比如有一个数据框,根据第一列ID去重,将所有重复的行删除,你用unique和duplicate函数,可能是错误的,这里总结一下。
模拟数据
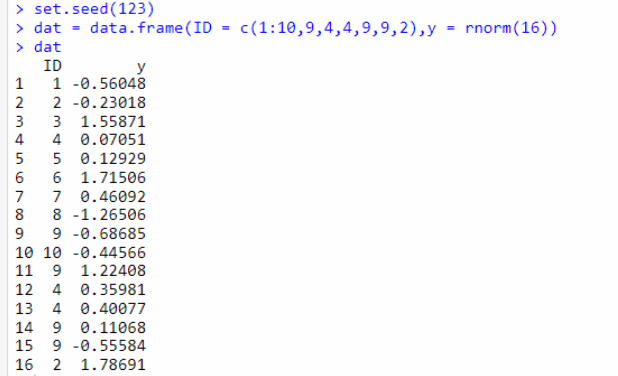
set.seed(123)
dat = data.frame(ID = c(1:10,9,4,4,9,9,2),y = rnorm(16))
dat
需求:
把ID重复的行都去掉。
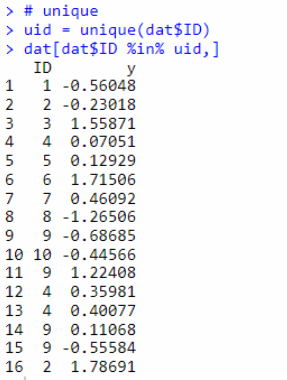
错误1:用unique函数
unique函数,会去掉重复的ID,保留不重复的ID,利用 1,2,3,1中1是重复的,用unique之后剩下:1,2,3,而不是2,3。
所以,下面的步骤是错误的。
uid = unique(dat$ID)
dat[dat$ID %in% uid,]
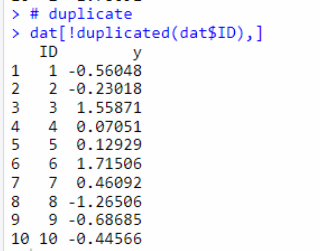
错误2:duplicate函数
duplicate会返回TRUE和FALSE状态,返回的是唯一值,而不是去掉所有重复ID的值。类似unique,不是我们想要的。
dat[!duplicated(dat$ID),]
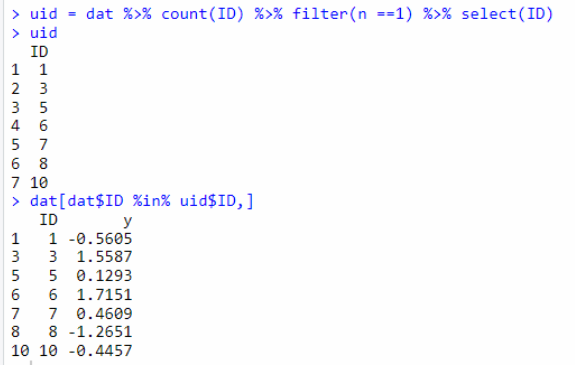
正确1:用filter函数
先判断出现的次数,提取ID,然后用filter进行提取。
uid = dat %>% count(ID) %>% filter(n ==1) %>% select(ID)
uid
dat[dat$ID %in% uid$ID,]
正确2:用%in%
先用duplicate打印出重复的ID,然后用filter排除即可。
uid2 = dat$ID[duplicated(dat$ID)]
uid2
dat %>% filter(!ID %in% uid2)

完整测试代码:
set.seed(123)
dat = data.frame(ID = c(1:10,9,4,4,9,9,2),y = rnorm(16))
dat
# 错误方法
dat[!duplicated(dat$ID),]
# 正确方法1
uid = unique(dat$ID)
dat[dat$ID %in% uid,]
uid = dat %>% count(ID) %>% filter(n ==1) %>% select(ID)
uid
dat %>% filter(ID %in% uid$ID)
# 正确方法2
uid2 = dat$ID[duplicated(dat$ID)]
uid2
dat %>% filter(!ID %in% uid2)