Microsoft Azure Machine Learning Studio是微软强大的机器学习平台,在设计器中,微软内置了15个场景案例,但网上似乎没有对这15个案例深度刨析的分析资料,所以我就计划写一个系列来完成。
既然是深度刨析,就不再是简单的介绍操作,而是深入每一个细节,宁愿过度详细扩展,也不简单扫过。
微软MVP实验室研究员

这次我们刨析的案例是:使用Vowpal Wabbit模型进行二分类 - 成人收入预测。
预备知识
▍数据集
该数据集是美国人口年收入数据集,原始数据来源于1994年美国人口普查数据库。该数据集共32560条数据,15列。但不建议您下载,在后面的步骤中,我们会讨论如何从Azure Machine Learning Studio的存储中获得该数据集。
| 列名 |
含义 |
类型 |
数据格式 |
| Age |
年龄 |
离散属性 |
Int64 |
| workclass |
工作类型 |
标称属性 |
Object |
| fnlwgt |
序号 |
连续属性 |
Int64 |
| education |
学历 |
标称属性 |
Object |
| education_num |
受教育时间 |
连续属性 |
Int64 |
| marital_status |
婚姻状态 |
标称属性 |
Object |
| occupation |
职业 |
标称属性 |
Object |
| relationship |
关系 |
标称属性 |
Object |
| race |
种族 |
标称属性 |
Object |
| sex |
性别 |
二元属性 |
Object |
| capital_gain |
资本收益 |
连续属性 |
Int64 |
| capital_loss |
资本损失 |
连续属性 |
Int64 |
| hours_per_week |
每周工作小时数 |
离散属性 |
Int64 |
| native_country |
原籍 |
标称属性 |
Object |
| income |
收入 |
二元属性 |
Object |
我们要预测的是新记录的可能的收入范围,在这个样本集中,收入的范围只有两个:>50K和<=50K,所以是典型的分类( Classification)问题。分类模型可用来预测离散值。当机器学习模型最终目标(模型输出)是布尔或一定范围的数时,例如判断一张图片是不是特定目标,结果是不是0或者1,或者输出是1-10之间的整数等等,这类需求则大多数可以通过分类问题来解决。典型的就是猜输赢。当我们对预测的结果已经有了明确的选项,就可以使用Classification方案。
-
下载地址:
https://archive.ics.uci.edu/ml/datasets/Adult
▍Vowpal Wabbit数据格式
Vowpal Wabbit,简称VW,是一个功能强大的开源,在线(online)和外存学习(out-of-core machine learning)系统,由微软研究院的John Langford及其同事创建。Azure ML 通过 Train VW 和 Score VW 模块对 VW 提供本机支持。可以使用它来训练大于 10 GB 的数据集,这通常是 Azure ML 中学习算法允许的上限。它支持许多学习算法,包括OLS回归(OLS regression),矩阵分解(matrix factorization),单层神经网络(single layer neural network),隐狄利克雷分配模型(Latent Dirichlet Allocation),上下文赌博机(Contextual Bandits)等
VW的输入数据每行表示一个样本,每个样本的格式必须如下
label | feature1:value1 feature2:value2 ...简单的说,每一条样本的第一个是标签(Label),后面是特征(Feature)。也就是每一条样本都是有标签样本(labeled)
▍Parquet 列式存储格式
Parquet 是 Hadoop 生态圈中主流的列式存储格式,最早是由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 孵化器里毕业成为 Apache 顶级项目。
有这样一句话流传:如果说 HDFS 是大数据时代文件系统的事实标准,Parquet 就是大数据时代存储格式的事实标准。Parquet 列式存储格式的压缩比很高,所以IO操作更小。
Parquet 是与语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与 Parquet 适配的查询引擎包括 Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL等,计算框架包括 MapReduce, Spark, Cascading, Crunch, Scalding, Kite 等,数据模型包括 Avro, Thrift, Protocol Buffer, POJOs 等。所以Parquet就是一个数据存储,提供引擎快速查询数据的格式。
深入分析
这个案例一共九个工作节点,我们逐个分析每一个节点中值得关注的细节和核心信息。
▍Adult Census Income Binary Classification dataset节点
这个节点是数据的输入,核心有三个信息
-
Datastore name:azureml_globaldatasets是一个链接,点击可以跳转到数据存储的位置
-
Relative path:描述在Datastore中当前文件的位置,默认是GenericCSV/Adult_Census_Income_Binary_Classification_dataset
点击azureml_globaldatasets将跳转到Datastore浏览器,您可以在这个浏览器下观察到您存储的数据。大致的界面如下

在左侧我们最需要关注的文件是_data.parquet,该文件是Parquet 列式存储格式文件。建议您下载,在后续的步骤中,我们将操作和分析这个文件。
▍Select Columns in Dataset节点
这个节点是对数据列(特征)的选择
关键信息是观察选择的列
| 列名 |
含义 |
类型 |
数据格式 |
选择 |
| Age |
年龄 |
离散属性 |
Int64 |
是 |
| workclass |
工作类型 |
标称属性 |
Object |
|
| fnlwgt |
序号 |
连续属性 |
Int64 |
是 |
| education |
学历 |
标称属性 |
Object |
是 |
| education_num |
受教育时间 |
连续属性 |
Int64 |
是 |
| marital_status |
婚姻状态 |
标称属性 |
Object |
是 |
| occupation |
职业 |
标称属性 |
Object |
|
| relationship |
关系 |
标称属性 |
Object |
是 |
| race |
种族 |
标称属性 |
Object |
是 |
| sex |
性别 |
二元属性 |
Object |
是 |
| capital_gain |
资本收益 |
连续属性 |
Int64 |
是 |
| capital_loss |
资本损失 |
连续属性 |
Int64 |
是 |
| hours_per_week |
每周工作小时数 |
离散属性 |
Int64 |
是 |
| native_country |
原籍 |
标称属性 |
Object |
|
| income |
收入 |
二元属性 |
Object |
是 |
▍Execute Python Script节点
这个节点是将Parquet 列式存储格式文件转为VW(Vowpal Wabbit),该节点核心是一段Python代码,我们来详细理解和分析这些代码(在这之前确保您已经下载了_data.parquet和您已经有了Python开发环境)
-
azureml_main函数是Azure ML必须的入口函数。
-
其余代码的核心就是装载parquet,设置标签和特征,生成vw格式。
为了更好的帮助您理解这些代码,我重新写了一段脚本,确保您可以在本地加载_data.parquet,并完整的理解整个过程。
先确保您安装了如下组件
python -m pip install pandaspython -m pip install pyarrow
详细代码和解释
import pandas as pdfrom pandas.api.types import is_numeric_dtypelabel_col = 'income'true_label = '>50K'# 读取_data.parquetdataframe=pd.read_parquet('_data.parquet')# 输出每一列的数据类型for col in dataframe:print(col)print('----------------------------------')# 特征列的集合(不包含income)feature_cols = [col for col in dataframe.columns if col != label_col]for col in dataframe:print(col)print('----------------------------------')# 所有数字列numeric_cols = [col for col in dataframe.columns if is_numeric_dtype(col)]for col in dataframe:print(str(col) +'type is :' + str(dataframe[col].dtype))print('----------------------------------')def parse_row(row):line = []# vw样本的第一个元素,定义该样本的权重,这里因为就两个状态,所以定义1和-1line.append(f"{1 if row[label_col] == true_label else -1} |")# 添加样本的后续值for col in feature_cols:if col in numeric_cols:# 具有数字的值,格式为列名:值line.append(f"{col}:{row[col]}")else:# 非数字的值,格式为列值line.append("".join((str(row[col])).split()).replace("|", "").replace(":", ""))print(line)vw_line = " ".join(line)return vw_linevw = dataframe.apply(parse_row, axis=1).to_frame()
输出样例
['-1 | 39 77516 Bachelors 13 Never-married Not-in-family White Male 2174 0 40']
['1 | 31 84154 Some-college 10 Married-civ-spouse Husband White Male 0 0 38']
▍Split Data节点
这个节点比较简单,按行将数据集分为50%和50%。
▍Train Vowpal Wabbit Model节点
这个节点就是将之前我们生成的vw数据集进行训练建模,需要关注的信息有
-
VW arguments(VW 参数):这个是Vowpal Wabbit可执行文件的命令行参数,loss_function参数开关可选有:classic、expectile、hinge、logistic、poisson、quantile、squared,默认时squared。
这里选择的是
--loss_function logisticlogistic回归由Cox在1958年提出,它的名字虽然叫回归,但其实这是一种二分类算法,并且是一种线性模型。由于是线性模型,因此在预测时计算简单,在某些大规模分类问题,如广告点击率预估(CTR)上得到了成功的应用。如果你的数据规模巨大,而且要求预测速度非常快,则非线性核的SVM、神经网络等非线性模型已经无法使用,此时logistic回归是你为数不多的选择。
-
Specify file type(指定文件类型):VW表示Vowpal Wabbit使用的内部格式,SVMLight是其他一些机器学习工具使用的一种格式。显然我们应该选择VW。
-
Output readable model file(输出可读模型):选择True,文件会保存在与输入文件相同的存储帐户和容器中
-
Output inverted hash file(输出反转哈希):选择True,文件会保存在与输入文件相同的存储帐户和容器中
▍Score Vowpal Wabbit Model节点
Score Vowpal Wabbit Model和 Train Vowpal Wabbit Model差不多,差异的参数是
-
VW arguments(VW 参数):link开关的参数可选有glf1、identity、logistic、poisson,默认是identity。
这里选择的是
--link logistic▍Execute Python Script节点
这个节点也是一段Python脚本,目的是添加一个评估列,这段脚本比较简单
关键代码
# 阈值设定,通过和结果概率比较,得到标签threshold = 0.5# 二分的结果标签binary_class_scored_col_name = "Binary Class Scored Labels"# 二分的评估概率,这个值会被反映为标签binary_class_scored_prob_col_name = "Binary Class Scored Probabilities"output = dataframe.rename(columns={"Results": binary_class_scored_prob_col_name})output[binary_class_scored_col_name] = output[binary_class_scored_prob_col_name].apply(lambda x: 1 if x >= threshold else -1)
▍Edit Metadata节点
Edit Metadata的核心是定义列的元数据,其有两个重要作用
-
重新定义列的数据类型,但要注意的是数据集中的值和数据类型实际上并未更改;更改的是机器学习内部的元数据,它告诉下游组件如何使用该列。比如把一个数字列重新定义为分类值,告诉机器学习将重新看待这个数据列。
-
指示哪一列包含类标签,或者要分类或预测的值。这个功能比较重要,可以帮助机器学习了解哪一列的的训练含义。
所以这次我们需要对Labels做定义,不改变数据类型,但将训练含义定义为Labels类型。这个描述有点绕,我们应该这么说:将一个名为Labels的列定义为标签(Labels)类型
这个元数据的定义,就是为了下一个Evaluate Model做准备,告诉Evaluate Model知道哪一个列是需要评估的标签。
▍Evaluate Model节点
评估模型返回的指标取决于您正在评估的模型类型:
-
分类模型
-
回归模型
-
聚类分析模型
在这个节点我们主要关心在训练完成后输出的图表
ROC 曲线(ROC curve):也称“受试者工作特征曲线”,或者感受性曲线。ROC曲线主要是用于X对Y的预测准确率情况。最初ROC曲线是运用在军事上,现在更多应用在医学领域,判断某种因素对于某种疾病的诊断是否有诊断价值。
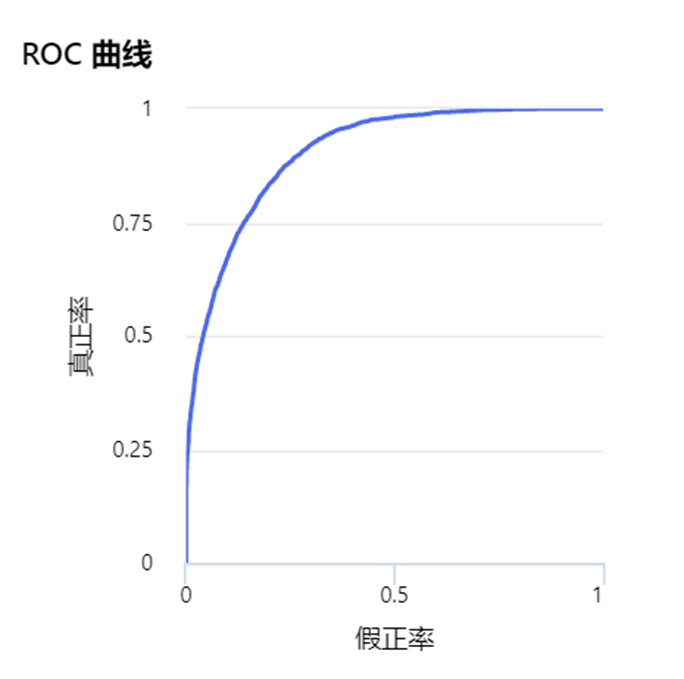
ROC曲线图是反映敏感性与特异性之间关系的曲线。我们一般这么看:横坐标X轴为 1 – 特异性,也称为假阳性率/假正率(误报率),X轴越接近零准确率越高;纵坐标Y轴称为敏感度,也称为真阳性率/真正率(敏感度),Y轴越大代表准确率越好。
根据曲线位置,把整个图划分成了两部分,曲线下方部分的面积被称为AUC(Area Under Curve),用来表示预测准确性,AUC值越高,也就是曲线下方面积越大,说明预测准确率越高。曲线越接近左上角(X越小,Y越大),预测准确率越高。也就是说AUC越接近1.0,检测方法真实性越高,小于等于0.5时,则真实性最低,无应用价值。
所以可以看出ROC曲线非常适合描述个二分问题,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况。如果一个实例是正类并且也 被 预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。
精度-召回曲线(Precision-recall curve):召回率是指正确预测为正的占全部实际为正的比例,召回率是针对原样本而言的,其含义是在实际为正的样本中被预测为正样本的概率。高的召回率意味着可能会有更多的误检,但是会尽力找到每一个应该被找到的对象。
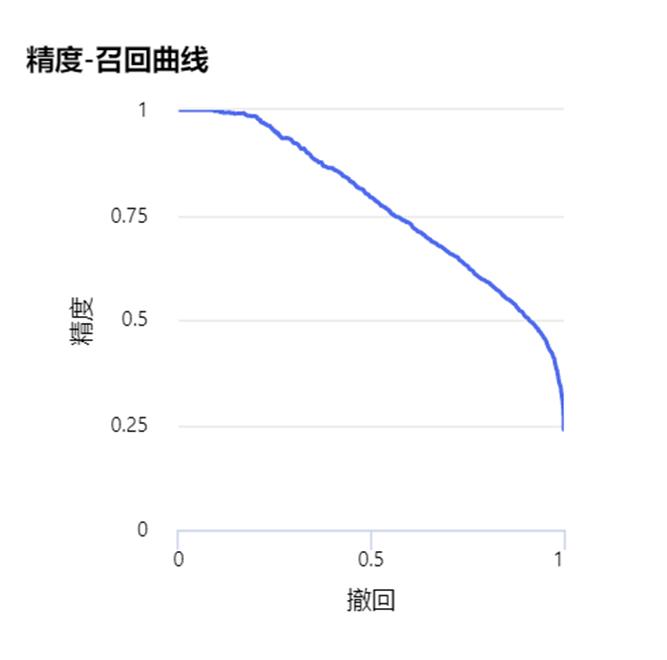
精确度 - 召回曲线显示了不同阈值时精度和召回之间的权衡。曲线下的高区域代表高召回率和高精度,其中高精度与低假正率有关,高召回率与低假负率有关。两者的高分都表明分类器正在返回准确的结果(高精度),并且返回所有正样本的大部分(高召回率)。
因为精度和召回的矛盾,所以我们引入了F1分数(F1 Score),用来衡量二分类模型精确度。它同时兼顾了分类模型的精确率和召回率。F1分数可以看作是模型精确率和召回率的一种调和平均,它的最大值是1,最小值是0。
提升曲线(Lift curve):与ROC曲线不同的是lift考虑分类器的准确性,也就是使用分类器获得的正类数量和不使用分类器随机获取正类数量的比例。提升曲线是评估一个预测模型是否有效的一个度量;这个比值由运用和不运用这个模型所得来的结果计算而来。
举例来说就是:一个公司的客群有10000个,随着业务的变化,其中有500个客户的资信开始变差。如果给1000个客户提供授信也就是说,可能会遇到50个客户因为资信问题,将遇到风险。但是如果运用模型对坏客户加以预测,只选择模型分数最高的1000个客户授信,如果这1000个客户表现出来最终安全有风险的只有8户,说明模型在其中是起到作用的,此时的LIFT就是大于1的。如果反过来最终证明出现风险的客户超过或等于50个,LIFT小于等于1,那么从效果上来看这个模型用了还不如不用。LIFT就是这样一个指标,可以衡量使用这个模型比随机选择对坏样本的预测能力提升了多少倍。
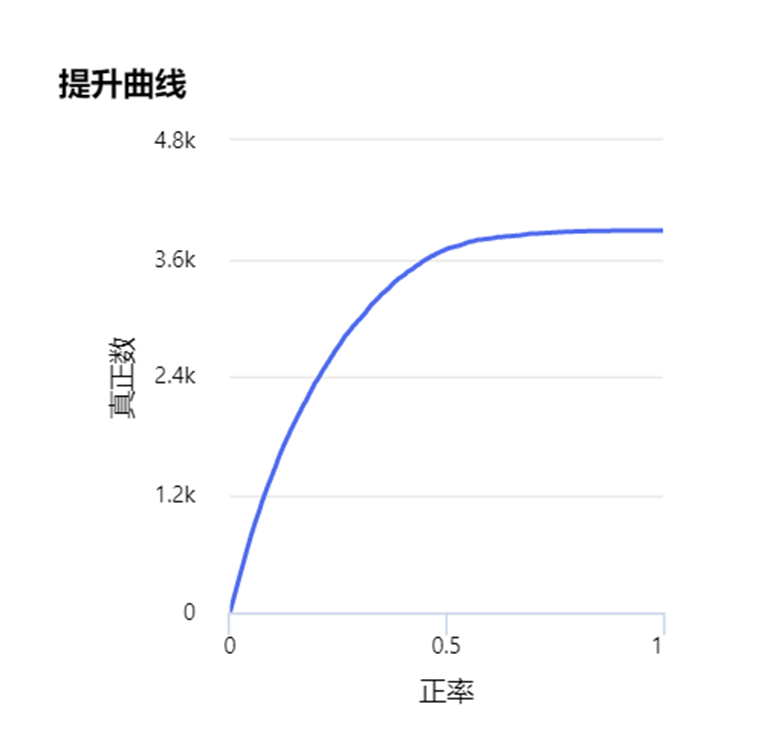
通常计算LIFT的时候会把模型的最终得分按照从低到高(风险概率从高到低)排序并等频分为10组,计算分数最低的一组对应的累计坏样本占比/累计总样本占比就等于LIFT值了。

到这里,Binary Classification using Vowpal Wabbit Model - Adult Income Prediction案例的分析我们完成了,在这个过程中,我们详细的了解到各个节点的核心信息和相关的概念。从数据源、数据处理、Python脚本、元数据定义和模型质量报告。也同时接触到了大量的机器学习概念,本篇非常值得推荐作为Microsoft Azure Machine Learning Studio和机器学习的入门和深入读物。
在这之后,我将继续编写其他Microsoft Azure Machine Learning Studio案例。每一篇案例都可以独立阅读,因此有些概念会重复出现在每一篇中。
微软最有价值专家(MVP)

微软最有价值专家是微软公司授予第三方技术专业人士的一个全球奖项。29年来,世界各地的技术社区领导者,因其在线上和线下的技术社区中分享专业知识和经验而获得此奖项。
MVP是经过严格挑选的专家团队,他们代表着技术最精湛且最具智慧的人,是对社区投入极大的热情并乐于助人的专家。MVP致力于通过演讲、论坛问答、创建网站、撰写博客、分享视频、开源项目、组织会议等方式来帮助他人,并最大程度地帮助微软技术社区用户使用 Microsoft 技术。
更多详情请登录官方网站:
https://mvp.microsoft.com/zh-cn
了解如何使用 Azure 机器学习训练和部署模型以及管理 ML 生命周期 (MLOps)。教程、代码示例、API 参考和其他资源。