如何提升Transformer的运行效率一直是业内研究的热点。Transformer中的attention操作,需要计算序列中两两向量之间的内积,这导致每层attention计算的时间复杂度是序列长度的指数次方,非常耗时。NAACL 2022发表了一篇论文FNet: Mixing Tokens with Fourier Transforms,被评为NAACL 2022最高效论文,通过将attention层替换成无参数的傅里叶变换,实现了在GPU上80%的运行效率提升。
1
从MLP-Mixer说起
首先介绍一下历史背景工作MLP-Mixer。MLP-Mixer是谷歌于2021年发表的一篇针对CV领域Transformer进行改造的文章,将Transformer替换成全部为MLP的更简单的结构。本文的基础方法建立在ViT这种基于Transformer的图像编码器思路的基础上,将图像分割成多个patch,将一个图像的多个patch视为一个序列,再输入到Transformer中。对这部分还不太了解的同学可以参考我之前的文章:从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程。
MLP-Mixer模型的整体结构如下图,主要分为channel-mixing MLPs和token-mixing MLPs两个部分:
channel-mixing MLPs:实现每个patch(token)内部不同channel的信息交互,在每个patch(token)内独立的进行;
token-mixing MLPs:实现整张图不同patch之间的信息交互,在所有patch上进行。
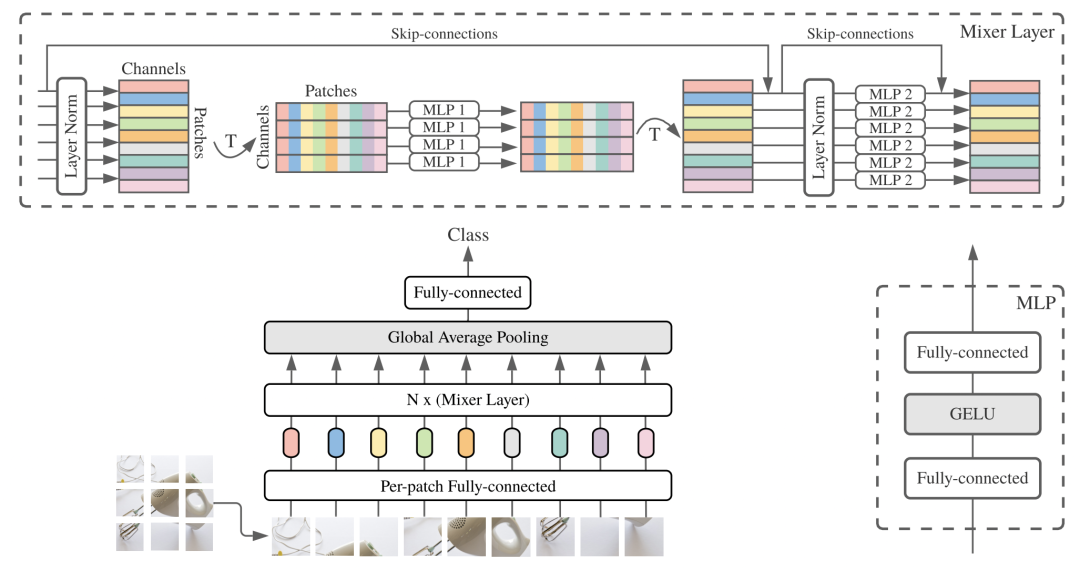
MLP-Mixer的结构简单,运行速度快,同时在大数据上训练后也取得了比较好的效果。
2
FNet—更高效的信息融合
无论是Attention还是MLP-Mixer,其核心都是为了实现token之间信息的交互方式。在MLP-Mixer中,利用内部、外部两种全连接,实现了token内部不同channel,以整个序列不同token之间的信息交互。而本文提出的FNet使用了傅里叶变换来实现token内部和外部的信息交互。
傅里叶变换的公式如下,从公式中可以看出,傅里叶变换生成的每个元素,都是原始序列中所有token信息的融合,这也是实现信息交互的一种方式。
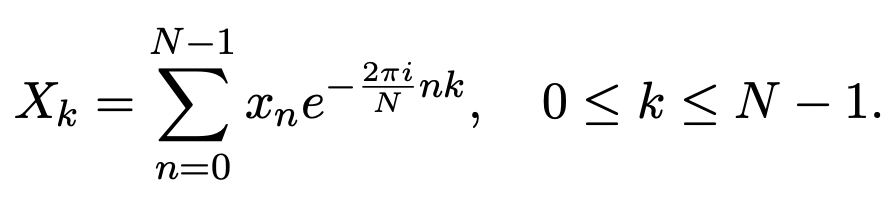
FNet将原始Transformer中的所有self-attention结构都替换成了上面的傅里叶变换形式,类似MLP-MIxer,也有两层傅里叶变换,一层用来进行token内部的信息交互,另一层用来进行整个序列各个token之间的信息交互。模型的整体输入和原始Bert一样,也是利用Word+Position+Type三种embedding实现的。
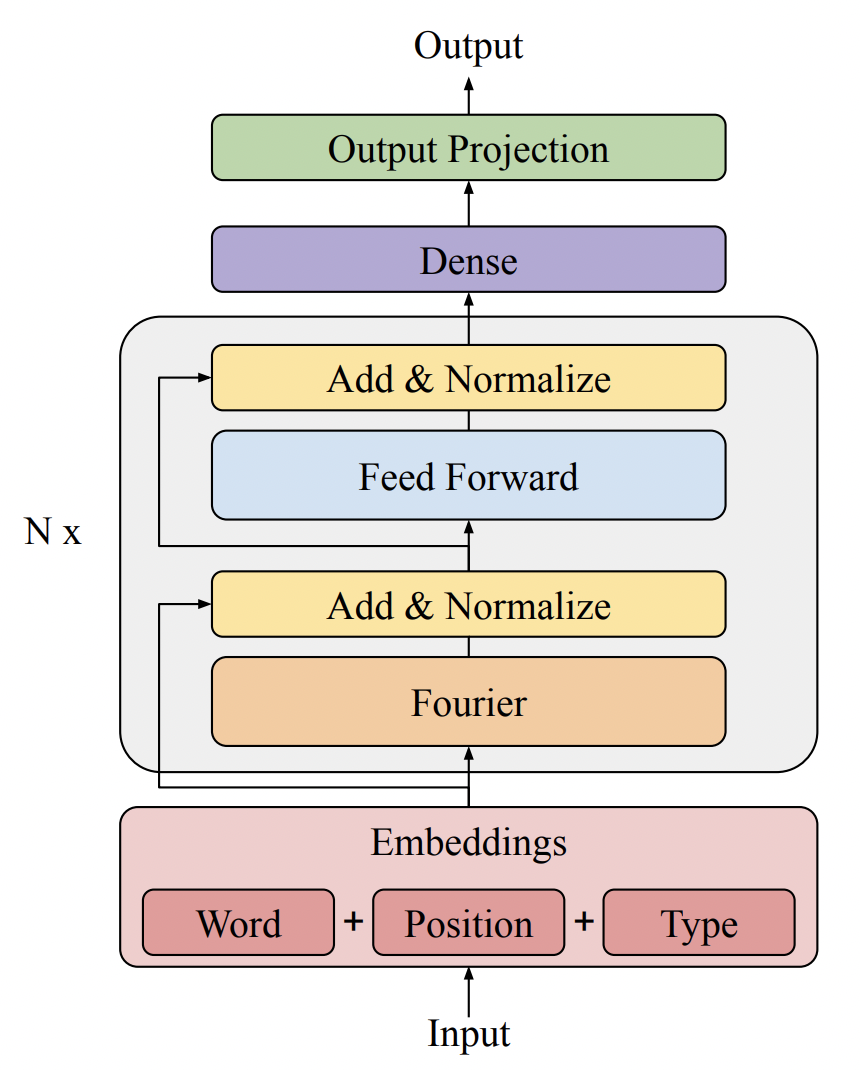
FNet和MLP-Mixer相比的一大特点是,FNet使用的傅里叶变换层不包括任何参数,可以实现更快速的运算,节省参数量。
3
效果和运行速度对比
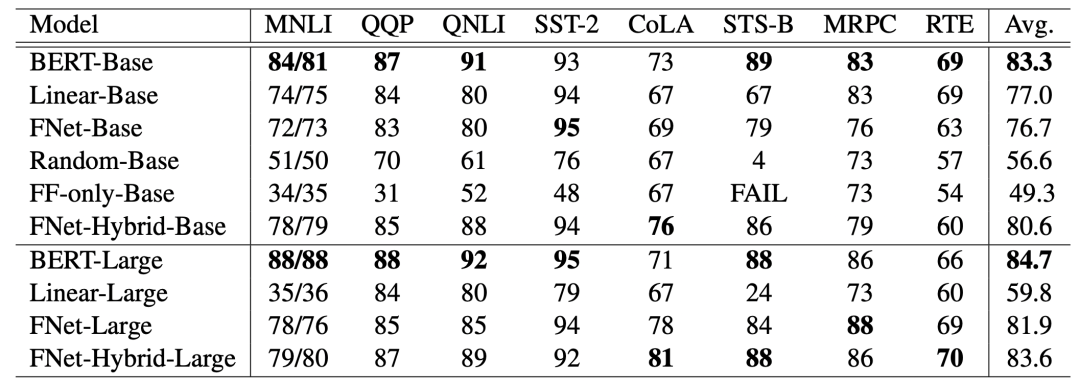
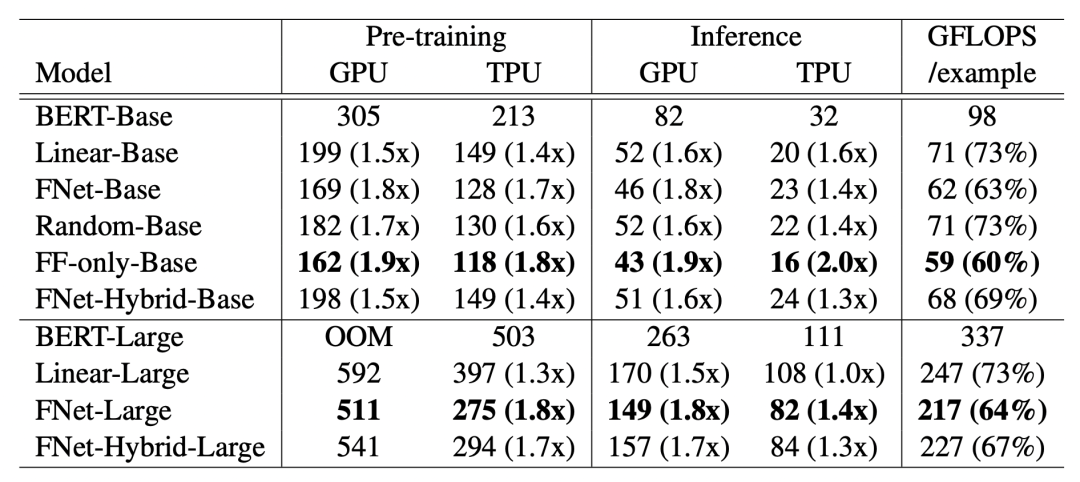
文中在多个公开数据集上,对比了基础的BERT,以及使用不同交互方式的Transformer简化版本的效果和运行速度。其中Linear-Base指的是使用MLP进行token内部和外部的信息交互,类似于MLP-Mixer结构。Random-Base指的是将self-attention替换成两个随机矩阵,分别用来进行内部和外部的交互。FF-only指的是完全去掉self-attention,不添加任何token之间的信息交互。FNet-Hybrid-Base中,作者将最后一层的self-attention保留,其他层仍然使用傅里叶变换。
实验结果如下图。从模型效果对比上看,不增加token交互的效果会差很多。FNet-Base相比BERT-Base在大部分数据集上效果都没有损失很多。虽然FNet将self-attention提出成了没有任何参数的傅里叶变换,但是效果也没有比使用全连接的Liner-Base差很多。对于Large模型,FNet和BERT的差距缩小到了3%,文中解释说是因为FNet-Large相比BERT-Large的训练过程更加稳定。
在GPU和TPU的运行速度上,FNet比BERT等模型的效率要提升很多,体现了FNet运算精简的优势。
4
总结
本文介绍了NAACL 2022的一篇Transformer提效工作FNet,通过将Transformer中的self-attention替换为无参数的傅里叶变换,实现了效果微跌的情况下,运行速度和计算开销的大幅提升。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书