文章目录
linux常用指令
1、文件和目录
cd /home 进入 '/ home' 目录'
cd /root 就是 ~目录
root:超级用户(系统管理员)的主目录
home:存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就是/home/user
[root@jack ~]# cd /
[root@jack /]# ll
total 84
drwxr-xr-x 3 root root 4096 Dec 18 15:44 2020
drwxr-xr-x 3 root root 4096 Dec 11 16:20 ab
lrwxrwxrwx. 1 root root 7 Sep 14 15:14 bin -> usr/bin
dr-xr-xr-x. 5 root root 4096 Sep 14 15:28 boot
drwxr-xr-x 19 root root 2960 Dec 7 14:19 dev
drwxr-xr-x. 80 root root 4096 Dec 24 10:34 etc
drwxr-xr-x. 7 root root 4096 Dec 24 10:26 home
lrwxrwxrwx. 1 root root 7 Sep 14 15:14 lib -> usr/lib
lrwxrwxrwx. 1 root root 9 Sep 14 15:14 lib64 -> usr/lib64
drwx------. 2 root root 16384 Sep 14 15:14 lost+found
drwxr-xr-x. 2 root root 4096 Apr 11 2018 media
drwxr-xr-x. 2 root root 4096 Apr 11 2018 mnt
drwxr-xr-x 3 root root 4096 Dec 8 01:22 mydata
drwxr-xr-x. 3 root root 4096 Dec 6 10:45 opt
drwxr-xr-x 3 root root 4096 Dec 10 20:45 p1
drwxr-xr-x 2 root root 4096 Dec 11 16:11 pkjl
dr-xr-xr-x 84 root root 0 Dec 7 14:19 proc
dr-xr-x---. 10 root root 4096 Dec 25 09:33 root
drwxr-xr-x 25 root root 720 Dec 25 09:53 run
lrwxrwxrwx. 1 root root 8 Sep 14 15:14 sbin -> usr/sbin
drwxr-xr-x. 2 root root 4096 Apr 11 2018 srv
dr-xr-xr-x 13 root root 0 Dec 7 14:37 sys
drwxr-xr-x 2 root root 4096 Dec 7 17:05 test
drwxrwxrwt. 10 root root 4096 Dec 25 03:37 tmp
drwxr-xr-x. 13 root root 4096 Sep 14 15:14 usr
drwxr-xr-x. 19 root root 4096 Sep 14 07:20 var
cd /home
[root@jack /]# cd home
[root@jack home]# ll
total 9464
-rw-r--r-- 1 root root 9650976 Dec 7 16:21 apache-tomcat-7.0.107.tar.gz
drwxr-xr-x 2 root root 4096 Dec 6 18:04 ceshi
-rw-r--r-- 1 root root 589 Dec 7 17:20 dockerfile
-rw-r--r-- 1 root root 5307 Mar 21 2012 jdk-8u171-linux-x64.tar.gz
drwxr-xr-x 3 root root 4096 Dec 7 18:27 kuangshen
drwxr-xr-x 4 root root 4096 Dec 6 21:09 mysql
drwx------ 2 sam sam 4096 Dec 24 10:39 sam
drwx------ 2 test001 test001 4096 Dec 11 19:33 test001
-rw-r--r-- 1 root root 10 Dec 6 18:03 test.java
[root@jack /]# cd root
[root@jack ~]# ll
total 1143240
-rw-r--r-- 1 root root 17019 Dec 7 16:38 18IicPYf7W0j-sHBXvfKyyg
-rw-r--r-- 1 root root 9978 Dec 7 17:08 1IYlJFvVdZoDPoilFfsx6YQ
-rw-r--r-- 1 root root 9650976 Dec 7 15:30 apache-tomcat-7.0.107.tar.gz
drwxrwxr-x 14 test001 test001 4096 Apr 21 2020 apache-zookeeper-3.6.1
-rw-r--r-- 1 root root 3348479 Dec 10 11:18 apache-zookeeper-3.6.1.tar.gz
drwxr-xr-x 6 root root 4096 Dec 25 09:33 daily-pratice
-rw-r--r-- 1 root root 1157627904 Mar 5 2019 ubuntu-14.04.6-desktop-amd64.iso
touch 文件名字 t1 创建文件t1
cd .. 返回上一级目录
cd ../.. 返回上两级目录
cd 进入个人的主目录
cd ~user1 进入个人的主目录
cd - 返回上次所在的目录
pwd 显示工作路径
ls 查看目录中的文件
ls -a 显示隐藏文件
ls *[0-9]* 当前目录显示包含数字的文件名
tree 显示文件和目录由根目录开始的树形结构
tree 目录名
mkdir dir1 创建一个叫做 'dir1' 的目录'
mkdir dir1 dir2 同时创建两个目录
mkdir -p tmp/dir1/dir2 创建一个目录树
rm -f file1 删除一个叫做 'file1' 的文件'
rm -rf dir1 dir2 同时删除两个目录及它们的内容
-r -R remove directories and their contents recursively 递归
mv dir1 new_dir 重命名/移动 一个目录
cp file1 file2 复制一个文件
cp dir/* . 复制一个目录下的所有文件到当前工作目录
cp -a /tmp/dir1 . 复制一个目录到当前工作目录
cp -r dir1 dir2 复制一个目录及子目录
-r: recursive
cd命令cd、 cd ~、cd /、cd../、cd /home
cd # 返回主目录
root用户,cd ~ 相当于 cd /root
普通用户,cd ~ 相当于cd /home/当前用户名
[root@VM-4-16-centos ~]# pwd
/root
对于普通用户说明
[root@VM-4-16-centos ~]# su lighthouse
[lighthouse@VM-4-16-centos root]$ cd
[lighthouse@VM-4-16-centos ~]$ pwd
/home/lighthouse
cd / # 返回根目录 根目录是所有用户共享的目录
cd /home 相当于查看有多少普通用户的家目录
[root@VM-4-16-centos /]# cd home
[root@VM-4-16-centos home]# ll
total 16
drwxr-xr-x 2 root root 4096 May 9 03:04 ceshi
drwxr-xr-x 2 root root 4096 May 9 03:41 dockerfile
drwx------ 5 lighthouse lighthouse 4096 Apr 7 20:21 lighthouse
drwxr-xr-x 4 root root 4096 May 8 18:15 mysql
2、文件搜索(重点)
find指令
用不同的搜索标准如名字、类型、所属人、大小等来搜索目录树
find / -name file1 从 '/' 开始进入根文件系统搜索文件和目录
find / -user user1 搜索属于用户 'user1' 的文件和目录
find /home/user1 -name \*.bin 在目录 '/ home/user1' 中搜索带有'.bin' 结尾的文件
eg: find -name m1.md # 查询所有文件夹中m1.md
eg: find file001 -name a.md # 查询文件夹file001里面的文件
eg:[root@jack m1]# find -name \*.md # 查询当前目录搜索有.md结尾的文件
./file001/a.md
./a.md
./b.md
./file002/file001/a.md
./c.md
./test001.md
ll命令,ls命令
ll *text* # 查询包含text文件夹
ls *text* # 查询包含text文件夹
locate指令
yum install mlocate
locate是一种比find更快的方式,因为它在数据库中查找文件。要更新搜索数据库,运行下面的命令:
# updatedb
使用locate查找文件的语法:
# locate test.file
就像find命令一样,locate也有很多选项来过滤输出。要了解更多你可以查看Linux Locate命令的手册。
[root@jack m1]# updatedb
[root@jack m1]# locate b.md
/root/daily-pratice/20201223test/m1/b.md
/root/daily-pratice/20201225test/m1/b.md
而是在一个数据库(/var/lib/locatedb)中搜索指定的文件。次数据库含有本地文件的所有信息,此数据库是linux系统自动创建的,数据库由updatedb程序来更新,updatedb是由cron daemon周期性建立的,默认情况下为每天更新一次,所以用locate命令你搜索不到最新更新的文件,除非你在用locate命令查找文件之前手动的用updatedb命令更新数据库。
3、打包和压缩文件
tar:可以把一大堆文件和目录全部打包一个文件,对于备份文件或者将几个文件组合成一个文件便于网络传输
两个概念:
打包:将一大堆文件目录变成一个总的文件 tar
压缩:将一个的文件通过一些压缩算法变成一个文件 gzip,bzip2
tar
解包:tar zxvf filename.tar
打包:tar czvf filename.tar dirname
eg:tar czvf m1.tar m1 # 打包一个文件
gz命令
解压1:gunzip filename.gz
解压2:gzip -d filename.gz
压缩:gzip filename
.tar.gz 和 .tgz
解压:tar zxvf filename.tar.gz
压缩:tar zcvf filename.tar.gz dirname
压缩多个文件:tar zcvf filename.tar.gz dirname1 dirname2 dirname3.....
eg: tar -zxvf apache-zookeeper-3.6.1.tar.gz # 解压一个zookeeper的压缩文件
eg:tar zcvf m1.tar.gz m1
打包:tar zcvf ab.tar.gz a.md b.md
解压:tar zxvf ab.tar.gz
bz2命令
解压1:bzip2 -d filename.bz2
解压2:bunzip2 filename.bz2
压缩:bzip2 -z filename
-d --decompress
# 强制解压缩。 bzip2, bunzip2 以及 bzcat 实际上是同一个程序,进行何种操作将根据程序名确定。 指定该选项后将不考虑这一机制,强制 bzip2 进行解压缩。
-z --compress
# -d 选项的补充:强制进行压缩操作,而不管执行的是哪个程序。
压缩:bzip2 -z b.md
解压:bzip2 -d b.md.bz2
# z:gzip压缩
# z:解压
# v:显示解压压缩过程
# f:接着压缩
# c:创建压缩包
# -C:解压到指定目录
zip命令
解压:unzip filename.zip
压缩:zip -r -q filename.zip dirname

4、查看文件内容
head命令
说明:显示文件的开头部分。
基本语法:head [OPTION]… [FILE]…
基本用途:
- 在未指定行数时默认显示前10行
- 处理多个文件时会在各个文件之前附加含有文件名的行
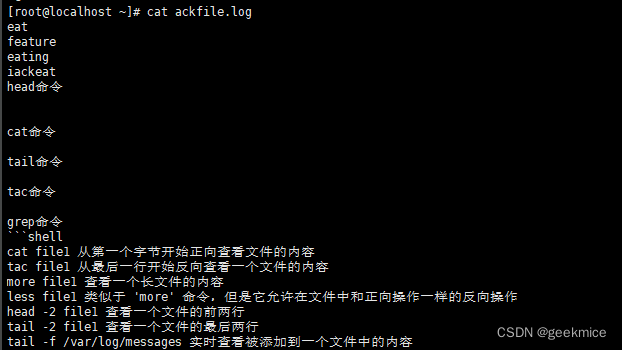
head ackfile.log # 不指定行数查看ackfile.log文件前十行
head -n 3 ackfile.log # 指定行数查看ackfile.log前三行
head -n +3 ackfile.log # 指定行数查看ackfile.log前三行
head -n -3 ackfile.log # 指定行数查看ackfile.log后三行的之外数据
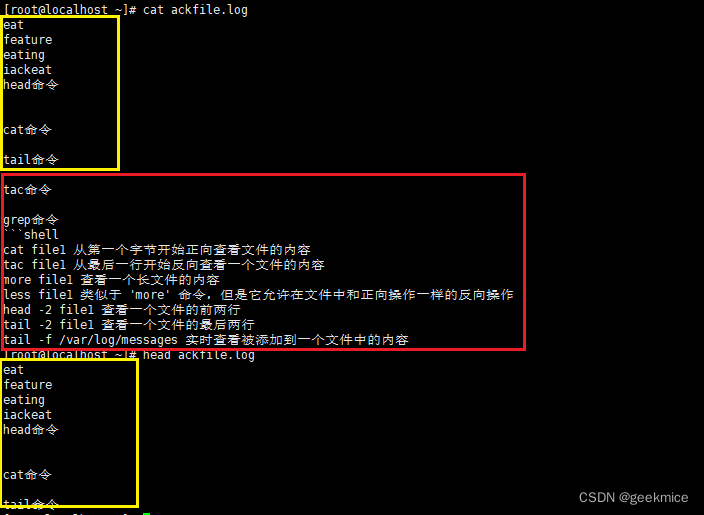
cat命令
说明:连接多个文件并打印到标准输出。
语法:cat [OPTION]… [FILE]…
主要用途:
- 多个文件的内容进行连接并打印到标准输出
cat -n ackfile.log
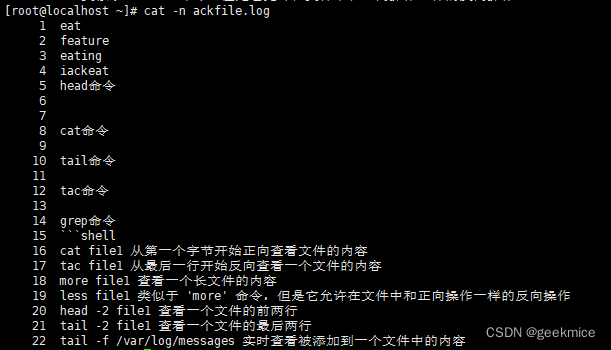
注意
- 建议您查看体积较大的文件时使用less、more命令或emacs、vi等文本编辑器
从第3000行开始,显示1000行。即显示3000~3999行
cat filename | tail -n +3000 | head -n 1000
显示1000行到3000行
cat filename| head -n 3000 | tail -n +1000
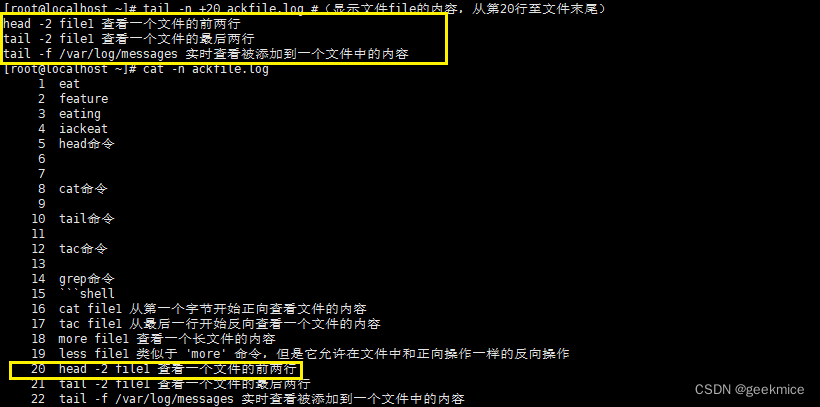
tail命令
说明:在屏幕上显示指定文件的末尾若干行
语法:tail (选项) (参数)
用途:
- 日志动态查询处理
tail file #(显示文件file的最后10行)
tail -n +20 ackfile.log #(显示文件file的内容,从第20行至文件末尾)
tail -25 ackfile.log # 显示 mail.log 最后的 25 行
tail -f mail.log # 等同于--follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止
tail -F mail.log # 等同于--follow=name --retry,根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪
grep命令
说明:grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤/搜索的特定字符。可使用正则表达式能配合多种命令使用,使用上十分灵活。
基本用法:
grep content file
注意
-i 不区分大小写
-v 反向抓取
-A after
-B before
-n 显示行号
-E 正则表达式
在管道使用场景,grep使用频率高
ls显示内容grep命令抓取带1的数据
1、grep “字符串”
cat -n ackfile.log | grep eat # 查看ackfile.log文件中eat行,模糊查询
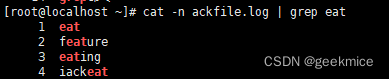
cat -n ackfile.log | grep -w eat # 查看ackfile.log文件中eat行,模糊查询
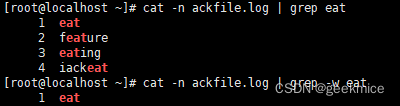
2、反向匹配
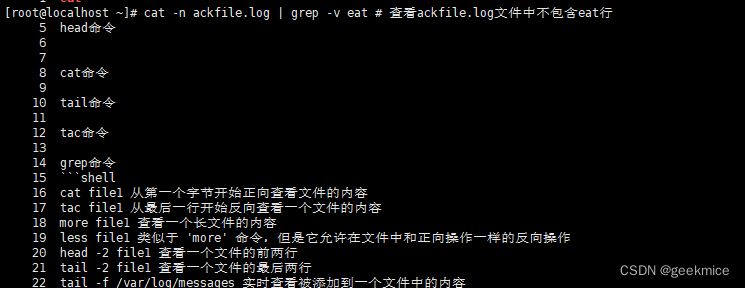
cat -n ackfile.log | grep -v eat # 查看ackfile.log文件中不包含eat行
3、grep -E 同时匹配多个关键字–或关系
grep -E 是使用扩展正则表达式
也就是egrep命令
# 查看ackfile.log文件中包含eat或者grep或者color行,显示出来
[root@localhost ~]# cat -n ackfile.log |grep -E 'eat|grep|color'
1 eat
2 feature
3 eating
4 iackeat
14 grep命令
4、同时匹配多个关键字–与关系
# 使用管道符连接多个 grep ,间接实现多个关键字的与关系匹配
[root@localhost ~]# cat -n ackfile.log | grep eat | grep eating | grep eatinged
6 eatinged

5、通配符
| 符号 | 注明 |
|---|---|
| ^ | 表示以什么开头 |
| $ | 表示以什么结尾 |
| * | 0到多次 |
| + | 1到多次 |
| {n} | 匹配n次 |
sed命令
它是文本处理中非常重要的工具,能够完美的配合正则表达式使用,功能不同凡响
查找功能
查看passwd文件的第5到第8行内容
sed -n '5,8 p' ackfile.log
查看passwd文件中以roo开头的行
sed -n '/^roo/ p' ackfile.log
忽略大小写,对含有root字符的行打印出来
sed -n '/root/I p' ackfile.log
查找passwd文件中有eat字符串的行
sed -n '\%/bin/bash% p' ackfile.log
5、文本处理 (重点)
cat file1 | command( sed, grep, awk, grep, etc...) > result.txt
合并一个文件的详细说明文本,并将简介写入一个新文件中
eg:
[root@jack m1]# cat test001.md | grep 1 > result.txt # 查询test001.md文件中含有1关键字的内容添加到新文件result.txt
[root@jack m1]# ll
total 52
-rw-r--r-- 1 root root 100 Dec 25 09:33 a.md
-rw-r--r-- 1 root root 0 Dec 25 09:33 b.md
-rw-r--r-- 1 root root 30 Dec 25 09:33 c.md
drwxr-xr-x 2 root root 4096 Dec 25 09:42 file001
drwxr-xr-x 3 root root 4096 Dec 25 09:43 file002
-rw-r--r-- 1 root root 0 Dec 25 09:33 filename.out
-rw-r--r-- 1 root root 15 Dec 25 09:33 m1
-rw-r--r-- 1 root root 15 Dec 25 09:33 m11
-rw-r--r-- 1 root root 124 Dec 25 09:33 m1.tar
-rw-r--r-- 1 root root 124 Dec 25 09:33 m1.tar.gz
-rw-r--r-- 1 root root 14 Dec 25 09:33 m2
-rw-r--r-- 1 root root 15 Dec 25 09:33 m3
drwxr-xr-x 2 root root 4096 Dec 25 09:33 m33
-rw-r--r-- 1 root root 17 Jan 12 13:23 result.txt
-rw-r--r-- 1 root root 27 Jan 12 13:22 test001.md
[root@jack m1]# cat result.txt
11
21
31
51
41
1
cat file1 | command( sed, grep, awk, grep, etc...) >> result.txt 合并一个文件的详细说明文本,并将简介写入一个已有的文件中
eg:
[root@jack m1]# cat a.md | grep 一 >> result.txt # 查看文件a.md并且找到一关键字内容合并到已经有的文件result.txt
[root@jack m1]# cat result.txt
11
21
31
51
41
1
第一行
grep Aug /var/log/messages 在文件 '/var/log/messages'中查找关键词"Aug"
[root@jack m1]# grep 第一行 /root/daily-pratice/20201225test/m1/a.md # 强调在文件中搜索"第一行"关键字
第一行
grep Aug -R /var/log/* 在目录 '/var/log' 及随后的目录中搜索字符串"Aug"
[root@jack m1]# grep 第一行 -R /root
/root/daily-pratice/20201225test/m1/file001/a.md:第一行
/root/daily-pratice/20201225test/m1/a.md:第一行
/root/daily-pratice/20201225test/m1/result.txt:第一行
/root/daily-pratice/20201225test/m1/result.txt:a.md:第一行
/root/daily-pratice/20201225test/m1/file002/file001/a.md:第一行
/root/daily-pratice/20201225test/m1/c.md:第一行
/root/daily-pratice/20201223test/m1/a.md:第一行
/root/daily-pratice/20201223test/m1/c.md:第一行
/root/daily-pratice/20201222test/m1/a.md:1、第一行
grep ^Aug /var/log/messages 在文件 '/var/log/messages'中查找以"Aug"开始的词汇
[root@jack m1]# grep -n ^1 test001.md
1:11
9:11
10:12
grep [0-9] /var/log/messages 选择 '/var/log/messages' 文件中所有包含数字的行
[root@jack m1]# grep -n [1] test001.md
1:11
2:21
3:31
5:51
8:41
9:1
sed 's/stringa1/stringa2/g' example.txt 将example.txt文件中的 "string1" 替换成 "string2"
sed '/^$/d' example.txt 从example.txt文件中删除所有空白行
sed '/ *#/d; /^$/d' example.txt 从example.txt文件中删除所有注释和空白行
echo 'esempio' | tr '[:lower:]' '[:upper:]' 合并上下单元格内容
sed -e '1d' result.txt 从文件example.txt 中排除第一行
sed -n '/stringa1/p' 查看只包含词汇 "string1"的行
sed -e 's/ *$//' example.txt 删除每一行最后的空白字符
sed -e 's/stringa1//g' example.txt 从文档中只删除词汇 "string1" 并保留剩余全部
sed -n '1,5p;5q' example.txt 查看从第一行到第5行内容
sed -n '5p;5q' example.txt 查看第5行
sed -e 's/00*/0/g' example.txt 用单个零替换多个零
cat -n file1 标示文件的行数
[root@jack m1]# cat -n a.md
1 第一行
2 第二行
3 第三行
4 第四行
5 第五行
6 第六行
7 第七行
8 第八行
9 第九行
10 第十行
cat example.txt | awk 'NR%2==1' 显示删除example.txt文件中的所有偶数行,但是源文件不变
[root@jack m1]# cat a.md | awk 'NR%2==1'
第一行
第三行
第五行
第七行
第九行
[root@jack m1]# cat a.md
第一行
第二行
第三行
第四行
第五行
第六行
第七行
第八行
第九行
第十行
echo a b c | awk '{print $1}' 查看一行第一栏
echo a b c | awk '{print $1,$3}' 查看一行的第一和第三栏
paste file1 file2 合并两个文件或两栏的内容
paste -d '+' file1 file2 合并两个文件或两栏的内容,中间用"+"区分
sort file1 file2 排序两个文件的内容
sort file1 file2 | uniq 取出两个文件的并集(重复的行只保留一份)
sort file1 file2 | uniq -u 删除交集,留下其他的行
sort file1 file2 | uniq -d 取出两个文件的交集(只留下同时存在于两个文件中的文件)
comm -1 file1 file2 比较两个文件的内容只删除 'file1' 所包含的内容
comm -2 file1 file2 比较两个文件的内容只删除 'file2' 所包含的内容
comm -3 file1 file2 比较两个文件的内容只删除两个文件共有的部分
6、用户和用户组管理
用户账号的添加、删除与修改。
用户口令的管理。
用户组的管理。
一、Linux系统用户账号的管理
用户账号的管理工作主要涉及到用户账号的添加、修改和删除。
添加用户账号就是在系统中创建一个新账号,然后为新账号分配用户号、用户组、主目录和登录Shell等资源。刚添加的账号是被锁定的,无法使用。
1、添加新的用户账号使用useradd命令
useradd 选项 用户名
选项:
-c comment 指定一段注释性描述。
-d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录。
-g 用户组 指定用户所属的用户组。
-G 用户组,用户组 指定用户所属的附加组。
-s Shell文件 指定用户的登录Shell。
-u 用户号 指定用户的用户号,如果同时有-o选项,则可以重复使用其他用户的标识号。
eg1:
[root@jack ~]# useradd -d /home/sam -m sam
[root@jack home]# cd sam
[root@jack sam]# ll
total 0
2、删除帐号
语法:userdel 选项 用户名
常用的选项是 -r,它的作用是把用户的主目录一起删除。
例如:
# userdel -r sam
此命令删除用户sam在系统文件中(主要是/etc/passwd, /etc/shadow, /etc/group等)的记录,同时删除用户的主目录。
3、修改帐号
修改用户账号就是根据实际情况更改用户的有关属性,如用户号、主目录、用户组、登录Shell等。
修改已有用户的信息使用usermod命令,其格式如下:
usermod 选项 用户名
例如:
# usermod -s /bin/ksh -d /home/z –g developer sam
此命令将用户sam的登录Shell修改为ksh,主目录改为/home/z,用户组改为developer。
4、用户口令的管理
passwd 选项 用户名
# passwd sam
5、查询用户信息
cat /etc/passwd 查看bai所有的用户du信息
[root@jack /]# cat etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
6、输入"cat /etc/passwd | grep 用户名 ",用于查找某个用户
[root@jack /]# cat /etc/passwd | grep test001
test001:x:1000:1000::/home/test001:/bin/bash
二、Linux系统用户组的管理
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
1、增加一个新的用户组使用groupadd命令。其格式如下:
groupadd 选项 用户组
可以使用的选项有:
-g GID 指定新用户组的组标识号(GID)。
-o 一般与-g选项同时使用,表示新用户组的GID可以与系统已有用户组的GID相同。
实例1:
# groupadd group1
此命令向系统中增加了一个新组group1,新组的组标识号是在当前已有的最大组标识号的基础上加1。
实例2:
# groupadd -g 101 group2
此命令向系统中增加了一个新组group2,同时指定新组的组标识号是101。
2、如果要删除一个已有的用户组,使用groupdel命令,其格式如下:
groupdel 用户组
例如:
# groupdel group1
此命令从系统中删除组group1。
3、修改用户组的属性使用groupmod命令。其语法如下:
groupmod 选项 用户组
常用的选项有:
-g GID 为用户组指定新的组标识号。
-o 与-g选项同时使用,用户组的新GID可以与系统已有用户组的GID相同。
-n新用户组 将用户组的名字改为新名字
实例1:
# groupmod -g 102 group2
此命令将组group2的组标识号修改为102。
实例2:
# groupmod –g 10000 -n group3 group2
此命令将组group2的标识号改为10000,组名修改为group3。
7、日志操作(重点)
tail、head、 cat、tac、sed、less、echo、grep
1、命令格式: tail [必要参数] [选择参数] [文件]
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示行数
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
tail -n 3 catalina.out 查询日志尾部最后3行的日志
[root@jack m1]# tail -n 3 a.md
3、第三行
4、第四行
5、第五行
tail -n +100 catalina.out 查询100行之后的所有日志;
tail -fn 100 catalina.out 循环实时查看最后100行记录(最常用的)
配合着grep用, 例如 : tail -fn 100 catalina.out | grep -- '关键字'
[root@jack m1]# tail -n 5 a.md | grep -- '行'
3、第三行
4、第四行
5、第五行
6、第六行
7、第七行
如果一次性查询的数据量太大,可以进行翻页查看,
例如:tail -n 6000 catalina.out |more -100 可以进行多屏显示(ctrl + f 或者 空格键可以快捷键)
[root@jack m1]# tail -n 10 a.md | more -3
1、第一行
2、第二行
3、第三行
--More--空格之后
1、第一行
2、第二行
3、第三行
4、第四行
5、第五行
6、第六行
--More--
1、第一行
2、第二行
3、第三行
4、第四行
5、第五行
6、第六行
7、第七行
8、第八行
9、第九行
--------------------------------------------------------------------------------------------------------------------------
2、head
head -n 1000 catalina.out //查询日志文件中的头10行日志;
head -n -1000 catalina.out //查询日志文件除了最后10行的其他所有日志;
head其他参数与tail 类似
[root@jack m1]# head -n 3 a.mdcat
1、第一行
2、第二行
3、第三行
[root@jack m1]# head -n -4 a.md
1、第一行
2、第二行
3、第三行
4、第四行
5、第五行
6、第六行
-----------------------------------------------------------------------------------------------------
3、cat
cat 是由第一行到最后一行连续显示在屏幕上
[root@jack m1]# cat a.md
1、第一行
2、第二行
3、第三行
4、第四行
5、第五行
6、第六行
7、第七行
8、第八行
9、第九行
10、第十行
[root@jack m1]# cat b.md
第一行
第二行
第三行
$ cat filename // 一次显示整个文件
$ cat > filename //从键盘创建一个文件
$cat file1 file2 > file //将几个文件合并为一个文件,只能创建新文件,不能编辑已有文件.
[root@jack m1]# cat a.md b.md > c.md
1、第一行
2、第二行
3、第三行
4、第四行
5、第五行
6、第六行
7、第七行
8、第八行
9、第九行
10、第十行
第一行
第二行
第三行
$cat -n textfile1 >> textfile2 //将一个日志文件的内容追加到另外一个(添加序号)
$echo > a.md // 清空一个日志文件
truncate -s 0 a.md // 清空一个日志文件
注意: >意思是创建, >>是追加。
cat其他参数与tail 类似
cat /dev/null > application.log
----------------------------------------------------------------------------------------------------------------------------------------
4.tac
tac 则是由最后一行到第一行反向在萤幕上显示出来
--------------------------------------------------------------------------------------------------------------------------------------
5.sed
这个命令可以查找日志文件特定的一段 , 也可以根据时间的一个范围查询
sed命令的选项(option):
-n :只打印模式匹配的行
-e :直接在命令行模式上进行sed动作编辑,此为默认选项
-f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作
-r :支持扩展表达式
-i :直接修改文件内容
sed在文件中查询文本的方式:
1)使用行号,可以是一个简单数字,或是一个行号范围
x --- x为行号
x,y --- 表示行号从x到y
/pattern --- 查询包含模式的行
/pattern /pattern --- 查询包含两个模式的行
pattern/,x --- 在给定行号上查询包含模式的行
x,/pattern/ --- 通过行号和模式查询匹配的行
x,y! --- 查询不包含指定行号x和y的行
例题说明:
[root@jack m1]# sed -n '1,4p' a.md # 查询a.md文件第一行到第四行数据 -n 表示只打印匹配的行
第一行
第二行
第三行
第四行
[root@jack m1]# sed -n '/十/p' a.md # 表示打印文件中匹配的十字符的行
第十行
[root@jack m1]# sed -n '/九/,10p' a.md
# 打印文件中从匹配九的行到第十行,九所处的行如果在第10行之后,则表示仅打印匹配九的行
第九行
第十行
[root@jack m1]# sed -n '/九/,8p' a.md
# 打印文件中从匹配九的行到第十行,九所处的行如果在第10行之后,则表示仅打印匹配九的行
第九行
[root@jack m1]# sed -n '2,/五/p' a.md
# 打印狄航开始匹配到第一次出现五字符的行,五字符的行
第二行
第三行
第四行
第五行
[root@jack m1]# sed -n '/八/,/九/p' a.md
# 打印匹配八字符行数据,打印九匹配字符数据
第八行
第九行
-------------------------------------------------------------------------------------------------
附录1
history // 所有的历史记录
history | grep XXX // 历史记录中包含某些指令的记录
history | more // 分页查看记录 空格
history -c // 清空所有的历史记录
!! 重复执行上一个命令
查询出来记录后选中 : !323
-------------------------------------------------------------------------------------------------------------
7、echo
输出 echo "12345"
-------------------------------------------------------------------------------------------
8、按照日期来查询
按照日期时间段查询,查询2022-07-25 十点到十一点的数据
grep '2022-07-25 1[0-1]' application.log
按照分钟时间段查询,查询2022-07-25 11:30->11:39数据
grep '2022-07-25 11:3[0-9]'
若是日志过多,可以采用more分页查询
grep '2022-07-25 11:3[0-9]' | more a # a 每页条数
8、线程操作(重点)
1、ps 命令用于查看当前正在运行的进程。
grep 是搜索
例如: ps -ef | grep java
表示查看所有进程里 CMD 是 java 的进程信息
2、ps -aux | grep java
-aux 显示所有状态
USER:该进程是由哪个用户产生的
PID:进程的ID号
%CPU:该进程占用CPU资源的百分比,占用越高,进程越耗费资源;
%MEM:该进程占用物理内存的百分比,占用越高,进程越耗费资源;
VSZ:该进程占用虚拟内存的大小,单位KB;
RSS:该进程占用实际物理内存的大小,单位KB;
TTY:该进程是在哪个终端中运行的。其中tty1-tty7代表本地控制台终端,tty1-tty6是本地的字符界面终端,tty7是图形终端。pts/0-255代表虚拟终端。
STAT:进程状态。常见的状态有:R:运行、S:睡眠、T:停止状态、s:包含子进程、+:位于后台
START:该进程的启动时间
TIME:该进程占用CPU的运算时间,注意不是系统时间
COMMAND:产生此进程的命令名
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 51924 3908 ? Ss Apr07 20:37 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0.0 0.0 0 0 ? S Apr07 0:01 [kthreadd]
root 4 0.0 0.0 0 0 ? S< Apr07 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? S Apr07 2:44 [ksoftirqd/0]
root 7 0.0 0.0 0 0 ? S Apr07 0:00 [migration/0]
root 8 0.0 0.0 0 0 ? S Apr07 0:00 [rcu_bh]
root 9 0.0 0.0 0 0 ? R Apr07 9:57 [rcu_sched]
root 10 0.0 0.0 0 0 ? S< Apr07 0:00 [lru-add-drain]
root 11 0.0 0.0 0 0 ? S Apr07 0:27 [watchdog/0]
root 13 0.0 0.0 0 0 ? S Apr07 0:00 [kdevtmpfs]
root 14 0.0 0.0 0 0 ? S< Apr07 0:00 [netns]
root 15 0.0 0.0 0 0 ? S Apr07 0:02 [khungtaskd]
root 16 0.0 0.0 0 0 ? S< Apr07 0:00 [writeback]
root 17 0.0 0.0 0 0 ? S< Apr07 0:00 [kintegrityd]
root 18 0.0 0.0 0 0 ? S< Apr07 0:00 [bioset]
root 19 0.0 0.0 0 0 ? S< Apr07 0:00 [bioset]
root 20 0.0 0.0 0 0 ? S< Apr07 0:00 [bioset]
root 21 0.0 0.0 0 0 ? S< Apr07 0:00 [kblockd]
root 22 0.0 0.0 0 0 ? S< Apr07 0:00 [md]
root 23 0.0 0.0 0 0 ? S< Apr07 0:00 [edac-poller]
root 24 0.0 0.0 0 0 ? S< Apr07 0:00 [watchdogd]
root 30 0.0 0.0 0 0 ? S Apr07 0:05 [kswapd0]
root 31 0.0 0.0 0 0 ? SN Apr07 0:00 [ksmd]
root 32 0.0 0.0 0 0 ? SN Apr07 0:07 [khugepaged]
root 33 0.0 0.0 0 0 ? S< Apr07 0:00 [crypto]
root 41 0.0 0.0 0 0 ? S< Apr07 0:00 [kthrotld]
root 43 0.0 0.0 0 0 ? S< Apr07 0:00 [kmpath_rdacd]
root 44 0.0 0.0 0 0 ? S< Apr07 0:00 [kaluad]
root 45 0.0 0.0 0 0 ? S< Apr07 0:00 [kpsmoused]
root 46 0.0 0.0 0 0 ? S< Apr07 0:00 [ipv6_addrconf]
root 59 0.0 0.0 0 0 ? S< Apr07 0:00 [deferwq]
root 108 0.0 0.0 0 0 ? S Apr07 0:11 [kauditd]
root 193 0.0 0.0 0 0 ? S< Apr07 0:00 [iscsi_eh]
root 244 0.0 0.0 0 0 ? S< Apr07 0:00 [ata_sff]
root 253 0.0 0.0 0 0 ? S Apr07 0:00 [scsi_eh_0]
root 254 0.0 0.0 0 0 ? S< Apr07 0:00 [scsi_tmf_0]
root 255 0.0 0.0 0 0 ? S Apr07 0:00 [scsi_eh_1]
root 256 0.0 0.0 0 0 ? S< Apr07 0:00 [scsi_tmf_1]
root 259 0.0 0.0 0 0 ? S< Apr07 0:00 [ttm_swap]
root 260 0.0 0.0 0 0 ? S< Apr07 0:51 [kworker/0:1H]
root 279 0.0 0.0 0 0 ? S Apr07 2:05 [jbd2/vda1-8]
root 280 0.0 0.0 0 0 ? S< Apr07 0:00 [ext4-rsv-conver]
root 374 0.0 1.4 71872 27824 ? Ss Apr07 5:05 /usr/lib/systemd/systemd-journald
root 389 0.0 0.0 116644 1088 ? Ss Apr07 0:00 /usr/sbin/lvmetad -f
root 398 0.0 0.0 45476 1792 ? Ss Apr07 0:00 /usr/lib/systemd/systemd-udevd
root 527 0.0 0.0 55532 1032 ? S<sl Apr07 1:13 /sbin/auditd
root 549 0.0 0.1 26808 2132 ? Ss Apr07 3:30 /usr/lib/systemd/systemd-logind
dbus 550 0.0 0.1 60304 2340 ? Ss Apr07 7:56 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
libstor+ 555 0.0 0.0 8580 796 ? Ss Apr07 0:12 /usr/bin/lsmd -d
polkitd 557 0.0 0.4 614444 8548 ? Ssl Apr07 2:31 /usr/lib/polkit-1/polkitd --no-debug
root 559 0.0 0.0 4388 516 ? Ss Apr07 0:00 /usr/sbin/acpid
ntp 561 0.0 0.1 49380 2348 ? Ss Apr07 0:09 /usr/sbin/ntpd -u ntp:ntp -g
root 827 0.0 0.1 102984 2176 ? Ss Apr07 0:00 /sbin/dhclient -q -lf /var/lib/dhclient/dhclient--eth0.lease -pf /var/run/dhclient-eth0.pid -H VM-4-16-cen
root 891 0.0 0.7 574284 14184 ? Ssl Apr07 10:57 /usr/bin/python2 -Es /usr/sbin/tuned -l -P
root 892 0.0 0.5 61488 10136 ? S<Ls Apr07 0:00 /sbin/iscsid -f
root 897 0.0 0.0 0 0 ? S 14:25 0:00 [kworker/0:1]
root 1132 0.0 0.1 91872 2044 ? Ss Apr07 0:13 /usr/libexec/postfix/master -w
postfix 1137 0.0 0.1 92044 2612 ? S Apr07 0:02 qmgr -l -t unix -u
root 1144 0.0 0.9 709656 18256 ? Ssl Apr07 6:26 /usr/sbin/rsyslogd -n
root 1150 0.0 0.0 126420 1612 ? Ss Apr07 0:47 /usr/sbin/crond -n
root 1151 0.0 0.0 25908 884 ? Ss Apr07 0:00 /usr/sbin/atd -f
root 1289 0.0 0.0 110208 820 tty1 Ss+ Apr07 0:00 /sbin/agetty --noclear tty1 linux
root 1290 0.0 0.0 110208 824 ttyS0 Ss+ Apr07 0:00 /sbin/agetty --keep-baud 115200,38400,9600 ttyS0 vt220
ps -ef
UID:用户ID
PID:进程ID
PPID:父进程ID
C:CPU用于计算执行优先级的因子。数值越大,表明进程是CPU密集型运算,执行优先级会降低;数值越小,表明进程是I/O密集型运算,执行优先级会提高
STIME:进程启动的时间
TTY:完整的终端名称
TIME:CPU时间
CMD:启动进程所用的命令和参数
如果想查看进程的CPU占用率和内存占用率,可以使用aux;
如果想查看进程的父进程ID可以使用ef;
3. kill 命令用于终止进程
例如: kill -9 [PID]
-9 表示强迫进程立即停止
通常用 ps 查看进程 PID ,用 kill 命令终止进程
4、使用top -H命令可以查看所有线程。
9、磁盘管理
linux中df命令的功能是用来检查linux服务器的文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
磁盘信息:df、du
df: disk free 空余硬盘
du: disk usage 磁盘用法
df命令
–功能:检查文件系统的磁盘空间占用情况
–语法:df [选项]
–选项:
-a 显示所有文件系统的磁盘使用情况,包括0块(block)的文件系统,如/proc文件系统。
-k 以k字节为单位显示。
-h 以可读性较好的方式显示。
-T 显示文件系统类型。
范例:
df -h -- 以可读性较好的方式显示。 查看当前目录磁盘使用情况:
查看指定目录磁盘使用情况:
df -h /data
[root@jack ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 909M 0 909M 0% /dev
tmpfs 919M 0 919M 0% /dev/shm
tmpfs 919M 476K 919M 1% /run
tmpfs 919M 0 919M 0% /sys/fs/cgroup
/dev/vda1 40G 17G 22G 44% /
tmpfs 184M 0 184M 0% /run/user/0
df -a 效果如下:
Filesystem 1K-blocks Used Available Use% Mounted on
sysfs 0 0 0 - /sys
proc 0 0 0 - /proc
devtmpfs 930632 0 930632 0% /dev
securityfs 0 0 0 - /sys/kernel/security
tmpfs 940976 0 940976 0% /dev/shm
devpts 0 0 0 - /dev/pts
tmpfs 940976 476 940500 1% /run
tmpfs 940976 0 940976 0% /sys/fs/cgroup
cgroup 0 0 0 - /sys/fs/cgroup/systemd
pstore 0 0 0 - /sys/fs/pstore
cgroup 0 0 0 - /sys/fs/cgroup/devices
cgroup 0 0 0 - /sys/fs/cgroup/perf_event
cgroup 0 0 0 - /sys/fs/cgroup/cpu,cpuacct
cgroup 0 0 0 - /sys/fs/cgroup/hugetlb
cgroup 0 0 0 - /sys/fs/cgroup/pids
cgroup 0 0 0 - /sys/fs/cgroup/net_cls,net_prio
cgroup 0 0 0 - /sys/fs/cgroup/blkio
cgroup 0 0 0 - /sys/fs/cgroup/memory
cgroup 0 0 0 - /sys/fs/cgroup/freezer
cgroup 0 0 0 - /sys/fs/cgroup/cpuset
configfs 0 0 0 - /sys/kernel/config
/dev/vda1 41152812 16907948 22341156 44% /
systemd-1 - - - - /proc/sys/fs/binfmt_misc
hugetlbfs 0 0 0 - /dev/hugepages
debugfs 0 0 0 - /sys/kernel/debug
mqueue 0 0 0 - /dev/mqueue
binfmt_misc 0 0 0 - /proc/sys/fs/binfmt_misc
tmpfs 188196 0 188196 0% /run/user/0
[root@jack ~]# df -k --以k字节显示单位
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 930632 0 930632 0% /dev
tmpfs 940976 0 940976 0% /dev/shm
tmpfs 940976 476 940500 1% /run
tmpfs 940976 0 940976 0% /sys/fs/cgroup
/dev/vda1 41152812 16907952 22341152 44% /
tmpfs 188196 0 188196 0% /run/user/0
[root@jack ~]# df -T
Filesystem Type 1K-blocks Used Available Use% Mounted on
devtmpfs devtmpfs 930632 0 930632 0% /dev
tmpfs tmpfs 940976 0 940976 0% /dev/shm
tmpfs tmpfs 940976 476 940500 1% /run
tmpfs tmpfs 940976 0 940976 0% /sys/fs/cgroup
/dev/vda1 ext4 41152812 16907952 22341152 44% /
tmpfs tmpfs 188196 0 188196 0% /run/user/0
du:
du (disk usage)命令
–功能:统计目录(或文件)所占磁盘空间的大小
–说明:该命令逐级进入指定目录的每一个子目录并显示该目录占用文件系统数据块(1024字节)的情况。若没有给出Names,则对当前目录进行统计。
–选项:
-s 对每个Names参数只给出占用的数据块总数
-a 递归地显示指定目录中各文件及子孙目录中各文件占用的数据块数。若既不指定-s,也不指定-a,则只显示Names中的每一个目录及其中的各子目录所占的磁盘块数。
-b 以字节为单位列出磁盘空间使用情况(系统缺省以k字节为单位)。
-k 以1024字节为单位列出磁盘空间使用情况。
-c 最后再加上一个总计(系统缺省设置)。
-l 计算所有的文件大小,对硬链接文件,则计算多次
# 查看指定目录/root/*所有文件大小
[root@jack ~]# du -h -s /root/* | sort
1.1G /root/ubuntu-14.04.6-desktop-amd64.iso
12G /root/项目组前期准备.zip
12K /root/1IYlJFvVdZoDPoilFfsx6YQ
20K /root/18IicPYf7W0j-sHBXvfKyyg
22M /root/apache-zookeeper-3.6.1
240K /root/daily-pratice
3.2M /root/apache-zookeeper-3.6.1.tar.gz
9.3M /root/apache-tomcat-7.0.107.tar.gz
查看目录的大小 du -sh dirname -s 仅显示总计 -h 以k、m、g为单位,提高信息的可读性。kb、mb、gb是以1024为换算单 位, -h以1000为换算单位
[root@jack /]# du -sh etc
38M etc
df与du区别
df命令用来查看磁盘的使用情况。常用df -ah 或者 df -h;可以查看一级文件夹大小、使用比例、档案系统及其挂入点,但对文件却无能为力
du可以查看文件及文件夹的大小,统计文件大小相加。du命令用来查询档案或目录的磁盘使用空间,常用:du -sh 目录 或者 du -h 目录
df 统计数据块使用情况
如果有一个进程在打开一个大文件的时候,这个大文件直接被rm 或者mv掉,则du会更新统计数值,df不会更新统计数值,还是认为空间没有释放。直到这个打开大文件的进程被Kill掉。
如此一来在定期删除 /var/spool/clientmqueue下面的文件时,如果没有杀掉其进程,那么空间一直没有释放。
使用下面的命令杀掉进程之后,系统恢复。
两者配合使用,非常有效。比如用df查看哪个一级目录过大,然后用du查看文件夹或文件的大小,如此便可迅速确定症结。
https://www.cnblogs.com/qmfsun/p/3800072.html
常见问题
grep命令显示高亮
grep命令后面加上 --aolor=auto
去重命令uniq
uniq是对文本文件进行行去去重的工具。
以行为单位,进行行与行之间的字符串比较并进行去重
只能对有序的文本行进行有效去重,所以常与sort命令结合使用
| 参数 | 解释说明 |
|---|---|
| -c | 统计行出现的次数 |
| -d | 只显示重复的行并且去重 |
| -u | 只显示唯一的行 |
| -i | 忽略字母大小写 |
| -f | 忽略前N个字段(字段间用空白字符分隔) |
1、与sort结合使用
cat hello.sh
---
hello this is linux
be better
be better
i am lhj
hello this is linux
i am lhj
i am lhj
be better
i am lhj
have a nice day
have a nice day
hello this is linux
hello this is linux
have a nice day
zzzzzzzzzzzzzz
dddddddd
gggggggggggggggggggg
---
# 单独使用uniq命令
uniq hello.sh
---
hello this is linux
be better
i am lhj
hello this is linux
i am lhj
be better
i am lhj
have a nice day
hello this is linux
have a nice day
zzzzzzzzzzzzzz
dddddddd
gggggggggggggggggggg
---
# 说明:可以看出单独使用uniq命令时只对相邻重复行进行去重,无法进行有效去重
# 与sort结合使用
cat hello.sh | sort | uniq
---
be better
dddddddd
gggggggggggggggggggg
have a nice day
hello this is linux
i am lhj
zzzzzzzzzzzzzz
---
# 先排序使重复的行相邻,然后使用uniq可以有效去重
# uniq支持管道符
cat hello.sh | sort | uniq
---
be better
dddddddd
gggggggggggggggggggg
have a nice day
hello this is linux
i am lhj
zzzzzzzzzzzzzz
---
2、统计出现的次数,使用-c参数
使用-c,–count可以统计重复行出现的次数
cat hello.sh | sort | uniq -c
---
1
3 be better
1 dddddddd
1 gggggggggggggggggggg
3 have a nice day
4 hello this is linux
4 i am lhj
1 zzzzzzzzzzzzzz
---
3、只显示唯一的行,使用-u参数
使用-d,–repeated只显示重复的行并且重复的行只显示一次
cat hello.sh | sort | uniq -dc
---
3 be better
3 have a nice day
4 hello this is linux
4 i am lhj
---
# 可以看到末尾的三行不重复的行没有显示,将重复的行进行去重后显示
4、忽略字母大小写,使用-i参数
[root@VM-4-16-centos ~]# cat test.sh
1 I am PMB
2 i am pmb
[root@VM-4-16-centos ~]# cat test.sh | sort | uniq -i 1
1 I am PMB
5、忽略前N个字段进行去重,使用-f参数
cat test.txt | sort | uniq -i -f 1
test.txt文件中每一行之前有行号,无法使用sort和uniq进行去重,可以使用-f参数忽略每一行的第一个字段,这样就可以忽略每一行之前的行号,对每一行之后的内容进行去重处理。
注意:字段之间必须是空白字符(空格或者tap键均属于空白字符)分隔,使用其他字符无法识别
对于这种情况也可以使用awk命令工具进行处理去除第一列的行号,然后通过管道符丢给sort和uniq命令处理,后续会继续更新awk等重要的文本处理工具。
获取文件行数
wc 命令
获取文件字节数,字数,行数
格式 wc option file
option说明
-c # 统计字节数,或--bytes或——chars:只显示Bytes数;。
-l # 统计行数,或——lines:只显示列数;。
-m # 统计字符数。这个标志不能与 -c 标志一起使用。
-w # 统计字数,或——words:只显示字数。一个字被定义为由空白、跳格或换行字符分隔的字符串。
-L # 打印最长行的长度。
-help # 显示帮助信息
--version # 显示版本信息
application.log文件内容
[root@VM-4-16-centos ~]# cat application.log
1
2
3
4
5
6
7
8
9
10
11
12
13
1、默认没有选项获取字节数,字数,行数
wc application.log
[root@VM-4-16-centos ~]# wc application.log
13 13 30 application.log
2、用wc命令怎么做到只打印统计数字不打印文件名
wc -l < application.log
[root@VM-4-16-centos ~]# wc -l < application.log
13
[root@VM-4-16-centos ~]# wc -l application.log | awk '{print$1}'
13
[root@VM-4-16-centos ~]# cat application.log | wc -l
13
seq 命令
以指定增量从首数开始打印数字到尾数
用于产生从某个数到另外一个数之间的所有整数
语法
seq p 表示尾数
seq p q 表示首数,尾数
seq p q r 表示 首数,增量,尾数
指定格式
-f, --format=格式 使用printf 样式的浮点格式
-s, --separator=字符串 使用指定字符串分隔数字(默认使用:\n)
-w, --equal-width 在列前添加0 使得宽度相同
[root@VM-4-16-centos ~]# seq 3
1
2
3
[root@VM-4-16-centos ~]# seq 1 7
1
2
3
4
5
6
7
[root@VM-4-16-centos ~]# seq 1 4 19
1
5
9
13
17
-f 指定格式
seq -f"%3g" 9 11
9
10
11
%后面指定数字的位数 默认是%g,%3g那么数字位数不足部分是空格。
sed -f"%03g" 9 11
seq -f"str%03g" 9 11
str009
str010
str011
这样的话数字位数不足部分是0,%前面制定字符串。
打印空行行号
grep -n '^$' emptyfile.log | awk -F: '{
print $1}'
awk命令
文本和数据进行处理的编程语言
awk模式和操作
模式
- 正则表达式
- 关系表达式
- 模式匹配
- begin,pattern,end语句块
操作 - 变量或者数组赋值
- 输出命令
- 内置函数
- 控制流语句
脚本基本结构
awk 'BEGIN{ print "start" } pattern{ commands } END{ print "end" }' file
一个awk脚本通常由:BEGIN语句块、能够使用模式匹配的通用语句块、END语句块3部分组成,这三个部分是可选的。任意一个部分都可以不出现在脚本中,脚本通常是被 单引号 或 双引号 中
工作原理
第一步:执行BEGIN{ commands }语句块中的语句;
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ commands }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{ commands }语句块。
BEGIN语句块* 在awk开始从输入流中读取行 之前 被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中。
END语句块* 在awk从输入流中读取完所有的行 之后 即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块。
pattern语句块* 中的通用命令是最重要的部分,它也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块。
echo -e "A line 1\nA line 2" | awk 'BEGIN{ print "Start" } { print } END{ print "End" }'
统计文件中行数
awk 'END{ print NR }' filename
ack命令
ack是比grep好用的文本搜索工具
在当前目录递归搜索单词”eat”,不匹配类似于”feature”或”eating”的字符串:
ack -w eat
[root@localhost ~]# ack -w eat
ackfile.log
1:eat
ack查找my.cnf文件
[root@localhost ~]# ack -f /etc/ | ack my.cnf
/etc/my.cnf
/etc/my.cnf.d/mysql-clients.cnf