基本上所做的项目中都出现了过拟合,这也是每个神经网络训练者需要面对的问题。越多的神经元,就越能表达复杂的模型,但也不是越多越好,在训练样本有限的情况下,很容易导致过拟合。
过拟合的解决方案:
1、重新清洗数据
2、增加训练数据量
3、损失函数加正则化项(详细可看正则化惩罚项文章链接)

不同惩罚系数下的拟合结果对比如图,惩罚系数λ=0.001伸出的爪子本质就是过拟合了,λ=0.1泛化能力强。
4、Dropout
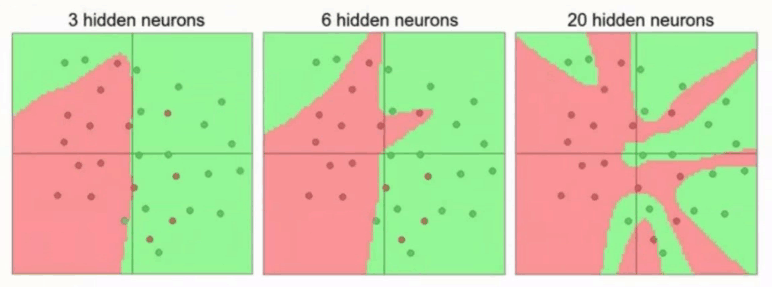
复杂的网络VC维非常高,这导致它的记忆能力非常强,很多个体上没有泛化能力的特征也会被它记忆学习下来,网络中的大量的w参数会记住点点星星的特点,使得整个网络不够简洁,很容易导致过拟合,进而导致损失函数在训练集上下降而在验证集上反而上升的现象。

Dropout(丢弃)方法在每一轮的训练上选择性的(原则上是随机的)丢弃部分网络节点(如图所示),让它们关闭,即既不输出也不输入,相当于整个网络的结构发生了变化,每次训练其实相当于网络的一部分所形成的一个自网络或者子模型,这在一定程度上降低了VC维的数量,减小了过拟合的风险。在最终的分类阶段将所有节点都置于有效状态,这样就可以把训练中得到的所有子网络“并联”使用,形成一个由多个VC维较低的部分的分类模型所组成的完整的分类模型。一般可设置dropout-rate为0.6,即训练时随机丢弃40%的节点,在Caffe和Tensorflow框架中可以很方便的设置实现,现在的神经网络基本上都使用dropout-rate基本上所有图像识别的项目都出现了过拟合,都得采取措施。
参考https://blog.csdn.net/willduan1/article/details/53070777
参考高扬《白话深度学习与Tensorflow》