1粗粒度,句子级情感分类
情感分析相关的任务有语句级情感分析、评论对象抽取、观点抽取等等。一般来讲,被人们所熟知的情感分析任务是语句级别的情感分析,该任务是在宏观上去分析整句话的感情色彩,其粒度可能相对比较粗。
2细粒度,属性级情感分类
因为在人们进行评论的时候,往往针对某一产品或服务进行多个属性的评论,对每个属性的评论可能也会褒贬不一,因此针对属性级别的情感分析在真实的场景中会更加实用,同时更能给到企业用户或商家更加具体的建议。例如这句关于薯片的评论。
这个薯片味道真的太好了,口感很脆,只是包装很一般。
可以看到,顾客在口感、包装和味道 三个属性上对薯片进行了评价,顾客在味道和口感两个方面给出了好评,但是在包装上给出了负面的评价。只有通过这种比较细粒度的分析,商家才能更有针对性的发现问题,进而改进自己的产品或服务。
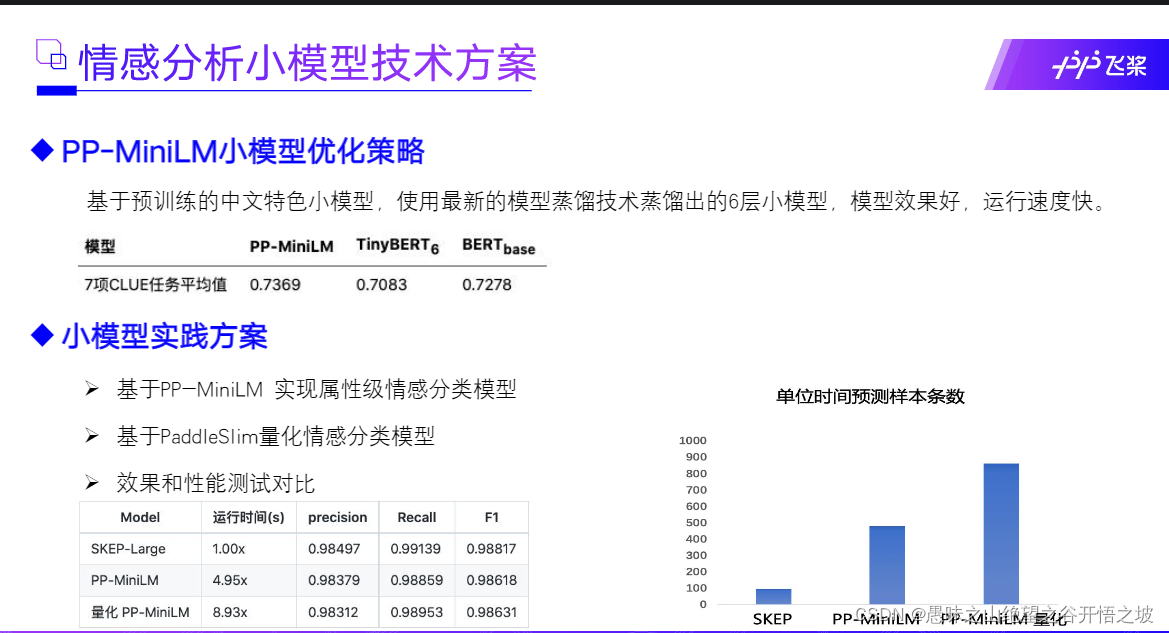
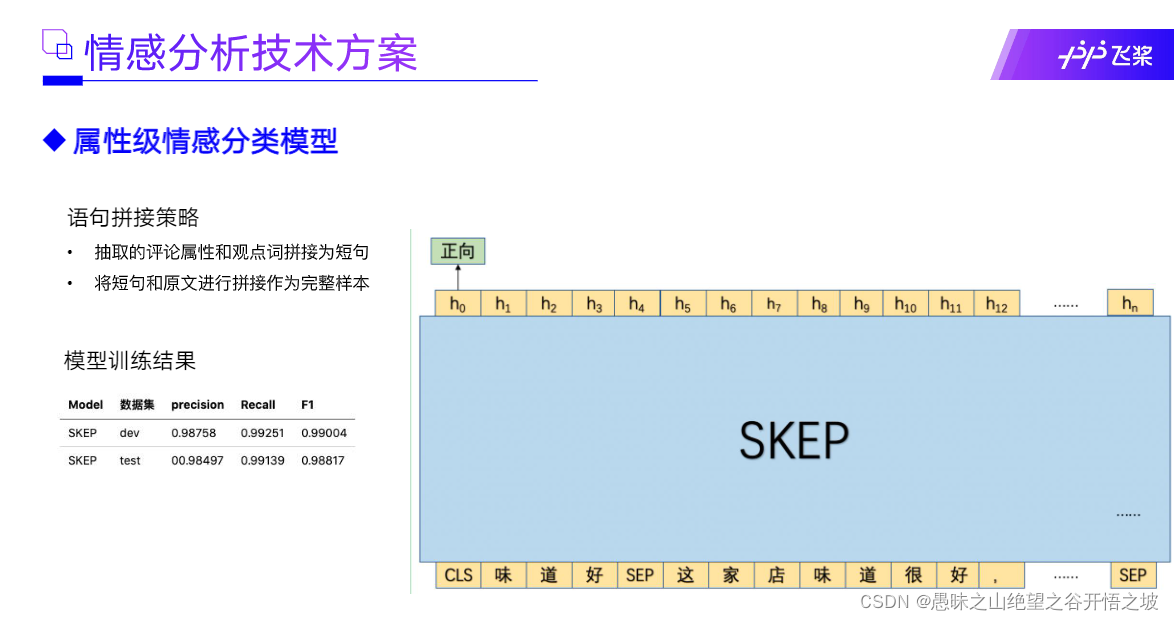
3流程,评论观点抽取模型(评价属性,观点属性)》属性级情感分类模型
整个情感分析的过程大致包含两个阶段,依次是评论观点抽取模型,属性级情感分类模型。对于给定的一段文本,首先基于前者抽取出文本语句中潜在的评论属性以及该属性相应的评论观点,然后将评论属性、观点以及原始文本进行拼接,传给属性级情感分类模型以识别出该评论属性的情感极性。
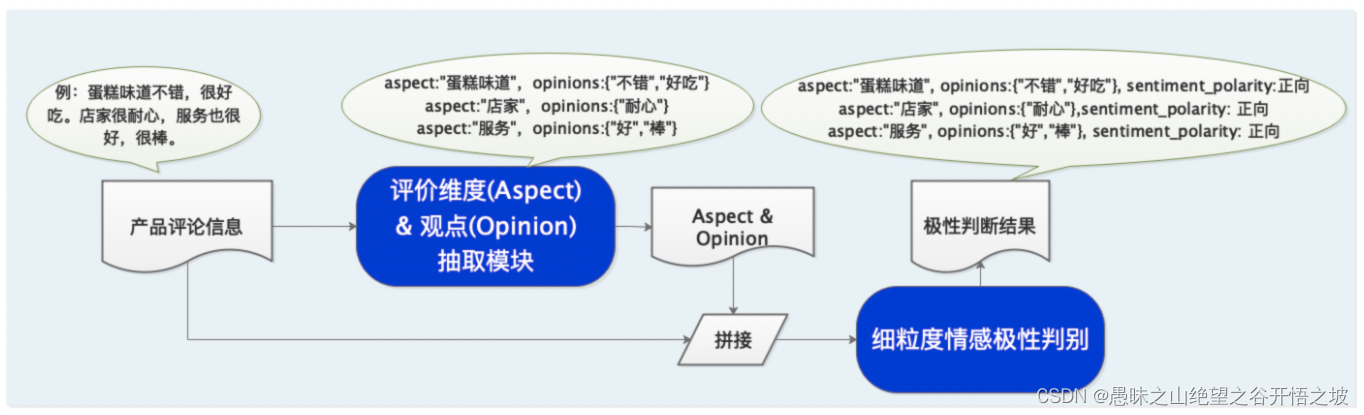
实体抽取
服务好,环境好,做出来效果也不错 B-Aspect I-Aspect B-Opinion O B-Aspect I-Aspect B-Opinion O O O O B-Aspect I-Aspect O B-Opinion I-Opinion
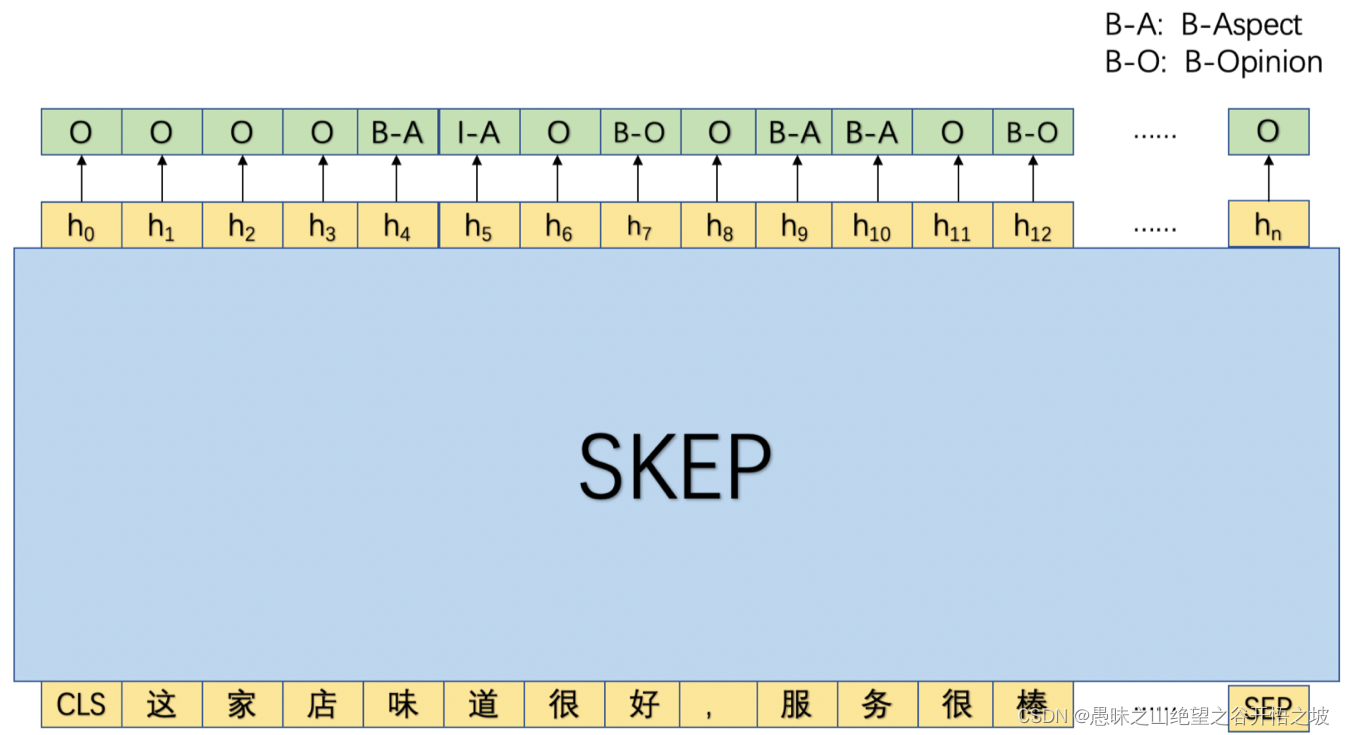
句子级情感分类
1 口味清淡 口味很清淡,价格也比较公道
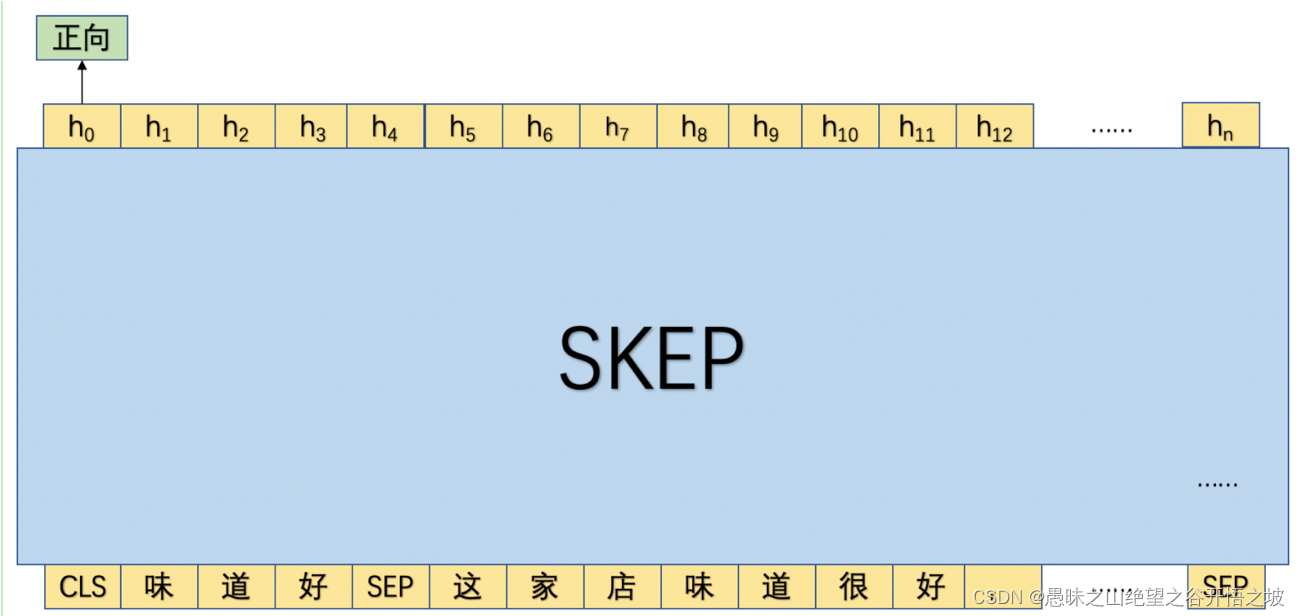
量化
节将基于 PaddleSlim ,对训练好的 PP-MiniLM 小模型进行量化。具体来讲,本节采用的是静态离线量化方法,即在训练好的模型基础上,使用少量校准数据计算量化因子,便可快速得到量化模型。量化过程中,默认使用 avg 的量化策略,对 matmul/matmul_v2 算子进行 channel_wise_abs_max 类型的量化。
本节需要使用安装有 Paddle Inference 预测库的 PaddlePaddle 2.2.1 进行预测,请根据合适的机器环境进行下载安装。若想要得到明显的加速效果,推荐在 NVIDA Tensor Core GPU(如 T4、A10、A100) 上进行测试,若在 V 系列 GPU 卡上测试,由于其不支持 Int8 Tensor Core,将达不到预期的加速效果。
本项目使用了动态 shape 功能 (tuned_dynamic_shape),因此需要设置获取 shape 的范围。Paddle Inference 提供了相应的接口,即首先通过离线输入数据来统计出所有临时 tensor 的 shape 范围,TensorRT 子图的 tensor 输入 shape 范围可直接根据上一步 tune 出来的结果来设置,即可完成自动 shape 范围设置。统计完成后,只需设置统计结果路径,即可启用 tuned_dynamic_shape 功能。
在本案例中,进行性能测试的脚本为 performance_test.py,需要先设置 --collect_shape 参数,然后再取消传入这个参数,再次运行 performance_test.py。可通过设置 --num_epochs 计算多轮运行时间,然后取平均时间作为最终结果,具体使用方式如下:
首先,设置 --collect_shape 参数,生成 shape range info 文件:
课程
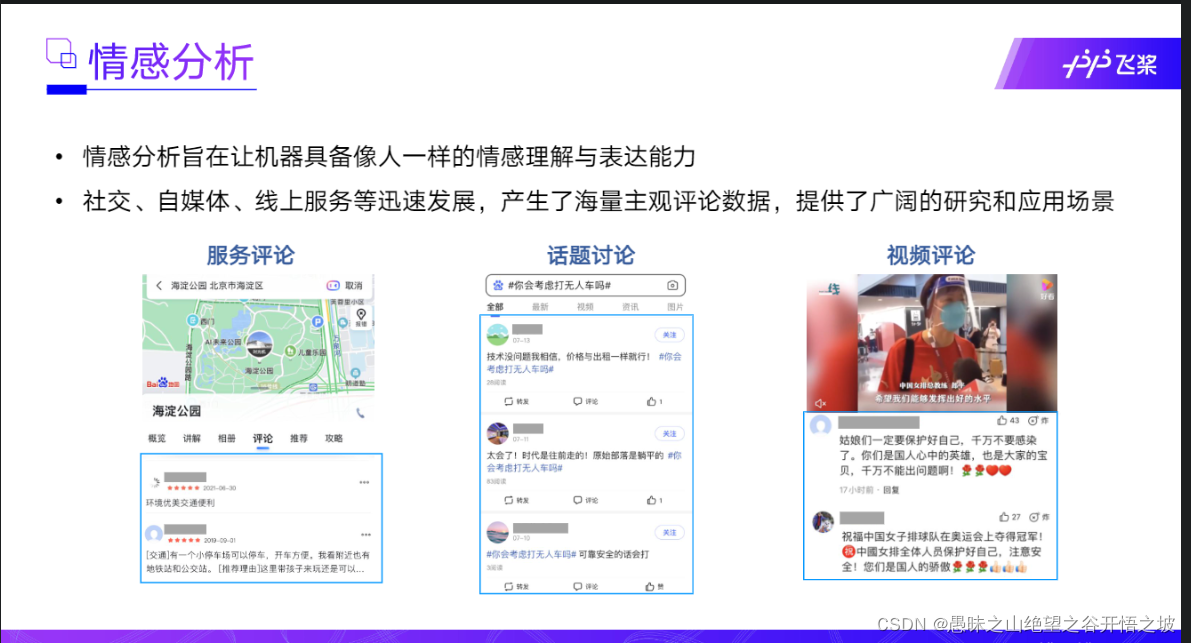
情感分析定义
内容维度和情感维度,包含实体识别和句子分类

情感分析应用

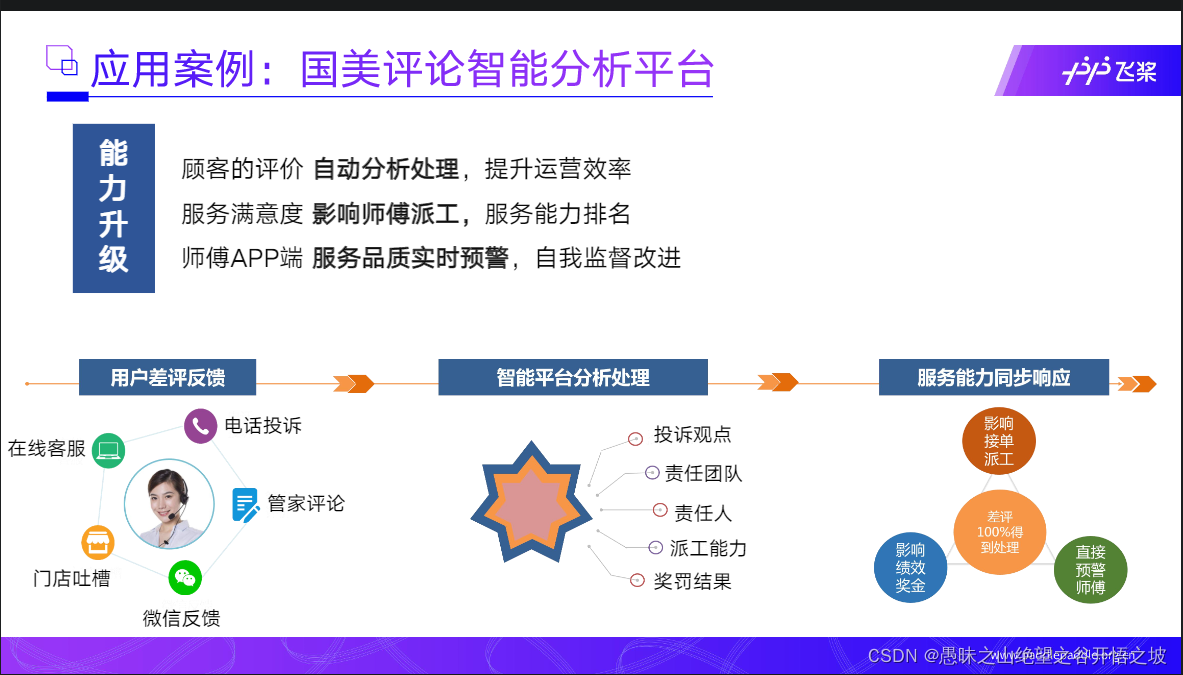
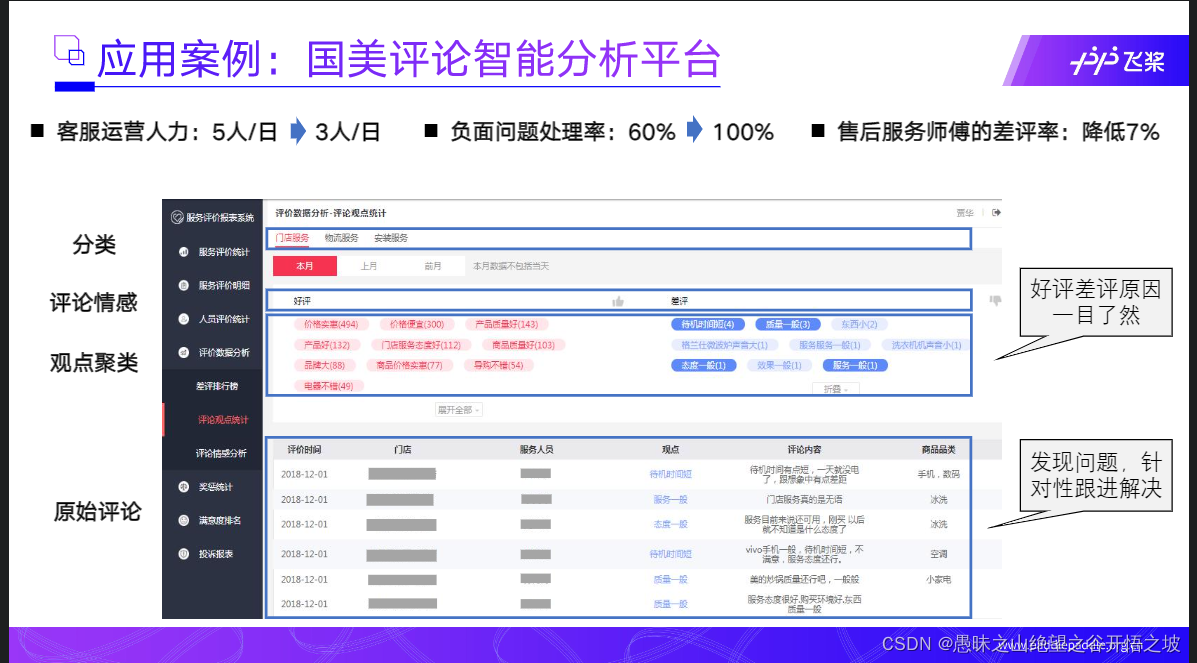
分析平台,输入和输出
可以进行观点聚类分析
发展趋势,规则,机器学习(人为特征工程),深度学习
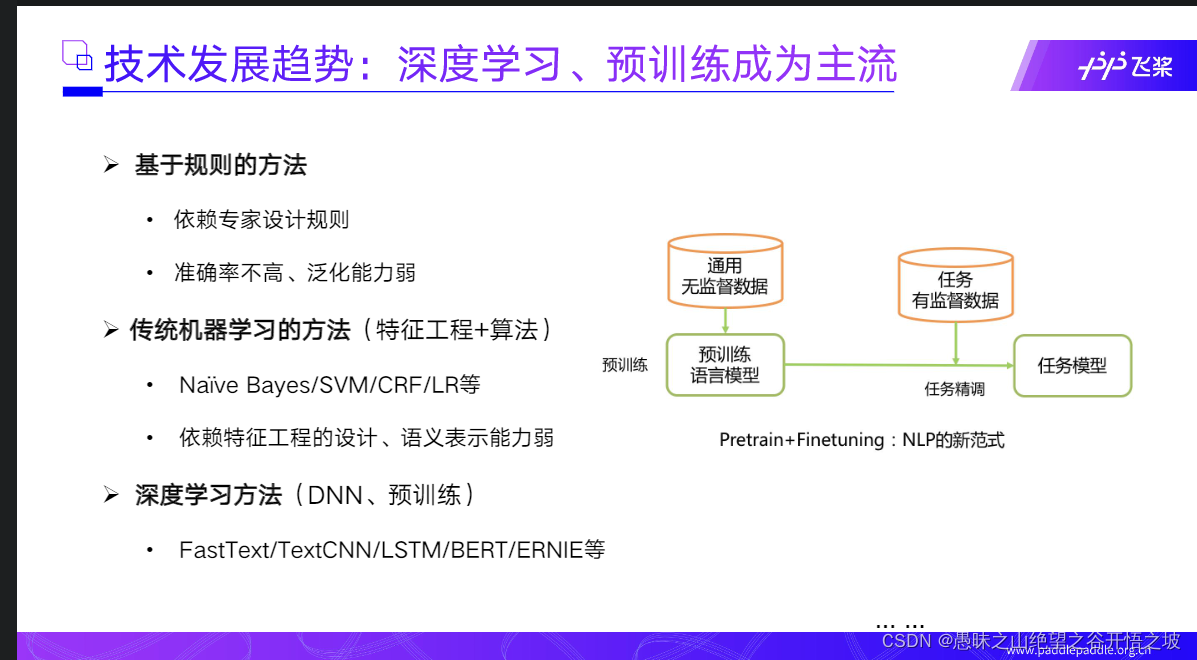
只是增强的预训练模型

效果
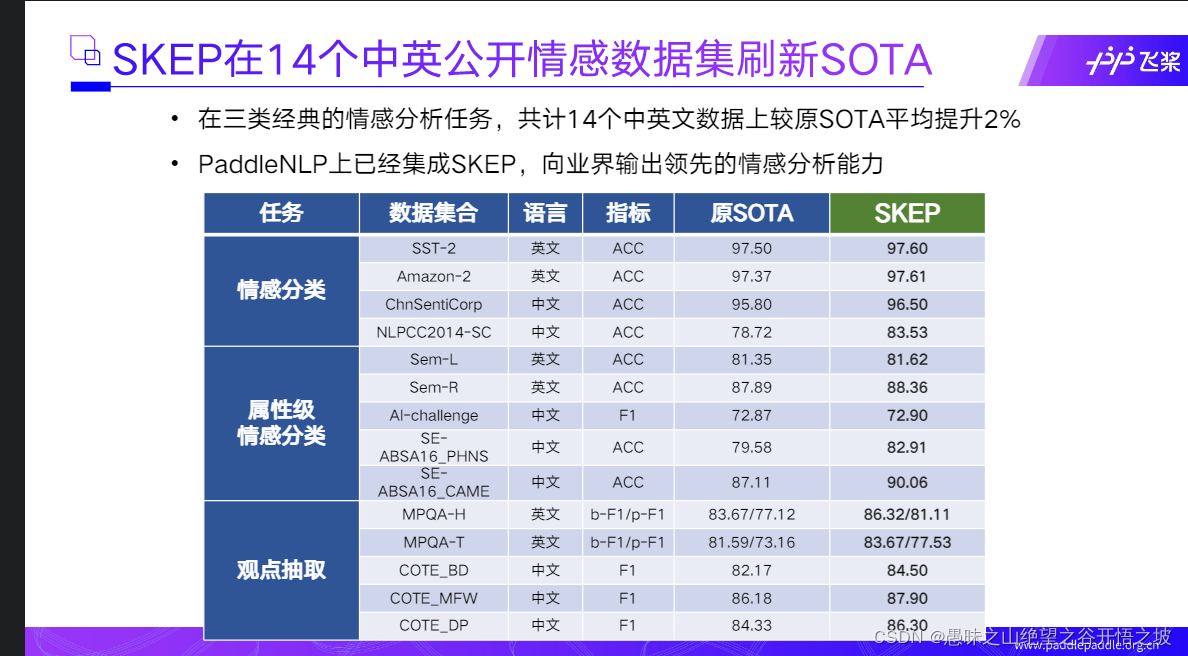
流程
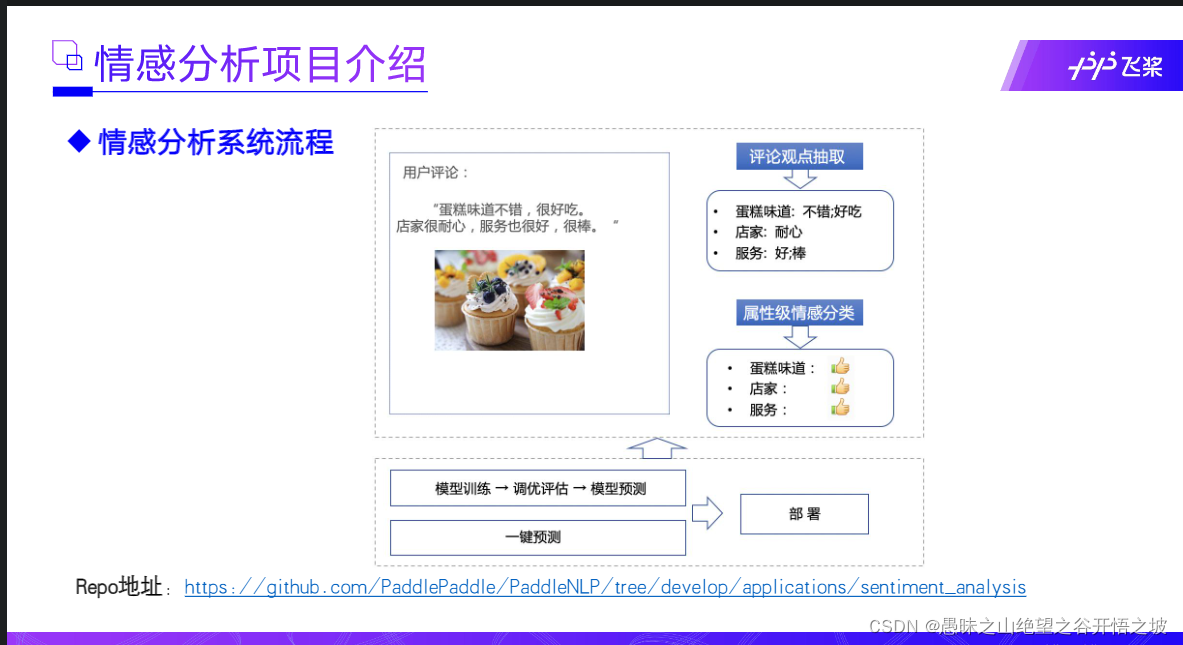
特点

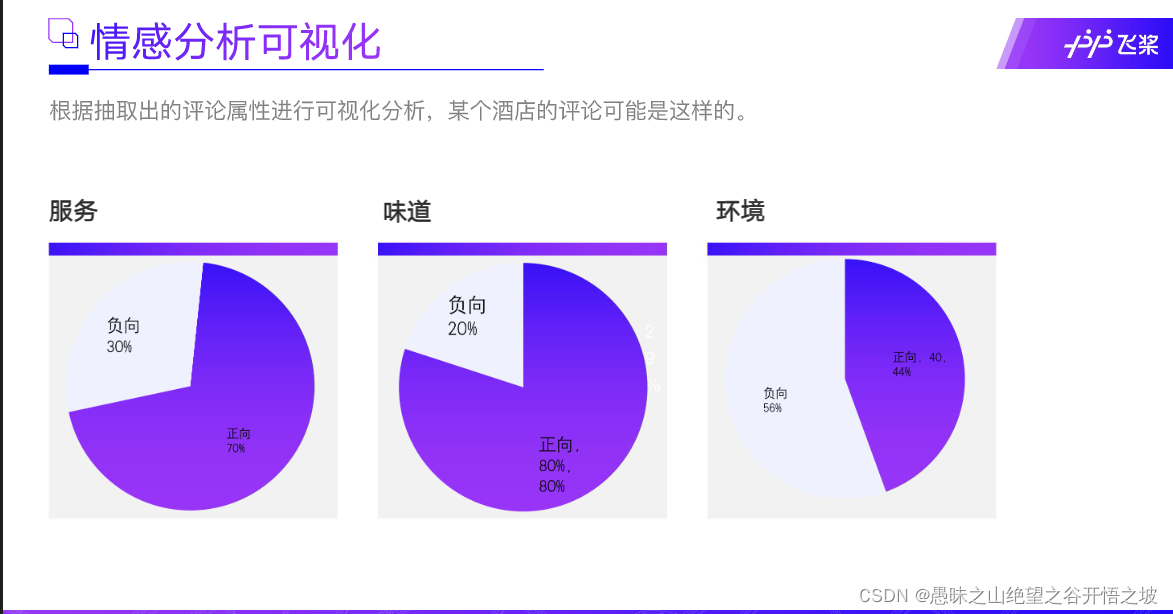
可视化分析
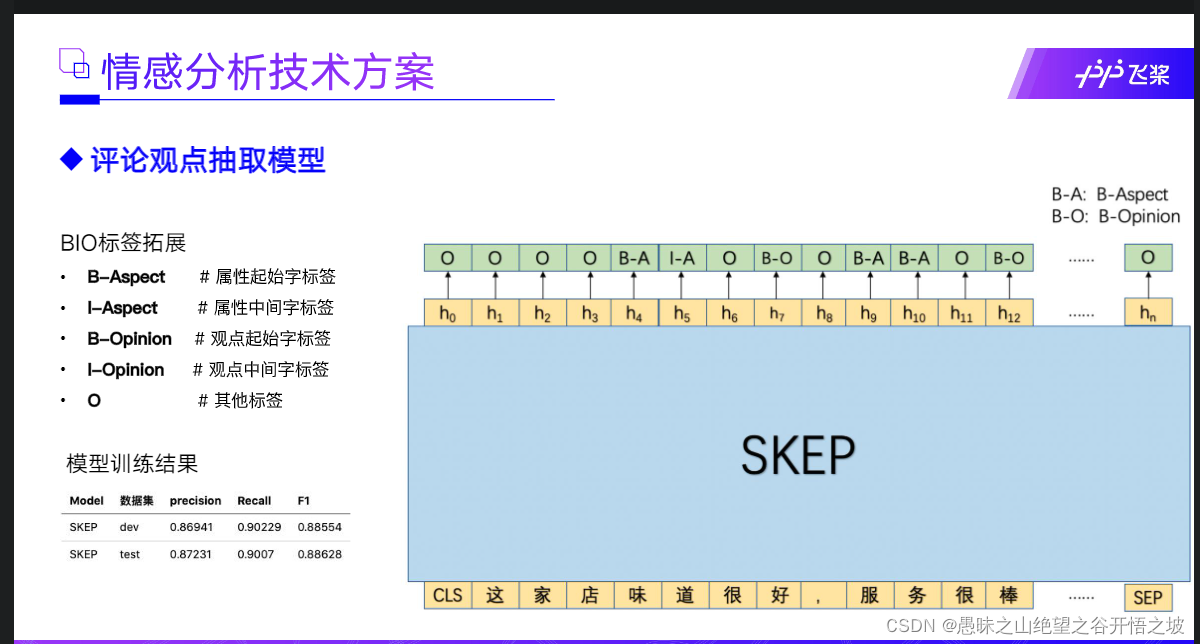
观点抽取
解码策略

属性级情感分析
全流程预测
小模型优化策略