目录
2.2.2 选择优化器(如rmsprop或adagrad)并指定损失函数
3.1 构建tf.keras.Sequential()的具体描述
3.1.1 tf.keras.models.Sequential 中的方法
0.学习地址推荐
深度学习:Keras入门(一)之基础篇 - lc19861217 - 博客园 (cnblogs.com)
(1条消息) 深度学习:Keras基础--序贯模型(sequential)_ZhaoJW86的博客-CSDN博客_sequential()
tf.keras.Sequential |TensorFlow Core v2.9.1 (google.cn)
1. tensorflow.dataset数据集操作
1.1 自定义生成数据集
从内存生成,适合不大的数据集。
import tensorflow as tf
# 传入list,将list中元素逐个转换为Tensor对象然后依次放入Dataset中
x1 = [0, 1, 2, 3, 4]
x2 = [[0, 1], [2, 3], [4, 5]]
ds1 = tf.data.Dataset.from_tensor_slices(x1)
ds2 = tf.data.Dataset.from_tensor_slices(x2)
for step, m in enumerate(ds1):
print(m) # tf.Tensor(0, shape=(), dtype=int32)...
for step, m in enumerate(ds2):
print(m) # tf.Tensor([0 1], shape=(2,), dtype=int32)...
# 传入tuple。这种形式适合整合特征和标签。
xx = [[0, 1], [2, 3], [4, 5]]
yy = [11, 22, 33]
ds11 = tf.data.Dataset.from_tensor_slices((xx, yy))
for step, (ds11_xx, ds11_yy) in enumerate(ds11):
print(ds11_xx) # tf.Tensor([0 1], shape=(2,), dtype=int32)...
print(ds11_yy) # tf.Tensor(11, shape=(), dtype=int32)...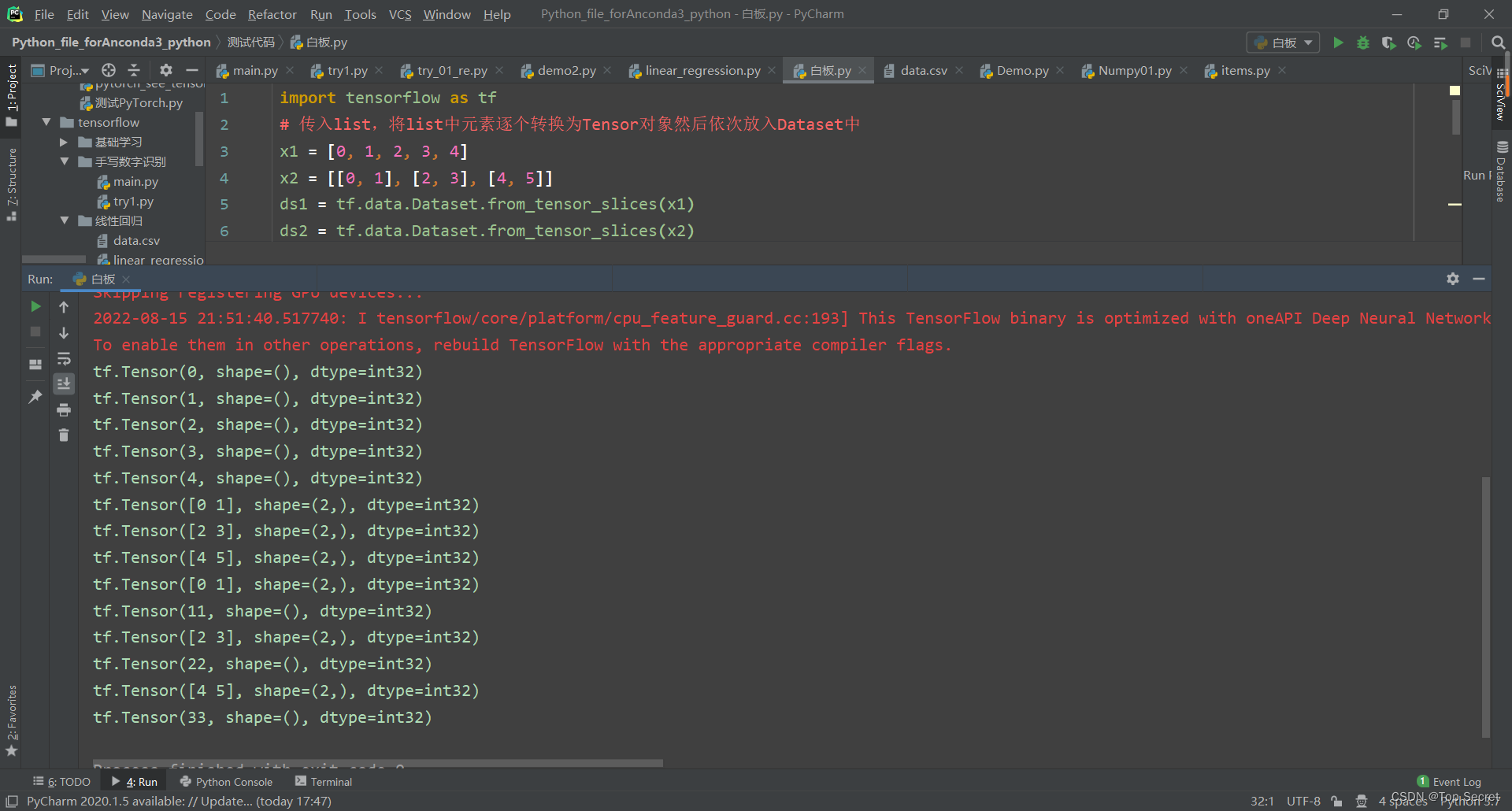
1.2 从CSV文件生成数据集
(1条消息) CSV文件处理形成数据集_三叶草~的博客-CSDN博客_csv数据集
2. keras中的sequential模型
keras中的主要数据结构是model(模型),它提供定义完整计算图的方法。通过将图层添加到现有模型/计算图,我们可以构建出复杂的神经网络。Keras有两种不同的构建模型的方法:
- Sequential models
- Functional API
2.1 Sequential模型
Sequential模型可以构建非常复杂的神经网络,包括全连接神经网络、卷积神经网络(CNN)、循环神经网络(RNN)、等等。这里的Sequential更准确的应该理解为堆叠,通过堆叠许多层,构建出深度神经网络。

2.2 基本的Sequential模型开发流程
机器学习通常包括定义模型、定义优化目标、输入数据、训练模型,最后通常还需要使用测试数据评估模型的性能。keras中的Sequential模型构建也包含这些步骤。
2.2.1 输入层
首先,网络的第一层是输入层,读取训练数据。为此,我们需要指定为网络提供的训练数据的大小,这里input_shape参数用于指定输入数据的形状:
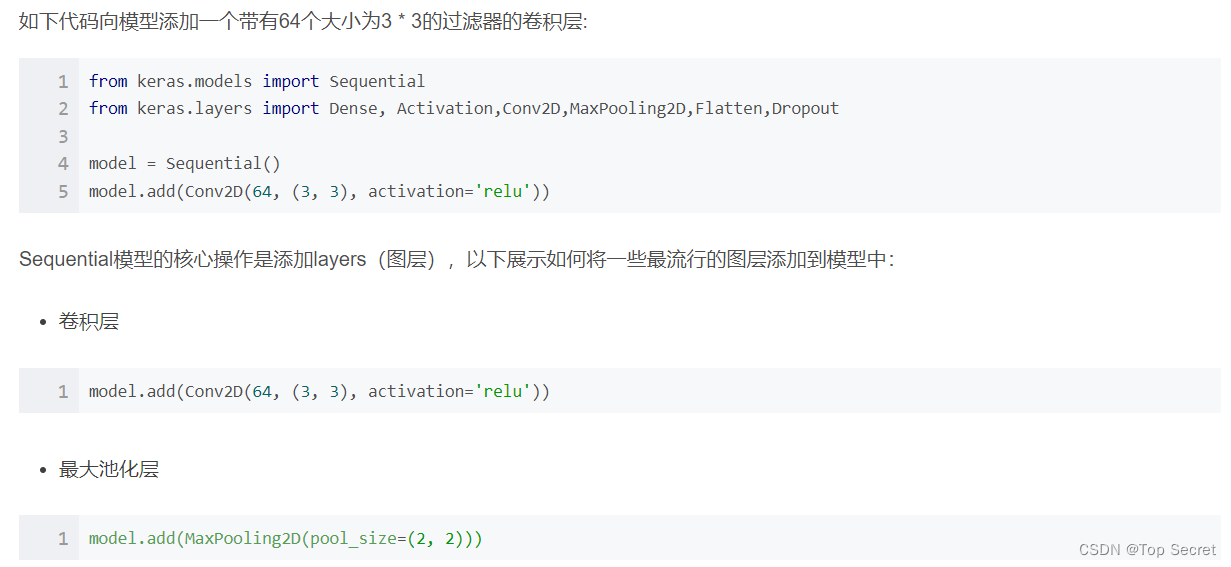
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(224, 224, 3)))上面的代码中,输入层是卷积层,其获取224 * 224 * 3的输入图像。
接下来就是为模型添加中间层和输出层,请参考上面一节的内容,这里不赘述。
2.2.2 选择优化器(如rmsprop或adagrad)并指定损失函数
然后,进入最重要的部分: 选择优化器(如rmsprop或adagrad)并指定损失函数(如categorical_crossentropy)来指定反向传播的计算方法。在keras中,Sequential模型的compile方法用来完成这一操作。例如,在下面的这一行代码中,我们使用’rmsprop’优化器,损失函数为’binary_crossentropy’。

2.3 使用Sequential模型解决线性回归问题
除了构建深度神经网络,keras也可以构建一些简单的算法模型,下面以线性学习为例,说明使用keras解决线性回归问题。
线性回归中,我们根据一些数据点,试图找出最拟合各数据点的直线。为了说明这一问题,我们创建100个数据点,然后通过回归找出拟合这100个数据点的直线。
2.3.1 创建训练数据
import keras
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
trX = np.linspace(-1, 1, 101)
trY = 3 * trX + np.random.randn(*trX.shape) * 0.332.3.2 创建模型
model = Sequential()
model.add(Dense(input_dim=1, output_dim=1, init='uniform', activation='linear'))代码创建一个Sequential模型,这里使用了一个采用线性激活的全连接(Dense)层。它实际上封装了输入值x乘以权重w,加上偏置(bias)b,然后进行线性激活以产生输出。
我们可以查看默认初始化的权重和偏置值:
weights = model.layers[0].get_weights()
w_init = weights[0][0][0]
b_init = weights[1][0]
print('Linear regression model is initialized with weights w: %.2f, b: %.2f' % (w_init, b_init))2.3.3 选择优化器和损失函数
model.compile(optimizer='sgd', loss='mse')选择简单的梯度递减优化算法,损失函数选择均方差(mean squared error, mse)。
2.3.4 训练模型
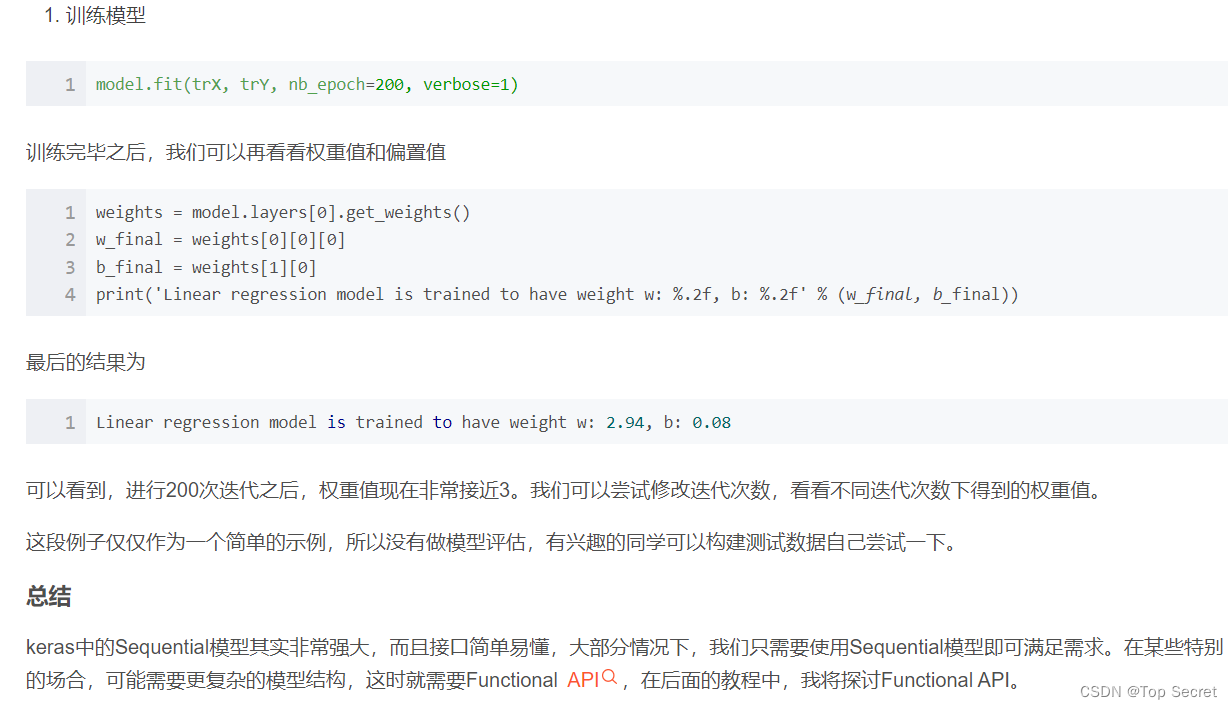
3. tf.keras.Sequential()
Keras有两种类型的模型,序贯模型(Sequential)和函数式模型(Model)。

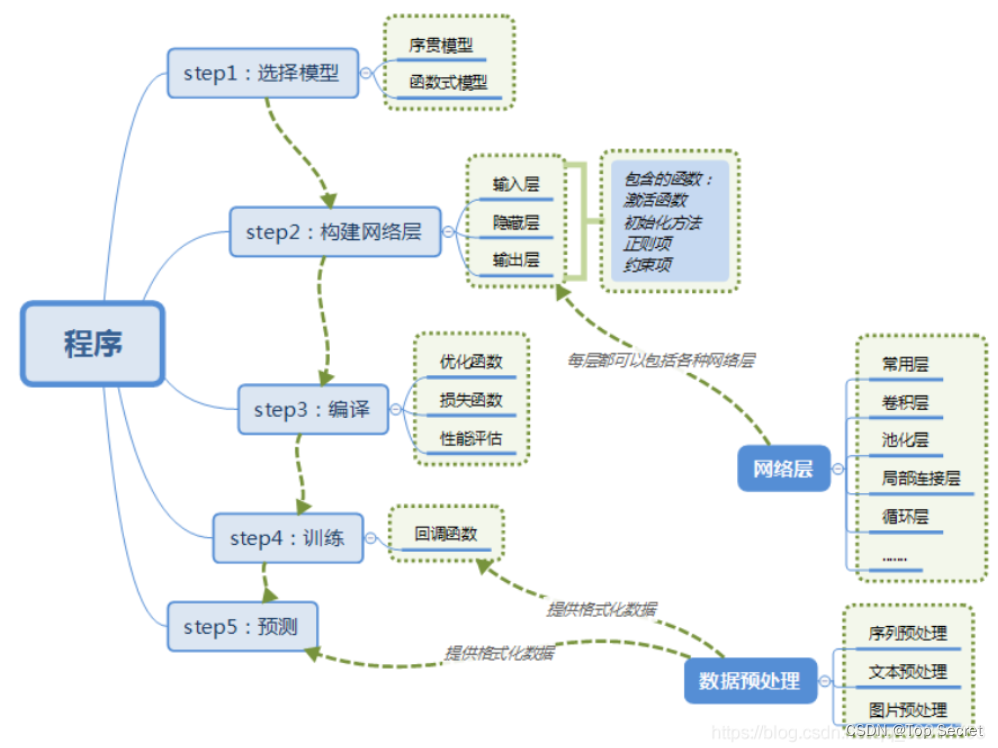
3.1 构建tf.keras.Sequential()的具体描述
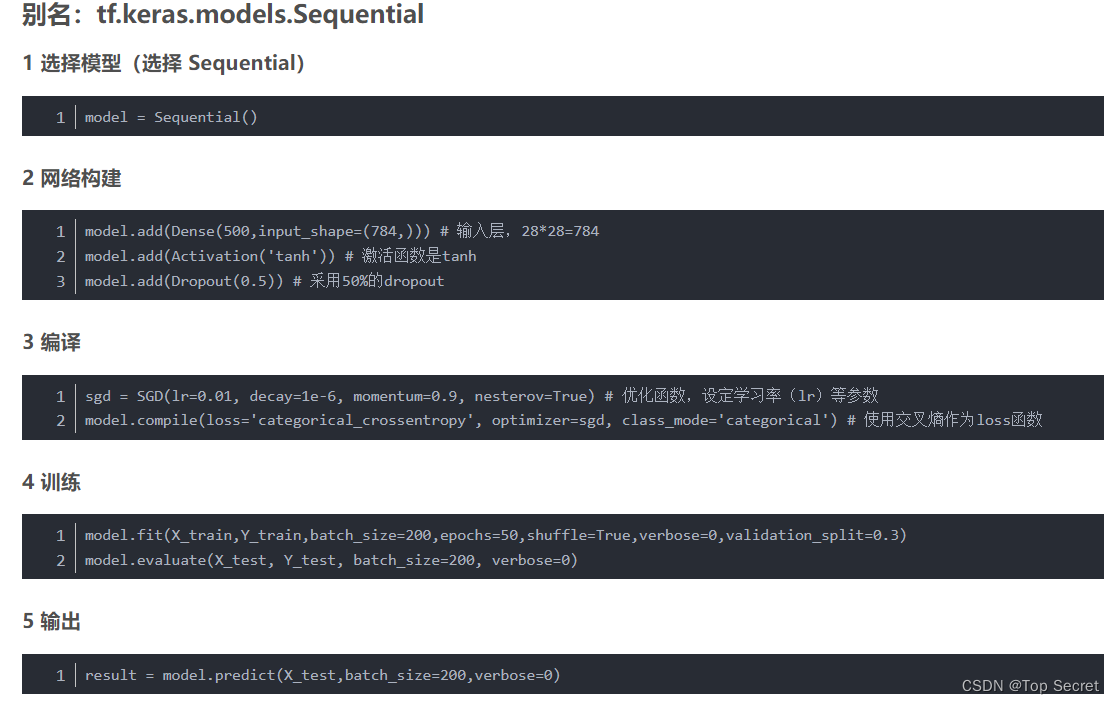
3.1.1 tf.keras.models.Sequential 中的方法
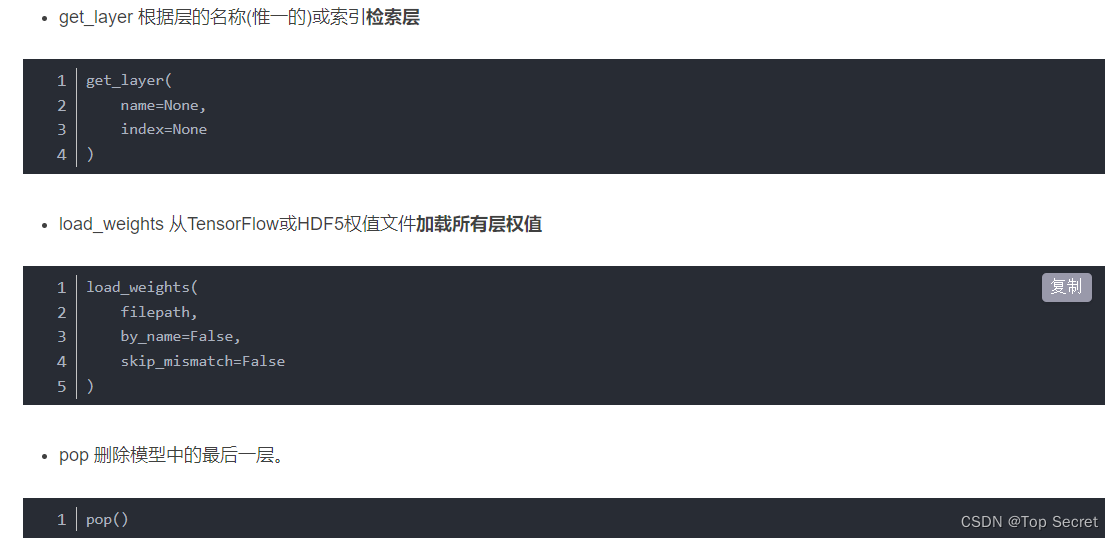
-
add(layer) 添加层
在层堆栈的顶部添加层实例 -
compile 模型配置
compile(
optimizer='rmsprop', # 字符串(优化器的名称)或优化器实例
loss=None, # 损失函数,如果模型有多个输出,您可以通过传递字典或损失列表来对每个输出
# 使用不同的损失,由模型最小化的损失值将是所有独立损失的总和。
metrics=None, # 在训练和测试期间,模型要评估的度量标准列表,通常将使用metrics=['accuracy']。
# 要为一个多输出模型的不同输出指定不同的度量,可以传递一个字典,例如metrics={'output_a': 'accuracy', 'output_b': ['accuracy', 'mse']}。
# 还可以传递矩阵列表(len = len(输出)),比如metrics=[[accuracy'], ['accuracy', 'mse'],或者metrics=['accuracy', ['accuracy', 'mse']]。
loss_weights=None, # 指定标量系数(Python浮点数)的可选列表或字典,以对不同模型输出的损失贡献进行加权。
sample_weight_mode=None, # 如果需要按时间步长进行样本加权(2D加权),请将其设置为“时间”。没有默认的采样权值(1D)。
weighted_metrics=None, # 在训练和测试期间,将通过sample_weight或class_weight评估和加权的度量列表。
target_tensors=None, # 默认情况下,Keras将为模型的目标创建占位符,这些占位符将在训练期间与目标数据一起提供。
# 相反,如果您想使用自己的目标张量(反过来,Keras在训练时不会期望这些目标的外部Numpy数据),可以通过target_tensors参数指定它们。
distribute=None, # 在TF 2.0中不支持
**kwargs # 任何额外的参数
)
- evaluate 评价
evaluate(
x=None, # 输入值
y=None, # 目标值
batch_size=None, # 每次梯度更新的样本数
verbose=1,
sample_weight=None, # 用于加权损失函数,在这种情况下,您应该确保在compile()中指定sample_weight_mode="temporal"。
# 当x是一个数据集时,不支持此参数,而是将示例权重作为x的第三个元素传递。
steps=None, # 样品批次数
callbacks=None, # 回调
max_queue_size=10, # 生成器队列的最大大小。如果未指定,max_queue_size将默认为10。
workers=1, # 使用基于进程的线程时要向上旋转的最大进程数,如果未指定,工人将默认为1。如果为0,将在主线程上执行生成器。
use_multiprocessing=False # 请注意,由于此实现依赖于多进程,因此不应该将非picklable参数传递给生成器,因为它们不能轻松传递给子进程。
)
返回: metrics_names将为标量输出提供显示标签。
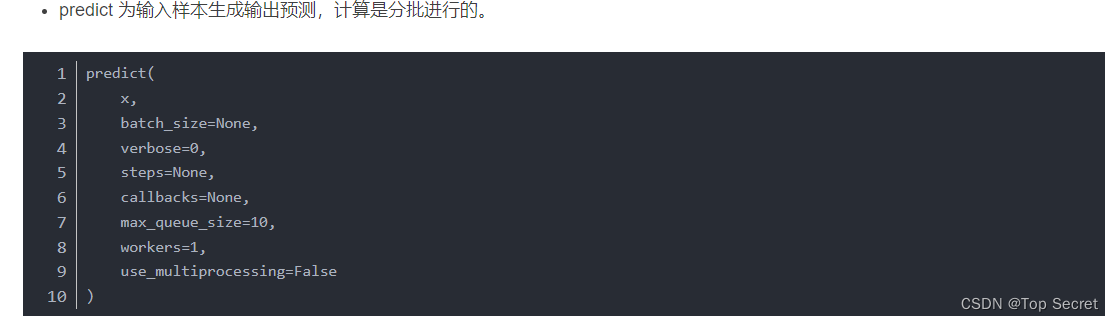
- fit
fit(
x=None,
y=None,
batch_size=None, # 每次梯度更新的样本数
epochs=1, # 训练模型的迭代数
verbose=1,
callbacks=None,
validation_split=0.0, # 将训练数据的一部分用作验证数据
validation_data=None, # 用于评估损失的数据和每个epoch结束时的任何模型度量。模型不会根据这些数据进行训练。validation_data将覆盖validation_split。
shuffle=True, # 在每个epoch之前对训练数据进行洗牌
class_weight=None,
sample_weight=None,
initial_epoch=0, # 开始训练的时间(对于恢复之前的训练很有用)。
steps_per_epoch=None,
validation_steps=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
**kwargs
)