隔5秒对DOWN的服务器进行检查,当某个时刻发现该服务器健康检查又成功了,则把该服务器重新标记为UP。健康检查的间隔时间和尝试次数要根据综合情况来设置,原则是既不会对业务产生影响,又不会对负载均衡设备造成较大负担。
nginx配置负载均衡工作在TCP/IP协议的第七层,即应用层,属于七层负载均衡。
4、会话保持
会话保持用于保持会话的连续性和一致性,由于服务器之间很难做到实时同步用户访问信息,这就要求把用户的前后访问会话保持到一台服务器上来处理。举个例子,用户访问一个电子商务网站,如果用户登录时是由第一台服务器来处理的,但用户购买商品的动作却由第二台服务器来处理,第二台服务器由于不知道用户信息,所以本次购买就不会成功。这种情况就需要会话保持,把用户的操作都通过第一台服务器来处理才能成功。当然并不是所有的访问都需要会话保持,例如服务器提供的是静态页面比如网站的新闻频道,各台服务器都有相同的内容,这种访问就不需要会话保持。负载均衡设备一般会默认配置一些会话保持的选项,例如源地址的会话保持,Cookie会话保持等,基于不同的应用要配置不同的会话保持,否则会引起负载的不均衡甚至访问异常。
5、正向代理与反向代理
1. 正向代理的概念
正向代理,也就是传说中的代理,他的工作原理就像一个跳板,简单的说,我是一个用户,我访问不了某网站,但是我能访问一个代理服务器,这个代理服务器呢,他能访问那个我不能访问的网站,于是我先连上代理服务器,告诉他我需要那个无法访问网站的内容,代理服务器去取回来,然后返回给我。从网站的角度,只在代理服务器来取内容的时候有一次记录,有时候并不知道是用户的请求,也隐藏了用户的资料,这取决于代理告不告诉网站。
结论就是,正向代理是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。
2. 反向代理的概念
例用户访问 http://www.test.com/readme,但www.test.com上并不存在readme页面,他是偷偷从另外一台服务器上取回来,然后作为自己的内容返回用户,但用户并不知情。这里所提到的 www.test.com 这个域名对应的服务器就设置了反向代理功能。
结论就是,反向代理正好相反,对于客户端而言它就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理的命名空间(name-space)中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端,就像这些内容原本就是它自己的一样。
3. 两者区别
- 从用途上来讲:
正向代理的典型用途是为在防火墙内的局域网客户端提供访问Internet的途径。正向代理还可以使用缓冲特性减少网络使用率。反向代理的典型用途是将防火墙后面的服务器提供给Internet用户访问。反向代理还可以为后端的多台服务器提供负载平衡,或为后端较慢的服务器提供缓冲服务。另外,反向代理还可以启用高级URL策略和管理技术,从而使处于不同web服务器系统的web页面同时存在于同一个URL空间下。
- 从安全性来讲:
正向代理允许客户端通过它访问任意网站并且隐藏客户端自身,因此你必须采取安全措施以确保仅为经过授权的客户端提供服务。反向代理对外都是透明的,访问者并不知道自己访问的是一个代理。
6、实现Nginx负载均衡的组件说明
实现Nginx负载均衡的组件主要有两个
nginx官网文档:nginx documentation
ngx_http_proxy_module //proxy代理模块。
ngx_http_upstream_module //负载均衡模块,可以实现网站的负载均衡功能及节点的健康检查。
7、Nginx负载均衡器搭建
1. 环境介绍
Nginx负载均衡至少需要三台虚拟机,一台Nginx负载均衡器,两台Web服务器
Nginx负载均衡器的安装参考前面所讲,安装命令如下:
yum install -y pcre-devel openssl-devel
useradd -s /sbin/nologin -M nginx
cd /server/tools/
wget http://nginx.org/download/nginx-1.6.3.tar.gz
tar zxvf nginx-1.6.3.tar.gz
cd nginx-1.6.3
./configure --prefix=/application/nginx-1.6.3 --user=nginx --group=nginx --with-http_ssl_module --with-http_stub_status_module
make
make install
ln -s /application/nginx-1.6.3 /application/nginx
/application/nginx/sbin/nginx两台节点Web服务器可以为Apache、Nginx等(建议一样),具体安装不再阐述,Web软件可以不一样,但要求站点文件和域名必须一样必须一样。
2. 配置负载均衡器
cd /application/nginx/conf/
egrep -v "#|^$" nginx.conf.default >nginx.conf #过滤#及空行在http段加入以下代码:
upstream bbs_server_pools {
server 192.168.80.100:80 weight=1;
server 192.168.80.101:80 weight=1;
}
server{
listen 80;
server_name bbs.etiantian.org;
location / {
proxy_pass http://bbs_server_pools;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
}
}注意:建议使用VIP而不使用主机的真实IP,便于切换,添加VIP命令:
ip addr add 192.168.80.103/24 dev eth0重启服务后查看:
netstat -lntup|grep nginx
tcp 0 0 192.168.80.103:80 0.0.0.0:* LISTEN 1826/nginx 3. 让后端服务器接收真实用户IP配置
如果负载均衡器下面的节点都是Nginx服务器,则默认情况下如果使用Nginx main日志格式,则"$http_x_forwarded_for"这个参数代表了客户端的IP地址:
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';如果负载均衡器下面的节点都是Apache服务器,则默认日志没有客户端的IP地址,需要修改Apache主配置文件中的日志格式中添加如下配置:
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{X-Forwarded-For}i\"" common
LogFormat "%{Referer}i -> %U" referer
LogFormat "%{User-agent}i" agent8、Nginx负载均衡核心组件介绍
1. Nginx upstream模块
nginx模块官网文档:nginx documentation
upstream模块介绍:
Nginx的负载均衡功能依赖于ngx_http_upstream_module模块,所支持的代理方式有proxy_pass,fastcgi_pass,memcached_pass,新版软件支持的方式所有增加。本文主要针对proxy_pass代理方式讲解。
ngx_http_upstream_module模块允许Nginx定义一组或多组节点服务器组,使用时可以通过proxy_pass代理方式把网站的请求发送到事先定义好的对应upstream组的名字上,具体写法为“proxy_pass http://www_server_pools;”其中www_server_pools就是一个upstream节点服务器组的名字。
2. upstream server标签参数
upstream模块的内容应放于nginx.oonf配置的http{}标签内.其默认调度节点算法是wrr(权重轮询weighted round-robin)
upstream模块内部server标签参数说明:
- server 192.168.80.103:80 负载均衡后面的Rs配置,可以是IP或域名,端口不写,默认是80端口。高并发场景IP可换成域名,通过DNS做负载均衡。
- weight=1 代表服务器的权重,默认值是1。权重数字越大表示接受的请求越多。
- max_fails=1 Nginx尝试连接后端主机失败的次数,这个数值是配合proxy_next_upstream,fastcgi_next_upstream and memcached_next_upstream这三个参数来使用的,当nginx接受后端服务器返回这三个参数定义的状态码时,会将这个请求转发给正常工作的后端服务器,例如404,502,503。Max-fails默认值是1;企业场景:建议2-3次。京东1次,蓝汛10次,根据业务需求去配置。
- backup 热备配置(RSs节点的高可用),当前面激活的RS都失败后会自动启用热备RS。这标志着这个服务器作为备份服务器,若主服务器全部宕机了,就会向它转发请求;注意,当负载调度算法为ip_hash时,后端服务器在负载均衡调度中的状态不能是weight和backup
- fail_timeout=10s 在max_fails定义的失败次数后,距离下次检查的间隔时间,默认是10s;如果max_fails是5,它就检测5次,如果5次都是502。那么,它就会根据fail_timeout的值,等待10s再去检查,还是只检查一次,如果持续502,在不重新加载nginx配置的情况下,每隔10s都只检测一次。常规业务2-3秒比较合理,比如京东3秒,蓝汛3秒,可根据业务需求去配置。
- down 这标志着服务器永远不可用,这个参数可配合ip_hash使用。
- max_conns=number 单个RS最大并发连接数限制,防止请求过载,保护节点服务器。
3. upstream模块调度算法
调度算法一般分为两类,第一类为静态调度算法,即负载均衡器根据自身设定的规则进行分配,不需要考虑后端节点服务器的情况,例如:rr、wrr、ip_hash等都属于静态调度算法。
第二类为动态调度算法,即负载均衡器会根据后端节点的当前状态来决定是否分发请求,例如:连接数少的优先获得请求,响巨时间短的获得请求。例如:least_conn,fair等都属于动态调度算法。
rr轮询(默认调度算法,静态调度算法)
按客户端请求顺序把客户端的请求逐一分配到不同的后端节点服务器,这相当于Lvs中的rr算法,如果后端节点服务器宕机(默认情况下nginx只检测80端口),宕机的服务器会被自动从节点服务器池中剔除,以使客户端的用户访问不受影响。新的请求会分配给正常的服务器。
wrr(权重轮询,静态调度算法)
在rr轮询算法的基础上加上权重,即为权重轮询算法,当使用该算法时,权重和用户访问成正比,权重值越大,被转发的请求也就越多:可以根据服务器的配置和性指定权重值大小,可以有效解决新旧服务器性能不均带来的请求分配问题。
ip_hash(静态调度算法)
每个请求按客户端IP的hash结果分配,当新的请求到达时,先将其客户端iP通过哈希算法哈希出一个值,在随后的客户端请求中,客户IP的哈希值只要相同,就会被分配至同一台服务器,该调度算法可以解决动态网页的session共享问题,但有时会导致请求分配不均,即无法保证1:1的负载均衡,因为在国内大多数公司都是NAT上网模式,多个客户端会对应一个外部IP,所以,这些客户端都会被分配到同一节点服务器,从而导致请求分配不均。Lvs负载均衡的-p参数、keepalived配置里的persistence_timeout 50参数都类似这个Nginx里的ip_hash参数。
注意:当负载调度算法为ip-hash时,后端服务器在负载均衡调度中的状态不能有weight和backup,即使有也不生效。
fair(动态调度算法)
此算法会根据后端节点服务器的响应时间来分配请求,响应时间短的优先分配。这是更加智能的调度算法。此种算法可以依据页面大小和加载时间长短智能地进行负载均衡,也就是根据后端服务器的响应时间来分配请求,响应时间短的优先分配:Nginx本身是不支持fair调度算法的,如果需要使用这种调度算法,必须下载Nginx的相关模块upstream_fair。
upstream www_server_pools {
server 192.168.80.103:80;
server 192.168.80.104:80;
fair;
}least_conn
least_conn算法会根据后端节点的连接数来决定分配情况,哪个机器连接数少就分发。此外还有一些第三方的调度算法.例如:url_sh、一致性HASH算法等。
一致性HASH算法
一致性HASH算法一般用于代理后端业务为缓存服务(Squid,melncached)的场景,通过将用户请求的URL或者指定字符串进行计算,然后调度到后端的服务器上,此后任何用户查找同一个URI都会被调度到这一台服务器上,因此后端的每个节点缓存的内容都是不同的,一致性HASH算法可以让后端某个或几个节点宕机后,缓存的数据动荡的最小,一致性HASH算法知识比较复杂,详细内容可以参考相关资料,这里仅仅给出配置示例:
worker_processes 1;
http {
upstream test {
consistent_hash $request_uri;
server 127.0.0.1:9001 id=1001 weight=3;
server 127.0.0.1:9002 id=1002 weight=10;
server 127.0.0.1:9003 id=1003 weight=20;
}
}Nginx本身不支持一致性HASH算法,而Nginx的分支tengine支持一致性HASH算法。
详细可见:一致性hash模块 - The Tengine Web Server
4. ngx_http_proxy_module
proxy-pass指令介绍
proxy-pass指令属于ngx_http_proxy_module模块,此模块可以将请求转发到另一台服务器,在实际的反向代理工作中,会通过location功能匹配指定的URI,然后把接收到的符合匹配URI的请求通过Proxy-pass抛给定义好的upstream节点池。
该指令官方地址见:Module ngx_http_proxy_module
例如:
location /name/ {
proxy_pass http://127.0.0.1/remote/;
}5. http proxy模块参数
Nginx的代理功能是通过http proxy模块来实现的。默认在安装Nginx时己经安装了http proxv模块,因此可直接使用http proxv模块。
下面详细解释模块中每个选项代表的含义:
- proxy_set_header 设置http请求header项传给后端服务器,例如:可实现让代理后端的服务器获取访问用户的真实lP地址。
- c11ent_body_buffer_size 用于指定客户端请求主体缓冲区大小。
- proxy_connect_timeout 表示代理与后端节点服务器连接的超时时间,即发起握手等候响应的超时时间。
- proxy_send_timeout 表示代理后端服务器的数据回传时间,即在规定时间之内后端服务器必须传完所有的数据,否则,Nginx将断开这个连接
- proxy_read_timeout 设置Nginx从代理的后端服务器获取信息的时间,表示连接建立成功后,Nginx等待后端服务器的响应时间,其实是Nginx已经进入后端的排队之中等候处理的时间
- proxy_buffer_size 设置缓冲区大小,默认该缓冲区大小等于指令proxy_buffers设置的大小。
- proxy_buffers 设置缓冲区的数量和大小。nginx从代理的后端服务器获取的响应信息,会放置到缓冲区
- proxy_busy_buffers_size 用于设置系统很忙时可以使用的proxy_buffers大小,官方推荐的大小为proxy_ buffers*2。
- proxy_temp_file_write_size 指定proxy缓存临时文件的大小
- proxy_next_upstream
语法:
proxy_next_upstream [error|timeout|invalid_header|http_500|http_502|http_503|http_504|http_404|off]确定在何种情况下请求将转发到下一个服务器。转发请求只发生在没有数据传递到客户端的过程中。
例如:
[root@lb1 conf]# vi proxy.conf
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 50m;
client_body_buffer_size 256k;
proxy_connect_timeout 30;
proxy_send_timeout 30;
proxy_read_timeout 60;
proxy_buffer_size 4k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 64k;
proxy_temp_file_write_size 64k;
proxy_next_upstream error timeout invalid_header http_500 http_503 http_404;
proxy_max_temp_file_size 128m;
proxy_store on;
proxy_store_access user:rw group:rw all:r;
#nginx cache
#client_body_temp_path /data/nginx_cache/client_body 1 2;
#proxy_temp_path /usr/local/nginx/proxy_temp 1 2;
[root@lb1 conf]# vi nginx.conf
server{
listen 192.168.80.101:80;
server_name www.etiantian.org;
location / {
proxy_pass http://www_server_pools;
include proxy.conf;
}
}6. 反向代理多虚拟主机节点服务器企业案例
server{
listen 192.168.80.103:80;
server_name bbs.etiantian.org;
location / {
proxy_pass http://bbs_server_pools;
proxy_set_header Host $host; # 在代理向后端服务器发送的http请求头中加入host字段信息,用于当后端服务器配置有多个虚拟主机时,可以识别代理的是哪个虚拟主机。这是节点服务器多虚拟巨机时的关键配置。
proxy_set_header X-Forwarded-For $remote_addr;
}7. 经过反向代理后的节点服务器记录用户IP企业案例
web01节点服务器对应的www虚拟主机的访问日志的第一个字段记录的并不是客户端的IP(192.168.1.203),而是反向代理服务器本身的IP(192.168.80.101),那么,如何解决这个问题呢?
同样是增加如下一行参数:
proxy_set_header X-Forwarded-For $remote_addr; #这是反向代理时,节点服务器获取户真实IP的必要功能配置。9、Proxy_pass代理转发
1. 根据url中的目录地址实现代理转发说明
案例背景:通过Nginx实现动静分离,即通过Nginx反向代理配置规则实现让动态资源和静态资源及其它业务分别由不同的服务器解析,以解决网站性能安全、用户体验等重要问题。
下图为企业常见的动静分离集群架构图,此架构图适合网站前端只使用同一个域名提供服务的场景,例如,用户访问的域名是www.etiantian.org,然后,当用户请求www.etiantian.org/upload/xx地址的时候,代理会分配请求到上传服务器池处理数据;当用户请求www.etiantian.org/static/xx地址的时候,代理会分配请求到静态服务器池请求数据;当用户请求www.etiantian.org/xx地址的时候,即不包含上述指定的目录地址路径时,代理会分配请求到默认的动态服务器池请求数据;注:xx表示任意路径。

2. 案例配置实战
先进行企业案例需求梳理:
- 当用户请求www.etiantian.org/upload/xx地址时实现由upload上传服务器池处理请求。
- 当用户请求www.etiantian.org/static/xx地址时实现由静态服务器池处理请求。
- 除此以外,对于其他访问请求,全都由默认的动态服务器池处理请求。
upstream池配置:
static_pools为静态服务器池,有一个服务器,地址为192.168.80.103,端口为80。
upstream static_pools {
server 192.168.80.103:80 weight=1;
}upload_pools为上传服务器池,有一个服务器,地址为192.168.80.104,端口为80。
upstream upload_pools{
server 192.168.80.104:80 weight=1;
}default_pools为默认的服务器池,即动态服务器池,有一个服务器,地址为192.168.80.104,端口为8080。
upstream default_pools{
server 192.168.80.104:8080 weight=1;
}域名服务配置:
方案一:location语句实现
server{
listen 192.168.80.101:80;
server_name www.etiantian.org;
location / {
proxy_pass http://default_pools;
include proxy.conf;
}
location /static/ {
proxy_pass http://static_pools;
include proxy.conf;
}
location /upload/ {
proxy_pass http://upload_pools;
include proxy.conf;
}
}方案二:if语句实现
server {
}
listen 192.168.80.101:80;
server_name www.etiantian.org;
location / {
if ($request_uri ~* "^/static/(.*)$") {
proxy_pass http://static_pools/$1;
}
if ($request_uri ~* "^/upload/(.*)$") {
proxy_pass http://upload_pools/$1;
}
proxy_pass http://default_pools;
include proxy.conf;
}
}创建站点目录:
static_pools 对应服务器的站点下创建static目录,并创建首页文件
upload_pools 对应服务器的站点下创建upload目录,并创建首页文件
default_pools 对应服务器设置域名端口为8080,并创建首页文件
3. 根据url目录地址转发的应用场景
根据http的url进行转发的应用情况,被称为第7层(应用层)的负载均衡,而lvs的负载均衡一般用于tcp等的转发,因此被称为第4层(传输层)的负载均衡
在企业中,有时希望只用一个域名对外提供服务,不希望使用多个域名对应同一个产品业务,此时就需要在代理服务器上通过配置规则,使得匹配不同规则的请求会交给不同的服务器池处理。这类业务有:
- 业务的域名没有拆分或者不希望拆分,但希望实现动静分离、多业务分离,这在前面已经讲解过案例了。
- 不同的客户端设备(例如:手机和PC端)使用同一个域名访问同一个业务网站,就需要根据规则将不同设备的用户请求交给后端不同的服务器处理,以便得到最佳的用户体验。这也是非常重要的,接下来就讲解相关案例。
4. 根据客户端的设备(user_agent)转发实践
这里还是使用static_pools、upload_pools作为本次实验的后端的服务器池。
下面先根据电脑客户端浏览器的不同设置对应的匹配规则:
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream static_pools {
server 192.168.80.103:80 weight=1;
}
upstream upload_pools{
server 192.168.80.104:80 weight=1;
}
upstream default_pools{
server 192.168.80.104:8080 weight=1;
}
server {
listen 192.168.80.101:80;
server_name www.etiantian.org;
location / {
if ($http_user_agent ~* "MSIE") {
proxy_pass http://static_pools;
} #如果请求的浏览器为微软IE浏览器(MSIE),则让请求由static_pools池处理
if ($http_user_agent ~* "Chrome") {
proxy_pass http://upload_pools;
} #如果请求的浏览器为谷歌浏览器(Chrome),则让请求由up1oad_poo1s池处理
proxy_pass http://default_pools; #其他浏览器使用default_pools处理
include proxy.conf;
}
}
}测试:
- IE浏览器访问www.etiantian.org则会让请求由static_pools池处理www.etiantian.org访问www.etiantian.org/satic,正常情况,www.etiantian.org/upload,出现错误
- www.etiantian.org则会让请求由upload_pools池处理www.etiantian.org访问www.etiantian.org/satic,出现错误,www.etiantian.org/upload,正常情况
- www.etiantian.org则会让请求由default _pools池处理
手机客户端转发:
配置模板同电脑客户端浏览器的配置,只是将浏览器的版本改为android、iphone、及其默认等,然后使用手机测试,手机客户端的标识可以通过手机访问网站,然后从web日志中读取。
upstream static_pools {
server 192.168.80.103:80 weight=1;
}
upstream upload_pools{
server 192.168.80.104:80 weight=1;
}
upstream default_pools{
server 192.168.80.104:8080 weight=1;
}
server {
listen 192.168.80.101:80;
server_name www.etiantian.org;
location / {
if ($http_user_agent ~* "android") {
proxy_pass http://static_pools;
}
if ($http_user_agent ~* " iphone") {
proxy_pass http://upload_pools;
}
proxy_pass http://default_pools;
include proxy.conf;
}
}5. 根据文件扩展名实现代理转发
相关server配置:
location ~ .*.(gif|jpg|jpeg|png|bmp|swf|css)$ {
proxy_pass http://static_pools;
include proxy.conf;
}下面是if语句方法的匹配规则:
location / {
if ($request_uri ~* ".*.(php|php5)$") {
proxy_pass http://php_server_pools;
}
if ($request_uri ~* ".*.(jsp|jsp*|do|do*)$") {
proxy_pass http://java_server_pools;
}
proxy_pass http://default_pools;
include proxy.conf;
}10、Nginx负载均衡监测节点状态
1. 利用第三方Nginx插件监控代理后端节点的服务器
淘宝技术团队开发了一个Tengine(Nginx的分支)模块nginx_upstream_check_moodule,
用于提供主动式后端服务器健康检查。通过它可以检测后端rea1Server的健康状态,如果后端realservcr不可用,则所有的请求就不会转发到该节点上。
Tengine原生支持这个模块,而Nginx则需要通过打补丁的方式将该模块添加到Nginx中。补丁下载地址:GitHub - yaoweibin/nginx_upstream_check_module: Health checks upstreams for nginx
下面介绍一下如何使用这个模块。
安装nginx_upstream_check_module模块:
提示:系统已经安装了nginx-1.6.2软件的情况。
[root@lb1 ~]# cd /server/tools/
[root@lb1 tools]# wget https://codeload.github.com/yaoweibin/nginx_upstream_check_module/zip/master
[root@lb1 tools]# unzip master
[root@lb1 nginx-1.6.3]# patch -p1 <../nginx_upstream_check_module-master/check_1.5.12+.patch
[root@lb1 nginx-1.6.3]# ./configure --prefix=/application/nginx-1.6.3 --user=nginx --group=nginx --with-http_ssl_module --with-http_stub_status_module --add-module=../nginx_upstream_check_module-master/
[root@lb1 nginx-1.6.3]# make如果是新的nginx,则继续执行make install一步,如果给已经安装了nginx的系统打监控补丁就不用执行了,make install的作用就是重新生成Nginx二进制启动命令而己。
[root@lb1 nginx-1.6.3]# mv /application/nginx/sbin/nginx /application/nginx/sbin/nginx.ori
[root@lb1 nginx-1.6.3]# cp ./objs/nginx /application/nginx/sbin/
[root@lb1 nginx-1.6.3]# /application/nginx/sbin/nginx -t配置nginx健康检查:
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream www_server_pools {
server 192.168.80.103:80 weight=1;
server 192.168.80.104:80 weight=1;
check interval=3000 rise=2 fall=5 timeout=1000 type=http;
}
server{
listen 192.168.80.101:80;
server_name www.etiantian.org;
location /status {
check_status;
access_log off;
}
location / {
proxy_pass http://www_server_pools;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
}
}
}重启nginx:
[root@lb1 conf]# /application/nginx/sbin/nginx -s stop
[root@lb1 conf]# /application/nginx/sbin/nginx
#注意此处必须重启Nginx,不能重新加载。check interval=3000 rise=2 fall=5 timeout=1000 type=http;
上面配置的意思是每隔3秒检测一次.请求2次正常则标记realserver状态为up.如果检测5次都失败.则标记realserver的状态为down,超时时间为1秒.检查的协议是http。
详细可见:ngx_http_upstream_check_module - The Tengine Web Server
六、Keepalived+Nginx高可用实战
1、Keepalived服务介绍
Keepalived起初是专为LVS设计的,专门用来监控LVS集群系统中各个服务节点的状态,后来又加入了VRRP的功能,因此除了配合LVS服务外,也可以作为其他服务(nginx,haproxy)的高可用软件,VRRP是Virtual Router Redundancy Protoco1(虚拟路由器冗余协议)的缩写,VRRP出现的目的就是为了解决静态路由出现的单点故障问题,它能够保证网络的不间断、稳定的运行。所以,keepalived一方面具有LVS cluster nodes healthchecks功能,另一方面也具有LVS directors failover功能。
Keepalived服务两大用途:healthchecks和failover
1. LVS directors failover功能
ha failover功能:实现LB master主机和Backup主机之间故障转移和自动切换。
这是针对有两个负载均衡器Director同时工作而采取的故障转移措施。当主负载均衡器(MASTER)失效或出现故障时,备份负载均衡器(BACKUP)将自动接管主负载均衡器的所有工作(VIP资源及相应服务);一旦主负载均衡器(MASTER)故障修复,MASTER又会接管回它原来处理的工作,而备份负载均衡器(BACKUP)会释放master失效时它接管的工作,此时两者将恢复到最初各自的角色状态。
2. LVS cluster nodes healthchecks功能
rs healthcheck功能:负载均衡定期检查Rs的可用性决定是否给其分发请求。当虚拟服务器中的某一个甚至是几个真实服务器同时发生故障无法提供服务时,负载均衡器会自动将失效的RS服务器从转发队列中清除出去,从而保证用户的访问不受影响;当故障的RS服务器被修复以后,系统又会自动地把它们加入转发队列,分发请求提供正常服务。
2、Keepalived故障切换转移原理
keepalived高可用对之间是通过VRRP协议通信的,VRRP协议是通过竞选机制来确定主备的,主的优先级高于备,因此,工作时主会获得所有的资源,备节点处于等待状态,当主挂了时候,备节点,接管主节点的资源,然后顶替主节点对外提供服务。
VRRP协议是通过IP多播包的方式(224.0.0.18)发送的。
在keepalived之间,只有作为主的服务器会一直发送VRRP广播包,告诉备他还活着,此时备不会抢占主,当主不可用时,即备监听不到主发送的广播包时,就会启动相关服务接管资源,保证业务的连续性。接管速度可以小于1秒。VRRP使用加密协议加密发送广播包。
那么,什么是VRRP协议呢?
VRRP协议简单介绍:
VRRP是Virtual Router Redundancy Protoco1(虚拟路由器冗余协议)的缩写,VRRP协议的出现就是为了解决静态路由的单点故障,VRRP协议是通过一种竞选协议机制来将路有任务交给某台VRRP路由器
MASTER and BACKUP
在一个VRRP虚拟路由器中,有多台物理的VRRP路由器.但是这多台物理的机器并不同时工作,而是由一台称为MASTER的负责路由工作,其他的都是BACKUP,MASTER并非一成不变,VRRP协议让每个VRRP路由器参与竞选.最终获胜的就是MASTER。MASTER有一些特权,比如拥有虚拟路由器的IP地址,我们的主机就是用这个IP地址作为静态路由的。拥有特权的MASTER要负责转发发送给网关地址的包和响应ARP请求。
VRRP通过竞选协议来实现虚拟路由器的功能,所有的协议报文都是通过IP多播(multicast)包(多播地址224.0.0.18)形式发送的。虚拟路由器由VRID(范围0-255)和一组IP地址组成.对外表现为一个周知的MAC地址:00-00-5E-00-01-{VRID}。所以,在一个虚拟路由器中不管谁是MASTER,对外都是相同的MAC和IP(称之为VIP),客户端主机并不需要因为MASTER的改变而修改自己的路由配置,对他们来说,这种主从的切换是透明的。
在一个虚拟路由器中,只有作为MASTER的VRRP路由器会一直发送VRRP广告包(VRRP Advertisement message),BACKUP不会抢占MASTER,除非它的优先级(priority)更高。当MASTER不可用时(BACKUP收不到广告包),多台BACKUP中优先级最高的这台会被抢占为MASTER。这种抢占是非常快速的(<ls),以保证服务的连续性。
出于安全性考虑,VRRP包使用了加密协议进行加密。
keepalived工作原理小结:
- VRRP协议,全称Virtual Router Redulldancy Protocol,中文名,虚拟路由器冗余协议,VRRP的出现就是为了解决静态路由的单点故障。
- VRRP是通过一种竞选协议机制来将路由任务交给某台VRRP路由器。
- VRRP是用过IP多播的方式实现通信。、
- 主发包,备接包,当备接不到主发的包的时候,就启动接管程序接管主的资源。备可以有多个,通过优先级竞选。
- VRRP使用了加密协议。
3、安装Keepalived实现服务高可用功能
keepalived官方网站:Keepalived for Linux
官方文档是:Keepalived for Linux
注意:在两台nginx反向代理服务器上同时操作。
yum install openssl-devel popt-devel -y
cd /server/tools
wget http://www.keepalived.org/software/keepalived-1.2.16.tar.gz
ln -s /usr/src/kernels/2.6.32-504.el6.x86_64/ /usr/src/linux
#也可以不执行,此步是配合lvs使用安装时,有可能会没有/usr/src/kernels/2.6.32-504.el6.x86_64。这是因为缺少kernel-devel软件包,此时需要提前通过yum install kernel-devel -y命令来安装。
tar zxvf keepalived-1.2.16.tar.gz
cd keepalived-1.2.16
./configure
yum install openssl-devel -y
./configure
make
make install配置规范启动:
/bin/cp /usr/local/etc/rc.d/init.d/keepalived /etc/init.d/ #生成启动脚本
/bin/cp /usr/local/etc/sysconfig/keepalived /etc/sysconfig/ #配置启动脚本参数
mkdir /etc/keepalived #创建默认的keepalived配置文件路径
/bin/cp /usr/local/etc/keepalived/keepalived.conf /etc/keepalived/ #生成keepalived配置模板
/bin/cp /usr/local/sbin/keepalived /usr/sbin/
/etc/init.d/keepalived start
/etc/init.d/keepalived stop
man keepalived 查看帮助配置文件说明:
[root@lb2 keepalived]# cat keepalived.conf
global_defs { #全局配置,此处可以不配置
notification_email {
[email protected] #收件人
}
notification_email_from [email protected] #发件人
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL #相当于mysql的server_id,需要唯一
}
vrrp_instance VI_1 { #定义vrrp实例
state MASTER
interface eth0 #LVS监控的网络接口
virtual_router_id 51 #同一实例下virtual_router_id必须相同
priority 150
advert_int 1 #MASTER与BACKUP负载均衡器之间同步检查的时间间隔,单位是秒
authentication { #验证类型和密码
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.80.10/24 #VIP,如果有多个,往下加就行了
}
}注意:backup服务器需要修改的。
/etc/init.d/keepalived start #启动服务,ip addr查看主备两边只有一个虚拟IP存在
ip addr add 192.168.80.10/24 dev eth0 #配置虚拟IP,不能使用ifconfig配置,此步不需要执行,启动服务会自动添加4、keepalived+nginx企业案例
1. nginx反向代理停掉及企业解决方案
keepalived只实现服务器级别的接管,nginx宕机不会接管,当nginx反向代理停掉后,应该停掉keepalived,可以写脚本实时监控nginx反向代理:
[root@lb2 scripts]# vi check_web.sh
#!/bin/bash
while true
do
if [ `ps -ef|grep nginx|grep -v grep|wc -l` -lt 2 ]
then
/etc/init.d/keepalived stop && exit 1
fi
sleep 5
done两台keepalived后台执行此脚本:
[root@lb2 scripts]# sh check_web.sh &2. keepalived高可用裂脑问题解决
开发脚本检测裂脑。
思路:可以ping通主节点,备节点有VIP就认为裂脑。
[root@nginx scripts]# vi check_split_brain.sh
#!/bin/bash
while true
do
ping -c 2 -w 3 192.168.80.101 &>/dev/null
if [ $? -eq 0 -a `ip addr|grep 192.168.80.10|wc -l` -eq 1 ]
then
echo "ha is split brain.warning"
else
echo "ha is ok"
fi
sleep 5
done
待测试3. keepalived日志配置
keepalived日志默认为系统日志/var/log/messages。
配置指定文件接收keepalived服务日志:
[root@lb2 ~]# vi /etc/sysconfig/keepalived #修改最后一行
KEEPALIVED_OPTIONS="-D -S 0 -d"
[root@lb2 ~]# vi /etc/rsyslog.conf #在最后一行添加
local0.* /var/log/keepalived.log
[root@lb2 ~]# /etc/init.d/rsyslog restart #重启rsyslog
[root@lb2 ~]# /etc/init.d/keepalived restart #重启keepalived
[root@lb2 ~]# tail /var/log/keepalived.log #查看日志4. keepalived高可用多实例
编辑keepalived.conf配置文件,再添加一个vrrp_instance VI_2模块:
vrrp_instance VI_2 {
state MASTER
interface eth0
virtual_router_id 52
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.80.11/24
}
}仅仅修改以上黑体部分,注意:可以让两台keepalived做不同实例的主,同一实例不能做双主。
5. 对Nginx反向代理后端Web服务器的健康检查
通过html页面,实时观测nginx负载均衡后端每台Web服务器及其Web服务的状态变化。html页面初始时,列出配置文件中管理池内所有服务器当前的“类型”、“主机名”及“状态”。
当有Web服务器断开或Web服务处于非启动状态时,脚本将自动把服务器从配置文件中的管理池内剔除,同时更新html页面的“状态”字段为“Bad”字样,更新“类型“字段为“Unknow”字样;当有Web服务器的Web服务恢复启动状态时,脚本将自动把服务器加回配置文件中的管理池内,同时更新html页面“状态“字段为“Good”字样,更新“类型”字段为真实服务器类型。
七、LVS+Keepalived集群架构实战
1、lvs负载均衡集群介绍
负载均衡(Load Balance)集群提供了一种廉价、有效、透明的方法,来扩展网络设备和服务器的负载、带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性。
搭建负载均衡服务的需求:
- 把单台计算机无法承受的大规模的并发访问或数据流量分担到多台节点设备上分别处理,减少用户等待响应的时间,提升用户体验;
- 单个重负载的运算分担到多台节点设备上做并行处理,每个节点设备处理结束后将结果汇总,返回给用户,系统处理能力得到大幅度提高。
- 7x24的服务保证,任意一个或多个有限后面节点设备宕机,要求不能影响业务。
在负载均衡集群中,所有计算机节点都应该提供相同的服务。集群负载均衡器截获所有对该服务的入站请求。然后将这些请求尽可能地平均地分配在所有集群节点上。
1. LVS(Linux Virtual Server)介绍
LVS负载均衡调度技术是在Linux内核中实现的,因此,被称之为Linux虚拟服务器(LlnuxVinualServer)。我们使用该软件配置LVS时候,不能直接配置内核中的ipvs,而需要使用iPvs的管理工具ipvsadm进行管理,当然,后文我们会讲通过keepalived软件直接管理ipvs,并不是通过ipvsadm来管理ipvs。
LVS技术点小结:
1、真正实现调度的工具是IPVS,工作在linux内核层面。
2、LVS自带的IPVS管理工具是1pvsadm。
3、keepalived实现管理IPVS及负载均衡器的高可用。
4、Redhat工具Piranha WEB管理实现调度的工具IPVS
2. LVS体系结构与工作原理简单描述
LVS集群负载均衡器接受服务的所有入站客户端计算机请求,并根据调度算法决定哪个集群节点应该处理回复请求。负载均衡器(简称LB)有时也被称为Lvs Director(简称Director)。
LVS虚拟服务器的体系结构如下图所示,一组服务器通过高速的局域网或者地理分布的广域网相互连接,在它们的前端有一个负载调度器(Load Balancer)。负载调度器能无缝地将网络请求调度到真实服务器上,从而使得服务器集群的结构对客户是透明的,客户访问集群系统提供的网络服务就像访问一台高性能、高可用的服务器一样。
客户程序不受服务器集群的影响不需作任何修改。系统的伸缩性通过在服务集群中透明地加入和删除一个节点来达到,通过检测节点或服务进程故障和正确地重置系统达到高可用性。由于我们的负载调度技术是在Linux内核中实现的,我们称之为Linux虚拟服务器(LinuxVirtualServer)。
3. LVS相关术语命名约定
虚拟IP地址件(virtual IP Address):缩写VIP,VIP为Director用于向客户端计算机提供服务的IP地址。比如:www.etiantian.org域名就要解析到VIP上提供服务。
真实IP地址很(Real serverIP Address):缩写RIP,在集群下面节点上使用的IP地址,物理IP地址。
Director的IP地址(Director IP address):缩写DIP,Director用于连接内外网络的IP地址,物理网卡上的IP地址。是负载均衡器上的IP
客户端主机IP地址(client IP Address):缩写CIP,客户端用户计算机请求集群服务器的IP地址,该地址用作发送给集群的请求的源IP地址。
2、ARP协议介绍
ARP协议,全称“Address Resolution Profocol",中文名是地址解析协议,使用ARP协议可实现通过IP地址获得对应主机的物理地址(MAC地址)。
在TCP/IP的网络环境下,每个联网的主机都会被分配一个32位的IP地址,这种互联网地址是在网际范围标识主机的一种逻辑地址。为了让报文在物理网路上传输,还必须要知道对方目的主机的物理地址(MAC)才行。这样就存在把IP地址变换成物理地址的地址转换的问题。
在以太网环境,为了正确地向目的主机传送报文,必须把目的主机的32位IP地址转换成为目的主机48位以太网的地址(NIAC地址)。这就需要在互连层有一个服务或功能将IP地址转换为相应的物理地址(MAC地址),这个服务或者功能就是ARP协议。所谓的“地址解析”,就是主机在发送帧之前将目标IP地址转换成目标MAC地址的过程。ARP协议的基本功能就是通过目标设备的IP地址,查询目标设备的MAC地址,以保证主机间互相通信的顺利进行。
arp协议是三层协议,工作于二层。
ARP协议和DNS有点相像之处。不同点是:DNS是在域名和1P之间的解析,另外,ARP协议不需要配置服务,而DNS要配置服务才行。
ARP协议要求通信的主机双方必须在同一个物理网段(即局域网环境)
1. ARP缓存表是把双刃剑
1)主机有了arp缓存表,可以加快ARP的解析速度,减少局域网内广播风暴。
2)正是有了arp缓存表,给恶意黑客带来了攻击服务器主机的风险,这个就是arp欺骗
3)切换路由器,负载均衡器等设备时,可会导致短时网络中断。
2. ARP在生产环境产生的问题及解决办法
- ARP病毒,ARP欺骗。
- 高可用服务器对之间切换时要考虑ARP缓存的问题。
- 路由器等设备无缝迁移时要考虑ARP缓存的问题,例如:更换办公室的路由器。
3. ARP欺骗原理
ARP攻击就是通过伪造IP地址和MAC地址对实现ARP欺骗的,如果一台主机中了ARP病毒,那么它就能够在网络中产生大量的ARP通信量(它会以很快的频率进行广播),以至于使网络阻塞,攻击者只要持续不断的发出伪造的ARP响应包就更改局域网中目标主机ARP缓存中的IP-MAC条目,造成网络中断或中间人攻击。
ARP攻击主要是存在于局域网网络中,局域网中若有一个人感染ARP木马,则感染该ARP木马的系统将会试图通过“ARP欺骗”手段截获所在网络内其它计算机的通信信息,并因此造成网内其它计算机的通信故障。
4. 服务器切换ARP问题
当网络中一台提供服务的机器宕机后,当在其他运行正常的机器添加宕机的机器的IP时,会因为客户端的ARP table cache的地址解析还是宕机的机器的MAC地址。从而导致即使在其他运行正常的机器添加宕机的机器的IP,也会发生客户依然无法访问的情况。
解决办法是:当机器宕机,IP地址迁移到其他机器上时,需要通过。arping命令来通知所有网络内机器清除其本地的ARP table cache,从而使得客户机访问时重新广播获取MAC地址。这个在自己开发脚本实现服务器的高可用时是要必须考虑的问题之一,几乎所有的高可用软件都会考虑这个问题。
ARP广播而进行新的地址解析:
arping [ -AbDfhqUV] [ -c count] [ -w deadline] [ -s source] -I interface destination例如:
/sbin/arping -I eth0 -c 3 -s 192.168.80.102 192.168.80.23、LVS集群的3种工作模式介绍
1. IP虚拟服务器软件IPVS
在调度器的实现技术中,IP负载均衡技术是效率最高的。在己有的IP负载均衡技术中有通过网络地址转换(Network Address Translation)将一组服务器构成一个高性能的、高可用的虚拟服务器,我们称之为VS/NAT技术(virtual Server via Network Address Translation),大多数商业化的IP负载均衡调度器产品都是使用NAT的方法,如Cisco的LocalDirector、F5、Netscaler的Big/IP和Alteon的ACEDirector。
在分析VS/NAT的缺点和网络服务的非对称性的基础上,我们提出通过IP隧道实现虚拟服务器的方法VS/TUN(Virtual server via IP Tunneling)和通过直接路由实现虚拟服务器的方法VS/DR(Virtual Server via Direct Routing),它们可以极大地提高系统的伸缩性。所以,IPVS软件实现了这三种IP负载均衡技术,它们的大致原理如下(我们将在其他章节对其工作原理进行详细描述)。淘宝开源的模式FULLNAT。FULLNAT(Virtual Server via FULL Network AddressTranslation).
2. DR模式特点
1)通过在调度器LB上修改数据包的目的MAC地址实现转发,注意,源正地址仍然是CIP,目的IP地址仍然是VIP。
2)请求的报文经过调度器,而RS响应处理后的报文无需经过调度器LB,因此,并发访问量大时使用效率很高(和NAT模式比)。
3)因DR模式是通过MAC地址的改写机制实现的转发,因此,所有RS节点和调度器LB只能在一个局域网LAN中(小缺点)。
4)需要注意RS节点的VIP的绑定(lo:vip/32,101,vip/32)和ARP抑制问题。,
5)强调下:RS节点的默认网关不需要是调度器LB的DIP,而直接是IDC机房分配的上级路由器的IP(这是RS带有外网正地址的情况),理论讲:只要RS可以出网即可,不是必须要配置外网IP。
6)由于DR模式的调度器仅进行了目的MAC地址的改写,因此,调度器LB无法改变请求的报文的目的端口(和NAT要区别)。
7)当前,调度器LB支持几乎所有的UNIX,LINUX系统,但目前不支持WINDOWS系统。真实服务器RS节点可以是WINDOWS系统。
8)总的来说DR模式效率很高,但是配置也较麻烦,因此,访问量不是特别大的公司可以用hoproxy/nginx取代之。这符合运维的原则:简单、易用、高效。日1000-2000w PV或并发请求1w以下都可以考虑用hoproxy/nginx
9)直接对外的访问业务,例如:web服务做RS节点,RS最好用公网护地址。如果不直接对外的业务,例如:MySQL,存储系统RS节点,最好只用内部IP地址。
3. NAT模式特点
1)NAT技术将请求的报文(通过DNAT方式改写)和响应的报文(通过SNAT方式改写),通过调度器地址重写然后在转发给内部的服务器,报文返回时在改写成原来的用户请求的地址。
2)只需要在调度器LB上配置WAN公网IP即可,调度器也要有私有LAN IP和内部RS节点通信。
3)每台内部RS节点的网关地址,必须要配成调度器LB的私有LAN内物理网卡地址(LDIP),这样才能确保数据报文返回时仍然经过调度器LB。
4)由于请求与响应的数据报文都经过调度器LB,因此,网站访问量大时调度器LB有较大瓶颈,一般要求最多10-20台节点。
5)NAT模式支持对IP及端口的转换,即用户请求10.0.0.1:80,可以通过调度器转换到RS节点的10.0.0.2:8080(DR和TUN模式不具备的)。
6)所有NAT内部RS节点只需配置私有LANIP即可。
7)由于数据包来回都需要经过调度器,因此,要开启内核转发net.ipv4.ip_forward=1,当然也包括iptables防火墙的forward功能(DR和TUN模式不需要)。
4. TUN模式
1)负载均衡器通过把请求的报文通过IP隧道(ipip隧道,高级班讲这个)的方式(请求的报文不经过原目的地址的改写(包括MAC),而是直接封装成另外的IP报文)转发至真实服务器,而真实服务器将响应处理后直接返回给客户端用户。
2)由于真实服务器将响应处理后的报文直接返回给客户端用户,因此,最好RS有一个外网IP地址,这样效率才会更高。理论上:只要能出网即可,无需外网IP地址。
3)由于调度器LB只处理入站请求的报文。因此,此集群系统的吞吐量可以提高10倍以上,但隧道模式也会带来一定的系统开销。TUN模式适合LAN/WAN。
4)TUN模式的LAN环境转发不如DR模式效率高,而且还要考虑系统对IP隧道的支持问题。
5)所有的RS服务器都要绑定VIP,抑制ARP,配置复杂。
6)LAN环境一般多采用DR模式,WAN环境可以用TUN模式,但是当前在WAN环境下,请求转发更多的被haproxy/nginx/DNS调度等代理取代。因此,TUN模式在国内公司实际应用的已经很少。跨机房应用要么拉光纤成局域网,要么DNS调度,底层数据还得同步。
7)直接对外的访问业务,例如:web服务做RS节点,最好用公网IP地址。不直接对外的业务,例如:MySQL,存储系统RS节点,最好用内部IP地址。
5. LVS的三种模式优缺点比较

4、LVS的调度算法
固定调度算法:rr,wrr,dh,sh
动态调度算法:wlc,lc,lb1c,lblcr,SED,NQ(后两种官方站点没提到,编译LVS,make过程可以看到)
rr:轮循调度(Round一Robin):它将请求依次分配不同的RS节点,也就是在RS节中均摊请求。这种算法简单,但是只适合于RS节点处理性能相差不大的情况。
wrr:加权轮循调度(Weighted Round-Robin):它将依据不同RS节点的权值分配任务,权值较高的RS将优先获得任务,并且分配到的连接数将比权值较低的RS节点更多,相同权值的RS得到相同数目的连接数。
dh:目的地址哈希调度(Destination Hashing):以目的地址为关键字查找一个静态hash表来获得需要的RS。
sh:源地址哈希调度(Source Hashing) :以源地址为关键字查找一个静态hash表来获得需要的RS。
wlc加权最小连接数调度(Weighted Least-Comnection) (WLC) :具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。假设各台RS的权值一次为Wi(l = 1..n),当前的TCP连接数依次为Ti(l=1..n)一次选取Ti/Wi为最小的RS作为下一个分配的RS
lc最小连接数调度(Least-Connection):IPVS表存储了所有的活动的连接。把新的链接请求发送到当前连接数最小的RS。
LBLC 基于局部性的最少链接(Locality-Based Least Connections):针对目标IP地址的负载均衡,目前主要用于Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用“最少链接” 的原则选出一个可用的服务器,将请求发送到该服务器。
LBLCR 带复制的基于局部性最少链接(Locality-Based Least Connections with Replication):它与LBLC算法的不同之处是它要维护从一个目标 IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。该算法根据请求的目标IP地址找出该目标IP地址对应的服务器组,按“最小连接”原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按“最小连接”原则从这个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度
SED 最短的期望的延迟(Shortest Expected Delay Scheduling SED)
NQ 最少队列调度(Never Queue Scheduling NQ)
LVS的调度算法的生产环境选型:
1. 一般的网络服务,如Mail、MySQL等,常用的LVS调度算法为:
a.基本轮询调度rr
b.加权最小连接调度wrr
c.加权轮询调度w1c
2. 基于局部性的最少链接LBLC和带复制的基于局部性最少链接LBLCR主要应用于webCache和DbCache集群,但是我们很少这样用。一致性哈希。
3. 源地址散列调度SH和目标地址散列调度DH可以结合使用在防火墙集群中,它可以保证整个系统的唯一出入口。
4. 最短预期延时调度SED和不排队调度NQ主要是对处理时间相对比较长的网络服务。
实际使用中,这些算法的适用范围不限于这些。我们最好参考内核中的连接调度算法的实现原理,根据具体的业务需求合理的选型。
5、lvs的安装部署
在安装好keepalived的机器上部署lvs:
lsmod|grep ip_vs #查看ip_vs模块,安装keepalived后默认会加载ip_vs模块,也可以安装lvs
ip_vs 125694 0 #后执行ipvsadm命令加载
libcrc32c 1246 1 ip_vs
ipv6 334932 137 ip_vs
这里选择yum安装lvs
yum install ipvsadm -y #yum安装lvs
sed -i 's#net.ipv4.ip_forward = 0#net.ipv4.ip_forward = 1#g' /etc/sysctl.conf #修改内核转发
sysctl -p编译安装LVS方式如下:
yum install libnl* popt* -y
wget http://linuxvirtualserver.org/software/kernel-2.6/ipvsadm-1.26.tar.gz
tar xvf ipvsadm-1.26.tar.gz
cd ipvsadm-1.26
make
make install
ipvsadm #加载ip_vs模块或(modprobe ip_vs)
lsmod |grep ip_vs #查看
注意:Centos5.X安装lvs, 使用1.24版本。不要用1.26。ipvsadm命令相关参数:
-A, --add-service Add a virtual service
-C, --clear Clear the virtual server table.
-D, --delete-service Delete a virtual service,
-d, --delete-server Remove a real server from a virtual service.
-g, --gatewaying Use gatewaying (direct routing) #DR模式
-i, --ipip Use ipip encapsulation (tunneling) #TUN模式
-m, --masquerading Use masquerading (network access translation, or NAT). #NAT模式
-p, --persistent [timeout] Specify that a virtual service is persistent #会话保持
-w, --weight weight #权重
-L, -l, --list List the virtual server table if no argument is specified
-s, --scheduler scheduling-method #调度算法
--set tcp tcpfin udp Change the timeout values used for IPVS connections.
-t, --tcp-service service-address Use TCP service. The service-address is of the form host[:port].配置lvs服务并添加RS:
ip addr add 192.168.80.11/24 dev eth0 label eth0:1
ipvsadm -C
ipvsadm --set 30 5 60
ipvsadm -A -t 192.168.80.11:80 -s rr
ipvsadm -a -t 192.168.80.11:80 -r 192.168.80.103:80 -g
ipvsadm -a -t 192.168.80.11:80 -r 192.168.80.104:80 -g配置所有RS绑定VIP并抑制arp:
配置别名为ifconfig eth0:0 10.0.0.10/24 up(Centos7已经淘汰)。
辅助IP为ip addr add 192.168.80.99/24 dev eth0。
ip addr add 192.168.80.11/32 dev lo label lo:1
route add -host 192.168.80.11 dev lo
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce有关arp_ignore的相关介绍:
0 - (默认值): 回应任何网络接口上对任何本地IP地址的arp查询请求
1 - 只回答目标IP地址是来访网络接口本地地址的ARP查询请求
2 -只回答目标IP地址是来访网络接口本地地址的ARP查询请求,且来访IP必须在该网络接口的子网段内
3 - 不回应该网络界面的arp请求,而只对设置的唯一和连接地址做出回应
4-7 - 保留未使用
8 -不回应所有(本地地址)的arp查询有关arp_announce的相关介绍:
arp_announce:对网络接口上,本地IP地址的发出的,ARP回应,作出相应级别的限制: 确定不同程度的限制,宣布对来自本地源IP地址发出Arp请求的接口
0 - (默认) 在任意网络接口(eth0,eth1,lo)上的任何本地地址
1 -尽量避免不在该网络接口子网段的本地地址做出arp回应. 当发起ARP请求的源IP地址是被设置应该经由路由达到此网络接口的时候很有用.此时会检查来访IP是否为所有接口上的子网段内ip之一.如果改来访IP不属于各个网络接口上的子网段内,那么将采用级别2的方式来进行处理.
2 - 对查询目标使用最适当的本地地址.在此模式下将忽略这个IP数据包的源地址并尝试选择与能与该地址通信的本地地址.首要是选择所有的网络接口的子网中外出访问子网中包含该目标IP地址的本地地址. 如果没有合适的地址被发现,将选择当前的发送网络接口或其他的有可能接受到该ARP回应的网络接口来进行发送6、lvs相关企业案例
1. 常见的LVS负载均衡高可用解决方案
(1)通过开发上面的脚本来解决,如果负载均衡器硬件坏了。几分钟或几秒从其他备机上完成新的部署,如果做的细的,还可以写脚本来做调度器之间的切换,早期的办法,还是比较笨重的,目前己不再推荐使用。
(2)keepalived+LVS方案,这是老男孩极力推荐的当前最优方案,因为这个方案符合简单、易用、高效的运维原则,也是接下来重点讲解的负载均衡及高可用解决方案。
2. LVS集群分发请求RS不均衡生产环境实战解决
生成环境中ipvsadm -Ln发现两台RS的负载不均衡,一台有很多请求,一台没有。并且没有请求的那台RS经测试服务正常,lo:VIP也有,但是就是没有请求。
TCP 192.168.80.11:80 rr wrr persistent 10
-> 192.168.80.103:80 Route 1 0 1
-> 192.168.80.104:80 Route 1 8 12758问题原因:
persistent10的原因,persistent会话保持,当clientA访问网站的时候,LVS把请求分发给了104,那么以后clientA再点击的其他燥作其他请求,也会发送给104这台机器。
到keepalived中注释掉persistent10,然后/etc/init.d/keepalived reload,然后可以看到以后负载均衡两边都请求都均衡了。
其他导致负载不均衡的原因可能有:
1)LVS自身的会话保持参数设置(-p300,persistent 300)。优化:大公司尽量用cookies替代session.
2)LVS调度算法设置,例如:rr,wrr,wlc,lc算法。
3)后端RS节点的会话保持参数,例如:apache的keealive参数。
4)访问量较少的情况,不均衡的现象更加明显
5)用户发送的请求时间长短,和请求资源多少大小。
① 大规模网站sesson会话保持思路及实践配置
1. 中小企业方案
把所有应用服务器sesson会话统一放到memcached里,web读取都读共享memcached,就保持一致了。php程序,php.ini里配,当然了,lvs -p,nginx ip_hash等等也是部分网友实现的思路。
企业集群共享会话实现架构图如下:

2. 门户网站方案
基于client cookie的sessionID是门户网站经常采用的,效率高,安全性一般,
另外cookie的数量很有限,如果不够,可以通过多值cookie解决,例如淘宝就是这么干的。
企业集群clinet会话实现架构图如下:

② LVS故障排错理论及实战讲解
排查的大的思路就是,要熟悉LVS的工作原理过程,然后根据原理过程来排查。
例如:
1. 调度器上LVS调度规则及IP的正确性。
2. RS节点上VIP绑定和arp抑制的检查。
生产处理思路:
- 对RS绑定的vip做实时监控,出问题报警或者自动处理后报警。
- 把RS绑定的vip做成配置文件,例如:vi/etc/sysconfig/network-scripts/lo:0。
ARP抑制的配置思路:
- 如果是单个VIP,那么可以用stop传参设置O。
- 如果RS端有多个VIP绑定,此时,即使是停止VIP绑定也一定不要置O。
if [ ${#VIP[@]} -le 1 ];then echo "0" >/proc/sys/net/ipv4/conf/lo/arp_ignore echo "0" >/proc/sys/net/ipv4/conf/lo/arp_announce echo "0" >/proc/sys/net/ipv4/conf/all/arp_ignore echo "0" >/proc/sys/net/ipv4/conf/all/arp_announce fi -
RS节点上自身提供服务的检查(DR不能端口转换)
-
辅助排除工具有tcpdump,ping等。
③ 多台RS代码上线方案思路
(lvs,nglnx,haproxy,f5等下的集群节点php,java程序如何上下线)
集群节点多,上线时希望最大限度的不影响用户体验。
1. 通过ipvsadm命令下线机器。
ipvsadm -d -t 192.168.1.181:80 -r 192.168.1.179:802. 通过url做健康检查,然后,移走健康检查文件:这样director会把此RS从转发池中移除。
④ LVS性能调优
1. 关闭iptables,换硬件防火墙。大流量时,iPtables是一个性能瓶颈,关闭或换换硬件防火墙。
2. ipvsadm --set tcp tcpfin udp
3. 内核优化
7、配置keepalived+lvs
ipvsadm -C #清空虚拟服务表
ip addr del 192.168.80.11/24 dev eth0 #删除虚拟IP
vi /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_1
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.80.11/24
}
}
virtual_server 192.168.80.11 80 {
delay_loop 6
lb_algo wrr
lb_kind DR
persistence_timeout 50
protocol TCP
real_server 192.168.80.103 80 {
weight 1
TCP_CHECK {
connect_timeout 5
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
real_server 192.168.80.104 80 {
weight 1
TCP_CHECK {
connect_timeout 5
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
}
测试:
在物理机的hosts文件修改主机记录:
192.168.80.11 www.etiantian.org bbs.etiantian.org blog.etiantian.org访问www.etiantian.org测试。