一、ES的安装
1、源码安装
0、注意事项
(1)elasticsearch不能用root用户启动,建议最开始就创建一个普通用户;后续wget安装包、安装/配置jdk等都用这个用户,免得后续因为文件权限、拥有者不匹配引发问题。
(2)es7之后对jdk版本有一定要求,例如es7要求jdk版本在11以后才行。如果本机jdk版本不满足也没关系,具体操作的时候本机jdk可以默认不动,/etc/profile里面配置es启用安装包的这个jdk就可以了。
(3)另外值得注意的是最好使用es安装包也有对应的jdk,这个版本是最稳妥的。
1、创建普通用户
首先创建一个root以外的普通用户,如下:
#添加一个用户
useradd shuozhuo
#设置密码
passwd shuozhuo
注:我这里设为为Zs+qq之后所有的操作都用这个用户,除非修改/etc/配置。
2、下载相应安装包
(1)搜索elasticsearch找到官网 这里
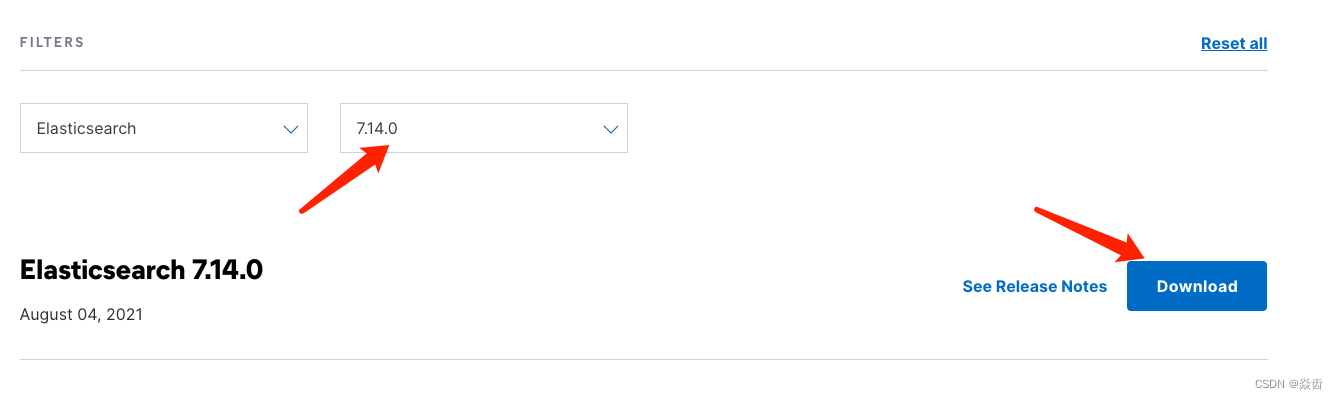
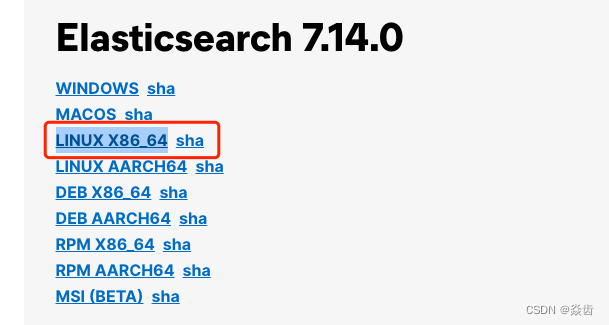
(2)点击下载→查看历史版本→选择对应的版本→下载→选择linux_64右键赋值链接
注:我这里下载的是7.14.0版本。

3、下载解压
#下载安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.14.0-linux-x86_64.tar.gz
#解压安装包
tar zxvf elasticsearch-7.14.0-linux-x86_64.tar.gz
解压后相应文件如下。
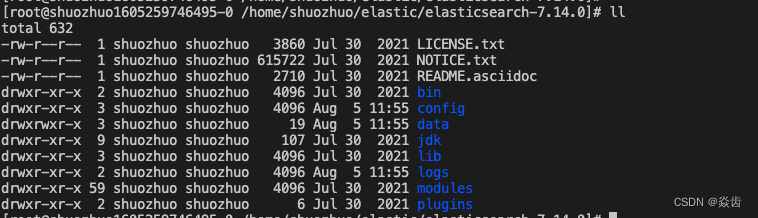
①bin:启动ES服务脚本的目录
②config:ES配置文件目录,其中常用的就是 elasticsearch.yml 文件
③data: ES的数据存放目录
④jdk:ES提供的需要指定的jdk目录。注:建议指定ES就用这个jdk。
⑤lib:ES依赖的第三方库的目录
⑥logs:ES的日志目录
⑦modules:ES各模块目录
⑧plugins:插件目录,ik分词器之类的应该就是安装在这里。7.14.0内置的jdk版本为16.0.1,如下:

4、配置环境变量
需要把ES中的JDK配置到JAVA_HOME中;同时在对应的/etc/profile中把路径配置给环境变量ES_JAVA_HOME。
注:ES_JAVA_HOME是ES默认的引用jdk的环境变量,最好配一下。
#注意:我这里的解压包的jdk的路径为 '/home/shuozhuo/elastic/elasticsearch-7.14.0/jdk
'
export JAVA_HOME=/home/shuozhuo/elastic/elasticsearch-7.14.0/jdk
export ES_JAVA_HOME=/home/shuozhuo/elastic/elasticsearch-7.14.0/jdk
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
#使之生效
source /etc/profile
或者直接 vim /etc/profile 进行编辑也是可以的。
5、启动
#跳转到bin目录下
cd bin
#执行启动
./elasticsearch
#后台启动
./elasticsearch -d
#关闭
kill -9 pid如下:

没有报错刷出一定量的日志应该就是成功了。ps查看也是有进程的。
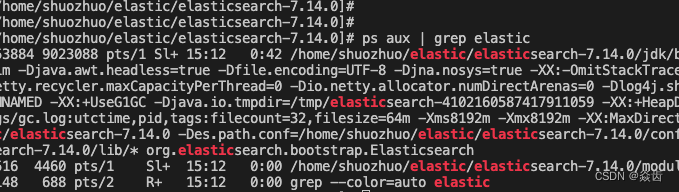
6、验证是否正常启动
#新开一个终端执行
curl 127.0.0.1:9200 或者
curl localhost:9200
curl http://localhost:9200出现如下json如下说明es运行是完全正常的。
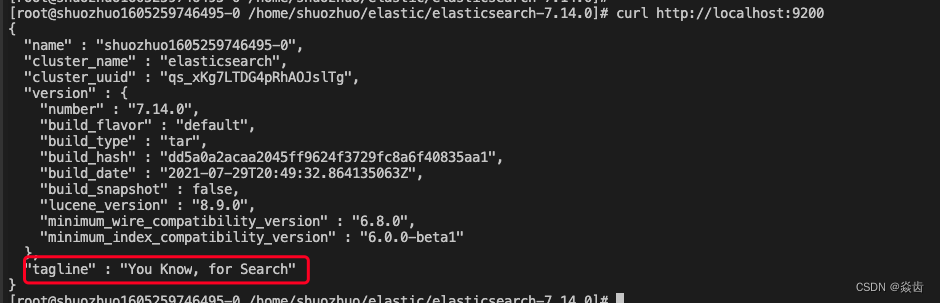
7、开启远程访问
1、关闭ES
2、vim elasticsearch.yml将其中的network.host修改为如下
network.host: 0.0.0.0注:0.0.0.0表示允许任何位置的任何ip访问。
之后启动发现出现如下报错。

关于这个错误说明一下。一旦开启外部连接模式ES会默认会以集群的方式启动,对于这个问题我们修改使之单节点启动即可。报错提示的就是缺少默认参数,这个三个默认参数的含义如下。
1 discovery.seed_hosts: 集群主机列表
2 discovery.seed_providers: 基于配置文件配置集群主机列表
3 cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填接下来配置单节点模式启动。
#打开配置文件
vim elasticsearch.yml
#将其中的如下语句
cluster.initial_master_nodes: ["node-1", "node-2"]
改为
cluster.initial_master_nodes: ["node-1"]注:其含义是使用一个节点去初始化集群;其中的node-1是节点名称。当前节点默认就是node-1如下。
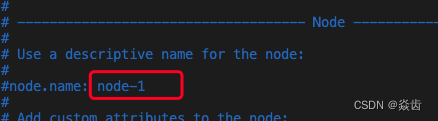
然后重新启动ES就可以了。
之后在网络配置畅通的情况下在浏览器访问IP:9200应该也是通的,如下就说明ok了。
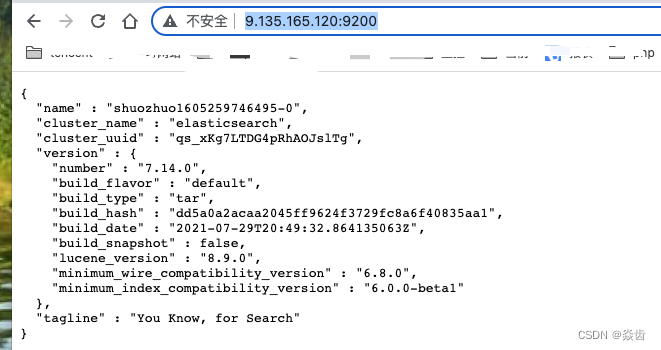
8、相关问题与报错
①默认启动的ES服务是不允许远程访问的
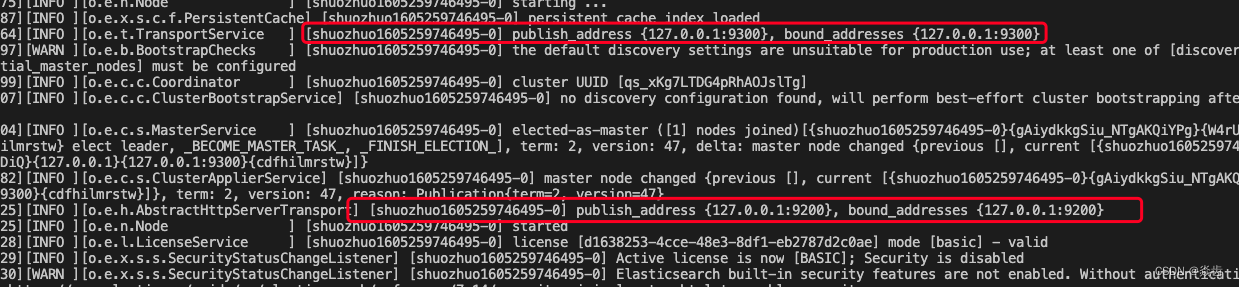
②默认ES监听的web(Restful)端口是9200,TCP端口是9300。启动日志也可以看到相应记录如下:
③注意启动ES的时候不能使用root用户,否则会有如下报错。

④如果没有权限的话执行会包如下错误


⑤另外还会有些内存不足等问题,直接网上搜一般都能搜出原因。
2、docker安装
前言:安装包的方式太复杂了,使用docker更简单。
0、安装docker
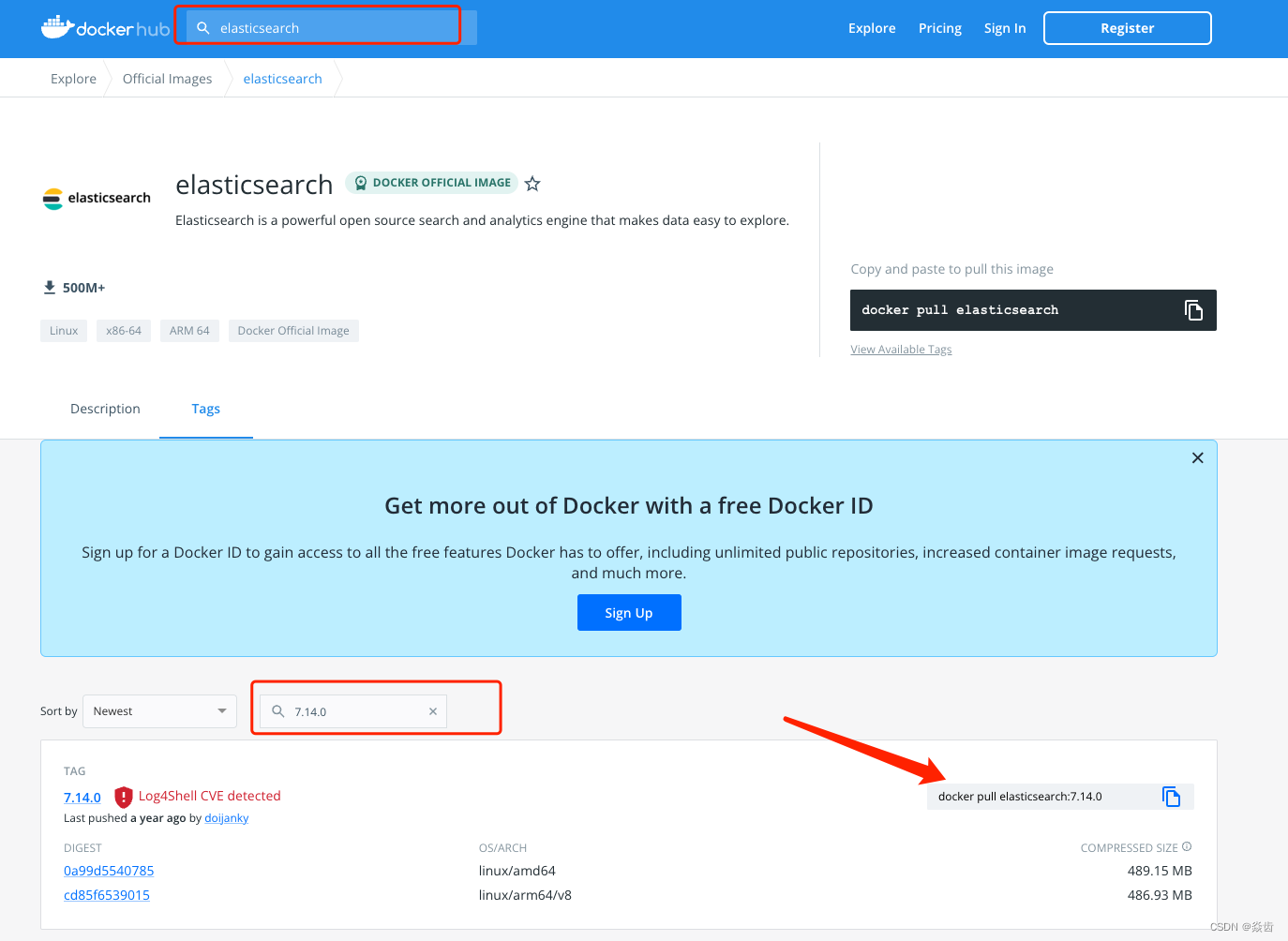
1、获取镜像
docker pull elasticsearch:7.14.0百度“dockerhub” →找到镜像库官网 → 搜索elasticsearch → Tag处搜索目标版本

2、运行ES
docker run -d -p 9200:9200 -p 9300:9300 -e "discover.type=single-node" elasticsearch:7.14.0①-p:通过外部的宿主机访问容器
②-d:后台运行
③9200:9200:宿主机的9200映射到docker的9200;宿主机的9300映射到docker的9300.
④-e “discoverXXX”: 以单节点启动
3、访问ES
http://ip:9200
二、Kibana的安装
1、源码安装
0、注意事项:
① Kibana版本一定要和es版本完全匹配!!!
② Kibana的安装要求es服务运行起来!!
1、ES官网下载对应版本的Kibana 这里
复制如下链接地址,Linux机器下载。
#下载对应版本
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.14.0-linux-x86_64.tar.gz
#解压缩
tar zxvf kibana-7.14.0-linux-x86_64.tar.gz2、编辑配置文件
编辑kibana配置文件 vim ./kibana/kibana.yml ;按如下方式修改。
#开启kibana远程访问
server.host: "0.0.0.0"
#指定kibana连接本机的es
elasticsearch.hosts: ["http://localhost:9200"] 
注:我这里也修改了下默认端口。
3、启动kibana
之后到bin目录下执行 ./kibana 启动kibana;如下应该就可以了。
注:可以看到其对应的端口是5601.

4、验证访问与连接
如下图说明kibana启动正常
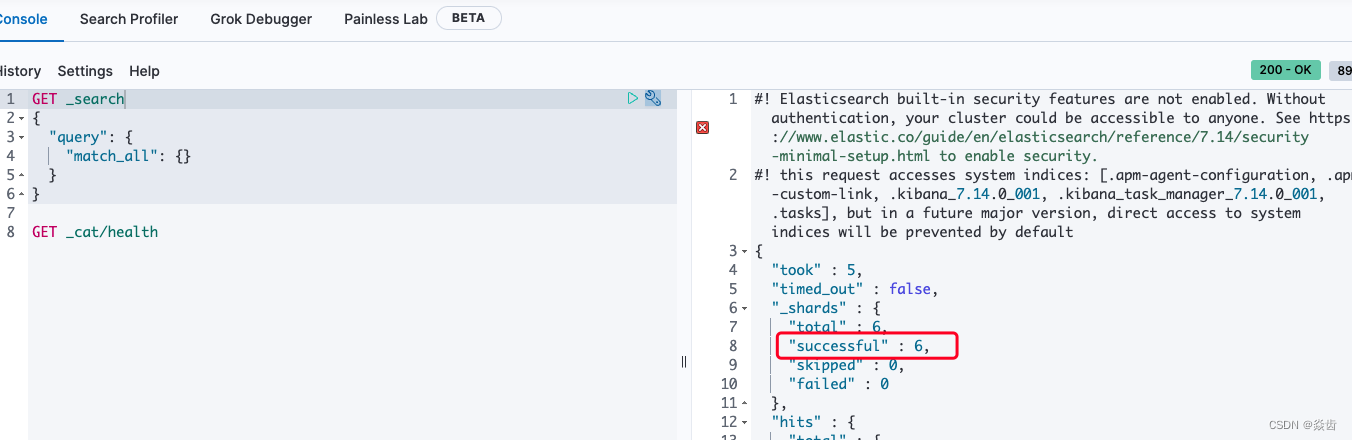
左侧边栏 Home → Dev Tools →执行默认的语句;如下就是ok的。
2、docker安装
类似ES
三、ES的分词器(安装分词器)
0、基本概念(Analysis与Analyzer)
Analysis:文本分析是指吧全文本转换成一系列单词(term/token)的过程,也要分词。
Analyzer:分词器。Analysis是由Analyzer实现的。分词就是将文档通过Analyzer分成一个个Term(关键词),每个Term都指向包含这个Term的文档。
分词器(Analyzer)组成:执行也按照如下顺序。不同分词器实现不同,一般②是必须有的。
①字符过滤器(character filter):对文本分词之前进行预处理,例如过滤掉html的标签等特殊字符、把&转换成and之类的。
②分词器(tokenizers):英文分词就根据空格将单词分开;中文比较复杂,可以采用机器学习算法来分词。
③token过滤器(Token filters):将切分的单子进行加工。如大小写转换、去掉停用词(如a、the这种)、加入同义词。
1、ES内置分词器及效果测试
①Standard Analyzer(标准分词器):英文按单词切分,小写处理、中文单字处理。 为默认分词器。
②Simple Analyzer(简单分词器):按照单词切分(符号被过滤),小写处理、中文按空格分词。
③Stop Analyzer: 小写处理,停用词过滤。
④Whiltespace Analyzer:按照空格切分,不转小写
⑤Keyword Analyzer:部分词,直接将输入作为输出。
分词器测试:
#简单分词器
POST /_analyze
{
"analyzer": "standard",
"text":"I love you, 问世间情为何物"
}
#简单分词器
POST /_analyze
{
"analyzer": "simple",
"text":"I love you, 问世间情为何物"
}
注:中文就是按照空格分词2、创建索引设置分词
#无非就是指定数据类型平齐的位置也指定下分词器就好了
PUT /test
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "keyword"
}
}
}
}3、中文分词器(IK分词器)安装
根据前面知道ES内置的分词器都是不适应于中文的;为此需要专门应用中文分词器。
常用的中文分词器有 smartCN、IK等,这里推荐使用最常见的IK分词器(Lucene时期就存在、对中文的处理也更智能)。
注意:IK分词器的版本要和ES完全一致(小版本号也要完全一致)
(0)在ES安装路径的plugins目录下新建ik目录
#叫什么名字无所谓;ES会自动扫描plugins路径中的信息,发现插件后会自动加载。
mkdir ik
cd ik(1)选择对应的版本,并下载。
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.14.0/elasticsearch-analysis-ik-7.14.0.zipgithub现在对应版本: IK
(2)解压
unzip elasticsearch-analysis-ik-7.14.0.zip
注:如果没有unzip需要用yum install -y unzip 安装(3)重启ES就可以了。
4、中文分词器(IK分词器)使用
IK分词器有两种颗粒度的拆分,两种分词简名分别是ik_smart和ik_max_word:
①ik_smart:最粗粒度的拆分。
②ik_max_word:会将文本做最细粒度的拆分。
如下实际测试就可以直观看到分词效果。
POST /_analyze
{
"text":"中华人民",
"analyzer": "ik_smart"
}
POST /_analyze
{
"text":"中华人民",
"analyzer": "ik_max_word"
}
5、扩展词、停用词配置
IK支持自定义 扩展词典 和 停用词典。
扩展词典:有些此并不是关键词,但是也希望被ES用来作为检索的关键词,可以将这些词加入扩展词典。
停用词典:有些此是关键词,但是出于业务需要不想这些关键词被检索到,可以将这些词放入停用词典。
举个例子:现在有一家公司名称为“全知科技”,另外有一个员工叫做“谭锦黎”。默认情况下即便是ik_max_word也不知道"全知"、“谭锦黎”是一个单独的词,但是我又有这种“全知 谭锦黎”的搜索需求。这个时候我们就可以借助扩展词配置来实现。
具体配置:
(0)分词器下有如下文件“分词器/config/IKAnalyzer.cfg.xml”,内容如下。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>(1)在配置文件中指定扩展字典文件名称为 shuozhuoext.dict
(2)然后在此路径下创建shuozhuoext.dic文件,并在文件中添加你想要扩展的关键词,如下。

(3)然后重启ES
(4)验证效果如下

(5)另外分词器/config目录下也给我们预先配置好了诸多生僻的词组,存与对应的.dic文件中。
通常扩展词典/停用词典分别就在默认的extra_main.dic和extra_stopword.dic中扩展就行了。
必要的时候再自己创建词典。