论文地址:Vision Transformer with Deformable Attention
源码:https://github.com/LeapLabTHU/DAT
1.解决问题
每个queries patch要参加的keys过多,会导致计算成本高,收敛速度慢,并增加了过拟合的风险
swin transformer和PVT虽然有效,但手工制作的注意力模式是与数据无关的,可能不是最佳的。相关的keys/values很可能被删除,而不那么重要的keys仍然被保留。

2. Deformable Attention
给定输入特征图![]() ,生成一个点
,生成一个点![]() 的统一网格作为参考。具体来说,网格大小从输入的特征图大小中降采样一个因子r,
的统一网格作为参考。具体来说,网格大小从输入的特征图大小中降采样一个因子r,=H/r,
=W/r。参考点的值为线性间隔的二维坐标
![]() ,然后根据网格形状
,然后根据网格形状将其归一化为范围[−1,+1],其中(−1,−1)表示左上角,(+1,+1)表示右下角。为了获得每个参考点的偏移量,将特征映射线性投影到查询标记q=xWq,然后输入一个轻量子网络θoffset(·),生成偏移量∆p=θoffset(q)。为了稳定训练过程,我们用一些预定义的因子s来缩放∆p的振幅,以防止过大的偏移量,即∆p←−stanh(∆p)。然后在变形点的位置采样特征作为键和值,然后是投影矩阵:

和
分别表示变形的键嵌入和值嵌入。具体来说,我们将采样函数
(·;·)设置为一个双线性插值,使其可微:
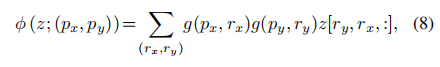
其中![]() 和
和索引了
![]() 上的所有位置。由于g只在最接近
上的所有位置。由于g只在最接近的4个积分点上不为零,因此它简化了等式(8)到4个地点的加权平均值。与现有的方法类似,我们对q、k、v进行多头注意,并采用相对位置偏移r。注意头的输出表述为:

其中![]() 对应于之前的工作[26]之后的位置嵌入,同时有一些适应。细节将在本节后面解释。每个头的特征被连接在一起,并通过Wo进行投影,得到最终的输出z为等式(3).
对应于之前的工作[26]之后的位置嵌入,同时有一些适应。细节将在本节后面解释。每个头的特征被连接在一起,并通过Wo进行投影,得到最终的输出z为等式(3).
位置偏移模块设计
采用子网络进行偏移生成,它分别消耗查询特征和输出参考点的偏移值。考虑到每个参考点覆盖一个局部s×s区域(s是偏移的最大值),生成网络也应该具有对局部特征的感知,以学习合理的偏移。因此,我们将子网络实现为两个具有非线性激活的卷积模块,如图所示输入特征首先通过一个5×5的深度卷积来捕获局部特征。然后,采用GELU激活和1×1卷积得到二维偏移量。同样值得注意的是,1×1卷积的偏差被降低,以缓解所有位置的强迫性偏移。
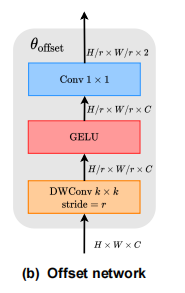
Offset groups
为了促进变形点的多样性,将特征通道划分为G组。每个组的特征使用共享的子网络分别生成相应的偏移量。在实际应用中,注意模块的头数M被设置为偏移组G大小的多倍,确保多个注意头被分配给一组变形的键和值。
相对位置偏差对每对查询和键之间的相对位置进行编码,通过空间信息增加了普通的注意力。考虑到一个形状为H×W的特征图,其相对坐标位移分别在二维的[−H,H]和[−W,W]的范围内。在Swin transformer中,构造了相对位置偏置表![]() ,通过在两个方向上进行索引,得到相对位置偏置B。由于可变形注意力具有连续的键位置,首先计算在归一化范围内的相对位移[−1,+1],然后通过连续的相对偏置在参数化偏置表
,通过在两个方向上进行索引,得到相对位置偏置B。由于可变形注意力具有连续的键位置,首先计算在归一化范围内的相对位移[−1,+1],然后通过连续的相对偏置在参数化偏置表![]() 中插值
中插值![]() ,以覆盖所有可能的偏移值。
,以覆盖所有可能的偏移值。
时间复杂度
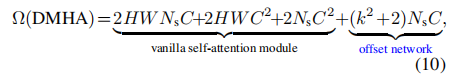
其中:![]()

3.网络架构
如图所示,首先嵌入一个H×W×3形状的输入图像,与步幅4进行4×4非重叠卷积,然后进行归一化层,得到H/4×W/4×C 的patch embeding。为了建立一个层次化的特征金字塔,主干包括4个阶段,步幅逐渐增加。在两个连续的阶段之间,有一个不重叠的2×2卷积与步幅2,以向下采样特征图,使空间尺寸减半,并使特征尺寸翻倍。在分类任务中,我们首先对最后一阶段输出的特征图进行归一化处理,然后采用具有合并特征的线性分类器来预测。在目标检测、实例分割和语义分割任务中,DAT在内部中扮演着骨干的角色


4.实验
对比模型:目标检测——swin transformer,图像分割——PVT


消融实验
在不同阶段出现的可变形的注意力。分别用不同阶段的可变形注意取代了[26]的转移窗口注意。如表7所示,只有替换最后一个阶段的注意力才能提高0.1,替换最后两个阶段的性能才能提高0.7(总体精度为82.0)。然而,在早期阶段用更多可变形的注意力代替会略微降低精度

不同的参数s。论文进一步研究了不同的最大偏移量的影响,即本文中的偏移量范围尺度因子s。进行了一个从0到16的消融实验,其中14对应于特征图的大小的最大合理偏移(阶段3的14×14)。如图4所示,s的广泛选择范围显示了DAT对这个超参数的鲁棒性。论文中的所有模型选择了一个小的s=2,没有额外的调优。

4.与可变形DETR的区别
首先,论文的可变形注意作为视觉主干中的特征提取器,而可变形DETR中用线性可变形注意取代了DETR[4]中的普通注意,发挥了检测头的作用。其次,将单尺度变形DETR中查询q的第m个头表示为

其中,K个关键点从输入特征中采样,由映射,然后由注意力权重
![]() 聚合。与此篇论文可变形注意力相比,这个注意权重从
聚合。与此篇论文可变形注意力相比,这个注意权重从线性投影,即
![]() ,
,![]() 的权重矩阵预测每个key的权重,然后一个softmax σ应用于的K 个keys规范化的注意分数。事实上,注意力权重是通过查询直接预测的,而不是测量查询和键之间的相似性。如果我们将σ函数改为s型,这将是调制的可变形卷积[53]的变体,因此这种可变形的注意更类似于卷积而不是注意。
的权重矩阵预测每个key的权重,然后一个softmax σ应用于的K 个keys规范化的注意分数。事实上,注意力权重是通过查询直接预测的,而不是测量查询和键之间的相似性。如果我们将σ函数改为s型,这将是调制的可变形卷积[53]的变体,因此这种可变形的注意更类似于卷积而不是注意。
第三,可变形DETR中的可变形注意与点积注意不兼容,因此,采用线性预测注意力来避免计算点积,并采用较少的keys K=4来降低内存成本。