最近在做爬虫的细节整理,想要弄清楚一些原来没有注意的问题,特此总结!
在进行对HTML解析时我们可能会遇到如下五种情况:
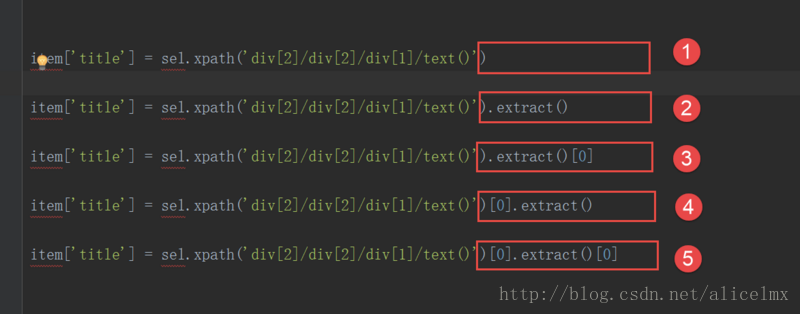
- 返回一个SelectorList 对象
SelectorList 类是内建 list 类的子类,提供了一些额外的方法:
xpath(query)
css(query)
extract()
re()
__nonzero__()- 返回一个list(就是系统自带的那个) 里面是一些你提取的内容
- 返回2中list的第一个元素(如果list为空抛出异常)
- 返回1中SelectorList里的第一个元素(如果list为空抛出异常),和3达成的效果一致
- 返回的是一个str, 所以5会返回str的第一个字符