题目:凑平方数
把0~9这10个数字,分成多个组,每个组恰好是一个平方数,这是能够办到的。
比如:0, 36, 5948721
再比如:
1098524736
1, 25, 6390784
0, 4, 289, 15376
等等…
注意,0可以作为独立的数字,但不能作为多位数字的开始。
分组时,必须用完所有的数字,不能重复,不能遗漏。
如果不计较小组内数据的先后顺序,请问有多少种不同的分组方案?
注意:需要提交的是一个整数,不要填写多余内容。
答案:
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Set;
public class Main
{
// 保存10位以内所有的平方数,方便进行全排列
static ArrayList<BigInteger> digitlist;
// 在深度优先搜索过程中标记digitlist中数字是否被选
public static boolean[] select;
// 保存所有的结果用集合去重,题目要求说生成的序列是无序的
public static Set<Set<String>> result = new HashSet<>();
// 检查当前字符串是否有相同字符
public static boolean check(String digitstr)
{
int len = digitstr.length();
Set<Character> set = new HashSet<>();
for (int i = 0; i < len; i++)
{
set.add(digitstr.charAt(i));
}
if (set.size() == len)
{
return true;
}
else
{
return false;
}
}
// 对所有的平方数排列
// dfs(还剩多少待选数字,之前选好的合并的数字串(方便检查是否有重复数字), 之前选好的数字集合)
public static void dfs(int len, String figure, Set<String> figureset)
{
if (len < 0)
return;
if (len == 0)
{
result.add(figureset);// 满足条件加入到结果集合中
return;
}
// 填剩下的那len个数字,当然不只填一个数可以很多,但一次dfs只填一个剩下的交给下一次dfs
for (int i = 0; i < select.length; i++)
{
// 为了避免上一层递归时,使用过的元素,上一层递归用过的就在select中置true了。
if (!select[i])
{
// 本层递归,对于当前的元素,先在select中置true,如果不符合条件,不选当前的这个元素,再置false。
select[i] = true;
String temp = digitlist.get(i).toString();
// 因为最先所有的平方数最先都是从小到大生成的后面的数肯定比当前的数要长因此后面就不用看了
if (len < temp.length())
{
select[i] = false;
// break以后就返回到上一层递归
break;
}
// 检查当前选的数字是否和以前选的有重复数字如果有则放弃这个,否则进行下一层dfs
if (check(figure + temp))
{
HashSet<String> tempset = new HashSet<>();
// 把上一层递归中已选择的平方数所在的HashSet加入tempset中
tempset.addAll(figureset);
tempset.add(temp);
dfs(len - temp.length(), figure + temp, tempset);
}
select[i] = false;
}
}
}
public static void main(String[] args)
{
int i = 0;
digitlist = new ArrayList<>();
// 由小到大生成平方数,把10位以内所有平方数算出来
while (true)
{
BigInteger temp = BigInteger.valueOf(i++).pow(2);
if (temp.toString().length() <= 10)
{
if (check(temp.toString()))
{
digitlist.add(temp);
}
}
else
{
break;
}
}
select = new boolean[digitlist.size()];
dfs(10, "", new HashSet<String>());
// 输出最终计算出的所有结果数目
System.out.println(result.size());
}
}心得:
注意点:
1、这些平方数都不超过10位
2、每一个平方数中不能有重复的数字,将数转为String来check
Set set = new HashSet<>();利用HashSet<>(),比较集合的size()和原字符串的长度来判断是否有重复的字符。
3、利用了递归的方式来进行遍历、穷举
4、必须将穷举法和DFS结合起来使用;如果只用DFS的话,可以保证每一个数字不重复,但无法确定每一个平方数的位数。
5、这道题的核心:一、在一组数据中,每一个数字都不能重复;二、一组数据的每一个数都必须为平方数;三、在所有数据组的集合中,数据组不能重复。利用HashSet来去重。
6、利用穷举法举出所有不超过10位数的平方数的时候,就保证每一个平方数中的数字都不重复。
7、在本道题中,HashSet去重的应用在:1、一个字符串中的字符中的数字;2、之前已选择的平方数+即将选择的平方数中的数字;3、已选择的方案与即将选择的方案。
//DFS 的总体格局:
开始–判断,当到达最后一层的时候,就return–for循环遍历,长度为flag[]的长度–if判断flag[i],看当前元素是否已使用过,false为未用过–如果没用过,flag[i]值置true,选择,进入下一层dfs(要传入下一层的对象),flag[i]值置 false 。
flag[]保证的是元素的不重复
这是DFS的基本格局,有些题目会在此基础上,进行一些改变,形成DFS 的变体,例如:DFS+穷举法、在进入下一层dfs之前,进行一些剪枝,就是加一个或多个if语句的判断过滤。
当传入下一层的对象有多个的时候,一定要小心了,多做几个还原的方案,就像本道题,就有点坑:
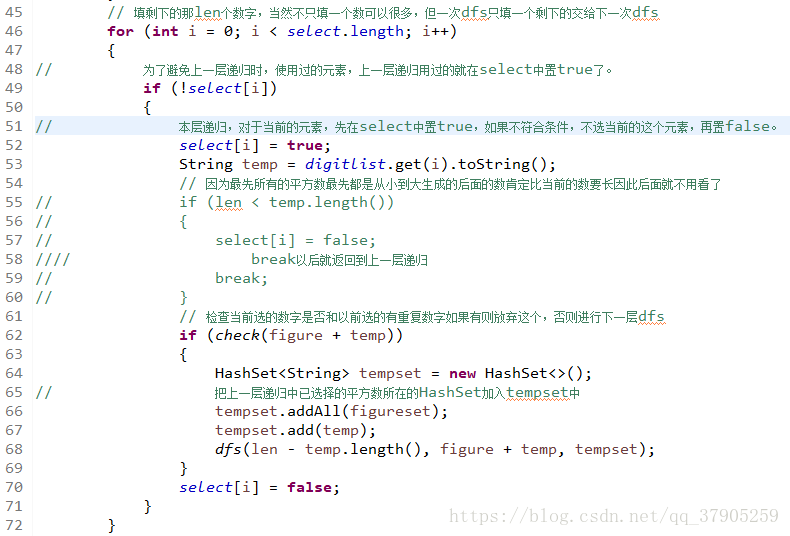
这样制作的还原策略是正确的,答案为 300
但是我改一下,
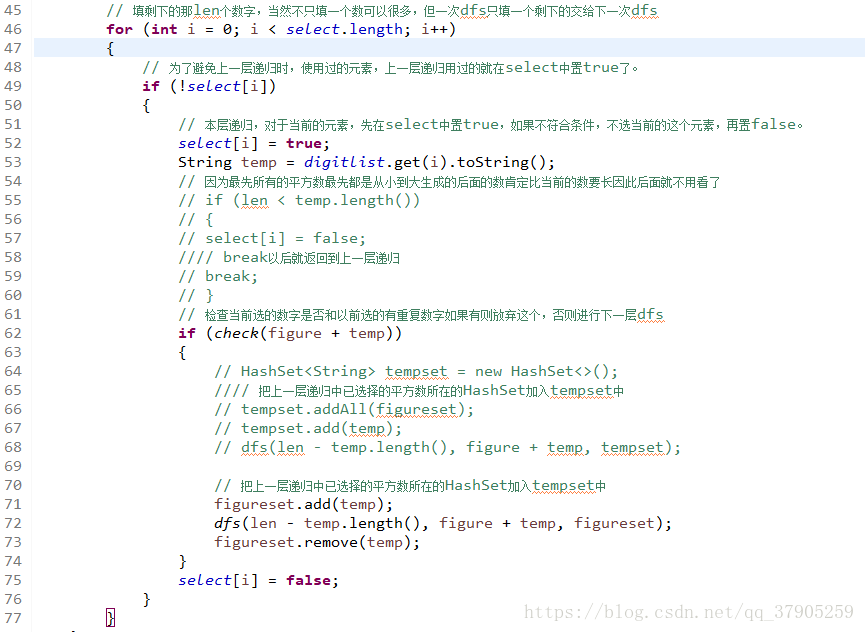
这样就错了,结果为299
我也不懂我为什么它会这样,太可怕了,以为自己是对的,结果错了,离正确结果差“1”步之遥。
反正,记住一点,当传入下一层的对象有多个的时候,多做几个还原策略试试,看看结果是否一致,尽可能地做到本层对象与下层对象相分离,当下一层return的时候,只要把flag[i]置为false,就完成还原操作了。
int exponent = 2;
BigInteger bi1, bi2;
bi1 = new BigInteger(“6”);
bi2 = bi1.pow(exponent);
Result is 6^2 = 36
集合框架(HashSet存储字符串并遍历)
https://blog.csdn.net/kairui007/article/details/50238717
HashSet保证元素唯一性
HashSet原理
- 对于基本类型,当HashSet调用add()方法存储对象的时候, 先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象。
- 如果没有哈希值相同的对象就直接存入集合 。
- 如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存。
- 对于自定义的类,存入HashSet去重复
- 类中必须重写hashCode()和equals()方法。
- hashCode():属性相同的对象返回值必须相同,属性不同的返回值尽量不同(提高效率)。equals():属性相同返回true, 属性不同返回false,返回false的时候存储 。